1. 概要
このラボでは、Vertex AI を使用して、TensorFlow モデルのハイパーパラメータ調整ジョブを実行します。このラボではモデルコードに TensorFlow を使用しますが、このコンセプトは別の ML フレームワークにも応用できます。
学習内容
次の方法を学習します。
- 自動でハイパーパラメータ調整を行うように、トレーニング アプリケーション コードを変更する
- Vertex AI UI でハイパーパラメータ調整ジョブを構成して起動する
- Vertex AI Python SDK を使用して、ハイパーパラメータ調整ジョブを構成して起動する
Google Cloud でこのラボを実行するための総費用は約 $3 USD です。
2. Vertex AI の概要
このラボでは、Google Cloud で利用できる最新の AI プロダクトを使用します。Vertex AI は Google Cloud 全体の ML サービスを統合してシームレスな開発エクスペリエンスを提供します。以前は、AutoML でトレーニングしたモデルやカスタムモデルにそれぞれ個別のサービスを介してアクセスする必要がありましたが、Vertex AI は、これらの個別のサービスを他の新しいプロダクトとともに 1 つの API にまとめます。既存のプロジェクトを Vertex AI に移行することもできます。ご意見やご質問がありましたら、サポートページからお寄せください。
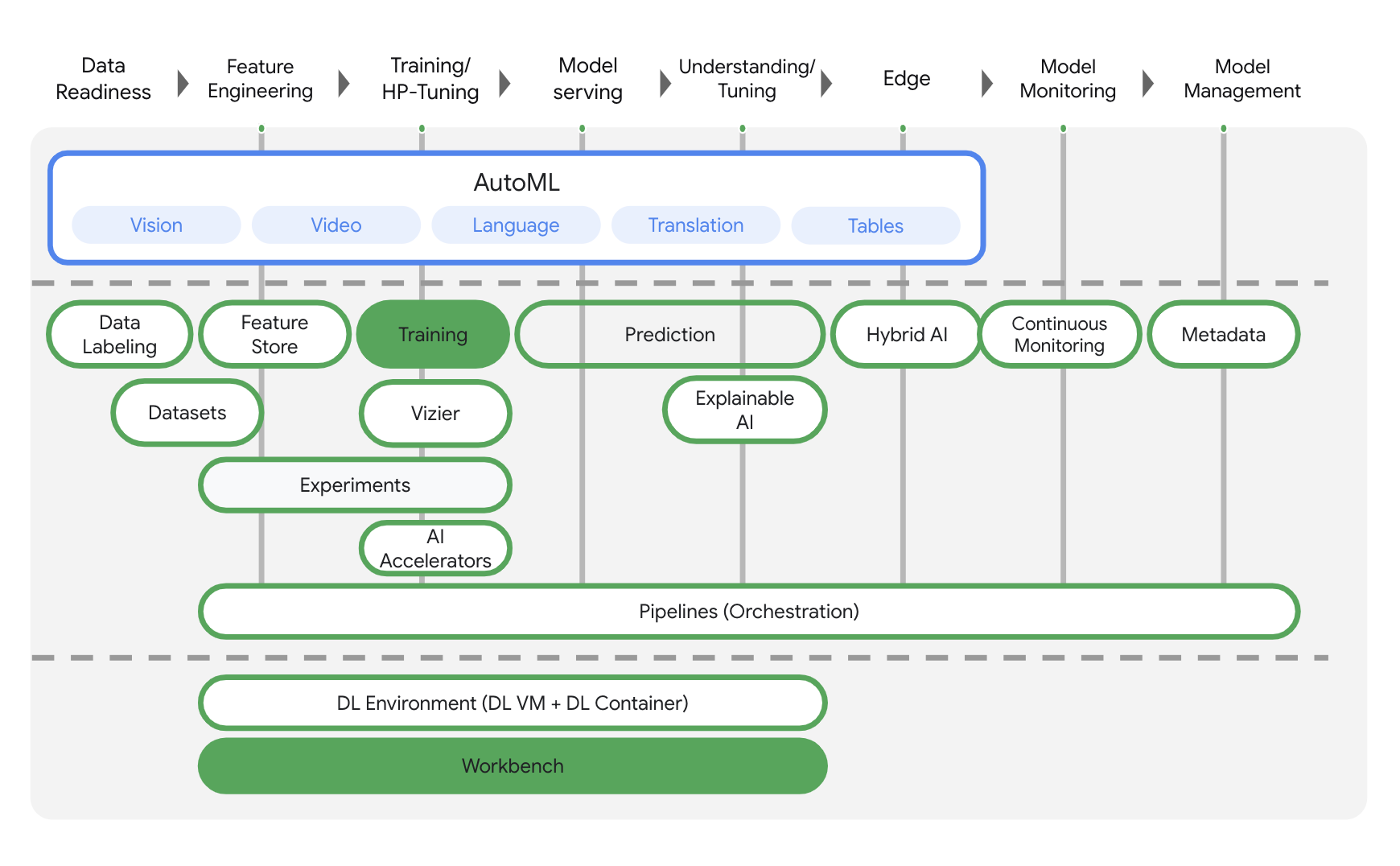
Vertex AI には、エンドツーエンドの ML ワークフローをサポートするさまざまなプロダクトが含まれています。このラボでは、トレーニング とワークベンチ という 2 つのプロダクトに焦点を当てます。
3. 環境を設定する
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順を行ってください。
ステップ 1: Compute Engine API を有効にする
Compute Engine に移動し、まだ有効になっていない場合は [有効にする] を選択します。これはノートブック インスタンスを作成するために必要です。
ステップ 2: Container Registry API を有効にする
まだ有効になっていない場合は、[Container Registry] に移動して [有効にする] を選択します。これは、カスタム トレーニング ジョブのコンテナを作成する際に使用します。
ステップ 3: Vertex AI API を有効にする
Cloud コンソールの [Vertex AI] セクションに移動し、[Vertex AI API を有効にする] をクリックします。
ステップ 4: Vertex AI Workbench インスタンスを作成する
Cloud Console の [Vertex AI] セクションで [ワークベンチ] をクリックします。
Notebooks API をまだ有効にしていない場合は、有効にします。
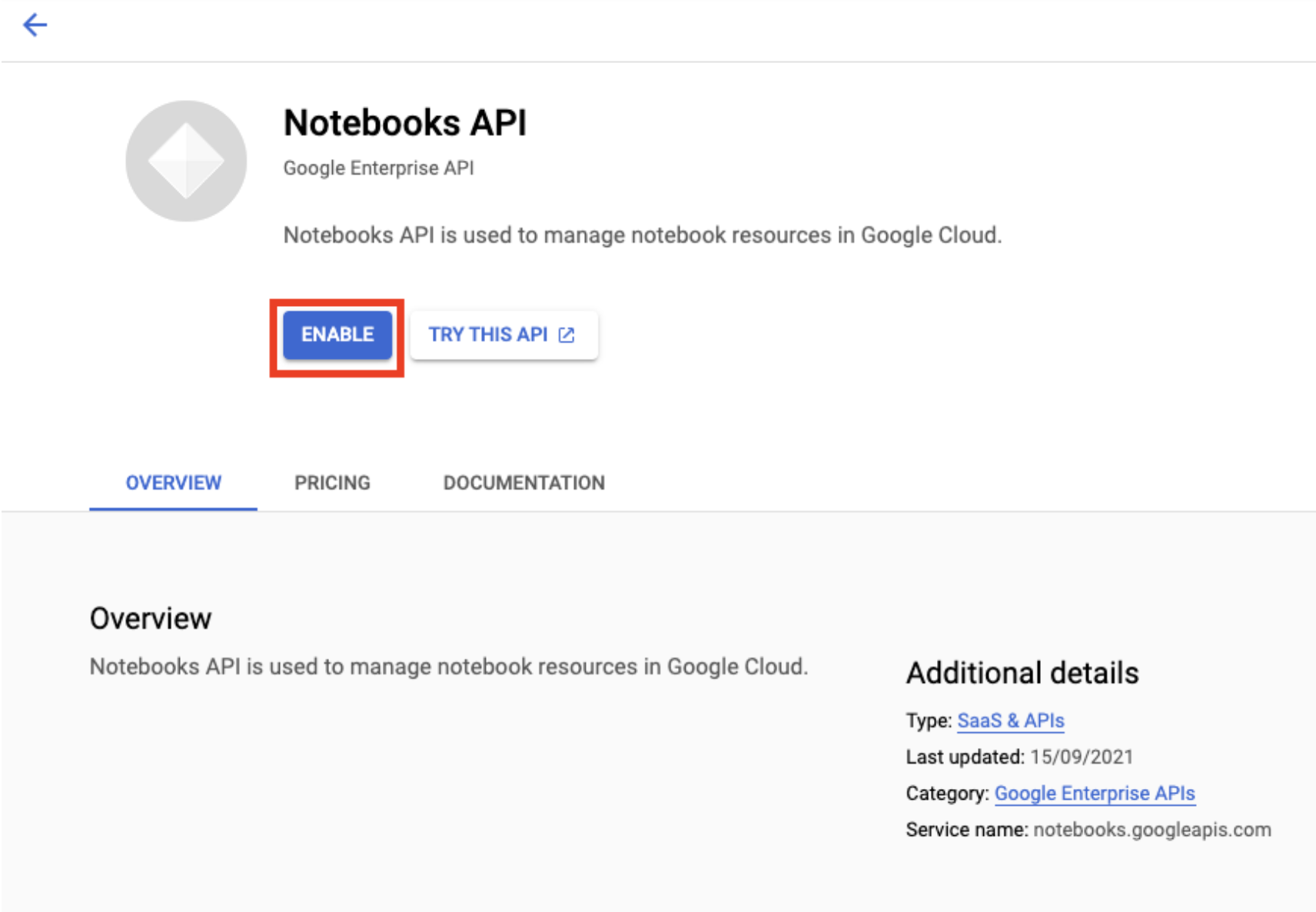
有効にしたら、[マネージド ノートブック] をクリックします。

[新しいノートブック] を選択します。
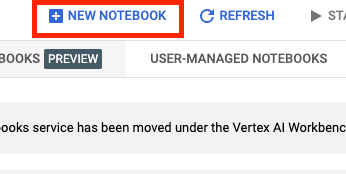
ノートブックに名前を付けて、[詳細設定] をクリックします。

[詳細設定] で、アイドル状態でのシャットダウンを有効にして、シャットダウンまでの時間(分)を 60 に設定します。これにより、使用されていないノートブックが自動的にシャットダウンされるため、不要なコストが発生しません。

まだ有効になっていない場合は、[セキュリティ ] で、[Enable terminal] を選択します。
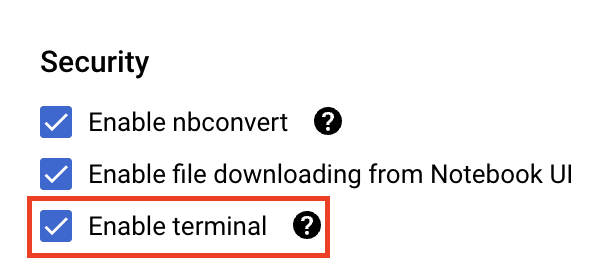
詳細設定のその他の設定はそのままで構いません。
[作成] をクリックします。インスタンスがプロビジョニングされるまでに数分かかります。
インスタンスが作成されたら、[JUPYTERLAB を開く] を選択します。

新しいインスタンスを初めて使用するときに、認証が求められます。その場合は、UI で手順を行います。
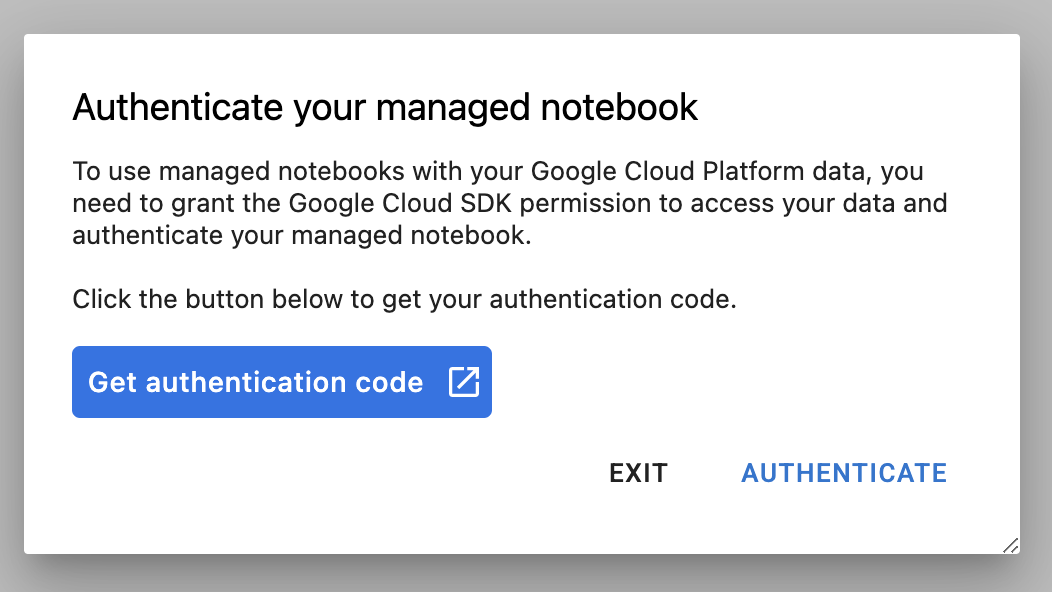
4. トレーニング アプリケーション コードをコンテナ化する
このラボでトレーニングや調整を行うモデルは、TensorFlow データセットにある馬と人間のデータセットによってトレーニングされる画像分類モデルです。
このハイパーパラメータ調整ジョブを Vertex AI に送信するには、トレーニング アプリケーション コードを Docker コンテナに配置してこのコンテナを Google Container Registry に push します。この方法により、任意のフレームワークで構築されたモデルのハイパーパラメータを調整できます。
まず、Launcher メニューから、ノートブック インスタンスでターミナル ウィンドウを開きます。

horses_or_humans という新しいディレクトリを作成し、そのディレクトリに移動します。
mkdir horses_or_humans
cd horses_or_humans
ステップ 1: Dockerfile を作成する
コードをコンテナ化する最初のステップは、Dockerfile の作成です。Dockerfile には、イメージの実行に必要なすべてのコマンドを含めます。このファイルにより、CloudML Hypertune ライブラリなど、必要なライブラリがすべてインストールされ、トレーニング コードのエントリ ポイントが設定されます。
ターミナルで、空の Dockerfile を作成します。
touch Dockerfile
Dockerfile を開き、次の内容をコピーします。
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
この Dockerfile は Deep Learning Container TensorFlow Enterprise 2.7 GPU Docker イメージを使用します。Google Cloud の Deep Learning Containers には一般的な ML およびデータ サイエンスのフレームワークが数多くプリインストールされています。該当するイメージのダウンロード後、この Dockerfile はトレーニング コードのエントリポイントを設定します。これらのファイルはまだ作成していません。次のステップで、モデルのトレーニングおよび調整用のコードを追加します。
ステップ 2: モデルのトレーニング コードを追加する
ターミナルで、次のように実行してトレーニング コード用のディレクトリと、コードを追加する Python ファイルを作成します。
mkdir trainer
touch trainer/task.py
horses_or_humans/ ディレクトリに、次のものが作成されます。
+ Dockerfile
+ trainer/
+ task.py
いま作成した task.py ファイルを開いて、次のコードをコピーします。
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
コンテナをビルドする前に、コードを詳しく見ておきましょう。ハイパーパラメータ調整サービスを使用するための専用コンポーネントがいくつかあります。
- このスクリプトは、
hypertuneライブラリをインポートします。ステップ 1 の Dockerfile には、このライブラリを pip インストールする命令が含まれていました。 get_args()関数では、調整するハイパーパラメータごとにコマンドライン引数を定義します。この例で調整するハイパーパラメータは、学習率、オプティマイザーのモメンタム値、モデルの最終隠しレイヤのユニット数ですが、その他のパラメータの調整も自由に試してください。これらの引数に渡された値はその後、コード内で対応するハイパーパラメータを設定するために使用されます。main()関数の最後で、hypertuneライブラリを使用して、最適化する指標を定義します。TensorFlow では、Kerasmodel.fitメソッドはHistoryオブジェクトを返します。History.history属性は、連続したエポックにおけるトレーニングの損失値と指標値の記録です。検証データをmodel.fitに渡した場合、History.history属性には検証損失値と指標値も含まれます。たとえば、検証データを用いて 3 回のエポックでモデルをトレーニングし、指標としてaccuracyを提供した場合、History.history属性は以下の辞書のようになります。
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
ハイパーパラメータ調整サービスでモデルの検証精度を最大化する値を見つけたい場合は、その指標を val_accuracy リストの最後のエントリ(または NUM_EPOCS - 1)として定義します。その後、この指標を HyperTune のインスタンスに渡します。hyperparameter_metric_tag には任意の文字列を選択できますが、ハイパーパラメータ調整ジョブを開始する際には、その文字列を再び使用する必要があります。
ステップ 3: コンテナをビルドする
ターミナルで以下のように実行して、プロジェクトの環境変数を定義します。その際、your-cloud-project は実際のプロジェクト ID で置き換えてください。
PROJECT_ID='your-cloud-project'
Google Container Registry 内のコンテナ イメージの URI を示す変数を定義します。
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Docker を構成します。
gcloud auth configure-docker
続いて、horses_or_humans ディレクトリのルートで次のように実行してコンテナをビルドします。
docker build ./ -t $IMAGE_URI
最後に、これを Google Container Registry に push します。
docker push $IMAGE_URI
コンテナを Container Registry に push したら、カスタムモデルのハイパーパラメータ調整ジョブをいつでも開始できます。
5. Vertex AI でハイパーパラメータ調整ジョブを実行する
このラボでは、Google Container Registry のカスタム コンテナによるカスタム トレーニングを使用します。ハイパーパラメータ調整ジョブは、Vertex AI ビルド済みコンテナを使って実行することもできます。
まず、Cloud コンソールの Vertex で [トレーニング] セクションに移動します。
ステップ 1: トレーニング ジョブを構成する
ハイパーパラメータ調整ジョブのパラメータを入力するには、[作成] をクリックします。
- [Dataset] で [マネージド データセットなし] を選択します。
- トレーニング方法として [カスタム トレーニング(上級者向け)] を選択し、[続行] をクリックします。
- [モデル名] には「
horses-humans-hyptertune」(または任意のモデル名)を入力します。 - [続行] をクリックする
コンテナの設定ステップで、[カスタム コンテナ] を選択します。

最初のボックス(コンテナ イメージ )で、前のセクションの IMAGE_URI 変数の値を入力します。これは gcr.io/your-cloud-project/horse-human:hypertune になります。`your-cloud-project` は実際のプロジェクト名に置き換えてください。その他のフィールドは空白のままにして、[続行] をクリックします。
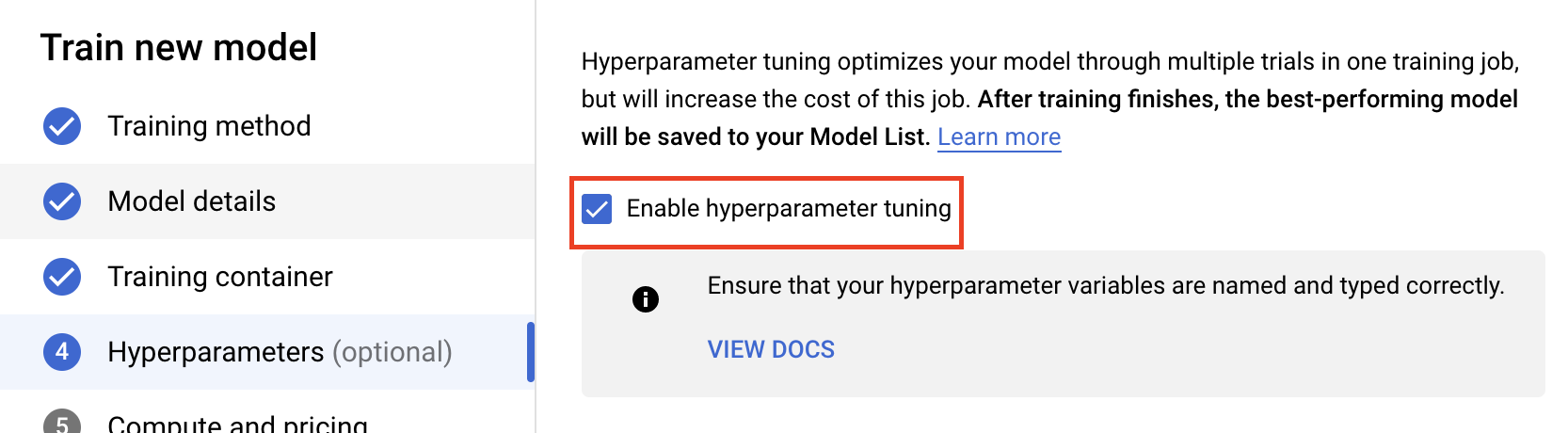
ステップ 2: ハイパーパラメータ調整ジョブを構成する
[Enable hyperparameter tuning] を選択します。
ハイパーパラメータを構成する
次に、トレーニング アプリケーションのコードで、コマンドライン引数として設定するハイパーパラメータを追加する必要があります。ハイパーパラメータを追加するには、まずその名前を指定する必要があります。この名前は argparse に渡した引数名と一致している必要があります。

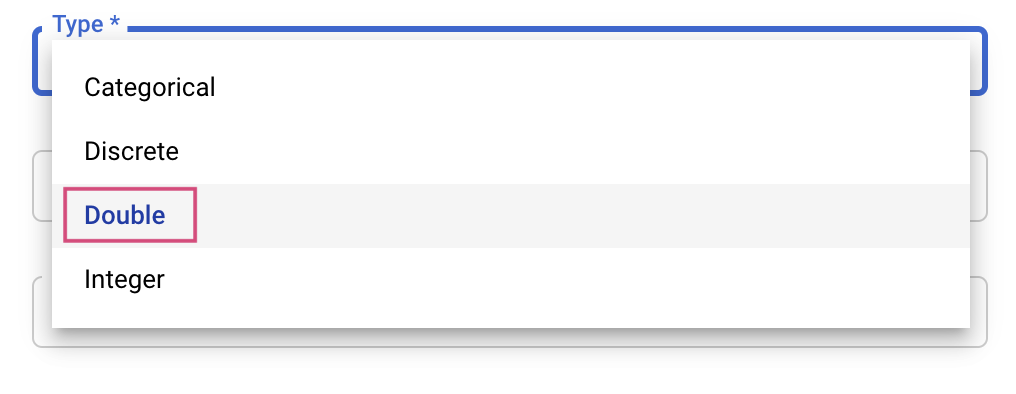
次に、タイプと調整サービスが試行する値の境界を選択します。タイプに Double または Integer を選択した場合は、最小値と最大値を指定する必要があります。Categorical または Discrete を選択した場合は、値を入力する必要があります。

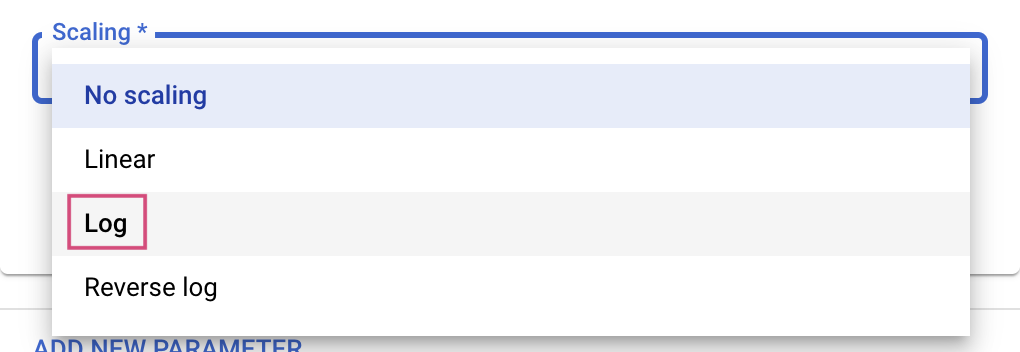
Double タイプと Integer タイプでは、Scaling の値も必要になります。
learning_rate ハイパーパラメータを追加したら、momentum と num_units のパラメータを追加します。


指標を構成する
ハイパーパラメータを追加した後、最適化する指標と目標を指定します。これは、トレーニング アプリケーションで設定した hyperparameter_metric_tag と同じにする必要があります。
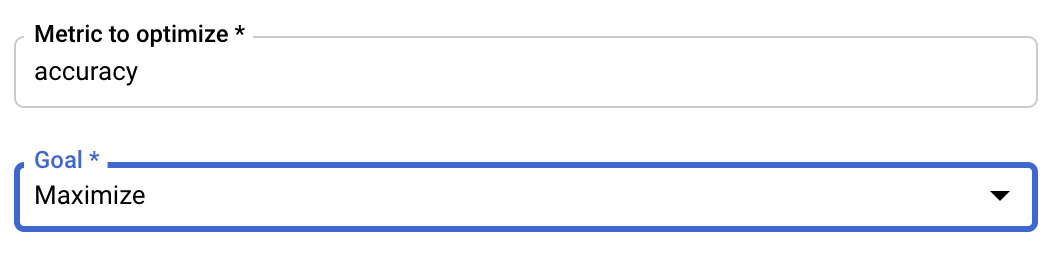
Vertex AI ハイパーパラメータ調整サービスは、これまでの手順で構成した値を用いてトレーニング アプリケーションのトライアルを複数回にわたって実行します。サービスが実行するトライアルの数に上限を設ける必要があります。トライアルの回数を増やすと一般的に良い結果が得られますが、収穫逓減のポイントがあり、それ以降はトライアルの回数を増やしても最適化しようとしている指標にほとんど影響がなくなります。少ないトライアル回数から始めて、選択したハイパーパラメータの影響力を把握してから、十分なトライアル回数までスケールアップするのがベスト プラクティスです。
並列トライアルの数に上限を設定する必要もあります。並列トライアルの回数を増やすと、ハイパーパラメータ調整ジョブの実行時間が短縮されますが、ジョブ全体の効果が低下する可能性がありますこれは、デフォルトの調整戦略では、過去のトライアルの結果を後続のトライアルでの値の割り当てに使用するためです。あまりに多くのトライアルを並列に実行した場合、まだ実行中のトライアルの結果を活用できないまま開始されるトライアルが出てきます。
デモを目的とする場合は、トライアルの数を 15 に、並列トライアルの最大数を 3 に設定するとよいでしょう。さまざまな数値を試すことができますが、そうすると調整にかかる時間が長くなり、費用がかさみます。

最後のステップは、検索アルゴリズムとして [デフォルト] を選択することです。この設定では、Google Vizier を使用してハイパーパラメータ調整のベイズ最適化が実行されます。このアルゴリズムの詳細については、こちらをご覧ください。
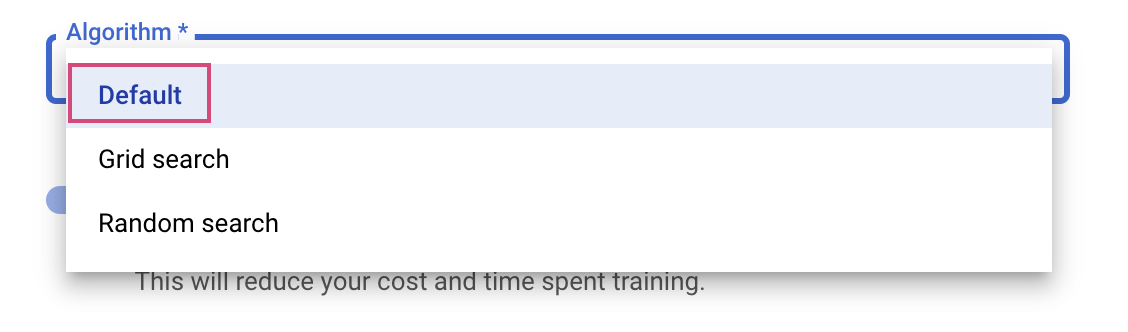
[続行] をクリックします。
ステップ 3: コンピューティングを構成する
[コンピューティングと料金] で、選択されているリージョンはそのままにしておき、[ワーカープール 0] を次のように構成します。
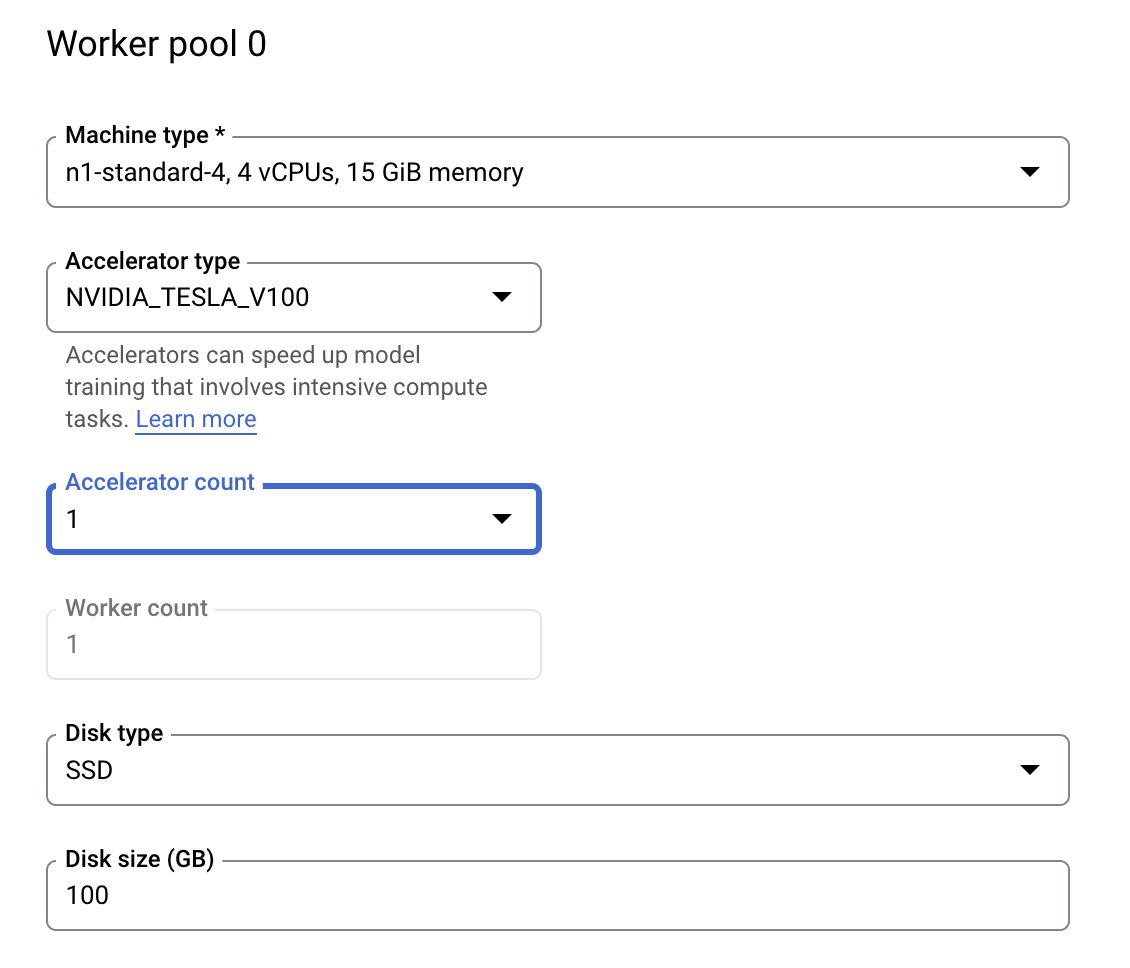
[トレーニングを開始] をクリックして、ハイパーパラメータ調整ジョブを開始します。コンソールの [トレーニング] セクションにある [ハイパーパラメータ調整ジョブ] タブに次のように表示されます。
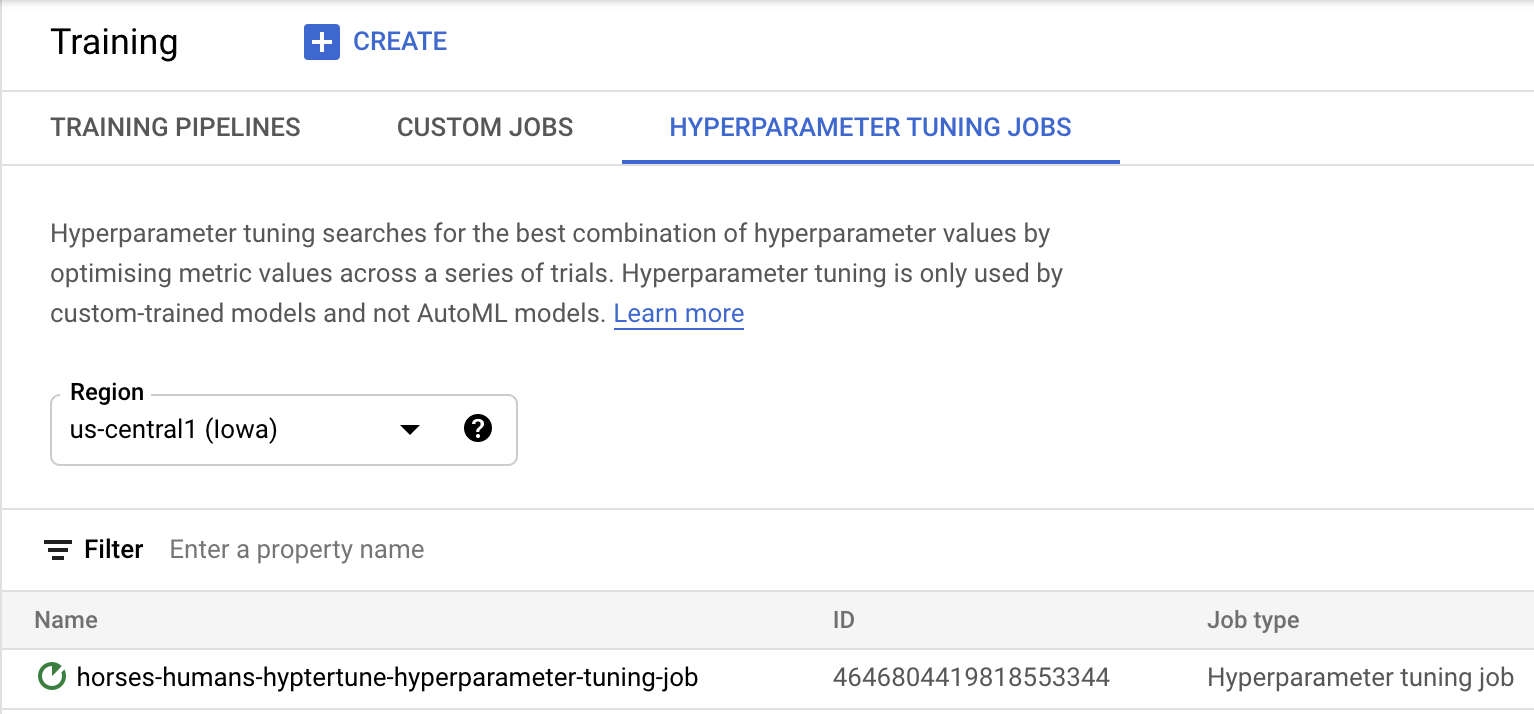
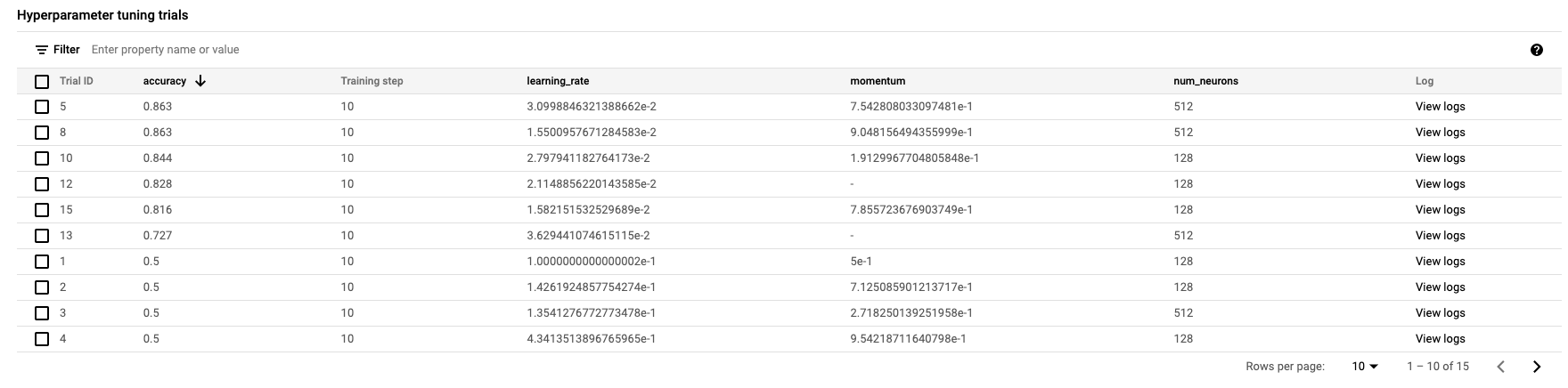
終了すると、ジョブ名をクリックして調整のトライアル結果を見ることができます。
お疲れさまでした🎉
Vertex AI を使って次のことを行う方法を学びました。
- カスタム コンテナに用意されているトレーニング コード用のハイパーパラメータ調整ジョブの起動: ここでは例として TensorFlow モデルを使用しましたが、カスタム コンテナを使って任意のフレームワークで構築されたモデルをトレーニングすることができます。
Vertex のさまざまな部分の説明については、ドキュメントをご覧ください。
6. [省略可] Vertex SDK を使用する
前のセクションでは、UI でハイパーパラメータ調整ジョブを起動する方法を説明しました。このセクションでは、Vertex Python API を使用してハイパーパラメータ調整ジョブを送信するという別の方法を説明します。
Launcher から TensorFlow 2 ノートブックを作成します。

Vertex AI SDK をインポートします。
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
ハイパーパラメータ調整ジョブを起動するには、まず以下の仕様を定義する必要があります。image_uri の {PROJECT_ID} は実際のプロジェクトに置き換えます。
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
次に、CustomJob を作成します。{YOUR_BUCKET} の部分はステージング用のプロジェクトのバケットで置き換える必要があります。
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
次に、HyperparameterTuningJob を作成して実行します。
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. クリーンアップ
ノートブックは、アイドル状態で 60 分が経過するとタイムアウトするように構成されています。このため、インスタンスのシャットダウンを心配する必要はありません。インスタンスを手動でシャットダウンする場合は、Console で [Vertex AI] の [ワークベンチ] セクションにある [停止] ボタンをクリックします。ノートブックを完全に削除する場合は、[削除] ボタンをクリックします。

ストレージ バケットを削除するには、Cloud コンソールのナビゲーション メニューで [ストレージ] に移動してバケットを選択し、[削除] をクリックします。