
1. 개요
이 실습에서는 데이터 탐색 및 ML 모델 학습에 Vertex AI Workbench를 사용하는 방법을 알아봅니다.
학습 내용
다음 작업을 수행하는 방법을 배우게 됩니다.
- Vertex AI Workbench 인스턴스 만들기 및 구성
- Vertex AI Workbench BigQuery 커넥터 사용
- Vertex AI Workbench 커널에서 모델 학습
Google Cloud에서 이 실습을 진행하는 데 드는 총 비용은 약 $1입니다.
2. Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 이전할 수도 있습니다.
Vertex AI에는 엔드 투 엔드 ML 워크플로를 지원하는 다양한 제품이 포함되어 있습니다. 이 실습에서는 Vertex AI Workbench에 중점을 둡니다.
Vertex AI Workbench는 데이터 서비스 (예: Dataproc, Dataflow, BigQuery, Dataplex) 및 Vertex AI와의 긴밀한 통합을 통해 사용자가 엔드 투 엔드 노트북 기반 워크플로를 빠르게 빌드할 수 있도록 지원합니다. 데이터 과학자는 이를 통해 GCP 데이터 서비스에 연결하고, 데이터 세트를 분석하고, 다양한 모델링 기법을 실험하고, 학습된 모델을 프로덕션에 배포하고, 모델 수명 주기를 통해 MLOps를 관리할 수 있습니다.
3. 사용 사례 개요
이 실습에서는 London Bicycles Hire 데이터 세트를 살펴봅니다. 이 데이터에는 2011년부터 런던의 공공 자전거 공유 프로그램에서 이루어진 자전거 여행에 관한 정보가 포함되어 있습니다. 먼저 Vertex AI Workbench BigQuery 커넥터를 통해 BigQuery에서 이 데이터 세트를 살펴봅니다. 그런 다음 pandas를 사용하여 데이터를 Jupyter Notebook에 로드하고, TensorFlow 모델을 학습시켜 여행이 발생한 시점과 사람이 자전거를 탄 거리를 기반으로 자전거 여행의 기간을 예측합니다.
이 실습에서는 Keras 사전 처리 레이어를 사용하여 모델 학습을 위한 입력 데이터를 변환하고 준비합니다. 이 API를 사용하면 TensorFlow 모델 그래프에 직접 사전 처리를 빌드하여 학습 데이터와 서빙 데이터가 동일한 변환을 거치도록 함으로써 학습/서빙 편향의 위험을 줄일 수 있습니다. TensorFlow 2.6부터 이 API는 안정적입니다. 이전 버전의 TensorFlow를 사용하는 경우 실험적 심볼을 가져와야 합니다.
4. 환경 설정하기
이 Codelab을 실행하려면 결제가 사용 설정된 Google Cloud Platform 프로젝트가 필요합니다. 프로젝트를 만들려면 여기의 안내를 따르세요.
1단계: Compute Engine API 사용 설정
아직 사용 설정되지 않은 경우 Compute Engine으로 이동하고 사용 설정을 선택합니다.
2단계: Vertex AI API 사용 설정
Cloud Console의 Vertex AI 섹션으로 이동하고 Vertex AI API 사용 설정을 클릭합니다.

3단계: Vertex AI Workbench 인스턴스 만들기
Cloud 콘솔의 Vertex AI 섹션에서 'Workbench'를 클릭합니다.

Notebooks API를 아직 사용 설정하지 않은 경우 사용 설정합니다.

사용 설정했으면 관리형 노트북을 클릭합니다.

그런 다음 새 노트북을 선택합니다.

노트북 이름을 지정하고 권한에서 서비스 계정을 선택합니다.

고급 설정을 선택합니다.
아직 사용 설정되지 않은 경우 보안에서 '터미널 사용 설정'을 선택합니다.

다른 고급 설정은 모두 그대로 두면 됩니다.
그런 다음 만들기를 클릭합니다.
인스턴스가 생성되면 JupyterLab 열기를 선택합니다.

5. BigQuery에서 데이터 세트 살펴보기
Vertex AI Workbench 인스턴스에서 왼쪽으로 이동하여 BigQuery in Notebooks 커넥터를 클릭합니다.

BigQuery 커넥터를 사용하면 BigQuery 데이터 세트를 쉽게 탐색하고 쿼리할 수 있습니다. 프로젝트의 데이터 세트 외에도 프로젝트 추가 버튼을 클릭하여 다른 프로젝트의 데이터 세트를 탐색할 수 있습니다.

이 실습에서는 BigQuery 공개 데이터 세트의 데이터를 사용합니다. london_bicycles 데이터 세트가 표시될 때까지 아래로 스크롤합니다. 이 데이터 세트에는 cycle_hire 및 cycle_stations라는 두 개의 테이블이 있습니다. 각각 살펴보겠습니다.

먼저 cycle_hire 테이블을 더블클릭합니다. 테이블이 테이블의 스키마와 행 수, 크기와 같은 메타데이터가 포함된 새 탭으로 열립니다.

미리보기 탭을 클릭하면 데이터 샘플을 볼 수 있습니다. 인기 있는 여정을 확인하기 위해 간단한 쿼리를 실행해 보겠습니다. 먼저 테이블 쿼리 버튼을 클릭합니다.

그런 다음 SQL 편집기에 다음을 붙여넣고 쿼리 제출을 클릭합니다.
SELECT
start_station_name,
end_station_name,
IF(start_station_name = end_station_name,
TRUE,
FALSE) same_station,
AVG(duration) AS avg_duration,
COUNT(*) AS total_rides
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY
start_station_name,
end_station_name,
same_station
ORDER BY
total_rides DESC
쿼리 결과를 보면 하이드 파크 코너역을 오가는 자전거 여행이 가장 인기 있었음을 알 수 있습니다.
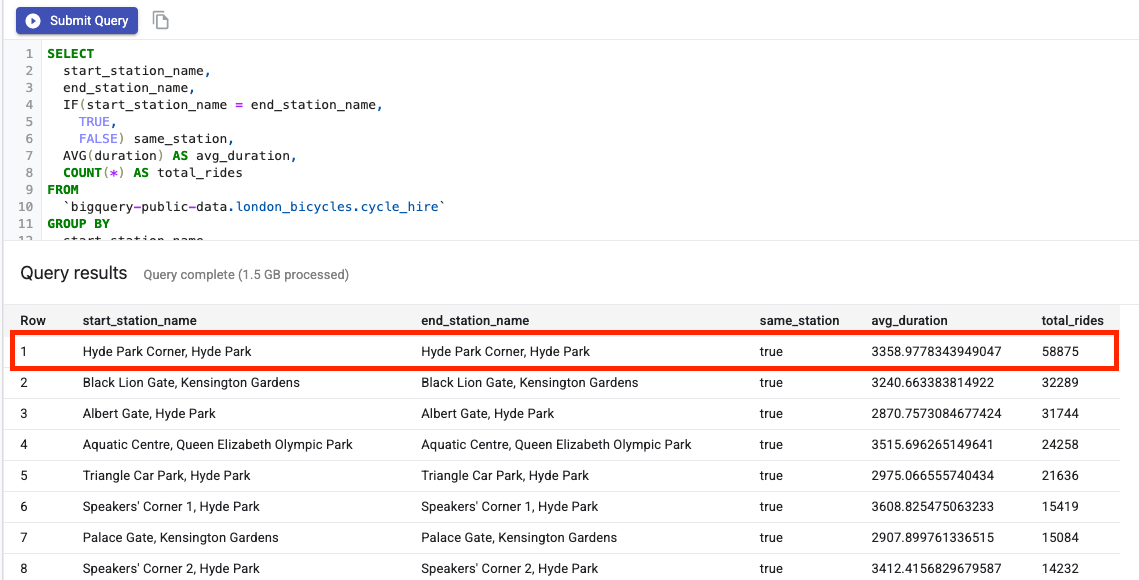
다음으로 각 역에 관한 정보를 제공하는 cycle_stations 테이블을 더블클릭합니다.
cycle_hire 테이블과 cycle_stations 테이블을 조인하려고 합니다. cycle_stations 테이블에는 각 대여소의 위도/경도가 포함됩니다. 이 정보를 사용하여 시작 대여소와 종료 대여소 간의 거리를 계산하여 각 자전거 여행에서 이동한 거리를 추정합니다.
이 계산을 수행하려면 BigQuery 지리 함수를 사용합니다. 구체적으로 각 위도/경도 문자열을 ST_GEOGPOINT로 변환하고 ST_DISTANCE 함수를 사용하여 두 지점 간의 직선 거리를 미터 단위로 계산합니다. 이 값을 각 사이클 이동에서 이동한 거리의 프록시로 사용합니다.
다음 쿼리를 SQL 편집기에 복사한 다음 '쿼리 제출'을 클릭합니다. 사이클의 시작 스테이션과 종료 스테이션의 위도/경도를 가져오기 위해 스테이션 테이블을 두 번 조인해야 하므로 JOIN 조건에는 세 개의 테이블이 있습니다.
WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING
6. TensorFlow 커널에서 ML 모델 학습
Vertex AI Workbench에는 단일 노트북 인스턴스에서 TensorFlow, PySpark, R 등의 커널을 모두 실행할 수 있는 컴퓨팅 호환성 레이어가 있습니다. 이 실습에서는 TensorFlow 커널을 사용하여 노트북을 만듭니다.
DataFrame 만들기
쿼리가 실행된 후 DataFrame의 코드 복사를 클릭합니다. 이렇게 하면 BigQuery 클라이언트에 연결되고 이 데이터를 Pandas DataFrame으로 추출하는 Python 코드를 노트북에 붙여넣을 수 있습니다.

그런 다음 런처로 돌아가 TensorFlow 2 노트북을 만듭니다.

노트북의 첫 번째 셀에 쿼리 편집기에서 복사한 코드를 붙여넣습니다. 다음과 같이 표시됩니다.
# The following two lines are only necessary to run once.
# Comment out otherwise for speed-up.
from google.cloud.bigquery import Client, QueryJobConfig
client = Client()
query = """WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING"""
job = client.query(query)
df = job.to_dataframe()
이 실습에서는 학습 시간을 단축하기 위해 데이터 세트를 700, 000개로 제한합니다. 하지만 쿼리를 수정하고 전체 데이터 세트를 사용해 실험해 보세요.
다음으로 필요한 라이브러리를 가져옵니다.
from datetime import datetime
import pandas as pd
import tensorflow as tf
다음 코드를 실행하여 이 연습의 ML 부분에 필요한 열만 포함된 축소된 데이터 프레임을 만듭니다.
values = df['bike'].values
duration = list(map(lambda a: a['duration'], values))
distance = list(map(lambda a: a['distance'], values))
dates = list(map(lambda a: a['start_date'], values))
data = pd.DataFrame(data={'duration': duration, 'distance': distance, 'start_date':dates})
data = data.dropna()
start_date 열은 Python datetime입니다. 모델에서 이 datetime를 직접 사용하는 대신 자전거 여행이 발생한 요일과 시간을 나타내는 두 가지 새로운 기능을 만듭니다.
data['weekday'] = data['start_date'].apply(lambda a: a.weekday())
data['hour'] = data['start_date'].apply(lambda a: a.time().hour)
data = data.drop(columns=['start_date'])
마지막으로 이해하기 쉽도록 기간 열을 초에서 분으로 변환합니다.
data['duration'] = data['duration'].apply(lambda x:float(x / 60))
형식이 지정된 DataFrame의 처음 몇 행을 검토합니다. 이제 각 사이클 여행에 대해 여행이 발생한 요일과 시간, 이동 거리에 관한 데이터를 확인할 수 있습니다. 이 정보를 바탕으로 이동 시간을 예측합니다.
data.head()

모델을 만들고 학습시키기 전에 데이터를 학습 세트와 검증 세트로 분할해야 합니다.
# Use 80/20 train/eval split
train_size = int(len(data) * .8)
print ("Train size: %d" % train_size)
print ("Evaluation size: %d" % (len(data) - train_size))
# Split data into train and test sets
train_data = data[:train_size]
val_data = data[train_size:]
TensorFlow 모델 만들기
Keras Functional API를 사용하여 TensorFlow 모델을 만듭니다. 입력 데이터를 사전 처리하려면 Keras 사전 처리 레이어 API를 사용합니다.
다음 유틸리티 함수는 pandas DataFrame에서 tf.data.Dataset를 만듭니다.
def df_to_dataset(dataframe, label, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop(label)
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
위 함수를 사용하여 tf.data.Dataset를 두 개 만듭니다. 하나는 학습용이고 하나는 검증용입니다. 경고가 표시될 수 있지만 무시해도 됩니다.
train_dataset = df_to_dataset(train_data, 'duration')
validation_dataset = df_to_dataset(val_data, 'duration')
모델에서 다음 전처리 레이어를 사용합니다.
- 정규화 레이어: 입력 특성의 특성별 정규화를 수행합니다.
- IntegerLookup 레이어: 정수 범주형 값을 정수 색인으로 변환합니다.
- CategoryEncoding 레이어: 정수 범주형 특성을 원-핫, 멀티-핫 또는 TF-IDF 밀집 표현으로 변환합니다.
이러한 레이어는 학습이 불가능합니다. 대신 adapt() 메서드를 통해 학습 데이터에 노출하여 사전 처리 레이어의 상태를 설정합니다.
다음 함수는 거리 특성에 사용할 수 있는 정규화 레이어를 만듭니다. 학습 데이터에서 adapt() 메서드를 사용하여 모델을 적합하기 전에 상태를 설정합니다. 이렇게 하면 정규화에 사용할 평균과 분산이 계산됩니다. 나중에 검증 데이터 세트를 모델에 전달하면 학습 데이터에서 계산된 동일한 평균과 분산이 검증 데이터를 스케일링하는 데 사용됩니다.
def get_normalization_layer(name, dataset):
# Create a Normalization layer for our feature.
normalizer = tf.keras.layers.Normalization(axis=None)
# Prepare a Dataset that only yields our feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
마찬가지로 다음 함수는 시간 및 요일 특성에 사용할 카테고리 인코딩을 만듭니다.
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
index = tf.keras.layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Create a Discretization for our integer indices.
encoder = tf.keras.layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply one-hot encoding to our indices. The lambda function captures the
# layer so we can use them, or include them in the functional model later.
return lambda feature: encoder(index(feature))
다음으로 모델의 전처리 부분을 만듭니다. 먼저 각 기능에 대해 tf.keras.Input 레이어를 만듭니다.
# Create a Keras input layer for each feature
numeric_col = tf.keras.Input(shape=(1,), name='distance')
hour_col = tf.keras.Input(shape=(1,), name='hour', dtype='int64')
weekday_col = tf.keras.Input(shape=(1,), name='weekday', dtype='int64')
그런 다음 정규화 및 카테고리 인코딩 레이어를 만들어 목록에 저장합니다.
all_inputs = []
encoded_features = []
# Pass 'distance' input to normalization layer
normalization_layer = get_normalization_layer('distance', train_dataset)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
# Pass 'hour' input to category encoding layer
encoding_layer = get_category_encoding_layer('hour', train_dataset, dtype='int64')
encoded_hour_col = encoding_layer(hour_col)
all_inputs.append(hour_col)
encoded_features.append(encoded_hour_col)
# Pass 'weekday' input to category encoding layer
encoding_layer = get_category_encoding_layer('weekday', train_dataset, dtype='int64')
encoded_weekday_col = encoding_layer(weekday_col)
all_inputs.append(weekday_col)
encoded_features.append(encoded_weekday_col)
전처리 레이어를 정의한 후 모델의 나머지 부분을 정의할 수 있습니다. 모든 입력 특성을 연결하고 이를 밀도층에 전달합니다. 이 문제는 회귀 문제이므로 출력 레이어는 단일 단위입니다.
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(64, activation="relu")(all_features)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
마지막으로 모델을 컴파일합니다.
model.compile(optimizer = tf.keras.optimizers.Adam(0.001),
loss='mean_squared_logarithmic_error')
이제 모델을 정의했으므로 아키텍처를 시각화할 수 있습니다.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")

이 모델은 이 간단한 데이터 세트에서는 다소 복잡합니다. 데모용입니다.
코드가 실행되는지 확인하기 위해 1에포크 동안 학습해 보겠습니다.
model.fit(train_dataset, validation_data = validation_dataset, epochs = 1)
GPU로 모델 학습
그런 다음 모델을 더 오래 학습시키고 하드웨어 전환기를 사용하여 학습 속도를 높입니다. Vertex AI Workbench를 사용하면 인스턴스를 종료하지 않고도 하드웨어를 변경할 수 있습니다. 필요할 때만 GPU를 추가하면 비용을 절감할 수 있습니다.
하드웨어 프로필을 변경하려면 오른쪽 상단에 있는 머신 유형을 클릭하고 하드웨어 수정을 선택합니다.

'GPU 연결'을 선택하고 NVIDIA T4 Tensor Core GPU를 선택합니다.

하드웨어가 구성되는 데 약 5분이 소요됩니다. 프로세스가 완료되면 모델을 조금 더 학습시켜 보겠습니다. 이제 각 에포크에 걸리는 시간이 줄어든 것을 확인할 수 있습니다.
model.fit(train_dataset, validation_data = validation_dataset, epochs = 5)
🎉 수고하셨습니다. 🎉
Vertex AI Workbench를 사용하여 다음을 수행하는 방법을 배웠습니다.
- BigQuery에서 데이터 탐색
- BigQuery 클라이언트를 사용하여 Python에 데이터 로드
- Keras 전처리 레이어와 GPU를 사용하여 TensorFlow 모델 학습
Vertex AI의 다른 부분에 대해 자세히 알아보려면 문서를 확인하세요.
7. 정리
노트북이 유휴 시간 60분 후에 타임아웃되도록 구성했으므로 인스턴스를 종료할 필요가 없습니다. 인스턴스를 수동으로 종료하려면 콘솔의 Vertex AI Workbench 섹션에서 중지 버튼을 클릭합니다. 노트북을 완전히 삭제하려면 삭제 버튼을 클릭합니다.
