
1. Visão geral
Neste laboratório, você vai aprender a usar o Vertex AI Workbench para explorar dados e treinamento de modelo de ML.
Conteúdo do laboratório
Você vai aprender a:
- Criar e configurar uma instância do Vertex AI Workbench
- Usar o conector do BigQuery do Vertex AI Workbench
- Treinar um modelo em um kernel do Vertex AI Workbench
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$ 1.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos para a Vertex AI.
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho integrais de ML. Este laboratório vai se concentrar no Vertex AI Workbench.
Com o Vertex AI Workbench, os usuários criam de modo rápido fluxos de trabalho completos com notebooks, por meio da integração entre serviços de dados (como Dataproc, Dataflow, BigQuery e Dataplex) e a Vertex AI. Ele permite que cientistas de dados se conectem aos serviços de dados do GCP, analisem conjuntos de dados, testem diferentes técnicas de modelagem, implantem modelos treinados na produção e gerenciem MLOps durante o ciclo de vida do modelo.
3. Visão geral do caso de uso
Neste laboratório, você vai analisar o conjunto de dados London Bicycles Hire. Esses dados contêm informações sobre viagens de bicicleta do programa público de compartilhamento de bicicletas de Londres desde 2011. Primeiro, você vai analisar esse conjunto de dados no BigQuery usando o conector do BigQuery no Vertex AI Workbench. Em seguida, você vai carregar os dados em um Jupyter Notebook usando o pandas e treinar um modelo do TensorFlow para prever a duração de um passeio de bicicleta com base em quando ele ocorreu e na distância percorrida.
Este laboratório usa camadas de pré-processamento do Keras para transformar e preparar os dados de entrada para o treinamento de modelo. Com essa API, é possível criar o pré-processamento diretamente no gráfico do modelo do TensorFlow, reduzindo o risco de distorção de treinamento/disponibilização. Isso garante que os dados de treinamento e de disponibilização passem por transformações idênticas. Desde o TensorFlow 2.6, essa API é estável. Se você estiver usando uma versão mais antiga do TensorFlow, importe o símbolo experimental.
4. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 1: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada.
Etapa 2: ativar a API Vertex AI
Navegue até a seção "Vertex AI" do Console do Cloud e clique em Ativar API Vertex AI.

Etapa 3: criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":

Ative a API Notebooks, se ela ainda não tiver sido ativada.

Após a ativação, clique em NOTEBOOK GERENCIADO:

Em seguida, selecione NOVO NOTEBOOK.

Dê um nome ao notebook. Em Permissão selecione Conta de serviço.
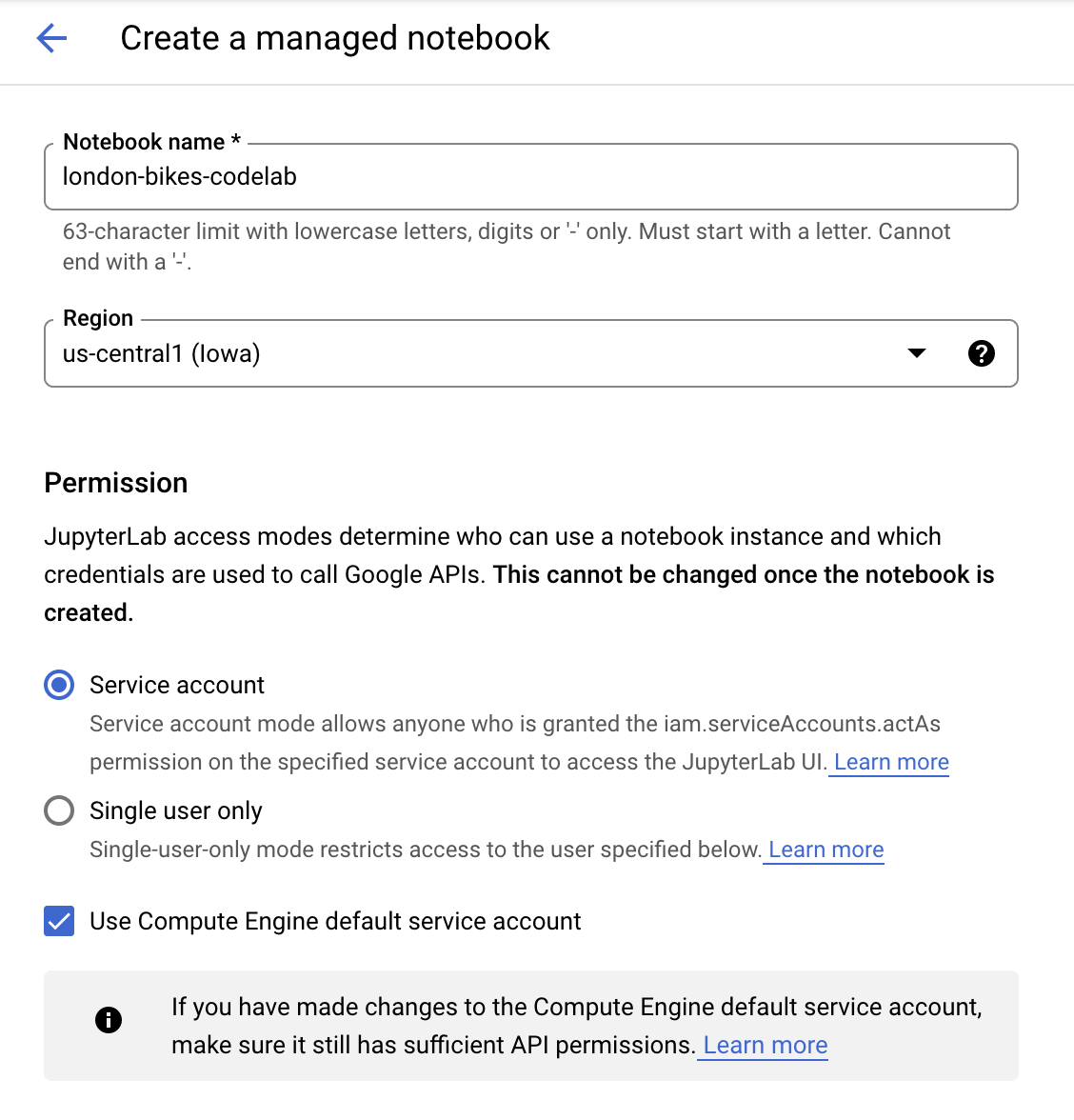
Selecione Configurações avançadas.
Em Segurança, selecione "Ativar terminal", se essa opção ainda não estiver ativada.

Você pode manter as outras configurações avançadas como estão.
Em seguida, clique em Criar.
Quando a instância tiver sido criada, selecione ABRIR O JUPYTERLAB.

5. Analisar o conjunto de dados no BigQuery
Na instância do Vertex AI Workbench, navegue até o lado esquerdo e clique no conector BigQuery em notebooks.

Com o conector do BigQuery, é fácil analisar e consultar conjuntos de dados do BigQuery. Além dos conjuntos de dados no seu projeto, você pode explorar conjuntos de dados em outros projetos clicando no botão Adicionar projeto.

Neste laboratório, você vai usar dados dos conjuntos de dados públicos do BigQuery. Role a tela para baixo até encontrar o conjunto de dados london_bicycles. Você vai notar que esse conjunto de dados tem duas tabelas, cycle_hire e cycle_stations. Vamos conhecer cada um deles.

Primeiro, clique duas vezes na tabela cycle_hire. A tabela será aberta como uma nova guia com o esquema dela e metadados, como o número de linhas e o tamanho.

Se você clicar na guia Visualização, poderá ver uma amostra dos dados. Vamos executar uma consulta simples para ver quais são os trajetos mais usados. Primeiro, clique no botão Consultar tabela.

Em seguida, cole o seguinte no editor SQL e clique em Enviar consulta.
SELECT
start_station_name,
end_station_name,
IF(start_station_name = end_station_name,
TRUE,
FALSE) same_station,
AVG(duration) AS avg_duration,
COUNT(*) AS total_rides
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY
start_station_name,
end_station_name,
same_station
ORDER BY
total_rides DESC
Nos resultados da consulta, você vai ver que os trajetos de bicicleta de e para a estação Hyde Park Corner foram os mais procurados.

Em seguida, clique duas vezes na tabela cycle_stations, que fornece informações sobre cada estação.
Queremos mesclar as tabelas cycle_hire e cycle_stations. A tabela cycle_stations contém a latitude/longitude de cada estação. Você vai usar essas informações para estimar a distância percorrida em cada viagem de bicicleta, calculando a distância entre as estações de início e término.
Para fazer esse cálculo, use as funções geográficas do BigQuery. Especificamente, você vai converter cada string de latitude/longitude em um ST_GEOGPOINT e usar a função ST_DISTANCE para calcular a distância em linha reta em metros entre os dois pontos. Você vai usar esse valor como um proxy para a distância percorrida em cada viagem de bicicleta.
Copie a consulta a seguir no editor de SQL e clique em "Enviar consulta". Há três tabelas na condição JOIN porque precisamos mesclar a tabela de estações duas vezes para receber a latitude/longitude da estação inicial e final do ciclo.
WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING
6. Treinar um modelo de ML em um kernel do TensorFlow
O Vertex AI Workbench tem uma camada de compatibilidade de computação que permite iniciar kernels para TensorFlow, PySpark, R etc., tudo em uma única instância de notebook. Neste laboratório, você vai criar um notebook usando o kernel do TensorFlow.
Criar DataFrame
Depois que a consulta for executada, clique em "Copiar código para DataFrame". Assim, você poderá colar o código Python em um notebook que se conecta ao cliente do BigQuery e extrai esses dados como um DataFrame pandas.

Em seguida, volte à tela de início e crie um notebook do TensorFlow 2.

Na primeira célula do notebook, cole o código copiado do Editor de consultas. Ele vai ficar assim:
# The following two lines are only necessary to run once.
# Comment out otherwise for speed-up.
from google.cloud.bigquery import Client, QueryJobConfig
client = Client()
query = """WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING"""
job = client.query(query)
df = job.to_dataframe()
Para fins deste laboratório, limitamos o conjunto de dados a 700.000 para reduzir o tempo de treinamento. Mas fique à vontade para modificar a consulta e testar o conjunto de dados inteiro.
Em seguida, importe as bibliotecas necessárias.
from datetime import datetime
import pandas as pd
import tensorflow as tf
Execute o código a seguir para criar um dataframe reduzido que contenha apenas as colunas necessárias para a parte de ML deste exercício.
values = df['bike'].values
duration = list(map(lambda a: a['duration'], values))
distance = list(map(lambda a: a['distance'], values))
dates = list(map(lambda a: a['start_date'], values))
data = pd.DataFrame(data={'duration': duration, 'distance': distance, 'start_date':dates})
data = data.dropna()
A coluna "start_date" é um datetime do Python. Em vez de usar esse datetime diretamente no modelo, você vai criar dois novos atributos que indicam o dia da semana e a hora do dia em que o passeio de bicicleta ocorreu.
data['weekday'] = data['start_date'].apply(lambda a: a.weekday())
data['hour'] = data['start_date'].apply(lambda a: a.time().hour)
data = data.drop(columns=['start_date'])
Por fim, converta a coluna de duração de segundos para minutos para facilitar a compreensão.
data['duration'] = data['duration'].apply(lambda x:float(x / 60))
Examine as primeiras linhas do DataFrame formatado. Agora, para cada viagem de bicicleta, você tem dados sobre o dia da semana e a hora do dia em que ela ocorreu, além da distância percorrida. Com essas informações, você vai tentar prever quanto tempo a viagem levou.
data.head()

Antes de criar e treinar o modelo, divida os dados em conjuntos de treinamento e validação.
# Use 80/20 train/eval split
train_size = int(len(data) * .8)
print ("Train size: %d" % train_size)
print ("Evaluation size: %d" % (len(data) - train_size))
# Split data into train and test sets
train_data = data[:train_size]
val_data = data[train_size:]
Criar um modelo do TensorFlow
Você vai criar um modelo do TensorFlow usando a API funcional do Keras. Para pré-processar os dados de entrada, você vai usar a API de camadas de pré-processamento do Keras.
A função utilitária a seguir vai criar um tf.data.Dataset com base no DataFrame do pandas.
def df_to_dataset(dataframe, label, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop(label)
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
Use a função acima para criar dois tf.data.Datasets, um para treinamento e outro para validação. Talvez apareçam alguns avisos, mas você pode ignorá-los com segurança.
train_dataset = df_to_dataset(train_data, 'duration')
validation_dataset = df_to_dataset(val_data, 'duration')
Você vai usar as seguintes camadas de pré-processamento no modelo:
- Camada de normalização: realiza uma normalização por atributos para atributos de entrada.
- Camada IntegerLookup: transforma valores categóricos de números inteiros em índices de números inteiros.
- Camada CategoryEncoding: transforma atributos categóricos de números inteiros em representações densas one-hot, multi-hot ou TF-IDF.
Essas camadas não podem ser treinadas. Em vez disso, defina o estado da camada de pré-processamento expondo-a aos dados de treinamento usando o método adapt().
A função a seguir cria uma camada de normalização que pode ser usada no recurso de distância. Você vai definir o estado antes de ajustar o modelo usando o método adapt() nos dados de treinamento. Isso vai calcular a média e a variância a serem usadas na normalização. Mais tarde, quando você transmitir o conjunto de dados de validação para o modelo, essa mesma média e variância calculadas nos dados de treinamento serão usadas para dimensionar os dados de validação.
def get_normalization_layer(name, dataset):
# Create a Normalization layer for our feature.
normalizer = tf.keras.layers.Normalization(axis=None)
# Prepare a Dataset that only yields our feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
Da mesma forma, a função a seguir cria uma codificação de categoria que você vai usar nos recursos de hora e dia da semana.
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
index = tf.keras.layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Create a Discretization for our integer indices.
encoder = tf.keras.layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply one-hot encoding to our indices. The lambda function captures the
# layer so we can use them, or include them in the functional model later.
return lambda feature: encoder(index(feature))
Em seguida, crie a parte de pré-processamento do modelo. Primeiro, crie uma camada tf.keras.Input para cada um dos recursos.
# Create a Keras input layer for each feature
numeric_col = tf.keras.Input(shape=(1,), name='distance')
hour_col = tf.keras.Input(shape=(1,), name='hour', dtype='int64')
weekday_col = tf.keras.Input(shape=(1,), name='weekday', dtype='int64')
Em seguida, crie as camadas de normalização e codificação de categoria, armazenando-as em uma lista.
all_inputs = []
encoded_features = []
# Pass 'distance' input to normalization layer
normalization_layer = get_normalization_layer('distance', train_dataset)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
# Pass 'hour' input to category encoding layer
encoding_layer = get_category_encoding_layer('hour', train_dataset, dtype='int64')
encoded_hour_col = encoding_layer(hour_col)
all_inputs.append(hour_col)
encoded_features.append(encoded_hour_col)
# Pass 'weekday' input to category encoding layer
encoding_layer = get_category_encoding_layer('weekday', train_dataset, dtype='int64')
encoded_weekday_col = encoding_layer(weekday_col)
all_inputs.append(weekday_col)
encoded_features.append(encoded_weekday_col)
Depois de definir as camadas de pré-processamento, você pode definir o restante do modelo. Você vai concatenar todos os recursos de entrada e transmiti-los a uma camada densa. A camada final é uma única unidade, já que este é um problema de regressão.
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(64, activation="relu")(all_features)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
Por fim, compile o modelo.
model.compile(optimizer = tf.keras.optimizers.Adam(0.001),
loss='mean_squared_logarithmic_error')
Agora que você definiu o modelo, é possível visualizar a arquitetura
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")

Esse modelo é bastante complicado para um conjunto de dados simples. Ele é destinado a fins de demonstração.
Vamos treinar por uma época apenas para confirmar que o código está sendo executado.
model.fit(train_dataset, validation_data = validation_dataset, epochs = 1)
Treinar o modelo com uma GPU
Em seguida, você vai treinar o modelo por mais tempo e usar o switcher de hardware para acelerar o treinamento. O Vertex AI Workbench permite mudar o hardware sem encerrar a instância. Ao adicionar a GPU apenas quando necessário, você pode manter os custos mais baixos.
Para mudar o perfil de hardware, clique no tipo de máquina no canto superior direito e selecione Modificar hardware.

Selecione "Anexar GPUs" e escolha uma GPU NVIDIA T4 Tensor Core.

A configuração do hardware leva cerca de cinco minutos. Quando o processo for concluído, vamos treinar o modelo por mais um tempo. Você vai notar que cada época leva menos tempo agora.
model.fit(train_dataset, validation_data = validation_dataset, epochs = 5)
Parabéns! 🎉
Você aprendeu a usar o Vertex AI Workbench para:
- Analisar dados no BigQuery
- Usar o cliente do BigQuery para carregar dados no Python
- Treinar um modelo do TensorFlow com camadas de pré-processamento do Keras e uma GPU
Para saber mais sobre partes diferentes da Vertex AI, acesse a documentação.
7. Limpeza
Como configuramos o notebook para expirar após 60 minutos de inatividade, não precisamos nos preocupar em desligar a instância. Para encerrar a instância manualmente, clique no botão "Parar" na seção "Vertex AI Workbench" do console. Se quiser excluir o notebook completamente, clique no botão "Excluir".
