
1. 概览
在此实验中,您将学习如何使用 Vertex AI Workbench 进行数据探索和机器学习模型训练。
学习内容
您将了解如何:
- 创建和配置 Vertex AI Workbench 实例
- 使用 Vertex AI Workbench BigQuery 连接器
- 在 Vertex AI Workbench 内核上训练模型
在 Google Cloud 上运行此实验的总费用约为 1 美元。
2. Vertex AI 简介
本实验使用的是 Google Cloud 上提供的最新 AI 产品。Vertex AI 将整个 Google Cloud 的机器学习产品集成到无缝的开发体验中。以前,使用 AutoML 训练的模型和自定义模型是通过不同的服务访问的。现在,该新产品与其他新产品一起将这两种模型合并到一个 API 中。您还可以将现有项目迁移到 Vertex AI。
Vertex AI 包含许多不同的产品,可支持端到端机器学习工作流。本实验将重点介绍 Vertex AI Workbench。
Vertex AI Workbench 通过与数据服务(如 Dataproc、Dataflow、BigQuery 和 Dataplex)和 Vertex AI 的深度集成,帮助用户快速构建基于笔记本的端到端工作流。它使数据科学家能够连接到 GCP 数据服务、分析数据集、尝试不同的建模技术、将训练好的模型部署到生产环境,并通过模型生命周期管理 MLOps。
3. 用例概览
在本实验中,您将探索伦敦自行车租赁数据集。此数据包含自 2011 年以来伦敦公共自行车共享计划的自行车行程信息。您将首先通过 Vertex AI Workbench BigQuery 连接器在 BigQuery 中探索此数据集。然后,您将使用 pandas 将数据加载到 Jupyter 笔记本中,并训练 TensorFlow 模型,以根据骑行时间和骑行距离预测骑行时长。
本实验使用 Keras 预处理层来转换和准备输入数据,以用于模型训练。借助此 API,您可以将预处理直接构建到 TensorFlow 模型图中,从而确保训练数据和部署数据经过相同的转换,进而降低训练/部署偏差的风险。请注意,自 TensorFlow 2.6 起,此 API 已稳定。如果您使用的是旧版 TensorFlow,则需要导入实验性符号。
4. 设置您的环境
您需要一个启用了结算功能的 Google Cloud Platform 项目才能运行此 Codelab。如需创建项目,请按照此处的说明操作。
第 1 步:启用 Compute Engine API
前往 Compute Engine,然后选择启用(如果尚未启用)。
第 2 步:启用 Vertex AI API
前往 Cloud Console 的 Vertex AI 部分,然后点击启用 Vertex AI API。

第 3 步:创建 Vertex AI Workbench 实例
在 Cloud Console 的 Vertex AI 部分中,点击“Workbench”:

启用 Notebooks API(如果尚未启用)。

启用后,点击代管式笔记本:

然后选择新建笔记本。

为笔记本命名,然后在权限下选择服务账号

选择高级设置。
在安全性下,选择“启用终端”(如果尚未启用)。

您可以保留所有其他高级设置。
接下来,点击创建。
创建实例后,选择打开 JUPYTERLAB。

5. 探索 BigQuery 中的数据集
在 Vertex AI Workbench 实例中,前往左侧并点击 BigQuery in Notebooks 连接器。

借助 BigQuery 连接器,您可以轻松探索和查询 BigQuery 数据集。除了项目中的任何数据集之外,您还可以点击添加项目按钮来探索其他项目中的数据集。

在本实验中,您将使用 BigQuery 公共数据集中的数据。向下滚动,直到您找到 london_bicycles 数据集。您会看到,此数据集包含两个表:cycle_hire 和 cycle_stations。我们来逐一了解一下。

首先,双击 cycle_hire 表。您会看到,该表会在新标签页中打开,其中包含表的架构以及行数和大小等元数据。

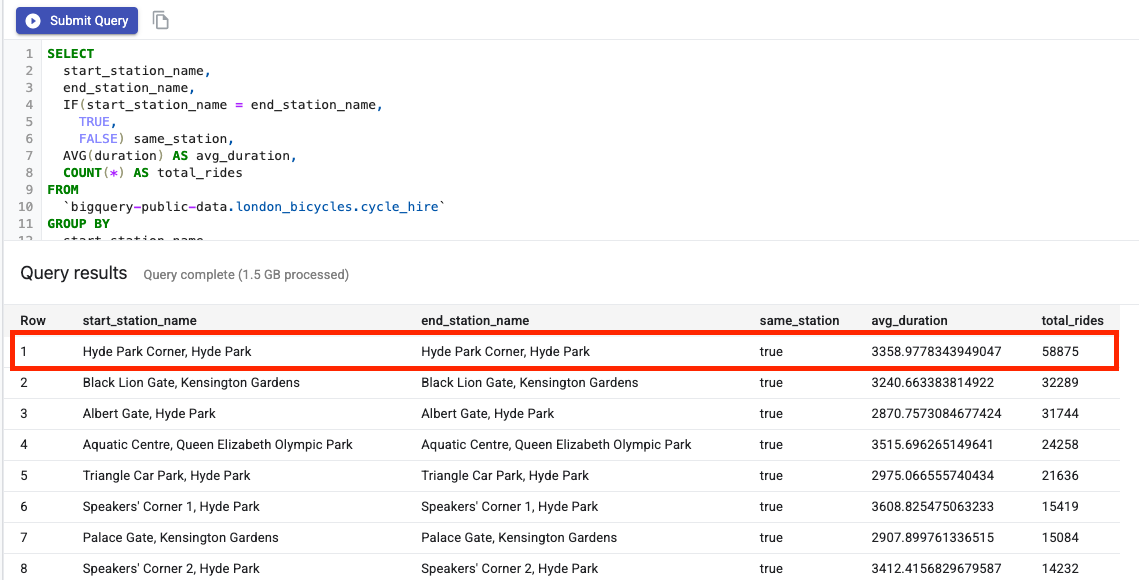
如果您点击预览标签页,则可以查看数据样本。我们来运行一个简单的查询,看看热门行程是什么。首先,点击查询表格按钮。

然后,将以下内容粘贴到 SQL 编辑器中,并点击提交查询。
SELECT
start_station_name,
end_station_name,
IF(start_station_name = end_station_name,
TRUE,
FALSE) same_station,
AVG(duration) AS avg_duration,
COUNT(*) AS total_rides
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY
start_station_name,
end_station_name,
same_station
ORDER BY
total_rides DESC
从查询结果中,您会看到往返海德公园角站的骑行行程最受欢迎。
接下来,双击 cycle_stations 表,其中提供了有关每个站点的相关信息。
我们希望联接 cycle_hire 和 cycle_stations 表。cycle_stations 表包含每个站点的纬度和经度。您将使用此信息来估算每次骑行行程的距离,方法是计算起点站和终点站之间的距离。
若要进行此计算,您将使用 BigQuery 地理位置函数。具体来说,您需要将每个纬度/经度字符串转换为 ST_GEOGPOINT,并使用 ST_DISTANCE 函数计算两点之间的直线距离(以米为单位)。您将使用此值作为每次骑行行程的行驶距离的代理。
将以下查询复制到 SQL 编辑器中,然后点击“提交查询”。请注意,JOIN 条件中有三个表,因为我们需要将 stations 表联接两次,以获取骑行行程的起点站和终点站的纬度/经度。
WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING
6. 在 TensorFlow 内核上训练机器学习模型
Vertex AI Workbench 具有计算兼容性层,可让您从单个笔记本实例启动 TensorFlow、PySpark、R 等内核。在本实验中,您将使用 TensorFlow 内核创建一个笔记本。
创建 DataFrame
查询执行完毕后,点击“Copy code for DataFrame”(复制 DataFrame 的代码)。这样一来,您就可以将 Python 代码粘贴到连接到 BigQuery 客户端的笔记本中,并将此数据提取为 Pandas DataFrame。

接下来,返回启动器并创建一个 TensorFlow 2 笔记本。

在笔记本的第一个单元格中,粘贴从查询编辑器复制的代码。完成后的代码应如下所示:
# The following two lines are only necessary to run once.
# Comment out otherwise for speed-up.
from google.cloud.bigquery import Client, QueryJobConfig
client = Client()
query = """WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING"""
job = client.query(query)
df = job.to_dataframe()
为了达到本次实验的目的,我们将数据集限制为 70 万,以缩短训练时间。不过,您可以随意修改查询,并使用整个数据集进行实验。
接下来,导入必要的库。
from datetime import datetime
import pandas as pd
import tensorflow as tf
运行以下代码以创建一个缩减的 DataFrame,其中仅包含本练习的机器学习部分所需的列。
values = df['bike'].values
duration = list(map(lambda a: a['duration'], values))
distance = list(map(lambda a: a['distance'], values))
dates = list(map(lambda a: a['start_date'], values))
data = pd.DataFrame(data={'duration': duration, 'distance': distance, 'start_date':dates})
data = data.dropna()
start_date 列是 Python datetime。您不会直接在模型中使用此 datetime,而是会创建两个新特征,分别用于指示骑行发生的星期和小时。
data['weekday'] = data['start_date'].apply(lambda a: a.weekday())
data['hour'] = data['start_date'].apply(lambda a: a.time().hour)
data = data.drop(columns=['start_date'])
最后,将时长列从秒转换为分钟,以便更易于理解
data['duration'] = data['duration'].apply(lambda x:float(x / 60))
检查格式化后的 DataFrame 的前几行。现在,对于每次骑行,您都可以获得骑行发生的星期和小时以及骑行距离方面的数据。您将尝试根据这些信息预测行程时长。
data.head()

在创建和训练模型之前,您需要将数据拆分为训练集和验证集。
# Use 80/20 train/eval split
train_size = int(len(data) * .8)
print ("Train size: %d" % train_size)
print ("Evaluation size: %d" % (len(data) - train_size))
# Split data into train and test sets
train_data = data[:train_size]
val_data = data[train_size:]
创建 TensorFlow 模型
您将使用 Keras Functional API 创建 TensorFlow 模型。为了预处理输入数据,您将使用 Keras 预处理层 API。
以下实用函数将根据 Pandas DataFrame 创建 tf.data.Dataset。
def df_to_dataset(dataframe, label, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop(label)
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
使用上述函数创建两个 tf.data.Dataset,一个用于训练,另一个用于验证。您可能会看到一些警告,但可以放心地忽略它们。
train_dataset = df_to_dataset(train_data, 'duration')
validation_dataset = df_to_dataset(val_data, 'duration')
您将在模型中使用以下预处理层:
- 归一化层:对输入特征执行按特征归一化。
- IntegerLookup 层:将整数类别值转换为整数索引。
- CategoryEncoding 层:将整数分类特征转换为独热、多热或 TF-IDF 密集表示形式。
请注意,这些层是不可训练的。而是通过 adapt() 方法将预处理层暴露给训练数据,从而设置预处理层的状态。
以下函数将创建一个可用于距离特征的归一化层。您将使用训练数据上的 adapt() 方法在拟合模型之前设置状态。这将计算用于归一化的平均值和方差。之后,当您将验证数据集传递给模型时,系统会使用基于训练数据计算出的相同平均值和方差来缩放验证数据。
def get_normalization_layer(name, dataset):
# Create a Normalization layer for our feature.
normalizer = tf.keras.layers.Normalization(axis=None)
# Prepare a Dataset that only yields our feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
同样,以下函数会创建一个类别编码,您将使用该编码来处理小时和工作日特征。
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
index = tf.keras.layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Create a Discretization for our integer indices.
encoder = tf.keras.layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply one-hot encoding to our indices. The lambda function captures the
# layer so we can use them, or include them in the functional model later.
return lambda feature: encoder(index(feature))
接下来,创建模型的预处理部分。首先,为每个特征创建一个 tf.keras.Input 层。
# Create a Keras input layer for each feature
numeric_col = tf.keras.Input(shape=(1,), name='distance')
hour_col = tf.keras.Input(shape=(1,), name='hour', dtype='int64')
weekday_col = tf.keras.Input(shape=(1,), name='weekday', dtype='int64')
然后,创建归一化层和类别编码层,并将它们存储在一个列表中。
all_inputs = []
encoded_features = []
# Pass 'distance' input to normalization layer
normalization_layer = get_normalization_layer('distance', train_dataset)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
# Pass 'hour' input to category encoding layer
encoding_layer = get_category_encoding_layer('hour', train_dataset, dtype='int64')
encoded_hour_col = encoding_layer(hour_col)
all_inputs.append(hour_col)
encoded_features.append(encoded_hour_col)
# Pass 'weekday' input to category encoding layer
encoding_layer = get_category_encoding_layer('weekday', train_dataset, dtype='int64')
encoded_weekday_col = encoding_layer(weekday_col)
all_inputs.append(weekday_col)
encoded_features.append(encoded_weekday_col)
定义预处理层后,您可以定义模型的其余部分。您将连接所有输入特征,并将它们传递给密集层。由于这是一个回归问题,因此输出层是单个单元。
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(64, activation="relu")(all_features)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
最后,编译模型。
model.compile(optimizer = tf.keras.optimizers.Adam(0.001),
loss='mean_squared_logarithmic_error')
现在,您已经定义了模型,可以直观呈现架构
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")

请注意,对于此简单的数据集,此模型相当复杂。仅用于演示目的。
我们训练 1 个周期,以确认代码可以运行。
model.fit(train_dataset, validation_data = validation_dataset, epochs = 1)
使用 GPU 训练模型
接下来,您将训练模型更长时间,并使用硬件切换器来加快训练速度。借助 Vertex AI Workbench,您可以在不关闭实例的情况下更改硬件。仅在需要时添加 GPU,有助于降低费用。
如需更改硬件配置文件,请点击右上角的机器类型,然后选择修改硬件

选择“附加 GPU”,然后选择 NVIDIA T4 Tensor Core GPU。

硬件配置大约需要 5 分钟。该过程完成后,我们再将模型训练时间延长一点。您会注意到,现在每个周期的耗时都缩短了。
model.fit(train_dataset, validation_data = validation_dataset, epochs = 5)
🎉 恭喜!🎉
您学习了如何使用 Vertex AI Workbench 执行以下操作:
- 探索 BigQuery 中的数据
- 使用 BigQuery 客户端将数据加载到 Python 中
- 使用 Keras 预处理层和 GPU 训练 TensorFlow 模型
如需详细了解 Vertex AI 的不同部分,请参阅相关文档。
7. 清理
因为我们将笔记本配置为在空闲 60 分钟后超时,所以不必担心关停实例。如果您要手动关停实例,请点击控制台的 Vertex AI Workbench 部分中的“停止”按钮。如果您想完全删除该笔记本,请点击“删除”按钮。
