1. Übersicht
In diesem Lab erstellen Sie mit Vertex AI eine Pipeline, die ein benutzerdefiniertes Keras-Modell in TensorFlow trainiert. Anschließend verwenden wir die neue Funktion in Vertex AI Experiments, um Modellausführungen zu verfolgen und zu vergleichen, um festzustellen, welche Kombination von Hyperparametern die beste Leistung erzielt.
Lerninhalte
Die folgenden Themen werden behandelt:
- Trainieren Sie ein benutzerdefiniertes Keras-Modell, um Spielerbewertungen vorherzusagen (z.B. Regression)
- Mit dem Kubeflow Pipelines SDK skalierbare ML-Pipelines erstellen
- Eine fünfstufige Pipeline erstellen und ausführen, die Daten aus Cloud Storage aufnimmt, skaliert, das Modell trainiert, bewertet und das resultierende Modell wieder in Cloud Storage speichert
- Nutzen Sie Vertex ML Metadata, um Modellartefakte wie Modelle und Modellmesswerte zu speichern
- Mit Vertex AI Experiments die Ergebnisse verschiedener Pipelineausführungen vergleichen
Die Gesamtkosten für das Lab in Google Cloud belaufen sich auf 1$.
2. Einführung in Vertex AI
In diesem Lab wird das neueste KI-Produktangebot verwendet, das in Google Cloud verfügbar ist. Vertex AI bindet die ML-Angebote in Google Cloud in eine nahtlose Entwicklungsumgebung ein. Zuvor waren mit AutoML trainierte und benutzerdefinierte Modelle über separate Dienste zugänglich. Das neue Angebot vereint beides in einer einzigen API sowie weitere neue Produkte. Sie können auch vorhandene Projekte zu Vertex AI migrieren.
Vertex AI umfasst viele verschiedene Produkte zur Unterstützung von End-to-End-ML-Workflows. In diesem Lab liegt der Schwerpunkt auf den unten aufgeführten Produkten: Tests, Pipelines, ML-Metadaten und Workbench.

3. Anwendungsfall – Übersicht
Wir verwenden ein beliebtes Fußball-Dataset von EA Sports FIFA-Videospielreihe. Sie umfasst mehr als 25.000 Fußballspiele und über 10.000 Spieler für die Saison 2008 bis 2016. Die Daten wurden vorab verarbeitet, damit Sie direkt loslegen können. Sie verwenden dieses Dataset im gesamten Lab, das sich jetzt in einem öffentlichen Cloud Storage-Bucket befindet. Wir werden später im Codelab weitere Informationen zum Zugriff auf das Dataset geben. Unser Ziel ist es, die Gesamtbewertung eines Spielers basierend auf verschiedenen In-Game-Aktionen wie Interceptions und Elfmetern vorherzusagen.
Warum sind Vertex AI Experiments nützlich für Data Science?
Die Datenwissenschaft ist experimentell und heißt schließlich doch als Wissenschaftler. Gute Fachkräfte für Datenwissenschaft arbeiten mit Hypothesen, die mithilfe von „Trial and Error“ verschiedene Hypothesen testen in der Hoffnung, dass aufeinanderfolgende Iterationen zu einem leistungsfähigeren Modell führen.
Data Science-Teams haben zwar Tests eingeführt, haben aber oft Schwierigkeiten, den Überblick über ihre Arbeit und die „Geheimzutat“ zu behalten, die sie durch ihre Testbemühungen entdeckt haben. Dafür gibt es mehrere Gründe:
- Das Tracking von Trainingsjobs kann mühsam sein und es ist leicht, den Überblick darüber zu verlieren, was funktioniert und was nicht.
- Dieses Problem verschärft sich noch, wenn man ein Data-Science-Team betrachtet, da nicht alle Mitglieder Experimente verfolgen oder ihre Ergebnisse sogar mit anderen teilen.
- Die Datenerfassung ist zeitaufwendig und die meisten Teams nutzen manuelle Methoden (z.B. Tabellen oder Dokumente), die zu uneinheitlichen und unvollständigen Informationen führen, aus denen sie lernen können
tl;dr::Vertex AI Experiments erledigt die Arbeit für Sie, sodass Sie Ihre Tests einfacher verfolgen und vergleichen können
Warum Vertex AI Experiments für Gaming?
Spiele sind in der Vergangenheit eine Spielwiese für maschinelles Lernen und ML-Experimente. Spiele produzieren nicht nur Milliarden von Echtzeit-Ereignissen pro Tag, sondern nutzen all diese Daten auch, indem sie ML- und ML-Experimente nutzen, um das Spielerlebnis zu verbessern, Spieler zu binden und die verschiedenen Spieler auf ihrer Plattform zu bewerten. Daher dachten wir, dass ein Gaming-Dataset gut zu unserer Testaufgabe insgesamt passt.
4. Umgebung einrichten
Sie benötigen ein Google Cloud-Projekt mit aktivierter Abrechnung, um dieses Codelab ausführen zu können. Folgen Sie dieser Anleitung, um ein Projekt zu erstellen.
Schritt 1: Compute Engine API aktivieren
Gehen Sie zu Compute Engine und wählen Sie Aktivieren aus, falls dies noch nicht geschehen ist.
Schritt 2: Vertex AI API aktivieren
Rufen Sie in der Cloud Console den Bereich Vertex AI auf und klicken Sie auf Vertex AI API aktivieren.
Schritt 3: Vertex AI Workbench-Instanz erstellen
Klicken Sie im Bereich Vertex AI der Cloud Console auf Workbench:
Aktivieren Sie die Notebooks API, falls noch nicht geschehen.
Klicken Sie nach der Aktivierung auf VERWALTETE NOTEBOOKS:

Wählen Sie dann NEUES NOTEBOOK aus.
Geben Sie Ihrem Notebook einen Namen und klicken Sie auf Erweiterte Einstellungen.

Aktivieren Sie unter „Erweiterte Einstellungen“ das Herunterfahren bei Inaktivität und legen Sie die Anzahl der Minuten auf 60 fest. Das bedeutet, dass Ihr Notebook bei Nichtgebrauch automatisch heruntergefahren wird, sodass Ihnen keine unnötigen Kosten entstehen.

Schritt 4: Notebook öffnen
Nachdem die Instanz erstellt wurde, wählen Sie JupyterLab öffnen aus.

Schritt 5: Authentifizieren (nur beim ersten Mal)
Wenn Sie eine neue Instanz zum ersten Mal verwenden, werden Sie aufgefordert, sich zu authentifizieren. Folgen Sie dazu den Schritten in der Benutzeroberfläche.
Schritt 6: Geeigneten Kernel auswählen
Verwaltete Notebooks bieten mehrere Kernel in einer einzigen UI. Wählen Sie den Kernel für Tensorflow 2 (lokal) aus.

5. Ersteinrichtung auf dem Notebook
Sie müssen eine Reihe zusätzlicher Schritte ausführen, um Ihre Umgebung in Ihrem Notebook einzurichten, bevor Sie Ihre Pipeline erstellen. Diese Schritte umfassen: Installieren zusätzlicher Pakete, Festlegen von Variablen, Erstellen eines Cloud Storage-Buckets, Kopieren des Gaming-Datasets aus einem öffentlichen Storage-Bucket, Importieren von Bibliotheken und Definieren zusätzlicher Konstanten.
Schritt 1: Zusätzliche Pakete installieren
Wir müssen zusätzliche Paketabhängigkeiten installieren, die derzeit nicht in Ihrer Notebookumgebung installiert sind. Ein Beispiel beinhaltet das KFP SDK.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
Anschließend müssen Sie den Notebook-Kernel neu starten, damit Sie die heruntergeladenen Pakete in Ihrem Notebook verwenden können.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Schritt 2: Variablen festlegen
Wir wollen unsere PROJECT_ID definieren. Wenn Sie die Project_ID nicht kennen, können Sie die PROJECT_ID möglicherweise mit gcloud abrufen.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Andernfalls legen Sie hier Ihren PROJECT_ID fest.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
Wir möchten auch die Variable REGION festlegen, die für den Rest dieses Notebooks verwendet wird. Im Folgenden finden Sie die Regionen, die für Vertex AI unterstützt werden. Wir empfehlen Ihnen, die Region auszuwählen, die Ihnen am nächsten liegt.
- Amerika: us-central1
- Europa: europe-west4
- Asiatisch-pazifischer Raum: asia-east1
Verwenden Sie für das Training mit Vertex AI keinen multiregionalen Bucket. Nicht alle Regionen bieten Unterstützung für alle Vertex-AI-Dienste. Weitere Informationen zu Vertex-AI-Regionen.
#set your region
REGION = "us-central1" # @param {type: "string"}
Zum Schluss legen wir eine TIMESTAMP-Variable fest. Mit dieser Variablen werden Namenskonflikte zwischen Nutzern bei erstellten Ressourcen vermieden. Sie erstellen eine TIMESTAMP für jede Instanzsitzung und hängen sie an den Namen der Ressourcen an, die Sie in dieser Anleitung erstellen.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Schritt 3: Cloud Storage-Bucket erstellen
Sie müssen einen Cloud Storage-Staging-Bucket angeben und nutzen. Im Staging-Bucket werden alle Daten gespeichert, die mit Ihrem Dataset und Ihren Modellressourcen verknüpft sind.
Legen Sie unten den Namen des Cloud Storage-Buckets fest. Bucket-Namen müssen global eindeutig über alle Google Cloud-Projekte hinweg sein, auch für Projekte außerhalb Ihrer Organisation.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
Wenn Ihr Bucket noch nicht vorhanden ist, können Sie die folgende Zelle ausführen, um Ihren Cloud Storage-Bucket zu erstellen.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Sie können dann den Zugriff auf Ihren Cloud Storage-Bucket überprüfen, indem Sie die folgende Zelle ausführen.
#verify access
! gsutil ls -al $BUCKET_URI
Schritt 4: Gaming-Dataset kopieren
Wie bereits erwähnt, verwenden Sie ein beliebtes Gaming-Dataset der beliebten Videospiele von EA Sports, FIFA. Wir haben die Vorverarbeitung für Sie erledigt, sodass Sie nur das Dataset aus dem öffentlichen Storage-Bucket kopieren und in den von Ihnen erstellten Bucket verschieben müssen.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
Schritt 5: Bibliotheken importieren und zusätzliche Konstanten definieren
Als Nächstes importieren wir unsere Bibliotheken für Vertex AI, KFP usw.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
Außerdem definieren wir zusätzliche Konstanten, auf die wir uns im Rest des Notebooks beziehen, z. B. die Dateipfade zu unseren Trainingsdaten.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. Unsere Pipeline erstellen
Jetzt können wir mit Vertex AI unsere Trainingspipeline erstellen. Wir initialisieren das Vertex AI SDK, richten unseren Trainingsjob als Pipelinekomponente ein, erstellen unsere Pipeline, senden unsere Pipelineausführungen und nutzen das Vertex AI SDK, um Tests anzusehen und ihren Status zu überwachen.
Schritt 1: Vertex AI SDK initialisieren
Initialisieren Sie das Vertex AI SDK und legen Sie PROJECT_ID und BUCKET_URI fest.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
Schritt 2: Trainingsjob als Pipelinekomponente einrichten
Um mit der Ausführung unserer Tests zu beginnen, müssen wir unseren Trainingsjob spezifizieren, indem wir ihn als Pipelinekomponente definieren. Unsere Pipeline nimmt Trainingsdaten und Hyperparameter (z. B. DROPOUT_RATE, LEARNING_RATE, EPOCHS) als Eingaben und Ausgabemodellmesswerte (z.B. MAE und RMSE) sowie ein Modellartefakt.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
Schritt 3: Unsere Pipeline aufbauen
Jetzt richten wir unseren Workflow mit der in KFP verfügbaren Domain Specific Language (DSL) ein und kompilieren unsere Pipeline in eine JSON-Datei.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
Schritt 4: Pipelineausführung(en) einreichen
Die harte Arbeit ist die Einrichtung der Komponente und die Definition der Pipeline abgeschlossen. Wir sind bereit, verschiedene Ausführungen der oben angegebenen Pipeline einzureichen. Dazu müssen wir die Werte für unsere verschiedenen Hyperparameter wie folgt definieren:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
Nachdem die Hyperparameter definiert sind, können wir mithilfe eines for loop die verschiedenen Ausführungen der Pipeline erfolgreich einspeisen:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
Schritt 5: Mit dem Vertex AI SDK Tests ansehen
Mit dem Vertex AI SDK können Sie den Status von Pipelineausführungen überwachen. Sie können damit auch Parameter und Messwerte der Pipelineausführungen im Vertex AI Experiment zurückgeben. Verwenden Sie den folgenden Code, um die mit Ihren Ausführungen verknüpften Parameter und ihren aktuellen Status aufzurufen.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
Mit dem folgenden Code können Sie Updates zum Status Ihrer Pipelineausführungen erhalten.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
Sie können auch bestimmte Pipelinejobs mit der run_name aufrufen.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
Schließlich können Sie den Status Ihrer Ausführungen in festgelegten Intervallen (z. B. alle 60 Sekunden) aktualisieren, um zu sehen, wie sich der Status von RUNNING in FAILED oder COMPLETE ändert.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. Den Lauf mit der besten Leistung ermitteln
Großartig, jetzt haben wir die Ergebnisse unserer Pipelineausführungen. Vielleicht fragen Sie sich, was ich aus den Ergebnissen lernen kann. Die Ausgabe Ihrer Tests sollte fünf Zeilen enthalten, eine für jeden Durchlauf der Pipeline. Sie sieht in etwa so aus:

Sowohl MAE als auch RMSE sind Maße für den durchschnittlichen Vorhersagefehler des Modells. Daher ist ein niedrigerer Wert für beide Messwerte in den meisten Fällen wünschenswert. Laut der Ausgabe von Vertex AI Experiments war der letzte Durchlauf bei beiden Messwerten der erfolgreichste Durchlauf mit einer dropout_rate von 0,001, einem learning_rate bei 0,001 und der Gesamtzahl von epochs 20. Auf Grundlage dieses Tests würden diese Modellparameter letztendlich in der Produktion verwendet, da sie die beste Modellleistung erzielen.
Damit haben Sie das Lab abgeschlossen.
🎉 Glückwunsch! 🎉
Sie haben gelernt, wie Sie mit Vertex AI Folgendes tun können:
- Trainieren Sie ein benutzerdefiniertes Keras-Modell, um Spielerbewertungen vorherzusagen (z.B. Regression)
- Mit dem Kubeflow Pipelines SDK skalierbare ML-Pipelines erstellen
- Eine aus fünf Schritten bestehende Pipeline erstellen und ausführen, die Daten aus GCS aufnimmt, die Daten skaliert, das Modell trainiert, auswertet und das resultierende Modell wieder in GCS speichert
- Nutzen Sie Vertex ML Metadata, um Modellartefakte wie Modelle und Modellmesswerte zu speichern
- Mit Vertex AI Experiments die Ergebnisse verschiedener Pipelineausführungen vergleichen
Weitere Informationen zu den verschiedenen Teilen von Vertex finden Sie in der Dokumentation.
8. Bereinigen
Damit Ihnen keine Kosten in Rechnung gestellt werden, sollten Sie die in diesem Lab erstellten Ressourcen löschen.
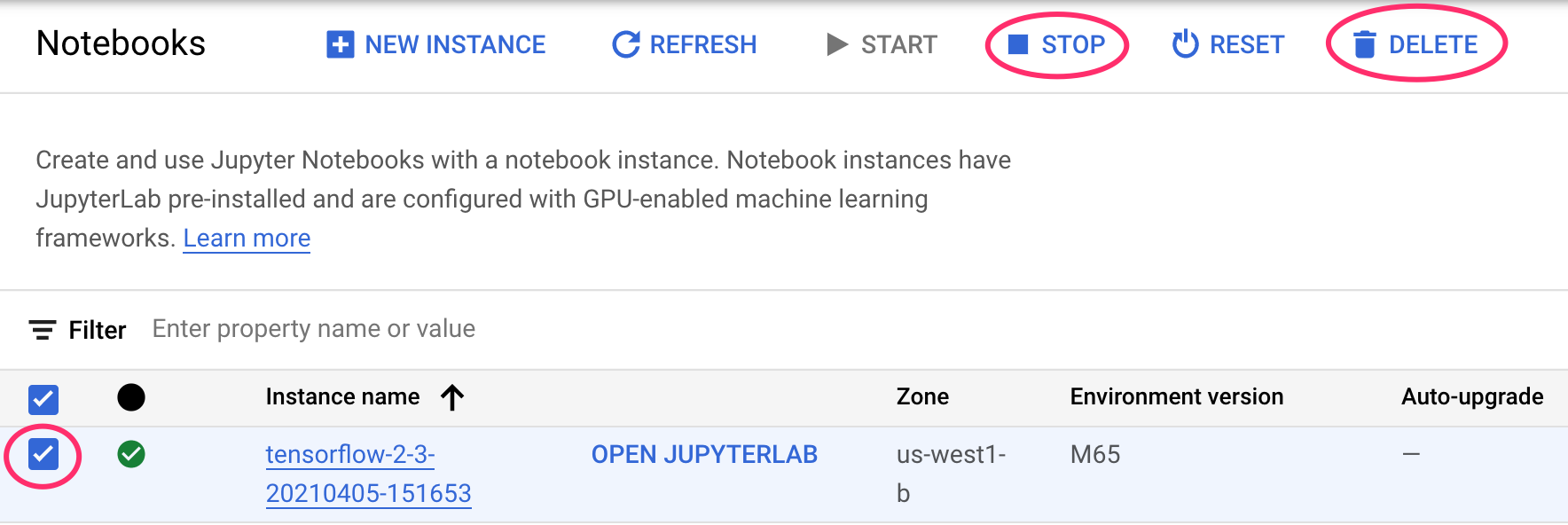
Schritt 1: Notebooks-Instanz beenden oder löschen
Wenn Sie das Notebook, das Sie in diesem Lab erstellt haben, weiter verwenden möchten, sollten Sie es deaktivieren, wenn Sie es nicht verwenden. Wählen Sie in der Notebooks-UI in der Cloud Console das Notebook und dann Beenden aus. Wenn Sie die Instanz vollständig löschen möchten, wählen Sie Löschen aus:
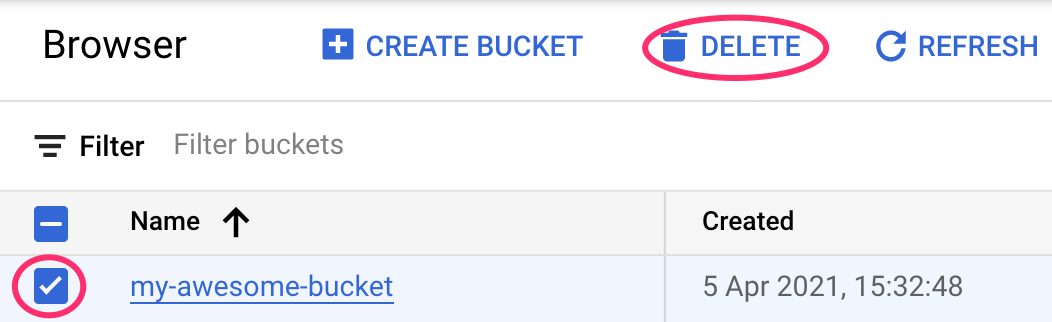
Schritt 2: Cloud Storage-Bucket löschen
Wenn Sie den Storage-Bucket löschen möchten, gehen Sie im Navigationsmenü der Cloud Console zu „Storage“, wählen Sie den Bucket aus und klicken Sie auf „Löschen“: