1. 개요
이 실습에서는 Vertex AI를 사용하여 TensorFlow에서 커스텀 Keras 모델을 학습시키는 파이프라인을 빌드합니다. 그런 다음 Vertex AI 실험에서 사용할 수 있는 새로운 기능을 사용하여 모델 실행을 추적하고 비교하여 어떤 초매개변수의 조합이 최고의 성능을 발휘하는지 확인합니다.
학습 내용
다음 작업을 수행하는 방법을 배우게 됩니다.
- 플레이어 평점 (예: 회귀)을 예측하도록 커스텀 Keras 모델 학습시키기
- Kubeflow Pipelines SDK를 사용하여 확장 가능한 ML 파이프라인 빌드
- Cloud Storage에서 데이터를 수집하고, 데이터를 확장하고, 모델을 학습시키고, 평가하고, 그 결과로 생성된 모델을 Cloud Storage에 다시 저장하는 5단계 파이프라인을 만들고 실행합니다.
- Vertex ML Metadata를 활용하여 모델 및 모델 측정항목과 같은 모델 아티팩트 저장
- Vertex AI 실험을 활용하여 다양한 파이프라인 실행의 결과 비교
Google Cloud에서 이 실습을 진행하는 데 드는 총 비용은 약 $1입니다.
2. Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 이전할 수도 있습니다.
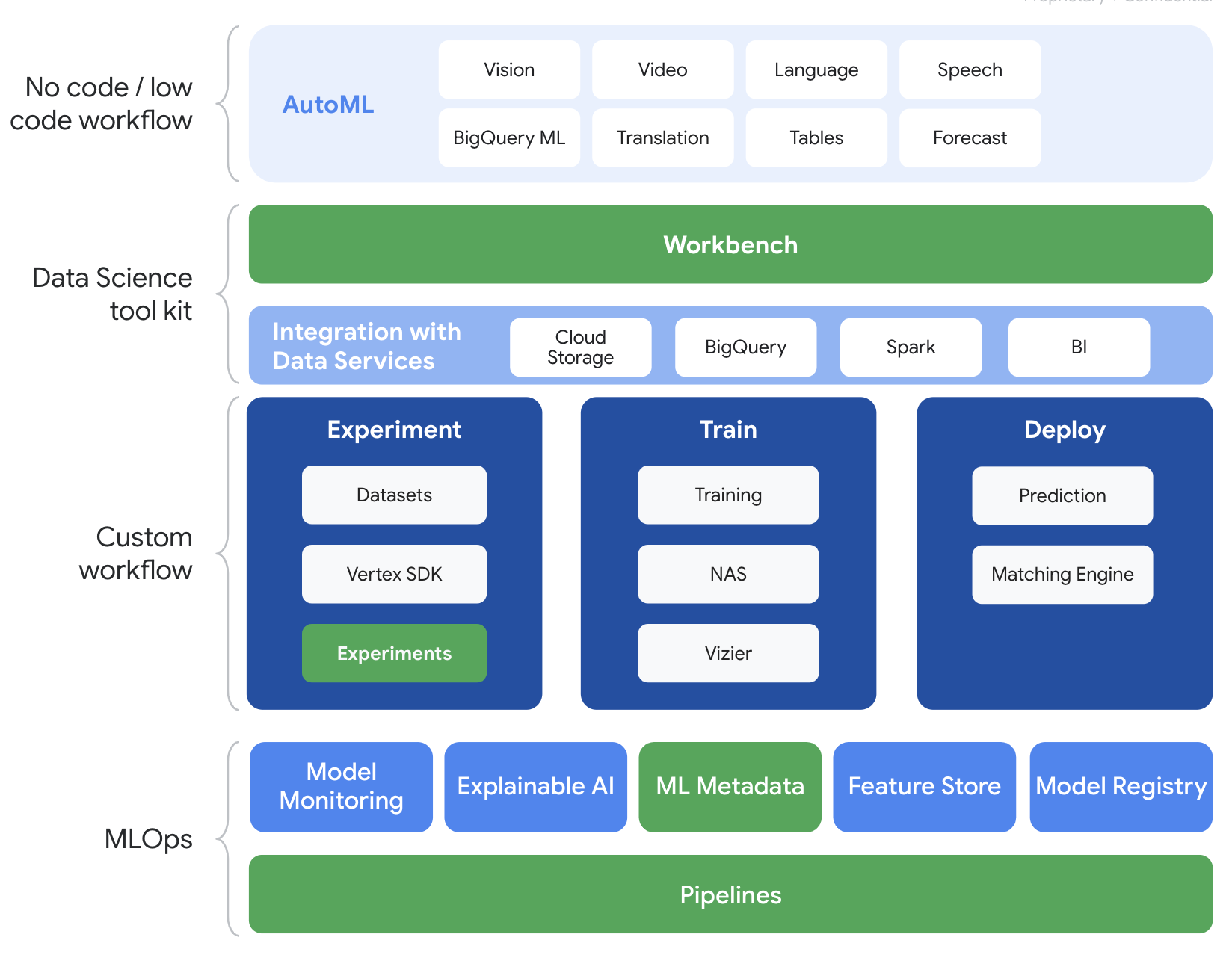
Vertex AI에는 엔드 투 엔드 ML 워크플로를 지원하는 다양한 제품이 포함되어 있습니다. 이 실습에서는 아래에 강조 표시된 실험, 파이프라인, ML 메타데이터, Workbench 제품에 중점을 둡니다.
3. 사용 사례 개요
여기서는 EA Sports'의 인기 축구 데이터 세트를 사용합니다. FIFA 비디오 게임 시리즈 2008~2016 시즌의 축구 경기 25,000여 개와 선수 10,000여 명이 포함되어 있습니다. 데이터가 사전 처리되어 있으므로 더 쉽게 시작할 수 있습니다. 이제 퍼블릭 Cloud Storage 버킷에서 찾을 수 있는 이 데이터 세트를 실습 전체에서 사용하게 됩니다. 데이터 세트에 액세스하는 방법은 Codelab 후반부에서 자세히 알아봅니다. 우리의 최종 목표는 인터셉션이나 페널티킥 등 게임 내 다양한 행동을 바탕으로 플레이어의 전반적인 점수를 예측하는 것입니다.
Vertex AI 실험이 데이터 과학에 유용한 이유는 무엇인가요?
데이터 과학은 본질적으로 실험적이며, 어쨌든 과학자라고 불립니다. 우수한 데이터 과학자는 가설을 기반으로 시행착오를 거쳐 다양한 가설을 테스트하며 반복을 거듭할수록 성능이 향상된 모델을 얻을 수 있기를 기대합니다.
데이터 과학팀은 실험을 수용했지만 작업과 '비법'을 추적하는 데 어려움을 겪는 경우가 많습니다. 다음과 같은 사실을 발견했습니다. 여기에는 다음과 같은 몇 가지 이유가 있을 수 있습니다.
- 학습 작업을 추적하는 작업이 번거로워져서 효과적인 부분과 그렇지 않은 작업을 구분하기 쉽도록 할 수 있습니다.
- 모든 구성원이 실험을 추적하거나 결과를 다른 사용자와 공유하지 않을 수 있으므로 데이터 과학팀 전체를 살펴볼 때 이 문제가 더욱 복잡해집니다.
- 데이터 캡처는 시간이 오래 걸리며 대부분의 팀은 수동 방법 (예: 시트 또는 문서)을 활용하여 일관되지 않고 불완전한 정보를 학습하게 됩니다.
tl;dr: Vertex AI 실험이 자동으로 진행되므로 실험을 더 쉽게 추적하고 비교할 수 있습니다.
게임을 위한 Vertex AI 실험을 사용해야 하는 이유
게임은 전통적으로 머신러닝 및 ML 실험의 놀이터였습니다. 게임은 매일 수십억 개의 실시간 이벤트를 생성할 뿐만 아니라 ML 및 ML 실험을 활용하여 게임 내 경험을 개선하고 플레이어를 유지하며 플랫폼의 다양한 플레이어를 평가함으로써 이러한 데이터를 모두 활용합니다. 따라서 우리는 게임 데이터 세트가 전체 실험 연습과 잘 맞다고 생각했습니다.
4. 환경 설정하기
이 Codelab을 실행하려면 결제가 사용 설정된 Google Cloud Platform 프로젝트가 필요합니다. 프로젝트를 만들려면 여기의 안내를 따르세요.
1단계: Compute Engine API 사용 설정
아직 사용 설정되지 않은 경우 Compute Engine으로 이동하고 사용 설정을 선택합니다.
2단계: Vertex AI API 사용 설정
Cloud Console의 Vertex AI 섹션으로 이동하고 Vertex AI API 사용 설정을 클릭합니다.
3단계: Vertex AI Workbench 인스턴스 만들기
Cloud 콘솔의 Vertex AI 섹션에서 'Workbench'를 클릭합니다.
Notebooks API를 아직 사용 설정하지 않은 경우 사용 설정합니다.
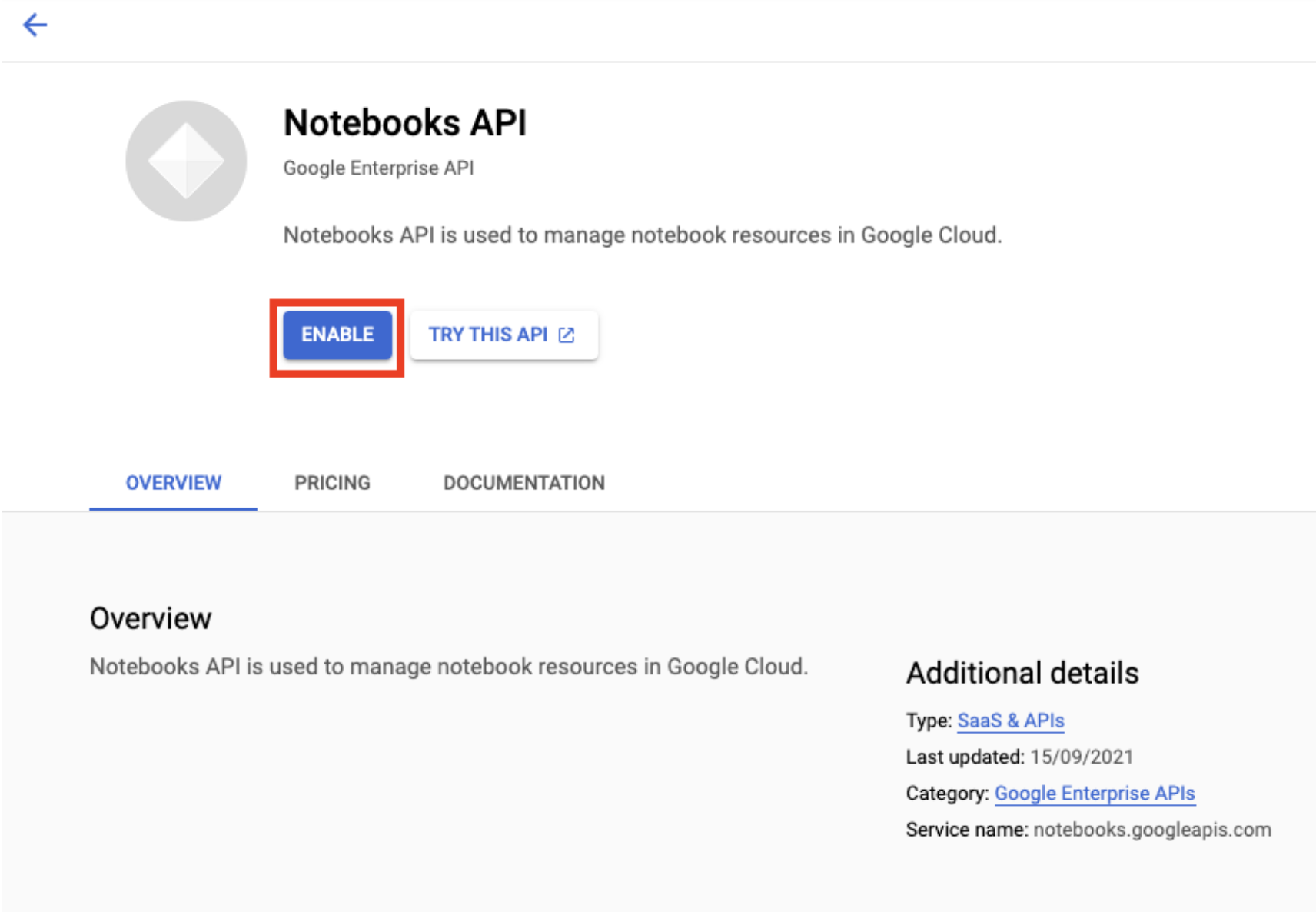
사용 설정했으면 관리형 노트북을 클릭합니다.

그런 다음 새 노트북을 선택합니다.
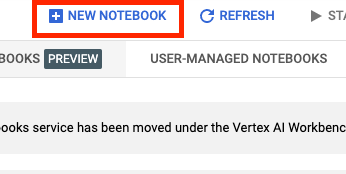
노트북 이름을 지정한 후 고급 설정을 클릭합니다.

고급 설정에서 유휴 상태 종료를 사용 설정하고 분을 60으로 설정합니다. 즉, 노트북을 사용하지 않을 때는 자동으로 종료되므로 불필요한 비용이 발생하지 않습니다.

4단계: 노트북 열기
인스턴스가 생성되면 JupyterLab 열기를 선택합니다.

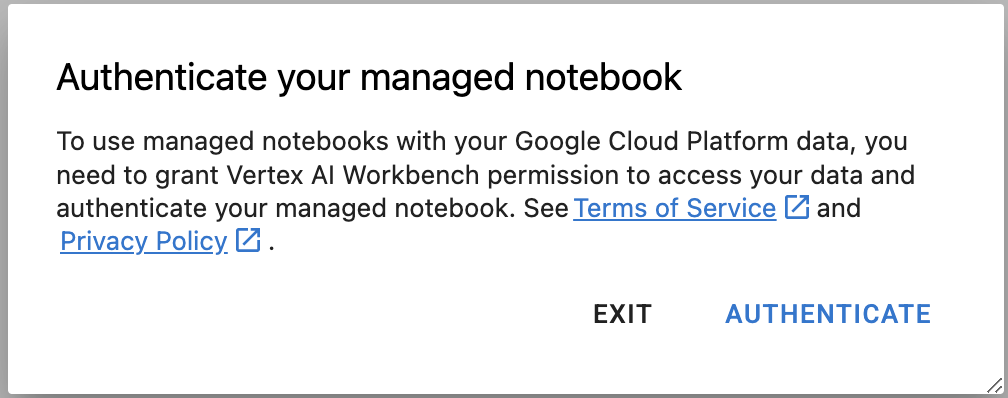
5단계: 인증 (처음인 경우에만)
새 인스턴스를 처음 사용하는 경우 인증하라는 메시지가 표시됩니다. 진행하려면 UI의 단계를 따릅니다.
6단계: 적절한 커널 선택
관리형 노트북은 단일 UI에서 여러 커널을 제공합니다. Tensorflow 2(로컬)의 커널을 선택합니다.

5. 노트북의 초기 설정 단계
파이프라인을 빌드하기 전에 일련의 추가 단계를 수행하여 노트북 내에서 환경을 설정해야 합니다. 이 단계에는 추가 패키지 설치, 변수 설정, 클라우드 스토리지 버킷 만들기, 공용 스토리지 버킷에서 게임 데이터 세트 복사, 라이브러리 가져오기, 추가 상수 정의가 포함됩니다.
1단계: 추가 패키지 설치하기
현재 노트북 환경에 설치되지 않은 패키지 종속 항목을 추가로 설치해야 합니다. KFP SDK도 한 가지 예로 들 수 있습니다.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
그런 다음 노트북 커널을 다시 시작하여 노트북 내에서 다운로드한 패키지를 사용하는 것이 좋습니다.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
2단계: 변수 설정
PROJECT_ID를 정의하려고 합니다. Project_ID을 모르면 gcloud를 사용하여 PROJECT_ID를 가져올 수 있습니다.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
아니면 여기에서 PROJECT_ID를 설정하세요.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
이 노트북의 나머지 부분에서 사용되는 REGION 변수도 설정합니다. 다음은 Vertex AI에 지원되는 리전입니다. 가장 가까운 리전을 선택하는 것이 좋습니다.
- 미주: us-central1
- 유럽: europe-west4
- 아시아 태평양: asia-east1
Vertex AI를 사용한 학습에 멀티 리전 버킷을 사용하지 마세요. 모든 리전에서 모든 Vertex AI 서비스 지원을 제공하지는 않습니다. Vertex AI 리전에 대해 자세히 알아보기
#set your region
REGION = "us-central1" # @param {type: "string"}
마지막으로 TIMESTAMP 변수를 설정합니다. 이 변수는 생성된 리소스에서 사용자 간의 이름 충돌을 방지하는 데 사용되며, 각 인스턴스 세션의 TIMESTAMP를 만든 후 이 튜토리얼에서 만든 리소스의 이름에 추가합니다.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
3단계: Cloud Storage 버킷 만들기
Cloud Storage 스테이징 버킷을 지정하고 활용해야 합니다. 스테이징 버킷에는 데이터 세트 및 모델 리소스와 연결된 모든 데이터가 여러 세션에 걸쳐 보관됩니다.
아래에서 Cloud Storage 버킷 이름을 설정합니다. 버킷 이름은 조직 외부의 버킷 이름을 포함하여 모든 Google Cloud 프로젝트 간에 전역으로 고유해야 합니다.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
버킷이 아직 없는 경우 다음 셀을 실행하여 Cloud Storage 버킷을 만들 수 있습니다.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
그러면 다음 셀을 실행하여 Cloud Storage 버킷에 대한 액세스를 확인할 수 있습니다.
#verify access
! gsutil ls -al $BUCKET_URI
4단계: 게임 데이터 세트 복사
앞서 언급했듯이 EA Sports의 인기 비디오 게임인 FIFA의 인기 게임 데이터 세트를 활용하게 됩니다. 사전 처리 작업이 완료되었으므로 공개 저장소 버킷에서 데이터 세트를 복사하여 직접 만든 버킷으로 이동하기만 하면 됩니다.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
5단계: 라이브러리 가져오기 및 추가 상수 정의
다음으로 Vertex AI, KFP 등의 라이브러리를 가져와야 합니다.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
또한 학습 데이터의 파일 경로와 같이 노트북의 나머지 부분에서 다시 참조할 추가 상수도 정의합니다.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. 파이프라인 빌드
이제 Vertex AI를 활용하여 학습 파이프라인을 빌드해 보겠습니다. Vertex AI SDK를 초기화하고, 학습 작업을 파이프라인 구성요소로 설정하고, 파이프라인을 빌드하고, 파이프라인 실행을 제출하고, Vertex AI SDK를 활용하여 실험을 보고 상태를 모니터링합니다.
1단계: Vertex AI SDK 초기화
PROJECT_ID 및 BUCKET_URI를 설정하여 Vertex AI SDK를 초기화합니다.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
2단계: 학습 작업을 파이프라인 구성요소로 설정
실험 실행을 시작하려면 학습 작업을 파이프라인 구성요소로 정의하여 지정해야 합니다. 이 파이프라인은 학습 데이터와 초매개변수 (예: DROPOUT_RATE, LEARNING_RATE, EPOCHS)을 입력 및 출력 모델 측정항목 (예: MAE 및 RMSE) 및 모델 아티팩트를 사용합니다.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
3단계: 파이프라인 구축
이제 KFP에서 제공되는 Domain Specific Language (DSL)를 사용하여 워크플로를 설정하고 파이프라인을 JSON 파일로 컴파일합니다.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
4단계: 파이프라인 실행 제출
구성요소를 설정하고 파이프라인을 정의하는 작업은 완료되었습니다. 위에서 지정한 파이프라인의 다양한 실행을 제출할 준비가 되었습니다. 이렇게 하려면 다음과 같이 다양한 초매개변수의 값을 정의해야 합니다.
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
초매개변수가 정의되면 for loop를 활용하여 파이프라인의 여러 실행을 성공적으로 제공할 수 있습니다.
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
5단계: Vertex AI SDK를 활용하여 실험 보기
Vertex AI SDK를 사용하면 파이프라인 실행 상태를 모니터링할 수 있습니다. Vertex AI 실험에서 파이프라인 실행의 매개변수와 측정항목을 반환하는 데도 사용할 수 있습니다. 다음 코드를 사용하여 실행과 관련된 매개변수 및 현재 상태를 확인하세요.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
아래 코드를 활용하여 파이프라인 실행 상태에 대한 업데이트를 받을 수 있습니다.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
run_name를 사용하여 특정 파이프라인 작업을 호출할 수도 있습니다.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
마지막으로 설정된 간격(예: 60초마다)으로 실행 상태를 새로고침하여 상태가 RUNNING에서 FAILED 또는 COMPLETE로 변경되는 것을 확인할 수 있습니다.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. 실적이 가장 우수한 실행 파악
좋습니다. 이제 파이프라인 실행 결과가 나왔습니다. 이 결과를 통해 무엇을 배울 수 있는지 궁금하실 텐데요. 실험의 출력에는 파이프라인 실행마다 하나씩 총 5개의 행이 포함되어야 합니다. 다음과 같이 표시됩니다.

MAE와 RMSE는 모두 평균 모델 예측 오차의 측정값이므로 대부분의 경우 두 측정항목의 값이 더 작은 것이 바람직합니다. Vertex AI 실험의 출력에 따르면 두 측정항목에서 가장 성공적인 실행은 dropout_rate가 0.001, learning_rate(0.001인 경우), 총 epochs 수가 20인 최종 실행이었습니다. 이 실험을 기반으로 최상의 모델 성능을 제공하는 모델 매개변수는 궁극적으로 프로덕션에 사용됩니다.
이로써 실습을 완료하셨습니다.
🎉 수고하셨습니다. 🎉
Vertex AI를 사용하여 다음을 수행하는 방법을 배웠습니다.
- 플레이어 평점 (예: 회귀)을 예측하도록 커스텀 Keras 모델 학습시키기
- Kubeflow Pipelines SDK를 사용하여 확장 가능한 ML 파이프라인 빌드
- GCS에서 데이터를 처리하고, 데이터를 확장하고, 모델을 학습시키고, 평가하고, 결과 모델을 GCS에 다시 저장하는 5단계 파이프라인을 만들고 실행합니다.
- Vertex ML Metadata를 활용하여 모델 및 모델 측정항목과 같은 모델 아티팩트 저장
- Vertex AI 실험을 활용하여 다양한 파이프라인 실행의 결과 비교
Vertex의 다른 부분에 대해 자세히 알아보려면 문서를 확인하세요.
8. 삭제
요금이 청구되지 않도록 이 실습을 통해 만든 리소스를 삭제하는 것이 좋습니다.
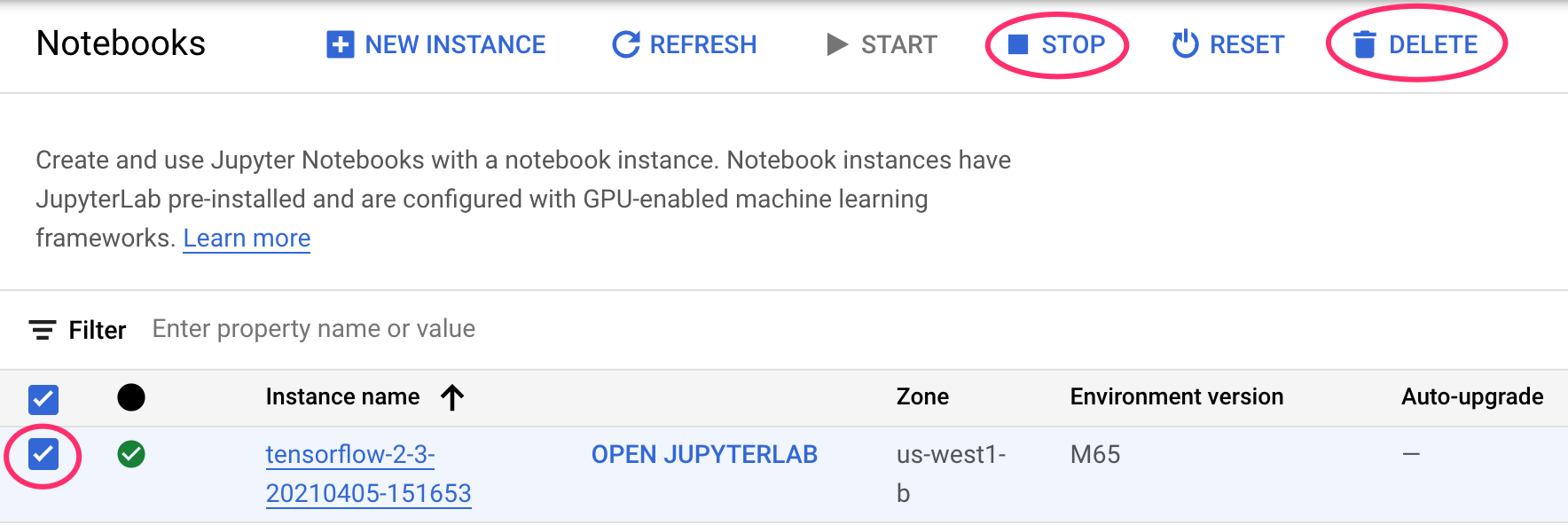
1단계: Notebooks 인스턴스 중지 또는 삭제
이 실습에서 만든 노트북을 계속 사용하려면 사용하지 않을 때 노트북을 끄는 것이 좋습니다. Cloud 콘솔의 Notebooks UI에서 노트북을 선택한 다음 중지를 선택합니다. 인스턴스를 완전히 삭제하려면 삭제를 선택합니다.
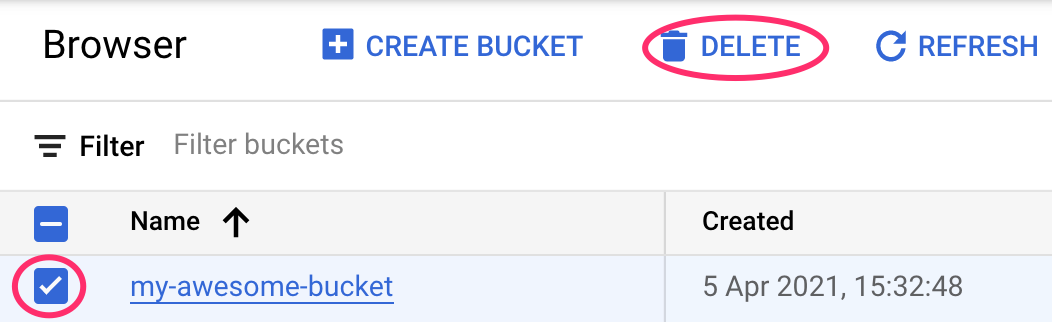
2단계: Cloud Storage 버킷 삭제
스토리지 버킷을 삭제하려면 Cloud 콘솔의 탐색 메뉴를 사용하여 스토리지로 이동하고 버킷을 선택하고 '삭제'를 클릭합니다.