
1. סקירה כללית
בשיעור ה-Lab הזה תשתמשו בכלי What-if כדי לנתח מודל XGBoost שאומן על נתונים פיננסיים. אחרי ניתוח המודל, תפרסו אותו ב-Vertex AI החדש של Cloud.
מה תלמדו
במאמר הזה נסביר איך:
- אימון מודל XGBoost במערך נתונים ציבורי של משכנתאות בתיקיית Notebook מתארחת
- ניתוח המודל באמצעות הכלי What-if
- פריסת מודל XGBoost ב-Vertex AI
העלות הכוללת להרצת שיעור ה-Lab הזה ב-Google Cloud היא בערך 1$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את מוצרי ה-ML ב-Google Cloud לחוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שאומנו באמצעות AutoML ולמודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את שניהם ב-API אחד, יחד עם מוצרים חדשים אחרים. אפשר גם להעביר פרויקטים קיימים אל Vertex AI. אם יש לך משוב, אפשר לעיין בדף התמיכה.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. בשיעור ה-Lab הזה נתמקד במוצרים שמודגשים בהמשך: Prediction ו-Notebooks.

3. הסבר קצר על XGBoost
XGBoost הוא framework ללמידת מכונה שמשתמש בעצי החלטה ובחיזוק גרדיאנט כדי לבנות מודלים לחיזוי. השיטה מבוססת על שילוב של כמה עצי החלטה על סמך הציון שמשויך לצמתי עלים שונים בעץ.
התרשים הבא הוא הדמיה של מודל פשוט של עץ החלטה שמעריך אם כדאי לשחק במשחק ספורט על סמך תחזית מזג האוויר:

למה אנחנו משתמשים ב-XGBoost למודל הזה? למרות שמחקרים הראו שרשתות נוירונים מסורתיות משיגות את הביצועים הכי טובים בנתונים לא מובנים כמו תמונות וטקסט, עצי החלטה משיגים בדרך כלל ביצועים טובים מאוד בנתונים מובְנים כמו קבוצת הנתונים של המשכנתאות שבה נשתמש ב-Codelab הזה.
4. הגדרת הסביבה
כדי להפעיל את ה-codelab הזה, צריך פרויקט ב-Google Cloud Platform שמופעל בו חיוב. כדי ליצור פרויקט, פועלים לפי ההוראות האלה.
שלב 1: הפעלת Compute Engine API
עוברים אל Compute Engine ובוחרים באפשרות הפעלה אם הוא עדיין לא מופעל. תצטרכו את זה כדי ליצור את מופע המחברת.
שלב 2: הפעלת Vertex AI API
עוברים אל הקטע Vertex במסוף Cloud ולוחצים על Enable Vertex AI API (הפעלת Vertex AI API).

שלב 3: יצירת מופע של Notebooks
בקטע Vertex ב-Cloud Console, לוחצים על Notebooks:

משם, בוחרים באפשרות New Instance (מופע חדש). לאחר מכן בוחרים את סוג האינסטנס TensorFlow Enterprise 2.3 without GPUs:

משתמשים באפשרויות ברירת המחדל ולוחצים על יצירה. אחרי שהמופע נוצר, בוחרים באפשרות Open JupyterLab.
שלב 4: מתקינים את XGBoost
אחרי שפותחים את מופע JupyterLab, צריך להוסיף את חבילת XGBoost.
כדי לעשות את זה, בוחרים באפשרות Terminal (טרמינל) ממרכז האפליקציות:

לאחר מכן מריצים את הפקודה הבאה כדי להתקין את הגרסה העדכנית ביותר של XGBoost שנתמכת על ידי Vertex AI:
pip3 install xgboost==1.2
אחרי שהפעולה הזו מסתיימת, פותחים מופע של Python 3 Notebook ממרכז האפליקציות. הכול מוכן להתחלת העבודה במחברת!
שלב 5: ייבוא חבילות Python
בתא הראשון של ה-Notebook, מוסיפים את הייבוא הבא ומריצים את התא. כדי להפעיל אותו, לוחצים על לחצן החץ ימינה בתפריט העליון או על Command-Enter:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
5. הורדה ועיבוד של נתונים
נשתמש במערך נתונים של משכנתאות מ-ffiec.gov כדי לאמן מודל XGBoost. ביצענו עיבוד מקדים של מערך הנתונים המקורי ויצרנו גרסה קטנה יותר שתוכלו להשתמש בה כדי לאמן את המודל. המודל יחזה אם בקשה מסוימת למשכנתא תאושר או לא.
שלב 1: הורדת מערך הנתונים שעבר עיבוד מראש
הכנו גרסה של מערך הנתונים שזמינה לכם ב-Google Cloud Storage. כדי להוריד אותו, מריצים את הפקודה הבאה של gsutil ב-Jupyter Notebook:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
שלב 2: קריאת מערך הנתונים באמצעות Pandas
לפני שיוצרים Pandas DataFrame, יוצרים dict של סוג הנתונים של כל עמוד כדי שמערך הנתונים ייקרא בצורה נכונה על ידי Pandas:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
בשלב הבא ניצור DataFrame, ונעביר אליו את סוגי הנתונים שציינו למעלה. חשוב לערבב את הנתונים למקרה שקבוצת הנתונים המקורית מסודרת בצורה מסוימת. לשם כך אנחנו משתמשים בכלי sklearn שנקרא shuffle, שייבאנו בתא הראשון:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() מאפשרת לנו לראות תצוגה מקדימה של חמש השורות הראשונות של מערך הנתונים ב-Pandas. אחרי שמריצים את התא שלמעלה, אמור להופיע משהו כזה:

אלה התכונות שבהן נשתמש כדי לאמן את המודל שלנו. אם גוללים עד הסוף, רואים את העמודה האחרונה approved, שבה מוצג מה שאנחנו מנסים לחזות. הערך 1 מציין שאפליקציה מסוימת אושרה, והערך 0 מציין שהיא נדחתה.
כדי לראות את הפיזור של הערכים שאושרו או נדחו במערך הנתונים וליצור מערך numpy של התוויות, מריצים את הפקודה הבאה:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
כ-66% ממערך הנתונים מכילים אפליקציות שאושרו.
שלב 3: יצירת עמודה פיקטיבית לערכים קטגוריים
מערך הנתונים הזה מכיל שילוב של ערכים קטגוריים ומספריים, אבל XGBoost דורש שכל התכונות יהיו מספריות. במקום לייצג ערכים קטגוריים באמצעות קידוד one-hot, נשתמש בפונקציה get_dummies של Pandas כדי ליצור את מודל XGBoost.
הפונקציה get_dummies מקבלת עמודה עם כמה ערכים אפשריים וממירה אותה לסדרה של עמודות, שכל אחת מהן מכילה רק את הערכים 0 ו-1. לדוגמה, אם יש לנו עמודה בשם 'צבע' עם הערכים האפשריים 'כחול' ו'אדום', הפונקציה get_dummies תמיר את העמודה הזו ל-2 עמודות בשם 'צבע_כחול' ו'צבע_אדום' עם כל הערכים הבוליאניים 0 ו-1.
כדי ליצור עמודות פיקטיביות לתכונות הקטגוריות, מריצים את הקוד הבא:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
כשמציגים תצוגה מקדימה של הנתונים הפעם, רואים תכונות בודדות (כמו purchaser_type שמוצגת בתמונה שלמטה) שמפוצלות לכמה עמודות:

שלב 4: פיצול הנתונים לקבוצות אימון ובדיקה
מושג חשוב בלמידה חישובית הוא פיצול לנתוני אימון ולנתוני בדיקה. אנחנו ניקח את רוב הנתונים ונשתמש בהם כדי לאמן את המודל, ואת הנתונים הנותרים נשמור בצד כדי לבדוק את המודל על נתונים שהוא לא ראה מעולם.
מוסיפים את הקוד הבא למחברת, שמשתמש בפונקציה train_test_split של Scikit-learn כדי לפצל את הנתונים:
x,y = data.values,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
עכשיו אפשר ליצור ולאמן את המודל.
6. יצירה, אימון והערכה של מודל XGBoost
שלב 1: הגדרת מודל XGBoost ואימון שלו
קל ליצור מודל ב-XGBoost. נשתמש במחלקה XGBClassifier כדי ליצור את המודל, ורק צריך להעביר את הפרמטר objective המתאים למשימת הסיווג הספציפית שלנו. במקרה הזה, אנחנו משתמשים ב-reg:logistic כי יש לנו בעיית סיווג בינארית ואנחנו רוצים שהמודל יפיק ערך יחיד בטווח (0,1): 0 אם הבקשה לא אושרה ו-1 אם היא אושרה.
הקוד הבא ייצור מודל XGBoost:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
אפשר לאמן את המודל באמצעות שורת קוד אחת, להפעיל את השיטה fit() ולהעביר לה את נתוני האימון והתוויות.
model.fit(x_train, y_train)
שלב 2: הערכת רמת הדיוק של המודל
עכשיו אפשר להשתמש במודל המאומן כדי ליצור תחזיות לגבי נתוני הבדיקה באמצעות הפונקציה predict().
לאחר מכן נשתמש בפונקציה accuracy_score() של Scikit-learn כדי לחשב את רמת הדיוק של המודל על סמך הביצועים שלו בנתוני הבדיקה. נעביר לו את ערכי אמת הקרקע יחד עם הערכים החזויים של המודל לכל דוגמה בקבוצת הנתונים לבדיקה שלנו:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
מידת הדיוק צריכה להיות בסביבות 87%, אבל היא תשתנה מעט כי תמיד יש אלמנט של אקראיות בלמידת מכונה.
שלב 3: שמירת המודל
כדי לפרוס את המודל, מריצים את הקוד הבא כדי לשמור אותו בקובץ מקומי:
model.save_model('model.bst')
7. שימוש בכלי What-if כדי לפרש את המודל
שלב 1: יצירת ויזואליזציה של הכלי 'מה אם'
כדי לקשר את כלי התרחישים למודל המקומי, צריך להעביר לו קבוצת משנה של דוגמאות הבדיקה יחד עם ערכי האמת הבסיסיים של הדוגמאות האלה. ניצור מערך Numpy של 500 דוגמאות מהבדיקה שלנו, יחד עם תוויות האמת שלהן:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples],y_test[:num_wit_examples].reshape(-1,1)))
כדי ליצור מופע של הכלי What-if, פשוט יוצרים אובייקט WitConfigBuilder ומעבירים לו את המודל שרוצים לנתח.
מכיוון שכלי ה-What-If מצפה לקבל רשימה של ציונים לכל מחלקה במודל שלנו (במקרה הזה 2), נשתמש בשיטה predict_proba של XGBoost עם כלי ה-What-If:
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_custom_predict_fn(model.predict_proba)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
לתשומת ליבכם: תהליך הטעינה של התרשים להמחשה יימשך דקה. אחרי הטעינה, אמורים להופיע הנתונים הבאים:

ציר ה-Y מציג את החיזוי של המודל, כאשר 1 הוא חיזוי עם רמת סמך גבוהה של approved, ו-0 הוא חיזוי עם רמת סמך גבוהה של denied. ציר ה-x מייצג את הפיזור של כל הנקודות על הגרף.
שלב 2: בדיקת נקודות נתונים ספציפיות
תצוגת ברירת המחדל בכלי 'מה אם' היא הכרטיסייה עורך נקודות הנתונים. כאן אפשר ללחוץ על כל נקודה על הגרף כדי לראות את המאפיינים שלה, לשנות את ערכי המאפיינים ולראות איך השינוי משפיע על התחזית של המודל לגבי נקודה על הגרף ספציפית.
בדוגמה שלמטה בחרנו נקודה על הגרף שקרובה לסף של 0 .5. בקשת המשכנתא שמשויכת לנקודת הנתונים הספציפית הזו הגיעה מ-CFPB. שינינו את התכונה הזו ל-0 וגם שינינו את הערך של agency_code_Department of Housing and Urban Development (HUD) ל-1 כדי לראות מה יקרה לתחזית של המודל אם ההלוואה הזו תגיע במקום זאת מ-HUD:

כפי שאפשר לראות בקטע הימני התחתון של הכלי 'מה אם', שינוי התכונה הזו הפחית באופן משמעותי את approved התחזית של המודל ב-32%. יכול להיות שהנתון הזה מצביע על כך שהסוכנות שממנה הגיע ההלוואה משפיעה מאוד על הפלט של המודל, אבל נצטרך לבצע ניתוח נוסף כדי להיות בטוחים.
בחלק התחתון מימין של ממשק המשתמש אפשר לראות גם את ערך האמת הבסיסי של כל נקודה על הגרף ולהשוות אותו לתחזית של המודל:

שלב 3: ניתוח קונטרה-פקטואלי
לאחר מכן, לוחצים על נקודת נתונים כלשהי ומזיזים את פס ההזזה הצגת נקודת הנתונים הקרובה ביותר של תרחיש נגדי שמאלה:

אם תבחרו באפשרות הזו, יוצג לכם נקודה על הגרף עם ערכי התכונות הכי דומים לנקודה על הגרף המקורית שבחרתם, אבל עם התחזית ההפוכה. אחר כך אפשר לגלול בין ערכי המאפיינים כדי לראות איפה יש הבדלים בין שתי נקודות הנתונים (ההבדלים מודגשים בירוק ובאותיות מודגשות).
שלב 4: עיון בתרשימי תלות חלקית
כדי לראות איך כל תכונה משפיעה על התחזיות של המודל באופן כללי, מסמנים את התיבה Partial dependence plots (תרשימי תלות חלקית) ומוודאים שהאפשרות Global partial dependence plots (תרשימי תלות חלקית גלובליים) מסומנת:
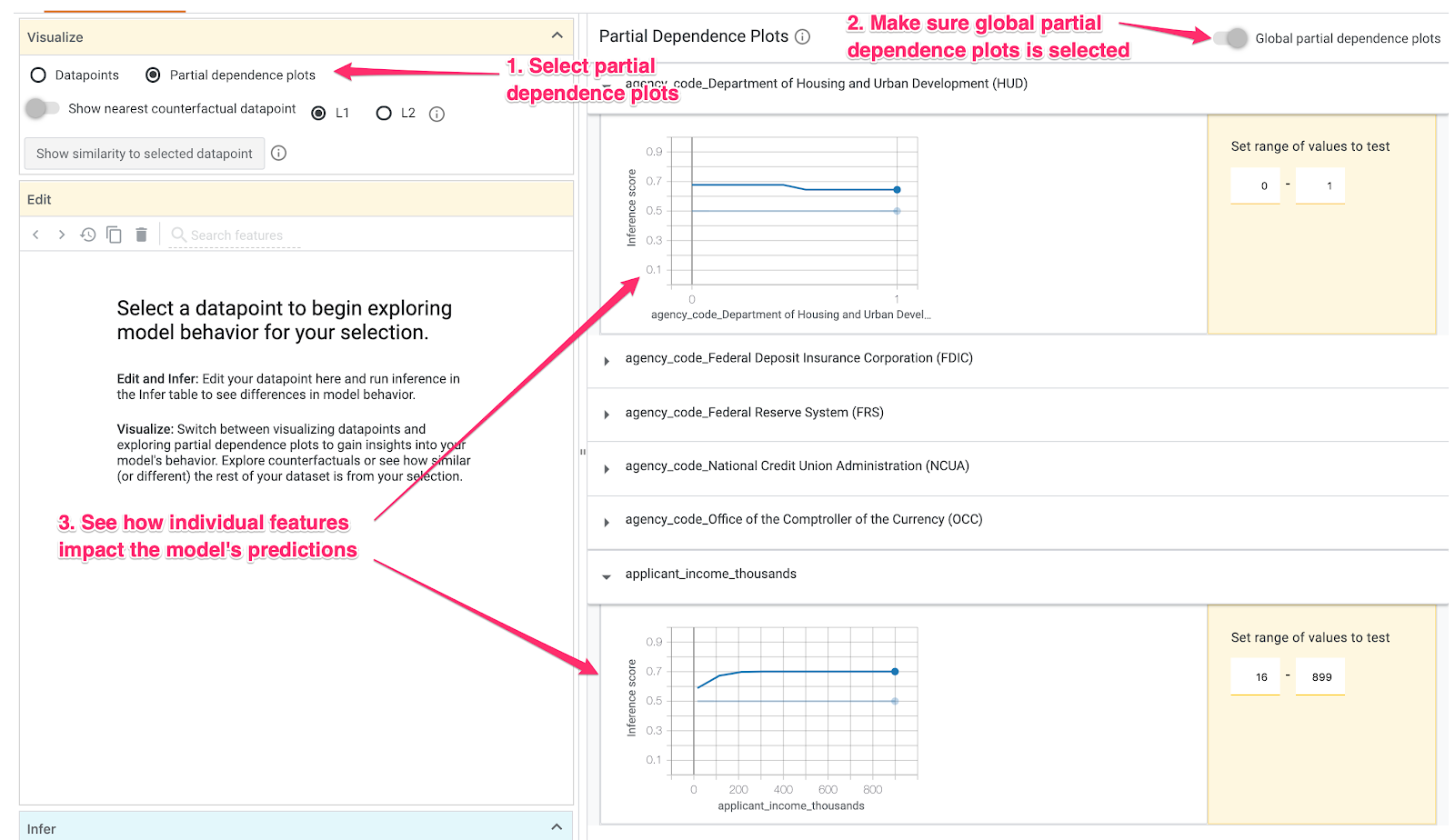
כאן אפשר לראות שהסיכוי לדחיית הלוואות שמקורן ב-HUD גבוה מעט יותר. הצורה של הגרף היא כזו כי קוד הסוכנות הוא תכונה בוליאנית, ולכן הערכים יכולים להיות בדיוק 0 או 1.
applicant_income_thousands היא תכונה מספרית, ובגרף התלות החלקית אפשר לראות שהכנסה גבוהה יותר מגדילה מעט את הסבירות לאישור הבקשה, אבל רק עד לסכום של כ-200,000$. אחרי 200,000$, התכונה הזו לא משפיעה על התחזית של המודל.
שלב 5: בדיקת הביצועים הכוללים וההוגנות
לאחר מכן עוברים לכרטיסייה ביצועים והוגנות. הדוח הזה מציג נתונים סטטיסטיים של הביצועים הכוללים של תוצאות המודל במערך הנתונים שסופק, כולל מטריצות בלבול, עקומות PR ועקומות ROC.
בוחרים באפשרות mortgage_status כמאפיין של נתוני האמת כדי לראות מטריצת בלבול:

מטריצת הבלבול הזו מציגה את החיזויים הנכונים והלא נכונים של המודל שלנו כאחוז מסך הכול. אם מחברים את הריבועים Actual Yes / Predicted Yes ו-Actual No / Predicted No, התוצאה צריכה להיות זהה לדיוק של המודל (במקרה הזה, בערך 87%, אבל יכול להיות שהתוצאה תהיה שונה כי יש אלמנט של אקראיות באימון מודלים של ML).
אפשר גם להתנסות עם סרגל ההזזה של ערך הסף, להעלות ולהוריד את ציון הסיווג החיובי שהמודל צריך להחזיר לפני שהוא מחליט לחזות approved לגבי ההלוואה, ולראות איך זה משנה את הדיוק, את התוצאות החיוביות הכוזבות ואת התוצאות השליליות הכוזבות. במקרה הזה, רמת הדיוק הכי גבוהה היא סביב סף של 0.55.
בשלב הבא, בתפריט הנפתח Slice by (פילוח לפי) בצד ימין, בוחרים באפשרות loan_purpose_Home_purchase:

עכשיו תוכלו לראות את הביצועים בשתי קבוצות המשנה של הנתונים: הפלח '0' מוצג כשההלוואה לא מיועדת לרכישת בית, והפלח '1' מוצג כשההלוואה מיועדת לרכישת בית. כדאי לבדוק את הדיוק, את שיעור התוצאות החיוביות השגויות ואת שיעור התוצאות השליליות השגויות בין שני הפלחים כדי לזהות הבדלים בביצועים.
אם מרחיבים את השורות כדי לראות את מטריצות הטעות, אפשר לראות שהמודל חוזה 'אישור' לכ-70% מהבקשות להלוואות לרכישת בית, ורק ל-46% מההלוואות שלא מיועדות לרכישת בית (האחוזים המדויקים משתנים בהתאם למודל):

אם בוחרים באפשרות Demographic parity (שוויון דמוגרפי) מתוך לחצני הבחירה שמימין, שני ערכי הסף יותאמו כך שהמודל יחזה approved עבור אחוז דומה של מועמדים בשני הפלחים. מה קורה לרמת הדיוק, לתוצאות חיוביות מוטעות ולתוצאות שליליות מוטעות בכל פלח?
שלב 6: בדיקת התפלגות התכונות
לבסוף, עוברים לכרטיסייה תכונות בכלי לניתוח תרחישים. כאן מוצגת התפלגות הערכים של כל תכונה במערך הנתונים:

אתם יכולים להשתמש בכרטיסייה הזו כדי לוודא שמערך הנתונים מאוזן. לדוגמה, נראה שרק מעט הלוואות במערך הנתונים הגיעו מ-Farm Service Agency. כדי לשפר את הדיוק של המודל, יכול להיות שנשקול להוסיף עוד הלוואות מהסוכנות הזו אם הנתונים יהיו זמינים.
במאמר הזה תיארנו רק כמה רעיונות לשימוש בכלי What-if. אתם מוזמנים להמשיך להתנסות בכלי, יש עוד הרבה תחומים שאפשר לחקור!
8. פריסת המודל ב-Vertex AI
המודל שלנו פועל באופן מקומי, אבל יהיה נחמד אם נוכל ליצור חיזויים על סמך המודל מכל מקום (לא רק מהמחברת הזו!). בשלב הזה נבצע פריסה לענן.
שלב 1: יצירת קטגוריה של Cloud Storage עבור המודל
קודם נגדיר כמה משתני סביבה שנשתמש בהם בהמשך ה-codelab. ממלאים את הערכים שלמטה בשם של פרויקט בענן של Google Cloud, בשם של קטגוריה של Cloud Storage שרוצים ליצור (חייב להיות ייחודי באופן גלובלי) ובשם הגרסה של הגרסה הראשונה של המודל:
# Update the variables below to your own Google Cloud project ID and GCS bucket name. You can leave the model name we've specified below:
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
MODEL_NAME = 'xgb_mortgage'
עכשיו אפשר ליצור קטגוריית אחסון לאחסון קובץ המודל של XGBoost. כשנפרוס את המודל, נציין את הקובץ הזה ב-Vertex AI.
מריצים את הפקודה gsutil מתוך ה-notebook כדי ליצור קטגוריית אחסון אזורית:
!gsutil mb -l us-central1 $MODEL_BUCKET
שלב 2: מעתיקים את קובץ המודל ל-Cloud Storage
בשלב הבא, נעתיק את קובץ המודל השמור של XGBoost ל-Cloud Storage. מריצים את פקודת gsutil הבאה:
!gsutil cp ./model.bst $MODEL_BUCKET
כדי לוודא שהקובץ הועתק, נכנסים לדפדפן האחסון במסוף Cloud:

שלב 3: יצירת המודל ופריסה לנקודת קצה
אנחנו כמעט מוכנים לפרוס את המודל בענן! ב-Vertex AI, מודל יכול להכיל כמה נקודות קצה. קודם ניצור מודל, אחר כך ניצור נקודת קצה בתוך המודל הזה ונפרוס אותו.
קודם כל, משתמשים ב-gcloud CLI כדי ליצור את המודל:
!gcloud beta ai models upload \
--display-name=$MODEL_NAME \
--artifact-uri=$MODEL_BUCKET \
--container-image-uri=us-docker.pkg.dev/cloud-aiplatform/prediction/xgboost-cpu.1-2:latest \
--region=us-central1
הפרמטר artifact-uri יצביע על מיקום האחסון שבו שמרתם את מודל XGBoost. הפרמטר container-image-uri מציין ל-Vertex AI באיזה קונטיינר מוכן מראש להשתמש לצורך מילוי בקשות. אחרי שהפקודה הזו מסתיימת, עוברים אל הקטע models במסוף Vertex כדי לקבל את המזהה של המודל החדש. אפשר למצוא אותו כאן:

מעתיקים את המזהה ושומרים אותו במשתנה:
MODEL_ID = "your_model_id"
עכשיו הגיע הזמן ליצור נקודת קצה במודל הזה. אפשר לעשות את זה באמצעות פקודת gcloud הבאה:
!gcloud beta ai endpoints create \
--display-name=xgb_mortgage_v1 \
--region=us-central1
בסיום התהליך, המיקום של נקודת הקצה יתועד בפלט של המחברת. מחפשים את השורה שבה מצוין שנקודת הקצה נוצרה עם נתיב שנראה כך: projects/project_ID/locations/us-central1/endpoints/endpoint_ID. ואז מחליפים את הערכים שבהמשך במזהים של נקודת הקצה שיצרתם למעלה:
ENDPOINT_ID = "your_endpoint_id"
כדי לפרוס את נקודת הקצה, מריצים את פקודת gcloud הבאה:
!gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=us-central1 \
--model=$MODEL_ID \
--display-name=xgb_mortgage_v1 \
--machine-type=n1-standard-2 \
--traffic-split=0=100
הפריסה של נקודת הקצה תימשך כ-5 עד 10 דקות. בזמן הפריסה של נקודת הקצה, עוברים אל הקטע models במסוף. לוחצים על המודל ורואים שהנקודה הסופית נפרסת:

כשהפריסה תושלם בהצלחה, יופיע סימן וי ירוק במקום סמל הטעינה.
שלב 4: בדיקת המודל שנפרס
כדי לוודא שהמודל שפרסתם פועל, אפשר לבדוק אותו באמצעות gcloud כדי ליצור חיזוי. קודם כול, שומרים קובץ JSON עם דוגמה מתוך קבוצת נתונים לבדיקה שלנו:
%%writefile predictions.json
{
"instances": [
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
]
}
מריצים את פקודת gcloud הבאה כדי לבדוק את המודל:
!gcloud beta ai endpoints predict $ENDPOINT_ID \
--json-request=predictions.json \
--region=us-central1
החיזוי של המודל אמור להופיע בפלט. הדוגמה הזו אושרה, לכן אמור להופיע ערך שקרוב ל-1.
9. הסרת המשאבים
אם רוצים להמשיך להשתמש ב-notebook הזה, מומלץ להשבית אותו כשלא משתמשים בו. בממשק המשתמש של Notebooks במסוף Cloud, בוחרים את מחברת ה-Notebook ואז בוחרים באפשרות Stop:

אם רוצים למחוק את כל המשאבים שיצרתם בשיעור Lab הזה, פשוט מוחקים את מופע ה-Notebook במקום להפסיק אותו.
כדי למחוק את נקודת הקצה שפרסתם, עוברים לקטע Endpoints (נקודות קצה) במסוף Vertex ולוחצים על סמל המחיקה:

כדי למחוק את קטגוריית האחסון, בתפריט הניווט ב-Cloud Console, עוברים אל Storage, בוחרים את הקטגוריה ולוחצים על Delete:
