
1. Visão geral
Neste laboratório, você vai usar a Vertex AI para criar um pipeline que treina um modelo personalizado do Keras no TensorFlow. Em seguida, vamos usar a nova funcionalidade disponível nos Experimentos da Vertex AI para rastrear e comparar execuções de modelos e identificar qual combinação de hiperparâmetros resulta no melhor desempenho.
Conteúdo do laboratório
Você vai aprender a:
- Treine um modelo personalizado do Keras para prever as classificações dos jogadores (por exemplo, regressão)
- usar o SDK do Kubeflow Pipelines para criar pipelines de ML escalonáveis;
- Criar e executar um pipeline de cinco etapas que ingere dados do Cloud Storage, escalona os dados, treina o modelo, avalia e salva o modelo resultante de volta no Cloud Storage
- usar o Vertex ML Metadata para salvar artefatos de modelo, como modelos e métricas
- Utilizar os Experimentos da Vertex AI para comparar os resultados das várias execuções de pipeline
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$ 1.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos para a Vertex AI.
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho integrais de ML. Os produtos destacados abaixo são o foco deste laboratório: Experimentos, Pipelines, Metadados de ML e Workbench.
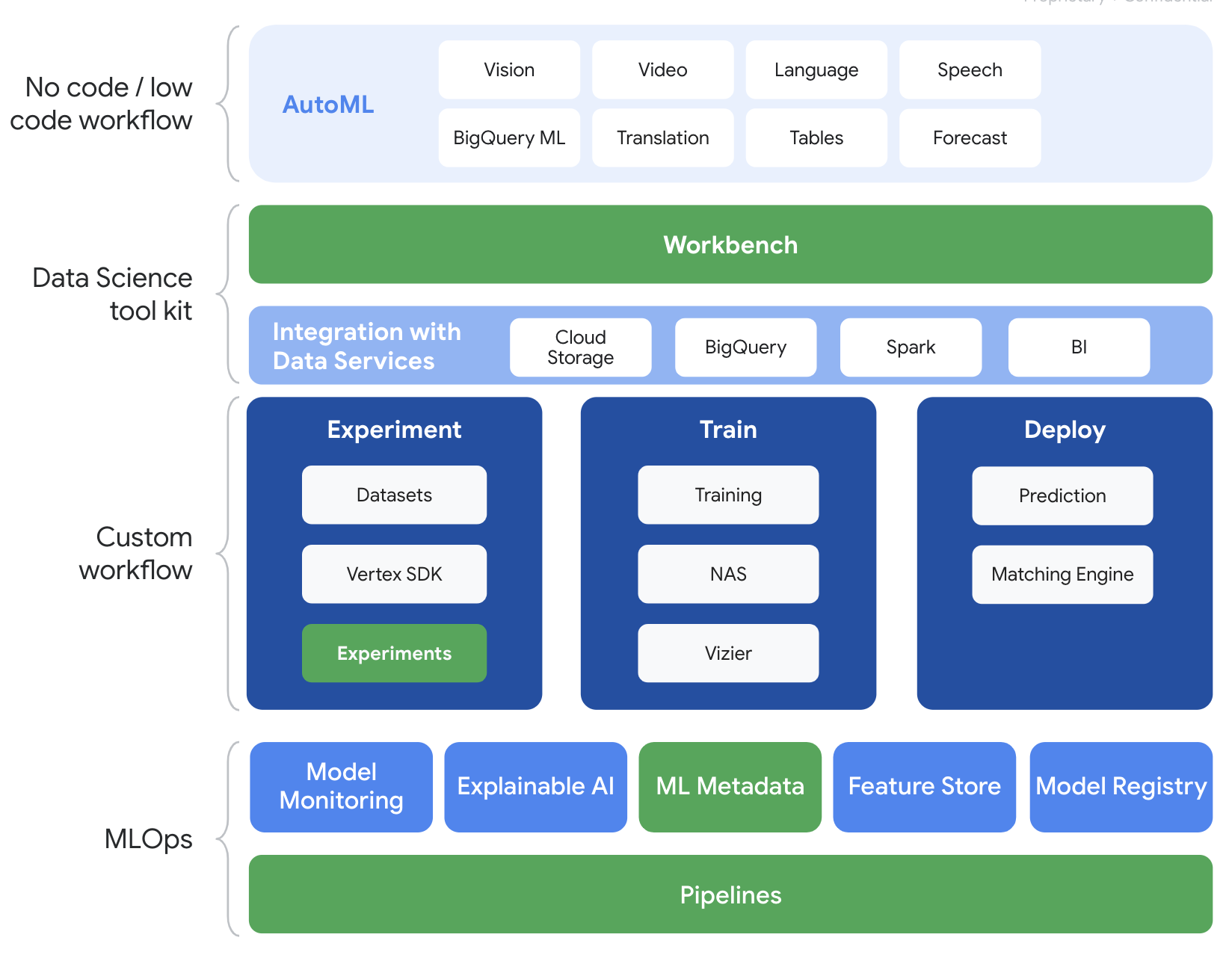
3. Visão geral do caso de uso
Usaremos um conjunto de dados de futebol conhecido da série de videogame FIFA da EA Sports. Ele inclui mais de 25 mil partidas de futebol e mais de 10 mil jogadores nas temporadas de 2008 a 2016. Os dados foram pré-processados com antecedência para que você possa começar a executar com mais facilidade. Você vai usar esse conjunto de dados em todo o laboratório, que agora pode ser encontrado em um bucket público do Cloud Storage. Vamos fornecer mais detalhes posteriormente no codelab sobre como acessar o conjunto de dados. Nosso objetivo final é prever a classificação geral de um jogador com base em várias ações no jogo, como interceptações e pênaltis.
Por que os Experimentos da Vertex AI são úteis para a ciência de dados?
A ciência de dados é experimental por natureza; afinal, eles são chamados de cientistas. Bons cientistas de dados são orientados por hipóteses, usando tentativa e erro para testar várias hipóteses com a esperança de que iterações sucessivas resultem em um modelo de melhor desempenho.
Embora as equipes de ciência de dados tenham abraçado a experimentação, muitas vezes elas têm dificuldade para monitorar seu trabalho e o "molho secreto" que foi descoberto por meio dos experimentos. Isso acontece por alguns motivos:
- Acompanhar os trabalhos de treinamento pode ser complicado, fazendo com que seja fácil perder de vista o que está funcionando e o que não está.
- Esse problema se agrava quando você olha para uma equipe de ciência de dados, pois nem todos os membros podem estar rastreando experimentos ou até mesmo compartilhar seus resultados com outras pessoas
- A captura de dados é demorada, e a maioria das equipes utiliza métodos manuais (por exemplo, planilhas ou documentos) que resultam em informações inconsistentes e incompletas para aprender.
tl;dr: Os Experimentos da Vertex AI fazem o trabalho por você, ajudando a rastrear e comparar seus experimentos com mais facilidade
Por que usar os Experimentos da Vertex AI para Jogos?
Historicamente, os jogos têm sido um playground para machine learning e experimentos de ML. Os jogos não só produzem bilhões de eventos em tempo real por dia, como também usam todos esses dados com experimentos de ML e ML para melhorar experiências, reter jogadores e avaliar diferentes jogadores na plataforma deles. Por isso, achamos que um conjunto de dados de jogos seria adequado para nosso exercício geral de experimentos.
4. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 1: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada.
Etapa 2: ativar a API Vertex AI
Navegue até a seção "Vertex AI" do Console do Cloud e clique em Ativar API Vertex AI.

Etapa 3: criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":

Ative a API Notebooks, se ela ainda não tiver sido ativada.

Após a ativação, clique em NOTEBOOK GERENCIADO:

Em seguida, selecione NOVO NOTEBOOK.

Dê um nome ao notebook e clique em Configurações avançadas.

Em "Configurações avançadas", ative o encerramento inativo e defina o número de minutos como 60. Isso significa que o notebook será desligado automaticamente quando não estiver sendo usado.

Etapa 4: abrir seu notebook
Quando a instância tiver sido criada, selecione Abrir o JupyterLab.

Etapa 5: autenticar (apenas na primeira vez)
Na primeira vez que usar uma nova instância, você vai receber uma solicitação de autenticação. Siga as etapas na IU para isso.

Etapa 6: selecionar o kernel apropriado
Os notebooks gerenciados oferecem vários kernels em uma única interface. Selecione o kernel para o Tensorflow 2 (local).

5. Etapas iniciais de configuração no notebook
Você precisará executar uma série de etapas adicionais para configurar o ambiente no notebook antes de criar o pipeline. Essas etapas incluem: instalar quaisquer pacotes adicionais, definir variáveis, criar seu bucket do Cloud Storage, copiar o conjunto de dados de jogos de um bucket de armazenamento público e importar bibliotecas e definir outras constantes.
Etapa 1: instalar pacotes adicionais
Vamos precisar instalar outras dependências de pacotes que ainda não estão instaladas no seu ambiente de notebook. Um exemplo inclui o SDK do KFP.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
Reinicie o kernel do notebook para usar os pacotes transferidos.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Etapa 2: definir variáveis
Queremos definir nossa PROJECT_ID. Se você não sabe o Project_ID, pode acessar o PROJECT_ID usando a gcloud.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Caso contrário, defina o PROJECT_ID aqui.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
Também vamos definir a variável REGION, que é usada no restante deste notebook. Abaixo estão as regiões compatíveis com a Vertex AI. Recomendamos escolher a região mais próxima de você.
- Américas: us-central1
- Europa: europe-west4
- Ásia-Pacífico: asia-east1
Não use um bucket multirregional para treinar com a Vertex AI. Nem todas as regiões são compatíveis com todos os serviços da Vertex AI. Saiba mais sobre as regiões da Vertex AI.
#set your region
REGION = "us-central1" # @param {type: "string"}
Por fim, vamos definir uma variável TIMESTAMP. Essas variáveis são usadas para evitar conflitos de nome entre usuários nos recursos criados. Crie um TIMESTAMP para cada sessão de instância e anexe-o ao nome dos recursos criados neste tutorial.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Etapa 3: criar um bucket do Cloud Storage
Você precisará especificar e utilizar um bucket de preparação do Cloud Storage. Todos os dados associados ao conjunto de dados e aos recursos do modelo são retidos nas sessões no bucket de preparo.
Defina o nome do bucket do Cloud Storage abaixo. Os nomes dos buckets precisam ser globalmente exclusivos em todos os projetos do Google Cloud, inclusive os de fora da sua organização.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
Se o bucket NÃO existir, execute a célula a seguir para criar o bucket do Cloud Storage.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Em seguida, verifique o acesso ao bucket do Cloud Storage executando a célula a seguir.
#verify access
! gsutil ls -al $BUCKET_URI
Etapa 4: copiar nosso conjunto de dados de jogos
Como mencionado anteriormente, você usará um conjunto de dados de jogos de sucesso da EA Sports, o FIFA. Fizemos o pré-processamento para você. Basta copiar o conjunto de dados do bucket de armazenamento público e movê-lo para o que você criou.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
Etapa 5: importar bibliotecas e definir outras constantes
Em seguida, vamos importar nossas bibliotecas para Vertex AI, KFP e assim por diante.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
Também definiremos outras constantes que serão consultadas no restante do notebook, como o(s) caminho(s) de arquivo para nossos dados de treinamento.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. Vamos criar nosso pipeline
A diversão começa agora, e podemos começar a usar a Vertex AI para criar nosso pipeline de treinamento. Vamos inicializar o SDK da Vertex AI, configurar o job de treinamento como um componente do pipeline, criar o pipeline, enviar as execuções de pipeline e aproveitar o SDK da Vertex AI para visualizar experimentos e monitorar o status deles.
Etapa 1: inicializar o SDK da Vertex AI
Inicialize o SDK da Vertex AI, definindo PROJECT_ID e BUCKET_URI.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
Etapa 2: configurar o job de treinamento como um componente do pipeline
Para começar a executar os experimentos, precisamos especificar o job de treinamento, definindo-o como um componente do pipeline. Nosso pipeline vai receber dados de treinamento e hiperparâmetros (por exemplo, DROPOUT_RATE, LEARNING_RATE, EPOCHS) como métricas de modelo de entrada e saída (por exemplo, MAE e RMSE) e um artefato de modelo.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
Etapa 3: criar nosso pipeline
Agora vamos configurar nosso fluxo de trabalho usando o Domain Specific Language (DSL) disponível no KFP e compilar o pipeline em um arquivo JSON.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
Etapa 4: enviar as execuções do pipeline
O trabalho árduo é feito a configuração do componente e a definição do pipeline. Estamos prontos para enviar várias execuções do pipeline que especificamos acima. Para fazer isso, precisamos definir os valores para nossos diferentes hiperparâmetros da seguinte maneira:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
Com os hiperparâmetros definidos, podemos aproveitar um for loop para alimentar com sucesso as diferentes execuções do pipeline:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
Etapa 5: usar o SDK da Vertex AI para conferir os experimentos
O SDK da Vertex AI permite monitorar o status das execuções de pipeline. Ele também pode ser usado para retornar parâmetros e métricas das execuções de pipelines no experimento da Vertex AI. Use o código abaixo para conferir os parâmetros associados às suas execuções e o estado atual delas.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
Use o código abaixo para receber atualizações sobre o status das execuções do pipeline.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
Também é possível chamar jobs específicos do pipeline usando o run_name.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
Por fim, é possível atualizar o estado das execuções em intervalos definidos (por exemplo, a cada 60 segundos) para ver os estados mudarem de RUNNING para FAILED ou COMPLETE.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. Identifique a corrida com melhor desempenho
Ótimo, agora temos os resultados das nossas execuções de pipeline. Você pode estar se perguntando o que pode aprender com os resultados. A saída dos experimentos precisa conter cinco linhas, uma para cada execução do pipeline. A aparência será semelhante a esta:

Tanto o MAE quanto a REQM são medidas do erro médio de previsão do modelo. Portanto, na maioria dos casos, é desejável um valor menor para as duas métricas. Com base na saída dos Experimentos da Vertex AI, a execução mais bem-sucedida em ambas as métricas foi a execução final com dropout_rate de 0,001, learning_rate se 0,001 e o número total de epochs sendo 20. Com base nesse experimento, os parâmetros do modelo vão ser usados na produção porque resultam no melhor desempenho.
Com isso, você concluiu o laboratório.
Parabéns! 🎉
Você aprendeu a usar a Vertex AI para:
- Treine um modelo personalizado do Keras para prever as classificações dos jogadores (por exemplo, regressão)
- usar o SDK do Kubeflow Pipelines para criar pipelines de ML escalonáveis;
- Criar e executar um pipeline de cinco etapas que ingere dados do GCS, escalona os dados, treina o modelo, avalia e salva o modelo resultante de volta no GCS.
- usar o Vertex ML Metadata para salvar artefatos de modelo, como modelos e métricas
- Utilizar os Experimentos da Vertex AI para comparar os resultados das várias execuções de pipeline
Para saber mais sobre as diferentes partes da Vertex, consulte a documentação.
8. Limpeza
Para não receber cobranças, recomendamos que você exclua os recursos criados neste laboratório.
Etapa 1: interromper ou excluir a instância de Notebooks
Se você quiser continuar usando o notebook que criou neste laboratório, é recomendado que você o desligue quando não estiver usando. A partir da interface de Notebooks no seu Console do Cloud, selecione o notebook e depois clique em Parar. Para excluir a instância completamente, selecione Excluir:

Etapa 2: excluir o bucket do Cloud Storage
Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em "Excluir":
