1. Übersicht
In diesem Lab verwenden Sie Vertex AI, um einen Hyperparameter-Abstimmungsjob für ein TensorFlow-Modell auszuführen. In diesem Lab wird TensorFlow für den Modellcode verwendet. Die Konzepte lassen sich jedoch auch auf andere ML-Frameworks anwenden.
Lerninhalte
Die folgenden Themen werden behandelt:
- Trainingsanwendungscode für die automatische Hyperparameter-Abstimmung ändern
- Hyperparameter-Abstimmungsjob über die Vertex AI-Benutzeroberfläche konfigurieren und starten
- Hyperparameter-Abstimmungsjob mit dem Vertex AI Python SDK konfigurieren und starten
Die Gesamtkosten für die Ausführung dieses Labs in Google Cloud betragen etwa 3$.
2. Einführung in Vertex AI
In diesem Lab wird das neueste KI-Produkt von Google Cloud verwendet. Vertex AI vereint die ML-Angebote von Google Cloud in einer nahtlosen Entwicklungsumgebung. Bisher musste auf mit AutoML trainierte und benutzerdefinierte Modelle über verschiedene Dienste zugegriffen werden. Das neue Angebot kombiniert diese und weitere, neue Produkte zu einer einzigen API. Sie können auch vorhandene Projekte zu Vertex AI migrieren. Wenn Sie Feedback haben, lesen Sie bitte die Supportseite.
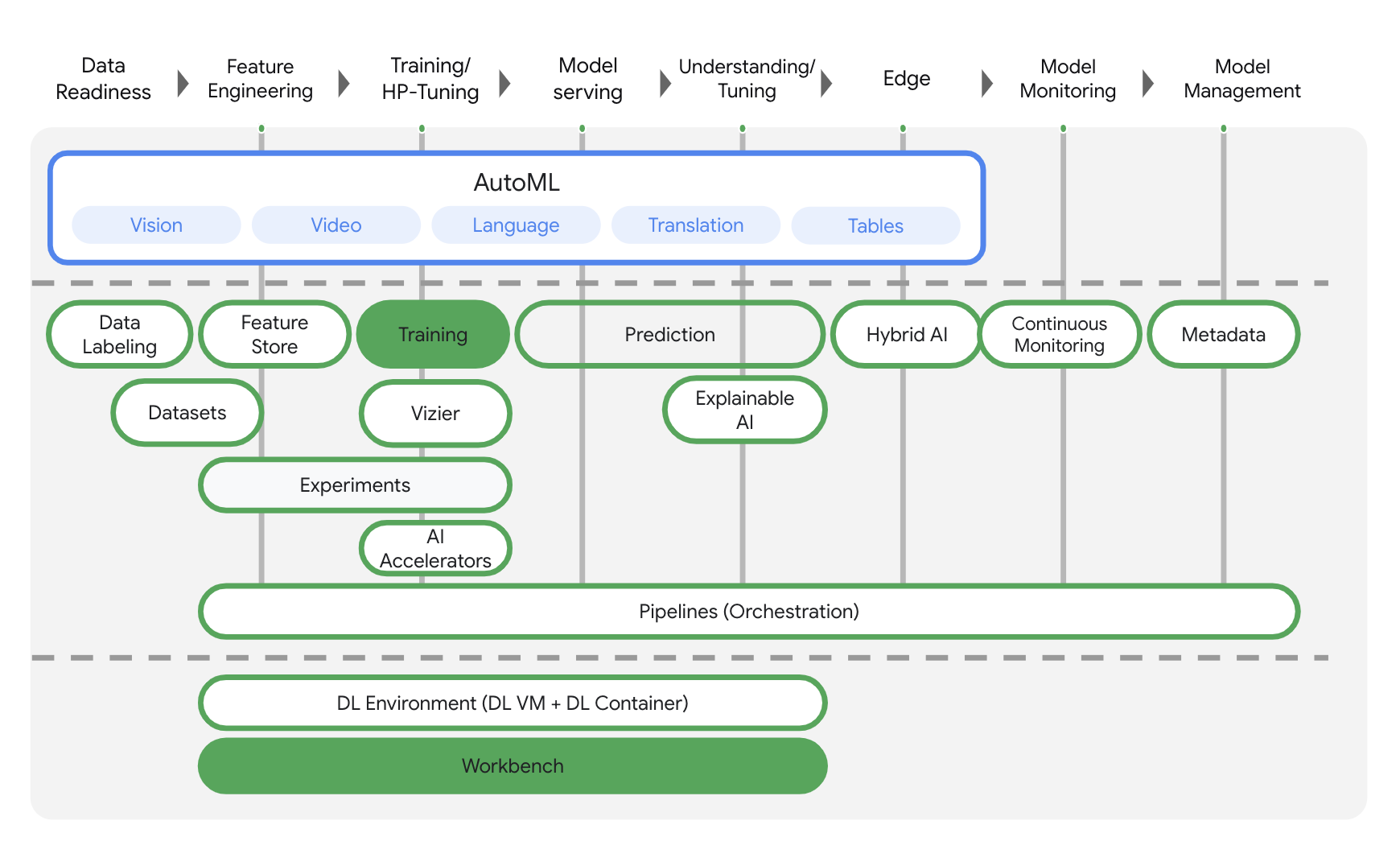
Vertex AI umfasst viele verschiedene Produkte zur Unterstützung von End-to-End-ML-Workflows. In diesem Lab geht es um die unten hervorgehobenen Produkte: Training und Workbench.
3. Richten Sie Ihre Umgebung ein.
Für dieses Codelab benötigen Sie ein Google Cloud Platform-Projekt mit aktivierter Abrechnung. Folgen Sie dieser Anleitung, um ein Projekt zu erstellen.
Schritt 1: Compute Engine API aktivieren
Rufen Sie Compute Engine auf und wählen Sie Aktivieren aus, falls die API noch nicht aktiviert ist. Sie benötigen diese, um Ihre Notebook-Instanz zu erstellen.
Schritt 2: Container Registry API aktivieren
Rufen Sie die Container Registry auf und wählen Sie Aktivieren aus, falls noch nicht geschehen. Damit erstellen Sie einen Container für Ihren benutzerdefinierten Trainingsjob.
Schritt 3: Vertex AI API aktivieren
Rufen Sie den Vertex AI-Bereich Ihrer Cloud Console auf und klicken Sie auf Vertex AI API aktivieren.
Schritt 4: Vertex AI Workbench-Instanz erstellen
Klicken Sie in der Cloud Console im Bereich „Vertex AI“ auf „Workbench“:
Aktivieren Sie die Notebooks API, falls sie noch nicht aktiviert ist.
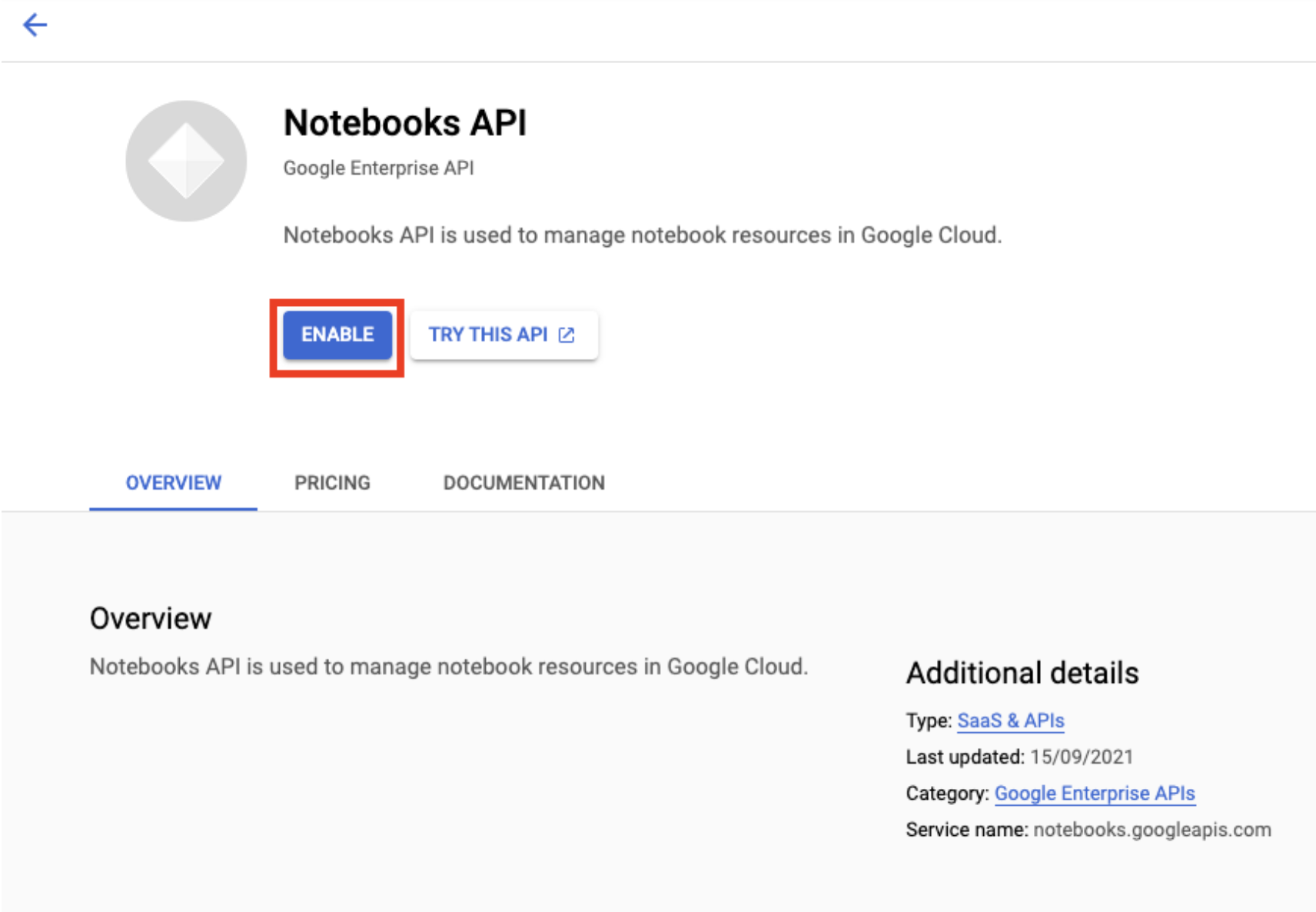
Klicken Sie nach der Aktivierung auf VERWALTETE NOTEBOOKS:

Wählen Sie dann NEUES NOTEBOOK aus.
Geben Sie einen Namen für das Notebook ein und klicken Sie auf Erweiterte Einstellungen.

Aktivieren Sie unter „Erweiterte Einstellungen“ das Herunterfahren bei Inaktivität und legen Sie die Anzahl der Minuten auf 60 fest. Das bedeutet, dass Ihr Notebook automatisch heruntergefahren wird, wenn es nicht verwendet wird, damit keine unnötigen Kosten anfallen.

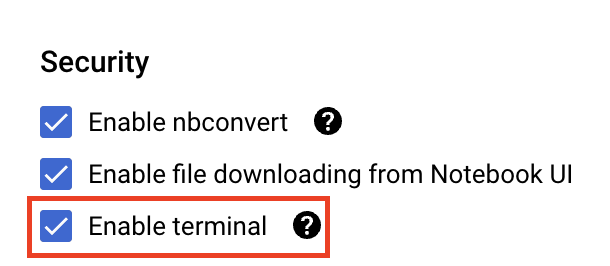
Wählen Sie unter Sicherheit die Option „Terminal aktivieren“ aus, falls sie noch nicht aktiviert ist.
Alle anderen erweiterten Einstellungen können Sie unverändert lassen.
Klicken Sie auf Erstellen. Die Bereitstellung der Instanz kann einige Minuten dauern.
Nachdem die Instanz erstellt wurde, klicken Sie auf JupyterLab öffnen.

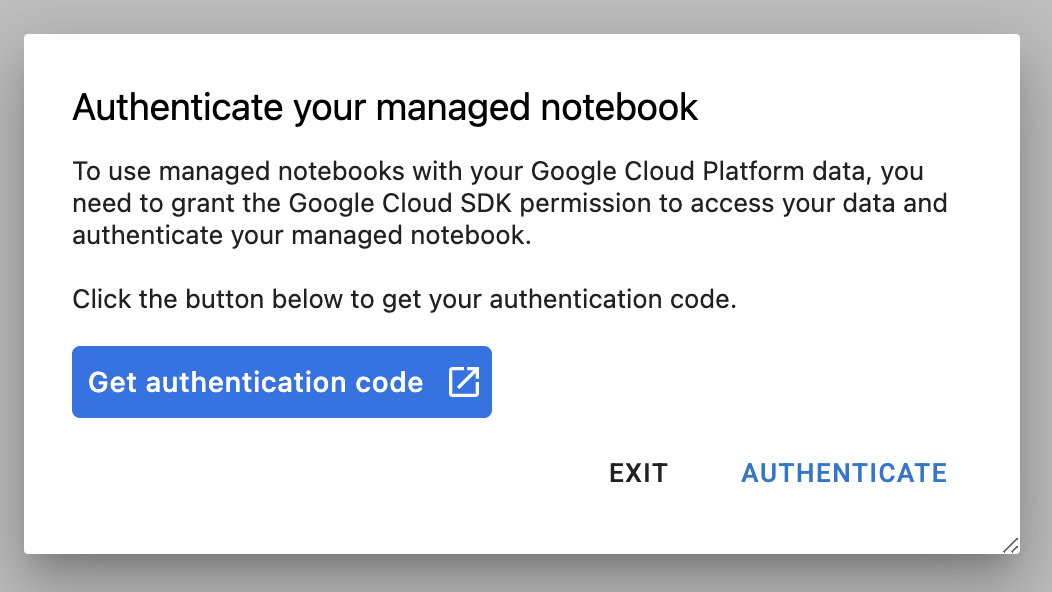
Wenn Sie eine neue Instanz zum ersten Mal verwenden, werden Sie aufgefordert, sich zu authentifizieren. Folgen Sie dazu der Anleitung auf der Benutzeroberfläche.
4. Trainingsanwendungscode containerisieren
Das Modell, das Sie in diesem Lab trainieren und optimieren, ist ein Bildklassifizierungsmodell, das mit dem Dataset für Pferde oder Menschen aus TensorFlow Datasets trainiert wurde.
Sie senden diesen Hyperparameter-Abstimmungsjob an Vertex AI, indem Sie den Code Ihrer Trainingsanwendung in einen Docker-Container einfügen und diesen Container in die Google Container Registry übertragen. Mit diesem Ansatz können Sie Hyperparameter für ein Modell abstimmen, das mit einem beliebigen Framework erstellt wurde.
Öffnen Sie zuerst über das Launcher-Menü ein Terminalfenster in Ihrer Notebook-Instanz:

Erstellen Sie ein neues Verzeichnis mit dem Namen horses_or_humans und wechseln Sie dorthin:
mkdir horses_or_humans
cd horses_or_humans
Schritt 1: Dockerfile erstellen
Der erste Schritt beim Containerisieren Ihres Codes ist das Erstellen eines Dockerfile. Das Dockerfile enthält alle Befehle, die zum Ausführen des Images erforderlich sind. Dadurch werden alle erforderlichen Bibliotheken, einschließlich der CloudML Hypertune-Bibliothek, installiert und der Einstiegspunkt für den Trainingscode eingerichtet.
Erstellen Sie über Ihr Terminal ein leeres Dockerfile:
touch Dockerfile
Öffnen Sie das Dockerfile und kopieren Sie Folgendes hinein:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
In diesem Dockerfile wird das Deep Learning Container TensorFlow Enterprise 2.7-GPU-Docker-Image verwendet. In den Deep Learning-Containern in Google Cloud sind viele gängige ML- und Data-Science-Frameworks vorinstalliert. Nachdem Sie dieses Image heruntergeladen haben, wird mit diesem Dockerfile der Einstiegspunkt für den Trainingscode eingerichtet. Sie haben diese Dateien noch nicht erstellt. Im nächsten Schritt fügen Sie den Code zum Trainieren und Optimieren des Modells hinzu.
Schritt 2: Code für das Modelltraining hinzufügen
Führen Sie im Terminal den folgenden Befehl aus, um ein Verzeichnis für den Trainingscode und eine Python-Datei zu erstellen, in die Sie den Code einfügen:
mkdir trainer
touch trainer/task.py
Ihr horses_or_humans/-Verzeichnis sollte jetzt Folgendes enthalten:
+ Dockerfile
+ trainer/
+ task.py
Öffnen Sie dann die gerade erstellte Datei task.py und kopieren Sie den folgenden Code.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Bevor Sie den Container erstellen, sehen wir uns den Code genauer an. Für die Verwendung des Hyperparameter-Abstimmungsdienstes sind einige spezielle Komponenten erforderlich.
- Das Skript importiert die
hypertune-Bibliothek. Das Dockerfile aus Schritt 1 enthielt Anweisungen zum Installieren dieser Bibliothek mit pip. - Die Funktion
get_args()definiert ein Befehlszeilenargument für jeden Hyperparameter, den Sie abstimmen möchten. In diesem Beispiel werden die Lernrate, der Momentum-Wert im Optimierer und die Anzahl der Einheiten in der letzten verborgenen Schicht des Modells optimiert. Sie können aber auch andere Hyperparameter verwenden. Der für diese Argumente übergebene Wert wird dann verwendet, um den entsprechenden Hyperparameter im Code festzulegen. - Am Ende der Funktion
main()wird diehypertune-Bibliothek verwendet, um den zu optimierenden Messwert zu definieren. In TensorFlow gibt die Keras-Methodemodel.fiteinHistory-Objekt zurück. Das AttributHistory.historyenthält eine Aufzeichnung der Trainingsverlustwerte und Messwerte in aufeinanderfolgenden Epochen. Wenn Sie Validierungsdaten anmodel.fitübergeben, enthält das AttributHistory.historyauch den Validierungsverlust und die Messwerte. Wenn Sie beispielsweise ein Modell für drei Epochen mit Validierungsdaten trainiert undaccuracyals Messwert angegeben haben, sieht das AttributHistory.historyin etwa so aus:
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Wenn der Hyperparameter-Abstimmungsdienst die Werte ermitteln soll, mit denen die Validierungsgenauigkeit des Modells maximiert wird, definieren Sie den Messwert als letzten Eintrag (oder NUM_EPOCS - 1) der Liste val_accuracy. Übergeben Sie diesen Messwert dann an eine Instanz von HyperTune. Sie können einen beliebigen String für hyperparameter_metric_tag auswählen. Sie müssen den String jedoch später wieder verwenden, wenn Sie den Hyperparameter-Abstimmungsjob starten.
Schritt 3: Container erstellen
Führen Sie im Terminal den folgenden Befehl aus, um eine Umgebungsvariable für Ihr Projekt zu definieren. Ersetzen Sie dabei your-cloud-project durch die ID Ihres Projekts:
PROJECT_ID='your-cloud-project'
Definieren Sie eine Variable mit dem URI Ihres Container-Images in der Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Docker konfigurieren
gcloud auth configure-docker
Erstellen Sie dann den Container, indem Sie den folgenden Befehl im Stammverzeichnis Ihres horses_or_humans-Verzeichnisses ausführen:
docker build ./ -t $IMAGE_URI
Übertragen Sie es schließlich per Push in die Google Container Registry:
docker push $IMAGE_URI
Nachdem der Container in Container Registry hochgeladen wurde, können Sie einen benutzerdefinierten Hyperparameter-Abstimmungsjob für das Modell starten.
5. Hyperparameter-Abstimmungsjob in Vertex AI ausführen
In diesem Lab wird benutzerdefiniertes Training über einen benutzerdefinierten Container in Google Container Registry verwendet. Sie können einen Hyperparameter-Abstimmungsjob aber auch mit einem vordefinierten Vertex AI-Container ausführen.
Rufen Sie zuerst in der Cloud Console im Bereich „Vertex“ den Abschnitt Training auf:
Schritt 1: Trainingsjob konfigurieren
Klicken Sie auf Erstellen, um die Parameter für Ihren Hyperparameter-Abstimmungsjob einzugeben.
- Wählen Sie unter Dataset die Option Kein verwaltetes Dataset aus.
- Wählen Sie dann Benutzerdefiniertes Training (erweitert) als Trainingsmethode aus und klicken Sie auf Weiter.
- Geben Sie
horses-humans-hyptertune(oder einen beliebigen anderen Namen für Ihr Modell) für Modellname ein. - Klicken Sie auf Weiter.
Wählen Sie im Schritt „Containereinstellungen“ die Option Benutzerdefinierter Container aus:

Geben Sie im ersten Feld (Container-Image) den Wert Ihrer IMAGE_URI-Variablen aus dem vorherigen Abschnitt ein. Sie sollte so aussehen: gcr.io/your-cloud-project/horse-human:hypertune, wobei Sie Ihren eigenen Projektnamen verwenden. Lassen Sie die anderen Felder leer und klicken Sie auf Weiter.
Schritt 2: Hyperparameter-Abstimmungsjob konfigurieren
Wählen Sie Hyperparameter-Abstimmung aktivieren aus.
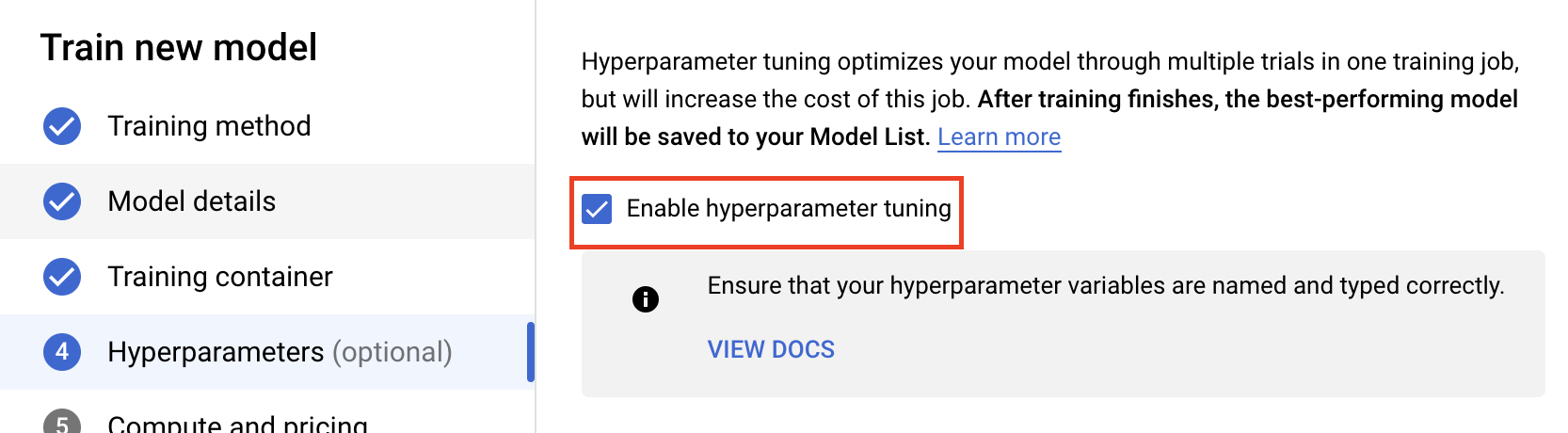
Hyperparameter konfigurieren
Als Nächstes müssen Sie die Hyperparameter hinzufügen, die Sie als Befehlszeilenargumente im Trainingsanwendungscode festgelegt haben. Wenn Sie einen Hyperparameter hinzufügen, müssen Sie zuerst den Namen angeben. Dieser sollte mit dem Argumentnamen übereinstimmen, den Sie an argparse übergeben haben.

Anschließend wählen Sie den Typ sowie die Grenzen für die Werte aus, die der Optimierungsdienst ausprobieren soll. Wenn Sie den Typ „Double“ oder „Integer“ auswählen, müssen Sie einen Mindest- und einen Höchstwert angeben. Wenn Sie „Kategorisch“ oder „Diskret“ auswählen, müssen Sie die Werte angeben.
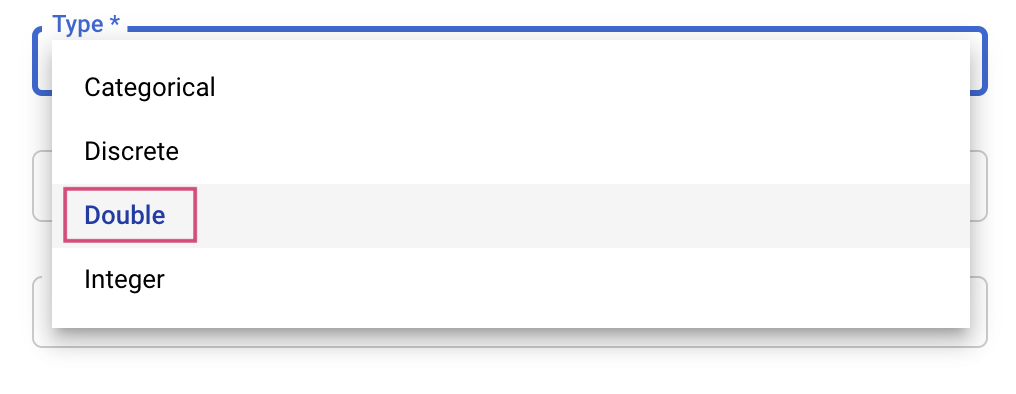

Für die Typen „Double“ und „Integer“ müssen Sie auch den Skalierungswert angeben.
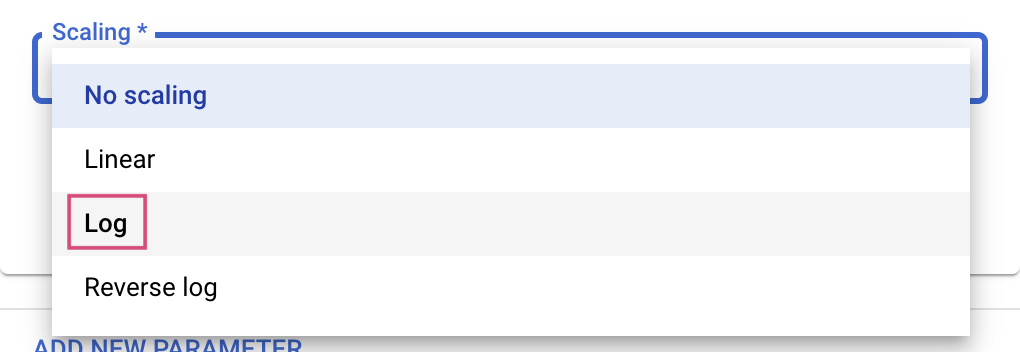
Fügen Sie nach dem Hyperparameter learning_rate Parameter für momentum und num_units hinzu.


Messwert konfigurieren
Nachdem Sie die Hyperparameter hinzugefügt haben, geben Sie den zu optimierenden Messwert und das Ziel an. Dieser Wert sollte mit dem hyperparameter_metric_tag übereinstimmen, den Sie in Ihrer Trainingsanwendung festgelegt haben.
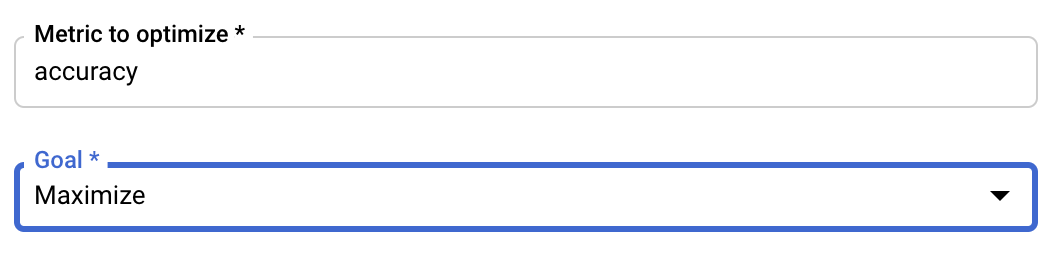
Der Vertex AI-Dienst zur Hyperparameter-Abstimmung führt mehrere Tests Ihrer Trainingsanwendung mit den in den vorherigen Schritten konfigurierten Werten aus. Sie müssen eine Obergrenze für die Anzahl der Tests festlegen, die der Dienst ausführt. Mehr Tests führen in der Regel zu besseren Ergebnissen. Es gibt jedoch einen Punkt, ab dem zusätzliche Tests kaum noch Auswirkungen auf den Messwert haben, den Sie optimieren möchten. Es empfiehlt sich, mit einer kleineren Anzahl von Tests zu beginnen, um zu sehen, wie sich die gewählten Hyperparameter auswirken, bevor Sie die Anzahl der Tests erhöhen.
Außerdem müssen Sie eine Obergrenze für die Anzahl paralleler Tests festlegen. Wenn Sie die Anzahl der parallelen Tests erhöhen, wird die Laufzeit des Hyperparameter-Abstimmungsjobs verkürzt. Dies kann jedoch die Effektivität des Jobs insgesamt verringern. Das liegt daran, dass bei der Standardstrategie zur Abstimmung die Ergebnisse vorheriger Tests verwendet werden, um die Zuweisung von Werten in nachfolgenden Tests zu optimieren. Wenn Sie zu viele Tests parallel ausführen, gibt es Tests, die ohne die Ergebnisse der noch laufenden Tests gestartet werden.
Zu Demonstrationszwecken können Sie die Anzahl der Tests auf 15 und die maximale Anzahl paralleler Tests auf 3 festlegen. Sie können mit verschiedenen Zahlen experimentieren, dies kann jedoch zu einer längeren Abstimmungszeit und höheren Kosten führen.

Im letzten Schritt wählen Sie „Standard“ als Suchalgorithmus aus. Damit wird Google Vizier verwendet, um die Bayes'sche Optimierung für die Feinabstimmung von Hyperparametern durchzuführen. Weitere Informationen zu diesem Algorithmus
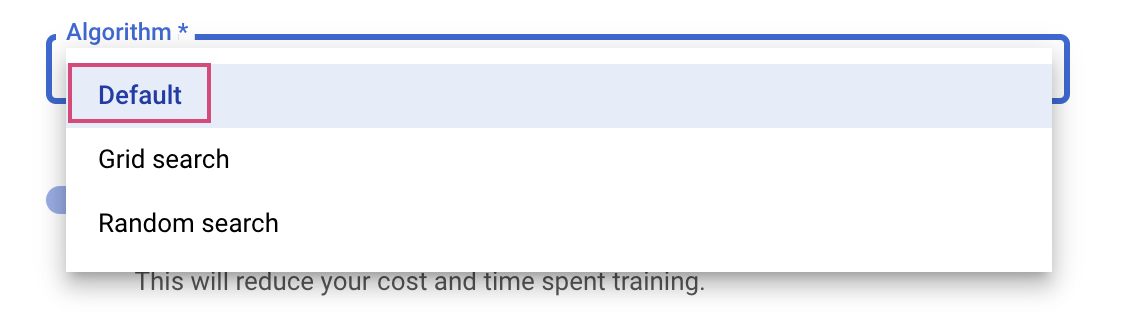
Klicken Sie auf Weiter.
Schritt 3: Compute konfigurieren
Lassen Sie unter Computing und Preise die ausgewählte Region unverändert und konfigurieren Sie Worker-Pool 0 so:
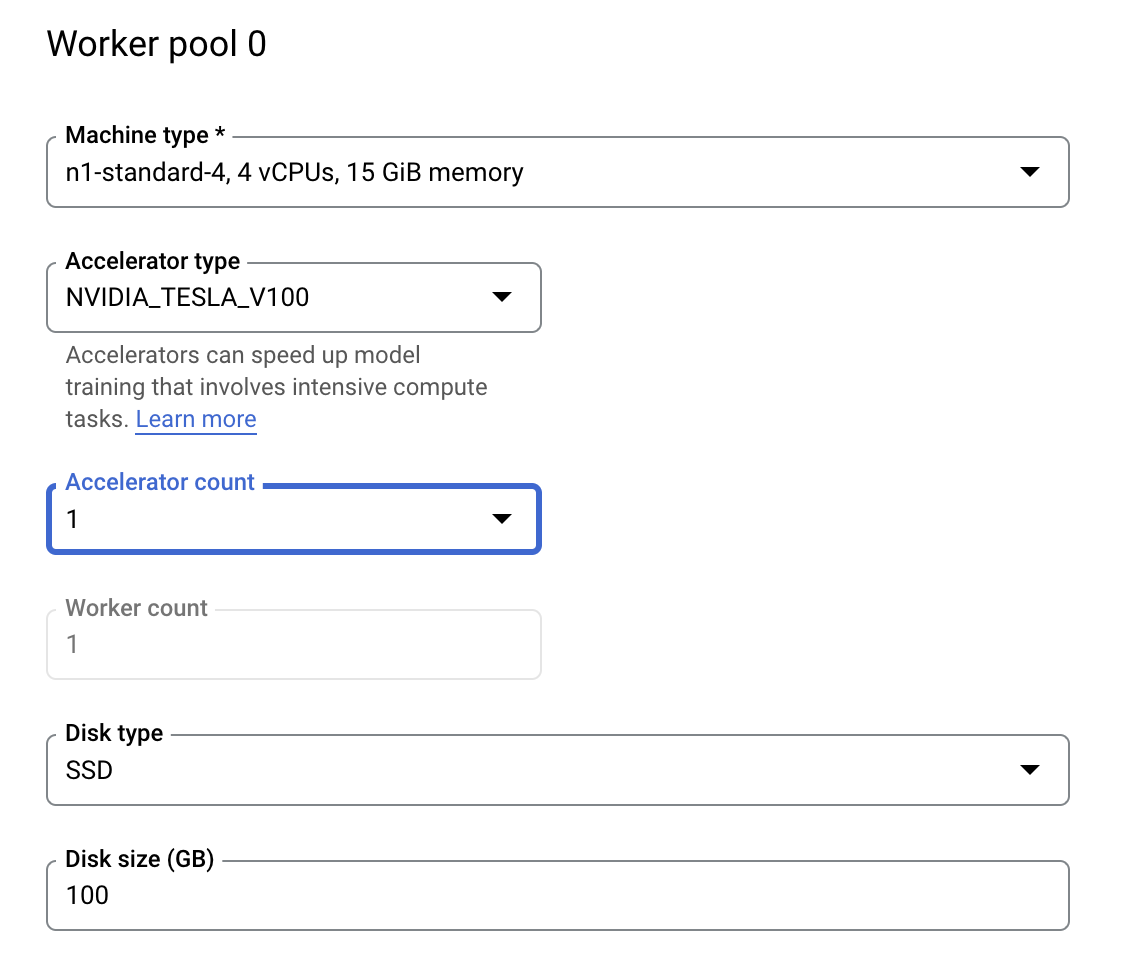
Klicken Sie auf Training starten, um den Hyperparameter-Abstimmungsjob zu starten. Im Bereich „Training“ Ihrer Konsole wird auf dem Tab HYPERPARAMETER TUNING JOBS (HYPERPARAMETER-ABSTIMMUNGSJOBS) Folgendes angezeigt:
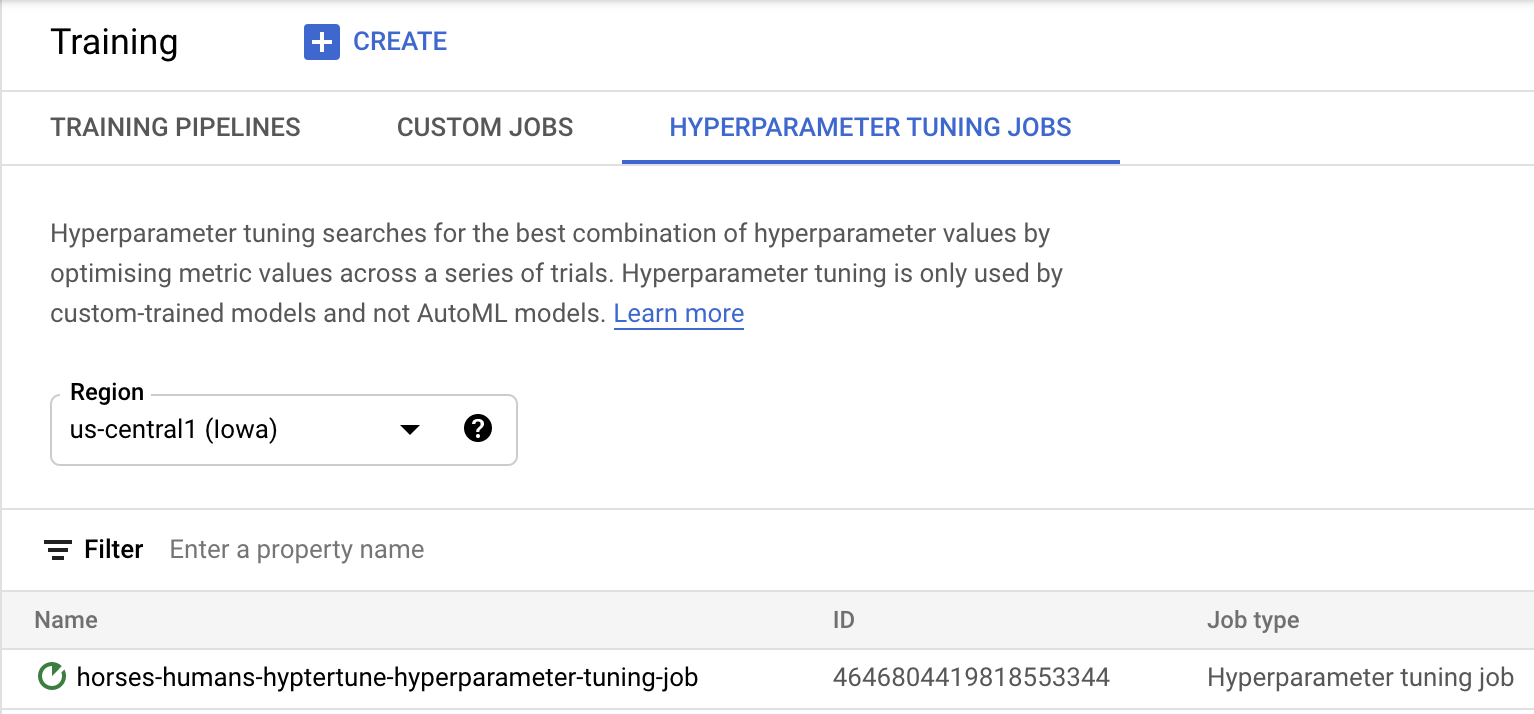
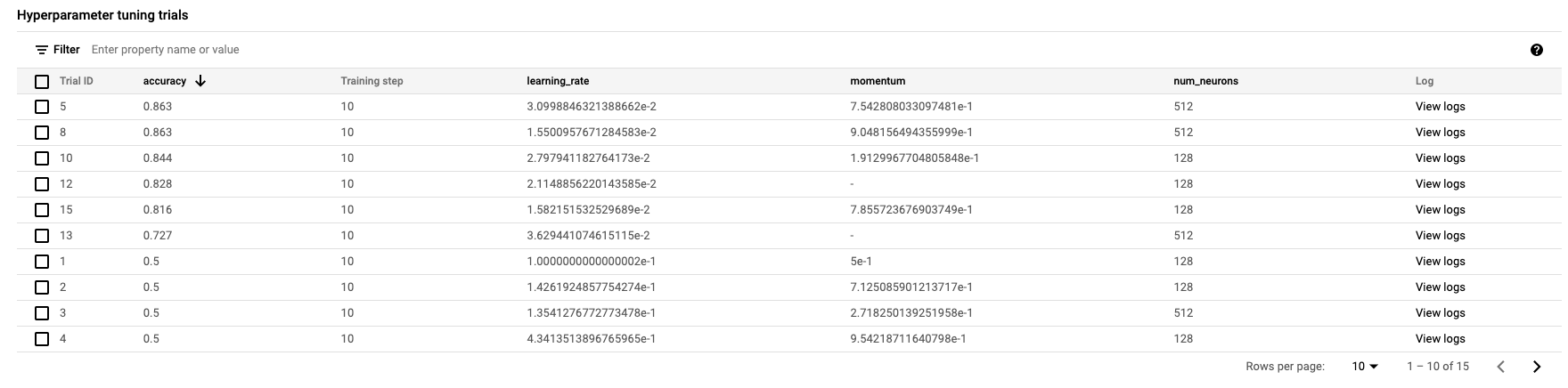
Wenn der Vorgang abgeschlossen ist, können Sie auf den Jobnamen klicken, um die Ergebnisse der Optimierungsversuche zu sehen.
🎉 Das wars! 🎉
Sie haben gelernt, wie Sie Vertex AI für folgende Aufgaben verwenden:
- Starten Sie einen Hyperparameter-Abstimmungsjob für Trainingscode, der in einem benutzerdefinierten Container bereitgestellt wird. In diesem Beispiel haben Sie ein TensorFlow-Modell verwendet. Sie können jedoch ein Modell, das mit einem beliebigen Framework erstellt wurde, mit benutzerdefinierten Containern trainieren.
Weitere Informationen zu den verschiedenen Bereichen von Vertex finden Sie in der Dokumentation.
6. [Optional] Vertex SDK verwenden
Im vorherigen Abschnitt wurde gezeigt, wie Sie den Hyperparameter-Abstimmungsjob über die Benutzeroberfläche starten. In diesem Abschnitt sehen Sie eine alternative Möglichkeit, den Hyperparameter-Abstimmungsjob mit der Vertex Python API zu senden.
Erstellen Sie über den Launcher ein TensorFlow 2-Notebook.

Importieren Sie das Vertex AI SDK.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Bevor Sie den Hyperparameter-Abstimmungsjob starten können, müssen Sie die folgenden Spezifikationen definieren. Ersetzen Sie {PROJECT_ID} in image_uri durch Ihr Projekt.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Erstellen Sie als Nächstes eine CustomJob. Sie müssen {YOUR_BUCKET} durch einen Bucket in Ihrem Projekt für das Staging ersetzen.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Erstellen und führen Sie dann die HyperparameterTuningJob aus.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Bereinigen
Da wir das Notebook so konfiguriert haben, dass es nach 60 Minuten Inaktivität ein Zeitlimit erreicht, müssen wir uns keine Gedanken über das Herunterfahren der Instanz machen. Wenn Sie die Instanz manuell herunterfahren möchten, klicken Sie im Bereich „Vertex AI Workbench“ der Console auf die Schaltfläche „Beenden“. Wenn Sie das Notebook vollständig löschen möchten, klicken Sie auf die Schaltfläche „Löschen“.

Wenn Sie den Storage-Bucket löschen möchten, rufen Sie in der Cloud Console über das Navigationsmenü „Storage“ auf, wählen Sie den Bucket aus und klicken Sie auf „Löschen“: