1. Genel Bakış
Bu laboratuvarda, TensorFlow'da özel bir Keras modelini eğiten bir ardışık düzen oluşturmak için Vertex AI'yı kullanacaksınız. Ardından, hangi hiperparametre kombinasyonunun en iyi performansı sağladığını belirlemek üzere model çalıştırmalarını izleyip karşılaştırmak için Vertex AI Experiments'ta bulunan yeni işlevden yararlanacağız.
Öğrenecekleriniz
Öğrenecekleriniz:
- Oyuncu puanlarını (ör. regresyon) tahmin etmek için özel bir Keras Modeli eğitme
- Ölçeklenebilir makine öğrenimi ardışık düzenleri derlemek için Kubeflow Pipelines SDK'yı kullanma
- Cloud Storage'dan veri alan, verileri ölçeklendiren, modeli eğiten, değerlendiren ve sonuç olarak elde edilen modeli tekrar Cloud Storage'a kaydeden 5 adımlı bir ardışık düzen oluşturup çalıştırın
- Modeller ve Model Metrikleri gibi model yapılarını kaydetmek için Vertex ML meta verilerinden yararlanın
- Çeşitli ardışık düzen çalıştırmalarının sonuçlarını karşılaştırmak için Vertex AI Experiments'ı kullanma
Bu laboratuvarı Google Cloud'da çalıştırmanın toplam maliyeti yaklaşık 1 ABD doları'dır.
2. Vertex AI'a giriş
Bu laboratuvarda, Google Cloud'daki en yeni AI ürün teklifi kullanılmaktadır. Vertex AI, Google Cloud'daki makine öğrenimi tekliflerini sorunsuz bir geliştirme deneyimine entegre eder. Daha önce, AutoML ile eğitilen modellere ve özel modellere ayrı hizmetler üzerinden erişilebiliyordu. Yeni teklif, her ikisi de tek bir API'de ve diğer yeni ürünlerle birleştirilir. Mevcut projeleri Vertex AI'a da taşıyabilirsiniz.
Vertex AI, uçtan uca makine öğrenimi iş akışlarını destekleyen birçok farklı ürün içerir. Bu laboratuvar aşağıda vurgulanan ürünlere odaklanacaktır: Denemeler, Ardışık düzenler, ML Meta Verileri ve Workbench.

3. Kullanım Alanına Genel Bakış
Bunun için EA Sports'un sitesinde bulunan popüler bir futbol veri kümesi kullanacağız. FIFA video oyunu serisi 2008-2016 sezonlarında 25.000'den fazla futbol maçı ve 10.000'den fazla oyuncu içerir. İşe daha kolay erişebilmeniz için veriler önceden işlendi. Artık herkese açık bir Cloud Storage paketinde bulabileceğiniz bu veri kümesini laboratuvar boyunca kullanacaksınız. Veri kümesine nasıl erişeceğinizle ilgili daha fazla bilgiyi codelab'in ilerleyen bölümlerinde bulabilirsiniz. Nihai hedefimiz, müdahale ve penaltı gibi oyun içi çeşitli işlemlere göre bir oyuncunun genel puanını tahmin etmektir.
Vertex AI Denemeleri, veri bilimi için neden faydalıdır?
Veri bilimi, doğası gereği deneyseldir. Sonuçta onlara bilim insanı denir. İyi veri bilimcileri varsayıma dayalıdırlar. Deneme yanılma yönteminden yararlanarak çeşitli hipotezleri test ederler, art arda iterasyonlar yaparak daha iyi performans gösteren bir model elde ederler.
Veri bilimi ekipleri deneysel çalışmayı benimsemiş olsa da işlerini ve "gizli sosları" takip etme konusunda genellikle zorlanıyorlar. ortaya koyduk. Bunun birkaç nedeni vardır:
- Eğitim işlerini takip etmek zahmetli bir hal alabilir. Bu da işe yarayan ve yaramayan şeyleri kolayca göz ardı etmeyi kolaylaştırır.
- Bu sorun, bir veri bilimi ekibine baktığınızda daha da büyür. Bunun nedeni, tüm üyelerin deneyleri takip etmemesi, hatta sonuçlarını başkalarıyla paylaşmaması olabilir.
- Veri yakalama zaman alır ve çoğu ekip, öğrenilmesi gereken bilgilerde tutarsız ve eksikliklere yol açan manuel yöntemlerden (ör.e-tablolar veya dokümanlar) yararlanır.
tl;dr: Vertex AI Experiments, denemelerinizi daha kolay izlemenize ve karşılaştırmanıza yardımcı olarak işi sizin yerinize yapar
Neden Oyun İçin Vertex AI Experiments?
Oyunlar, geçmişte makine öğrenimi ve makine öğrenimi denemeleri için bir oyun alanı olmuştur. Oyunlar her gün milyarlarca gerçek zamanlı etkinlik oluşturmakla kalmaz, aynı zamanda oyun içi deneyimleri iyileştirmek, oyuncuları elde tutmak ve platformlarındaki farklı oyuncuları değerlendirmek için makine öğrenimi ve makine öğrenimi denemelerinden yararlanarak tüm bu verilerden yararlanır. Bu nedenle, oyun veri kümesinin genel deneme alıştırmamıza çok uygun olduğunu düşündük.
4. Ortamınızı ayarlama
Bu codelab'i çalıştırmak için faturalandırmanın etkin olduğu bir Google Cloud Platform projesine ihtiyacınız var. Proje oluşturmak için buradaki talimatları uygulayın.
1. Adım: Compute Engine API'yi etkinleştirin
Compute Engine'e gidin ve zaten etkinleştirilmemişse Etkinleştir'i seçin.
2. adım: Vertex AI API'yi etkinleştirin
Cloud Console'un Vertex AI bölümüne gidip Enable Vertex AI API'yi (Vertex AI API'yi etkinleştir) tıklayın.
3. Adım: Vertex AI Workbench örneği oluşturun
Cloud Console'unuzun Vertex AI bölümünden Workbench'i tıklayın:
Henüz etkinleştirilmemişse Notebooks API'yi etkinleştirin.
Etkinleştirdikten sonra YÖNETİLEN NOT KİTAPLARI'nı tıklayın:

Ardından YENİ NOT DEFTERİ'ni seçin.
Not defterinize bir ad verin ve Gelişmiş Ayarlar'ı tıklayın.

Gelişmiş ayarlar bölümünde, boştayken kapatma özelliğini etkinleştirin ve dakika sayısını 60 olarak ayarlayın. Bu sayede, gereksiz maliyetlere maruz kalmamak için dizüstü bilgisayarınız kullanılmadığında otomatik olarak kapanır.

4. Adım: Not Defterinizi açın
Örnek oluşturulduktan sonra JupyterLab'i aç'ı seçin.

5. Adım: Kimlik doğrulama yapın (yalnızca ilk kez)
Yeni bir örneği ilk kez kullandığınızda kimliğinizi doğrulamanız istenir. Bu işlemi yapmak için kullanıcı arayüzündeki adımları uygulayın.
6. Adım: Uygun Kernel'i seçin
Yönetilen not defterleri, tek bir kullanıcı arayüzünde birden çok çekirdek sağlar. Tensorflow 2 (yerel) için çekirdeği seçin.

5. Not Defterinizdeki İlk Kurulum Adımları
Ardışık düzeninizi oluşturmadan önce not defterinizde ortamınızı ayarlamak için bir dizi ek adım uygulamanız gerekir. Bu adımlar şunları içerir: ek paketler yükleme, değişkenleri ayarlama, bulut depolama paketinizi oluşturma, oyun veri kümesini herkese açık depolama paketinden kopyalama, kitaplıkları içe aktarma ve ek sabit değerler tanımlama.
1. Adım: Ek Paketler Yükleyin
Şu anda not defteri ortamınızda yüklü olmayan ek paket bağımlılıkları yüklememiz gerekecek. KFP SDK'sını içeren bir örnek.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
Ardından, indirilen paketleri not defterinizde kullanabilmek için Not Defteri Kernel'ini yeniden başlatmanız gerekir.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
2. Adım: Değişkenleri Ayarlayın
PROJECT_ID tanımlamak istiyoruz. Project_ID cihazınızı bilmiyorsanız gcloud kullanarak PROJECT_ID alabilirsiniz.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Aksi durumda PROJECT_ID ayarlarını burada yapabilirsiniz.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
Ayrıca, bu not defterinin geri kalanında kullanılan REGION değişkenini de ayarlamak istiyoruz. Aşağıda Vertex AI'ın desteklendiği bölgeler verilmiştir. Size en yakın bölgeyi seçmenizi öneririz.
- Amerika: us-central1
- Avrupa: europe-west4
- Asya Pasifik: asia-east1
Vertex AI ile eğitim için lütfen çok bölgeli paket kullanmayın. Her bölgede tüm Vertex AI hizmetleri için destek sunulmaz. Vertex AI bölgeleri hakkında daha fazla bilgi
#set your region
REGION = "us-central1" # @param {type: "string"}
Son olarak, bir TIMESTAMP değişkeni belirleyeceğiz. Bu değişkenler, oluşturulan kaynaklarda kullanıcılar arasındaki ad çakışmalarını önlemek için kullanılır. Her örnek oturumu için bir TIMESTAMP oluşturursunuz ve bunu, bu eğiticide oluşturduğunuz kaynakların adına eklersiniz.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
3. Adım: Cloud Storage paketi oluşturun
Bir Cloud Storage hazırlık paketi belirtmeniz ve ondan yararlanmanız gerekir. Hazırlık paketi, veri kümenizle ve model kaynaklarınızla ilişkilendirilen tüm verilerin oturumlar genelinde tutulduğu yerdir.
Aşağıda Cloud Storage paketinizin adını ayarlayın. Paket adları, kuruluşunuzun dışındakiler de dahil olmak üzere tüm Google Cloud projelerinde genel olarak benzersiz olmalıdır.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
Paketiniz halihazırda YOKSA Cloud Storage paketinizi oluşturmak için aşağıdaki hücreyi çalıştırabilirsiniz.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Ardından, aşağıdaki hücreyi çalıştırarak Cloud Storage paketinize erişimi doğrulayabilirsiniz.
#verify access
! gsutil ls -al $BUCKET_URI
4. Adım: Oyun veri kümesini kopyalayın
Daha önce de belirttiğimiz gibi, EA Sports'un popüler video oyunlarının popüler oyun veri kümesinden (FIFA) yararlanacaksınız. Ön işleme sürecini sizin için tamamladık. Bu nedenle veri kümesini herkese açık depolama paketinden kopyalayıp oluşturduğunuz pakete taşımanız yeterli olacak.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
5. Adım: Kitaplıkları İçe Aktarma ve Ek Sabitler Tanımlama
Ardından Vertex AI, KFP vb. için kitaplıklarımızı içe aktaracağız.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
Ayrıca, not defterinin geri kalanında başvuracağımız ek sabitler de(ör. eğitim verilerimizin dosya yolları) tanımlayacağız.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. Ardışık düzenimizi oluşturalım
Şimdi eğlenceli kısım başlıyor. Eğitim ardışık düzenimizi oluşturmak için Vertex AI'dan yararlanmaya başlayabiliriz. Vertex AI SDK'sını başlatacak, eğitim işimizi bir ardışık düzen bileşeni olarak ayarlayacak, ardışık düzenimizi oluşturacak, ardışık düzen çalıştırmalarımızı gönderecek ve denemeleri görüntülemek ve durumlarını izlemek için Vertex AI SDK'sından yararlanacağız.
1. adım: Vertex AI SDK'yı başlatın
PROJECT_ID ve BUCKET_URI ayarlarınızı yaparak Vertex AI SDK'sını başlatın.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
2. Adım: Eğitim İşimizi Ardışık Düzen Bileşeni olarak ayarlayın
Denemelerimizi çalıştırmaya başlamak için eğitim işimizi bir ardışık düzen bileşeni olarak tanımlayarak belirtmemiz gerekecek. Ardışık düzenimiz, eğitim verilerini ve hiperparametreleri (ör. DROPOUT_RATE, LEARNING_RATE, EPOCHS) ve çıkış modeli metrikleri (ör. MAE ve RMSE) ve bir model yapısını içerir.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
3. Adım: Ardışık Düzenimizi Oluşturma
Şimdi, KFP'de bulunan Domain Specific Language (DSL) kullanarak iş akışımızı kuracak ve ardışık düzenimizi JSON dosyasında derleyeceğiz.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
4. Adım: Ardışık Düzen Çalıştırmalarımızı gönderin
Zor iş, bileşenimizin kurulumunu ve ardışık düzenimizi tanımlamayı tamamladı. Yukarıda belirttiğimiz ardışık düzenin çeşitli çalıştırmalarını göndermeye hazırız. Bunu yapmak için, farklı hiperparametrelerimizin değerlerini aşağıdaki gibi tanımlamamız gerekir:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
Hiperparametreler tanımlandıktan sonra, ardışık düzenin farklı çalıştırmalarına başarılı bir şekilde feed sağlamak için bir for loop'ten yararlanabiliriz:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
5. adım: Denemeleri görüntülemek için Vertex AI SDK'sından yararlanın
Vertex AI SDK'sı, ardışık düzen çalıştırmalarının durumunu izlemenizi sağlar. Vertex AI denemesinde Ardışık Düzen Çalıştırmalarının parametrelerini ve metriklerini döndürmek için de kullanabilirsiniz. Çalıştırmalarınızla ilişkili parametreleri ve mevcut durumunu görmek için aşağıdaki kodu kullanın.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
Ardışık düzeninizin çalışma durumuyla ilgili güncellemeler almak için aşağıdaki koddan yararlanabilirsiniz.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
Ayrıca run_name kullanarak belirli ardışık düzen işlerini çağırabilirsiniz.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
Son olarak, çalıştırmalarınızın durumunu ayarlanan aralıklarla (örneğin her 60 saniyede bir) yenileyerek RUNNING olan durumların FAILED veya COMPLETE olarak değiştiğini görebilirsiniz.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. En İyi Performans Gösteren Koşuyu Belirleme
Çok iyi, artık ardışık düzen çalıştırmalarımızın sonuçlarını aldık. Sonuçlardan ne öğrenebileceğimi soruyor olabilirsiniz. Denemelerinizin sonucu, ardışık düzenin her çalıştırması için bir tane olmak üzere beş satır içermelidir. Aşağıdaki gibi görünür:

Hem MAE hem de RMSE, ortalama model tahmin hatasının ölçümüdür. Bu nedenle, çoğu durumda her iki metrik için daha düşük bir değer tercih edilir. Vertex AI Experiments'tan elde edilen sonuçlara göre, her iki metrikte de en başarılı çalıştırmamızın dropout_rate değeri 0,001, dropout_rate değeri 0,001 olduğunda learning_rate ve toplam epochs sayısı 20 olacak şekilde son çalıştırma oldu. Bu denemeye göre, en iyi model performansını sağladığı için bu model parametreleri nihai olarak üretimde kullanılacaktır.
Böylece laboratuvarı tamamlamış oldunuz.
🎉 Tebrikler! 🎉
Aşağıdakiler için Vertex AI'ı nasıl kullanacağınızı öğrendiniz:
- Oyuncu puanlarını (ör. regresyon) tahmin etmek için özel bir Keras Modeli eğitin
- Ölçeklenebilir makine öğrenimi ardışık düzenleri derlemek için Kubeflow Pipelines SDK'yı kullanma
- GCS'den veri alan, verileri ölçeklendiren, modeli eğiten, değerlendiren ve sonuç olarak elde edilen modeli tekrar GCS'ye kaydeden 5 adımlı bir ardışık düzen oluşturup çalıştırın
- Modeller ve Model Metrikleri gibi model yapılarını kaydetmek için Vertex ML meta verilerinden yararlanın
- Çeşitli ardışık düzen çalıştırmalarının sonuçlarını karşılaştırmak için Vertex AI Experiments'ı kullanma
Vertex'in farklı bölümleri hakkında daha fazla bilgi edinmek için dokümanlara göz atın.
8. Temizleme
Ücret ödememek için bu laboratuvar boyunca oluşturulan kaynakları silmeniz önerilir.
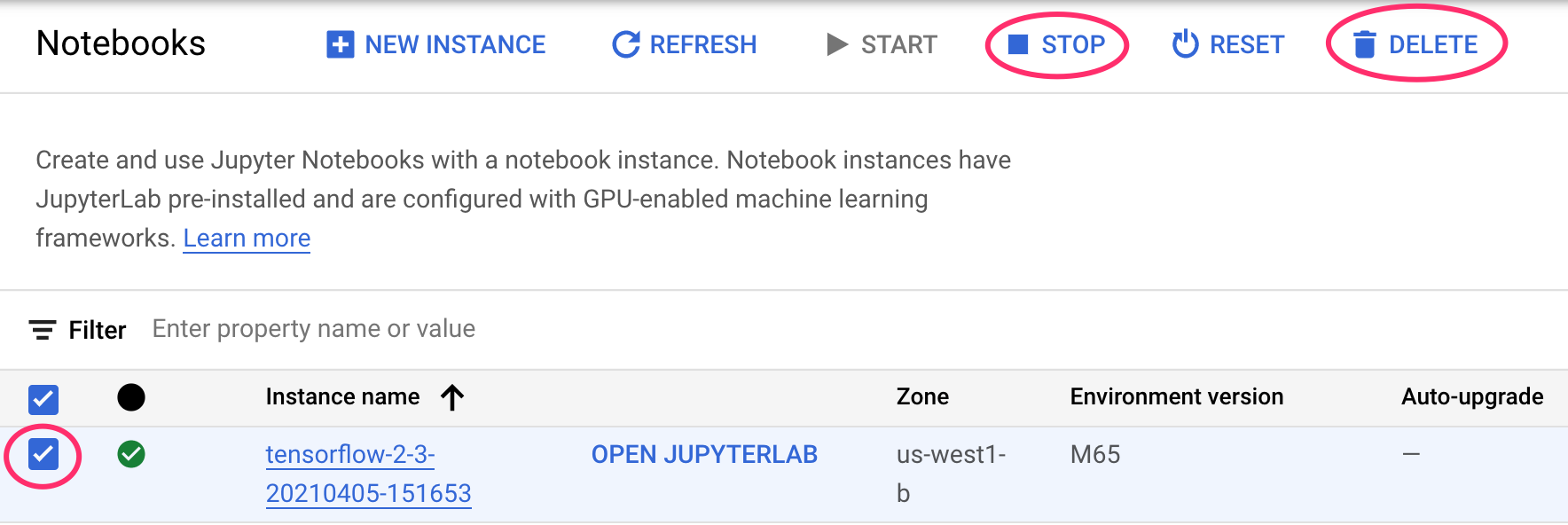
1. Adım: Notebooks örneğinizi durdurun veya silin
Bu laboratuvarda oluşturduğunuz not defterini kullanmaya devam etmek istiyorsanız, kullanmadığınız not defterini kapatmanız önerilir. Cloud Console'daki Notebooks kullanıcı arayüzünde not defterini, ardından Stop'ı (Durdur) seçin. Örneği tamamen silmek istiyorsanız Sil'i seçin:
2. Adım: Cloud Storage paketinizi silin
Storage Paketini silmek için Cloud Console'unuzdaki gezinme menüsünü kullanarak Storage'a gidin, paketinizi seçin ve Sil'i tıklayın: