
מידע על Codelab זה
1. סקירה כללית
בשיעור ה-Lab הזה תלמדו להשתמש ב-Vertex AI כדי ליצור צינור עיבוד נתונים לאימון מודל Keras בהתאמה אישית ב-TensorFlow. אחר כך נשתמש בפונקציונליות החדשה שזמינה בניסויים של Vertex AI כדי לעקוב אחרי הפעלות של מודלים ולהשוות ביניהן, במטרה לזהות איזה שילוב של היפר-פרמטרים מניב את הביצועים הטובים ביותר.
מה תלמדו
נסביר לכם איך:
- לאמן מודל Keras בהתאמה אישית כדי לחזות את דירוגי השחקנים (למשל, רגרסיה)
- שימוש ב-Kubeflow Pipelines SDK ליצירת צינורות עיבוד נתונים של למידת מכונה שניתן להתאים לעומס
- יצירה והפעלה של צינור עיבוד נתונים בן 5 שלבים שמטמיע נתונים מ-Cloud Storage, מדרג את הנתונים, מאמן את המודל, מעריך אותם ושומר את המודל שנוצר בחזרה ב-Cloud Storage
- משתמשים במטא-נתונים של Vertex ML כדי לשמור ארטיפקטים של מודל כמו מודלים ומדדי מודל
- להשתמש בניסויים ב-Vertex AI כדי להשוות תוצאות של הפעלות שונות של צינורות עיבוד נתונים
העלות הכוללת של הפעלת שיעור ה-Lab הזה ב-Google Cloud היא כ-$1.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את הצעות למידת המכונה ב-Google Cloud ליצירת חוויית פיתוח חלקה. בעבר, ניתן היה לגשת למודלים שעברו אימון באמצעות AutoML ומודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את כל ממשקי ה-API האלה בממשק API אחד, לצד מוצרים חדשים אחרים. תוכלו גם להעביר פרויקטים קיימים ל-Vertex AI.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. שיעור ה-Lab הזה יתמקד במוצרים המודגשים הבאים: ניסויים, צינורות עיבוד נתונים, מטא-נתונים של למידת מכונה וסביבת עבודה

3. סקירה כללית של תרחיש לדוגמה
נשתמש במערך נתונים פופולרי בנושא כדורגל מ-EA Sports סדרת משחקי הווידאו FIFA הוא כולל יותר מ-25,000 משחקי כדורגל ומעל 10,000 שחקנים בעונות 2008-2016. הנתונים עברו עיבוד מראש מראש כדי שיהיה לכם קל יותר להתחיל לעבוד. מערך הנתונים הזה ישמש אתכם במהלך שיעור ה-Lab, שעכשיו נמצא בקטגוריה ציבורית של Cloud Storage. אנחנו נספק פרטים נוספים בהמשך ב-Codelab על האופן שבו אפשר לגשת למערך הנתונים. המטרה הסופית שלנו היא לחזות את הדירוג הכולל של השחקן על סמך פעולות שונות במשחק, כמו חטיפות כדור ובעיטות עונשין.
למה Vertex AI Experiments שימושי למדעי הנתונים?
מדע הנתונים הוא ניסיוני בטבעו, אחרי הכול, הם נקראים מדענים. מדעני נתונים טובים מבוססים על השערות, ומשתמשים בניסוי וטעמה כדי לבחון השערות שונות, בתקווה שחזרות עוקבות יובילו למודל עם ביצועים טובים יותר.
צוותים במדעי הנתונים אימצו ניסויים, אבל לעיתים קרובות הם מתקשים לעקוב אחרי העבודה שלהם ואחר 'הרוטב הסודי'. שמתגלה במסגרת מאמצי הניסוי שלהם. יכולות להיות לכך כמה סיבות:
- מעקב אחרי משימות אימון יכול להיות מסורבל, ולכן קל לאבד את הקשר בין מה שעובד לבין מה שלא עובד.
- הבעיה הזו מורכבת כשבוחנים צוות במדעי הנתונים, כי לא כל החברים בו עוקבים אחרי ניסויים או אפילו משתפים את התוצאות שלהם עם אחרים.
- תהליך תיעוד הנתונים אורך זמן רב, ורוב הצוותים משתמשים בשיטות ידניות (למשל, גיליונות או מסמכים) שמניבות מידע לא עקבי ולא מלא שאפשר ללמוד ממנו
tl;dr: הניסויים של Vertex AI עושים את העבודה בשבילכם ועוזרים לכם לעקוב בקלות אחרי הניסויים ולהשוות ביניהם
למה כדאי להשתמש בניסויים של Vertex AI לגיימינג?
בעבר, גיימינג שימש כמגרש משחקים ללמידת מכונה ולניסויים בלמידת מכונה. לא רק שמשחקים מייצרים מיליארדי אירועים בזמן אמת מדי יום, אלא גם משתמשים בכל הנתונים האלה על ידי מינוף ניסויים בלמידת מכונה ובלמידת מכונה כדי לשפר את חוויות המשחק, לשמר את השחקנים ולהעריך את השחקנים השונים בפלטפורמה שלהם. לכן, חשבנו שמערך נתונים של משחקים יתאים היטב לתרגול הניסויים הכולל שלנו.
4. הגדרת הסביבה
כדי להריץ את סדנת הקוד הזו, צריך פרויקט ב-Google Cloud Platform שבו החיוב מופעל. כדי ליצור פרויקט, יש לפעול לפי ההוראות האלה.
שלב 1: מפעילים את ממשק ה-API של Compute Engine
עוברים אל Compute Engine ובוחרים באפשרות Enable (הפעלה) אם היא לא מופעלת עדיין.
שלב 2: מפעילים את Vertex AI API
עוברים אל הקטע Vertex AI במסוף Cloud ולוחצים על Enable Vertex AI API.
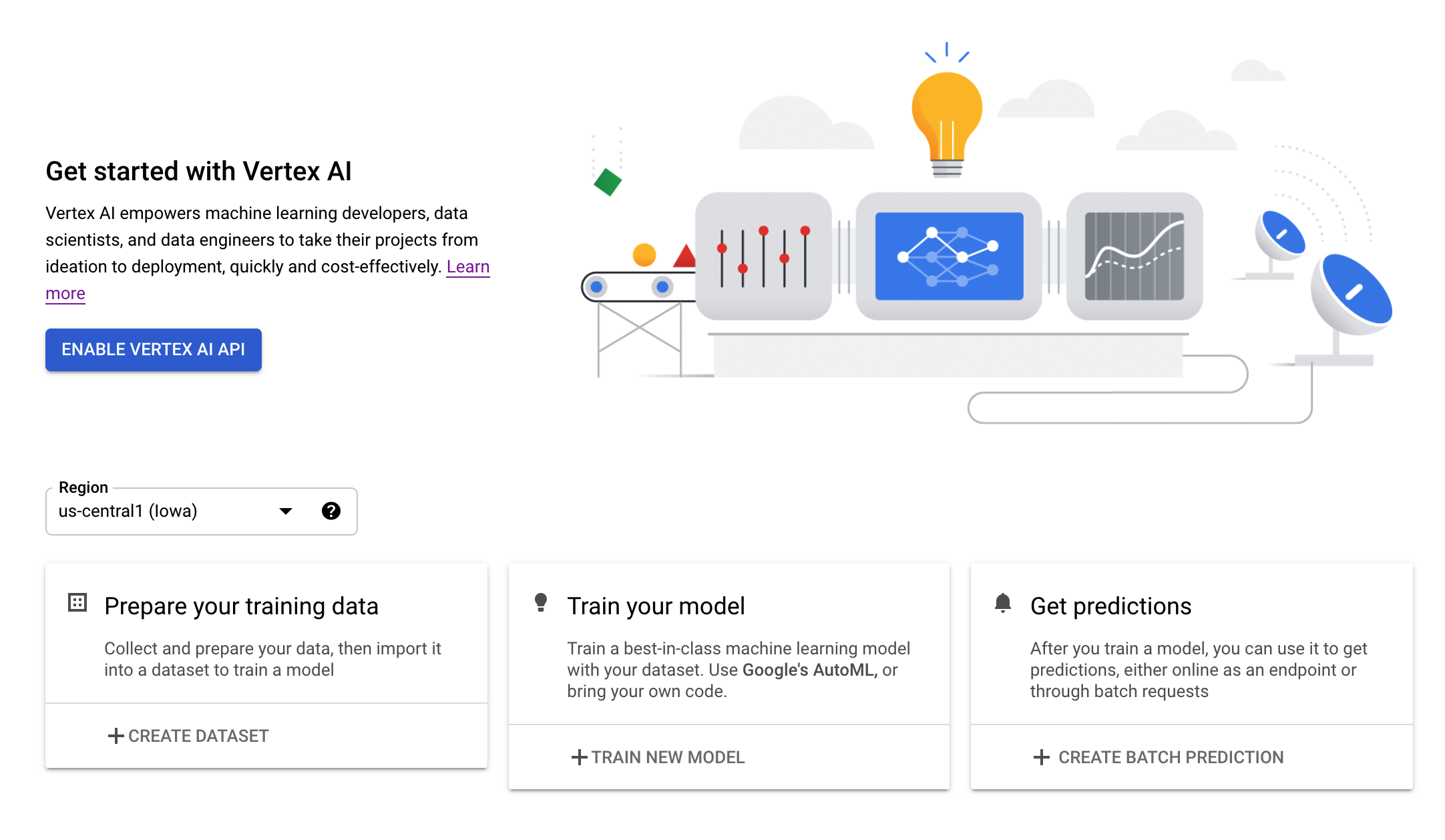
שלב 3: יצירת מכונה של Vertex AI Workbench
בקטע Vertex AI במסוף Cloud, לוחצים על Workbench:
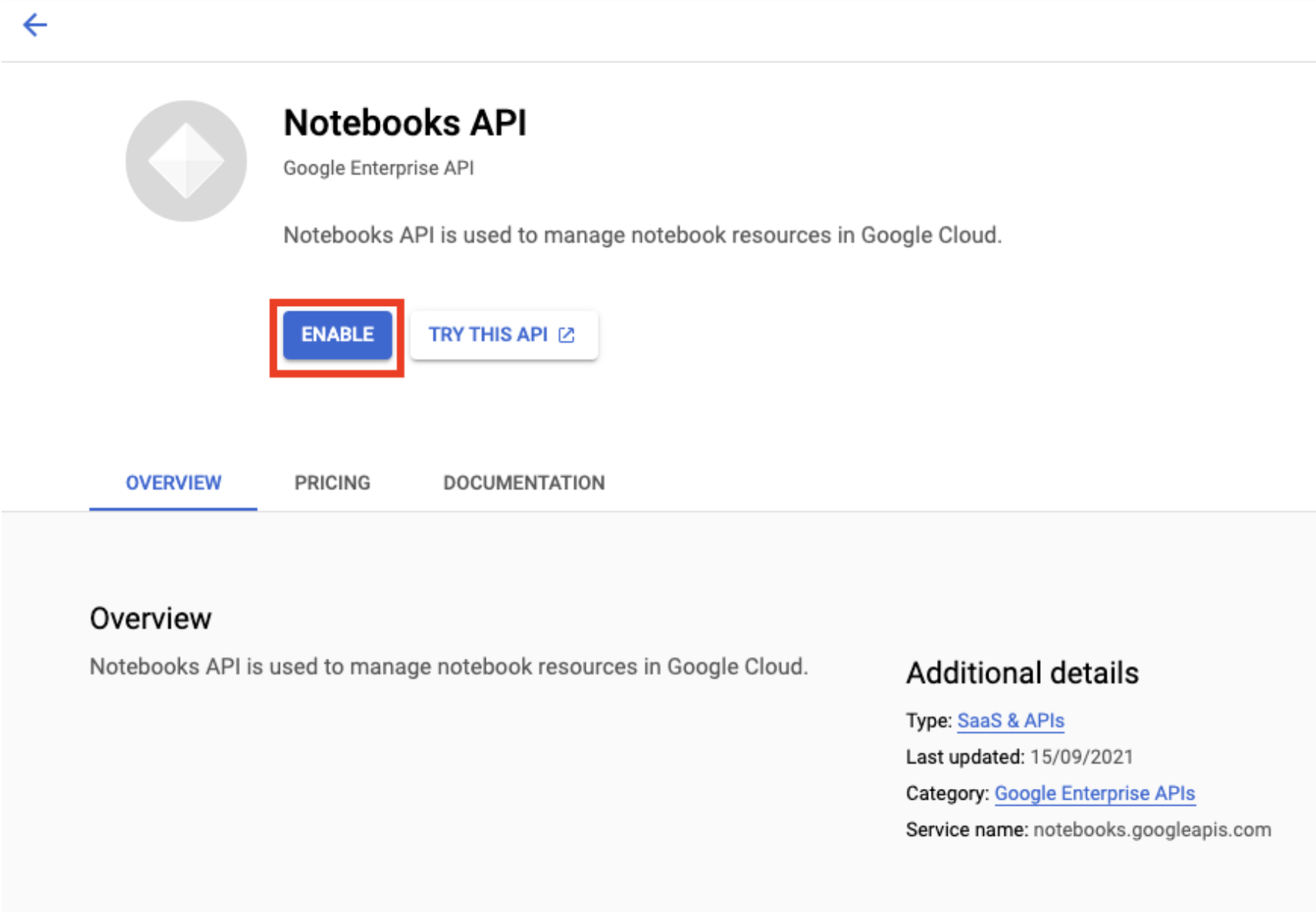
מפעילים את Notebooks API, אם הוא לא פועל.
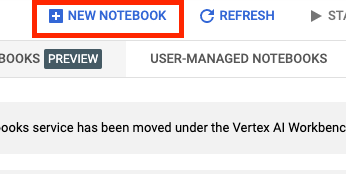
לאחר ההפעלה, לוחצים על פנקסי רשימות מנוהלים:

לאחר מכן בוחרים פנקס רשימות חדש.
נותנים שם ל-notebook ולוחצים על הגדרות מתקדמות.

בקטע 'הגדרות מתקדמות', מפעילים כיבוי ללא פעילות ומגדירים את מספר הדקות ל-60. כלומר, המחשב יכבה באופן אוטומטי כשהוא לא בשימוש כדי שלא תצברו עלויות מיותרות.

שלב 4: פותחים את ה-notebook
אחרי שהמכונה נוצרה, בוחרים באפשרות Open JupyterLab.

שלב 5: אימות (בפעם הראשונה בלבד)
בפעם הראשונה שתשתמשו במכונה חדשה, תתבקשו לבצע אימות. כדי לעשות זאת, פועלים לפי השלבים שבממשק המשתמש.
שלב 6: בוחרים את הליבה המתאימה
notebooks מנוהלים מספקים כמה ליבות בממשק משתמש אחד. בוחרים את הליבה של Tensorflow 2 (מקומי).

5. שלבי הגדרה ראשוניים ב-notebook
תצטרכו לבצע סדרת פעולות נוספות כדי להגדיר את הסביבה ב-notebook לפני פיתוח צינור עיבוד הנתונים. השלבים האלה כוללים: התקנת חבילות נוספות, הגדרת משתנים, יצירת קטגוריה של אחסון בענן, העתקת מערך הנתונים של המשחקים מקטגוריית אחסון ציבורית, וייבוא ספריות והגדרת קבועים נוספים.
שלב 1: התקנת חבילות נוספות
נצטרך להתקין יחסי תלות נוספים של חבילות שלא מותקנות כרגע בסביבת היומן. לדוגמה, ערכת ה-SDK של KFP.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
לאחר מכן עליך להפעיל מחדש את הליבה של ה-notebook כדי להשתמש בחבילות שהורדת מה-notebook.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
שלב 2: הגדרת משתנים
אנחנו רוצים להגדיר את PROJECT_ID. אם לא ידוע לך מהו Project_ID, ייתכן שתהיה לך אפשרות לקבל את ה-PROJECT_ID באמצעות gcloud.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
אחרת, צריך להגדיר את PROJECT_ID כאן.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
חשוב גם להגדיר את המשתנה REGION, שישמש לשארית ה-notebook הזה. בהמשך מפורטים האזורים הנתמכים ב-Vertex AI. מומלץ לבחור את האזור הקרוב ביותר אליכם.
- יבשת אמריקה: us-central1
- אירופה: europe-west4
- אסיה והאוקיינוס השקט: asia-east1
אסור להשתמש בקטגוריה במספר אזורים לאימון באמצעות Vertex AI. לא בכל האזורים יש תמיכה בכל שירותי Vertex AI. מידע נוסף על האזורים של Vertex AI
#set your region
REGION = "us-central1" # @param {type: "string"}
בשלב האחרון נגדיר משתנה TIMESTAMP. המשתנים האלה משמשים כדי למנוע התנגשויות בשמות בין משתמשים במשאבים שנוצרים. יוצרים משתנה TIMESTAMP לכל סשן של מכונה ומצרפים אותו לשם המשאבים שיצרתם במדריך הזה.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
שלב 3: יצירת קטגוריה ב-Cloud Storage
תצטרכו לציין קטגוריית Staging של Cloud Storage ולהשתמש בה. קטגוריית ה-Staging היא המקום שבו כל הנתונים שמשויכים למשאבים של מערך הנתונים והמודל נשמרים בכל הסשנים.
מגדירים את שם הקטגוריה של Cloud Storage למטה. שמות הקטגוריות חייבים להיות ייחודיים בכל הפרויקטים ב-Google Cloud, כולל פרויקטים מחוץ לארגון.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
אם הקטגוריה שלכם עדיין לא קיימת, תוכלו להריץ את התא הבא כדי ליצור את הקטגוריה של Cloud Storage.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
עכשיו אפשר לאמת את הגישה לקטגוריה של Cloud Storage על ידי הרצת התא הבא.
#verify access
! gsutil ls -al $BUCKET_URI
שלב 4: מעתיקים את מערך הנתונים של המשחקים שלנו
כמו שציינו קודם, אתם תשתמשו במערך נתונים פופולרי של גיימינג ממשחקי הווידאו של EA Sports, FIFA. סיימנו את תהליך העיבוד מראש, לכן צריך רק להעתיק את מערך הנתונים מקטגוריית האחסון הציבורי ולהעביר אותו לזה שיצרתם.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
שלב 5: מייבאים ספריות ומגדירים קבועים נוספים
בשלב הבא נרצה לייבא את הספריות שלנו עבור Vertex AI, KFP וכו'.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
נגדיר גם קבועים נוספים שנתייחס אליהם בהמשך המחברות, כמו נתיבי הקבצים לנתוני האימון.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. קדימה, נבנה את צינור עיבוד הנתונים
עכשיו הכיף יכול להתחיל ואנחנו יכולים להתחיל להשתמש ב-Vertex AI כדי לפתח את צינור ההכשרה שלנו. אנחנו נפעיל את Vertex AI SDK, נגדיר את משימת האימון כרכיב בצינור עיבוד נתונים, נפתח את צינור עיבוד הנתונים, נשלח את תהליכי צינור עיבוד הנתונים שלנו ונשתמש ב-Vertex AI SDK כדי לצפות בניסויים ולעקוב אחרי הסטטוס שלהם.
שלב 1: איך מפעילים את Vertex AI SDK
מפעילים את Vertex AI SDK ומגדירים את PROJECT_ID והBUCKET_URI.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
שלב 2: הגדרה של משימת האימון שלנו כרכיב בצינור עיבוד נתונים
כדי להתחיל להריץ את הניסויים שלנו, נצטרך לציין את משימת האימון שלנו על ידי הגדרתה כרכיב בצינור עיבוד נתונים. צינור עיבוד הנתונים שלנו יטפל בנתוני אימון ובהיפר-פרמטרים (למשל, DROPOUT_RATE, LEARNING_RATE, EPOCHS) כקלט וכמדדים של מודל הפלט (למשל, MAE ו-RMSE) וגם ארטיפקט של המודל.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
שלב 3: פיתוח צינור עיבוד הנתונים
עכשיו נגדיר את תהליך העבודה באמצעות Domain Specific Language (DSL) שזמין ב-KFP ונרכיב את צינור עיבוד הנתונים שלנו לקובץ JSON.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
שלב 4: שליחת הפעלות צינור עיבוד נתונים
העבודה הקשה היא הגדרת הרכיב שלנו והגדרת צינור עיבוד הנתונים שלנו. אנחנו מוכנים לשלוח הפעלות שונות של צינור עיבוד הנתונים שציינו למעלה. לשם כך, עלינו להגדיר את הערכים של ההיפר-פרמטרים השונים שלנו באופן הבא:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
אחרי שמגדירים את הפרמטרים ההיפר-מרחביים, אפשר להשתמש ב-for loop כדי להזין בהצלחה את ההרצות השונות של צינור עיבוד הנתונים:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
שלב 5: משתמשים ב-Vertex AI SDK כדי לצפות בניסויים
Vertex AI SDK מאפשר לכם לעקוב אחרי הסטטוס של הפעלות של צינור עיבוד נתונים. אפשר להשתמש בו גם כדי להחזיר פרמטרים ומדדים של הרצת צינורות עיבוד נתונים בניסוי של Vertex AI. תוכלו להשתמש בקוד הבא כדי לראות את הפרמטרים שמשויכים להפעלות שלכם ואת המצב הנוכחי שלהן.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
אפשר להשתמש בקוד הבא כדי לקבל עדכונים לגבי הסטטוס של צינורות עיבוד הנתונים שלכם.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
אפשר גם לקרוא למשימות ספציפיות בצינור עיבוד הנתונים באמצעות run_name.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
לבסוף, אפשר לרענן את מצב ההפעלות במרווחי זמן קבועים (למשל כל 60 שניות) כדי לראות את המצבים משתנים מ-RUNNING ל-FAILED או ל-COMPLETE.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. זיהוי ההפעלה עם הביצועים הטובים ביותר
נהדר, עכשיו יש לנו את התוצאות של הרצת צינורות עיבוד הנתונים. ייתכן ששאלתם: מה אפשר ללמוד מהתוצאות? הפלט מהניסויים צריך להכיל חמש שורות, אחת לכל הפעלה של צינור עיבוד הנתונים. זה ייראה בערך כך:

גם MAE וגם RMSE הם מדדים של השגיאה הממוצעת בחיזוי המודל, ולכן ברוב המקרים רצוי להקצות ערך נמוך יותר עבור שני המדדים. על סמך הפלט מהניסויים של Vertex AI אנחנו יכולים לראות שהריצה המוצלחת ביותר בשני המדדים הייתה ההפעלה הסופית עם dropout_rate מתוך 0.001, אם learning_rate אם 0.001 והמספר הכולל של epochs הוא 20. על סמך הניסוי הזה, הפרמטרים האלה של המודל ישמשו בסופו של דבר בסביבת הייצור, כדי להניב את ביצועי המודל הטובים ביותר.
זהו, סיימתם את שיעור ה-Lab!
🎉 כל הכבוד! 🎉
למדתם איך להשתמש ב-Vertex AI כדי:
- לאמן מודל Keras בהתאמה אישית כדי לחזות את דירוגי השחקנים (למשל, רגרסיה)
- שימוש ב-Kubeflow Pipelines SDK כדי לפתח צינורות עיבוד נתונים ניתנים להתאמה של למידת מכונה
- יצירה והפעלה של צינור עיבוד נתונים בן 5 שלבים שמטמיע נתונים מ-GCS, מדרג את הנתונים, מאמן את המודל, מעריך אותו ושומר את המודל שנוצר בחזרה ב-GCS
- איך משתמשים במטא-נתונים של Vertex ML כדי לשמור ארטיפקטים של מודל כמו מודלים ומדדי מודל
- להשתמש בניסויים ב-Vertex AI כדי להשוות תוצאות של הפעלות שונות של צינורות עיבוד נתונים
כדי לקבל מידע נוסף על החלקים השונים ב-Vertex, אתם יכולים לעיין במסמכי העזרה.
8. הסרת המשאבים
כדי שלא תחויבו, מומלץ למחוק את המשאבים שנוצרו בשיעור ה-Lab הזה.
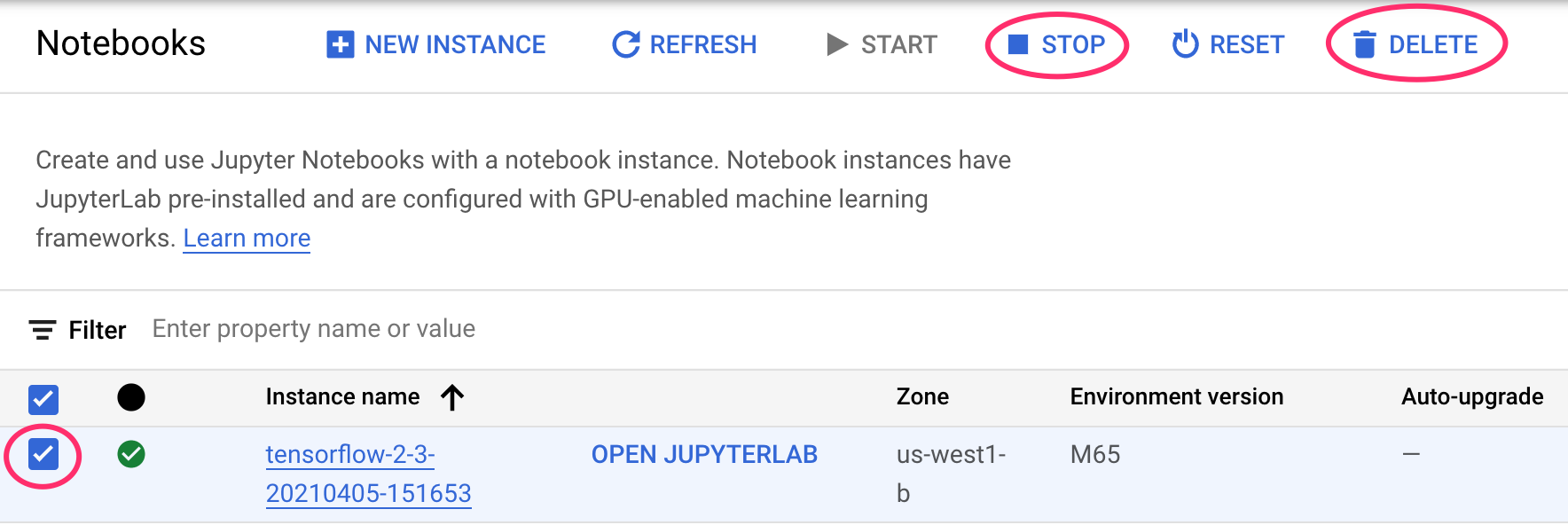
שלב 1: מפסיקים או מוחקים את המכונה של Notebooks
אם אתם רוצים להמשיך להשתמש ב-notebook שיצרתם בשיעור ה-Lab הזה, מומלץ להשבית אותו כשהוא לא בשימוש. בממשק המשתמש של Notebooks במסוף Cloud, בוחרים את המחברות ואז בוחרים באפשרות Stop. כדי למחוק את המכונה לגמרי, בוחרים באפשרות מחיקה:
שלב 2: מחיקת הקטגוריה של Cloud Storage
כדי למחוק את קטגוריית האחסון, באמצעות תפריט הניווט במסוף Cloud, עוברים אל Storage (אחסון), בוחרים את הקטגוריה ולוחצים על סמל המחיקה:
