1. Présentation
Dans cet atelier, vous allez utiliser Vertex AI afin d'exécuter un job de réglage des hyperparamètres pour un modèle TensorFlow. Cet atelier utilise TensorFlow pour le code du modèle, les concepts s'appliquent également à d'autres frameworks de ML.
Objectifs
Vous allez apprendre à effectuer les opérations suivantes :
- Modifier le code de l'application d'entraînement pour le réglage automatique des hyperparamètres
- Configurer et lancer un job de réglage des hyperparamètres à partir de l'interface utilisateur de Vertex AI
- Configurer et lancer un job de réglage des hyperparamètres avec le SDK Vertex AI pour Python
Le coût total d'exécution de cet atelier sur Google Cloud est d'environ 3 USD.
2. Présentation de Vertex AI
Cet atelier utilise la toute dernière offre de produits d'IA de Google Cloud. Vertex AI simplifie l'expérience de développement en intégrant toutes les offres de ML de Google Cloud. Auparavant, les modèles entraînés avec AutoML et les modèles personnalisés étaient accessibles depuis des services distincts. La nouvelle offre regroupe ces deux types de modèles mais aussi d'autres nouveaux produits en une seule API. Vous pouvez également migrer des projets existants vers Vertex AI. Pour envoyer un commentaire, consultez la page d'assistance.
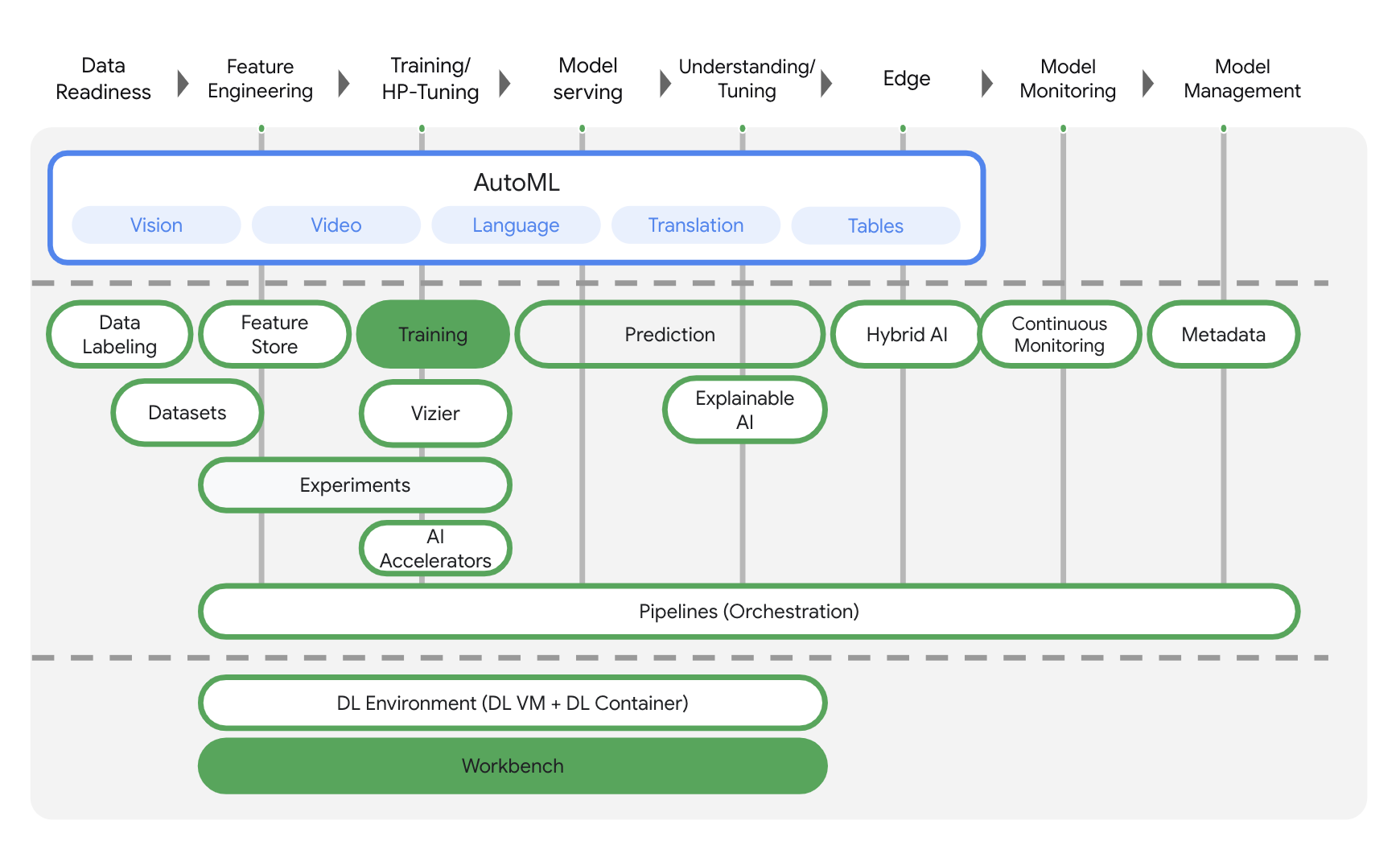
Vertex AI comprend de nombreux produits différents qui permettent de gérer les workflows de ML de bout en bout. Cet atelier se concentre sur les produits mis en évidence ci-dessous : Training et Workbench.
3. Configurer votre environnement
Pour suivre cet atelier de programmation, vous aurez besoin d'un projet Google Cloud Platform dans lequel la facturation est activée. Pour créer un projet, suivez ces instructions.
Étape 1 : Activez l'API Compute Engine
Accédez à Compute Engine et cliquez sur Activer si ce n'est pas déjà fait. Vous en aurez besoin pour créer votre instance de notebook.
Étape 2 : Activez l'API Container Registry
Accédez à Container Registry et cliquez sur Activer si ce n'est pas déjà fait. Vous utiliserez ce service afin de créer un conteneur pour votre tâche d'entraînement personnalisé.
Étape 3 : Activez l'API Vertex AI
Accédez à la section Vertex AI de Cloud Console, puis cliquez sur Activer l'API Vertex AI.
Étape 4 : Créez une instance Vertex AI Workbench
Dans la section Vertex AI de Cloud Console, cliquez sur Workbench :
Activez l'API Notebooks si ce n'est pas déjà fait.
Une fois l'API activée, cliquez sur NOTEBOOKS GÉRÉS :

Sélectionnez ensuite NOUVEAU NOTEBOOK.
Attribuez un nom à votre notebook, puis cliquez sur Paramètres avancés.

Sous "Paramètres avancés", activez l'arrêt en cas d'inactivité et définissez le nombre de minutes sur 60. Cela entraîne l'arrêt automatique du notebook lorsqu'il n'est pas utilisé. Vous ne payez donc pas de frais inutiles.

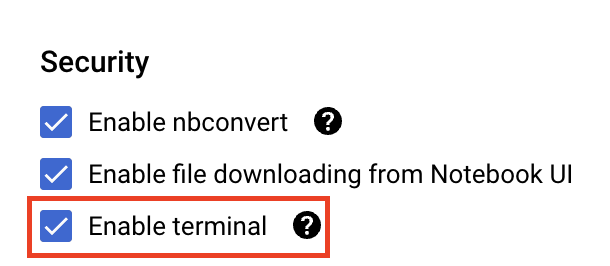
Dans la section Sécurité , sélectionnez "Activer le terminal" si ce n'est pas déjà fait.
Vous pouvez conserver tous les autres paramètres avancés tels quels.
Cliquez ensuite sur Créer. Le provisionnement de l'instance prend quelques minutes.
Une fois l'instance créée, sélectionnez Ouvrir JupyterLab.

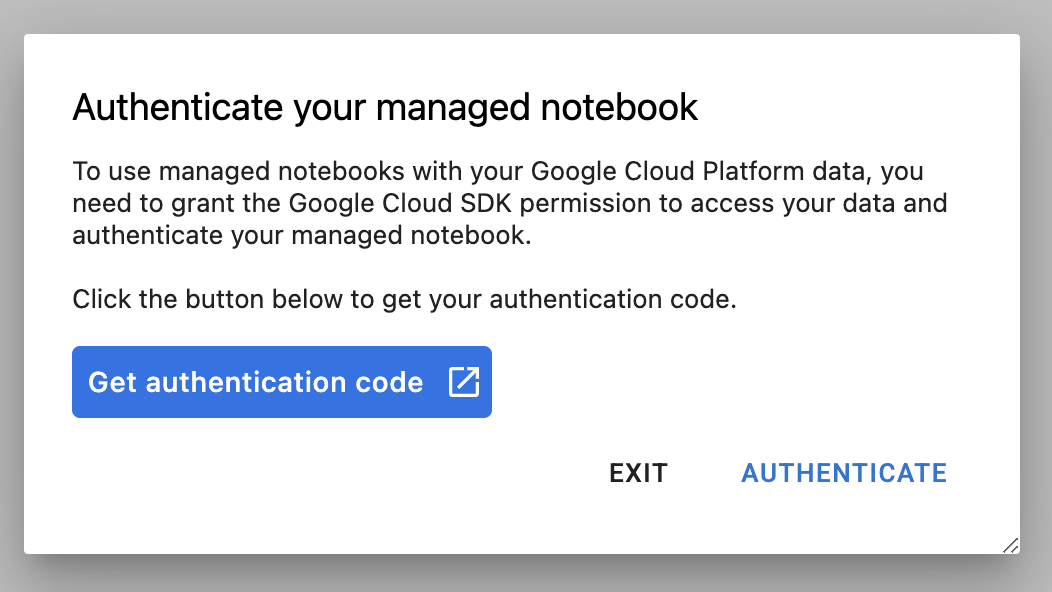
La première fois que vous utilisez une nouvelle instance, vous êtes invité à vous authentifier. Pour ce faire, suivez les étapes indiquées dans l'interface utilisateur.
4. Conteneuriser le code de l'application d'entraînement
Le modèle que vous allez entraîner et régler dans cet atelier est un modèle de classification d'images entraîné avec l'ensemble de données horses_or_humans de TensorFlow.
Vous allez envoyer ce job de réglage des hyperparamètres à Vertex AI en plaçant le code de votre application d'entraînement dans un conteneur Docker et en transférant ce conteneur vers Google Container Registry. Cette approche vous permet de régler les hyperparamètres d'un modèle créé avec n'importe quel framework.
Pour commencer, à partir du menu de lancement, ouvrez une fenêtre de terminal dans votre instance de notebook :

Créez un répertoire appelé horses_or_humans et utilisez la commande cd pour y accéder :
mkdir horses_or_humans
cd horses_or_humans
Étape 1 : Créez un Dockerfile
La première étape de la conteneurisation de votre code consiste à créer un Dockerfile. Vous allez placer dans ce Dockerfile toutes les commandes nécessaires à l'exécution de l'image. Il installera toutes les bibliothèques requises, y compris la bibliothèque cloudml-hypertune, et configurera le point d'entrée du code d'entraînement.
Depuis votre terminal, créez un Dockerfile vide :
touch Dockerfile
Ouvrez le Dockerfile et copiez-y le code suivant :
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Ce fichier Dockerfile utilise l'image Docker avec GPU de TensorFlow Enterprise 2.7 comme conteneur de deep learning. Les conteneurs de deep learning sur Google Cloud sont fournis avec de nombreux frameworks de ML et de data science courants préinstallés. Une fois cette image téléchargée, ce Dockerfile configure le point d'entrée du code d'entraînement. Vous n'avez pas encore créé ces fichiers. À la prochaine étape, vous allez ajouter le code d'entraînement et de réglage du modèle.
Étape 2 : Ajoutez le code d'entraînement du modèle
Depuis votre terminal, exécutez le code suivant afin de créer un répertoire pour le code d'entraînement et un fichier Python dans lequel vous ajouterez le code :
mkdir trainer
touch trainer/task.py
Votre répertoire horses_or_humans/ doit maintenant contenir les éléments suivants :
+ Dockerfile
+ trainer/
+ task.py
Ouvrez ensuite le fichier task.py que vous venez de créer et copiez-y le code ci-dessous.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Avant de créer le conteneur, examinons le code de plus près. Certains composants sont utilisés spécifiquement pour le service de réglage des hyperparamètres.
- Le script importe la bibliothèque
hypertune. Notez que le Dockerfile de l'étape 1 contenait des instructions pour l'installation de cette bibliothèque avec pip. - La fonction
get_args()définit un argument de ligne de commande pour chaque hyperparamètre que vous souhaitez régler. Dans cet exemple, les hyperparamètres qui seront réglés sont le taux d'apprentissage, la valeur du momentum dans l'optimiseur et le nombre d'unités dans la dernière couche cachée du modèle, mais n'hésitez pas à effectuer des tests avec d'autres hyperparamètres. La valeur transmise dans ces arguments est ensuite utilisée pour définir l'hyperparamètre correspondant dans le code. - À la fin de la fonction
main(), la bibliothèquehypertunepermet de définir la métrique que vous souhaitez optimiser. Dans TensorFlow, la méthode Kerasmodel.fitrenvoie un objetHistory. L'attributHistory.historyest un enregistrement des valeurs de perte d'entraînement et des métriques à des époques successives. Si vous transmettez des données de validation àmodel.fit, l'attributHistory.historyinclut également les valeurs de perte de validation et celles des métriques. Par exemple, si vous aviez entraîné un modèle pendant trois époques avec des données de validation et que vous aviez fourniaccuracycomme métrique, l'attributHistory.historyressemblerait au dictionnaire suivant.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Si vous souhaitez que le service de réglage des hyperparamètres découvre les valeurs qui maximisent la justesse de la validation du modèle, vous devez définir la métrique en tant que dernière entrée (ou NUM_EPOCS - 1) de la liste val_accuracy. Transmettez ensuite cette métrique à une instance de HyperTune. Vous pouvez choisir la chaîne que vous voulez pour hyperparameter_metric_tag, mais vous devrez la réutiliser ultérieurement lorsque vous lancerez le job de réglage des hyperparamètres.
Étape 3 : Créez le conteneur
Depuis votre terminal, exécutez la commande suivante afin de définir une variable d'environnement pour votre projet, en veillant à remplacer your-cloud-project par l'ID de votre projet :
PROJECT_ID='your-cloud-project'
Définissez une variable avec l'URI de votre image de conteneur dans Google Container Registry :
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Configurez Docker.
gcloud auth configure-docker
Ensuite, créez le conteneur en exécutant la commande suivante à partir de la racine de votre répertoire horses_or_humans :
docker build ./ -t $IMAGE_URI
Enfin, transférez-le vers Google Container Registry :
docker push $IMAGE_URI
Maintenant que le conteneur a été transféré vers Container Registry, vous êtes prêt à lancer un job de réglage des hyperparamètres d'un modèle personnalisé.
5. Exécuter une tâche de réglage des hyperparamètres sur Vertex AI
Cet atelier utilise un entraînement personnalisé avec un conteneur personnalisé de Google Container Registry, mais vous pouvez également exécuter un job de réglage des hyperparamètres avec un conteneur prédéfini Vertex AI.
Pour commencer, accédez à l'onglet Entraînement de la section Vertex de votre console Cloud :
Étape 1 : Configurez le job d'entraînement
Cliquez sur Créer pour saisir les paramètres de votre tâche de réglage des hyperparamètres.
- Sous Ensemble de données, sélectionnez Aucun ensemble de données géré
- Sélectionnez ensuite Entraînement personnalisé (avancé) comme méthode d'entraînement, puis cliquez sur Continuer.
- Saisissez
horses-humans-hyptertune(ou tout autre nom que vous voudriez donner à votre modèle) pour Nom du modèle. - Cliquez sur Continuer.
À l'étape des paramètres du conteneur, sélectionnez Conteneur personnalisé :

Dans le premier champ (Image du conteneur), saisissez la valeur de votre variable IMAGE_URI de la section précédente. Elle doit être : gcr.io/your-cloud-project/horse-human:hypertune, avec le nom de votre propre projet. Laissez les autres champs vides et cliquez sur Continuer.
Étape 2 : Configurez le job de réglage des hyperparamètres
Sélectionnez Activer le réglage des hyperparamètres.
Configurez les hyperparamètres
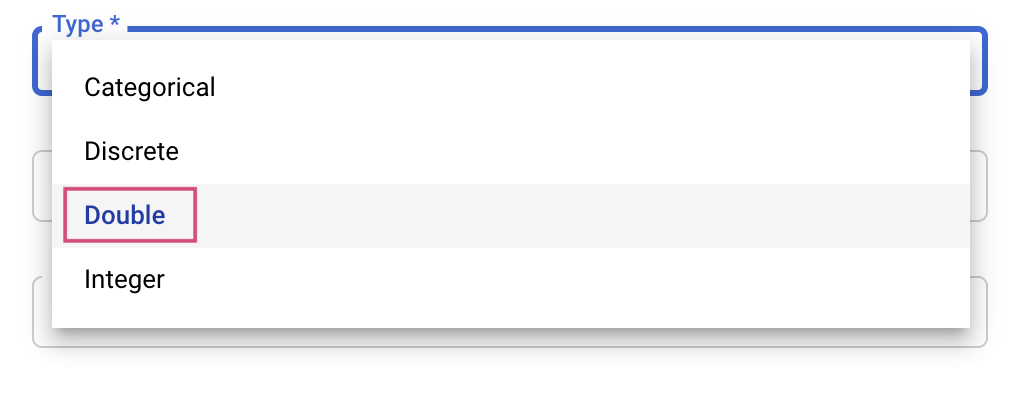
Vous devez ensuite ajouter les hyperparamètres que vous définissez comme arguments de ligne de commande dans le code de l'application d'entraînement. Lorsque vous ajoutez un hyperparamètre, vous devez d'abord en indiquer le nom. Celui-ci doit correspondre au nom d'argument que vous avez transmis à argparse.

Sélectionnez ensuite le type ainsi que les limites pour les valeurs que le service de réglage testera. Si vous sélectionnez le type "Double" ou "Entier", vous devez indiquer des valeurs minimale et maximale. Si vous sélectionnez un type "Catégoriel" ou "Discret", vous devez indiquer les valeurs.

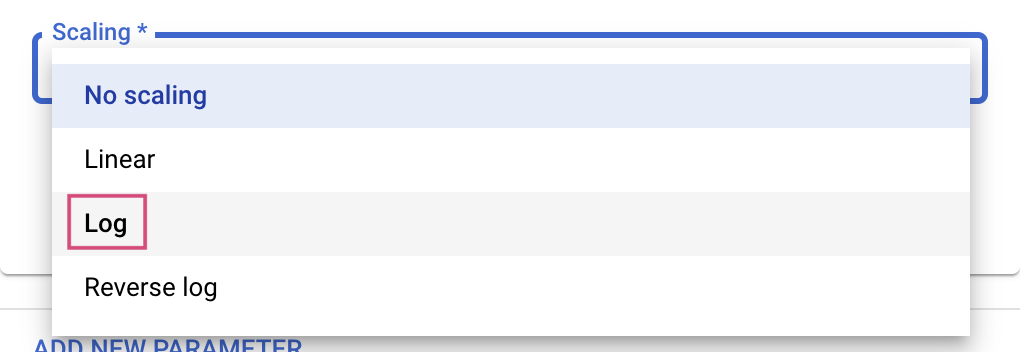
Pour les types "Double" et "Entier", vous devez également fournir la valeur de scaling.
Après avoir ajouté l'hyperparamètre learning_rate, ajoutez des paramètres pour momentum et num_units.


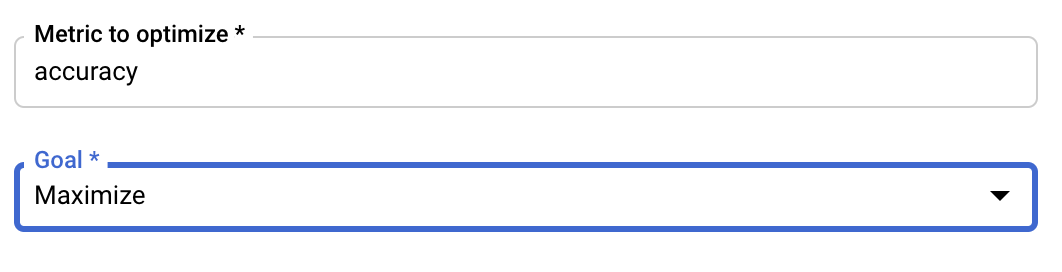
Configurez la métrique
Une fois que vous avez ajouté les hyperparamètres, vous devez fournir la métrique que vous voulez optimiser ainsi que l'objectif. La métrique doit être identique à la valeur que vous avez définie pour hyperparameter_metric_tag dans votre application d'entraînement.
Le service de réglage des hyperparamètres de Vertex AI effectue plusieurs essais avec votre application d'entraînement en utilisant les valeurs configurées au cours des étapes précédentes. Vous devez fixer une limite pour que le service ne dépasse pas un certain nombre d'essais. Un plus grand nombre d'essais permet généralement d'obtenir de meilleurs résultats, mais il existe un point de retours décroissants au-delà duquel les essais supplémentaires n'ont que peu ou pas d'effet sur la métrique que vous essayez d'optimiser. Il est recommandé de commencer avec un petit nombre d'essais et d'attendre d'avoir une idée du degré d'impact des hyperparamètres choisis pour passer à un grand nombre d'essais.
Vous devez également définir un nombre maximal d'essais parallèles. L'augmentation du nombre d'essais parallèles a pour effet de réduire le temps nécessaire à l'exécution du job de réglage des hyperparamètres. Toutefois, elle peut réduire l'efficacité globale du job. En effet, la stratégie de réglage par défaut utilise les résultats des essais précédents pour ajuster les valeurs affectées lors des essais suivants. Si vous exécutez un trop grand nombre d'essais en parallèle, certains essais démarreront sans bénéficier du résultat des essais qui sont toujours en cours d'exécution.
À titre de démonstration, vous pouvez définir le nombre d'essais sur 15 et le nombre maximal d'essais parallèles sur 3. Vous pouvez faire des tests avec des valeurs différentes, mais cela risque d'allonger le temps de réglage et d'augmenter les coûts.

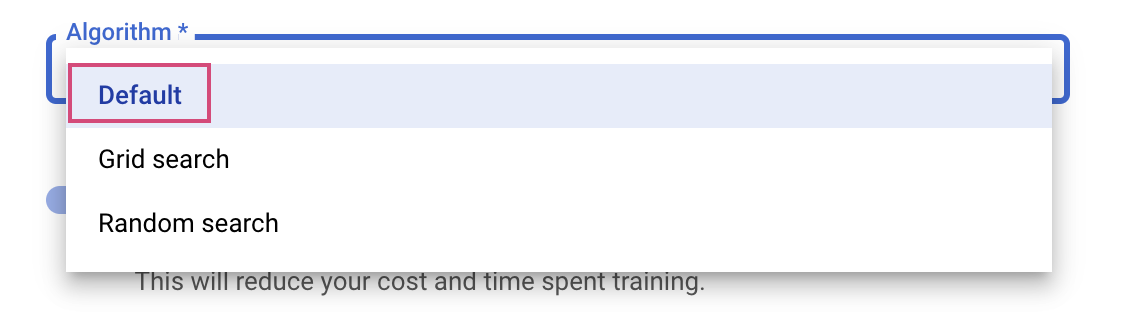
La dernière étape consiste à sélectionner "Par défaut" comme algorithme de recherche. Ainsi, c'est avec Google Vizier que sera effectuée l'optimisation bayésienne pour le réglage des hyperparamètres. Pour en savoir plus sur cet algorithme, cliquez ici.
Cliquez sur Continuer.
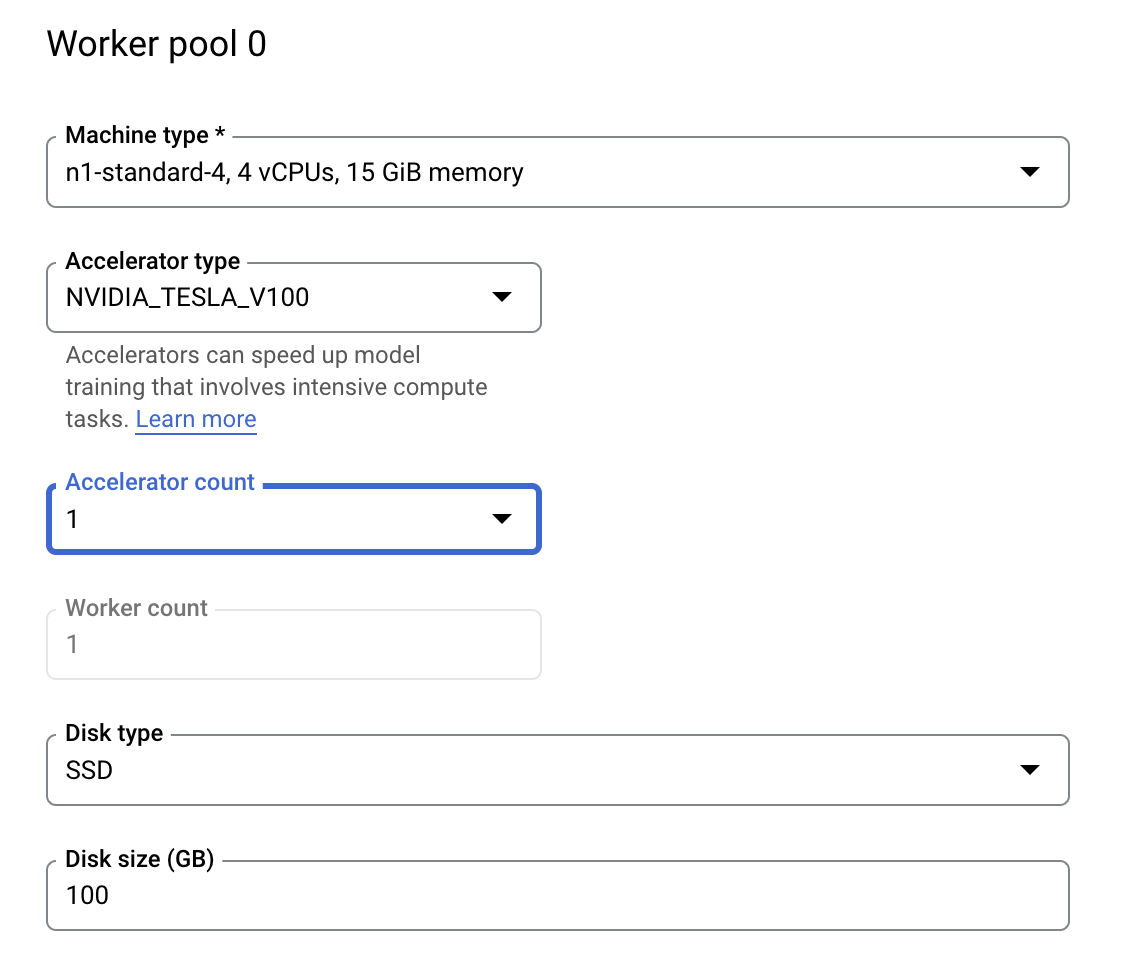
Étape 3 : Configurez le calcul
Dans Options de calcul et tarifs, ne modifiez pas la région sélectionnée et configurez le pool de nœuds de calcul 0 de la manière suivante.
Cliquez sur Démarrer l'entraînement pour lancer le job de réglage des hyperparamètres. Le contenu de l'onglet TÂCHES DE RÉGLAGE D'HYPERPARAMÈTRES de la section Entraînement de votre console ressemblera à ceci :
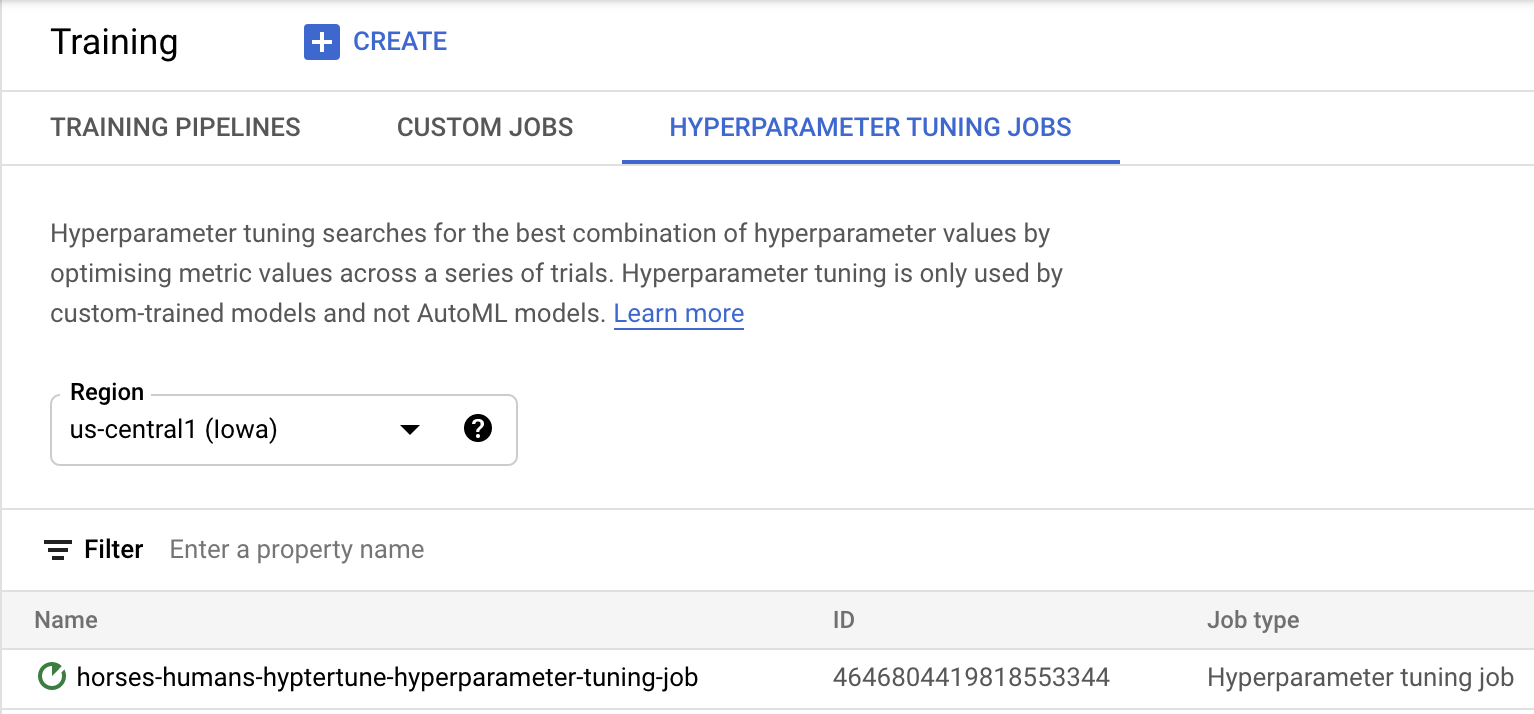
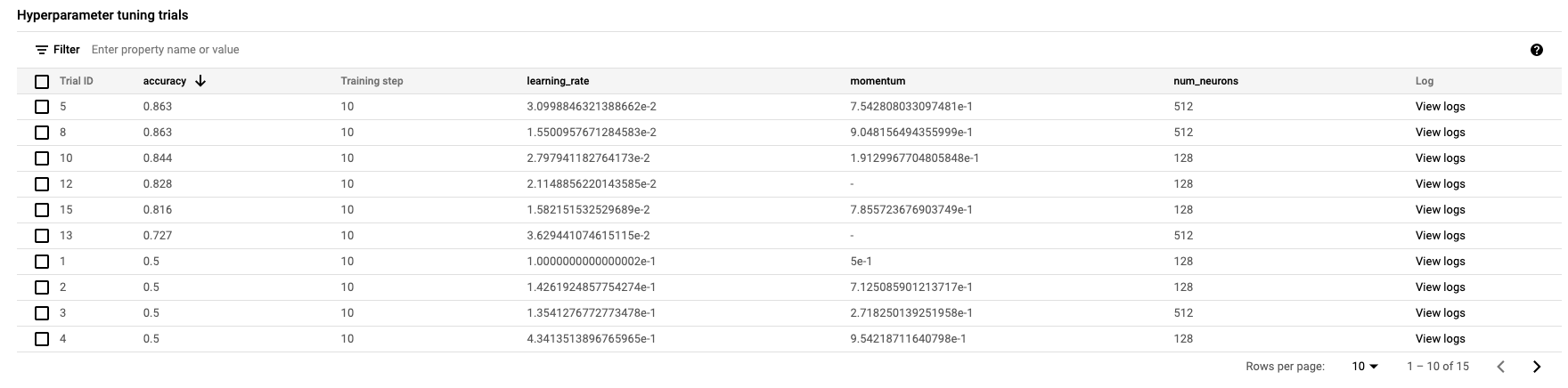
Quand il sera terminé, vous pourrez cliquer sur le nom du job et voir les résultats des essais de réglage.
🎉 Félicitations ! 🎉
Vous savez désormais utiliser Vertex AI pour :
- lancer un job de réglage des hyperparamètres pour le code d'entraînement fourni dans un conteneur personnalisé. dans cet exemple, vous avez utilisé un modèle TensorFlow, mais vous pouvez entraîner un modèle créé avec n'importe quel framework à l'aide de conteneurs personnalisés.
Pour en savoir plus sur les différents composants de Vertex, consultez la documentation.
6. [Facultatif] Utiliser Vertex SDK
La section précédente vous a indiqué comment lancer la tâche de réglage des hyperparamètres via l'interface utilisateur. Dans cette section, vous allez voir comment lancer cette tâche à l'aide de l'API Vertex pour Python.
Créez un notebook TensorFlow 2 via le lanceur.

Importez le SDK Vertex AI.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Pour lancer la tâche de réglage des hyperparamètres, vous devez d'abord définir les spécifications suivantes. Vous devrez remplacer {PROJECT_ID} par l'ID de votre projet dans image_uri.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Créez ensuite un CustomJob. Vous devez remplacer {YOUR_BUCKET} par un bucket de votre projet pour la préproduction.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Ensuite, créez et exécutez HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Nettoyage
Comme le notebook est configuré pour expirer au bout de 60 minutes d'inactivité, il n'est pas nécessaire d'arrêter l'instance. Si vous souhaitez arrêter l'instance manuellement, cliquez sur le bouton "Arrêter" dans la section "Vertex AI Workbench" de la console. Si vous souhaitez supprimer le notebook définitivement, cliquez sur le bouton "Supprimer".

Pour supprimer le bucket de stockage, utilisez le menu de navigation de la console Cloud pour accéder à Stockage, sélectionnez votre bucket puis cliquez sur "Supprimer" :