
1. Descripción general
En este lab, usarás Vertex AI para compilar una canalización que entrene un modelo de Keras personalizado en TensorFlow. Luego, usaremos la nueva funcionalidad disponible en Vertex AI Experiments para hacer un seguimiento y comparar las ejecuciones del modelo, y así identificar qué combinación de hiperparámetros da como resultado el mejor rendimiento.
Qué aprenderá
Aprenderás a hacer lo siguiente:
- Entrena un modelo personalizado de Keras para predecir las calificaciones de los jugadores (p.ej., regresión)
- Usar el SDK de canalizaciones de Kubeflow para compilar canalizaciones de AA escalables
- Crear y ejecutar una canalización de 5 pasos que transfiera datos de Cloud Storage, los ajuste, entrene el modelo, lo evalúe y guarde el modelo resultante en Cloud Storage
- Aprovecha Vertex ML Metadata para guardar artefactos del modelo, como modelos y métricas del modelo
- Utiliza Vertex AI Experiments para comparar los resultados de las distintas ejecuciones de canalizaciones
El costo total de la ejecución de este lab en Google Cloud es de aproximadamente $1.
2. Introducción a Vertex AI
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puedes migrar proyectos existentes a Vertex AI.
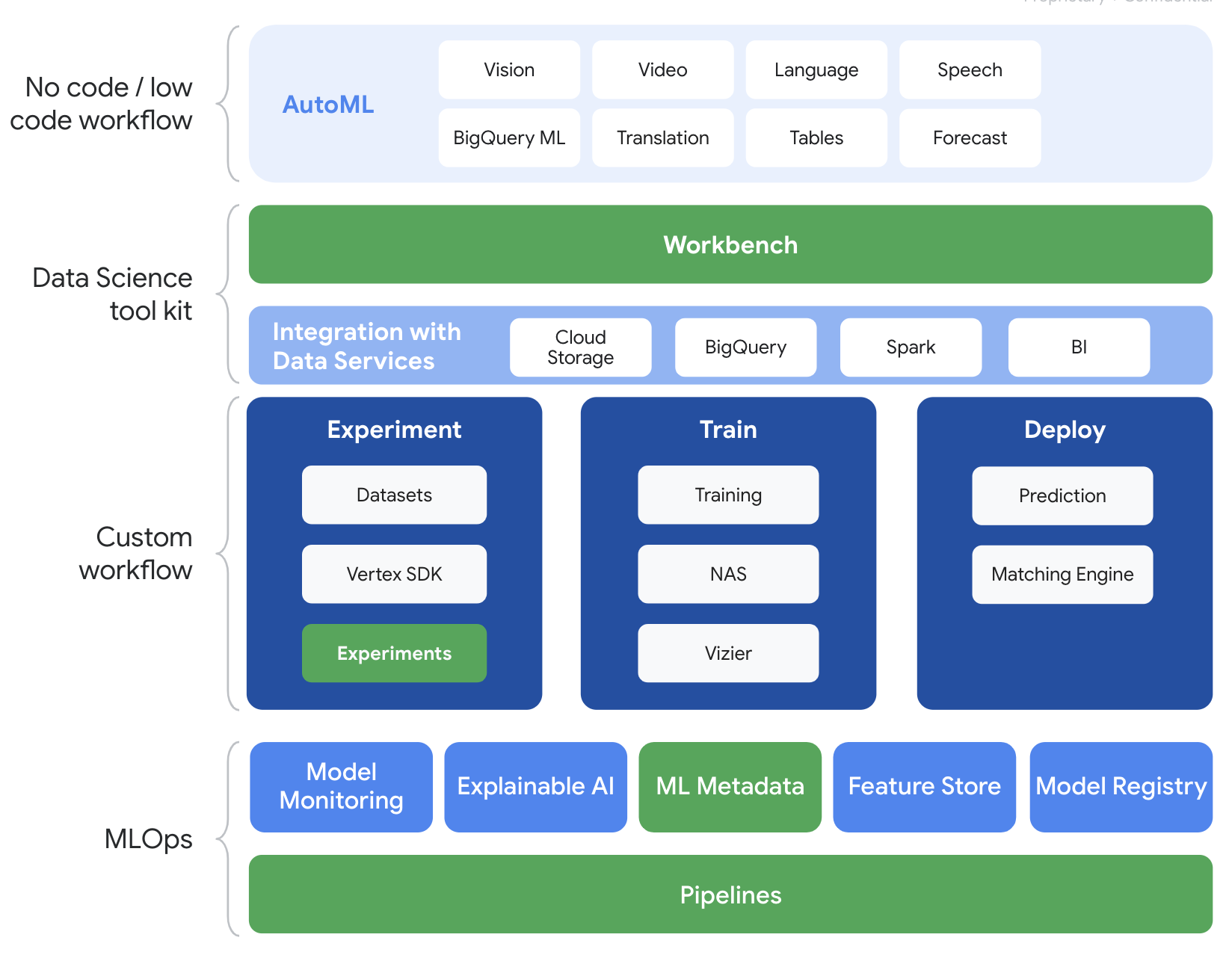
Vertex AI incluye muchos productos distintos para respaldar flujos de trabajo de AA de extremo a extremo. Este lab se enfocará en los productos que se destacan a continuación: Experiments, Pipelines, ML Metadata y Workbench
3. Descripción general del caso de uso
Usaremos un conjunto de datos de fútbol popular proveniente de la serie de videojuegos FIFA de EA Sports. Incluye más de 25,000 partidos de fútbol y más de 10,000 jugadores para las temporadas 2008-2016. Los datos se procesaron previamente para que puedas comenzar a trabajar más fácilmente. Usarás este conjunto de datos a lo largo del lab, que ahora se encuentra en un bucket público de Cloud Storage. Más adelante en el codelab, proporcionaremos más detalles para acceder al conjunto de datos. Nuestro objetivo final es predecir la calificación general de un jugador en función de varias acciones en el juego, como intercepciones y penalidades.
¿Por qué Vertex AI Experiments es útil para la ciencia de datos?
La ciencia de datos es experimental por naturaleza (después de todo, se les llama científicos). Los buenos científicos de datos se basan en hipótesis y usan el método de prueba y error para probar varias hipótesis con la esperanza de que las iteraciones sucesivas generen un modelo con mejor rendimiento.
Si bien los equipos de ciencia de datos adoptaron la experimentación, a menudo tienen dificultades para hacer un seguimiento de su trabajo y de la "fórmula secreta" que descubrieron a través de sus esfuerzos de experimentación. Esto sucede por los siguientes motivos:
- El seguimiento de los trabajos de entrenamiento puede volverse engorroso, lo que dificulta saber qué funciona y qué no.
- Este problema se agrava cuando se analiza un equipo de ciencia de datos, ya que no todos los miembros pueden hacer un seguimiento de los experimentos ni compartir sus resultados con otros.
- La captura de datos lleva mucho tiempo, y la mayoría de los equipos aprovechan los métodos manuales (p. ej., hojas o documentos) que generan información incoherente e incompleta para aprender.
En resumen: Vertex AI Experiments hace el trabajo por ti y te ayuda a hacer un seguimiento de tus experimentos y compararlos con mayor facilidad.
¿Por qué usar Vertex AI Experiments para juegos?
Históricamente, los videojuegos han sido un campo de pruebas para el aprendizaje automático y los experimentos de AA. Los juegos no solo producen miles de millones de eventos en tiempo real por día, sino que también aprovechan todos esos datos con el AA y los experimentos de AA para mejorar las experiencias en el juego, retener a los jugadores y evaluar a los diferentes jugadores en su plataforma. Por lo tanto, pensamos que un conjunto de datos de juegos se ajustaba bien a nuestro ejercicio general de experimentos.
4. Configura el entorno
Para ejecutar este codelab, necesitarás un proyecto de Google Cloud Platform que tenga habilitada la facturación. Para crear un proyecto, sigue estas instrucciones.
Paso 1: Habilita la API de Compute Engine
Ve a Compute Engine y selecciona Habilitar (si aún no está habilitada).
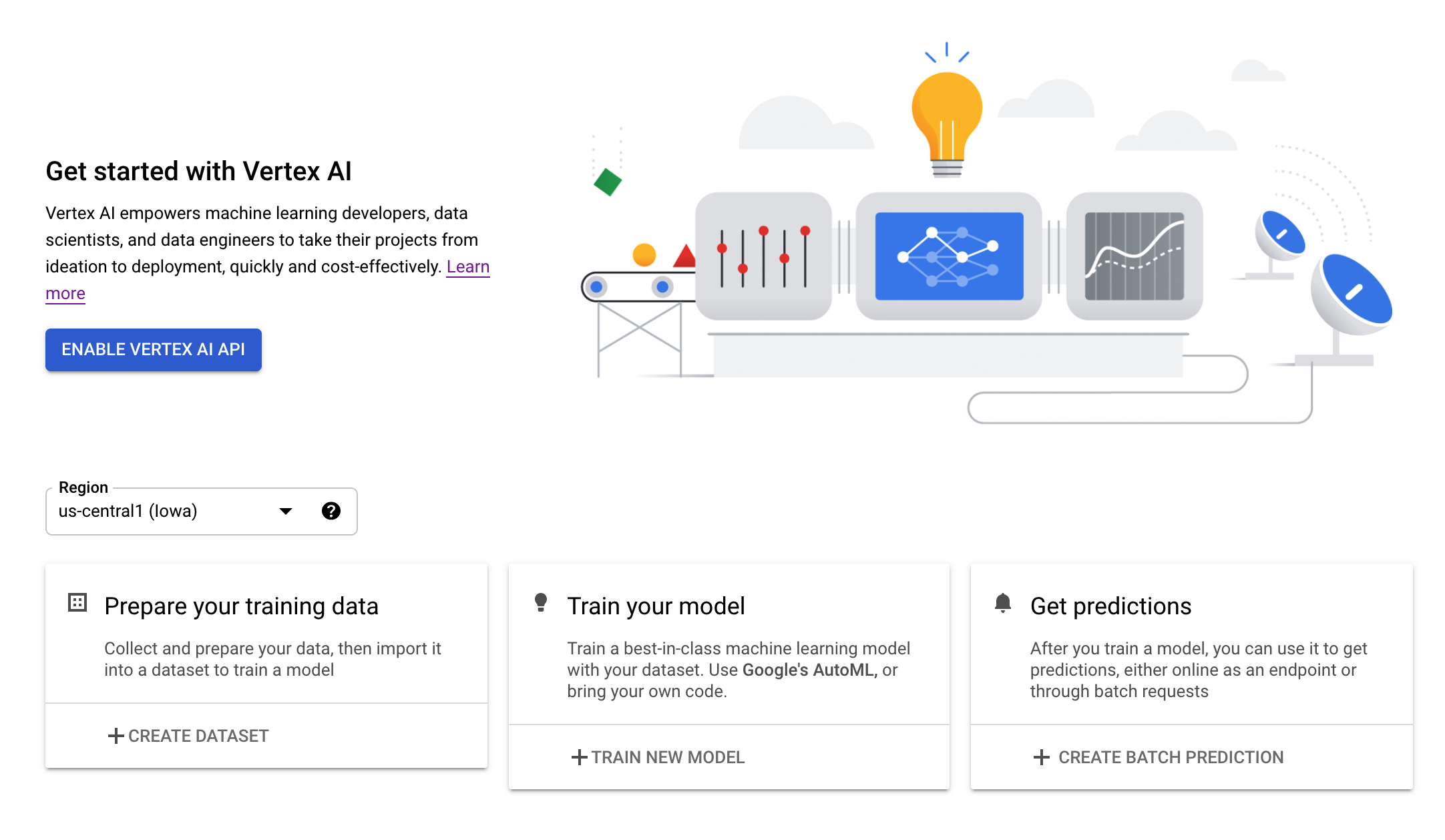
Paso 2: Habilita la API de Vertex AI
Navegue hasta la sección de Vertex AI en la consola de Cloud y haga clic en Habilitar API de Vertex AI.
Paso 3: Crea una instancia de Vertex AI Workbench
En la sección Vertex AI de Cloud Console, haz clic en Workbench:

Habilita la API de Notebooks si aún no está habilitada.

Una vez habilitada, haz clic en NOTEBOOKS ADMINISTRADOS (MANAGED NOTEBOOKS):

Luego, selecciona NUEVO NOTEBOOK (NEW NOTEBOOK).

Asígnale un nombre al notebook y, luego, haz clic en Configuración avanzada (Advanced settings).

En Configuración avanzada (Advanced settings), activa la opción Habilitar el cierre inactivo (Enable Idle Shutdown) y establece la cantidad de minutos en 60. Esto provocará que el notebook se cierre automáticamente cuando no esté en uso para que no se generen costos innecesarios.

Paso 4: Abre tu notebook
Una vez que se crea la instancia, selecciona Abrir JupyterLab (Open JupyterLab).

Paso 5: Autentica (solo la primera vez)
La primera vez que uses una instancia nueva, se te solicitará que te autentiques. Sigue los pasos en la IU para hacerlo.

Paso 6: Selecciona el kernel adecuado
Los notebooks administrados proporcionan varios kernels en una sola IU. Selecciona el kernel para TensorFlow 2 (local).

5. Pasos iniciales para la configuración en tu notebook
Deberás seguir una serie de pasos adicionales para configurar tu entorno en el notebook antes de crear tu canalización. Estos pasos incluyen la instalación de paquetes adicionales, la configuración de variables, la creación de tu bucket de Cloud Storage, la copia del conjunto de datos de juegos desde un bucket de almacenamiento público, y la importación de bibliotecas y la definición de constantes adicionales.
Paso 1: Instala paquetes adicionales
Deberemos instalar dependencias de paquetes adicionales que no están instaladas actualmente en tu entorno de notebook. Un ejemplo incluye el SDK de KFP.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
Luego, deberás reiniciar el kernel del notebook para poder usar los paquetes descargados en él.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Paso 2: Establece variables
Queremos definir nuestro PROJECT_ID. Si no conoces tu Project_ID, es posible que puedas obtener tu PROJECT_ID con gcloud.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
De lo contrario, configura tu PROJECT_ID aquí.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
También deberemos establecer la variable REGION, que se usa en el resto de este notebook. A continuación, se indican las regiones compatibles con Vertex AI. Te recomendamos que elijas la región más cercana a ti.
- América: us-central1
- Europa: europe-west4
- Asia Pacífico: asia-east1
No utilices un bucket multirregional para el entrenamiento con Vertex AI. No todas las regiones admiten todos los servicios de Vertex AI. Obtén más información sobre las regiones de Vertex AI.
#set your region
REGION = "us-central1" # @param {type: "string"}
Por último, estableceremos una variable TIMESTAMP. Esta variable se usa para evitar conflictos de nombres entre los usuarios en los recursos creados. Crea un TIMESTAMP para cada sesión de instancia y agrégalo al nombre de los recursos que crees en este instructivo.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Paso 3: Crea un bucket de Cloud Storage
Deberás especificar y aprovechar un bucket de Cloud Storage para la etapa de pruebas. El bucket de etapa de pruebas es donde se conservan todos los datos asociados con tu conjunto de datos y los recursos del modelo en todas las sesiones.
A continuación, establece el nombre del bucket de Cloud Storage. Los nombres de los buckets deben ser únicos a nivel global en todos los proyectos de Google Cloud, incluso aquellos fuera de tu organización.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
Si tu bucket AÚN NO existe, puedes ejecutar la siguiente celda para crear tu bucket de Cloud Storage.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Luego, puedes verificar el acceso a tu bucket de Cloud Storage ejecutando la siguiente celda.
#verify access
! gsutil ls -al $BUCKET_URI
Paso 4: Copia nuestro conjunto de datos de juegos
Como se mencionó anteriormente, utilizarás un conjunto de datos de juegos populares de los videojuegos exitosos de EA Sports, FIFA. Ya hicimos el trabajo de preprocesamiento por ti, por lo que solo tendrás que copiar el conjunto de datos del bucket de almacenamiento público y transferirlo al que creaste.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
Paso 5: Importa bibliotecas y define constantes adicionales
A continuación, importaremos nuestras bibliotecas para Vertex AI, KFP, etcétera.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
También definiremos constantes adicionales a las que haremos referencia durante el resto del notebook, como las rutas de acceso a nuestros datos de entrenamiento.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. Creemos nuestra canalización
Ahora puede comenzar la diversión y podemos aprovechar Vertex AI para crear nuestra canalización de entrenamiento. Inicializaremos el SDK de Vertex AI, configuraremos nuestro trabajo de entrenamiento como un componente de la canalización, compilaremos nuestra canalización, enviaremos nuestras ejecuciones de canalización y aprovecharemos el SDK de Vertex AI para ver los experimentos y supervisar su estado.
Paso 1: Inicializa el SDK de Vertex AI
Inicializa el SDK de Vertex AI y configura tus PROJECT_ID y BUCKET_URI.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
Paso 2: Configura nuestro trabajo de entrenamiento como un componente de canalización
Para comenzar a ejecutar nuestros experimentos, deberemos especificar nuestro trabajo de entrenamiento definiéndolo como un componente de canalización. Nuestra canalización tomará los datos de entrenamiento y los hiperparámetros (p.ej., DROPOUT_RATE, LEARNING_RATE, EPOCHS) como entradas y generará métricas del modelo (p.ej., MAE y RMSE) y un artefacto del modelo.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
Paso 3: Compila nuestra canalización
Ahora configuraremos nuestro flujo de trabajo con Domain Specific Language (DSL) disponible en KFP y compilaremos nuestra canalización en un archivo JSON.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
Paso 4: Envía nuestras ejecuciones de canalización
El trabajo arduo ya se realizó con la configuración de nuestro componente y la definición de nuestra canalización. Estamos listos para enviar varias ejecuciones de la canalización que especificamos anteriormente. Para ello, deberemos definir los valores de nuestros diferentes hiperparámetros de la siguiente manera:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
Con los hiperparámetros definidos, podemos aprovechar un for loop para ingresar correctamente las diferentes ejecuciones de la canalización:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
Paso 5: Aprovecha el SDK de Vertex AI para ver experimentos
El SDK de Vertex AI te permite supervisar el estado de las ejecuciones de canalizaciones. También puedes usarlo para devolver parámetros y métricas de las ejecuciones de canalizaciones en el experimento de Vertex AI. Usa el siguiente código para ver los parámetros asociados con tus ejecuciones y su estado actual.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
Puedes aprovechar el siguiente código para obtener actualizaciones sobre el estado de las ejecuciones de tu canalización.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
También puedes llamar a trabajos de canalización específicos con run_name.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
Por último, puedes actualizar el estado de tus ejecuciones en intervalos establecidos (por ejemplo, cada 60 segundos) para ver cómo cambian los estados de RUNNING a FAILED o COMPLETE.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. Identifica la ejecución con mejor rendimiento
Excelente. Ahora tenemos los resultados de las ejecuciones de nuestra canalización. Quizás te preguntes qué puedes aprender de los resultados. El resultado de tus experimentos debe contener cinco filas, una para cada ejecución de la canalización. Se verá de la siguiente manera:

Tanto el MAE como el RMSE son medidas del error promedio de predicción del modelo, por lo que, en la mayoría de los casos, es deseable un valor más bajo para ambas métricas. Según los resultados de Vertex AI Experiments, la ejecución más exitosa en ambas métricas fue la última, con un dropout_rate de 0.001, un learning_rate de 0.001 y una cantidad total de epochs de 20. Según este experimento, estos parámetros del modelo se usarían en producción, ya que generan el mejor rendimiento del modelo.
Con eso, terminaste el lab.
🎉 ¡Felicitaciones! 🎉
Aprendiste a usar Vertex AI para hacer lo siguiente:
- Entrena un modelo personalizado de Keras para predecir las calificaciones de los jugadores (p.ej., regresión)
- Usar el SDK de canalizaciones de Kubeflow para compilar canalizaciones de AA escalables
- Crea y ejecuta una canalización de 5 pasos que ingiere datos de GCS, los ajusta, entrena el modelo, lo evalúa y guarda el modelo resultante en GCS.
- Aprovecha Vertex ML Metadata para guardar artefactos del modelo, como modelos y métricas del modelo
- Utiliza Vertex AI Experiments para comparar los resultados de las distintas ejecuciones de canalizaciones
Para obtener más información sobre las distintas partes de Vertex, consulte la documentación.
8. Limpieza
Para que no se te cobre, te recomendamos que borres los recursos que creaste durante este lab.
Paso 1: Detén o borra tu instancia de Notebooks
Si quieres continuar usando el notebook que creaste en este lab, te recomendamos que lo desactives cuando no lo utilices. En la IU de Notebooks de la consola de Cloud, selecciona el notebook y, luego, haz clic en Detener. Si quieres borrar la instancia por completo, selecciona Borrar:

Paso 2: Borra el bucket de Cloud Storage
Para borrar el bucket de almacenamiento, en el menú de navegación de la consola de Cloud, navega a Almacenamiento, selecciona tu bucket y haz clic en Borrar (Delete):
