1. Overview
In this lab, you'll use Vertex AI to run a hyperparameter tuning job for a TensorFlow model. While this lab uses TensorFlow for the model code, the concepts are applicable to other ML frameworks as well.
What you learn
You'll learn how to:
- Modify training application code for automated hyperparameter tuning
- Configure and launch a hyperparameter tuning job from the Vertex AI UI
- Configure and launch a hyperparameter tuning job with the Vertex AI Python SDK
The total cost to run this lab on Google Cloud is about $3 USD.
2. Intro to Vertex AI
This lab uses the newest AI product offering available on Google Cloud. Vertex AI integrates the ML offerings across Google Cloud into a seamless development experience. Previously, models trained with AutoML and custom models were accessible via separate services. The new offering combines both into a single API, along with other new products. You can also migrate existing projects to Vertex AI. If you have any feedback, please see the support page.
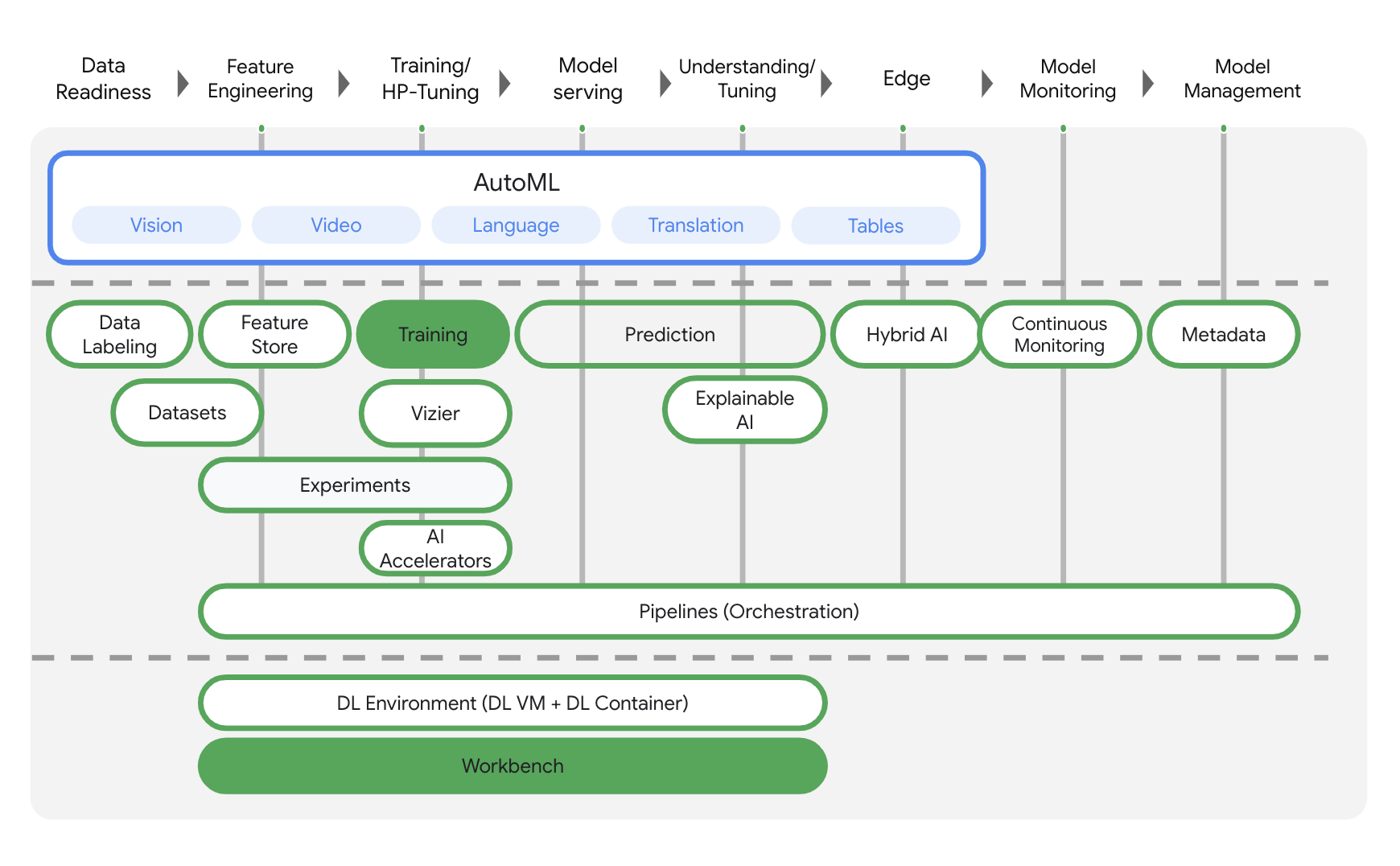
Vertex AI includes many different products to support end-to-end ML workflows. This lab will focus on the products highlighted below: Training and Workbench.
3. Setup your environment
You'll need a Google Cloud Platform project with billing enabled to run this codelab. To create a project, follow the instructions here.
Step 1: Enable the Compute Engine API
Navigate to Compute Engine and select Enable if it isn't already enabled. You'll need this to create your notebook instance.
Step 2: Enable the Container Registry API
Navigate to the Container Registry and select Enable if it isn't already. You'll use this to create a container for your custom training job.
Step 3: Enable the Vertex AI API
Navigate to the Vertex AI section of your Cloud Console and click Enable Vertex AI API.
Step 4: Create a Vertex AI Workbench instance
From the Vertex AI section of your Cloud Console, click on Workbench:
Enable the Notebooks API if it isn't already.
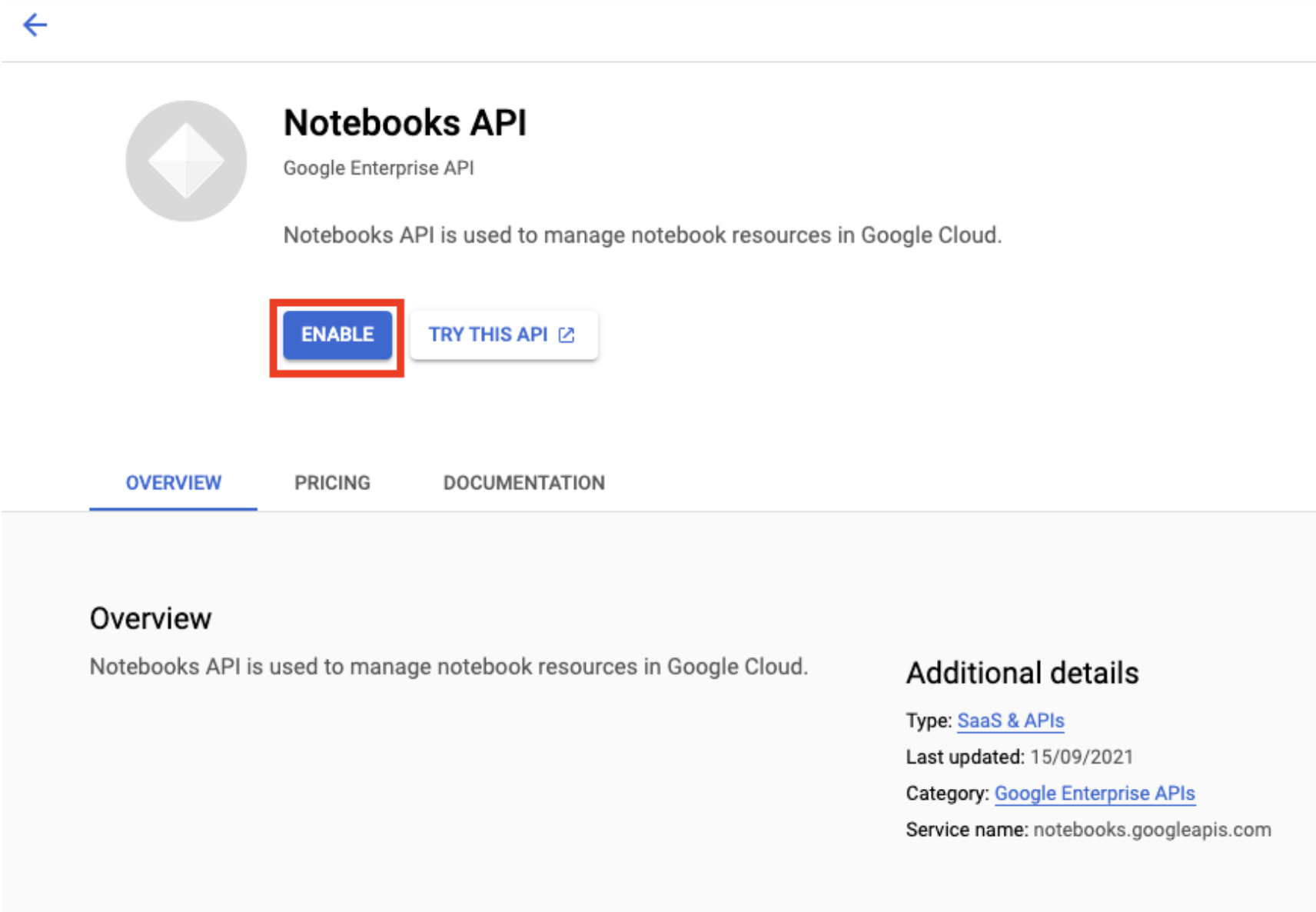
Once enabled, click MANAGED NOTEBOOKS:

Then select NEW NOTEBOOK.
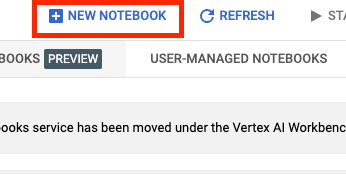
Give your notebook a name, and then click Advanced Settings.

Under Advanced Settings, enable idle shutdown and set the number of minutes to 60. This means your notebook will shutdown automatically when not in use so you don't incur unnecessary costs.

Under Security select "Enable terminal" if it is not already enabled.

You can leave all of the other advanced settings as is.
Next, click Create. The instance will take a couple minutes to be provisioned.
Once the instance has been created, select Open JupyterLab.

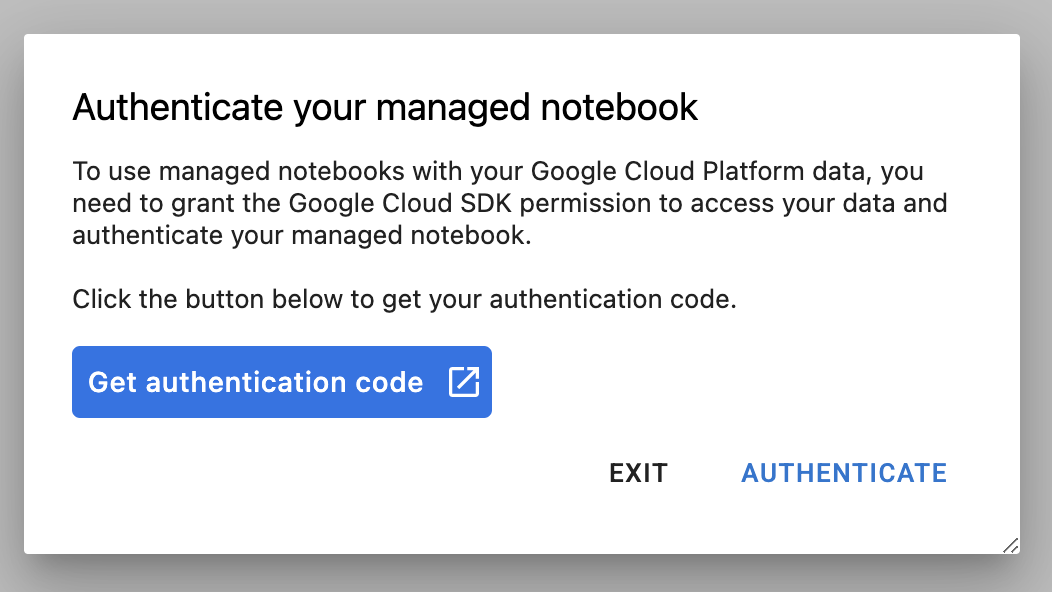
The first time you use a new instance, you'll be asked to authenticate. Follow the steps in the UI to do so.
4. Containerize training application code
The model you'll be training and tuning in this lab is an image classification model trained on the horses or humans dataset from TensorFlow Datasets.
You'll submit this hyperparameter tuning job to Vertex AI by putting your training application code in a Docker container and pushing this container to Google Container Registry. Using this approach, you can tune hyperparameters for a model built with any framework.
To start, from the Launcher menu, open a Terminal window in your notebook instance:

Create a new directory called horses_or_humans and cd into it:
mkdir horses_or_humans
cd horses_or_humans
Step 1: Create a Dockerfile
The first step in containerizing your code is to create a Dockerfile. In the Dockerfile you'll include all the commands needed to run the image. It'll install all the necessary libraries, including the CloudML Hypertune library, and set up the entry point for the training code.
From your Terminal, create an empty Dockerfile:
touch Dockerfile
Open the Dockerfile and copy the following into it:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
This Dockerfile uses the Deep Learning Container TensorFlow Enterprise 2.7 GPU Docker image. The Deep Learning Containers on Google Cloud come with many common ML and data science frameworks pre-installed. After downloading that image, this Dockerfile sets up the entrypoint for the training code. You haven't created these files yet – in the next step, you'll add the code for training and tuning the model.
Step 2: Add model training code
From your Terminal, run the following to create a directory for the training code and a Python file where you'll add the code:
mkdir trainer
touch trainer/task.py
You should now have the following in your horses_or_humans/ directory:
+ Dockerfile
+ trainer/
+ task.py
Next, open the task.py file you just created and copy the code below.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Before you build the container, let's take a deeper look at the code. There are a few components that are specific to using the hyperparameter tuning service.
- The script imports the
hypertunelibrary. Note that the Dockerfile from Step 1 included instructions to pip install this library. - The function
get_args()defines a command-line argument for each hyperparameter you want to tune. In this example, the hyperparameters that will be tuned are the learning rate, the momentum value in the optimizer, and the number of units in the last hidden layer of the model, but feel free to experiment with others. The value passed in those arguments is then used to set the corresponding hyperparameter in the code. - At the end of the
main()function, thehypertunelibrary is used to define the metric you want to optimize. In TensorFlow, the kerasmodel.fitmethod returns aHistoryobject. TheHistory.historyattribute is a record of training loss values and metrics values at successive epochs. If you pass validation data tomodel.fittheHistory.historyattribute will include validation loss and metrics values as well. For example, if you trained a model for three epochs with validation data and providedaccuracyas a metric, theHistory.historyattribute would look similar to the following dictionary.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
If you want the hyperparameter tuning service to discover the values that maximize the model's validation accuracy, you define the metric as the last entry (or NUM_EPOCS - 1) of the val_accuracy list. Then, pass this metric to an instance of HyperTune. You can pick whatever string you like for the hyperparameter_metric_tag, but you'll need to use the string again later when you kick off the hyperparameter tuning job.
Step 3: Build the container
From your Terminal, run the following to define an env variable for your project, making sure to replace your-cloud-project with the ID of your project:
PROJECT_ID='your-cloud-project'
Define a variable with the URI of your container image in Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Configure docker
gcloud auth configure-docker
Then, build the container by running the following from the root of your horses_or_humans directory:
docker build ./ -t $IMAGE_URI
Lastly, push it to Google Container Registry:
docker push $IMAGE_URI
With the container pushed to Container Registry, you're now ready to kick off a custom model hyperparameter tuning job.
5. Run a hyperparameter tuning job on Vertex AI
This lab uses custom training via a custom container on Google Container Registry, but you can also run a hyperparameter tuning job with a Vertex AI Pre-built container.
To start, navigate to the Training section in the Vertex section of your Cloud console:
Step 1: Configure training job
Click Create to enter the parameters for your hyperparameter tuning job.
- Under Dataset, select No managed dataset
- Then select Custom training (advanced) as your training method and click Continue.
- Enter
horses-humans-hyptertune(or whatever you'd like to call your model) for Model name - Click Continue
In the Container settings step, select Custom container:

In the first box (Container image), enter the value of your IMAGE_URI variable from the previous section. It should be: gcr.io/your-cloud-project/horse-human:hypertune, with your own project name. Leave the rest of the fields blank and click Continue.
Step 2: Configure hyperparameter tuning job
Select Enable hyperparameter tuning.
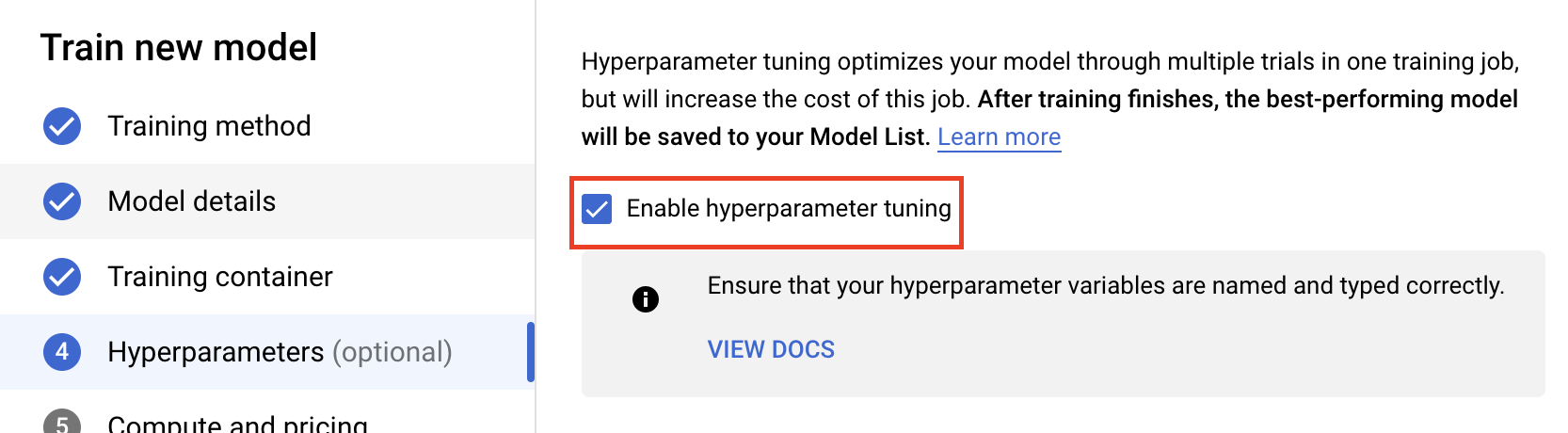
Configure hyperparameters
Next, you'll need to add the hyperparameters that you set as command line arguments in the training application code. When adding a hyperparameter, you'll first need to provide the name. This should match the argument name that you passed to argparse.

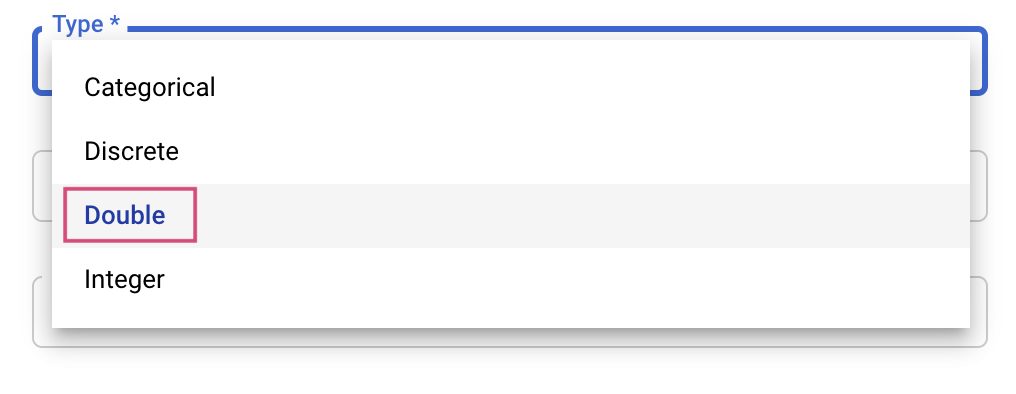
Then, you'll select the Type as well as the bounds for the values that the tuning service will try. If you select the type Double or Integer, you'll need to provide a minimum and maximum value. And if you select Categorical or Discrete you'll need to provide the values.

For the Double and Integer types, you'll also need to provide the Scaling value.
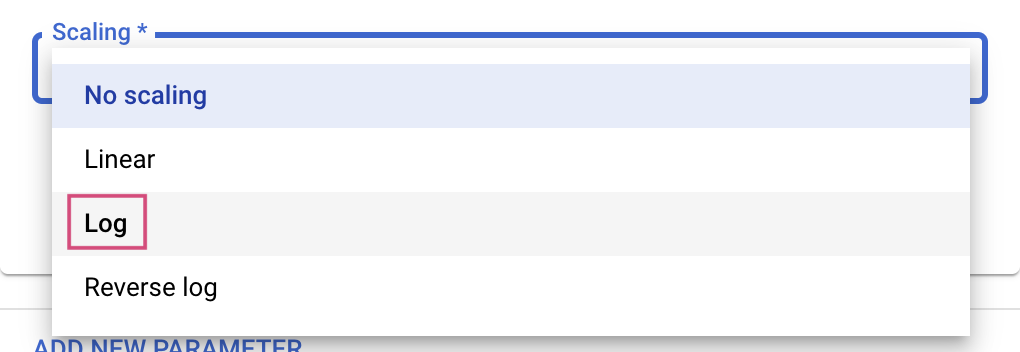
After adding the learning_rate hyperparameter, add parameters for momentum and num_units.


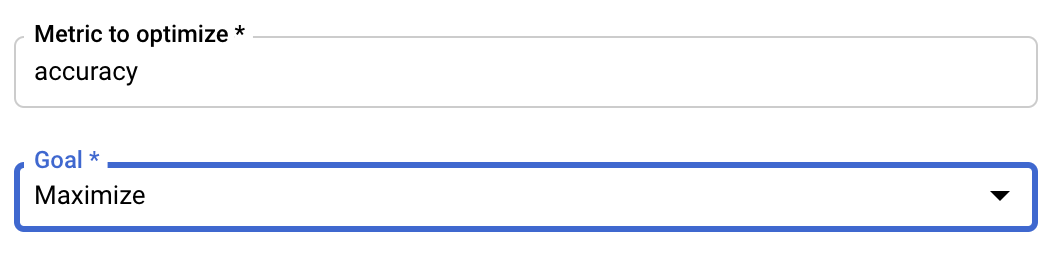
Configure Metric
After adding the hyperparameters, you'll next provide the metric you want to optimize as well as the goal. This should be the same as the hyperparameter_metric_tag you set in your training application.
The Vertex AI Hyperparameter tuning service will run multiple trials of your training application with the values configured in the previous steps. You'll need to put an upper bound on the number of trials the service will run. More trials generally leads to better results, but there will be a point of diminishing returns after which additional trials have little or no effect on the metric you're trying to optimize. It is a best practice to start with a smaller number of trials and get a sense of how impactful your chosen hyperparameters are before scaling up to a large number of trials.
You'll also need to set an upper bound on the number of parallel trials. Increasing the number of parallel trials will reduce the amount of time the hyperparameter tuning job takes to run; however, it can reduce the effectiveness of the job over all. This is because the default tuning strategy uses results of previous trials to inform the assignment of values in subsequent trials. If you run too many trials in parallel, there will be trials that start without the benefit of the result from the trials still running.
For demonstration purposes, you can set the number of trials to be 15 and the max number of parallel trials to be 3. You can experiment with different numbers, but this can result in a longer tuning time and higher cost.

The last step is to select Default as the search algorithm, which will use Google Vizier to perform Bayesian optimization for hyperparameter tuning. You can learn more about this algorithm here.
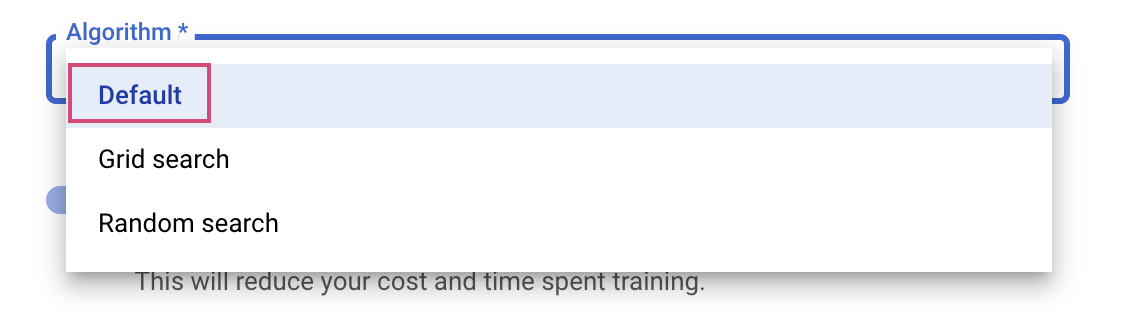
Click Continue.
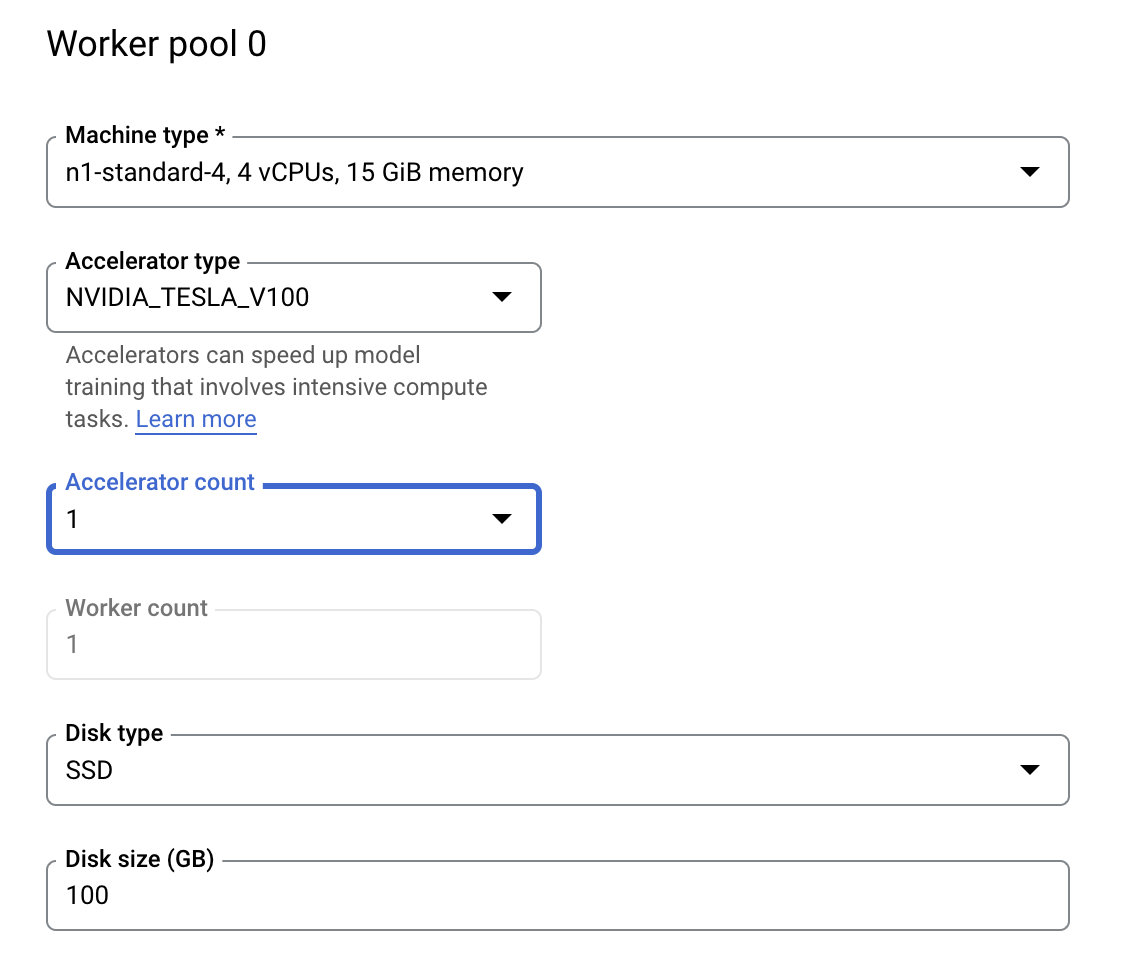
Step 3: Configure compute
In Compute and pricing, leave the selected region as-is and configure Worker pool 0 as follows.
Click Start training to kick off the hyperparameter tuning job. In the Training section of your console under the HYPERPARAMETER TUNING JOBS tab you'll see something like this:
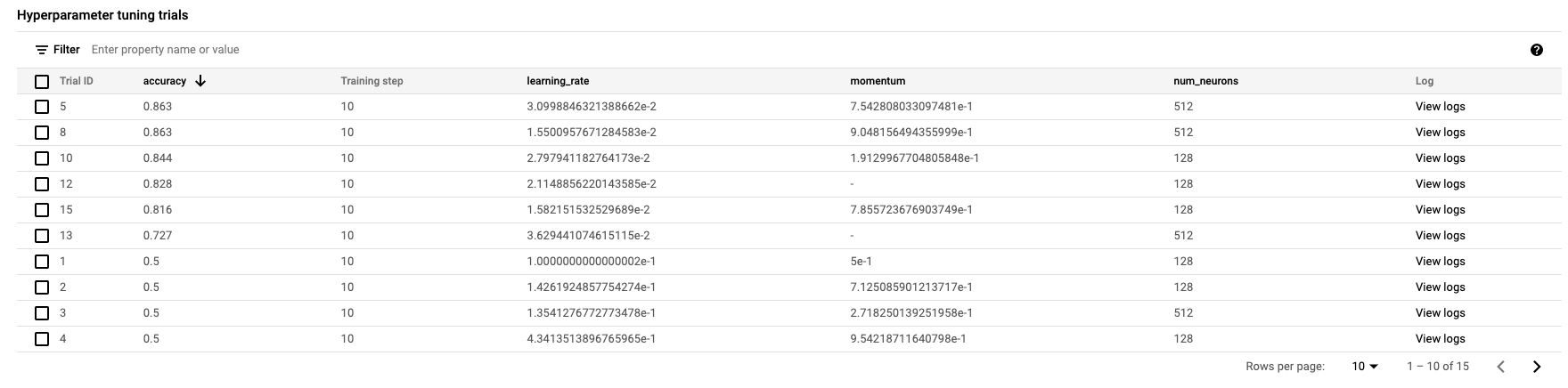
When it's finished, you'll be able to click on the job name and see the results of the tuning trials.
🎉 Congratulations! 🎉
You've learned how to use Vertex AI to:
- Launch a hyperparameter tuning job for training code provided in a custom container. You used a TensorFlow model in this example, but you can train a model built with any framework using custom containers.
To learn more about different parts of Vertex, check out the documentation.
6. [Optional] Use the Vertex SDK
The previous section showed how to launch the hyperparameter tuning job via the UI. In this section, you'll see an alternative way to submit the hyperparameter tuning job by using the Vertex Python API.
From the Launcher, create a TensorFlow 2 notebook.

Import the Vertex AI SDK.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
To launch the hyperparameter tuning job, you need to first define the following specs. You'll need to replace {PROJECT_ID} in the image_uri with your project.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Next, create a CustomJob. You'll need to replace {YOUR_BUCKET} with a bucket in your project for staging.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Then, create and run the HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Cleanup
Because we configured the notebook to time out after 60 idle minutes, we don't need to worry about shutting the instance down. If you would like to manually shut down the instance, click the Stop button on the Vertex AI Workbench section of the console. If you'd like to delete the notebook entirely, click the Delete button.

To delete the Storage Bucket, using the Navigation menu in your Cloud Console, browse to Storage, select your bucket, and click Delete: