
1. 概览
在本实验中,您将使用 Vertex AI 构建一个流水线,用于在 TensorFlow 中训练自定义 Keras 模型。然后,我们将使用 Vertex AI 实验中提供的新功能来跟踪和比较模型运行情况,以确定哪些超参数组合可带来最佳性能。
学习内容
您将了解如何:
- 训练自定义 Keras 模型以预测玩家评分(例如回归)
- 使用 Kubeflow Pipelines SDK 构建可扩缩的机器学习流水线
- 创建并运行包含 5 个步骤的流水线,用于从 Cloud Storage 中提取数据、扩缩数据、训练模型、对其进行评估并将生成的模型保存回 Cloud Storage
- 利用 Vertex ML Metadata 保存模型和模型指标等模型制品
- 利用 Vertex AI 实验来比较各种流水线运行的结果
在 Google Cloud 上运行本实验的总费用约为 $1。
2. Vertex AI 简介
本实验使用的是 Google Cloud 上提供的最新 AI 产品。Vertex AI 将整个 Google Cloud 的机器学习产品集成到无缝的开发体验中。以前,使用 AutoML 训练的模型和自定义模型是通过不同的服务访问的。现在,该新产品与其他新产品一起将这两种模型合并到一个 API 中。您还可以将现有项目迁移到 Vertex AI。
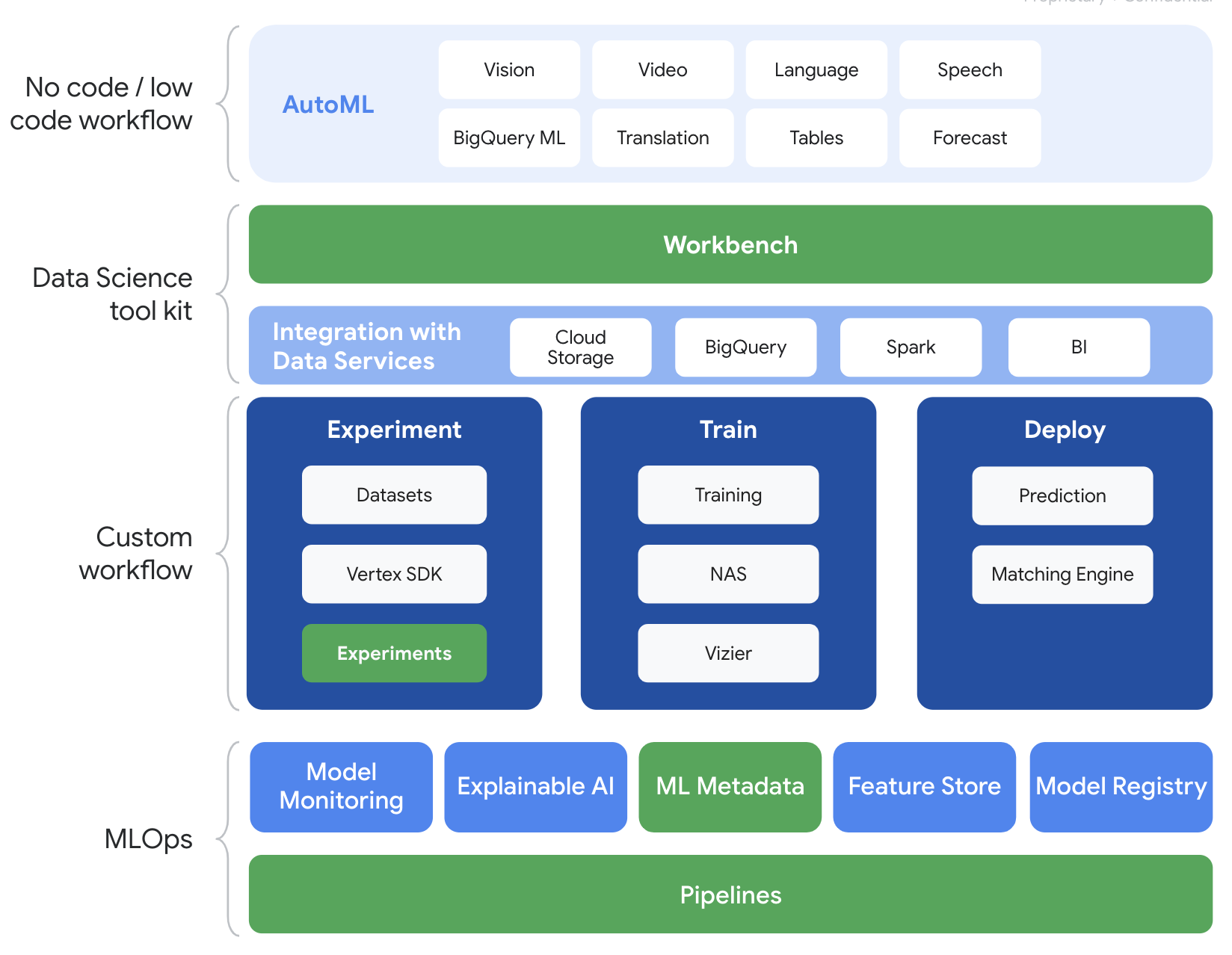
Vertex AI 包含许多不同的产品,可支持端到端机器学习工作流。本实验将重点介绍下面重点展示的产品:实验、流水线、机器学习元数据和 Workbench
3. 用例概览
我们将使用来自 EA Sports'FIFA 视频游戏系列。其中包括 2008-2016 赛季的 25,000 多场足球比赛和 10,000 多名球员。数据已预先经过预处理,因此您可以更轻松地着手使用。在整个实验过程中,您将用到此数据集,它现在可以在公开的 Cloud Storage 存储分区中找到。我们稍后会在此 Codelab 中详细介绍如何访问数据集。我们的最终目标是根据球员在比赛中的各种行为(例如截球和罚球)来预测其总体评分。
Vertex AI 实验对数据科学有何帮助?
数据科学本质上是实验性的,毕竟他们被称为科学家。优秀的数据科学家要以假设为导向,通过试错法来测试各种假设,并希望通过连续迭代后能产生性能更高的模型。
虽然数据科学团队已开始接受实验,但他们往往很难跟踪自己的工作以及通过实验发现的“秘诀”。导致这种情况的原因有以下几种:
- 跟踪训练作业可能会很麻烦,因此很容易分不清哪些是有效的,哪些没有
- 考虑到数据科学团队的情况,这个问题会比较复杂,因为并非所有成员都在跟踪实验,甚至可能与他人分享实验结果
- 获取数据非常耗时,大多数团队会采用手动方法(如表格或文档),导致学习信息不一致且不完整
tl;dr::Vertex AI 实验可为您代劳,帮助您更轻松地跟踪和比较实验
为何要选择适用于游戏的 Vertex AI 实验?
游戏历来都是机器学习和机器学习实验的游乐场。游戏不仅每天生成数十亿个实时活动,还会利用这些数据,通过利用机器学习和机器学习实验来改善游戏内体验、留住玩家以及评估平台上的不同玩家。因此,我们认为游戏数据集与我们的整体实验练习非常契合。
4. 设置您的环境
您需要一个启用了结算功能的 Google Cloud Platform 项目才能运行此 Codelab。如需创建项目,请按照此处的说明操作。
第 1 步:启用 Compute Engine API
前往 Compute Engine,然后选择启用(如果尚未启用)。
第 2 步:启用 Vertex AI API
前往 Cloud Console 的 Vertex AI 部分,然后点击启用 Vertex AI API。

第 3 步:创建 Vertex AI Workbench 实例
在 Cloud Console 的 Vertex AI 部分中,点击“Workbench”:

启用 Notebooks API(如果尚未启用)。

启用后,点击代管式笔记本:

然后选择新建笔记本。

为您的笔记本命名,然后点击高级设置。

在“高级设置”下,启用空闲关闭,并将分钟数设置为 60。这意味着,您的笔记本处于未使用状态时会自动关闭,以免产生不必要的费用。

第 4 步:打开笔记本
创建实例后,选择打开 JupyterLab。

第 5 步:进行身份验证(仅限首次)
首次使用新实例时,系统会要求您进行身份验证。为此,请按照界面中的步骤操作。

第 6 步:选择相应的内核
托管式笔记本在单个界面中提供多个内核。选择 TensorFlow 2 的内核(本地)。

5. 在 Notebook 中执行初始设置步骤
在构建流水线之前,您需要执行一系列额外步骤在笔记本中设置环境。这些步骤包括:安装任何其他软件包、设置变量、创建 Cloud Storage 存储分区、从公共存储分区复制游戏数据集、导入库并定义其他常量。
第 1 步:安装其他软件包
我们需要安装您的笔记本环境中当前未安装的其他软件包依赖项。例如,KFP SDK。
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
然后,您需要重启笔记本内核,以便在笔记本中使用下载的软件包。
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
第 2 步:设置变量
我们想要定义 PROJECT_ID。如果您不知道 Project_ID,或许可以使用 gcloud 获取 PROJECT_ID。
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
否则,请在此处设置您的 PROJECT_ID。
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
我们还需要设置 REGION 变量,该变量将在此笔记本的其余部分中使用。以下是 Vertex AI 支持的区域。我们建议您选择离您最近的区域。
- 美洲:us-central1
- 欧洲:europe-west4
- 亚太地区:asia-east1
请勿使用多区域存储分区进行 Vertex AI 训练。并非所有区域都支持所有 Vertex AI 服务。详细了解 Vertex AI 区域。
#set your region
REGION = "us-central1" # @param {type: "string"}
最后,我们将设置 TIMESTAMP 变量。此变量用于避免创建的资源在用户之间发生名称冲突,您可以为每个实例会话创建一个 TIMESTAMP,并将其附加到您在本教程中创建的资源名称上。
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
第 3 步:创建 Cloud Storage 存储分区
您需要指定并使用 Cloud Storage 暂存桶。在暂存存储分区中,与数据集和模型资源相关联的所有数据都会跨会话保留。
在下面设置 Cloud Storage 存储桶的名称。存储分区名称在所有 Google Cloud 项目(包括组织外部的项目)中必须是全局唯一的。
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
如果您的存储分区尚不存在,您可以运行以下单元来创建您的 Cloud Storage 存储分区。
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
然后,您可以运行以下单元来验证对 Cloud Storage 存储分区的访问权限。
#verify access
! gsutil ls -al $BUCKET_URI
第 4 步:复制游戏数据集
如前所述,您将使用来自 EA Sports 热门视频游戏《FIFA》的热门游戏数据集。我们已为您完成预处理工作,因此您只需从公共存储分区复制数据集,然后将其移至您已创建的存储分区中即可。
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
第 5 步:导入库并定义其他常量
接下来,我们需要导入 Vertex AI、KF 等的库。
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
我们还将定义可在笔记本的其余部分引用的其他常量,例如训练数据的文件路径。
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. 我们来建立销售漏斗
接下来,我们就可以开始利用 Vertex AI 构建训练流水线了。我们将初始化 Vertex AI SDK,将训练作业设置为流水线组件,构建流水线,提交流水线运行作业,并利用 Vertex AI SDK 查看实验并监控实验状态。
第 1 步:初始化 Vertex AI SDK
初始化 Vertex AI SDK,并设置 PROJECT_ID 和 BUCKET_URI。
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
第 2 步:将训练作业设置为流水线组件
为了开始运行实验,我们需要将训练作业定义为流水线组件,以指定该作业。我们的流水线将接受训练数据和超参数(例如,DROPOUT_RATE、LEARNING_RATE、EPOCHS)作为输入,并输出模型指标(例如MAE 和 RMSE)以及模型工件。
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
第 3 步:建立销售漏斗
现在,我们将使用 KFP 中提供的 Domain Specific Language (DSL) 设置工作流,并将流水线编译到 JSON 文件中。
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
第 4 步:提交我们的流水线运行作业
最困难的工作是设置组件和定义流水线。我们已准备好提交上面指定的流水线的各种运行作业。为此,我们需要定义不同超参数的值,如下所示:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
定义超参数后,我们可以利用 for loop 成功馈送流水线的不同运行作业:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
第 5 步:利用 Vertex AI SDK 查看实验
借助 Vertex AI SDK,您可以监控流水线运行的状态。您还可以使用它返回 Vertex AI 实验中的流水线运行参数和指标。使用以下代码可查看与运行相关的参数及其当前状态。
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
您可以利用以下代码获取流水线运行状态的最新动态。
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
您还可以使用 run_name 调用特定的流水线作业。
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
最后,您可以按设定的间隔(例如每 60 秒)刷新运行状态,以查看状态从 RUNNING 更改为 FAILED 或 COMPLETE。
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. 确定效果最佳的运行作业
太棒了,我们现在有流水线运行的结果了。您可能会问,我能从结果中学到什么?实验的输出应该包含五行,流水线的每次运行各占一行。该代码将如下所示:

MAE 和 RMSE 都是对平均模型预测误差的度量,因此在大多数情况下,最好为这两个指标设置较低的值。根据 Vertex AI 实验的输出结果,我们可以在这两个指标上最成功的运行结果是最终运行:dropout_rate 为 0.001,learning_rate 为 0.001,epochs 总数为 20。根据此实验,这些模型参数最终将用于生产环境,因为这样可以获得最佳模型性能。
至此,您已完成本实验!
🎉 恭喜!🎉
您学习了如何使用 Vertex AI 执行以下操作:
- 训练自定义 Keras 模型以预测玩家评分(例如回归)
- 使用 Kubeflow Pipelines SDK 构建可扩缩的机器学习流水线
- 创建并运行包含 5 个步骤的流水线,用于从 GCS 中提取数据、扩缩数据、训练模型、对其进行评估并将生成的模型保存回 GCS
- 利用 Vertex ML Metadata 保存模型和模型指标等模型制品
- 利用 Vertex AI 实验来比较各种流水线运行的结果
如需详细了解 Vertex 的不同部分,请参阅相关文档。
8. 清理
为了不向您收费,因此建议您删除在整个实验过程中创建的资源。
第 1 步:停止或删除 Notebooks 实例
如果您想继续使用在本实验中创建的笔记本,建议您在不使用时将其关闭。在 Cloud 控制台的 Notebooks 界面中,选择相应笔记本,然后选择停止。如果您想完全删除实例,请选择删除:

第 2 步:删除 Cloud Storage 存储分区
如需删除存储桶,请使用 Cloud Console 中的导航菜单,浏览到“存储空间”,选择您的存储桶,然后点击“删除”:
