1. Visão geral
Neste laboratório, você vai usar a Vertex AI na execução de um job de ajuste de hiperparâmetros para um modelo do TensorFlow. Embora este laboratório use o TensorFlow para o código do modelo, os conceitos também são aplicáveis a outros frameworks de ML.
Conteúdo do laboratório
Você vai aprender a:
- modificar o código do aplicativo de treinamento para ajuste do hiperparâmetro automatizado;
- configurar e iniciar um job de ajuste de hiperparâmetros usando a interface da Vertex AI;
- configurar e iniciar um job de ajuste de hiperparâmetros com o SDK da Vertex AI para Python.
O custo total para executar este laboratório no Google Cloud é de cerca de US$3.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos existentes para a Vertex AI. Se você tiver algum feedback, consulte a página de suporte.
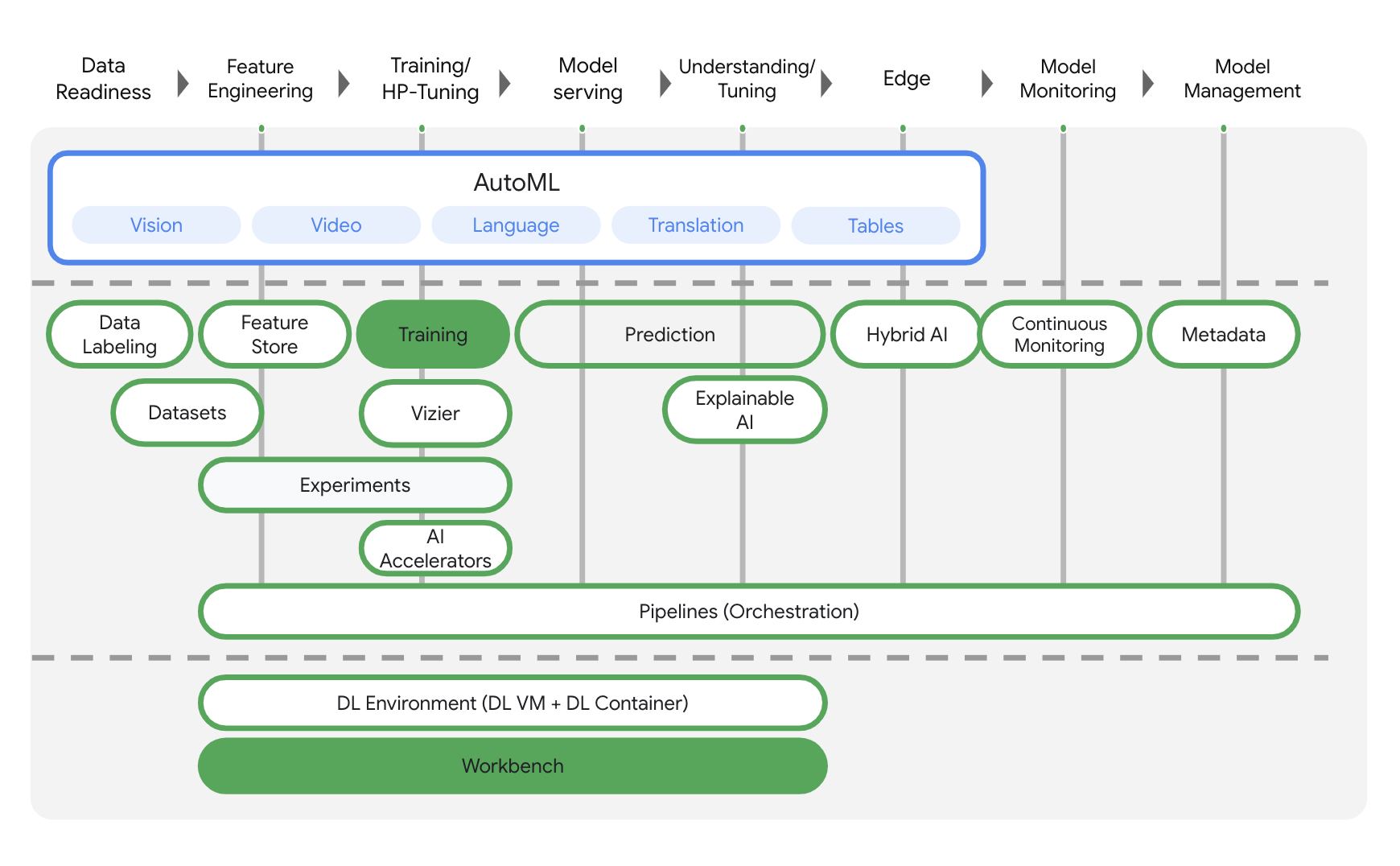
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho integrais de ML. Os produtos destacados abaixo são o foco deste laboratório: Treinamentos e Workbench.
3. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 1: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada. Você vai precisar disso para criar sua instância de notebook.
Etapa 2: ativar a API Container Registry
Navegue até o Container Registry e selecione Ativar. Use isso para criar um contêiner para seu job de treinamento personalizado.
Etapa 3: ativar a API Vertex AI
Navegue até a seção "Vertex AI" do Console do Cloud e clique em Ativar API Vertex AI.
Etapa 4: criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":
Ative a API Notebooks, se ela ainda não tiver sido ativada.
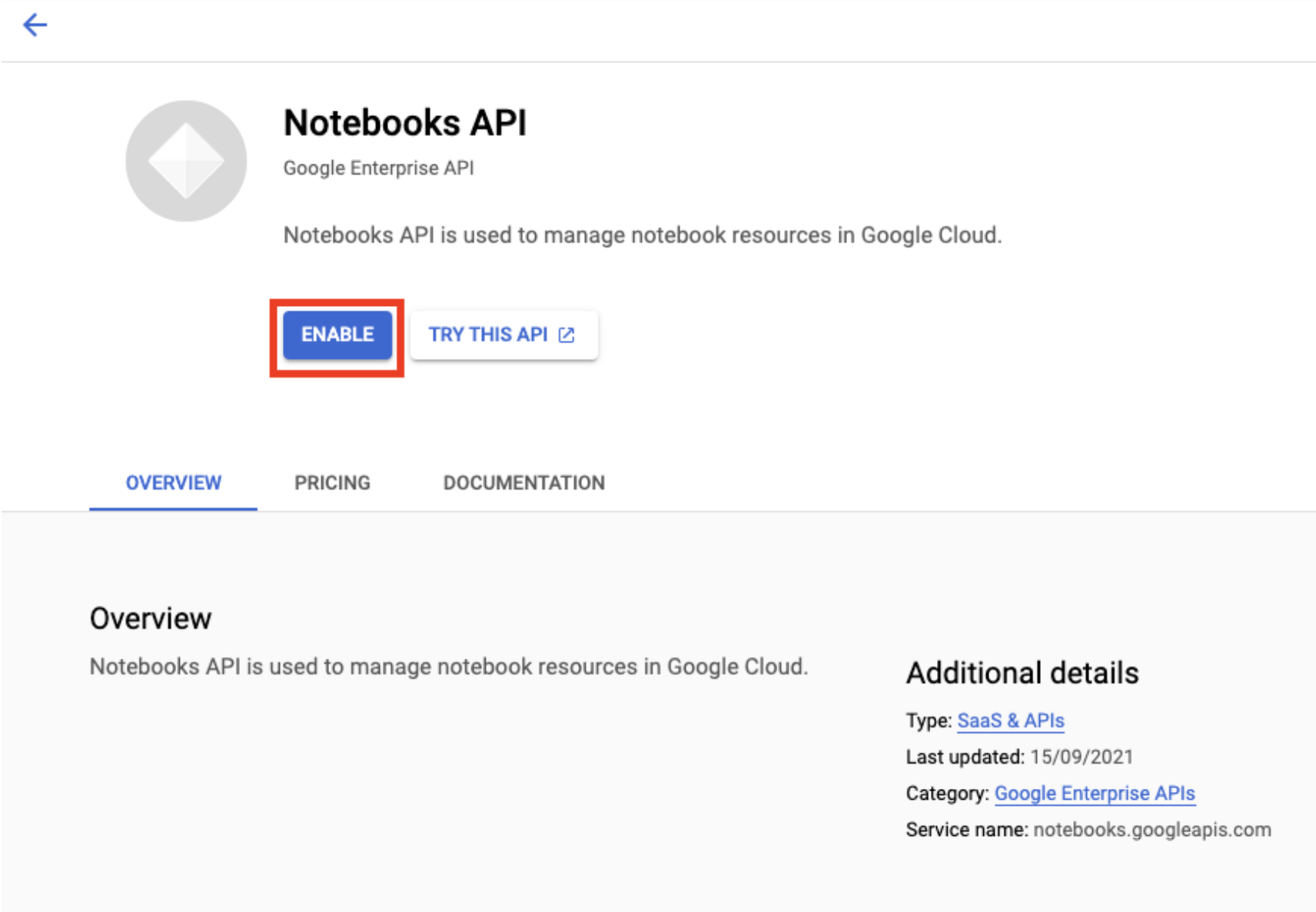
Após a ativação, clique em NOTEBOOK GERENCIADO:

Em seguida, selecione NOVO NOTEBOOK.
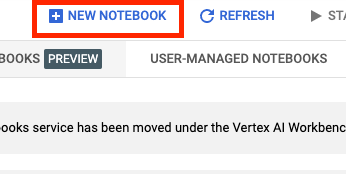
Dê um nome ao notebook e clique em Configurações avançadas.

Em "Configurações avançadas", ative o encerramento inativo e defina o número de minutos como 60. Isso significa que o notebook será desligado automaticamente quando não estiver sendo usado.

Em Segurança , selecione "Ativar terminal", se essa opção ainda não estiver ativada.
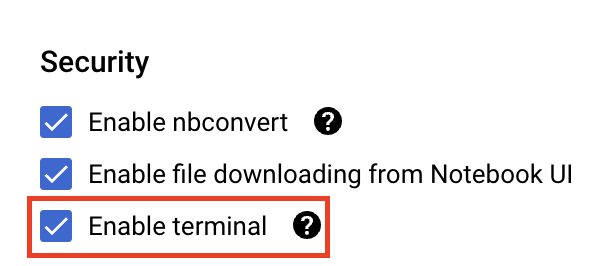
Você pode manter as outras configurações avançadas como estão.
Em seguida, clique em Criar. O provisionamento da instância vai levar alguns minutos.
Quando a instância tiver sido criada, selecione Abrir o JupyterLab.

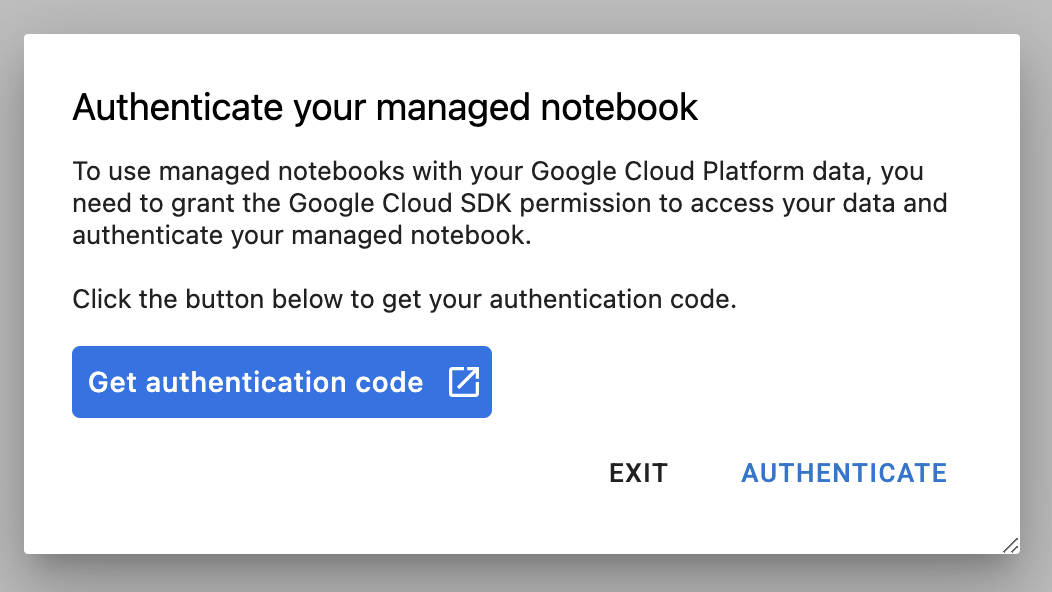
Na primeira vez que usar uma nova instância, você vai receber uma solicitação de autenticação. Siga as etapas na IU para isso.
4. fazer a conteinerização do código do aplicativo de treinamento
O modelo que você vai treinar e ajustar neste laboratório é um modelo de classificação de imagens treinado no conjunto de dados cavalos ou humanos dos conjuntos de dados do TensorFlow.
Para enviar este job de ajuste de hiperparâmetros à Vertex AI, coloque o código do aplicativo de treinamento em um contêiner do Docker e envie-o ao Google Container Registry. Dessa forma, é possível ajustar hiperparâmetros para um modelo integrado a qualquer framework.
Para começar, no menu de acesso rápido, abra uma janela de terminal na instância do notebook:

Crie um novo diretório chamado horses_or_humans e coloque cd nele:
mkdir horses_or_humans
cd horses_or_humans
Etapa 1: criar um Dockerfile
A primeira etapa na conteinerização de seu código é a criação de um Dockerfile. No Dockerfile, você vai incluir todos os comandos necessários para executar a imagem. Ele vai instalar todas as bibliotecas necessárias, incluindo a biblioteca CloudML Hypertune e também configurar o ponto de entrada para o código de treinamento.
No seu terminal, crie um Dockerfile vazio:
touch Dockerfile
Abra o Dockerfile e copie o seguinte nele:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Este Dockerfile usa a imagem do Docker do TensorFlow Enterprise 2.7 GPU no Deep Learning Container. O componente Deep Learning Containers no Google Cloud vem com vários frameworks de ciência de dados já instalados. Após fazer download dessa imagem, este Dockerfile configura o ponto de entrada para o código de treinamento. Você ainda não criou esses arquivos – na próxima etapa, você vai adicionar o código para treinar e ajustar o modelo.
Etapa 2: adicionar código de treinamento de modelo
No seu Terminal, execute o seguinte para criar um diretório para o código de treinamento e um arquivo Python onde você vai adicionar o código:
mkdir trainer
touch trainer/task.py
Agora você deve ter o seguinte no diretório horses_or_humans/:
+ Dockerfile
+ trainer/
+ task.py
Depois abra o arquivo task.py que você acabou de criar e copie o código abaixo.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Antes de criar o contêiner, vamos analisar o código mais a fundo. Existem alguns componentes específicos para usar o serviço de ajuste de hiperparâmetros.
- O script importa a biblioteca
hypertune. Note que o Dockerfile da Etapa 1 incluiu instruções para instalar esta biblioteca com o pip. - A função
get_args()define um argumento de linha de comando para cada hiperparâmetro a ser ajustado. No exemplo, os hiperparâmetros que serão ajustados são a taxa de aprendizado, o valor do momentum no optimizer e o número de unidades na última camada escondida do modelo, mas fique à vontade para testar outros. O valor transferido nesses argumentos é usado para definir o hiperparâmetro correspondente no código. - Ao final da função
main(), a bibliotecahypertuneé usada para definir a métrica a ser otimizada. No TensorFlow, o métodomodel.fitda Keras retorna um objetoHistory. O atributoHistory.historyé um registro de valores de perda de treinamento e de valores de métricas em épocas sucessivas. Se você transmitir os dados de validação paramodel.fit, o atributoHistory.historyvai incluir também valores de perda de validação e de métricas. Por exemplo, se você treinar um modelo para três épocas com dados de validação e informaraccuracycomo a métrica, o atributoHistory.historyserá semelhante ao dicionário a seguir.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Se você quiser que o serviço de ajuste de hiperparâmetros descubra os valores que maximizam a acurácia da validação do modelo, defina a métrica como a última entrada (ou NUM_EPOCS - 1) da lista val_accuracy. Em seguida, transfira essa métrica para uma instância do HyperTune. É possível escolher qualquer string para o argumento hyperparameter_metric_tag, mas será preciso usar a string novamente, quando você iniciar o job de ajuste de hiperparâmetros.
Etapa 3: criar o contêiner
No Terminal, execute o comando a seguir e defina uma variável env para o projeto. Lembre-se de substituir your-cloud-project pelo ID do projeto.
PROJECT_ID='your-cloud-project'
Defina uma variável com o URI da imagem do contêiner no Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Configure o Docker.
gcloud auth configure-docker
Em seguida, crie o contêiner executando o seguinte comando na raiz do diretório horses_or_humans:
docker build ./ -t $IMAGE_URI
Por fim, envie para o Google Container Registry:
docker push $IMAGE_URI
Depois que o contêiner for enviado para o Container Registry, estará tudo pronto para iniciar um job de ajuste de hiperparâmetros de modelos personalizados.
5. Execute um job de ajuste de hiperparâmetros na Vertex AI
Este laboratório usa treinamento personalizado com um contêiner específico no Google Container Registry, mas também é possível executar um job de ajuste de hiperparâmetros com um contêiner pré-criado da Vertex AI.
Para começar, navegue até a seção Treinamento na seção da Vertex do console do Cloud:
Etapa 1: configurar job de treinamento
Clique em Criar para inserir os parâmetros para seu job de ajuste de hiperparâmetros.
- Em Conjunto de dados, selecione Sem conjunto de dados gerenciado.
- Selecione Treinamento personalizado (avançado) como seu método de treinamento e clique em Continuar.
- Insira
horses-humans-hyptertune(ou como quiser nomear seu modelo) em Nome do modelo. - Clique em Continuar.
Na etapa "Configurações do contêiner", selecione Container personalizado:

Na primeira caixa (Imagem do contêiner), insira o valor da sua variável IMAGE_URI da seção anterior. Ela precisa ser: gcr.io/your-cloud-project/horse-human:hypertune, com o nome do seu projeto. Deixe os demais campos em branco e clique em Continuar.
Etapa 2: configurar o job de ajuste de hiperparâmetros
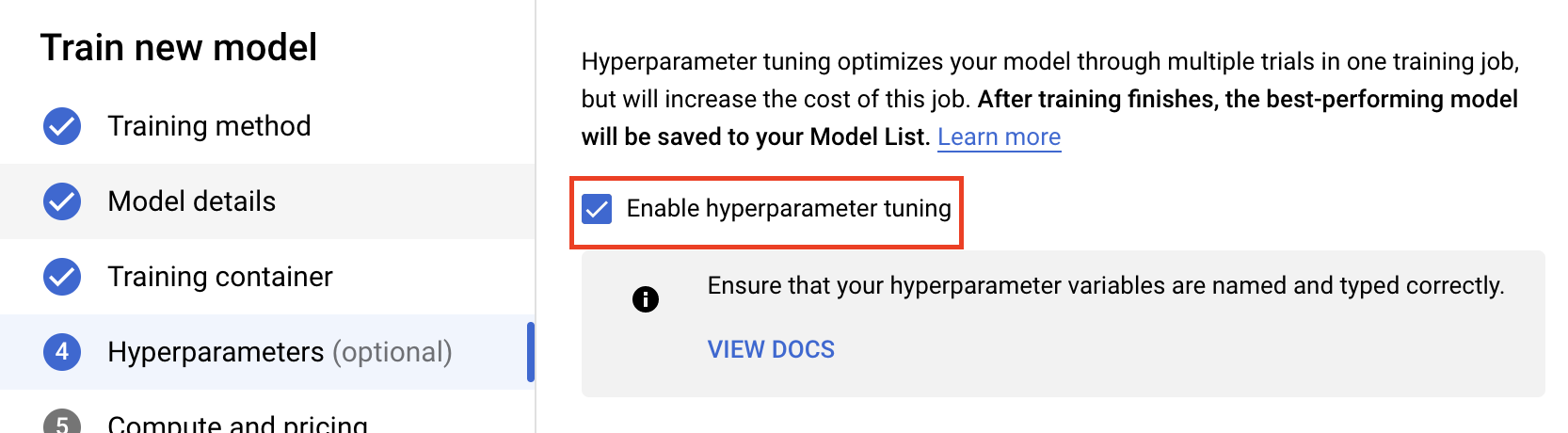
Selecione Ativar ajuste de hiperparâmetros.
Configure os hiperparâmetros
Em seguida, você vai precisar adicionar os hiperparâmetros definidos como argumentos de linha de comando no código do aplicativo de treinamento. Ao adicionar um hiperparâmetro, primeiro você vai precisar fornecer o nome. Ele deve corresponder ao nome do argumento que você passou para argparse.

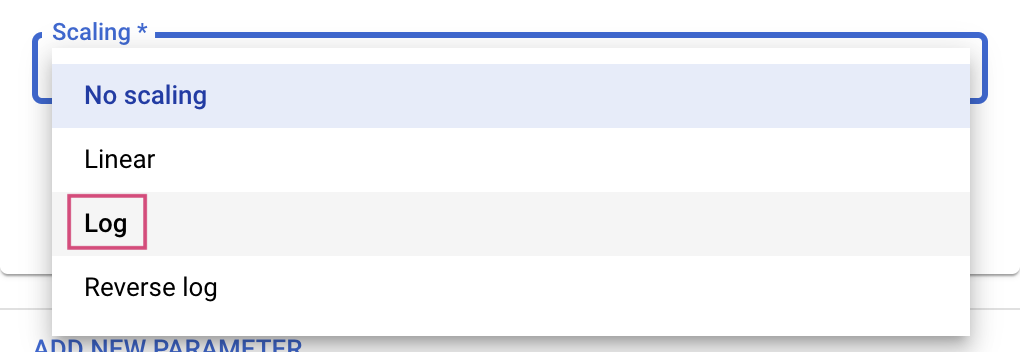
Em seguida, selecione o tipo e os limites dos valores que o serviço de ajuste vai tentar. Se você selecionar o tipo "Duplo" ou "Inteiro", vai precisar fornecer um valor mínimo e máximo. E, se você selecionar "Categórico" ou "Discreto", vai ter que fornecer os valores.


Para os tipos duplo e inteiro, você também precisa fornecer o valor de escalonamento.
Depois de adicionar o hiperparâmetro learning_rate, adicione parâmetros para momentum e num_units.


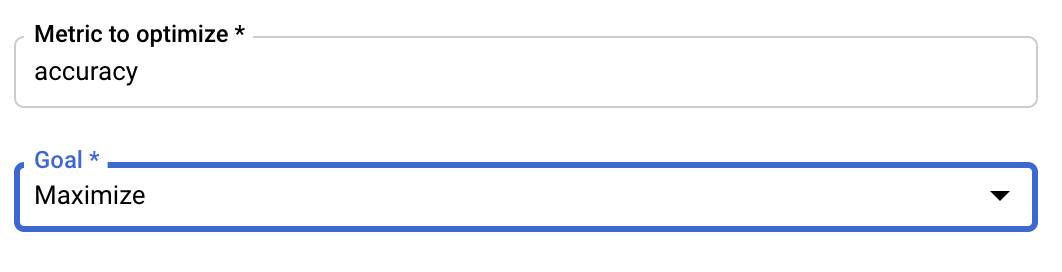
Configure a métrica
Depois de adicionar os hiperparâmetros, você vai fornecer a métrica que quer otimizar, e também a meta. Isso deve ser igual à hyperparameter_metric_tag que você configurou no seu aplicativo de treinamento.
O serviço de ajuste de hiperparâmetros da Vertex AI vai executar diversas avaliações do seu aplicativo de treinamento com os valores configurados nas etapas anteriores. Você vai precisar definir um limite superior para o número de tentativas que o serviço vai executar. Uma maior quantidade de testes geralmente leva a melhores resultados, mas vai haver um ponto de retornos decrescentes e, depois dele, testes adicionais vão ter pouco ou nenhum efeito sobre a métrica que você está tentando otimizar. É uma prática recomendada começar com um número menor de testes e ter uma noção do impacto dos hiperparâmetros escolhidos antes de escalonar verticalmente para um grande número de testes.
Você também vai precisar definir um limite superior para o número de tentativas paralelas. Aumentar o número de testes paralelos vai reduzir o tempo que o job de ajuste de hiperparâmetros leva para ser executado. No entanto, isso pode reduzir a eficácia do job em geral. Isso ocorre porque a estratégia de ajuste padrão usa resultados de tentativas anteriores para informar a atribuição de valores em tentativas subsequentes. Se você executar muitos testes em paralelo, vai haver testes que vão começar sem o benefício do resultado dos testes ainda em execução.
Para fins de demonstração, é possível definir o número de testes como 15 e o número máximo de testes paralelos como 3. É possível usar números diferentes, mas isso pode resultar em um tempo de ajuste mais longo e em custos mais altos.

A última etapa é selecionar "Padrão" como o algoritmo de pesquisa, que vai usar o Google Vizier para realizar a otimização bayesiana para o ajuste de hiperparâmetros. Você pode saber mais sobre este algoritmo aqui.

Clique em Continuar.
Etapa 3: configurar a computação
Em Computação e preços, deixe a região selecionada como está e configure o Pool de workers 0 da seguinte forma.
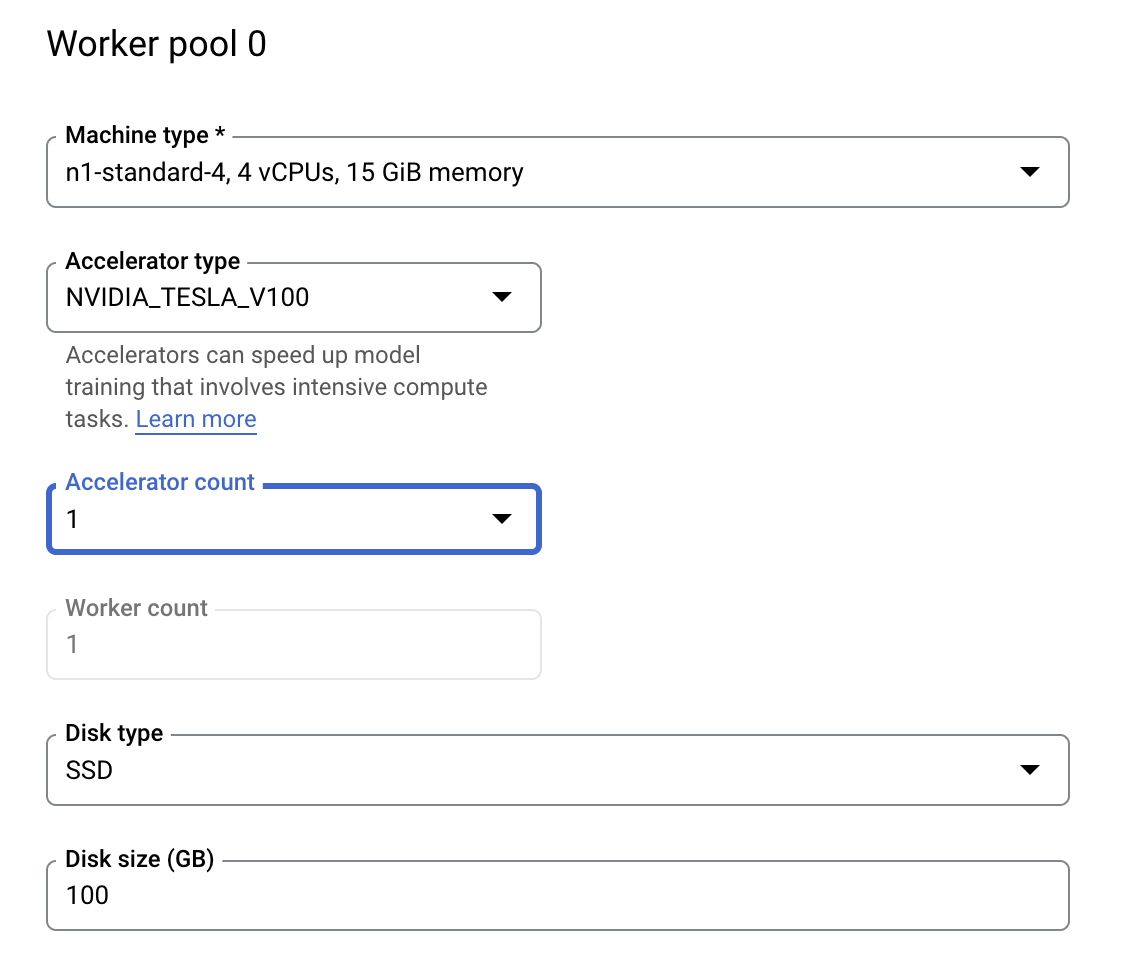
Clique em Iniciar treinamento para iniciar o job de ajuste de hiperparâmetros. Na seção de Treinamento do seu console, na guia de JOBS DE AJUSTE DE HIPERPARÂMETROS você vai ver algo assim:
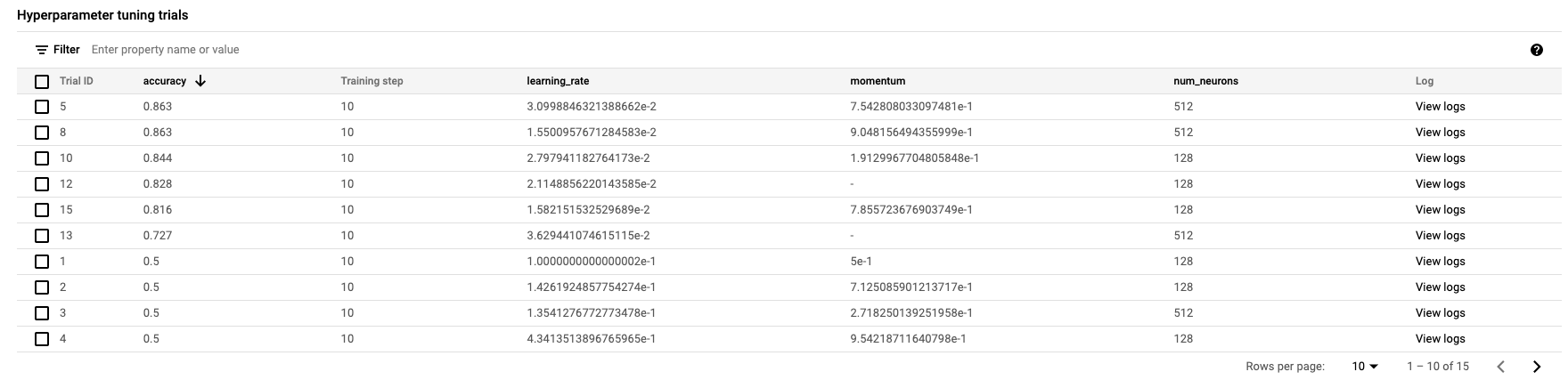
Quando estiver concluído, você poderá clicar no nome do job e conferir os resultados dos testes de ajuste.
Parabéns! 🎉
Você aprendeu a usar a Vertex AI para:
- Iniciar um job de ajuste de hiperparâmetros para um código de treinamento fornecido em um contêiner personalizado. Neste exemplo, você usou um modelo do TensorFlow, mas é possível treinar um modelo criado com qualquer framework usando contêineres personalizados.
Para saber mais sobre as diferentes partes da Vertex, consulte a documentação.
6. use o SDK Vertex [Opcional]
A seção anterior mostrou como lançar o job de ajuste de hiperparâmetros na IU. Nesta seção, você vai ver uma forma alternativa de enviar o job de ajuste de hiperparâmetro usando a API Python do Vertex.
Na tela de início, crie um notebook do TensorFlow 2.

Importe o SDK da Vertex AI.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Para lançar o job de ajuste de hiperparâmetro, você precisa primeiro definir as etapas a seguir. Será necessário substituir {PROJECT_ID} no image_uri pelo seu projeto.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Em seguida, crie um CustomJob. Você vai precisar substituir {YOUR_BUCKET} com um bucket no seu projeto para o preparo.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Em seguida, crie e execute o HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Limpeza
Como configuramos o notebook para expirar após 60 minutos de inatividade, não precisamos nos preocupar em desligar a instância. Para encerrar a instância manualmente, clique no botão "Parar" na seção "Vertex AI Workbench" do console. Se quiser excluir o notebook completamente, clique no botão "Excluir".

Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em "Excluir":