एक्सपेरिमेंट का ज़्यादा से ज़्यादा फ़ायदा पाएं: Vertex AI की मदद से मशीन लर्निंग के एक्सपेरिमेंट मैनेज करें
इस कोडलैब (कोड बनाना सीखने के लिए ट्यूटोरियल) के बारे में जानकारी
1. खास जानकारी
इस लैब में, आपको Vertex AI का इस्तेमाल करके ऐसी पाइपलाइन बनानी होगी जो TensorFlow में पसंद के मुताबिक Keras मॉडल को ट्रेनिंग देती है. इसके बाद, हम Vertex AI एक्सपेरिमेंट में उपलब्ध नई सुविधा का इस्तेमाल करके, मॉडल के चलने को ट्रैक और तुलना करेंगे. इससे, यह पता लगाया जा सकेगा कि हाइपरपैरामीटर के किस कॉम्बिनेशन से सबसे अच्छी परफ़ॉर्मेंस मिलती है.
आपको ये सब सीखने को मिलेगा
आपको, इनके बारे में जानकारी मिलेगी:
- खिलाड़ी की रेटिंग का अनुमान लगाने के लिए, पसंद के मुताबिक बनाए गए Keras मॉडल को ट्रेनिंग दें. जैसे, रिग्रेशन
- स्केलेबल एमएल पाइपलाइन बनाने के लिए, Kubeflow Pipelines SDK टूल का इस्तेमाल करना
- पांच चरणों की एक ऐसी पाइपलाइन बनाएं और चलाएं जो Cloud Storage से डेटा डालने, डेटा को स्केल करने, मॉडल को ट्रेनिंग देने, उसका आकलन करने, और इस मॉडल को फिर से Cloud Storage में सेव करने के लिए करती है
- मॉडल और मॉडल मेट्रिक जैसे मॉडल आर्टफ़ैक्ट सेव करने के लिए, Vertex ML मेटाडेटा का इस्तेमाल करें
- Vertex AI Experiments का इस्तेमाल करके, अलग-अलग पाइपलाइन के नतीजों की तुलना करें
Google Cloud पर इस लैब को चलाने की कुल लागत करीब $1 है.
2. Vertex AI के बारे में जानकारी
यह लैब, Google Cloud पर उपलब्ध एआई (AI) प्रॉडक्ट के सबसे नए वर्शन का इस्तेमाल करती है. Vertex AI, Google Cloud के सभी मशीन लर्निंग प्लैटफ़ॉर्म को आसानी से डेवलप करने के लिए इंटिग्रेट करता है. पहले, AutoML और कस्टम मॉडल की मदद से ट्रेन किए गए मॉडल अलग-अलग सेवाओं से ऐक्सेस किए जा सकते थे. नई सुविधा, दोनों को एक ही एपीआई में जोड़ती है. साथ ही, इसमें अन्य नए प्रॉडक्ट भी शामिल हैं. आपके पास मौजूदा प्रोजेक्ट को Vertex AI पर माइग्रेट करने का विकल्प भी है.
Vertex AI में कई तरह के प्रॉडक्ट शामिल हैं, जो मशीन लर्निंग के वर्कफ़्लो को मैनेज करने में मदद करते हैं. यह लैब, यहां हाइलाइट किए गए प्रॉडक्ट पर फ़ोकस करेगी: एक्सपेरिमेंट, पाइपलाइन, एमएल मेटाडेटा, और वर्कबेंच

3. इस्तेमाल के उदाहरण की खास जानकारी
हम EA Sports' से लिए गए, फ़ुटबॉल के लोकप्रिय डेटासेट का इस्तेमाल करेंगे FIFA वीडियो गेम सीरीज़. इसमें 2008-2016 के सीज़न के लिए 25,000 से ज़्यादा फ़ुटबॉल मैच और 10,000 से ज़्यादा खिलाड़ी शामिल हैं. डेटा को पहले से प्रोसेस कर लिया जाता है, ताकि डेटा को आसानी से मैनेज किया जा सके. आपको इस डेटासेट का इस्तेमाल पूरे लैब में करना होगा. यह डेटासेट, अब सार्वजनिक Cloud Storage बकेट में उपलब्ध है. डेटासेट को ऐक्सेस करने के तरीके के बारे में हम बाद में कोडलैब में ज़्यादा जानकारी देंगे. हमारा लक्ष्य, गेम में की गई अलग-अलग कार्रवाइयों के आधार पर, खिलाड़ी की कुल रेटिंग का अनुमान लगाना है. जैसे, इंटरसेप्शन और पेनल्टी.
डेटा साइंस के लिए, Vertex AI एक्सपेरिमेंट क्यों मददगार है?
डेटा साइंस एक प्रयोग है, इसलिए आखिरकार इन्हें वैज्ञानिक कहा जाता है. अच्छे डेटा साइंटिस्ट, अलग-अलग अनुमान लगाने के लिए, आज़मा-चुकने के तरीके का इस्तेमाल करते हैं. वे इस उम्मीद के साथ ऐसा करते हैं कि बार-बार आज़माने से, बेहतर परफ़ॉर्म करने वाला मॉडल बनेगा.
डेटा साइंस की टीमों ने कई बार प्रयोग किया है, लेकिन उन्हें अपने काम और "सीक्रेट सॉस" को ट्रैक करने में अक्सर परेशानी होती है जो उनके एक्सपेरिमेंट से पता चला. ऐसा आगे बताई गई कुछ वजहों से होता है:
- ट्रेनिंग वाली नौकरियों को ट्रैक करना मुश्किल हो सकता है. इसकी मदद से, यह आसानी से याद रखा जा सकता है कि कौनसी चीज़ काम कर रही है और कौनसी नहीं
- डेटा साइंस टीम के मामले में यह समस्या और भी बढ़ जाती है, क्योंकि हो सकता है कि सभी सदस्य एक्सपेरिमेंट को ट्रैक न कर रहे हों या अपने नतीजे दूसरों के साथ शेयर न कर रहे हों
- डेटा कैप्चर करने में बहुत समय लगता है और ज़्यादातर टीमें मैन्युअल तरीकों (जैसे कि शीट या दस्तावेज़) का इस्तेमाल करती हैं. इन तरीकों से सीखने के लिए, अलग-अलग और अधूरी जानकारी मिलती है
tl;dr: Vertex AI Experiments आपके लिए काम का है, जिससे आप अपने प्रयोगों को ज़्यादा आसानी से ट्रैक और उनकी तुलना कर सकते हैं
गेमिंग के लिए Vertex AI को एक्सपेरिमेंट क्यों इस्तेमाल करना चाहिए?
लंबे समय से गेमिंग, मशीन लर्निंग और मशीन लर्निंग के एक्सपेरिमेंट के लिए सबसे अहम रही है. गेम न सिर्फ़ हर दिन अरबों रीयल टाइम इवेंट तैयार करते हैं, बल्कि वे मशीन लर्निंग और मशीन लर्निंग के एक्सपेरिमेंट का इस्तेमाल करके, पूरे डेटा का इस्तेमाल करते हैं. इससे उन्हें गेम के अनुभव को बेहतर बनाने, खिलाड़ियों को बनाए रखने, और अपने प्लैटफ़ॉर्म पर अलग-अलग खिलाड़ियों का आकलन करने में मदद मिलती है. इसलिए, हमें लगा कि एक गेमिंग डेटासेट, हमारे एक्सपेरिमेंट के तौर पर सही है.
4. अपना एनवायरमेंट सेट अप करें
इस कोडलैब को चलाने के लिए, आपके पास Google Cloud Platform का ऐसा प्रोजेक्ट होना चाहिए जिसमें बिलिंग की सुविधा चालू हो. प्रोजेक्ट बनाने के लिए, यहां दिए गए निर्देशों का पालन करें.
पहला चरण: Compute Engine API चालू करना
Compute Engine पर जाएं और अगर यह पहले से चालू नहीं है, तो चालू करें को चुनें.
दूसरा चरण: Vertex AI API को चालू करना
अपने Cloud Console के Vertex AI सेक्शन पर जाएं और Vertex AI API को चालू करें पर क्लिक करें.
तीसरा चरण: Vertex AI Workbench इंस्टेंस बनाना
अपने Cloud Console के Vertex AI सेक्शन में, वर्कबेंच पर क्लिक करें:
अगर Notebooks API पहले से चालू नहीं है, तो उसे चालू करें.
इसके बाद, मैनेज की गई किताबें पर क्लिक करें:

इसके बाद, नई नोटबुक चुनें.
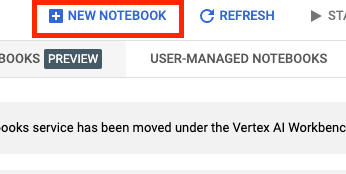
अपनी नोटबुक को कोई नाम दें. इसके बाद, बेहतर सेटिंग पर क्लिक करें.

बेहतर सेटिंग में जाकर, डिवाइस के इस्तेमाल में न होने पर बंद होने की सुविधा चालू करें. साथ ही, मिनटों की संख्या को 60 पर सेट करें. इसका मतलब है कि इस्तेमाल में न होने पर, आपका नोटबुक अपने-आप बंद हो जाएगा, ताकि आपको अनचाहे खर्च न करने पड़ें.

चौथा चरण: अपनी Notebook खोलें
इंस्टेंस बनाने के बाद, JupyterLab खोलें को चुनें.

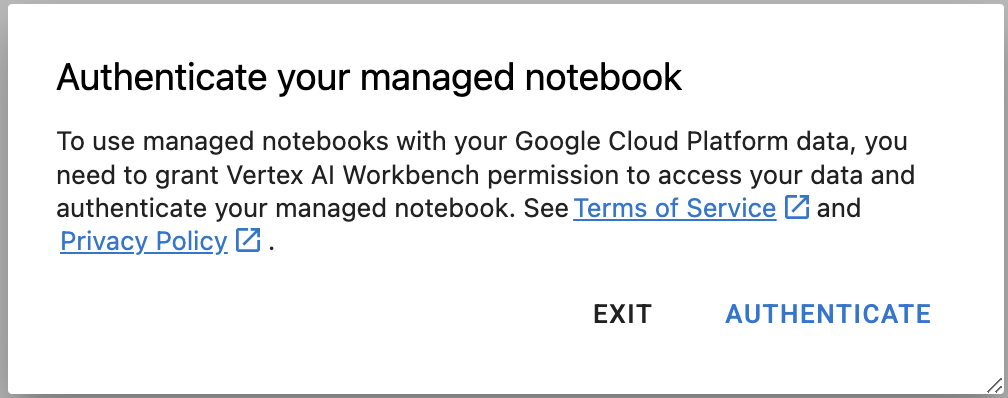
पांचवां चरण: पुष्टि करें (सिर्फ़ पहली बार)
पहली बार किसी नए इंस्टेंस का इस्तेमाल करने पर, आपसे पुष्टि करने के लिए कहा जाएगा. ऐसा करने के लिए, यूज़र इंटरफ़ेस (यूआई) में दिया गया तरीका अपनाएं.
छठा चरण: सही कर्नेल चुनना
मैनेज की जा रही नोटबुक में एक यूज़र इंटरफ़ेस (यूआई) में कई कर्नेल दिए जाते हैं. Tensorflow 2 (लोकल) के लिए कोई कर्नेल चुनें.

5. आपकी Notebook के शुरुआती सेटअप के चरण
अपनी पाइपलाइन बनाने से पहले, आपको अपनी नोटबुक में अपना एनवायरमेंट सेटअप करने के लिए, कई और चरण पूरे करने होंगे. इन चरणों में ये शामिल हैं: कोई भी अतिरिक्त पैकेज इंस्टॉल करना, वैरिएबल सेट करना, अपना क्लाउड स्टोरेज बकेट बनाना, सार्वजनिक स्टोरेज बकेट से गेमिंग डेटासेट कॉपी करना, लाइब्रेरी इंपोर्ट करना और अतिरिक्त कॉन्सटेंट तय करना.
पहला चरण: अन्य पैकेज इंस्टॉल करना
हमें ऐसी अतिरिक्त पैकेज डिपेंडेंसी इंस्टॉल करनी होगी जो आपके notebook के एनवायरमेंट में फ़िलहाल इंस्टॉल नहीं हैं. उदाहरण के लिए, KFP SDK टूल.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
इसके बाद, Notebook कर्नेल को रीस्टार्ट करें, ताकि आप अपनी notebook में डाउनलोड किए गए पैकेज का इस्तेमाल कर सकें.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
दूसरा चरण: वैरिएबल सेट करना
हम अपनी PROJECT_ID के बारे में बताना चाहते हैं. अगर आपको अपना Project_ID नहीं पता है, तो gcloud का इस्तेमाल करके अपना PROJECT_ID पाया जा सकता है.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
अगर ऐसा नहीं है, तो PROJECT_ID को यहां सेट करें.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
हम REGION वैरिएबल भी सेट करना चाहेंगे, जिसका इस्तेमाल इस नोटबुक के बाकी हिस्से में किया जाता है. Vertex AI में इस्तेमाल किए जा सकने वाले इलाके यहां दिए गए हैं. हमारा सुझाव है कि आप अपने सबसे नज़दीकी इलाके को चुनें.
- अमेरिका: us-central1
- यूरोप: europe-west4
- एशिया पैसिफ़िक: asia-east1
कृपया Vertex AI की ट्रेनिंग के लिए, एक से ज़्यादा क्षेत्रों के हिसाब से बकेट का इस्तेमाल न करें. Vertex AI की सभी सेवाएं सभी इलाकों में काम नहीं करतीं. Vertex AI के क्षेत्रों के बारे में ज़्यादा जानें.
#set your region
REGION = "us-central1" # @param {type: "string"}
आखिर में, हम TIMESTAMP वैरिएबल सेट करेंगे. इस वैरिएबल का इस्तेमाल, बनाए गए संसाधनों पर उपयोगकर्ताओं के नाम के बीच टकराव से बचने के लिए किया जाता है. आपने हर इंस्टेंस सेशन के लिए एक TIMESTAMP बनाया है और उसे इस ट्यूटोरियल में बनाए गए संसाधनों के नाम में जोड़ा है.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
तीसरा चरण: Cloud Storage बकेट बनाना
आपको Cloud Storage स्टेजिंग बकेट के बारे में बताना होगा और उसका फ़ायदा लेना होगा. स्टेजिंग बकेट वह जगह होती है जहां आपके डेटासेट और मॉडल के संसाधनों से जुड़ा सारा डेटा, सभी सेशन में सेव रहता है.
यहां अपनी Cloud Storage बकेट का नाम सेट करें. Google Cloud के सभी प्रोजेक्ट में बकेट के नाम, दुनिया भर में अलग-अलग होने चाहिए. इनमें, आपके संगठन से बाहर के प्रोजेक्ट भी शामिल हैं.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
अगर आपकी बकेट पहले से मौजूद नहीं है, तो अपना Cloud Storage बकेट बनाने के लिए, नीचे दिए गए सेल को चलाएं.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
इसके बाद, नीचे दी गई सेल को चलाकर, अपनी Cloud Storage बकेट के ऐक्सेस की पुष्टि की जा सकती है.
#verify access
! gsutil ls -al $BUCKET_URI
चौथा चरण: हमारा गेमिंग डेटासेट कॉपी करना
जैसा कि हमने पहले बताया था, आपको EA Sports के हिट वीडियो गेम, FIFA से लोकप्रिय गेमिंग डेटासेट का फ़ायदा मिलेगा. हमने आपके लिए प्री-प्रोसेसिंग का काम कर दिया है, इसलिए आपको बस सार्वजनिक स्टोरेज बकेट से डेटासेट को कॉपी करना होगा और उसे अपने बनाए गए बकेट में ले जाना होगा.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
पांचवां चरण: लाइब्रेरी इंपोर्ट करना और अतिरिक्त कॉन्स्टेंट तय करना
इसके बाद, हमें Vertex AI, KFP वगैरह के लिए, अपनी लाइब्रेरी इंपोर्ट करनी होंगी.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
हम उन अतिरिक्त कॉन्सटेंट को भी तय करेंगे जिनके बारे में हम पूरी नोटबुक में जानेंगे. जैसे, ट्रेनिंग डेटा के लिए फ़ाइल पाथ.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. आइए हमारी पाइपलाइन बनाएं
अब इस मस्ती की शुरुआत हो सकती है और हम अपनी ट्रेनिंग पाइपलाइन बनाने के लिए, Vertex AI की मदद से इसका इस्तेमाल कर सकते हैं. हम Vertex AI SDK टूल को शुरू करेंगे, अपनी ट्रेनिंग जॉब को पाइपलाइन कॉम्पोनेंट के तौर पर सेट अप करेंगे, अपनी पाइपलाइन बनाएंगे, अपनी पाइपलाइन के रन सबमिट करेंगे, और एक्सपेरिमेंट देखने और उनकी स्थिति पर नज़र रखने के लिए, Vertex AI SDK टूल का इस्तेमाल करेंगे.
पहला चरण: Vertex AI SDK टूल शुरू करना
अपने PROJECT_ID और BUCKET_URI को सेट करते हुए, Vertex AI SDK टूल शुरू करें.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
दूसरा चरण: ट्रेनिंग जॉब को पाइपलाइन कॉम्पोनेंट के तौर पर सेट अप करना
हमारे एक्सपेरिमेंट चलाने के लिए, हमें अपने ट्रेनिंग जॉब को पाइपलाइन कॉम्पोनेंट के तौर पर तय करना होगा. हमारी पाइपलाइन में, ट्रेनिंग डेटा और हाइपर पैरामीटर (उदाहरण के लिए, DROPOUT_RATE, LEARNING_RATE, EPOCHS को इनपुट और आउटपुट मॉडल की मेट्रिक के तौर पर शामिल करें (जैसे, MAE और RMSE) और एक मॉडल आर्टफ़ैक्ट.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
तीसरा चरण: हमारी पाइपलाइन बनाना
अब हम KFP में उपलब्ध Domain Specific Language (DSL) का इस्तेमाल करके, अपना वर्कफ़्लो सेटअप करेंगे और अपनी पाइपलाइन को JSON फ़ाइल में कंपाइल करेंगे.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
चौथा चरण: पाइपलाइन रन सबमिट करना
हमारे कॉम्पोनेंट को सेट अप करने और हमारी पाइपलाइन को तय करने में, कड़ी मेहनत की जाती है. हम उन पाइपलाइन के अलग-अलग रन सबमिट करने के लिए तैयार हैं, जिनके बारे में हमने ऊपर बताया है. ऐसा करने के लिए, हमें अपने अलग-अलग हाइपर पैरामीटर की वैल्यू इस तरह तय करनी होंगी:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
इसके बाद, हाइपर पैरामीटर तय करके, हम for loop का इस्तेमाल करके, पाइपलाइन के अलग-अलग रनों को सही तरीके से फ़ीड कर सकते हैं:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
पांचवां चरण: एक्सपेरिमेंट देखने के लिए, Vertex AI SDK का इस्तेमाल करें
Vertex AI SDK की मदद से, पाइपलाइन के चलने की स्थिति पर नज़र रखी जा सकती है. इसका इस्तेमाल Vertex AI प्रयोग में पाइपलाइन रन के पैरामीटर और मेट्रिक दिखाने के लिए भी किया जा सकता है. अपनी दौड़ और उसकी मौजूदा स्थिति से जुड़े पैरामीटर देखने के लिए, नीचे दिए गए कोड का इस्तेमाल करें.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
पाइपलाइन के चलने की स्थिति के बारे में अपडेट पाने के लिए, नीचे दिए गए कोड का इस्तेमाल किया जा सकता है.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
run_name का इस्तेमाल करके, कुछ पाइपलाइन जॉब को कॉल भी किया जा सकता है.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
आखिर में, तय इंटरवल (जैसे कि हर 60 सेकंड) पर अपनी दौड़ की स्थिति को रीफ़्रेश करके देखा जा सकता है कि स्टेटस RUNNING से बदलकर FAILED या COMPLETE हो गए हैं.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. सबसे बढ़िया परफ़ॉर्म करने वाली दौड़ का पता लगाएं
बहुत बढ़िया, अब हमारी पाइपलाइन के नतीजे आ गए हैं. आपके मन में यह सवाल आ सकता है कि इन नतीजों से मैं क्या सीख सकती हूं? आपके प्रयोग के आउटपुट में पांच पंक्तियां होनी चाहिए, यानी पाइपलाइन के हर रन के लिए एक लाइन. यह कुछ ऐसा दिखेगा:

MAE और RMSE, दोनों ही मॉडल के औसत अनुमान की गड़बड़ी का आकलन करते हैं. इसलिए, ज़्यादातर मामलों में दोनों मेट्रिक की कम वैल्यू तय करनी चाहिए. Vertex AI एक्सपेरिमेंट के आउटपुट के आधार पर, हम देख सकते हैं कि दोनों मेट्रिक में सबसे अच्छा परफ़ॉर्म करने वाला रन, फ़ाइनल रन था. इसमें dropout_rate 0.001, learning_rate 0.001, और epochs की कुल संख्या 20 थी. इस एक्सपेरिमेंट के आधार पर, इन मॉडल पैरामीटर का इस्तेमाल प्रोडक्शन में किया जाएगा, क्योंकि इससे मॉडल की परफ़ॉर्मेंस सबसे अच्छी होती है.
इसके साथ ही, आपने लैब खत्म कर लिया है!
🎉 बधाई हो! 🎉
आपने Vertex AI को इस्तेमाल करने का तरीका सीख लिया है, ताकि:
- खिलाड़ी की रेटिंग का अनुमान लगाने के लिए, कस्टम Keras मॉडल को ट्रेनिंग दें. जैसे, रिग्रेशन
- बढ़ाने लायक एमएल पाइपलाइन बनाने के लिए, Kubeflow Pipelines SDK टूल का इस्तेमाल करें
- पांच चरणों वाली एक ऐसी पाइपलाइन बनाएं और चलाएं जो GCS से डेटा इंपोर्ट करती है, डेटा को स्केल करती है, मॉडल को ट्रेनिंग देती है, उसका आकलन करती है, और इस मॉडल को वापस GCS में सेव करती है
- मॉडल और मॉडल मेट्रिक जैसे मॉडल आर्टफ़ैक्ट को सेव करने के लिए, Vertex ML मेटाडेटा का इस्तेमाल करना
- Vertex AI Experiments का इस्तेमाल करके, अलग-अलग पाइपलाइन के नतीजों की तुलना करें
Vertex के अलग-अलग हिस्सों के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
8. साफ़-सफ़ाई सेवा
आपसे शुल्क न लिया जाए, इसलिए हमारा सुझाव है कि आप इस लैब में बनाए गए संसाधनों को मिटा दें.
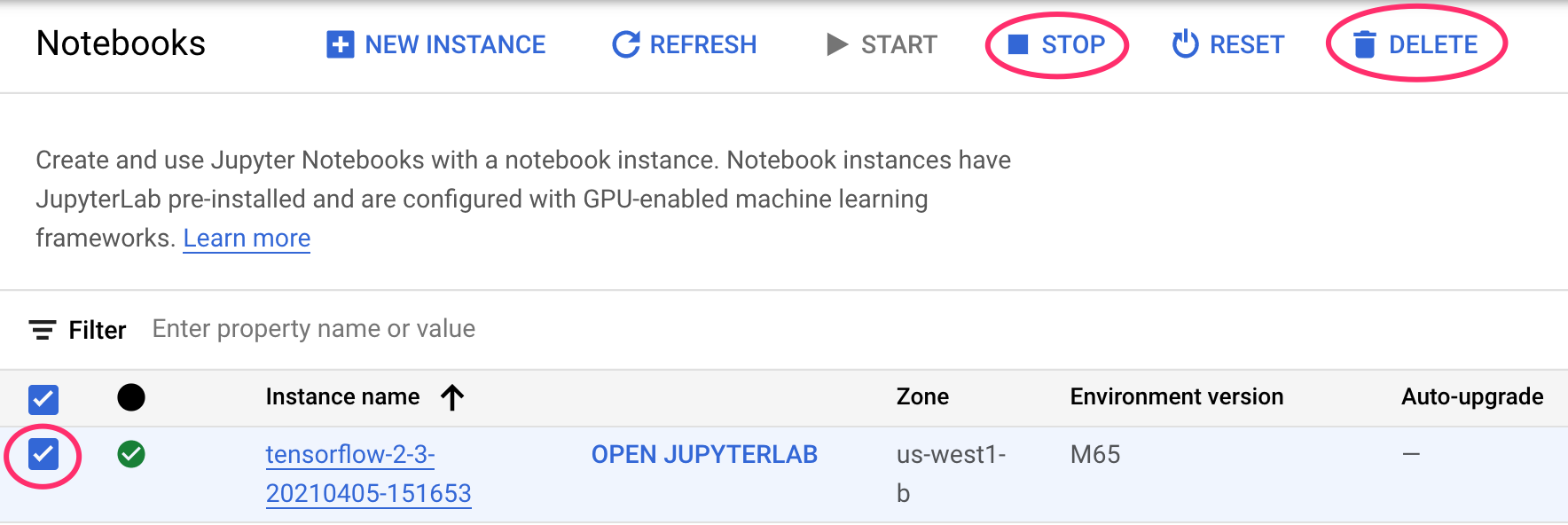
पहला चरण: अपने Notebooks इंस्टेंस को रोकना या मिटाना
यदि आप इस लैब में बनाए गए नोटबुक का उपयोग करना जारी रखना चाहते हैं, तो यह अनुशंसा की जाती है कि आप उपयोग में नहीं होने पर इसे बंद कर दें. अपने Cloud Console में Notebook के यूज़र इंटरफ़ेस (यूआई) से, नोटबुक चुनें और फिर बंद करें चुनें. अगर आपको इस इंस्टेंस को पूरी तरह से मिटाना है, तो मिटाएं चुनें:
दूसरा चरण: Cloud Storage बकेट को मिटाना
अपने Cloud Console में नेविगेशन मेन्यू का इस्तेमाल करके, स्टोरेज बकेट मिटाने के लिए स्टोरेज पर जाएं. इसके बाद, अपनी बकेट चुनें और मिटाएं पर क्लिक करें: