
1. סקירה כללית
בשיעור ה-Lab הזה תשתמשו ב-Vertex AI כדי להריץ משימת כוונון היפר-פרמטרים למודל TensorFlow. בשיעור Lab הזה נעשה שימוש ב-TensorFlow לקוד המודל, אבל המושגים רלוונטיים גם למסגרות אחרות של ML.
מה לומדים
במאמר הזה נסביר איך:
- שינוי קוד אפליקציה של האימון לצורך כוונון אוטומטי של היפרפרמטרים
- הגדרה והפעלה של משימת כוונון היפר-פרמטרים מממשק המשתמש של Vertex AI
- הגדרת משימת כוונון של היפר-פרמטר והפעלתה באמצעות Vertex AI Python SDK
העלות הכוללת להרצת ה-Lab הזה ב-Google Cloud היא בערך 3$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את מוצרי ה-ML ב-Google Cloud לחוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שאומנו באמצעות AutoML ולמודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את שניהם ב-API אחד, יחד עם מוצרים חדשים אחרים. אפשר גם להעביר פרויקטים קיימים אל Vertex AI. אם יש לך משוב, אפשר לעיין בדף התמיכה.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. בשיעור ה-Lab הזה נתמקד במוצרים שמודגשים בהמשך: Training ו-Workbench.

3. הגדרת הסביבה
כדי להפעיל את ה-codelab הזה, צריך פרויקט ב-Google Cloud Platform שמופעל בו חיוב. כדי ליצור פרויקט, פועלים לפי ההוראות האלה.
שלב 1: הפעלת Compute Engine API
עוברים אל Compute Engine ובוחרים באפשרות הפעלה אם הוא עדיין לא מופעל. תצטרכו את זה כדי ליצור את מופע המחברת.
שלב 2: הפעלת Container Registry API
עוברים אל Container Registry ובוחרים באפשרות Enable (הפעלה) אם היא עדיין לא מסומנת. תשתמשו בזה כדי ליצור קונטיינר למשימת האימון המותאמת אישית.
שלב 3: הפעלת Vertex AI API
עוברים אל הקטע Vertex AI במסוף Cloud ולוחצים על הפעלת Vertex AI API.

שלב 4: יצירת מכונה של Vertex AI Workbench
בקטע Vertex AI במסוף Cloud, לוחצים על Workbench:

מפעילים את Notebooks API אם הוא עדיין לא מופעל.

אחרי ההפעלה, לוחצים על מחברות מנוהלות:

לאחר מכן בוחרים באפשרות מחברת חדשה.

נותנים שם למחברת ולוחצים על הגדרות מתקדמות.

בקטע 'הגדרות מתקדמות', מפעילים את ההגדרה 'כיבוי במצב לא פעיל' ומגדירים את מספר הדקות ל-60. המשמעות היא שמחברת ה-notebook תיסגר אוטומטית כשלא משתמשים בה, כדי שלא תצטברו עלויות מיותרות.

בקטע אבטחה, בוחרים באפשרות 'הפעלת מסוף' אם היא עדיין לא מופעלת.

אפשר להשאיר את כל ההגדרות המתקדמות האחרות כמו שהן.
אחרי כן, לוחצים על יצירה. ייקח כמה דקות עד שהמופע יוקצה.
אחרי שהמופע נוצר, בוחרים באפשרות Open JupyterLab.

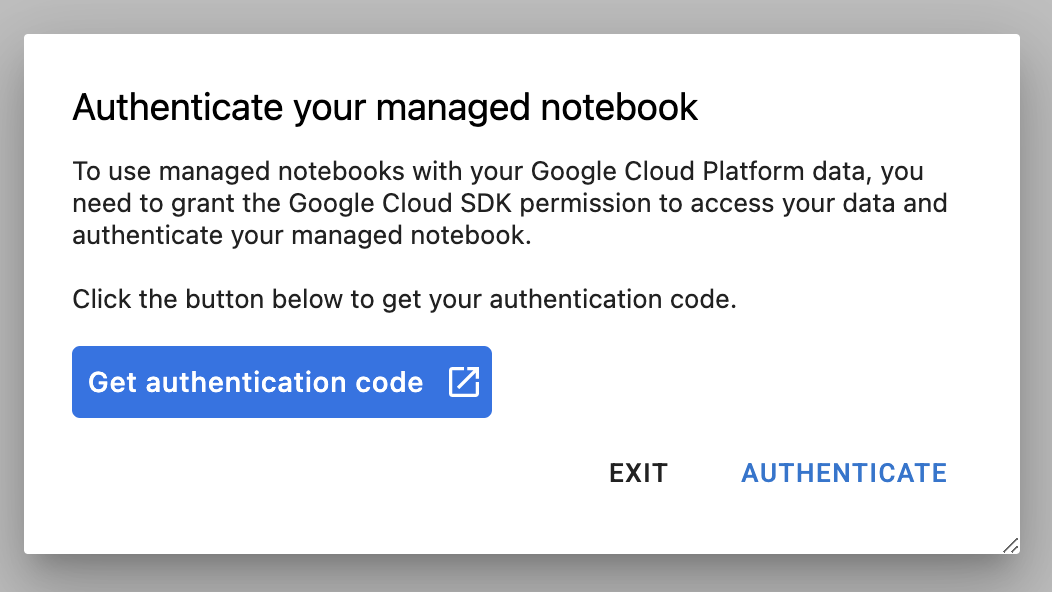
בפעם הראשונה שמשתמשים במופע חדש, תופיע בקשה לבצע אימות. פועלים לפי השלבים בממשק המשתמש.
4. יצירת קונטיינר לקוד אפליקציה של אימון
המודל שתאמנו ותשפרו בשיעור ה-Lab הזה הוא מודל לסיווג תמונות שאומן על מערך הנתונים של סוסים או בני אדם מתוך TensorFlow Datasets.
תשלחו את משימת כוונון ההיפרפרמטרים אל Vertex AI על ידי הכנסת קוד אפליקציית האימון אל קונטיינר Docker והעברת הקונטיינר הזה אל Google Container Registry. באמצעות הגישה הזו, אפשר לכוונן היפרפרמטרים של מודל שנבנה באמצעות כל מסגרת.
כדי להתחיל, בתפריט מרכז האפליקציות, פותחים חלון הטרמינל במופע של מחברת:

יוצרים ספרייה חדשה בשם horses_or_humans ועוברים אליה באמצעות הפקודה cd:
mkdir horses_or_humans
cd horses_or_humans
שלב 1: יצירת Dockerfile
השלב הראשון בהעברת הקוד למאגר הוא יצירת Dockerfile. ב-Dockerfile, צריך לכלול את כל הפקודות שנדרשות להרצת האימג'. הוא יתקין את כל הספריות הנדרשות, כולל ספריית CloudML Hypertune, ויגדיר את נקודת הכניסה לקוד האימון.
ב-Terminal, יוצרים קובץ Dockerfile ריק:
touch Dockerfile
פותחים את Dockerfile ומעתיקים לתוכו את הקוד הבא:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
קובץ ה-Dockerfile הזה משתמש בקובץ אימג' של Docker ל-GPU של TensorFlow Enterprise 2.7 של Deep Learning Container. הקונטיינרים של Deep Learning ב-Google Cloud מגיעים עם הרבה frameworks נפוצים של ML ומדעי נתונים שהותקנו מראש. אחרי שמורידים את התמונה הזו, קובץ ה-Docker הזה מגדיר את נקודת הכניסה לקוד האימון. עדיין לא יצרתם את הקבצים האלה – בשלב הבא תוסיפו את הקוד לאימון המודל ולכוונון שלו.
שלב 2: מוסיפים קוד לאימון המודל
במסוף, מריצים את הפקודה הבאה כדי ליצור ספרייה לקוד האימון וקובץ Python שבו תוסיפו את הקוד:
mkdir trainer
touch trainer/task.py
עכשיו אמורים להיות לכם הקבצים הבאים בספרייה horses_or_humans/:
+ Dockerfile
+ trainer/
+ task.py
לאחר מכן, פותחים את הקובץ task.py שיצרתם ומעתיקים את הקוד שבהמשך.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
לפני שיוצרים את הקונטיינר, כדאי לעיין בקוד. יש כמה רכיבים שספציפיים לשימוש בשירות להתאמת היפרפרמטרים.
- הסקריפט מייבא את הספרייה
hypertune. שימו לב שקובץ ה-Dockerfile משלב 1 כולל הוראות להתקנת הספרייה הזו באמצעות pip. - הפונקציה
get_args()מגדירה ארגומנט בשורת הפקודה לכל היפרפרמטר שרוצים לכוונן. בדוגמה הזו, ההיפרפרמטרים שיעברו אופטימיזציה הם קצב הלמידה, ערך המומנטום באופטימיזציה ומספר היחידות בשכבה הנסתרת האחרונה של המודל, אבל אתם יכולים להתנסות גם עם פרמטרים אחרים. הערך שמועבר בארגומנטים האלה משמש להגדרת ההיפרפרמטר המתאים בקוד. - בסוף הפונקציה
main(), נעשה שימוש בספרייהhypertuneכדי להגדיר את המדד שרוצים לבצע אופטימיזציה שלו. ב-TensorFlow, השיטהmodel.fitשל keras מחזירה אובייקטHistory. המאפייןHistory.historyהוא רשומה של ערכי הפסד באימון וערכי מדדים בתקופות עוקבות. אם מעבירים נתוני אימות אלmodel.fit, מאפייןHistory.historyיכלול גם את ערכי המדדים ואת הפסד האימות. לדוגמה, אם אימנתם מודל ל-3 תקופות עם נתוני אימות וסיפקתם אתaccuracyכמדד, מאפייןHistory.historyייראה בערך כמו המילון הבא.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
אם רוצים ששירות אופטימיזציית ההיפרפרמטרים יגלה את הערכים שממקסמים את דיוק האימות של המודל, צריך להגדיר את המדד כערך האחרון (או NUM_EPOCS - 1) ברשימה val_accuracy. לאחר מכן, מעבירים את המדד הזה למופע של HyperTune. אתם יכולים לבחור איזו מחרוזת שתרצו בשביל hyperparameter_metric_tag, אבל תצטרכו להשתמש במחרוזת שוב בהמשך כשמפעילים את משימת ההתאמה של ההיפרפרמטרים.
שלב 3: בניית מאגר התגים
במסוף, מריצים את הפקודה הבאה כדי להגדיר משתנה סביבה לפרויקט. חשוב להחליף את your-cloud-project במזהה הפרויקט:
PROJECT_ID='your-cloud-project'
מגדירים משתנה עם ה-URI של קובץ אימג' של קונטיינר ב-Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
הגדרת Docker
gcloud auth configure-docker
לאחר מכן, בונים את הקונטיינר על ידי הרצת הפקודה הבאה מתיקיית השורש של horses_or_humans:
docker build ./ -t $IMAGE_URI
לבסוף, מעלים אותו אל Google Container Registry:
docker push $IMAGE_URI
אחרי שמעבירים את הקונטיינר אל Container Registry, אפשר להתחיל להריץ משימה של כוונון היפרפרמטרים של מודל בהתאמה אישית.
5. הרצת משימת כוונון של היפר-פרמטרים ב-Vertex AI
במעבדה הזו נעשה שימוש באימון בהתאמה אישית באמצעות קונטיינר בהתאמה אישית ב-Google Container Registry, אבל אפשר גם להריץ משימת אופטימיזציה של היפרפרמטרים באמצעות קונטיינר מוכן מראש של Vertex AI.
כדי להתחיל, עוברים לקטע Training בקטע Vertex במסוף Cloud:

שלב 1: הגדרת משימת אימון
לוחצים על יצירה כדי להזין את הפרמטרים של משימת כוונון ההיפר-פרמטרים.
- בקטע מערך נתונים, בוחרים באפשרות אין מערך נתונים מנוהל.
- לאחר מכן בוחרים באפשרות Custom training (advanced) (אימון בהתאמה אישית (מתקדם)) בתור שיטת האימון ולוחצים על Continue (המשך).
- מזינים
horses-humans-hyptertune(או כל שם אחר שרוצים לתת למודל) בשדה שם המודל. - לוחצים על המשך.
בשלב Container settings (הגדרות מאגר התגים), בוחרים באפשרות Custom container (מאגר תגים בהתאמה אישית):

בתיבה הראשונה (קובץ אימג' של קונטיינר), מזינים את הערך של המשתנה IMAGE_URI מהקטע הקודם. הוא צריך להיות: gcr.io/your-cloud-project/horse-human:hypertune, עם שם הפרויקט שלכם. משאירים את שאר השדות ריקים ולוחצים על המשך.
שלב 2: הגדרת משימת כוונון של היפר-פרמטר
בוחרים באפשרות הפעלת כוונון של היפר-פרמטרים.

הגדרת היפרפרמטרים
לאחר מכן, צריך להוסיף את ההיפרפרמטרים שהגדרתם כארגומנטים של שורת הפקודה בקוד אפליקציית האימון. כשמוסיפים היפרפרמטר, קודם צריך לציין את השם שלו. השם הזה צריך להיות זהה לשם הארגומנט שהעברתם אל argparse.

לאחר מכן בוחרים את הסוג ואת הגבולות של הערכים ששירות הכוונון ינסה. אם בוחרים את הסוג Double או Integer, צריך לציין ערך מינימלי ומקסימלי. אם בוחרים באפשרות 'קטגורי' או 'דיסקרטי', צריך לספק את הערכים.
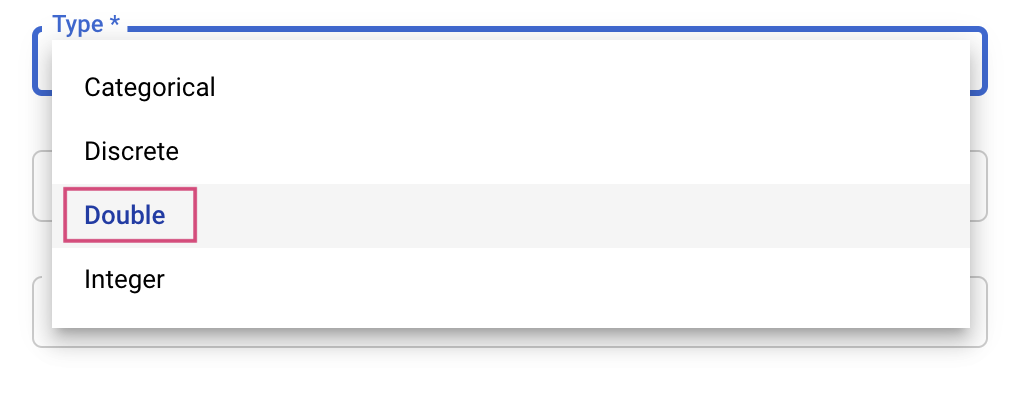

עבור הסוגים Double ו-Integer, תצטרכו לציין גם את ערך ההתאמה.

אחרי שמוסיפים את ההיפר-פרמטר learning_rate, מוסיפים פרמטרים ל-momentum ול-num_units.


הגדרת מדד
אחרי שמוסיפים את ההיפרפרמטרים, צריך לציין את המדד שרוצים לבצע אופטימיזציה שלו ואת היעד. הכתובת צריכה להיות זהה לכתובת hyperparameter_metric_tag שהגדרתם בבקשה להצטרפות לתוכנית.

שירות Vertex AI Hyperparameter tuning יריץ כמה ניסויים של אפליקציית האימון עם הערכים שהוגדרו בשלבים הקודמים. תצטרכו להגדיר את מספר הניסיונות המקסימלי שהשירות יבצע. בדרך כלל, ככל שמבצעים יותר ניסויים התוצאות טובות יותר, אבל מגיע שלב שבו התועלת מניסויים נוספים פוחתת, ואחריו ניסויים נוספים לא משפיעים על המדד שמנסים לבצע בו אופטימיזציה, או שההשפעה שלהם קטנה מאוד. מומלץ להתחיל עם מספר קטן יותר של ניסויים כדי להבין את ההשפעה של ההיפרפרמטרים שבחרתם, לפני שמרחיבים למספר גדול של ניסויים.
תצטרכו גם להגדיר את הגבול העליון למספר הניסויים המקבילים. הגדלת מספר הניסויים המקבילים תקצר את משך הזמן שיידרש להרצת משימת האופטימיזציה של ההיפר-פרמטרים, אבל היא עלולה לפגוע ביעילות הכוללת של המשימה. הסיבה לכך היא שאסטרטגיית הכוונון שמוגדרת כברירת מחדל משתמשת בתוצאות של ניסיונות קודמים כדי להקצות ערכים בניסיונות הבאים. אם מריצים יותר מדי ניסויים במקביל, יהיו ניסויים שיתחילו בלי להסתמך על התוצאות של הניסויים שעדיין פועלים.
לצורך הדגמה, אפשר להגדיר את מספר הניסויים ל-15 ואת המספר המקסימלי של ניסויים מקבילים ל-3. אפשר להתנסות במספרים שונים, אבל זה עלול להאריך את זמן הכוונון ולהגדיל את העלות.

השלב האחרון הוא לבחור באפשרות 'ברירת מחדל' בתור אלגוריתם החיפוש, וכך מערכת Google Vizier תבצע אופטימיזציה בייסיאנית לכוונון היפר-פרמטרים. מידע נוסף על האלגוריתם הזה
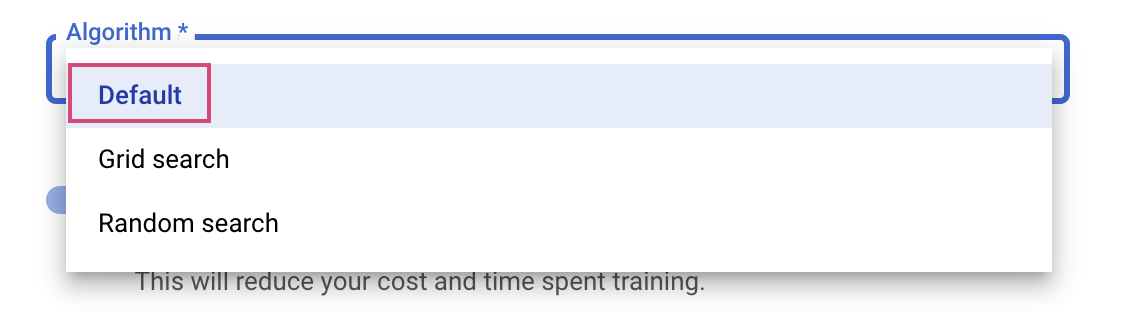
לוחצים על המשך.
שלב 3: הגדרת מחשוב
בקטע Compute and pricing (חישוב ותמחור), משאירים את האזור שנבחר כמו שהוא ומגדירים את Worker pool 0 (מאגר העובדים 0) באופן הבא.

כדי להפעיל את עבודת הכוונון של ההיפרפרמטרים, לוחצים על Start training (התחלת האימון). בקטע Training (אימון) במסוף, בכרטיסייה HYPERPARAMETER TUNING JOBS (משימות של אופטימיזציה של היפרפרמטרים), יופיעו נתונים דומים לאלה:

כשהניסוי יסתיים, תוכלו ללחוץ על שם המשימה ולראות את תוצאות הניסויים של ההתאמה.

🎉 איזה כיף! 🎉
למדתם איך להשתמש ב-Vertex AI כדי:
- הפעלת משימת כוונון היפר-פרמטרים לאימון קוד שסופק בקונטיינר בהתאמה אישית. בדוגמה הזו השתמשנו במודל TensorFlow, אבל אפשר לאמן מודל שנבנה עם כל מסגרת באמצעות קונטיינרים בהתאמה אישית.
מידע נוסף על החלקים השונים של Vertex זמין בתיעוד.
6. [אופציונלי] שימוש ב-Vertex SDK
בקטע הקודם ראינו איך להפעיל את עבודת הכוונון של ההיפר-פרמטרים דרך ממשק המשתמש. בקטע הזה מוצגת דרך חלופית לשליחת משימת כוונון ההיפר-פרמטרים באמצעות Vertex API בשפת Python.
במרכז האפליקציות, יוצרים מחברת TensorFlow 2.

מייבאים את Vertex AI SDK.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
כדי להפעיל את משימת האופטימיזציה של היפר-פרמטרים, צריך קודם להגדיר את המפרטים הבאים. צריך להחליף את {PROJECT_ID} ב-image_uri בפרויקט שלכם.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
לאחר מכן, יוצרים CustomJob. צריך להחליף את {YOUR_BUCKET} בקטגוריה בפרויקט שלכם לצורך העברה זמנית.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
לאחר מכן, יוצרים ומריצים את HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. הסרת המשאבים
הגדרנו את מחברת ה-Jupyter כך שתפסיק לפעול אחרי 60 דקות של חוסר פעילות, ולכן אין צורך לדאוג להשבתת המופע. כדי לכבות את המופע באופן ידני, לוחצים על הלחצן Stop (עצירה) בקטע Vertex AI Workbench במסוף. כדי למחוק את ה-Notebook לגמרי, לוחצים על לחצן המחיקה.

כדי למחוק את קטגוריית האחסון, בתפריט הניווט ב-Cloud Console, עוברים אל Storage, בוחרים את הקטגוריה ולוחצים על Delete:
