لمحة عن هذا الدرس التطبيقي حول الترميز
1. نظرة عامة
في هذا التمرين، ستستخدم Vertex AI لتدريب نموذج TensorFlow وعرضه باستخدام رمز في حاوية مخصّصة.
وبينما نستخدم TensorFlow لرمز النموذج هنا، يمكنك استبداله بسهولة بإطار عمل آخر.
المعلومات التي تطّلع عليها
وستتعرّف على كيفية:
- إنشاء رمز تدريب النموذج ووضعه في حاويات في Vertex Workbench
- إرسال مهمة تدريب النموذج المخصّص إلى Vertex AI
- نشر النموذج المدرَّب في نقطة نهاية واستخدام نقطة النهاية هذه للحصول على تنبؤات
تبلغ التكلفة الإجمالية لتشغيل هذا التمرين على Google Cloud حوالي $1.
2. مقدمة عن Vertex AI
يستخدم هذا البرنامج أحدث منتجات الذكاء الاصطناعي المتوفّرة على Google Cloud. تدمج Vertex AI عروض تعلُّم الآلة في Google Cloud في تجربة تطوير سلسة. في السابق، كان بالإمكان الوصول إلى النماذج المدربة باستخدام AutoML والنماذج المخصّصة من خلال خدمات منفصلة. ويدمج العرض الجديد كلاً من واجهة برمجة تطبيقات واحدة مع منتجات جديدة أخرى. يمكنك أيضًا نقل المشاريع الحالية إلى Vertex AI. إذا كان لديك أي ملاحظات، يُرجى الاطّلاع على صفحة الدعم.
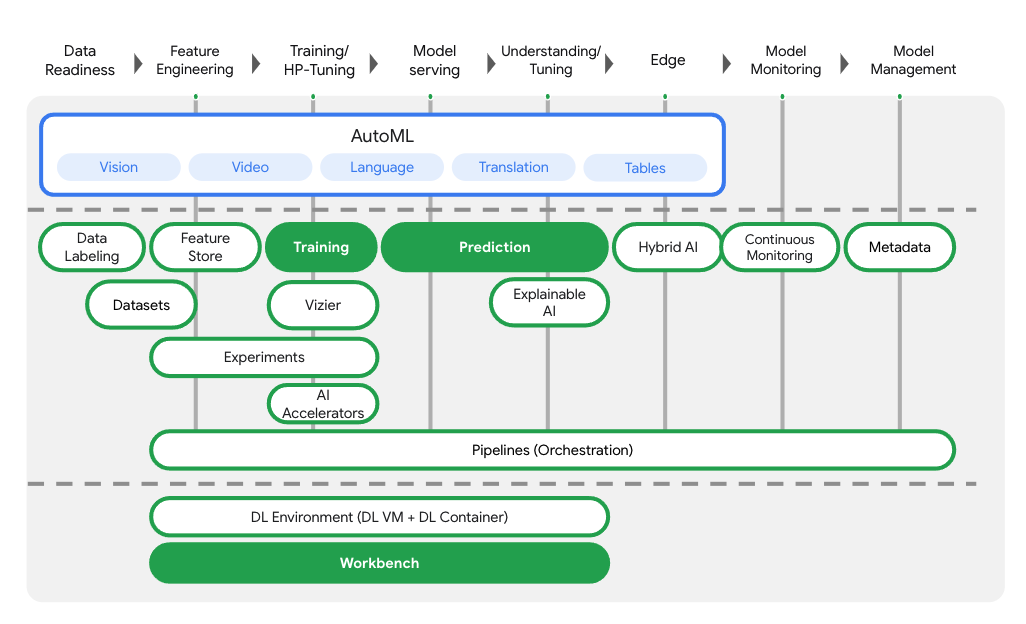
تتضمّن Vertex AI العديد من المنتجات المختلفة لدعم سير عمل تعلُّم الآلة من البداية إلى النهاية. سيركّز هذا الدرس التطبيقي على المنتجات المميّزة أدناه: "التعليم" و"التوقّعات" و"Workbench".
3. إعداد البيئة
ستحتاج إلى مشروع Google Cloud Platform مع تفعيل الفوترة لتشغيل هذا الدرس التطبيقي حول الترميز. لإنشاء مشروع، يُرجى اتّباع التعليمات هنا.
الخطوة 1: تفعيل واجهة برمجة تطبيقات Compute Engine
انتقِل إلى Compute Engine واختَر تفعيل إذا لم يسبق لك تفعيله. ستحتاج إلى هذا لإنشاء مثيل دفتر الملاحظات.
الخطوة 2: تفعيل Vertex AI API
انتقِل إلى قسم Vertex AI في Cloud Console وانقر على تفعيل Vertex AI API.
الخطوة 3: تفعيل Container Registry API
انتقِل إلى Container Registry واختَر تفعيل إذا لم يسبق لك إجراء ذلك. ستستخدم هذا لإنشاء حاوية لمهمّة التدريب المخصّصة.
الخطوة 4: إنشاء مثيل Vertex AI Workbench
من قسم Vertex AI في Cloud Console، انقر على Workbench:
من هناك، ضمن دفاتر الملاحظات التي يديرها المستخدم، انقر على دفتر ملاحظات جديد:

بعد ذلك، اختَر أحدث إصدار من نوع مثيل TensorFlow Enterprise (مع LTS) بدون وحدات معالجة الرسومات:
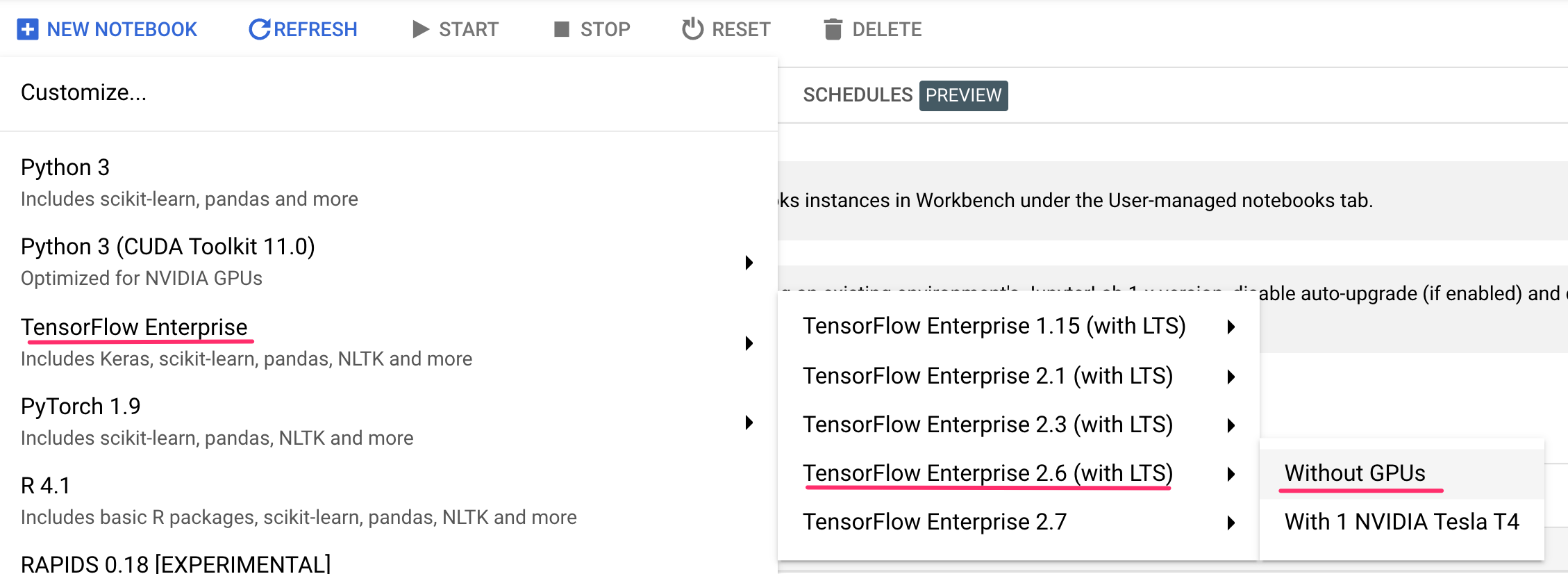
استخدِم الخيارات التلقائية، ثم انقر على إنشاء.
يستند النموذج الذي سنتدربه وعرضه في هذا التمرين إلى هذا البرنامج التعليمي الوارد في مستندات TensorFlow. يستخدم البرنامج التعليمي مجموعة بيانات Auto MPG من Kaggle لتوقّع كفاءة استهلاك الوقود في مركبة.
4. رمز التدريب على الحاوية
سنرسِل هذه المهمة التدريبية إلى Vertex من خلال وضع رمز التدريب في حاوية Docker وإرسال هذه الحاوية إلى Google Container Registry. وباستخدام هذا النهج، يمكننا تدريب نموذج تم إنشاؤه باستخدام أي إطار عمل.
للبدء، من قائمة "مشغّل التطبيقات"، افتح نافذة المحطة الطرفية في مثيل ورقة الملاحظات:
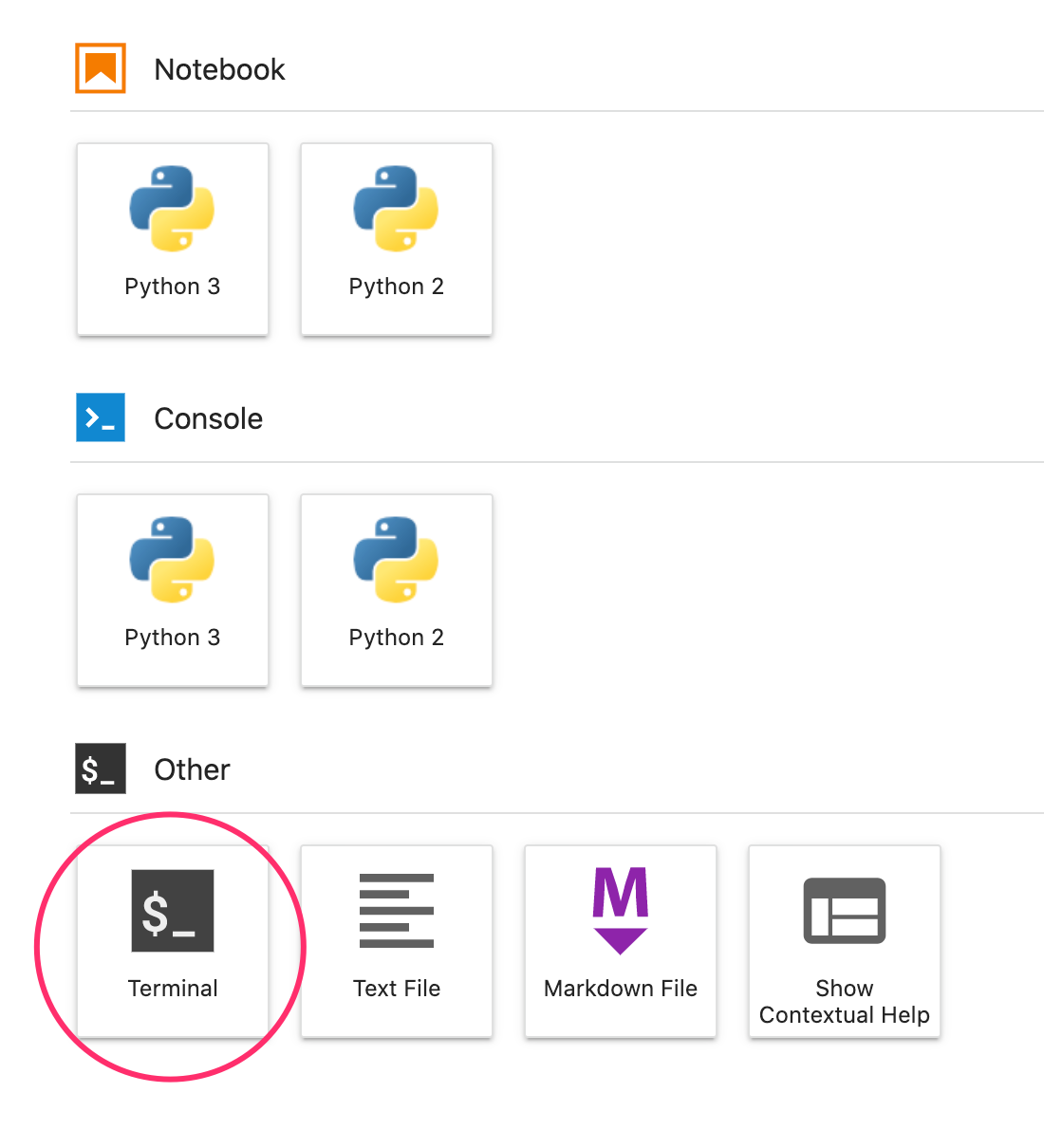
أنشئ دليلاً جديدًا باسم mpg وأضِفه إليه:
mkdir mpg
cd mpg
الخطوة 1: إنشاء ملف شامل
خطوتنا الأولى في احتواء التعليمة البرمجية هي إنشاء ملف Dockerfile. سنضمّن في Dockerfile جميع الأوامر اللازمة لتشغيل صورتنا. سيقوم بتثبيت جميع المكتبات التي نستخدمها وإعداد نقطة الدخول لشفرة التدريب. من Terminal، أنشئ ملف Dockerfile فارغًا:
touch Dockerfile
افتح Dockerfile وانسخ ما يلي إليه:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-6
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
يستخدم هذا الملف الشامل صورة Deep Learning Container TensorFlow Enterprise 2.3 Docker. تأتي حاويات التعلّم المتعمق على Google Cloud مع العديد من أُطر العمل الشائعة لتعلُّم الآلة وعلوم البيانات والمثبَّتة مسبقًا. تشمل حزمة البيانات التي نستخدمها TF Enterprise 2.3 وPandas وScikit-learn وغيرها. بعد تنزيل تلك الصورة، يُعِدّ هذا الملف الشامل نقطة الدخول لرمز التدريب الخاص بنا. لم ننشئ هذه الملفات بعد، وفي الخطوة التالية، سنضيف الرمز للتدريب وتصدير نموذجنا.
الخطوة 2: إنشاء حزمة على Cloud Storage
في المهمة التدريبية، سنصدِّر نموذج TensorFlow المدرَّب إلى حزمة Cloud Storage. سيستخدم Vertex هذا الإذن لقراءة أصول النموذج التي تم تصديرها ونشر النموذج. من Terminal، نفِّذ ما يلي لتحديد متغيّر env لمشروعك، مع الحرص على استبدال your-cloud-project بمعرّف مشروعك:
PROJECT_ID='your-cloud-project'
بعد ذلك، نفِّذ ما يلي في Terminal لإنشاء حزمة جديدة في مشروعك. إنّ علامة -l (الموقع الجغرافي) مهمّة لأنّها يجب أن تكون في المنطقة نفسها التي تنشر فيها نقطة نهاية النموذج لاحقًا في البرنامج التعليمي:
BUCKET_NAME="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET_NAME
الخطوة 3: إضافة رمز تدريب النموذج
من الوحدة الطرفية، قم بتشغيل ما يلي لإنشاء دليل لرمز التدريب الخاص بنا وملف Python حيث نضيف الرمز:
mkdir trainer
touch trainer/train.py
يُفترض أن يكون لديك الآن ما يلي في دليل mpg/ :
+ Dockerfile
+ trainer/
+ train.py
بعد ذلك، افتح ملف train.py الذي أنشأته للتو وانسخ الرمز البرمجي أدناه (تم اقتباس هذا الرمز من الدليل التعليمي في مستندات TensorFlow).
في بداية الملف، عدِّل المتغيّر BUCKET باسم "حزمة التخزين" التي أنشأتها في الخطوة السابقة:
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
"""Import it using pandas"""
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset.tail()
# TODO: replace `your-gcs-bucket` with the name of the Storage bucket you created earlier
BUCKET = 'gs://your-gcs-bucket'
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"Origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
الخطوة 4: إنشاء الحاوية واختبارها محليًا
من الوحدة الطرفية، حدد متغيرًا باستخدام معرف الموارد المنتظم (URI) لصورة الحاوية في Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/mpg:v1"
بعد ذلك، أنشِئ الحاوية عن طريق تنفيذ ما يلي من جذر الدليل mpg:
docker build ./ -t $IMAGE_URI
شغِّل الحاوية داخل مثيل ورقة الملاحظات للتأكد من أنها تعمل بشكل صحيح:
docker run $IMAGE_URI
من المفترَض أن ينهي النموذج التدريب خلال دقيقة أو دقيقتَين، مع دقة تحقُّق تبلغ %72 تقريبًا (قد تختلف الدقة الدقيقة). عند الانتهاء من تشغيل الحاوية محليًا، ادفعها إلى Google Container Registry:
docker push $IMAGE_URI
بعد إرسال حاويتنا إلى Container Registry، أصبحنا جاهزون الآن لبدء مهمة تدريب النموذج المخصّص.
5. تنفيذ وظيفة تدريب على Vertex AI
يمنحك Vertex AI خيارَين لنماذج التدريب:
- AutoML: يمكنك تدريب نماذج عالية الجودة بأقل جهد وخبرة في تعلُّم الآلة.
- التدريب المخصّص: يمكنك تشغيل تطبيقات التدريب المخصّص في السحابة الإلكترونية باستخدام إحدى حاويات Google Cloud المُنشأة مسبقًا أو استخدام حاويتك الخاصة.
في هذا التمرين المعملي، نستخدم تدريبًا مخصصًا عبر حاويتنا المخصصة على Google Container Registry. للبدء، انتقِل إلى قسم النماذج في قسم Vertex في Cloud Console:
الخطوة 1: بدء المهمة التدريبية
انقر على إنشاء لإدخال المَعلمات لمهمة التدريب والنموذج المنشور:
- ضمن مجموعة البيانات، اختَر ما مِن مجموعة بيانات مُدارة.
- بعد ذلك، اختَر التدريب المخصّص (متقدّم) كطريقة تدريب وانقر على متابعة.
- انقر على متابعة.
في الخطوة التالية، أدخِل mpg (أو أي اسم تريد تسميته للنموذج) في حقل اسم النموذج. بعد ذلك، حدّد حاوية مخصّصة:
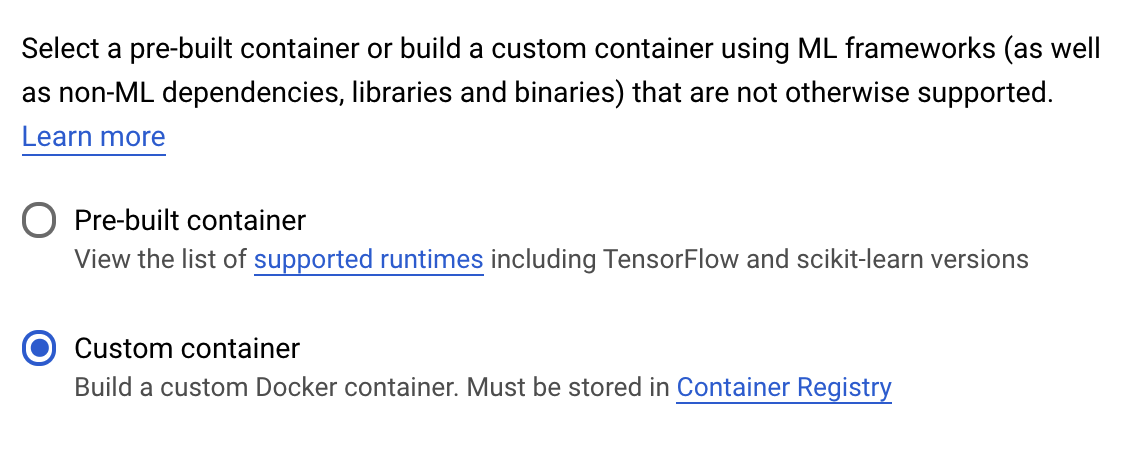
في مربع النص صورة الحاوية (Container image)، انقر على تصفّح واعثر على صورة Docker التي حمّلتها للتوّ إلى Container Registry. اترك باقي الحقول فارغةً وانقر على متابعة.
لن نستخدم ميزة ضبط المدخلات الفائقة في هذا الدليل التعليمي، لذا اترك مربّع تفعيل ميزة ضبط المدخلات الفائقة غير محدَّد وانقر على متابعة.
في قسم الحوسبة والأسعار، اترك المنطقة المحدّدة كما هي واختَر n1-standard-4 كنوع جهازك:

اترك حقول مسرعات الأداء فارغة وانقر على متابعة. نظرًا لأن النموذج في هذا العرض التوضيحي يتم تدريبه بسرعة، فإننا نستخدم نوع جهاز أصغر.
ضمن خطوة حاوية التنبؤ، اختَر حاوية مُنشأة مسبقًا، ثم اختَر TensorFlow 2.6.
اترُك الإعدادات التلقائية للحاوية المُنشأة مسبقًا كما هي. ضمن دليل النماذج، أدخِل حزمة GCS مع الدليل الفرعي mpg. هذا هو المسار في نص تدريب النموذج الذي تُصدِّر فيه النموذج المدَّرب:
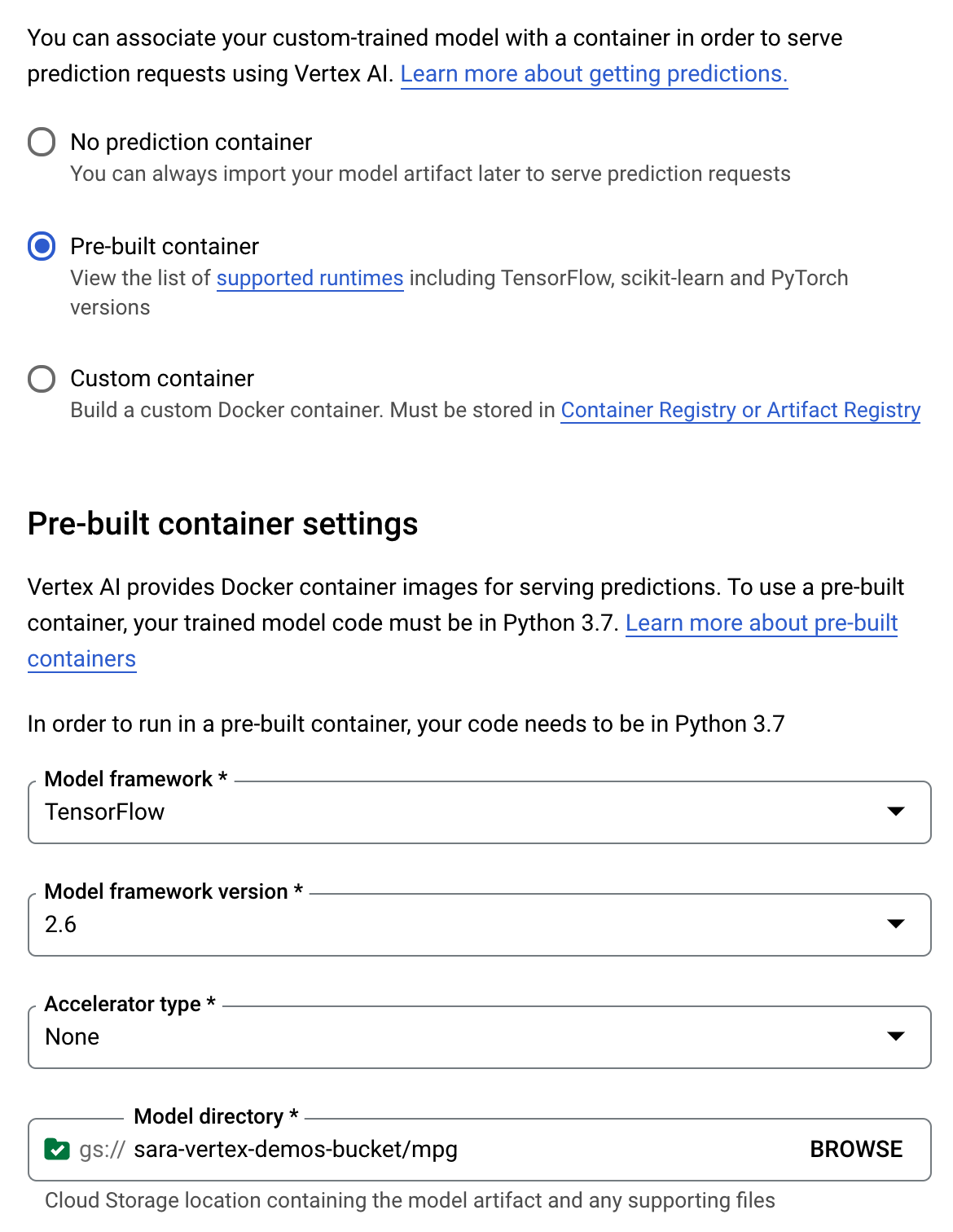
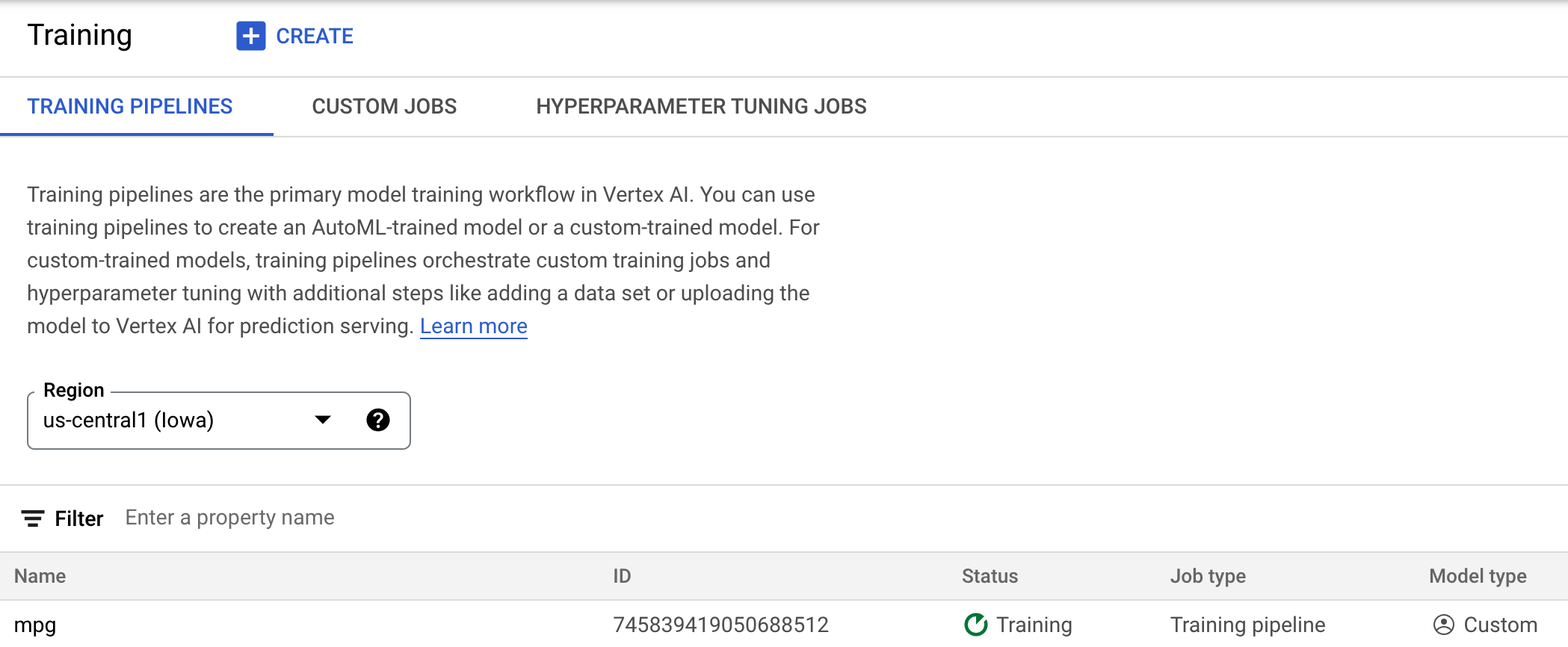
سيبحث Vertex في هذا الموقع الجغرافي عند نشر النموذج. أنت الآن جاهز للتدريب! انقر على بدء التدريب لبدء مهمة التدريب. في قسم "التدريب" في وحدة التحكم، سترى شيئًا مثل هذا:
6. نشر نقطة نهاية نموذج
عندما أعددت مهمة التدريب، حددنا المواضع التي يجب أن يبحث فيها Vertex AI عن مواد عرض النموذج التي يتم تصديرها. وكجزء من مسار التدريب لدينا، سينشئ Vertex نموذج مورد استنادًا إلى مسار مادة العرض هذا. لا يُعدّ مورد النموذج نفسه نموذجًا مُنشرًا، ولكن بعد الحصول على نموذج، تكون مستعدًا لنشره على نقطة نهاية. لمزيد من المعلومات حول النماذج ونقاط النهاية في Vertex AI، يمكنك الاطّلاع على المستندات.
سننشئ في هذه الخطوة نقطة نهاية للنموذج المدرَّب. ويمكننا استخدام هذه المعلومات للحصول على توقّعات بشأن النموذج عبر Vertex AI API.
الخطوة 1: نشر نقطة النهاية
عند اكتمال مهمة التدريب، من المفترض أن يظهر لك نموذج باسم mpg (أو أي اسم سمّيته) في قسم النماذج من وحدة التحكّم:
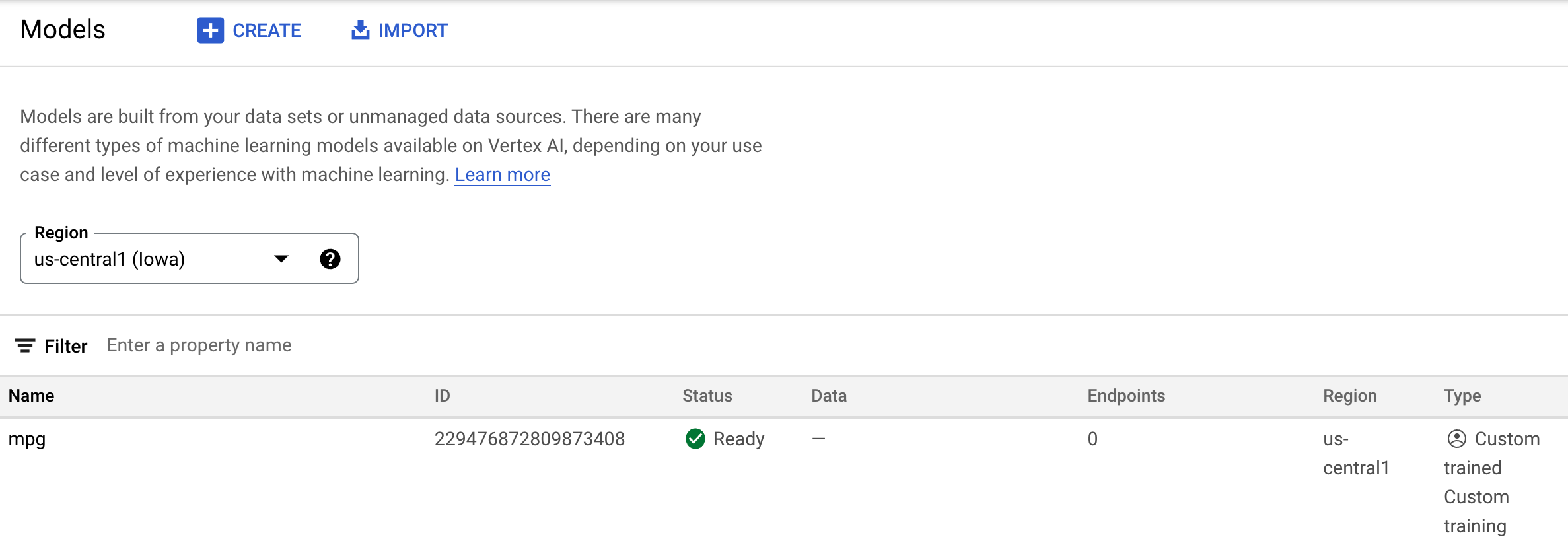
عند تنفيذ مهمة التدريب، أنشأ Vertex نموذج مورد لك. لاستخدام هذا النموذج، يجب نشر نقطة نهاية. يمكنك إنشاء العديد من نقاط النهاية لكل نموذج. انقر على النموذج، ثم انقر على النشر إلى نقطة النهاية.
اختَر إنشاء نقطة نهاية جديدة وأدخِل اسمًا لها، مثل v1. اترك الخيار عادي محددًا للوصول، ثم انقر على متابعة.
اترك تقسيم عدد الزيارات على 100 وأدخِل 1 للاطّلاع على الحد الأدنى لعدد عُقد الحوسبة. ضمن نوع الجهاز، اختَر n1-standard-2 (أو أي نوع جهاز تريده). اترك بقية الإعدادات التلقائية محددة، ثم انقر على متابعة. ولن نفعِّل المراقبة لهذا النموذج، لذا انقر بعد ذلك على نشر لبدء نشر نقطة النهاية.
سيستغرق نشر نقطة النهاية من 10 إلى 15 دقيقة، وستصلك رسالة إلكترونية عند اكتمال عملية النشر. عند الانتهاء من نشر نقطة النهاية، سيظهر لك ما يلي، والذي يعرض نقطة نهاية واحدة تم نشرها ضمن مورد النموذج:

الخطوة 2: الحصول على توقّعات بشأن النموذج المنشور
سوف نحصل على تنبؤات بشأن النموذج المُدرَّب من دفتر ملاحظات Python، باستخدام Vertex Python API. يمكنك الرجوع إلى مثيل دفتر الملاحظات وإنشاء دفتر ملاحظات Python 3 من "مشغّل التطبيقات":

في دفتر ملاحظاتك، شغِّل ما يلي في خلية لتثبيت حزمة تطوير البرامج Vertex AI:
!pip3 install google-cloud-aiplatform --upgrade --user
بعد ذلك، أضِف خلية في دفتر الملاحظات لاستيراد حزمة SDK وإنشاء إشارة إلى نقطة النهاية التي تم نشرها للتو:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/us-central1/endpoints/YOUR-ENDPOINT-ID"
)
عليك استبدال قيمتَين في سلسلة endpoint_name أعلاه برقم المشروع ونقطة النهاية. يمكنك العثور على رقم مشروعك من خلال الانتقال إلى لوحة بيانات المشروع والحصول على قيمة "رقم المشروع".
يمكنك العثور على رقم تعريف نقطة النهاية في قسم نقاط النهاية في وحدة التحكم هنا:
أخيرًا، يمكنك إجراء توقّع لنقطة النهاية من خلال نسخ الرمز البرمجي أدناه وتنفيذه في خلية جديدة:
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
يتضمن هذا المثال قيمًا تمت تسويتها، وهو التنسيق الذي يتوقعه نموذجنا.
وعند تنفيذ هذه الخلية، يُفترض أن يظهر لك ناتج التنبؤ حوالي 16 ميلاً لكل غالون.
🎉 تهانينا. 🎉
لقد تعلمت كيفية استخدام Vertex AI لإجراء ما يلي:
- يمكنك تدريب نموذج من خلال تقديم رمز التدريب في حاوية مخصّصة. لقد استخدمت نموذج TensorFlow في هذا المثال، ولكن يمكنك تدريب نموذج تم إنشاؤه باستخدام أي إطار عمل باستخدام حاويات مخصّصة.
- يمكنك نشر نموذج TensorFlow باستخدام حاوية تم إنشاؤها مسبقًا كجزء من سير العمل نفسه الذي استخدمته للتدريب.
- إنشاء نقطة نهاية نموذج وإنشاء عبارة بحث مقترحة.
لمعرفة المزيد عن الأجزاء المختلفة من Vertex، اطّلِع على المستندات.
7. تنظيف
إذا أردت مواصلة استخدام الدفتر الذي أنشأته في هذا التمرين المعملي، ننصحك بإيقافه عندما لا يكون قيد الاستخدام. من واجهة مستخدم Workbench في Cloud Console، اختَر ورقة الملاحظات ثم انقر على إيقاف.
إذا كنت ترغب في حذف دفتر الملاحظات بالكامل، فانقر فوق الزر حذف في أعلى الجانب الأيمن.
لحذف نقطة النهاية التي تم نشرها، انتقِل إلى قسم نقاط النهاية في وحدة تحكّم Vertex AI، وانقر على نقطة النهاية التي أنشأتها، ثم اختَر إلغاء نشر النموذج من نقطة النهاية:

لحذف "حزمة التخزين"، باستخدام قائمة التنقّل في Cloud Console، انتقِل إلى "مساحة التخزين" واختَر الحزمة وانقر على "حذف":