
1. Genel Bakış
Bu laboratuvarda, özel bir container'daki kodu kullanarak TensorFlow modeli eğitmek ve sunmak için Vertex AI'ı kullanacaksınız.
Burada model kodu için TensorFlow'u kullanıyoruz ancak bunu kolayca başka bir çerçeveyle değiştirebilirsiniz.
Öğrenecekleriniz
Öğrenecekleriniz:
- Vertex Workbench'te model eğitimi kodu oluşturma ve kapsülleme
- Vertex AI'a özel model eğitimi işi gönderme
- Eğitilen modelinizi bir uç noktaya dağıtma ve bu uç noktayı kullanarak tahminler alma
Bu laboratuvarı Google Cloud'da çalıştırmanın toplam maliyeti yaklaşık 1 ABD dolarıdır.
2. Vertex AI'a giriş
Bu laboratuvarda, Google Cloud'da sunulan en yeni yapay zeka ürünü kullanılmaktadır. Vertex AI, Google Cloud'daki makine öğrenimi tekliflerini sorunsuz bir geliştirme deneyimi için entegre eder. Daha önce, AutoML ile eğitilmiş modeller ve özel modeller ayrı hizmetler üzerinden erişilebiliyordu. Yeni teklif, diğer yeni ürünlerle birlikte bu iki ürünü tek bir API'de birleştirir. Mevcut projeleri de Vertex AI'a taşıyabilirsiniz. Geri bildiriminiz varsa lütfen destek sayfasına göz atın.
Vertex AI, uçtan uca makine öğrenimi iş akışlarını desteklemek için birçok farklı ürün içerir. Bu laboratuvarda, aşağıda vurgulanan ürünlere odaklanılacaktır: Eğitim, Tahmin ve Workbench.

3. Ortamınızı ayarlama
Bu codelab'i çalıştırmak için faturalandırmanın etkin olduğu bir Google Cloud Platform projesine ihtiyacınız vardır. Proje oluşturmak için buradaki talimatları uygulayın.
1. adım: Compute Engine API'yi etkinleştirin
Compute Engine'e gidin ve henüz etkinleştirilmemişse Etkinleştir'i seçin. Not defteri örneğinizi oluşturmak için bu bilgiye ihtiyacınız vardır.
2. adım: Vertex AI API'yi etkinleştirin
Cloud Console'unuzun Vertex AI bölümüne gidin ve Vertex AI API'yi etkinleştir'i tıklayın.

3. adım: Container Registry API'yi etkinleştirin
Container Registry'ye gidin ve henüz etkin değilse Etkinleştir'i seçin. Bu dosyayı, özel eğitim işiniz için bir kapsayıcı oluşturmak üzere kullanacaksınız.
4. adım: Vertex AI Workbench örneği oluşturma
Cloud Console'unuzun Vertex AI bölümünde Workbench'i tıklayın:

Buradan Kullanıcı tarafından yönetilen not defterleri bölümünde Yeni not defteri'ni tıklayın:

Ardından, GPU'suz en son TensorFlow Enterprise (LTS özellikli) örnek türünü seçin:

Varsayılan seçenekleri kullanıp Oluştur'u tıklayın.
Bu laboratuvarda eğiteceğimiz ve sunacağımız model, TensorFlow belgelerindeki bu eğitime dayanmaktadır. Eğitimde, bir aracın yakıt verimliliğini tahmin etmek için Kaggle'daki Auto MPG veri kümesi kullanılır.
4. Eğitim kodunu kapsayıcıya alma
Eğitim kodumuzu bir Docker container'ına yerleştirip bu container'ı Google Container Registry'ye aktararak bu eğitim işini Vertex'e göndeririz. Bu yaklaşımı kullanarak herhangi bir çerçeveyle oluşturulmuş bir modeli eğitebiliriz.
Başlamak için Başlatıcı menüsünden not defteri örneğinizde bir Terminal penceresi açın:

mpg adlı yeni bir dizin oluşturun ve bu dizine gidin:
mkdir mpg
cd mpg
1. adım: Dockerfile oluşturun
Kodumuzu kapsayıcılaştırmanın ilk adımı Dockerfile oluşturmaktır. Dockerfile'ımıza, görüntümüzü çalıştırmak için gereken tüm komutları ekleyeceğiz. Bu işlem, kullandığımız tüm kitaplıkları yükler ve eğitim kodumuz için giriş noktasını ayarlar. Terminalinizden boş bir Dockerfile oluşturun:
touch Dockerfile
Dockerfile'ı açın ve aşağıdakileri kopyalayın:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-6
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Bu Dockerfile, Deep Learning Container TensorFlow Enterprise 2.3 Docker görüntüsünü kullanır. Google Cloud'daki Deep Learning Containers'da birçok yaygın makine öğrenimi ve veri bilimi çerçevesi önceden yüklenmiş olarak gelir. Kullandığımız sürümde TF Enterprise 2.3, Pandas, Scikit-learn ve diğerleri yer alıyor. Bu görüntüyü indirdikten sonra, bu Dockerfile eğitim kodumuz için giriş noktasını ayarlar. Bu dosyaları henüz oluşturmadık. Sonraki adımda, modelimizi eğitmek ve dışa aktarmak için kodu ekleyeceğiz.
2. adım: Cloud Storage paketi oluşturma
Eğitim işimizde, eğitilmiş TensorFlow modelimizi bir Cloud Storage paketine aktaracağız. Vertex, dışa aktarılan model öğelerimizi okumak ve modeli dağıtmak için bu bilgiyi kullanır. Terminalinizde, projeniz için bir ortam değişkeni tanımlamak üzere aşağıdakileri çalıştırın. your-cloud-project yerine projenizin kimliğini yazdığınızdan emin olun:
PROJECT_ID='your-cloud-project'
Ardından, projenizde yeni bir paket oluşturmak için Terminal'inizde aşağıdakileri çalıştırın. -l (konum) işareti önemlidir. Çünkü bu işaret, eğitimin ilerleyen bölümlerinde model uç noktası dağıtacağınız bölgeyle aynı olmalıdır:
BUCKET_NAME="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET_NAME
3. adım: Model eğitimi kodu ekleyin
Terminalinizde aşağıdaki komutu çalıştırarak eğitim kodumuz için bir dizin ve kodu ekleyeceğimiz bir Python dosyası oluşturun:
mkdir trainer
touch trainer/train.py
Şimdi mpg/ dizininizde şunlar olmalıdır:
+ Dockerfile
+ trainer/
+ train.py
Ardından, az önce oluşturduğunuz train.py dosyasını açın ve aşağıdaki kodu kopyalayın (bu kod, TensorFlow dokümanlarındaki eğitimden alınmıştır).
Dosyanın başında, BUCKET değişkenini önceki adımda oluşturduğunuz Storage Bucket'ın adıyla güncelleyin:
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
"""Import it using pandas"""
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset.tail()
# TODO: replace `your-gcs-bucket` with the name of the Storage bucket you created earlier
BUCKET = 'gs://your-gcs-bucket'
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"Origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
4. adım: Kapsayıcıyı yerel olarak oluşturun ve test edin
Terminalinizden, Google Container Registry'deki container görüntünüzün URI'siyle bir değişken tanımlayın:
IMAGE_URI="gcr.io/$PROJECT_ID/mpg:v1"
Ardından, mpg dizininizin kökünden aşağıdaki komutu çalıştırarak kapsayıcıyı oluşturun:
docker build ./ -t $IMAGE_URI
Doğru çalıştığından emin olmak için kapsayıcıyı not defteri örneğinizde çalıştırın:
docker run $IMAGE_URI
Modelin eğitimi 1-2 dakika içinde tamamlanmalı ve doğrulama doğruluğu yaklaşık %72 olmalıdır (tam doğruluk değişebilir). Container'ı yerel olarak çalıştırmayı tamamladığınızda Google Container Registry'ye aktarın:
docker push $IMAGE_URI
Container'ımız Container Registry'ye aktarıldığına göre artık özel model eğitim işini başlatmaya hazırız.
5. Vertex AI'da eğitim işi çalıştırma
Vertex AI, modelleri eğitmek için iki seçenek sunar:
- AutoML: Minimum düzeyde çaba ve makine öğrenimi uzmanlığı ile yüksek kaliteli modeller eğitin.
- Özel eğitim: Google Cloud'un önceden oluşturulmuş container'larından birini kullanarak veya kendi container'ınızı kullanarak özel eğitim uygulamalarınızı bulutta çalıştırın.
Bu laboratuvarda, Google Container Registry'deki kendi özel container'ımız aracılığıyla özel eğitim kullanıyoruz. Başlamak için Cloud Console'unuzun Vertex bölümündeki Modeller bölümüne gidin:

1. adım: Eğitim işini başlatın
Eğitim işinizin ve dağıtılan modelinizin parametrelerini girmek için Oluştur'u tıklayın:
- Veri kümesi bölümünde Yönetilen veri kümesi yok'u seçin.
- Ardından eğitim yönteminiz olarak Özel eğitim (gelişmiş)'i seçip Devam'ı tıklayın.
- Devam et'i tıklayın.
Sonraki adımda, Model adı için mpg (veya modelinize vermek istediğiniz adı) girin. Ardından Özel kapsayıcı'yı seçin:

Container image (Kapsayıcı görüntüsü) metin kutusunda Browse'u (Gözat) tıklayın ve Container Registry'ye yeni yüklediğiniz Docker görüntüsünü bulun. Diğer alanları boş bırakıp Devam'ı tıklayın.
Bu eğitimde hiperparametre ayarını kullanmayacağız. Bu nedenle, Hiperparametre ayarını etkinleştir kutusunu işaretsiz bırakın ve Devam'ı tıklayın.
Compute and pricing (İşlem ve fiyatlandırma) bölümünde, seçili bölgeyi olduğu gibi bırakın ve makine türünüz olarak n1-standard-4'ü seçin:
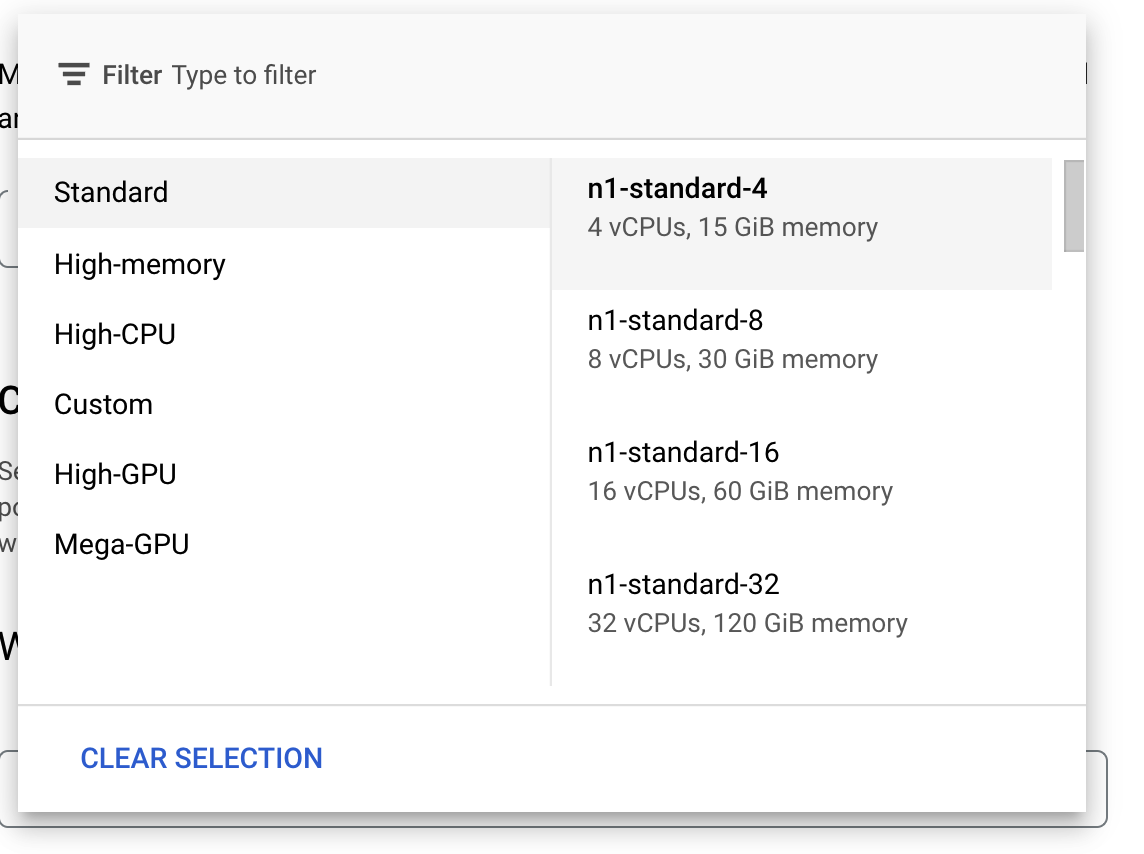
Hızlandırıcı alanlarını boş bırakın ve Devam'ı seçin. Bu demoda model hızlı bir şekilde eğitildiğinden daha küçük bir makine türü kullanıyoruz.
Tahmin kapsayıcısı adımında Önceden oluşturulmuş kapsayıcı'yı ve ardından TensorFlow 2.6'yı seçin.
Önceden oluşturulmuş kapsayıcı için varsayılan ayarları olduğu gibi bırakın. Model dizini bölümünde, mpg alt dizinini içeren GCS paketinizi girin. Bu, model eğitimi komut dosyanızda eğitilmiş modelinizi dışa aktardığınız yoldur:

Vertex, modelinizi dağıtırken bu konuma bakar. Artık eğitime hazırsınız. Eğitim işini başlatmak için Eğitimi başlat'ı tıklayın. Konsolunuzun Eğitim bölümünde şuna benzer bir şey görürsünüz:

6. Model uç noktası dağıtma
Eğitim işimizi oluştururken Vertex AI'ın, dışa aktarılan model öğelerimizi nerede arayacağını belirttik. Vertex, eğitim ardışık düzenimizin bir parçası olarak bu öğe yolunu temel alan bir model kaynağı oluşturur. Model kaynağının kendisi dağıtılmış bir model değildir ancak bir modeliniz olduğunda bunu bir uç noktaya dağıtmaya hazırsınız demektir. Vertex AI'daki modeller ve uç noktalar hakkında daha fazla bilgi edinmek için belgelere göz atın.
Bu adımda, eğitilmiş modelimiz için bir uç nokta oluşturacağız. Bunu, Vertex AI API aracılığıyla modelimizle ilgili tahminler almak için kullanabiliriz.
1. adım: Uç noktayı dağıtın
Eğitim işiniz tamamlandığında konsolunuzun Modeller bölümünde mpg (veya adını ne koyduysanız) adlı bir model görürsünüz:

Eğitim işiniz çalıştırıldığında Vertex sizin için bir model kaynağı oluşturdu. Bu modeli kullanmak için bir uç nokta dağıtmanız gerekir. Model başına birçok uç nokta olabilir. Modeli ve ardından Uç noktaya dağıt'ı tıklayın.
Yeni uç nokta oluştur'u seçin ve uç noktaya v1 gibi bir ad verin. Erişim için Standart'ı seçili olarak bırakın ve Devam'ı tıklayın.
Trafik yükü'nü 100 olarak bırakın ve Minimum işlem düğümü sayısı için 1 girin. Makine türü bölümünde n1-standard-2'yi (veya istediğiniz herhangi bir makine türünü) seçin. Varsayılan ayarların geri kalanını seçili olarak bırakıp Devam'ı tıklayın. Bu model için izleme etkinleştirilmeyecek. Bu nedenle, uç nokta dağıtımını başlatmak için Dağıt'ı tıklayın.
Uç noktanın dağıtılması 10-15 dakika sürer. Dağıtım tamamlandığında e-posta alırsınız. Uç nokta dağıtımı tamamlandığında, Model kaynağınız altında dağıtılan bir uç noktayı gösteren aşağıdaki iletiyi görürsünüz:

2. adım: Dağıtılan modelle ilgili tahminler alın
Vertex Python API'yi kullanarak bir Python not defterinden eğitilmiş modelimizle ilgili tahminler alacağız. Not defteri örneğinize geri dönün ve Başlatıcı'dan bir Python 3 not defteri oluşturun:

Not defterinizde, Vertex AI SDK'yı yüklemek için bir hücrede aşağıdakileri çalıştırın:
!pip3 install google-cloud-aiplatform --upgrade --user
Ardından, SDK'yı içe aktarmak ve yeni dağıttığınız uç nokta için bir referans oluşturmak üzere not defterinize bir hücre ekleyin:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/us-central1/endpoints/YOUR-ENDPOINT-ID"
)
Yukarıdaki endpoint_name dizesinde iki değeri proje numaranız ve uç noktanızla değiştirmeniz gerekir. Proje numaranızı bulmak için proje kontrol panelinize gidip Proje Numarası değerini alın.
Uç nokta kimliğinizi konsolun uç noktalar bölümünde bulabilirsiniz:

Son olarak, aşağıdaki kodu yeni bir hücreye kopyalayıp çalıştırarak uç noktanız için bir tahminde bulunun:
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Bu örnekte, modelimizin beklediği biçim olan normalleştirilmiş değerler zaten mevcut.
Bu hücreyi çalıştırdığınızda, galon başına yaklaşık 16 mil değerinde bir tahmin çıkışı görmeniz gerekir.
🎉 Tebrikler! 🎉
Vertex AI'ı kullanarak şunları yapmayı öğrendiniz:
- Özel bir kapsayıcıda eğitim kodu sağlayarak modeli eğitin. Bu örnekte TensorFlow modeli kullanılmıştır ancak özel container'lar kullanarak herhangi bir çerçeveyle oluşturulmuş bir modeli eğitebilirsiniz.
- Eğitim için kullandığınız iş akışının bir parçası olarak önceden oluşturulmuş bir container kullanarak TensorFlow modeli dağıtın.
- Model uç noktası oluşturun ve tahmin oluşturun.
Vertex'in farklı bölümleri hakkında daha fazla bilgi edinmek için belgelere göz atın.
7. Temizleme
Bu laboratuvarda oluşturduğunuz not defterini kullanmaya devam etmek istiyorsanız kullanmadığınız zamanlarda kapatmanız önerilir. Cloud Console'daki Workbench kullanıcı arayüzünde not defterini ve ardından Durdur'u seçin.
Not defterini tamamen silmek istiyorsanız sağ üstteki Sil düğmesini tıklayın.
Dağıttığınız uç noktayı silmek için Vertex AI konsolunuzun Uç noktalar bölümüne gidin, oluşturduğunuz uç noktayı tıklayın ve Modeli uç noktadan dağıtımı kaldır'ı seçin:

Cloud Console'unuzdaki gezinme menüsünü kullanarak depolama paketini silmek için Storage'a gidin, paketinizi seçin ve Sil'i tıklayın:
