1. نظرة عامة
في هذا التمرين المعملي، ستستخدم Vertex AI لإنشاء مسار مسطّح لتدريب نموذج Keras المخصّص في TensorFlow. سنستخدم بعد ذلك الوظيفة الجديدة المتاحة في تجارب Vertex AI لتتبُّع عمليات تنفيذ النماذج ومقارنتها من أجل تحديد مجموعة من المعلَمات الفائقة التي تحقّق أفضل أداء.
المعلومات التي تطّلع عليها
وستتعرّف على كيفية:
- تدريب نموذج Keras المخصّص للتنبؤ بتقييمات اللاعبين (مثل الانحدار)
- استخدام حزمة تطوير البرامج لمنصة Kubeflow Pipelines لإنشاء مسارات تعلُّم الآلة قابلة للتوسّع
- يمكنك إنشاء وتشغيل مسار مؤلف من 5 خطوات لنقل البيانات من Cloud Storage، وقياس البيانات، وتدريب النموذج، وتقييمه، ثم حفظ النموذج الناتج في Cloud Storage مرة أخرى.
- الاستفادة من البيانات الوصفية لتعلُّم الآلة في Vertex لحفظ عناصر النموذج، مثل "نماذج Google" و"مقاييس النماذج"
- استخدام تجارب Vertex AI لمقارنة نتائج مسارات التعلّم المختلفة
تبلغ التكلفة الإجمالية لتنفيذ هذا البرنامج التدريبي على Google Cloud حوالي 1 دولار أمريكي.
2. مقدّمة عن Vertex AI
يستخدم هذا البرنامج أحدث منتجات الذكاء الاصطناعي المتوفّرة على Google Cloud. تدمج Vertex AI عروض تعلُّم الآلة في Google Cloud في تجربة تطوير سلسة. في السابق، كان بالإمكان الوصول إلى النماذج المدربة باستخدام AutoML والنماذج المخصّصة من خلال خدمات منفصلة. ويدمج العرض الجديد كلاً من واجهة برمجة تطبيقات واحدة مع منتجات جديدة أخرى. يمكنك أيضًا نقل المشاريع الحالية إلى Vertex AI.
يتضمّن Vertex AI العديد من المنتجات المختلفة لدعم سير العمل الشامل لتعلُّم الآلة. سيركّز هذا التمرين المعملي على المنتجات الموضَّحة أدناه: التجارب وPipelines والبيانات الوصفية لتعلُّم الآلة وWorkbench.

3- نظرة عامة على حالة الاستخدام
سنستخدم مجموعة بيانات شهيرة لكرة القدم مصدرها EA Sports سلسلة ألعاب فيديو FIFA ويشمل أكثر من 25,000 مباراة كرة قدم وما يزيد عن 10,000 لاعب للمواسم 2008-2016. تمت معالجة البيانات مسبقًا بشكل مسبق حتى تتمكّن من البدء بسرعة أكبر. ستستخدم مجموعة البيانات هذه في جميع أنحاء المختبر، والتي يمكن العثور عليها الآن في حزمة علنية على Cloud Storage. وسنقدم المزيد من التفاصيل لاحقًا في التمرين المعملي حول الترميز حول كيفية الوصول إلى مجموعة البيانات. هدفنا النهائي هو توقّع التقييم العام للاعب استنادًا إلى الإجراءات المختلفة داخل اللعبة، مثل عمليات الاعتراضات والعقوبات.
لماذا تُعد تجربة Vertex AI مفيدة لعلوم البيانات؟
علم البيانات تجريبي بطبيعته، فنحن نُطلَق على علماء البيانات اسم "علماء". يعتمد علماء البيانات الجيدون على الفرضيات، ويستخدمون التجربة والخطأ لاختبار فرضيات مختلفة على أمل أن تؤدي التكرارات المتتالية إلى نموذج يحقّق أداءً أفضل.
على الرغم من أنّ فِرق علم البيانات قد تبنّت التجارب، إلا أنّها غالبًا ما تواجه صعوبة في تتبُّع عملها و"السرّ" الذي تم اكتشافه من خلال جهودها التجريبية. ويحدث ذلك لعدة أسباب:
- يمكن أن يصبح تتبع وظائف التدريب أمرًا مرهقًا، مما يجعل من السهل إغفال ما هو ناجح مقابل ما هو غير ناجح
- تتراكم هذه المشكلة عند النظر عبر فريق علم البيانات حيث قد لا يقوم جميع الأعضاء بتتبع التجارب أو حتى مشاركة نتائجهم مع الآخرين
- تستغرق عملية جمع البيانات وقتًا طويلاً، وتعتمد معظم الفِرق على طرق يدوية (مثل جداول البيانات أو المستندات) تؤدي إلى الحصول على معلومات غير متّسقة وغير مكتملة يمكن الاستفادة منها.
تنجز tl;dr: المهمة نيابةً عنك، ما يساعدك في تتبُّع تجاربك ومقارنتها بسهولة أكبر.
أهمية تجربة Vertex AI لألعاب الفيديو
كانت الألعاب في السابق مساحة للتعلّم الآلي وتجارب تعلُّم الآلة. لا تنتج الألعاب فقط مليارات الأحداث في الوقت الفعلي، بل تستفيد من كل هذه البيانات من خلال الاستفادة من تجارب تعلُّم الآلة وتعلُّم الآلة لتحسين التجارب داخل اللعبة والاحتفاظ باللاعبين وتقييم اللاعبين المختلفين على منصاتهم. وبالتالي رأينا أن مجموعة بيانات الألعاب تتلاءم جيدًا مع تمرين تجاربنا الشاملة.
4. إعداد البيئة
ستحتاج إلى مشروع Google Cloud Platform مع تفعيل الفوترة لتشغيل هذا الدرس التطبيقي حول الترميز. لإنشاء مشروع، يُرجى اتّباع التعليمات هنا.
الخطوة 1: تفعيل واجهة برمجة تطبيقات Compute Engine
انتقِل إلى Compute Engine واختَر تفعيل إذا لم يسبق لك تفعيله.
الخطوة 2: تفعيل واجهة برمجة التطبيقات Vertex AI API
انتقِل إلى قسم Vertex AI في Cloud Console وانقر على تفعيل Vertex AI API.
الخطوة 3: إنشاء مثيل Vertex AI Workbench
من قسم Vertex AI في Cloud Console، انقر على Workbench:
فعِّل Notebooks API إذا لم يسبق لك تفعيلها.
بعد التفعيل، انقر على المفكرات المُدارة:

ثم اختَر مفكرة جديدة.
أدخِل اسمًا لدفتر الملاحظات، ثم انقر على الإعدادات المتقدّمة.

ضمن "الإعدادات المتقدّمة"، فعِّل ميزة "إيقاف الجهاز في حال عدم النشاط" واضبط عدد الدقائق على 60. وهذا يعني أنه سيتم إغلاق دفتر الملاحظات تلقائيًا عندما لا يتم استخدامه، وبذلك لن تتحمل أي تكاليف غير ضرورية.

الخطوة 4: فتح دفتر الملاحظات
بعد إنشاء المثيل، اختَر فتح JupyterLab.

الخطوة 5: المصادقة (للمرة الأولى فقط)
عند استخدام مثيل جديد لأول مرة، سيُطلب منك المصادقة. اتّبِع الخطوات في واجهة المستخدم لإجراء ذلك.
الخطوة 6: تحديد Kernel المناسب
توفر أوراق الملاحظات المُدارة نواة متعددة في واجهة مستخدم واحدة. حدد النواة لـ Tensorflow 2 (محلي).

5- خطوات الإعداد الأولية في دفتر ملاحظاتك
ستحتاج إلى اتخاذ سلسلة من الخطوات الإضافية لإعداد بيئتك داخل دفتر الملاحظات قبل إنشاء مسار العملية. تتضمن هذه الخطوات: تثبيت أي حزم إضافية، وإعداد المتغيرات، وإنشاء حزمة التخزين في السحابة الإلكترونية، ونسخ مجموعة بيانات الألعاب من حزمة تخزين عامة، واستيراد المكتبات، وتحديد ثوابت إضافية.
الخطوة 1: تثبيت حِزم إضافية
سنحتاج إلى تثبيت حِزم إضافية غير مثبّتة حاليًا في بيئة دفتر الملاحظات. يتضمن أحد الأمثلة حزمة تطوير البرامج (SDK) لـ KFP.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
ستحتاج بعد ذلك إلى إعادة تشغيل النواة الدفترية لكي تتمكن من استخدام الحزم التي تم تنزيلها داخل دفتر الملاحظات.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
الخطوة 2: ضبط المتغيرات
نريد تعريف PROJECT_ID. إذا كنت لا تعرف Project_ID، قد يكون بإمكانك الحصول على PROJECT_ID باستخدام gcloud.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
وبخلاف ذلك، يمكنك ضبط PROJECT_ID هنا.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
يجب أيضًا ضبط المتغيّر REGION، والذي يُستخدم في باقي ورقة الملاحظات هذه. في ما يلي المناطق التي تتوفّر فيها خدمة Vertex AI. ننصحك باختيار المنطقة الأقرب إليك.
- الأمريكتان: us-central1
- أوروبا: europe-west4
- آسيا والمحيط الهادئ: asia-east1
يُرجى عدم استخدام حزمة متعددة المناطق للتدريب باستخدام Vertex AI. لا تتوفّر جميع خدمات Vertex AI في بعض المناطق. مزيد من المعلومات حول مناطق Vertex AI
#set your region
REGION = "us-central1" # @param {type: "string"}
أخيرًا، سنقوم بتعيين متغير TIMESTAMP. تُستخدم هذه المُتغيّرات لتجنُّب تعارض الأسماء بين المستخدمين في الموارد التي يتم إنشاؤها، وعليك إنشاء TIMESTAMP لكل جلسة مثيل وإلحاقها باسم الموارد التي تنشئها في هذا الدليل التوجيهي.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
الخطوة 3: إنشاء حزمة على Cloud Storage
يجب تحديد حزمة مراحل مرحلية في Cloud Storage والاستفادة منها. إنّ حزمة التقسيم المرحلي هي المكان الذي يتم فيه الاحتفاظ بجميع البيانات المرتبطة بمجموعة البيانات وموارد النموذج في جميع الجلسات.
اضبط اسم حزمة Cloud Storage أدناه. يجب أن تكون أسماء الحِزم فريدة على مستوى العالم في جميع مشاريع Google Cloud، بما في ذلك المشاريع خارج مؤسستك.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
إذا لم تكن حزمتك متوفّرة، يمكنك تشغيل الخلية التالية لإنشاء حزمتك على Cloud Storage.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
يمكنك بعد ذلك إثبات إمكانية الوصول إلى حزمة Cloud Storage من خلال تنفيذ الخلية التالية.
#verify access
! gsutil ls -al $BUCKET_URI
الخطوة 4: نسخ مجموعة بيانات الألعاب
كما ذكرنا سابقًا، سيتم الاستفادة من مجموعة بيانات الألعاب الرائجة التي توفّرها ألعاب الفيديو الرائجة FIFA التابعة لشركة EA Sports. لقد أنجزنا إجراءات المعالجة المسبقة لك، لذا لن تحتاج سوى نسخ مجموعة البيانات من حزمة مساحة التخزين العامة ونقلها إلى الحزمة التي أنشأتها.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
الخطوة 5: استيراد المكتبات وتحديد الثوابت الإضافية
بعد ذلك، سنحتاج إلى استيراد مكتباتنا من Vertex AI وKFP وغيرها.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
سنعرّف أيضًا ثوابتًا إضافية سنشير إليها في باقي ورقة الملاحظات مثل مسارات الملفات في بيانات التدريب.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6- دعنا ننشئ مسارنا
أصبح بإمكاننا الآن الاستفادة من Vertex AI لإنشاء مسار التدريب. سنبدأ في إعداد حزمة تطوير برامج Vertex AI، وإعداد المهمة التدريبية كمكوّن لمسار التعلّم، وبناء المسارات، وإرسال مسارات التعلّم، والاستفادة من حزمة تطوير برامج Vertex AI لعرض التجارب ورصد حالتها.
الخطوة 1: إعداد حزمة تطوير برامج Vertex AI
يجب إعداد حزمة تطوير برامج Vertex AI، وإعداد PROJECT_ID وBUCKET_URI.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
الخطوة 2: إعداد مهمة التدريب كمكوّن لمسار
لكي نبدأ إجراء تجاربنا، سنحتاج إلى تحديد مهمة التدريب من خلال تعريفها كمكون من مسارات التعلّم. ستستخدِم مسار الإحالة الناجحة بيانات التدريب ومدخلات الضبط (مثل DROPOUT_RATE وLEARNING_RATE وEPOCHS) كمدخلات ومقاييس نموذج الإخراج (على سبيل المثال، MAE وRMSE) وقطعة نموذجية.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
الخطوة 3: بناء الأنابيب
سنبدأ الآن بإعداد سير العمل باستخدام Domain Specific Language (DSL) المتوفر في KFP وتجميع المسار في ملف JSON.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
الخطوة 4: إرسال خطوات التنفيذ
ويأتي العمل الشاق في إعداد المكون وتحديد مسار العملية. نحن جاهزون لإرسال مسارات مختلفة لسير العمل التي حدّدناها أعلاه. ولإجراء ذلك، سنحتاج إلى تحديد قيم المعلَمات الفائقة المختلفة على النحو التالي:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
بعد تحديد المَعلمات الفائقة، يمكننا بعد ذلك الاستفادة من for loop لإضافة عمليات التشغيل المختلفة لمسار الإحالة الناجحة بنجاح:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
الخطوة 5: الاستفادة من حزمة تطوير برامج Vertex AI للاطّلاع على التجارب
تسمح لك حزمة تطوير برامج Vertex AI بمراقبة حالة عمليات تشغيل المسارات. يمكنك أيضًا استخدامها لعرض مَعلمات ومقاييس عمليات تنفيذ مسار الإحالة الناجحة في تجربة Vertex AI. استخدِم الرمز التالي للاطّلاع على المعلَمات المرتبطة بعمليات التشغيل وحالتها الحالية.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
يمكنك الاستفادة من الرمز البرمجي أدناه للحصول على آخر الأخبار حول حالة عمليات تنفيذ مسارات التعلّم.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
يمكنك أيضًا استدعاء مهام محددة لمسار التعلّم باستخدام run_name.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
أخيرًا، يمكنك تعديل حالة عمليات التشغيل على فترات زمنية محدّدة (مثلاً كل 60 ثانية) للاطّلاع على تغيير الحالات من RUNNING إلى FAILED أو COMPLETE.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. تحديد تمرين الجري الأفضل أداءً
رائع، لدينا الآن نتائج عمليات التنفيذ. قد تتساءل ماذا يمكنني أن أتعلم من النتائج؟ يجب أن تحتوي النتائج من تجاربك على خمسة صفوف، صف واحد لكل عملية تشغيل في مسار التعلّم. وسيبدو كما يلي:

يُعدّ كلّ من MAE وRMSE مقياسَين لمتوسط خطأ توقّعات النموذج، لذا من المستحسن الحصول على قيمة أقل لكلا المقياسَين في معظم الحالات. استنادًا إلى النتائج التي توصّلنا إليها في Vertex AI Experience، تبيّن أنّ الأداء الأكثر نجاحًا على مستوى كلا المقياسَين كان الاختبار النهائي بقيمة dropout_rate بقيمة 0.001، وlearning_rate إذا كانت 0.001، وإجمالي عدد epochs هو 20. استنادًا إلى هذه التجربة، سيتم استخدام معلَمات النموذج هذه في النهاية في الإنتاج لأنّها تؤدي إلى تحقيق أفضل أداء للنموذج.
بذلك تكون قد أنهيت التمرين المعملي!
🎉 تهانينا. 🎉
لقد تعلمت كيفية استخدام Vertex AI لإجراء ما يلي:
- تدريب نموذج Keras المخصّص للتنبؤ بتقييمات اللاعبين (مثل الانحدار)
- استخدام حِزم تطوير البرامج (SDK) لمسار Kubeflow Pipelines لإنشاء مسارات تعلُّم آلي قابلة للتطوير
- إنشاء وتشغيل مسار مكوَّن من 5 خطوات لنقل البيانات من فريق GCS، وقياس البيانات، وتدريب النموذج، وتقييمه، ثم حفظ النموذج الناتج في GCS مرة أخرى
- الاستفادة من البيانات الوصفية لتعلُّم الآلة في Vertex لحفظ عناصر النموذج، مثل "نماذج Google" و"مقاييس النماذج"
- استخدام تجارب Vertex AI لمقارنة نتائج مسارات التعلّم المختلفة
لمزيد من المعلومات حول أجزاء مختلفة من Vertex، يمكنك الاطّلاع على المستندات.
8. تنظيف
حتى لا يتم تحصيل رسوم منك، ننصحك بحذف الموارد التي تم إنشاؤها خلال هذا الدرس التطبيقي.
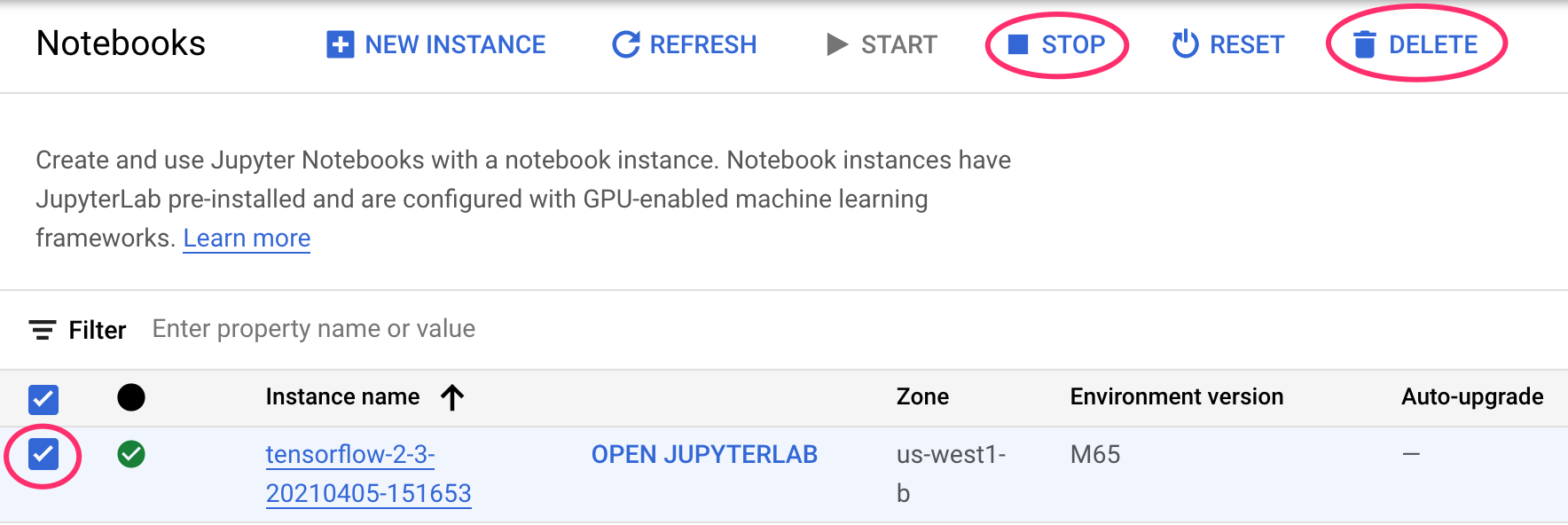
الخطوة 1: إيقاف أو حذف مثيل "دفاتر ملاحظات Google"
إذا أردت مواصلة استخدام الدفتر الذي أنشأته في هذا التمرين المعملي، ننصحك بإيقافه عندما لا يكون قيد الاستخدام. من واجهة مستخدم "دفاتر الملاحظات" في Cloud Console، اختَر ورقة الملاحظات ثم انقر على إيقاف. إذا أردت حذف المثيل بأكمله، انقر على حذف:
الخطوة 2: حذف حزمة Cloud Storage
لحذف "حزمة التخزين"، باستخدام قائمة التنقّل في Cloud Console، انتقِل إلى "مساحة التخزين" واختَر الحزمة وانقر على "حذف":