1. Présentation
Dans cet atelier, vous allez utiliser Vertex AI pour créer un pipeline qui entraîne un modèle Keras personnalisé dans TensorFlow. Nous utiliserons ensuite la nouvelle fonctionnalité disponible dans les tests Vertex AI pour suivre et comparer les exécutions de modèles afin d'identifier la combinaison d'hyperparamètres qui offre les meilleures performances.
Objectifs
Vous allez apprendre à effectuer les opérations suivantes :
- Entraîner un modèle Keras personnalisé pour prédire les notes des joueurs (par exemple, une régression)
- Utiliser le SDK Kubeflow Pipelines pour créer des pipelines de ML évolutifs
- Créer et exécuter un pipeline en cinq étapes qui ingère des données à partir de Cloud Storage, les fait évoluer, entraîne le modèle, l'évalue et enregistre le modèle ainsi obtenu dans Cloud Storage
- Exploiter Vertex ML Metadata pour enregistrer des artefacts de modèle tels que les modèles et les métriques du modèle
- Utiliser les tests Vertex AI pour comparer les résultats des différentes exécutions de pipeline
Le coût total d'exécution de cet atelier sur Google Cloud est d'environ 1 $.
2. Présentation de Vertex AI
Cet atelier utilise la toute dernière offre de produits d'IA de Google Cloud. Vertex AI simplifie l'expérience de développement en intégrant toutes les offres de ML de Google Cloud. Auparavant, les modèles entraînés avec AutoML et les modèles personnalisés étaient accessibles depuis des services distincts. La nouvelle offre regroupe ces deux types de modèles mais aussi d'autres nouveaux produits en une seule API. Vous pouvez également migrer des projets existants vers Vertex AI.
Vertex AI comprend de nombreux produits différents qui permettent de gérer les workflows de ML de bout en bout. Cet atelier se concentre sur les produits mis en évidence ci-dessous: Tests, Pipelines, ML Metadata (Métadonnées de ML) et Workbench.

3. Présentation du cas d'utilisation
Nous utiliserons un ensemble de données de football populaire provenant de la série de jeux vidéo FIFA d'EA Sports. Il comprend plus de 25 000 matchs de football et plus de 10 000 joueurs pour les saisons 2008-2016. Les données ont été prétraitées à l'avance pour que vous puissiez vous lancer plus facilement. Vous allez utiliser cet ensemble de données tout au long de l'atelier. Il se trouve désormais dans un bucket Cloud Storage public. Nous vous expliquerons plus en détail comment accéder à l'ensemble de données dans la suite de cet atelier de programmation. Notre objectif final est de prédire la note globale d'un joueur en fonction de diverses actions dans le jeu, comme les interceptions et les pénalités.
Pourquoi les tests Vertex AI sont-ils utiles pour la data science ?
La data science est expérimentale par nature ; on les appelle après tout des scientifiques. Les bons data scientists reposent sur des hypothèses et utilisent des essais et des erreurs pour tester différentes hypothèses en espérant que des itérations successives permettront d'obtenir un modèle plus performant.
Si les équipes de data science ont adopté l'expérimentation, elles ont souvent du mal à suivre leur travail et la "sauce secrète". découverts grâce à leurs expérimentations. Cela se produit pour plusieurs raisons:
- Le suivi des tâches d'entraînement peut devenir fastidieux, ce qui peut facilement vous faire perdre de vue ce qui fonctionne et ce qui ne fonctionne pas.
- Ce problème s'aggrave lorsque vous examinez une équipe de data scientists, car il est possible que tous les membres ne suivent pas les tests ou ne partagent pas leurs résultats avec d'autres.
- La capture de données prend du temps et la plupart des équipes utilisent des méthodes manuelles (par exemple, des feuilles ou des documents) qui donnent lieu à des informations incohérentes et incomplètes à partir desquelles tirer des leçons.
La fonctionnalité tl;dr::Vertex AI Experiments fait le travail à votre place pour vous aider à suivre et comparer plus facilement vos tests.
Pourquoi utiliser les tests Vertex AI pour les jeux vidéo ?
Les jeux vidéo ont toujours été un terrain d'expérimentation pour le machine learning. Les jeux génèrent non seulement des milliards d'événements en temps réel par jour, mais ils exploitent également toutes ces données en exploitant le ML et les expériences de ML pour améliorer les expériences dans le jeu, fidéliser les joueurs et évaluer les différents joueurs sur leur plate-forme. Nous avons donc pensé qu'un ensemble de données sur les jeux vidéo convenait parfaitement à notre exercice d'expérimentation global.
4. Configurer votre environnement
Pour suivre cet atelier de programmation, vous aurez besoin d'un projet Google Cloud Platform dans lequel la facturation est activée. Pour créer un projet, suivez ces instructions.
Étape 1 : Activez l'API Compute Engine
Accédez à Compute Engine et cliquez sur Activer si ce n'est pas déjà fait.
Étape 2: Activez l'API Vertex AI
Accédez à la section Vertex AI de Cloud Console, puis cliquez sur Activer l'API Vertex AI.
Étape 3: Créez une instance Vertex AI Workbench
Dans la section Vertex AI de Cloud Console, cliquez sur Workbench :
Activez l'API Notebooks si ce n'est pas déjà fait.
Une fois l'API activée, cliquez sur NOTEBOOKS GÉRÉS :

Sélectionnez ensuite NOUVEAU NOTEBOOK.
Attribuez un nom à votre notebook, puis cliquez sur Paramètres avancés.

Sous "Paramètres avancés", activez l'arrêt en cas d'inactivité et définissez le nombre de minutes sur 60. Cela entraîne l'arrêt automatique du notebook lorsqu'il n'est pas utilisé. Vous ne payez donc pas de frais inutiles.

Étape 4 : Ouvrez votre notebook
Une fois l'instance créée, sélectionnez Ouvrir JupyterLab.

Étape 5 : Authentifiez-vous (première fois uniquement)
La première fois que vous utilisez une nouvelle instance, vous êtes invité à vous authentifier. Pour ce faire, suivez les étapes indiquées dans l'interface utilisateur.
Étape 6: Sélectionnez le noyau approprié
Managed-notebooks fournit plusieurs noyaux dans une seule UI. Sélectionnez le kernel pour Tensorflow 2 (local).

5. Premières étapes de configuration dans votre notebook
Vous devrez effectuer une série d'étapes supplémentaires pour configurer votre environnement dans votre notebook avant de créer votre pipeline. Ces étapes incluent l'installation de packages supplémentaires, la définition de variables, la création de votre bucket Cloud Storage, la copie de l'ensemble de données de jeux vidéo à partir d'un bucket de stockage public, l'importation de bibliothèques et la définition de constantes supplémentaires.
Étape 1: Installez les packages supplémentaires
Nous devrons installer des dépendances de packages supplémentaires qui ne sont pas actuellement installées dans votre environnement de notebook. Le SDK KFP en est un exemple.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
Vous devrez ensuite redémarrer le noyau du notebook afin de pouvoir utiliser les packages téléchargés dans votre notebook.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Étape 2: Définir les variables
Nous voulons définir notre PROJECT_ID. Si vous ne connaissez pas votre Project_ID, vous pouvez peut-être obtenir votre PROJECT_ID à l'aide de gcloud.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Sinon, définissez votre PROJECT_ID ici.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
Nous allons également définir la variable REGION, qui sera utilisée dans le reste de ce notebook. Vous trouverez ci-dessous les régions compatibles avec Vertex AI. Nous vous recommandons de choisir la région la plus proche de vous.
- Amériques: us-central1
- Europe: europe-west4
- Asie-Pacifique: asia-east1
Veuillez ne pas utiliser de bucket multirégional pour l'entraînement avec Vertex AI. Toutes les régions ne sont pas compatibles avec les services Vertex AI. Apprenez-en plus sur les régions Vertex AI.
#set your region
REGION = "us-central1" # @param {type: "string"}
Enfin, nous allons définir une variable TIMESTAMP. Cette variable permet d'éviter les conflits de noms entre les utilisateurs sur les ressources créées. Vous devez créer un TIMESTAMP pour chaque session d'instance et l'ajouter au nom des ressources que vous créez dans ce tutoriel.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Étape 3: Créez un bucket Cloud Storage
Vous devez spécifier et exploiter un bucket de préproduction Cloud Storage. Le bucket de préproduction contient toutes les données associées à votre ensemble de données et aux ressources de votre modèle d'une session à l'autre.
Définissez le nom de votre bucket Cloud Storage ci-dessous. Les noms de buckets doivent être uniques au niveau mondial sur tous les projets Google Cloud, y compris ceux qui ne font pas partie de votre organisation.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
Si votre bucket N'existe PAS déjà, vous pouvez exécuter la cellule suivante pour créer votre bucket Cloud Storage.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Vous pouvez ensuite vérifier l'accès à votre bucket Cloud Storage en exécutant la cellule suivante.
#verify access
! gsutil ls -al $BUCKET_URI
Étape 4: Copiez l'ensemble de données "Gaming"
Comme indiqué précédemment, vous allez utiliser un ensemble de données de jeu populaire provenant du jeu vidéo à succès FIFA d'EA Sports. Nous avons effectué le prétraitement pour vous. Il vous suffit donc de copier l'ensemble de données à partir du bucket de stockage public et de le déplacer vers celui que vous avez créé.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
Étape 5: Importer des bibliothèques et définir des constantes supplémentaires
Nous allons maintenant importer nos bibliothèques pour Vertex AI, KFP, etc.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
Nous allons également définir des constantes supplémentaires auxquelles nous ferons référence dans le reste du notebook, comme le ou les chemins d'accès aux fichiers de nos données d'entraînement.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. Créons notre pipeline
Nous pouvons maintenant commencer à exploiter Vertex AI pour créer notre pipeline d'entraînement. Nous allons initialiser le SDK Vertex AI, configurer notre job d'entraînement en tant que composant de pipeline, créer notre pipeline, envoyer nos exécutions de pipeline et exploiter le SDK Vertex AI pour afficher les tests et surveiller leur état.
Étape 1: Initialiser le SDK Vertex AI
Initialisez le SDK Vertex AI en définissant votre PROJECT_ID et votre BUCKET_URI.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
Étape 2: Configurer le job d'entraînement en tant que composant de pipeline
Avant de commencer à exécuter nos tests, nous devons spécifier notre job d'entraînement en le définissant en tant que composant du pipeline. Notre pipeline intégrera des données d'entraînement et des hyperparamètres (par exemple, DROPOUT_RATE, LEARNING_RATE ou EPOCHS) en tant qu'entrées et métriques du modèle de sortie (par exemple, EAM et RMSE) et un artefact de modèle.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
Étape 3: Construire notre pipeline
Nous allons maintenant configurer notre workflow à l'aide de Domain Specific Language (DSL) disponible dans KFP et compiler notre pipeline dans un fichier JSON.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
Étape 4 : Envoyez l'exécution de votre pipeline
Le plus dur est de configurer le composant et de définir le pipeline. Nous sommes prêts à envoyer différentes exécutions du pipeline que nous avons spécifiées ci-dessus. Pour ce faire, nous devons définir les valeurs de nos différents hyperparamètres comme suit:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
Une fois les hyperparamètres définis, nous pouvons utiliser un for loop pour alimenter les différentes exécutions du pipeline:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
Étape 5: Utiliser le SDK Vertex AI pour afficher les tests
Le SDK Vertex AI vous permet de surveiller l'état des exécutions du pipeline. Vous pouvez également l'utiliser pour renvoyer les paramètres et les métriques des exécutions de pipeline dans le test Vertex AI. Utilisez le code suivant pour afficher les paramètres associés à vos exécutions et leur état actuel.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
Vous pouvez utiliser le code ci-dessous pour obtenir des informations sur l'état d'exécution de votre pipeline.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
Vous pouvez également appeler des jobs de pipeline spécifiques à l'aide de run_name.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
Enfin, vous pouvez actualiser l'état de vos exécutions à des intervalles définis (par exemple, toutes les 60 secondes) pour voir les états passer de RUNNING à FAILED ou COMPLETE.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. Identifier l'exécution la plus performante
Parfait, nous avons maintenant les résultats de nos exécutions de pipeline. Vous vous demandez peut-être ce que vous pouvez apprendre des résultats. Le résultat de vos tests doit contenir cinq lignes, une pour chaque exécution du pipeline. L'URL doit ressembler à ceci:

L'EAM et la RMSE sont toutes deux des mesures de l'erreur de prédiction moyenne du modèle. Il est donc souhaitable d'obtenir une valeur inférieure pour les deux métriques dans la plupart des cas. D'après la sortie des tests Vertex AI, l'exécution la plus réussie pour les deux métriques est l'exécution finale, avec un dropout_rate de 0,001, un learning_rate de 0,001 et un nombre total de epochs de 20. Sur la base de ce test, ces paramètres de modèle seraient finalement utilisés en production, car ils offrent les meilleures performances du modèle.
Vous avez maintenant terminé l'atelier.
🎉 Félicitations ! 🎉
Vous savez désormais utiliser Vertex AI pour :
- Entraîner un modèle Keras personnalisé pour prédire les notes des joueurs (par exemple, une régression)
- Utiliser le SDK Kubeflow Pipelines pour créer des pipelines de ML évolutifs
- Créer et exécuter un pipeline en cinq étapes qui ingère les données de GCS, les met à l'échelle, entraîne le modèle, l'évalue et enregistre le modèle ainsi obtenu dans GCS
- Exploiter Vertex ML Metadata pour enregistrer des artefacts de modèle tels que les modèles et les métriques du modèle
- Utiliser les tests Vertex AI pour comparer les résultats des différentes exécutions de pipeline
Pour en savoir plus sur les différents composants de Vertex, consultez la documentation.
8. Nettoyage
Pour ne pas être facturé, nous vous recommandons de supprimer les ressources créées tout au long de cet atelier.
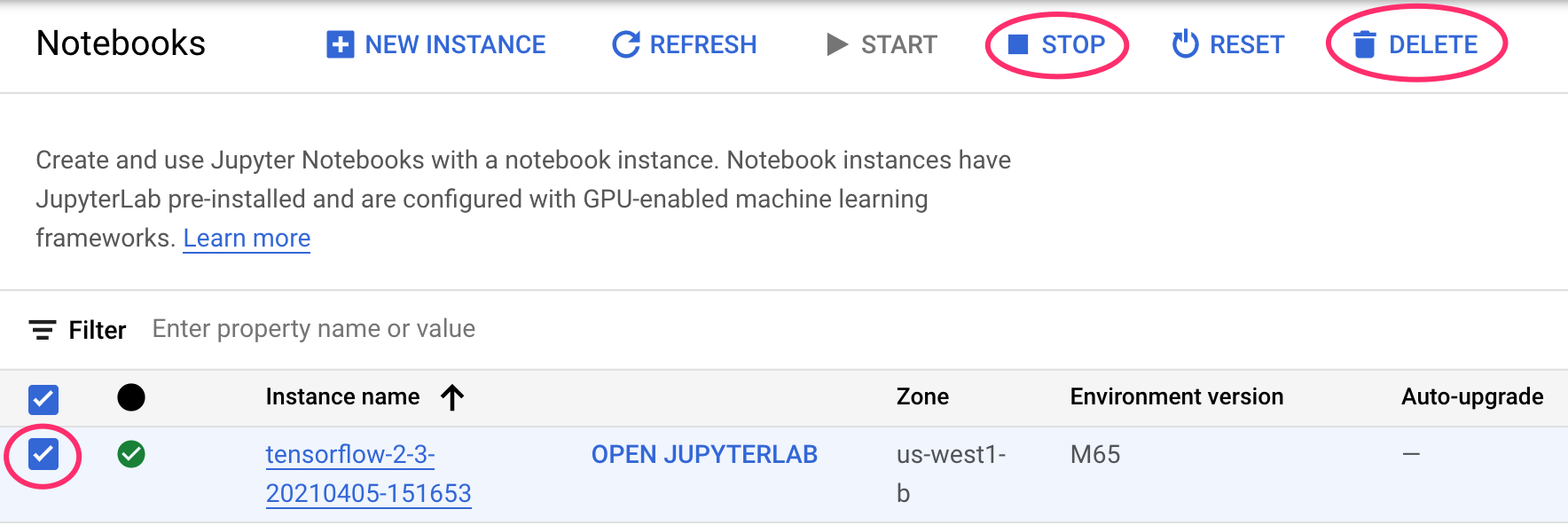
Étape 1 : Arrêtez ou supprimez votre instance de Notebooks
Si vous souhaitez continuer à utiliser le notebook que vous avez créé dans cet atelier, nous vous recommandons de le désactiver quand vous ne vous en servez pas. À partir de l'interface utilisateur de Notebooks dans la console Cloud, sélectionnez le notebook et cliquez sur Arrêter. Si vous souhaitez supprimer entièrement l'instance, sélectionnez Supprimer:
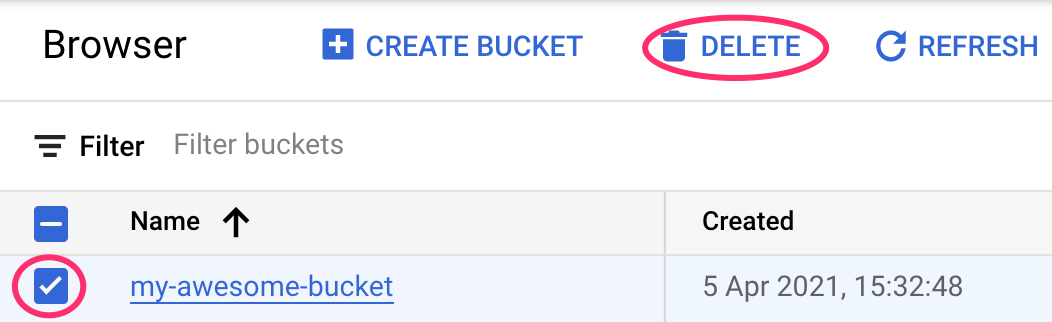
Étape 2: Supprimez votre bucket Cloud Storage
Pour supprimer le bucket de stockage, utilisez le menu de navigation de la console Cloud pour accéder à Stockage, sélectionnez votre bucket puis cliquez sur "Supprimer" :