1. Ringkasan
Di lab ini, Anda akan menggunakan Vertex AI untuk membuat pipeline yang melatih Model Keras kustom di TensorFlow. Kemudian, kami akan menggunakan fungsi baru yang tersedia di Vertex AI Experiments untuk melacak dan membandingkan model yang berjalan guna mengidentifikasi kombinasi hyperparameter mana yang menghasilkan performa terbaik.
Yang Anda pelajari
Anda akan mempelajari cara:
- Melatih Model Keras kustom untuk memprediksi rating pemain (misalnya, regresi)
- Menggunakan Kubeflow Pipelines SDK untuk membangun pipeline ML yang skalabel
- Membuat dan menjalankan pipeline 5 langkah yang menyerap data dari Cloud Storage, menskalakan data, melatih model, mengevaluasinya, dan menyimpan kembali model yang dihasilkan ke Cloud Storage
- Memanfaatkan Metadata Vertex ML untuk menyimpan artefak model seperti Model dan Metrik Model
- Memanfaatkan Eksperimen Vertex AI untuk membandingkan hasil dari berbagai operasi pipeline
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $1.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI.
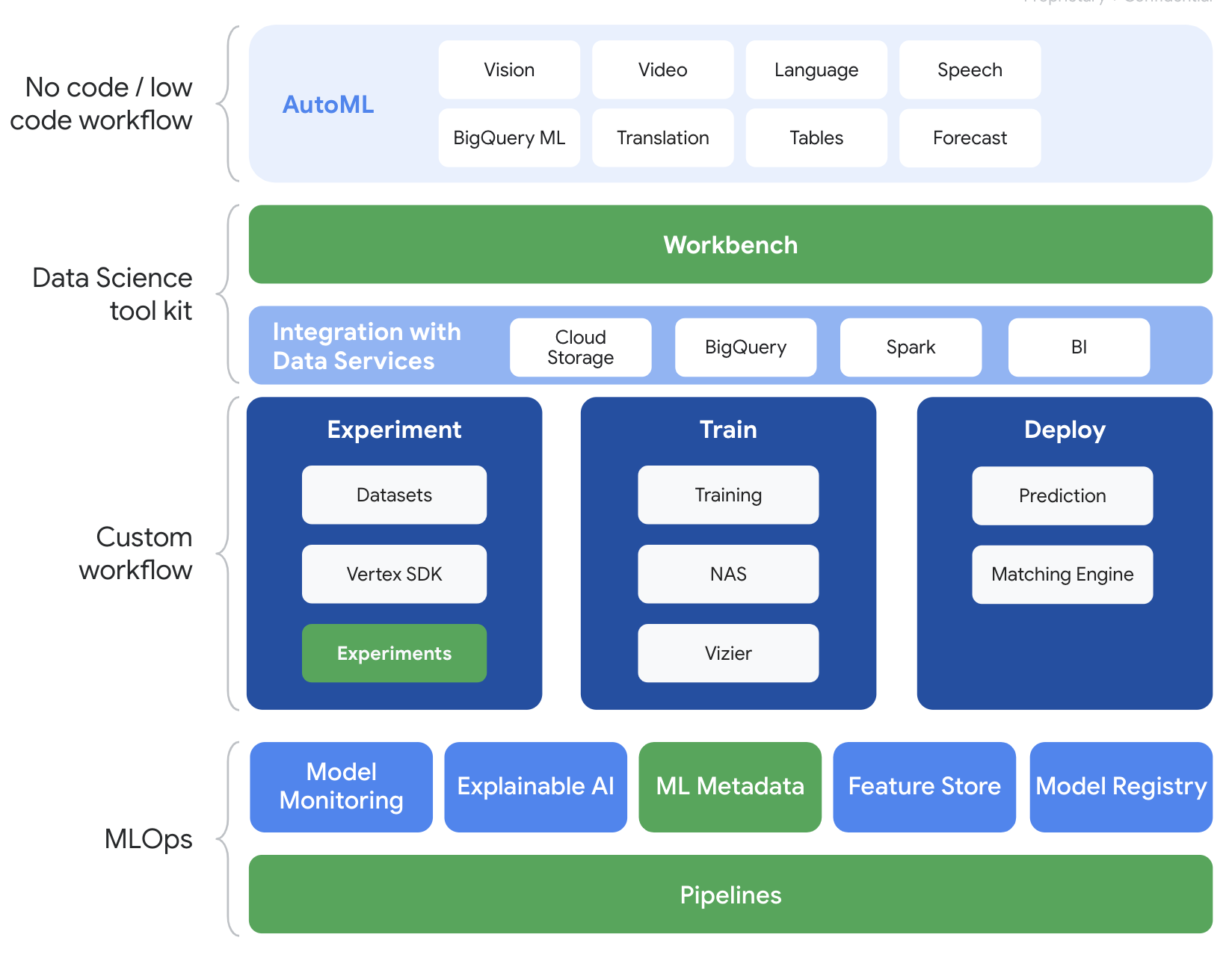
Vertex AI mencakup banyak produk yang berbeda untuk mendukung alur kerja ML secara menyeluruh. Lab ini akan berfokus pada produk yang disorot di bawah: Eksperimen, Pipeline, Metadata ML, dan Workbench
3. Ringkasan Kasus Penggunaan
Kita akan menggunakan set data sepak bola populer yang bersumber dari EA Sports' Serial video game FIFA. Ini mencakup lebih dari 25.000 pertandingan sepak bola dan 10.000+ pemain untuk musim 2008-2016. Datanya telah diproses sebelumnya sehingga Anda dapat memulai dengan lebih mudah. Anda akan menggunakan set data ini di seluruh lab, yang kini dapat ditemukan di bucket Cloud Storage publik. Kita akan memberikan detail selengkapnya nanti di codelab tentang cara mengakses set data. Tujuan akhir kami adalah memprediksi rating keseluruhan pemain berdasarkan berbagai tindakan dalam game seperti intersepsi dan penalti.
Mengapa Eksperimen Vertex AI bermanfaat untuk Data Science?
Ilmu data bersifat eksperimental - mereka disebut ilmuwan. Data scientist yang baik didasarkan pada hipotesis, menggunakan uji coba dan kesalahan untuk menguji berbagai hipotesis dengan harapan bahwa iterasi berturut-turut akan menghasilkan model yang lebih berperforma.
Meskipun tim {i>data science<i} telah melakukan eksperimen, mereka sering kali kesulitan melacak pekerjaan mereka dan mempelajari “rahasia” yang terungkap melalui upaya eksperimen mereka. Hal ini terjadi karena beberapa alasan:
- Melacak pekerjaan pelatihan bisa menjadi rumit, sehingga mudah untuk melupakan apa yang berhasil versus apa yang tidak.
- Masalah ini menjadi lebih kompleks ketika Anda melihat tim {i>data science<i} karena tidak semua anggota dapat melacak eksperimen atau bahkan membagikan hasilnya kepada orang lain
- Pengambilan data memakan waktu dan sebagian besar tim memanfaatkan metode manual (misalnya, spreadsheet atau dokumen) yang menghasilkan informasi yang tidak konsisten dan tidak lengkap untuk dipelajari
tl;dr: Eksperimen Vertex AI bekerja untuk Anda, membantu Anda melacak dan membandingkan eksperimen dengan lebih mudah
Mengapa Eksperimen Vertex AI untuk Game?
Game secara historis telah menjadi tempat bermain untuk machine learning dan eksperimen ML. Game tidak hanya menghasilkan miliaran peristiwa real time per hari, tetapi mereka memanfaatkan semua data tersebut dengan memanfaatkan eksperimen ML dan ML untuk meningkatkan pengalaman dalam game, mempertahankan pemain, dan mengevaluasi berbagai pemain di platform mereka. Oleh karena itu, kami pikir set data game sangat cocok dengan latihan eksperimen secara keseluruhan.
4. Menyiapkan lingkungan Anda
Anda memerlukan project Google Cloud Platform dengan penagihan yang diaktifkan untuk menjalankan codelab ini. Untuk membuat project, ikuti petunjuk di sini.
Langkah 1: Aktifkan Compute Engine API
Buka Compute Engine dan pilih Aktifkan jika belum diaktifkan.
Langkah 2: Aktifkan Vertex AI API
Buka bagian Vertex AI di Cloud Console Anda, lalu klik Aktifkan Vertex AI API.
Langkah 3: Membuat instance Vertex AI Workbench
Dari bagian Vertex AI di Cloud Console Anda, klik Workbench:
Aktifkan Notebooks API jika belum diaktifkan.
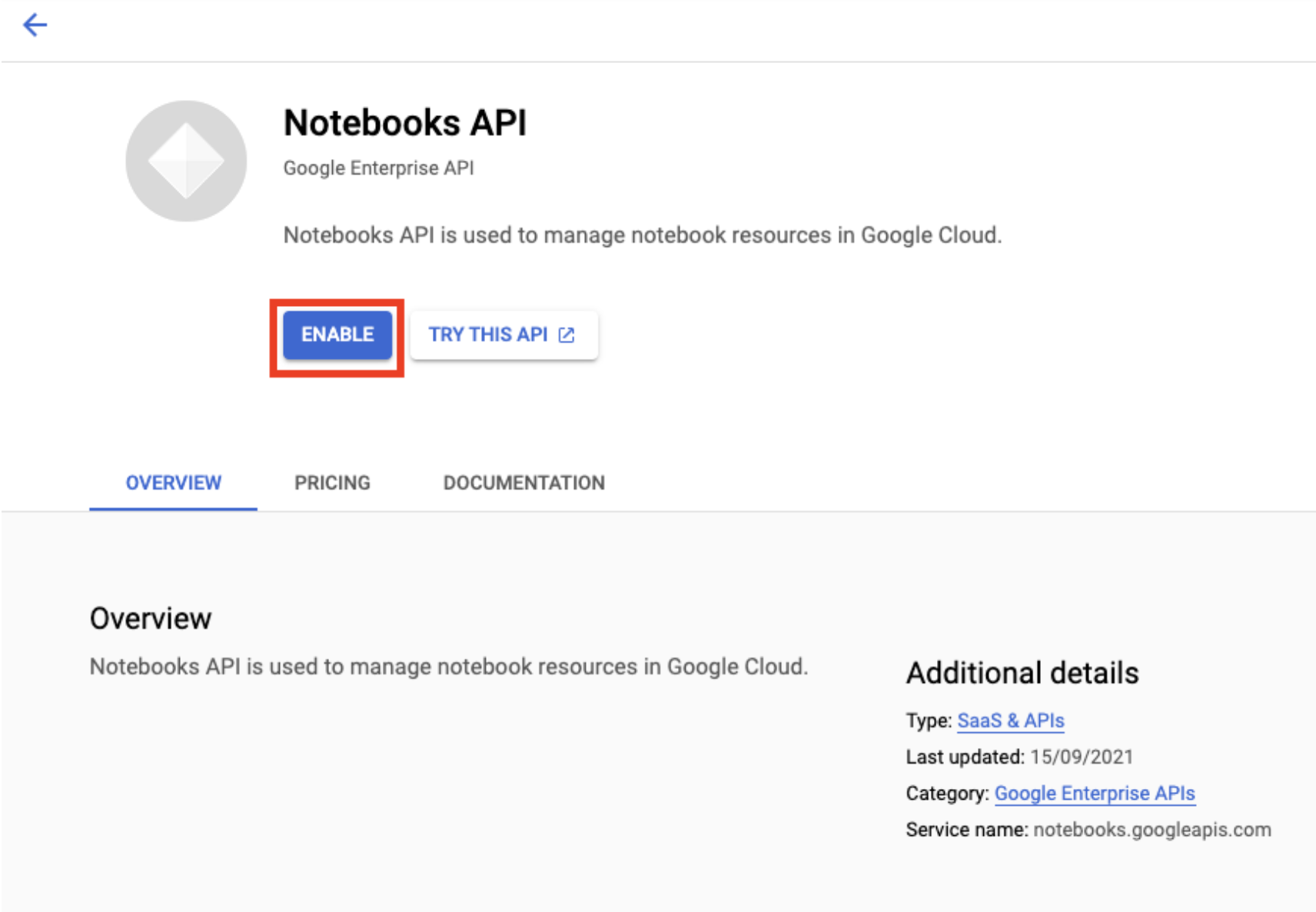
Setelah diaktifkan, klik NOTEBOOK TERKELOLA:

Kemudian, pilih NOTEBOOK BARU.
Beri nama notebook Anda, lalu klik Setelan Lanjutan.

Di bagian Setelan Lanjutan, aktifkan penonaktifan tidak ada aktivitas dan setel jumlah menit ke 60. Artinya, notebook Anda akan otomatis dinonaktifkan saat tidak digunakan agar tidak menimbulkan biaya tambahan.

Langkah 4: Buka Notebook Anda
Setelah instance dibuat, pilih Buka JupyterLab.

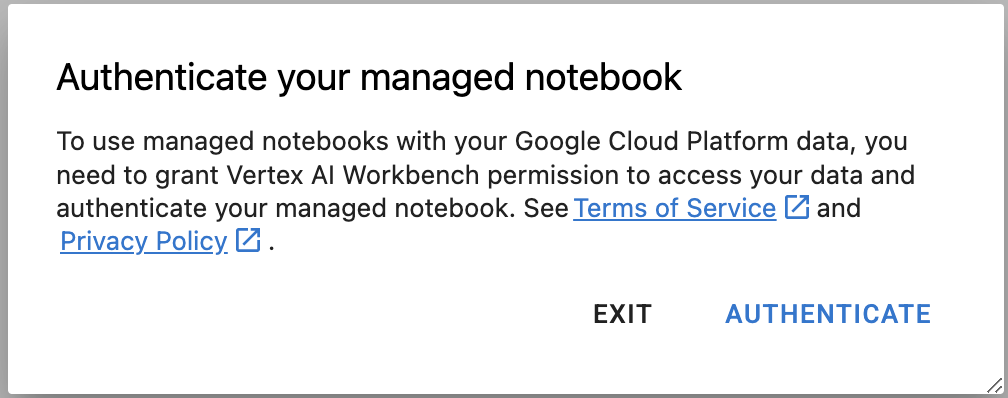
Langkah 5: Autentikasi (khusus pertama kali)
Saat pertama kali menggunakan instance baru, Anda akan diminta untuk mengautentikasi. Ikuti langkah-langkah di UI untuk melakukannya.
Langkah 6: Pilih Kernel yang sesuai
Notebook terkelola menyediakan beberapa kernel dalam satu UI. Pilih kernel untuk Tensorflow 2 (lokal).

5. Langkah-Langkah Penyiapan Awal di Buku Catatan Anda
Anda harus melakukan serangkaian langkah tambahan untuk menyiapkan lingkungan dalam notebook sebelum membangun pipeline. Langkah-langkah ini mencakup: menginstal paket tambahan, menetapkan variabel, membuat bucket cloud storage, menyalin set data game dari bucket penyimpanan publik, serta mengimpor library dan menentukan konstanta tambahan.
Langkah 1: Instal Paket Tambahan
Kami perlu menginstal dependensi paket tambahan yang saat ini tidak terinstal di lingkungan notebook Anda. Contohnya mencakup KFP SDK.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
Anda kemudian perlu memulai ulang {i> Notebook Kernel<i} sehingga Anda dapat menggunakan paket yang diunduh di dalam {i>notebook<i} Anda.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Langkah 2: Tetapkan Variabel
Kita ingin menentukan PROJECT_ID. Jika tidak mengetahui Project_ID, Anda mungkin bisa mendapatkan PROJECT_ID menggunakan gcloud.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Jika tidak, tetapkan PROJECT_ID Anda di sini.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
Kita juga ingin menetapkan variabel REGION, yang digunakan di seluruh notebook ini. Berikut adalah region yang didukung untuk Vertex AI. Sebaiknya pilih region yang paling dekat dengan Anda.
- Amerika: us-central1
- Eropa: europe-west4
- Asia Pasifik: asia-east1
Jangan gunakan bucket multi-regional untuk pelatihan dengan Vertex AI. Tidak semua region menyediakan dukungan untuk semua layanan Vertex AI. Pelajari region Vertex AI lebih lanjut.
#set your region
REGION = "us-central1" # @param {type: "string"}
Terakhir, kita akan menetapkan variabel TIMESTAMP. Variabel ini digunakan untuk menghindari konflik nama antarpengguna pada resource yang dibuat, Anda membuat TIMESTAMP untuk setiap sesi instance, dan menambahkannya ke nama resource yang Anda buat dalam tutorial ini.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Langkah 3: Buat bucket Cloud Storage
Anda harus menentukan dan memanfaatkan bucket staging Cloud Storage. Bucket staging adalah tempat semua data yang terkait dengan set data dan resource model Anda disimpan di seluruh sesi.
Tetapkan nama bucket Cloud Storage Anda di bawah. Nama bucket harus unik secara global di semua project Google Cloud, termasuk project di luar organisasi Anda.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
Jika bucket BELUM ada, Anda dapat menjalankan sel berikut untuk membuat bucket Cloud Storage.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Kemudian, Anda dapat memverifikasi akses ke bucket Cloud Storage dengan menjalankan sel berikut.
#verify access
! gsutil ls -al $BUCKET_URI
Langkah 4: Salin Set Data Game kami
Seperti yang disebutkan sebelumnya, Anda akan memanfaatkan {i>dataset<i} game populer dari video game populer EA Sports, FIFA. Kami telah melakukan prapemrosesan untuk Anda sehingga Anda hanya perlu menyalin set data dari bucket penyimpanan publik dan memindahkannya ke set data yang telah Anda buat.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
Langkah 5: Impor Library dan Tentukan Konstanta Tambahan
Selanjutnya, kita akan mengimpor library untuk Vertex AI, KFP, dan sebagainya.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
Kita juga akan menentukan konstanta tambahan yang akan kita rujuk kembali di seluruh notebook seperti jalur file ke data pelatihan kita.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. Mari Membangun Pipeline
Sekarang keseruan bisa dimulai dan kita dapat mulai memanfaatkan Vertex AI untuk membangun pipeline pelatihan. Kami akan melakukan inisialisasi Vertex AI SDK, menyiapkan tugas pelatihan sebagai komponen pipeline, membangun pipeline, mengirimkan proses pipeline, dan memanfaatkan Vertex AI SDK untuk melihat eksperimen dan memantau statusnya.
Langkah 1: Lakukan inisialisasi Vertex AI SDK
Lakukan inisialisasi Vertex AI SDK, dengan menetapkan PROJECT_ID dan BUCKET_URI.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
Langkah 2: Siapkan Tugas Pelatihan sebagai Komponen Pipeline
Untuk mulai menjalankan eksperimen, kita perlu menetapkan tugas pelatihan dengan menentukannya sebagai komponen pipeline. Pipeline kita akan menerima data pelatihan dan hyperparameter (mis., DROPOUT_RATE, LEARNING_RATE, EPOCHS) sebagai input dan metrik model output (misalnya, MAE dan RMSE) serta artefak model.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
Langkah 3: Membuat Pipeline
Sekarang kita akan menyiapkan alur kerja menggunakan Domain Specific Language (DSL) yang tersedia di KFP dan mengompilasi pipeline menjadi file JSON.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
Langkah 4: Kirimkan Operasi Pipeline kami
Kerja keras telah selesai menyiapkan komponen dan menentukan pipeline kita. Kita siap mengirimkan berbagai operasi pipeline yang telah ditentukan di atas. Untuk melakukannya, kita harus menentukan nilai untuk berbagai hyperparameter sebagai berikut:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
Setelah hyperparameter ditentukan, kita kemudian dapat memanfaatkan for loop agar berhasil melakukan feed dalam berbagai proses pipeline:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
Langkah 5: Manfaatkan Vertex AI SDK untuk Melihat Eksperimen
Vertex AI SDK memungkinkan Anda memantau status operasi pipeline. Anda juga dapat menggunakannya untuk menampilkan parameter dan metrik Pipeline Runs di Vertex AI Experiment. Gunakan kode berikut untuk melihat parameter yang terkait dengan operasi Anda dan statusnya saat ini.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
Anda dapat memanfaatkan kode di bawah ini untuk mendapatkan info terbaru tentang status operasi pipeline Anda.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
Anda juga dapat memanggil tugas pipeline tertentu menggunakan run_name.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
Terakhir, Anda dapat memuat ulang status lari pada interval yang ditetapkan (misalnya setiap 60 detik) untuk melihat perubahan status dari RUNNING menjadi FAILED atau COMPLETE.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. Identifikasi Lari Berperforma Terbaik
Bagus, sekarang hasil dari pipeline kita berjalan. Anda mungkin bertanya, apa yang bisa saya pelajari dari hasilnya? Output dari eksperimen Anda harus berisi lima baris, satu untuk setiap operasi pipeline. Hasilnya akan terlihat seperti berikut:

MAE dan RMSE merupakan ukuran error prediksi model rata-rata, sehingga dalam sebagian besar kasus, nilai yang lebih rendah untuk kedua metrik adalah yang diinginkan. Kita dapat melihat berdasarkan output dari Vertex AI Experiments bahwa operasi paling sukses kami di kedua metrik adalah proses terakhir dengan dropout_rate 0,001, learning_rate jika 0,001, dan jumlah total epochs adalah 20. Berdasarkan eksperimen ini, parameter model tersebut pada akhirnya akan digunakan dalam produksi karena akan menghasilkan performa model terbaik.
Dengan begitu, kamu sudah menyelesaikan lab!
🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI untuk:
- Latih Model Keras kustom untuk memprediksi rating pemain (misalnya, regresi)
- Menggunakan Kubeflow Pipelines SDK untuk membangun pipeline ML yang skalabel
- Membuat dan menjalankan pipeline 5 langkah yang menyerap data dari GCS, menskalakan data, melatih model, mengevaluasinya, dan menyimpan model yang dihasilkan kembali ke GCS
- Memanfaatkan Metadata Vertex ML untuk menyimpan artefak model seperti Model dan Metrik Model
- Memanfaatkan Eksperimen Vertex AI untuk membandingkan hasil dari berbagai operasi pipeline
Untuk mempelajari lebih lanjut berbagai bagian Vertex, lihat dokumentasinya.
8. Pembersihan
Agar Anda tidak dikenai biaya, sebaiknya hapus resource yang dibuat di lab ini.
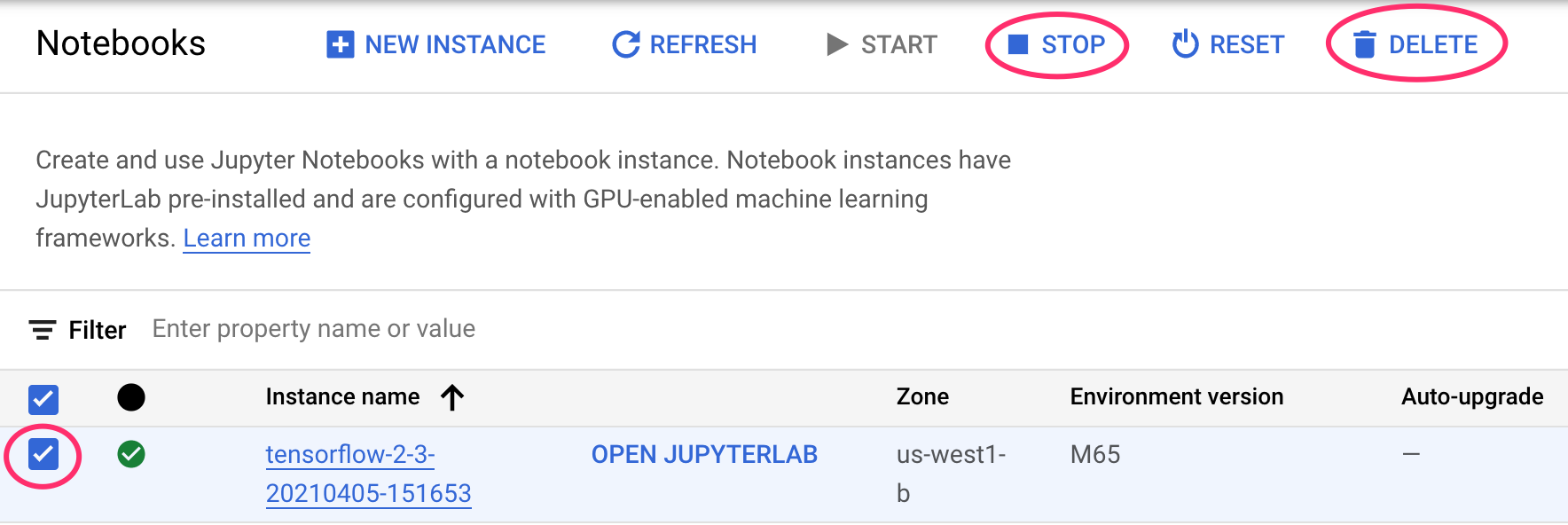
Langkah 1: Hentikan atau hapus instance Notebooks Anda
Jika ingin terus menggunakan notebook yang Anda buat di lab ini, sebaiknya nonaktifkan notebook tersebut saat tidak digunakan. Dari UI Notebooks di Konsol Cloud, pilih notebook, lalu pilih Stop. Jika Anda ingin menghapus instance secara keseluruhan, pilih Hapus:
Langkah 2: Hapus bucket Cloud Storage
Untuk menghapus Bucket Penyimpanan menggunakan menu Navigasi di Cloud Console, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus: