
1. 概要
このラボでは、Vertex AI を使用して、TensorFlow でカスタム Keras モデルをトレーニングするパイプラインを作成します。次に、Vertex AI Experiments の新しい機能を使用して、モデルの実行を追跡して比較し、最適なパフォーマンスのハイパーパラメータの組み合わせを特定します。
学習内容
次の方法を学習します。
- カスタム Keras モデルをトレーニングして、プレーヤーの評価を予測する(回帰など)
- Kubeflow Pipelines SDK を使用してスケーラブルな ML パイプラインを構築する
- Cloud Storage からのデータの取り込み、データのスケーリング、モデルのトレーニング、評価、Cloud Storage へのモデルの再保存を行う 5 ステップのパイプラインを作成して実行する
- Vertex ML Metadata を利用して、モデルやモデルの指標などのモデル アーティファクトを保存する
- Vertex AI Experiments を使用して、さまざまなパイプライン実行の結果を比較する
このラボを Google Cloud で実行するための総費用は約 $1 です。
2. Vertex AI の概要
このラボでは、Google Cloud で利用できる最新の AI プロダクトを使用します。Vertex AI は Google Cloud 全体の ML サービスを統合してシームレスな開発エクスペリエンスを提供します。以前は、AutoML でトレーニングしたモデルやカスタムモデルには、個別のサービスを介してアクセスする必要がありました。Vertex AI は、これらの個別のサービスを他の新しいプロダクトとともに 1 つの API へと結合します。既存のプロジェクトを Vertex AI に移行することもできます。
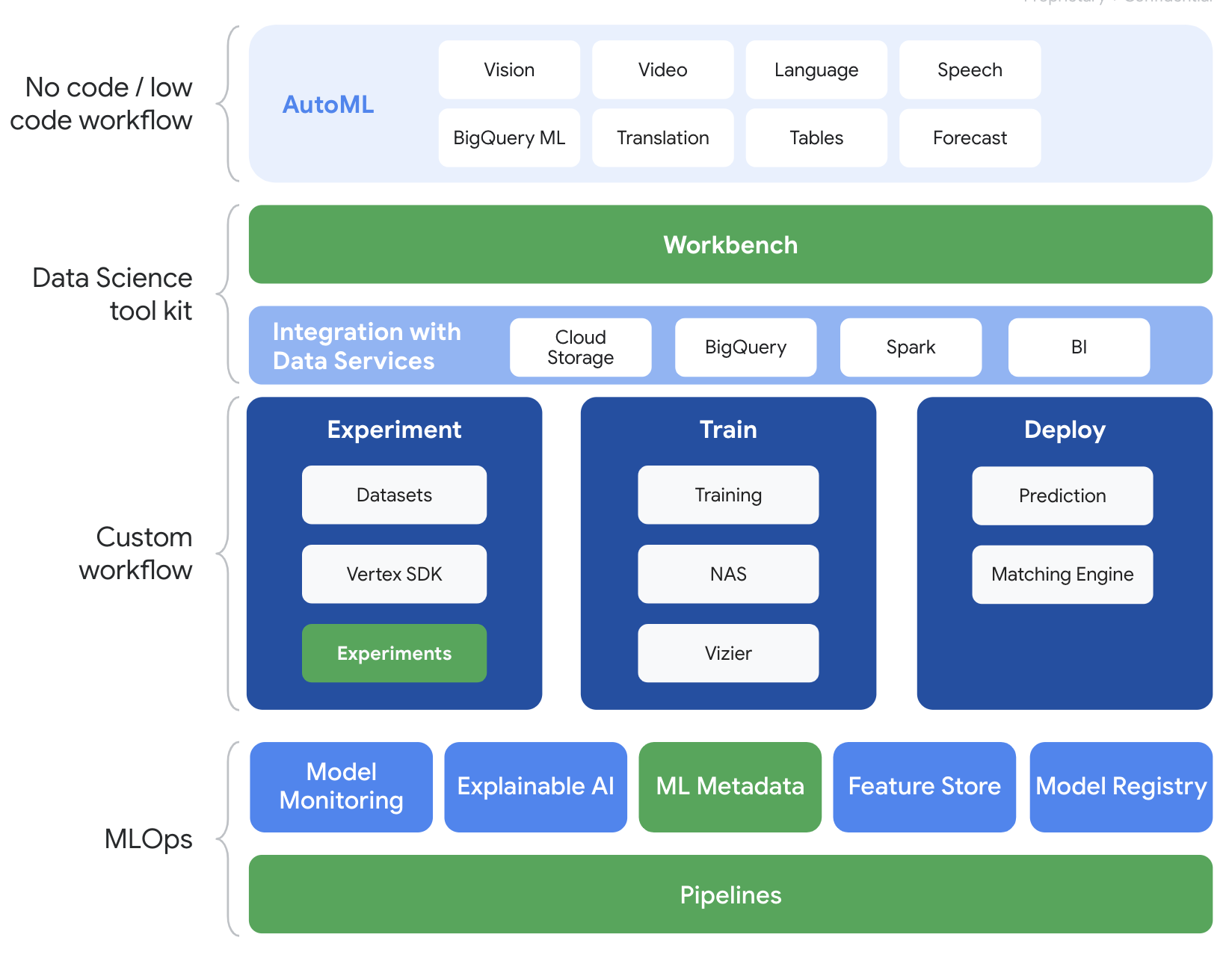
Vertex AI には、エンドツーエンドの ML ワークフローをサポートするさまざまなプロダクトが含まれています。このラボでは、以下でハイライト表示されているプロダクト(Experiments、Pipelines、ML Metadata、Workbench)を中心に学習します。
3. ユースケースの概要
ここでは、EA Sports'FIFA ビデオゲーム シリーズ。2008 ~ 2016 年シーズンの 25,000 以上のサッカーの試合と 10,000 人以上の選手が含まれています。すぐに使い始めることができるように、データは事前に前処理されています。このデータセットはラボ全体を通して使用します。このデータセットは Cloud Storage の公開バケットにあります。このデータセットへのアクセス方法については、この Codelab の後半で詳しく説明します。最終的な目標は、インターセプトやペナルティなどのさまざまなゲーム内アクションに基づいて、選手の総合評価を予測することです。
Vertex AI Experiments がデータ サイエンスに役立つ理由
データ サイエンスは本質的に実験的なものであり、結局のところ「サイエンティスト」と呼ばれます。優れたデータ サイエンティストは仮説に基づいて行動し、試行錯誤を繰り返しながらモデルのパフォーマンスが向上することを期待して、さまざまな仮説をテストします。
データ サイエンス チームはテストを導入していますが、多くの場合、作業とテストを通じて発見された「秘密のソース」を追跡するのに苦労しています。これには、次のような理由が考えられます。
- トレーニング ジョブの追跡が煩雑になり、どのジョブが有効でどのジョブが有効でないかを見失いやすくなります。
- データ サイエンス チーム全体で見ると、すべてのメンバーが実験を追跡したり、結果を他の人と共有したりしていない可能性があるため、この問題はさらに悪化します。
- データ キャプチャに時間がかかり、ほとんどのチームが手動(スプレッドシートやドキュメントなど)の方法を利用しているため、学習に使用する情報に一貫性がなく不完全である
要約: Vertex AI Experiments が自動的にテストを実行し、テストの追跡と比較を簡単に行えます。
ゲームに Vertex AI Experiments を使用する理由
ゲームは歴史的に、機械学習と ML のテストの場となってきました。ゲームでは、1 日に数十億件ものリアルタイム イベントが発生するだけでなく、ML と ML テストを活用して、ゲーム内エクスペリエンスの改善、プレーヤーの維持、プラットフォーム上のさまざまなプレーヤーの評価に、そのすべてのデータを使用しています。そのため、ゲームのデータセットは今回のテスト全体の内容に適していると考えました。
4. 環境の設定
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順を行ってください。
ステップ 1: Compute Engine API を有効にする
まだ有効になっていない場合は、[Compute Engine] に移動して [有効にする] を選択します。
ステップ 2: Vertex AI API を有効にする
Cloud コンソールの [Vertex AI] セクションに移動し、[Vertex AI API を有効にする] をクリックします。

ステップ 3: Vertex AI Workbench インスタンスを作成する
Cloud Console の [Vertex AI] セクションで [ワークベンチ] をクリックします。

Notebooks API をまだ有効にしていない場合は、有効にします。

有効にしたら、[マネージド ノートブック] をクリックします。

[新しいノートブック] を選択します。

ノートブックに名前を付けて、[詳細設定] をクリックします。

[詳細設定] で、アイドル状態でのシャットダウンを有効にして、シャットダウンまでの時間(分)を 60 に設定します。これにより、使用されていないノートブックが自動的にシャットダウンされるため、不要なコストが発生しません。

ステップ 4: ノートブックを開く
インスタンスが作成されたら、[JUPYTERLAB を開く] を選択します。

ステップ 5: 認証する(初回のみ)
新しいインスタンスを初めて使用するときに、認証が求められます。その場合は、UI で手順を行います。

ステップ 6: 適切なカーネルを選択する
マネージド ノートブックでは、1 つの UI で複数のカーネルを使用できます。TensorFlow 2(ローカル)のカーネルを選択します。

5. ノートブックの初期設定手順
パイプラインを構築する前に、ノートブック内で環境を設定する一連の追加手順を行う必要があります。このステップには、追加パッケージのインストール、変数の設定、Cloud Storage バケットの作成、公開ストレージ バケットからのゲーム データセットのコピー、ライブラリのインポートと追加の定数の定義が含まれます。
ステップ 1: 追加パッケージをインストールする
ノートブック環境に現在インストールされていない追加のパッケージ依存関係をインストールする必要があります。たとえば、KFP SDK などです。
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
次に、ダウンロードしたパッケージをノートブックで使用できるように、ノートブック カーネルを再起動します。
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
ステップ 2: 変数を設定する
PROJECT_ID を定義します。Project_ID がわからない場合は、gcloud を使用して PROJECT_ID を取得できます。
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
それ以外の場合は、PROJECT_ID をここで設定します。
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
また、このノートブックの残りの部分で使用する REGION 変数も設定します。Vertex AI でサポートされているリージョンは次のとおりです。最も近いリージョンを選択することをおすすめします。
- 南北アメリカ: us-central1
- ヨーロッパ: europe-west4
- アジア太平洋: asia-east1
Vertex AI でのトレーニングには、マルチリージョン バケットを使用しないでください。すべてのリージョンがすべての Vertex AI サービスをサポートしているわけではありません。Vertex AI のリージョンの詳細を確認する。
#set your region
REGION = "us-central1" # @param {type: "string"}
最後に、TIMESTAMP 変数を設定します。この変数は、作成したリソースについてユーザー間での名前の競合を回避するために使用します。インスタンス セッションごとに TIMESTAMP を作成し、このチュートリアルで作成するリソースの名前に追加します。
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
ステップ 3: Cloud Storage バケットを作成する
Cloud Storage ステージング バケットを指定して使用する必要があります。ステージング バケットでは、データセットとモデルリソースに関連付けられたすべてのデータがセッション間で保持されます。
Cloud Storage バケットの名前を設定します。バケット名は、組織外のものも含め、すべての Google Cloud プロジェクトでグローバルに一意である必要があります。
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
バケットがまだ存在しない場合は、次のセルを実行して Cloud Storage バケットを作成できます。
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
その後、次のセルを実行して、Cloud Storage バケットへのアクセスを確認します。
#verify access
! gsutil ls -al $BUCKET_URI
ステップ 4: ゲーム データセットをコピーする
前述のとおり、EA Sports の人気ビデオゲーム FIFA の人気ゲーム データセットを活用します。Google が前処理の作業を行ったので、データセットを一般公開ストレージ バケットからコピーし、作成したデータセットに移動するだけです。
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
ステップ 5: ライブラリをインポートし、追加の定数を定義する
次に、Vertex AI や KFP などのライブラリをインポートします。
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
また、トレーニング データのファイルパスなど、ノートブックの残りの部分で参照する追加の定数も定義します。
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. パイプラインを構築しましょう
それでは、Vertex AI を活用してトレーニング パイプラインを構築してみましょう。Vertex AI SDK を初期化し、トレーニング ジョブをパイプライン コンポーネントとして設定します。次に、パイプラインを構築してパイプライン実行を送信し、Vertex AI SDK を利用してテストを表示し、そのステータスをモニタリングします。
ステップ 1: Vertex AI SDK を初期化する
Vertex AI SDK を初期化して、PROJECT_ID と BUCKET_URI を設定します。
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
ステップ 2: トレーニング ジョブをパイプライン コンポーネントとして設定する
テストを開始するには、トレーニング ジョブをパイプライン コンポーネントとして定義して指定する必要があります。パイプラインはトレーニング データとハイパーパラメータ(例:DROPOUT_RATE、LEARNING_RATE、EPOCHS など)を入力として使用し、出力モデルの指標(例:MAE と RMSE)として取り込み、また、モデル アーティファクトを取り込みます。
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
ステップ 3: パイプラインを構築する
次に、KFP で利用可能な Domain Specific Language (DSL) を使用してワークフローを設定し、パイプラインを JSON ファイルにコンパイルします。
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
ステップ 4: パイプライン実行を送信する
コンポーネントの設定とパイプラインの定義は完了しました。上記で指定したパイプラインのさまざまな実行を送信する準備が整いました。そのためには、次のようにさまざまなハイパーパラメータの値を定義する必要があります。
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
ハイパーパラメータを定義したら、for loop を利用してパイプラインのさまざまな実行を正常にフィードできます。
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
ステップ 5: Vertex AI SDK を利用してテストを表示する
Vertex AI SDK を使用すると、パイプライン実行のステータスをモニタリングできます。また、Vertex AI Experiments でパイプライン実行のパラメータと指標を返す場合にも使用できます。次のコードを使用して、実行に関連付けられたパラメータとその現在の状態を確認します。
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
以下のコードを使用すると、パイプライン実行のステータスに関する最新情報を取得できます。
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
run_name を使用して特定のパイプライン ジョブを呼び出すこともできます。
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
最後に、設定した間隔(60 秒ごとなど)で実行の状態を更新して、状態が RUNNING から FAILED または COMPLETE に変わるのを確認できます。
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. パフォーマンスが最も高い実行を特定する
これでパイプライン実行の結果が出ました。「結果から何がわかるか?」と疑問に思われるかもしれません。テストの出力には、パイプラインの実行ごとに 1 行、合計 5 行が表示されます。次のようになります。

MAE と RMSE はどちらも平均モデル予測誤差の尺度であるため、両方の指標の値を小さくするのが理想的です。Vertex AI Experiments の出力から、両方の指標で最もパフォーマンスの高い実行は最後の実行で、dropout_rate が 0.001、learning_rate が 0.001、epochs の合計数が 20 であることがわかります。このテストに基づいて、モデルの最適なパフォーマンスが得られるため、これらのモデル パラメータは最終的に本番環境で使用されます。
これでラボは終了です。
お疲れさまでした
Vertex AI を使って次のことを行う方法を学びました。
- カスタム Keras モデルをトレーニングして、プレーヤーの評価を予測する(回帰など)
- Kubeflow Pipelines SDK を使用してスケーラブルな ML パイプラインを構築する
- GCS からのデータの取り込み、データのスケーリング、モデルのトレーニング、評価、GCS へのモデルの再保存を行う 5 ステップのパイプラインを作成して実行する
- Vertex ML Metadata を利用して、モデルやモデルの指標などのモデル アーティファクトを保存する
- Vertex AI Experiments を使用して、さまざまなパイプライン実行の結果を比較する
Vertex のさまざまな部分の説明については、ドキュメントをご覧ください。
8. クリーンアップ
料金が発生しないようにするため、このラボで作成したリソースを削除することをおすすめします。
ステップ 1: Notebooks インスタンスを停止または削除する
このラボで作成したノートブックを引き続き使用する場合は、未使用時にオフにすることをおすすめします。Cloud コンソールの Notebooks UI で、ノートブックを選択して [停止] を選択します。インスタンスを完全に削除する場合は、[削除] を選択します。

ステップ 2: Cloud Storage バケットを削除する
ストレージ バケットを削除するには、Cloud コンソールのナビゲーション メニューで [ストレージ] に移動してバケットを選択し、[削除] をクリックします。
