
1. Ringkasan
Di lab ini, Anda akan menggunakan Vertex AI untuk melatih dan menyajikan model TensorFlow menggunakan kode dalam container kustom.
Meskipun kita menggunakan TensorFlow untuk kode model di sini, Anda dapat dengan mudah menggantinya dengan framework lain.
Yang Anda pelajari
Anda akan mempelajari cara:
- Membangun dan membuat container kode pelatihan model di Vertex Workbench
- Mengirimkan tugas pelatihan model kustom ke Vertex AI
- Men-deploy model terlatih ke endpoint, dan menggunakan endpoint tersebut untuk mendapatkan prediksi
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $1.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI. Jika Anda memiliki masukan, harap lihat halaman dukungan.
Vertex AI mencakup banyak produk yang berbeda untuk mendukung alur kerja ML secara menyeluruh. Lab ini akan berfokus pada produk yang disorot di bawah: Training, Prediction, dan Workbench.

3. Menyiapkan lingkungan Anda
Anda memerlukan project Google Cloud Platform dengan penagihan yang diaktifkan untuk menjalankan codelab ini. Untuk membuat project, ikuti petunjuk di sini.
Langkah 1: Aktifkan Compute Engine API
Buka Compute Engine dan pilih Aktifkan jika belum diaktifkan. Anda akan memerlukan ini untuk membuat instance notebook.
Langkah 2: Aktifkan Vertex AI API
Buka bagian Vertex AI di Cloud Console Anda, lalu klik Aktifkan Vertex AI API.

Langkah 3: Aktifkan Container Registry API
Buka Container Registry dan pilih Aktifkan jika belum melakukannya. Anda akan menggunakannya untuk membuat container tugas pelatihan kustom.
Langkah 4: Buat instance Vertex AI Workbench
Dari bagian Vertex AI di Cloud Console Anda, klik Workbench:

Dari sana, di Notebook yang dikelola pengguna, klik Notebook Baru:

Kemudian, pilih jenis instance TensorFlow Enterprise (dengan LTS) versi terbaru tanpa GPU:

Gunakan opsi default, lalu klik Buat.
Model yang akan kita latih dan sajikan di lab ini dibangun berdasarkan tutorial ini dari dokumentasi TensorFlow. Tutorial ini menggunakan set data Auto MPG dari Kaggle untuk memprediksi efisiensi bahan bakar kendaraan.
4. Mem-build kode pelatihan dalam container
Kita akan mengirimkan tugas pelatihan ini ke Vertex dengan menempatkan kode pelatihan dalam container Docker dan mengirimkan container ini ke Google Container Registry. Dengan pendekatan ini, kita dapat melatih model yang dibangun dengan framework apa pun.
Untuk memulai, dari menu Peluncur, buka jendela Terminal di instance notebook Anda:

Buat direktori baru bernama mpg dan cd ke dalamnya:
mkdir mpg
cd mpg
Langkah 1: Buat Dockerfile
Langkah pertama dalam mem-build kode dalam container adalah membuat Dockerfile. Dalam Dockerfile, kita akan menyertakan semua perintah yang diperlukan untuk menjalankan image. Tindakan ini akan menginstal semua library yang kita gunakan dan menyiapkan titik entri untuk kode pelatihan kita. Dari Terminal Anda, buat Dockerfile kosong:
touch Dockerfile
Buka Dockerfile dan salin kode berikut ke dalamnya:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-6
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Dockerfile ini menggunakan image Docker Deep Learning Container TensorFlow Enterprise 2.3. Deep Learning Containers di Google Cloud dilengkapi dengan banyak ML umum dan framework data science yang diiinstal sebelumnya. Yang kita gunakan mencakup TF Enterprise 2.3, Pandas, Scikit-learn, dan lainnya. Setelah mendownload image tersebut, Dockerfile ini akan menyiapkan titik entri untuk kode pelatihan kita. Kita belum membuat file ini – pada langkah berikutnya, kita akan menambahkan kode untuk melatih dan mengekspor model.
Langkah 2: Buat bucket Cloud Storage
Dalam tugas pelatihan, kita akan mengekspor model TensorFlow terlatih ke Bucket Cloud Storage. Vertex akan menggunakan ini untuk membaca aset model yang diekspor dan men-deploy model. Dari Terminal Anda, jalankan perintah berikut untuk menentukan variabel env untuk project Anda, pastikan untuk mengganti your-cloud-project dengan ID project Anda:
PROJECT_ID='your-cloud-project'
Selanjutnya, jalankan perintah berikut di Terminal untuk membuat bucket baru dalam project Anda. Flag -l (lokasi) penting karena harus berada di region yang sama dengan tempat Anda men-deploy endpoint model nanti dalam tutorial:
BUCKET_NAME="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET_NAME
Langkah 3: Tambahkan kode pelatihan model
Dari Terminal, jalankan perintah berikut untuk membuat direktori bagi kode pelatihan dan file Python tempat kita akan menambahkan kode:
mkdir trainer
touch trainer/train.py
Sekarang Anda akan memiliki kode berikut di direktori mpg/:
+ Dockerfile
+ trainer/
+ train.py
Selanjutnya, buka file train.py yang baru saja Anda buat dan salin kode di bawah (kode ini diadaptasi dari tutorial di dokumentasi TensorFlow).
Di awal file, perbarui variabel BUCKET dengan nama Bucket Penyimpanan yang Anda buat di langkah sebelumnya:
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
"""Import it using pandas"""
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset.tail()
# TODO: replace `your-gcs-bucket` with the name of the Storage bucket you created earlier
BUCKET = 'gs://your-gcs-bucket'
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"Origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Langkah 4: Bangun dan uji container secara lokal
Dari Terminal, tentukan variabel dengan URI image container Anda di Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/mpg:v1"
Kemudian, build container dengan menjalankan perintah berikut dari root direktori mpg Anda:
docker build ./ -t $IMAGE_URI
Jalankan container dalam instance notebook Anda untuk memastikan container berfungsi dengan benar:
docker run $IMAGE_URI
Model akan selesai dilatih dalam waktu 1-2 menit dengan akurasi validasi sekitar 72% (akurasi yang tepat dapat bervariasi). Setelah selesai menjalankan container secara lokal, teruskan ke Google Container Registry:
docker push $IMAGE_URI
Setelah container dikirim ke Container Registry, kita siap untuk memulai tugas pelatihan model kustom.
5. Menjalankan tugas pelatihan di Vertex AI
Vertex AI memberi Anda dua opsi untuk melatih model:
- AutoML: Latih model berkualitas tinggi dengan upaya dan keahlian ML minimal.
- Pelatihan kustom: Jalankan aplikasi pelatihan kustom Anda di cloud menggunakan salah satu container bawaan Google Cloud atau gunakan container Anda sendiri.
Dalam lab ini, kita menggunakan pelatihan kustom melalui container kustom kita sendiri di Google Container Registry. Untuk memulai, buka bagian Model di bagian Vertex pada Konsol Cloud Anda:

Langkah 1: Mulai tugas pelatihan
Klik Buat untuk memasukkan parameter ke tugas pelatihan dan model yang di-deploy:
- Di bagian Set data, pilih Tidak ada set data terkelola
- Lalu, pilih Pelatihan kustom (lanjutan) sebagai metode pelatihan Anda dan klik Lanjutkan.
- Klik Lanjutkan
Pada langkah berikutnya, masukkan mpg (atau apa pun nama model yang Anda inginkan) untuk Nama model. Kemudian, pilih Container kustom:

Di kotak teks Container image, klik Browse dan temukan image Docker yang baru saja Anda upload ke Container Registry. Biarkan kolom lainnya kosong, lalu klik Lanjutkan.
Kita tidak akan menggunakan penyesuaian hyperparameter dalam tutorial ini, jadi biarkan kotak Enable hyperparameter tuning tidak dicentang, lalu klik Continue.
Di Compute and pricing, biarkan region yang dipilih seperti apa adanya dan pilih n1-standard-4 sebagai jenis mesin Anda:
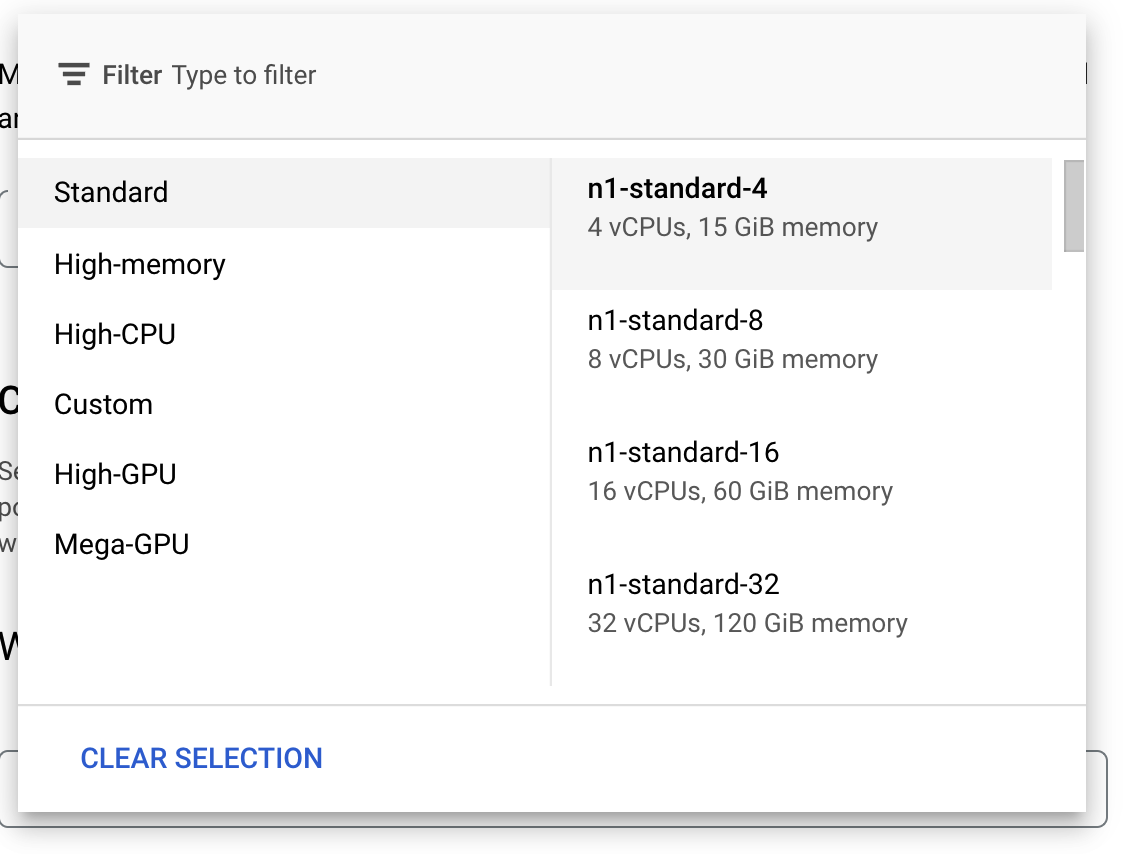
Biarkan kolom akselerator kosong, lalu pilih Lanjutkan. Karena model dalam demo ini dilatih dengan cepat, kita menggunakan jenis mesin yang lebih kecil.
Di langkah Prediction container, pilih Pre-built container, lalu pilih TensorFlow 2.6.
Biarkan setelan default untuk container bawaan apa adanya. Di bagian Direktori model, masukkan bucket GCS Anda dengan subdirektori mpg. Ini adalah jalur dalam skrip pelatihan model tempat Anda mengekspor model terlatih:

Vertex akan mencari di lokasi ini saat men-deploy model Anda. Sekarang Anda siap untuk pelatihan. Klik Start training untuk memulai tugas pelatihan. Di bagian Pelatihan konsol, Anda akan melihat sesuatu seperti ini:

6. Men-deploy endpoint model
Saat menyiapkan tugas pelatihan, kita menentukan tempat Vertex AI harus mencari aset model yang diekspor. Sebagai bagian dari pipeline pelatihan kami, Vertex akan membuat resource model berdasarkan jalur aset ini. Resource model itu sendiri bukanlah model yang di-deploy, tetapi setelah memiliki model, Anda siap men-deploy-nya ke endpoint. Untuk mempelajari lebih lanjut Model dan Endpoint di Vertex AI, lihat dokumentasinya.
Pada langkah ini, kita akan membuat endpoint untuk model terlatih. Kita dapat menggunakannya untuk mendapatkan prediksi pada model melalui Vertex AI API.
Langkah 1: Deploy endpoint
Setelah tugas pelatihan selesai, Anda akan melihat model bernama mpg (atau apa pun namanya) di bagian Model di konsol Anda:

Saat tugas pelatihan Anda berjalan, Vertex membuat resource model untuk Anda. Untuk menggunakan model ini, Anda harus men-deploy endpoint. Anda dapat memiliki banyak endpoint per model. Klik model, lalu klik Deploy ke endpoint.
Pilih Buat endpoint baru, lalu beri nama, seperti v1. Biarkan Standard dipilih untuk Akses, lalu klik Lanjutkan.
Biarkan Traffic split pada 100 dan masukkan 1 untuk Minimum number of compute nodes. Di bagian Machine type, pilih n1-standard-2 (atau jenis mesin apa pun yang Anda inginkan). Biarkan setelan default lainnya tetap dipilih, lalu klik Continue. Kita tidak akan mengaktifkan pemantauan untuk model ini, jadi klik Deploy untuk memulai deployment endpoint.
Endpoint akan di-deploy selama 10-15 menit, dan Anda akan menerima email saat deployment selesai. Setelah endpoint selesai di-deploy, Anda akan melihat hal berikut, yang menunjukkan satu endpoint di-deploy di resource Model Anda:

Langkah 2: Mendapatkan prediksi pada model yang di-deploy
Kita akan mendapatkan prediksi pada model terlatih dari notebook Python, menggunakan Vertex Python API. Kembali ke instance notebook Anda, dan buat notebook Python 3 dari Peluncur:

Di notebook Anda, jalankan kode berikut dalam sel untuk menginstal Vertex AI SDK:
!pip3 install google-cloud-aiplatform --upgrade --user
Kemudian, tambahkan sel di notebook Anda untuk mengimpor SDK dan membuat referensi ke endpoint yang baru saja Anda deploy:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/us-central1/endpoints/YOUR-ENDPOINT-ID"
)
Anda harus mengganti dua nilai dalam string endpoint_name di atas dengan nomor project dan endpoint Anda. Anda dapat menemukan nomor project dengan membuka dasbor project dan mendapatkan nilai Project Number.
Anda dapat menemukan ID endpoint di bagian endpoint pada konsol di sini:

Terakhir, buat prediksi ke endpoint Anda dengan menyalin dan menjalankan kode di bawah ini di sel baru:
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Contoh ini sudah memiliki nilai yang dinormalisasi, yang merupakan format yang diharapkan model kami.
Jalankan sel ini, dan Anda akan melihat output prediksi sekitar 16 mil per galon.
🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI untuk:
- Latih model dengan memberikan kode pelatihan dalam container kustom. Anda telah menggunakan model TensorFlow dalam contoh ini, tetapi Anda dapat melatih model yang dibangun dengan framework apa pun menggunakan container kustom.
- Deploy model TensorFlow menggunakan container bawaan sebagai bagian dari alur kerja yang sama dengan yang Anda gunakan untuk pelatihan.
- Buat endpoint model dan hasilkan prediksi.
Untuk mempelajari lebih lanjut berbagai bagian Vertex, lihat dokumentasinya.
7. Pembersihan
Jika Anda ingin terus menggunakan notebook yang Anda buat di lab ini, sebaiknya nonaktifkan notebook tersebut saat tidak digunakan. Dari UI Workbench di Konsol Cloud, pilih notebook, lalu pilih Stop.
Jika Anda ingin menghapus notebook secara keseluruhan, klik tombol Hapus di kanan atas.
Untuk menghapus endpoint yang Anda deploy, buka bagian Endpoints di konsol Vertex AI, klik endpoint yang Anda buat, lalu pilih Undeploy model from endpoint:

Untuk menghapus Bucket Penyimpanan menggunakan menu Navigasi di Cloud Console, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus:
