เกี่ยวกับ Codelab นี้
1 ภาพรวม
ในชั้นเรียนนี้ คุณจะใช้ Vertex AI เพื่อเรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์สําหรับโมเดล TensorFlow แม้ว่าห้องทดลองนี้ใช้ TensorFlow สำหรับโค้ดโมเดล แต่แนวคิดดังกล่าวก็นำมาใช้กับเฟรมเวิร์ก ML อื่นๆ ได้เช่นกัน
สิ่งที่ได้เรียนรู้
โดยคุณจะได้เรียนรู้วิธีต่อไปนี้
- แก้ไขโค้ดแอปพลิเคชันการฝึกอบรมสำหรับการปรับแต่งไฮเปอร์พารามิเตอร์อัตโนมัติ
- กำหนดค่าและเปิดงานการปรับแต่งไฮเปอร์พารามิเตอร์จาก Vertex AI UI
- กำหนดค่าและเปิดงานการปรับแต่งไฮเปอร์พารามิเตอร์ด้วย Vertex AI Python SDK
ค่าใช้จ่ายรวมในการเรียกใช้ห้องทดลองนี้ใน Google Cloud อยู่ที่ประมาณ $3 USD
2 ข้อมูลเบื้องต้นเกี่ยวกับ Vertex AI
ห้องทดลองนี้ใช้ข้อเสนอผลิตภัณฑ์ AI ใหม่ล่าสุดที่มีให้บริการใน Google Cloud Vertex AI ผสานรวมข้อเสนอ ML ใน Google Cloud เข้ากับประสบการณ์การพัฒนาที่ราบรื่น ก่อนหน้านี้โมเดลที่ฝึกด้วย AutoML และโมเดลที่กำหนดเองจะเข้าถึงได้ผ่านบริการแยกต่างหาก ข้อเสนอใหม่จะรวมทั้ง 2 อย่างไว้ใน API เดียว รวมทั้งผลิตภัณฑ์ใหม่อื่นๆ นอกจากนี้ คุณยังย้ายข้อมูลโปรเจ็กต์ที่มีอยู่ไปยัง Vertex AI ได้ด้วย หากมีความคิดเห็น โปรดดูหน้าการสนับสนุน
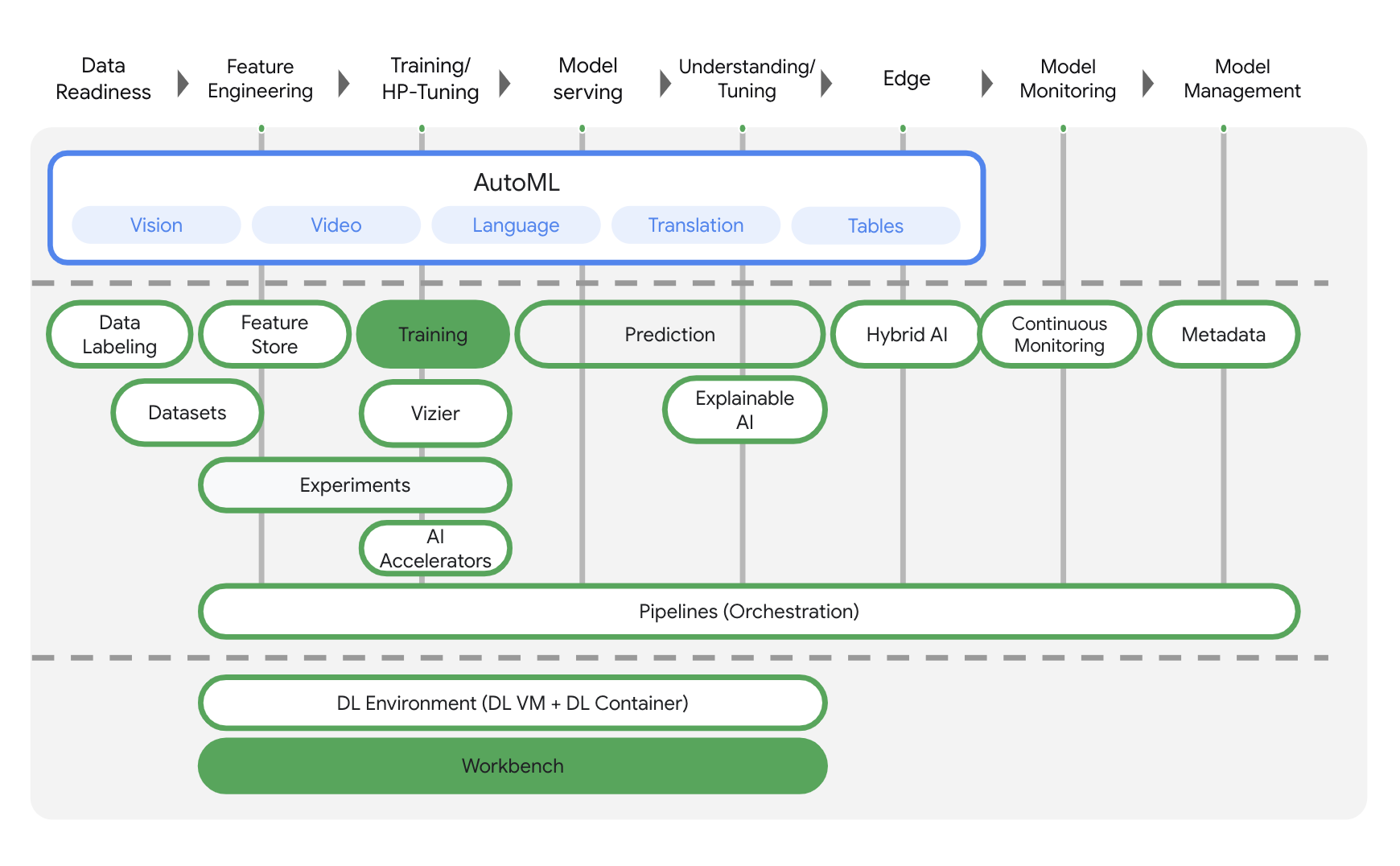
Vertex AI มีผลิตภัณฑ์ต่างๆ มากมายเพื่อรองรับเวิร์กโฟลว์ ML แบบครบวงจร ห้องทดลองนี้จะมุ่งเน้นที่ผลิตภัณฑ์ที่ไฮไลต์ไว้ด้านล่าง ได้แก่ การฝึกอบรมและ Workbench
3 ตั้งค่าสภาพแวดล้อมของคุณ
คุณจะต้องมีโปรเจ็กต์ Google Cloud Platform ที่เปิดใช้การเรียกเก็บเงินเพื่อเรียกใช้โค้ดแล็บนี้ หากต้องการสร้างโปรเจ็กต์ ให้ทำตามวิธีการที่นี่
ขั้นตอนที่ 1: เปิดใช้ Compute Engine API
ไปที่ Compute Engine แล้วเลือกเปิดใช้หากยังไม่ได้เปิดใช้ ซึ่งคุณจะต้องใช้ในการสร้างอินสแตนซ์สมุดบันทึก
ขั้นตอนที่ 2: เปิดใช้ Container Registry API
ไปที่ Container Registry แล้วเลือกเปิดใช้ หากยังไม่ได้เปิดใช้ คุณจะใช้ข้อมูลนี้เพื่อสร้างคอนเทนเนอร์สำหรับงานการฝึกที่กำหนดเอง
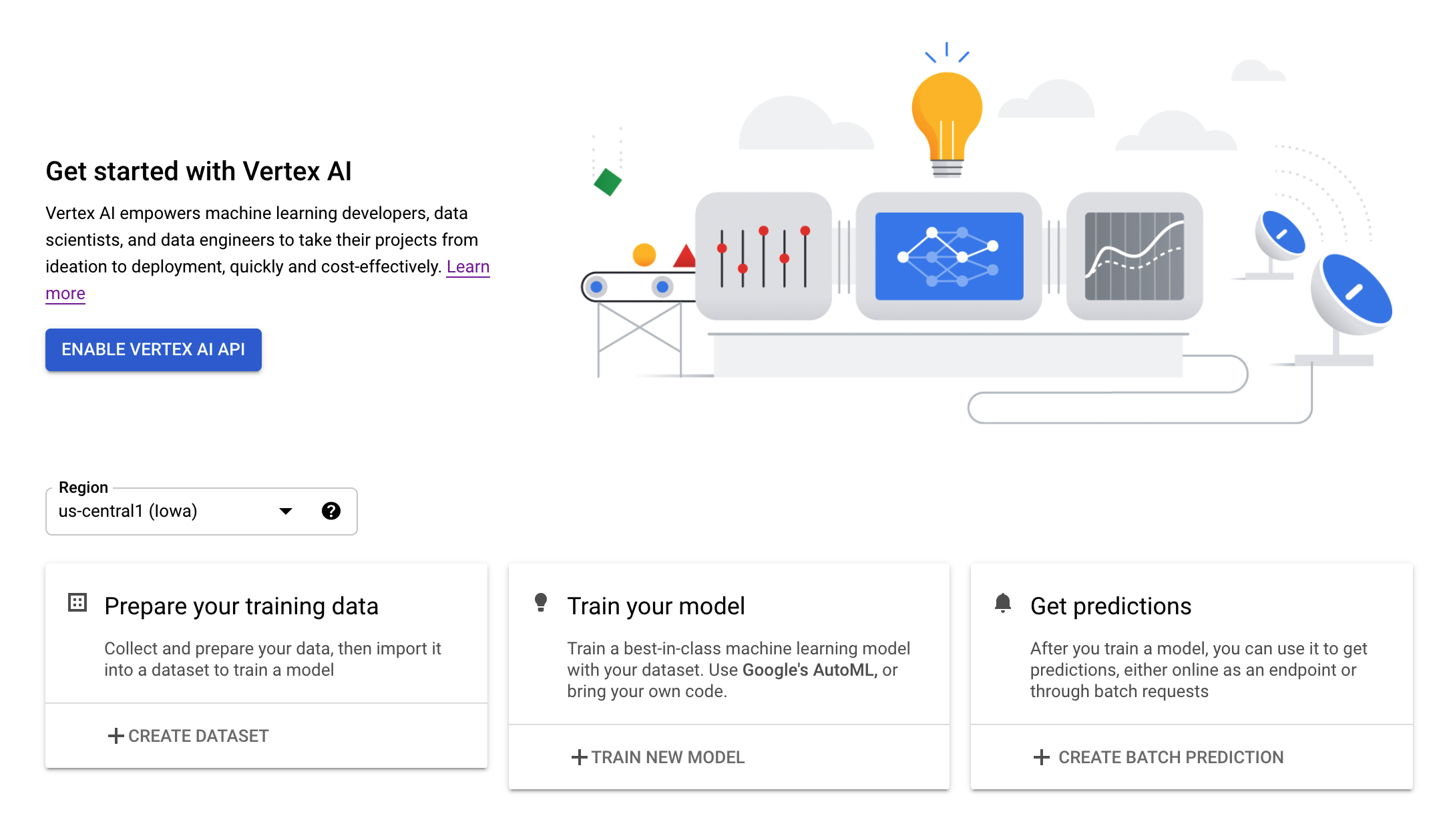
ขั้นตอนที่ 3: เปิดใช้ Vertex AI API
ไปที่ส่วน Vertex AI ของ Cloud Console แล้วคลิกเปิดใช้ Vertex AI API
ขั้นตอนที่ 4: สร้างอินสแตนซ์ Vertex AI Workbench
จากส่วน Vertex AI ของ Cloud Console ให้คลิก Workbench
เปิดใช้ Notebooks API หากยังไม่ได้เปิดใช้
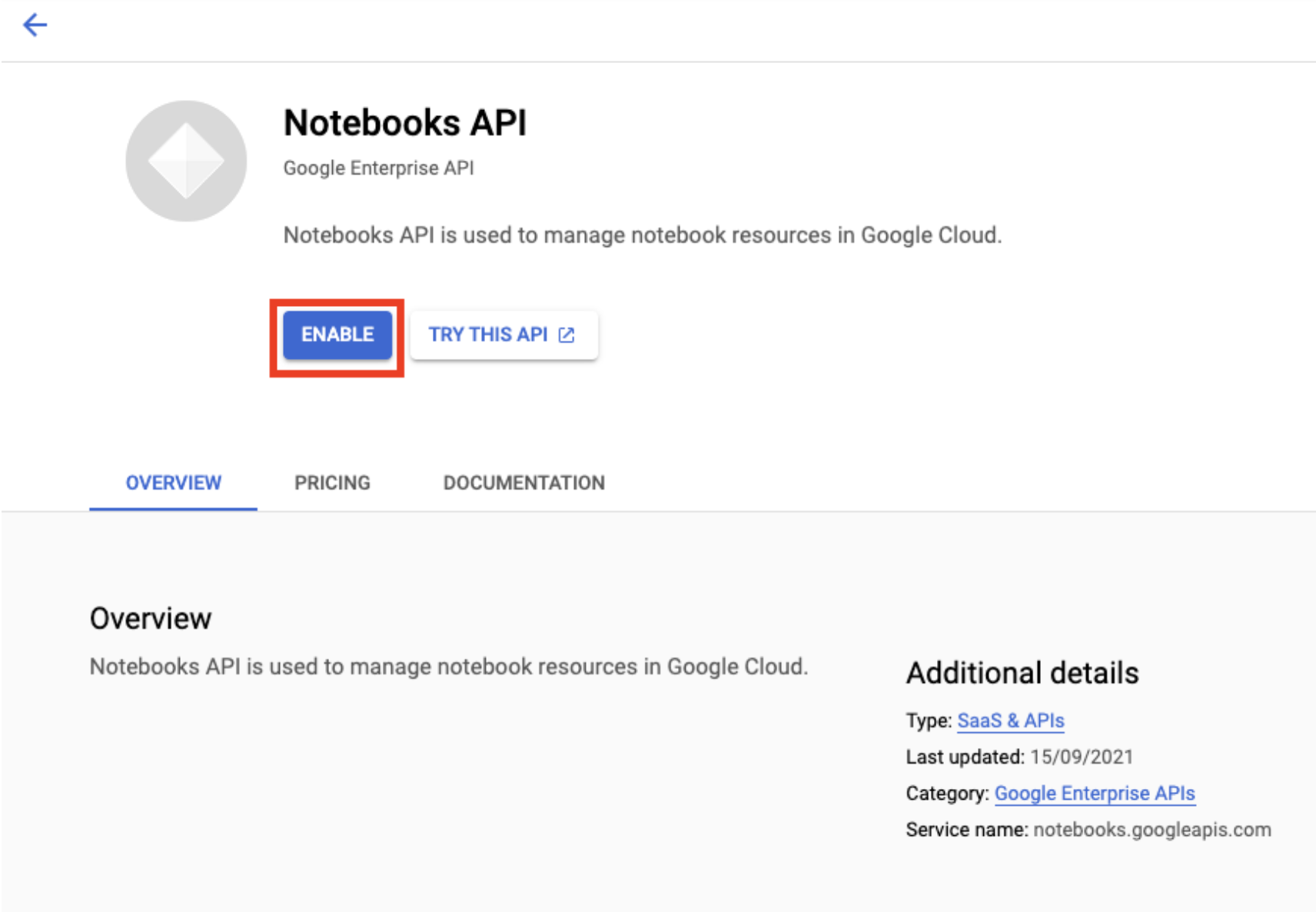
เมื่อเปิดใช้แล้ว ให้คลิกสมุดบันทึกที่มีการจัดการ

จากนั้นเลือกสมุดบันทึกใหม่
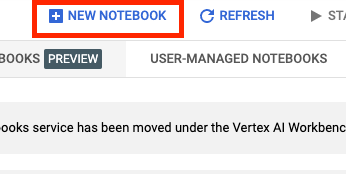
ตั้งชื่อสมุดบันทึก แล้วคลิกการตั้งค่าขั้นสูง

ภายใต้การตั้งค่าขั้นสูง ให้เปิดใช้การปิดเมื่อไม่มีการใช้งาน และตั้งค่าจำนวนนาทีเป็น 60 ซึ่งหมายความว่าสมุดบันทึกจะปิดโดยอัตโนมัติเมื่อไม่ได้ใช้งาน คุณจึงไม่จำเป็นต้องมีค่าใช้จ่ายที่ไม่จำเป็น

ในส่วนความปลอดภัย ให้เลือก "เปิดใช้เทอร์มินัล" หากยังไม่ได้เปิดใช้
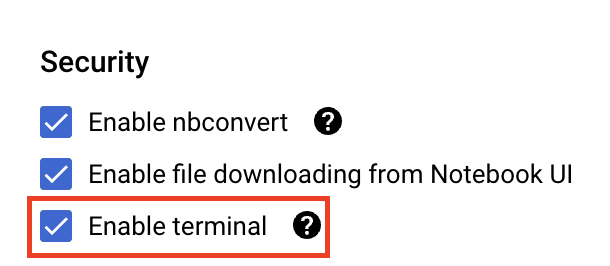
คุณปล่อยการตั้งค่าขั้นสูงอื่นๆ ทั้งหมดไว้ตามเดิมได้
จากนั้นคลิกสร้าง การจัดสรรอินสแตนซ์จะใช้เวลา 2-3 นาที
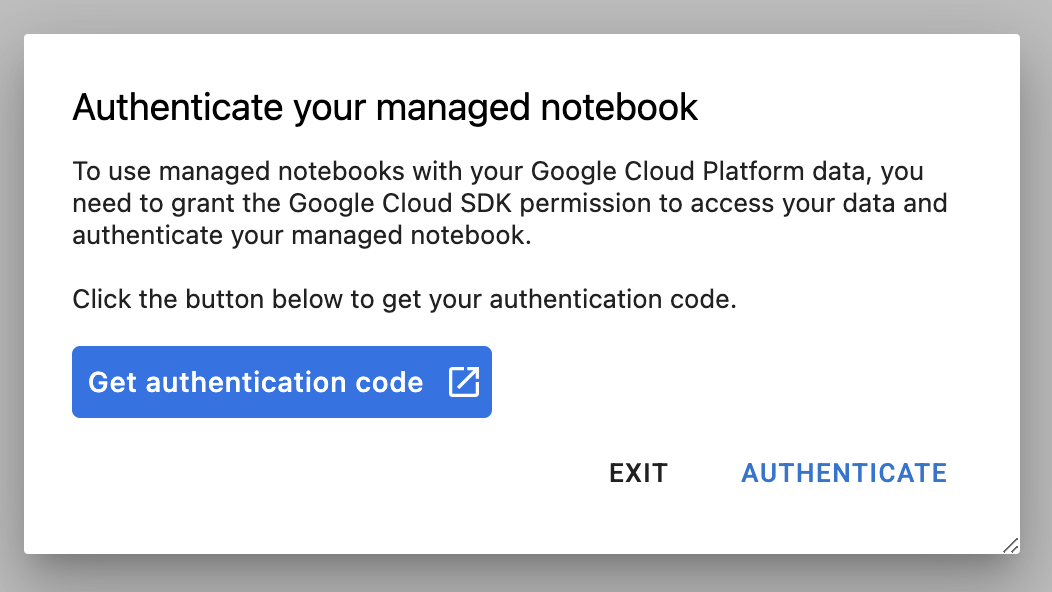
เมื่อสร้างอินสแตนซ์แล้ว ให้เลือก Open JupyterLab

ครั้งแรกที่คุณใช้อินสแตนซ์ใหม่ ระบบจะขอให้คุณตรวจสอบสิทธิ์ ทําตามขั้นตอนใน UI
4 สร้างคอนเทนเนอร์โค้ดแอปพลิเคชันการฝึก
โมเดลที่คุณจะฝึกและปรับแต่งในห้องทดลองนี้เป็นโมเดลการจัดประเภทอิมเมจที่ได้รับการฝึกบนชุดข้อมูลม้าหรือมนุษย์จากชุดข้อมูล TensorFlow
คุณจะส่งงานการปรับแต่งไฮเปอร์พารามิเตอร์นี้ไปยัง Vertex AI โดยการวางโค้ดแอปพลิเคชันการฝึกในคอนเทนเนอร์ Docker และพุชคอนเทนเนอร์นี้ไปยัง Google Container Registry เมื่อใช้วิธีการนี้ คุณสามารถปรับแต่งไฮเปอร์พารามิเตอร์สำหรับโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้
ในการเริ่มต้น จากเมนู Launcher ให้เปิดหน้าต่างเทอร์มินัลในอินสแตนซ์สมุดบันทึก โดยทำดังนี้

สร้างไดเรกทอรีใหม่ชื่อ horses_or_humans และเข้ารหัสลงในไดเรกทอรีดังกล่าว:
mkdir horses_or_humans
cd horses_or_humans
ขั้นตอนที่ 1: สร้าง Dockerfile
ขั้นตอนแรกในการสร้างคอนเทนเนอร์โค้ดคือการสร้าง Dockerfile คุณจะต้องรวมคำสั่งทั้งหมดที่จำเป็นในการเรียกใช้อิมเมจใน Dockerfile ซึ่งจะติดตั้งไลบรารีที่จำเป็นทั้งหมด รวมถึงไลบรารี CloudML Hypertune และตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึก
สร้าง Dockerfile เปล่าจากเทอร์มินัล โดยทำดังนี้
touch Dockerfile
เปิด Dockerfile และคัดลอกไฟล์ต่อไปนี้ลงในไฟล์
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Dockerfile นี้ใช้อิมเมจ Docker ของ Deep Learning สำหรับคอนเทนเนอร์ TensorFlow Enterprise 2.7 คอนเทนเนอร์การเรียนรู้เชิงลึกใน Google Cloud มาพร้อมกับเฟรมเวิร์ก ML และวิทยาการข้อมูลทั่วไปที่ติดตั้งไว้ล่วงหน้าหลายรายการ หลังจากดาวน์โหลดอิมเมจดังกล่าว Dockerfile นี้จะตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึก คุณยังไม่ได้สร้างไฟล์เหล่านี้ ในขั้นตอนถัดไป คุณจะต้องเพิ่มโค้ดสำหรับการฝึกและปรับแต่งโมเดล
ขั้นตอนที่ 2: เพิ่มโค้ดการฝึกโมเดล
จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างไดเรกทอรีสำหรับโค้ดการฝึกและไฟล์ Python สำหรับเพิ่มโค้ด
mkdir trainer
touch trainer/task.py
ตอนนี้คุณควรมีสิ่งต่อไปนี้ในไดเรกทอรี horses_or_humans/
+ Dockerfile
+ trainer/
+ task.py
จากนั้นให้เปิดไฟล์ task.py ที่คุณเพิ่งสร้างและคัดลอกโค้ดด้านล่าง
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
ก่อนที่จะสร้างคอนเทนเนอร์ เรามาเจาะลึกโค้ดกัน มีคอมโพเนนต์ที่เฉพาะเจาะจงสำหรับการใช้บริการปรับแต่งไฮเปอร์พารามิเตอร์บางส่วน
- สคริปต์จะนำเข้าไลบรารี
hypertuneโปรดทราบว่า Dockerfile จากขั้นตอนที่ 1 มีคำแนะนำในการติดตั้งไลบรารีนี้แบบ PIP - ฟังก์ชัน
get_args()จะกำหนดอาร์กิวเมนต์บรรทัดคำสั่งสำหรับไฮเปอร์พารามิเตอร์แต่ละรายการที่คุณต้องการปรับแต่ง ในตัวอย่างนี้ ไฮเปอร์พารามิเตอร์ที่จะปรับแต่งคืออัตราการเรียนรู้ ค่าโมเมนตัมในเครื่องมือเพิ่มประสิทธิภาพ และจำนวนหน่วยในเลเยอร์ที่ซ่อนอยู่สุดท้ายของโมเดล แต่คุณสามารถทดลองกับผู้อื่นได้ จากนั้นระบบจะนำค่าที่ส่งผ่านในอาร์กิวเมนต์เหล่านั้นมาใช้ตั้งค่าไฮเปอร์พารามิเตอร์ที่เกี่ยวข้องในโค้ด - ในตอนท้ายของฟังก์ชัน
main()ไลบรารีhypertuneจะใช้เพื่อกำหนดเมตริกที่คุณต้องการเพิ่มประสิทธิภาพ ใน TensorFlow เมธอด kerasmodel.fitจะแสดงผลออบเจ็กต์Historyแอตทริบิวต์History.historyคือระเบียนของค่าการสูญเสียการฝึกและค่าเมตริกที่ Epoch ต่อเนื่อง หากคุณส่งข้อมูลการตรวจสอบไปยังmodel.fitแอตทริบิวต์History.historyจะรวมค่าการสูญหายของการตรวจสอบและค่าเมตริกไว้ด้วย เช่น หากฝึกโมเดลสำหรับ 3 Epoch ด้วยข้อมูลการตรวจสอบ และระบุaccuracyเป็นเมตริก แอตทริบิวต์History.historyจะมีลักษณะคล้ายกับพจนานุกรมต่อไปนี้
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
หากต้องการให้บริการปรับแต่งไฮเปอร์พารามิเตอร์ค้นพบค่าที่จะเพิ่มความแม่นยำในการตรวจสอบของโมเดลให้ได้สูงสุด คุณจะต้องกำหนดเมตริกให้เป็นรายการสุดท้าย (หรือ NUM_EPOCS - 1) ของรายการ val_accuracy จากนั้น ส่งเมตริกนี้ไปยังอินสแตนซ์ HyperTune คุณเลือกสตริงใดก็ได้ที่ต้องการสำหรับ hyperparameter_metric_tag แต่จะต้องใช้สตริงอีกครั้งในภายหลังเมื่อเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์
ขั้นตอนที่ 3: สร้างคอนเทนเนอร์
จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อกำหนดตัวแปร env สำหรับโปรเจ็กต์ของคุณ และแทนที่ your-cloud-project ด้วยรหัสโปรเจ็กต์ของคุณ
PROJECT_ID='your-cloud-project'
กำหนดตัวแปรด้วย URI ของอิมเมจคอนเทนเนอร์ใน Google Container Registry ดังนี้
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
กำหนดค่า Docker
gcloud auth configure-docker
จากนั้นสร้างคอนเทนเนอร์โดยเรียกใช้คำสั่งต่อไปนี้จากรูทของไดเรกทอรี horses_or_humans
docker build ./ -t $IMAGE_URI
สุดท้าย พุชไปยัง Google Container Registry ดังนี้
docker push $IMAGE_URI
เมื่อพุชคอนเทนเนอร์ไปยัง Container Registry แล้ว คุณก็พร้อมที่จะเริ่มต้นงานการปรับแต่งไฮเปอร์พารามิเตอร์ของโมเดลที่กำหนดเองแล้ว
5 เรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ใน Vertex AI
ห้องทดลองนี้ใช้การฝึกแบบกำหนดเองผ่านคอนเทนเนอร์ที่กำหนดเองใน Google Container Registry แต่คุณยังเรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ด้วยคอนเทนเนอร์ที่สร้างไว้ล่วงหน้าของ Vertex AI ได้ด้วย
เริ่มต้นด้วยการไปที่ส่วนการฝึกในส่วน Vertex ของ Cloud Console โดยทำดังนี้
ขั้นตอนที่ 1: กำหนดค่างานการฝึก
คลิกสร้างเพื่อป้อนพารามิเตอร์สำหรับงานการปรับแต่งไฮเปอร์พารามิเตอร์
- ในส่วนชุดข้อมูล ให้เลือกไม่มีชุดข้อมูลที่มีการจัดการ
- จากนั้นเลือกการฝึกแบบกำหนดเอง (ขั้นสูง) เป็นวิธีการฝึก แล้วคลิกต่อไป
- ป้อน
horses-humans-hyptertune(หรืออะไรก็ตามที่ต้องการเรียกโมเดลของคุณ) สำหรับชื่อโมเดล - คลิกต่อไป
ในขั้นตอนการตั้งค่าคอนเทนเนอร์ ให้เลือกคอนเทนเนอร์ที่กำหนดเอง ดังนี้

ในช่องแรก (รูปภาพคอนเทนเนอร์) ให้ป้อนค่าตัวแปร IMAGE_URI จากส่วนก่อนหน้า ซึ่งควรเป็น: gcr.io/your-cloud-project/horse-human:hypertune พร้อมชื่อโปรเจ็กต์ของคุณเอง เว้นช่องที่เหลือว่างไว้และคลิกดำเนินการต่อ
ขั้นตอนที่ 2: กำหนดค่างานการปรับแต่งไฮเปอร์พารามิเตอร์
เลือกเปิดใช้การปรับแต่งไฮเปอร์พารามิเตอร์
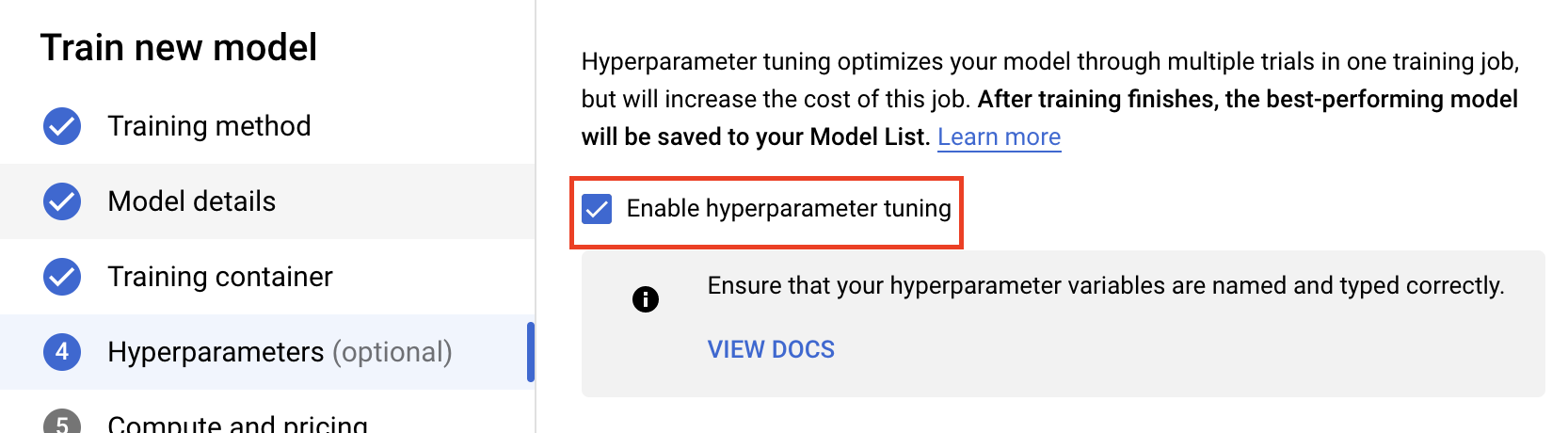
กำหนดค่าไฮเปอร์พารามิเตอร์
ถัดไป คุณจะต้องเพิ่มไฮเปอร์พารามิเตอร์ที่คุณตั้งค่าเป็นอาร์กิวเมนต์บรรทัดคำสั่งในโค้ดแอปพลิเคชันการฝึก เมื่อเพิ่มไฮเปอร์พารามิเตอร์ คุณจะต้องระบุชื่อก่อน ชื่อนี้ควรตรงกับชื่ออาร์กิวเมนต์ที่คุณส่งไปยัง argparse

จากนั้นเลือก "ประเภท" และขอบเขตของค่าที่บริการปรับแต่งจะลองใช้ หากคุณเลือกประเภท "ดับเบิล" หรือ "จำนวนเต็ม" คุณจะต้องระบุค่าต่ำสุดและสูงสุด และถ้าคุณเลือกเชิงหมวดหมู่หรือแยก คุณจะต้องกำหนดค่า


สำหรับประเภทเลขคู่และจำนวนเต็ม คุณจะต้องระบุค่าการปรับขนาดด้วย
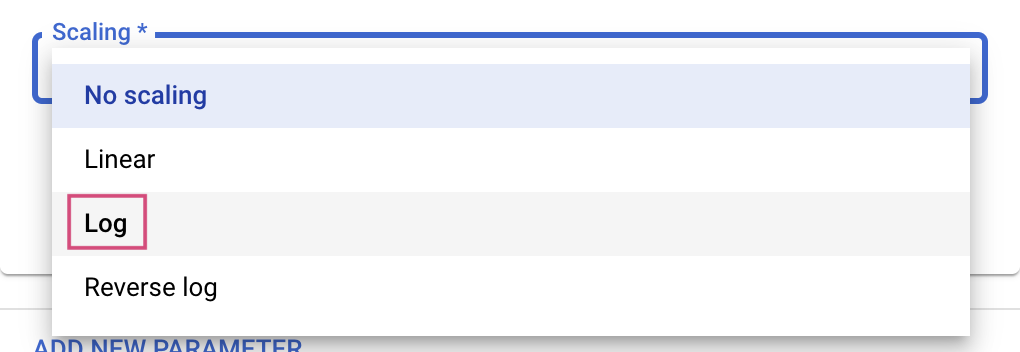
หลังจากเพิ่มไฮเปอร์พารามิเตอร์ learning_rate ให้เพิ่มพารามิเตอร์สำหรับ momentum และ num_units


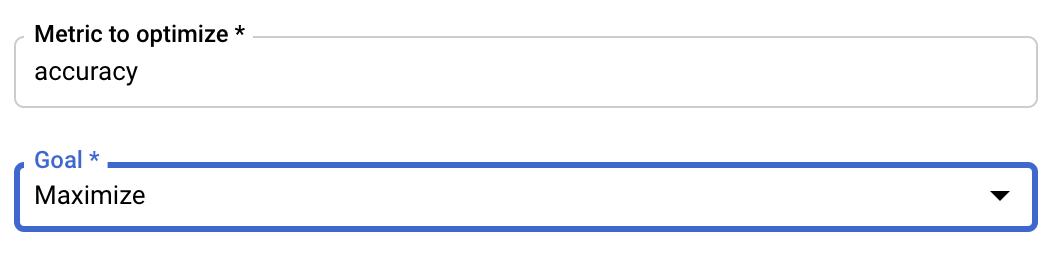
กำหนดค่าเมตริก
หลังจากเพิ่มไฮเปอร์พารามิเตอร์แล้ว คุณจะต้องระบุเมตริกที่คุณต้องการเพิ่มประสิทธิภาพรวมถึงเป้าหมายต่อไป ซึ่งควรเหมือนกับ hyperparameter_metric_tag ที่คุณตั้งไว้ในใบสมัครเข้าร่วมการฝึกอบรม
บริการปรับแต่ง Vertex AI Hyperparameter จะเรียกใช้การทดลองใช้แอปพลิเคชันการฝึกหลายรายการด้วยค่าที่กำหนดค่าไว้ในขั้นตอนก่อนหน้า คุณจะต้องกําหนดขอบเขตบนของจํานวนการทดสอบที่บริการจะทํา โดยทั่วไปการทดลองจำนวนมากขึ้นจะให้ผลลัพธ์ที่ดีกว่า แต่จะมีจุดให้ผลตอบแทนลดลง หลังจากนั้นการทดลองใช้เพิ่มเติมจะส่งผลกระทบน้อยมากหรือไม่มีเลยกับเมตริกที่คุณพยายามเพิ่มประสิทธิภาพ แนวทางปฏิบัติแนะนำคือให้เริ่มจากการทดลองจำนวนน้อยๆ ก่อน และศึกษาว่าไฮเปอร์พารามิเตอร์ที่คุณเลือกมีประสิทธิภาพเพียงใดก่อนที่จะปรับขนาดการทดลองเป็นวงกว้าง
และจะต้องกำหนดขอบเขตสูงสุดของจำนวนการทดลองใช้พร้อมกันด้วย การเพิ่มจำนวนการทดลองใช้แบบพร้อมกันจะลดระยะเวลาในการทำงานการปรับแต่งไฮเปอร์พารามิเตอร์ แต่จะทำให้ประสิทธิภาพของงานนี้ลดลง เนื่องจากกลยุทธ์การปรับแต่งเริ่มต้นจะใช้ผลลัพธ์ของช่วงทดลองใช้ครั้งก่อนในการบอกการกำหนดค่าในการทดลองครั้งต่อๆ ไป หากเรียกใช้การทดลองพร้อมกันหลายรายการเกินไป จะมีช่วงทดลองใช้ที่เริ่มต้นโดยไม่ได้รับประโยชน์จากผลของการทดลองที่ยังทำงานอยู่
คุณสามารถกําหนดจํานวนการทดสอบเป็น 15 และจํานวนการทดสอบพร้อมกันสูงสุดเป็น 3 เพื่อเป็นการสาธิต คุณสามารถทดสอบด้วยหมายเลขที่แตกต่างกันได้ แต่วิธีนี้อาจทำให้ใช้เวลาปรับแต่งนานขึ้นและมีค่าใช้จ่ายสูงขึ้น

ขั้นตอนสุดท้ายคือการเลือก Default เป็นอัลกอริทึมการค้นหา ซึ่งจะใช้ Google Vizier ในการเพิ่มประสิทธิภาพ Bayesian สำหรับการปรับแต่งไฮเปอร์พารามิเตอร์ ดูข้อมูลเพิ่มเติมเกี่ยวกับอัลกอริทึมนี้ได้ที่นี่

คลิกต่อไป
ขั้นตอนที่ 3: กำหนดค่าการประมวลผล
ในส่วนการประมวลผลและการกำหนดราคา ให้ปล่อยภูมิภาคที่เลือกไว้ตามเดิมและกำหนดค่า Worker Pool 0 ดังนี้

คลิกเริ่มการฝึกเพื่อเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์ ในส่วนการฝึกของคอนโซลใต้แท็บ HYPERPARAMETER TUNING JobS คุณจะเห็นข้อมูลดังนี้
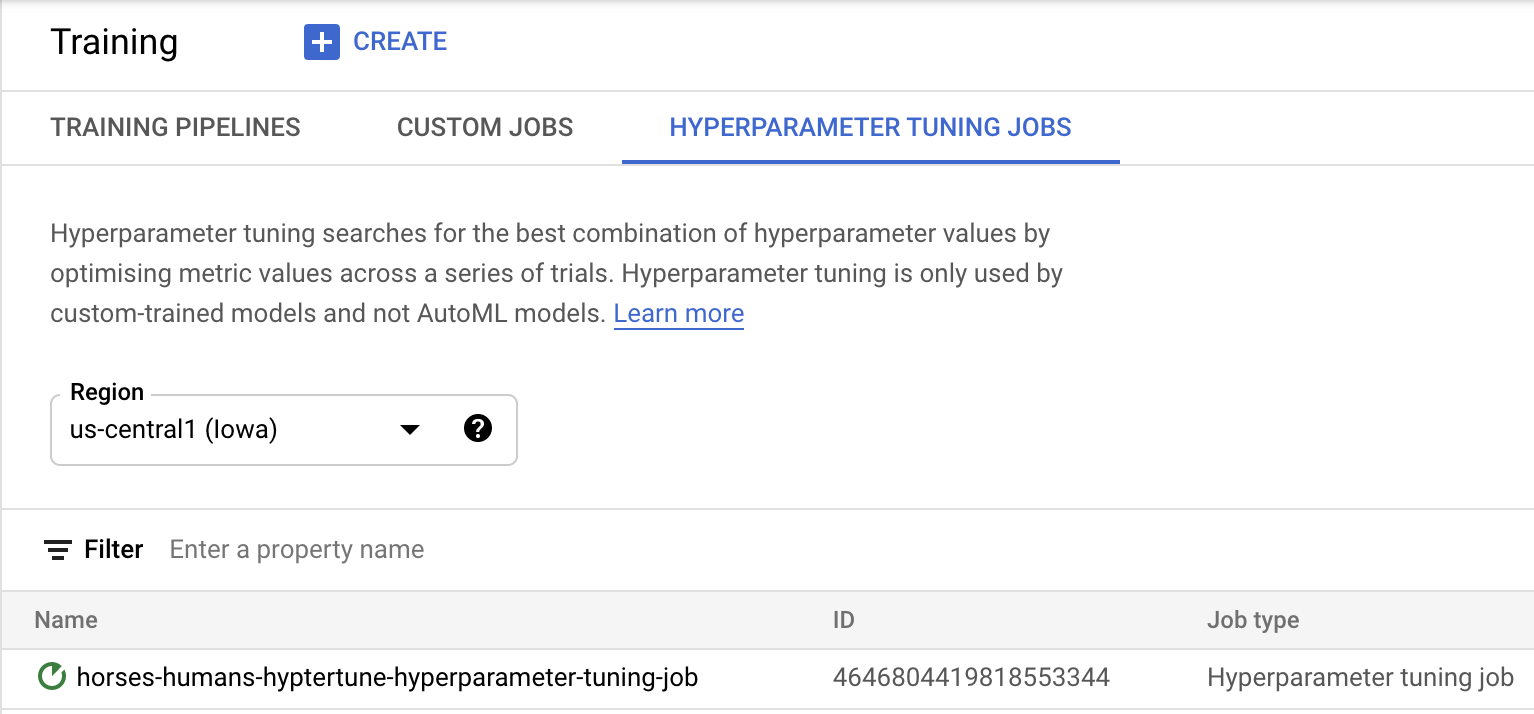
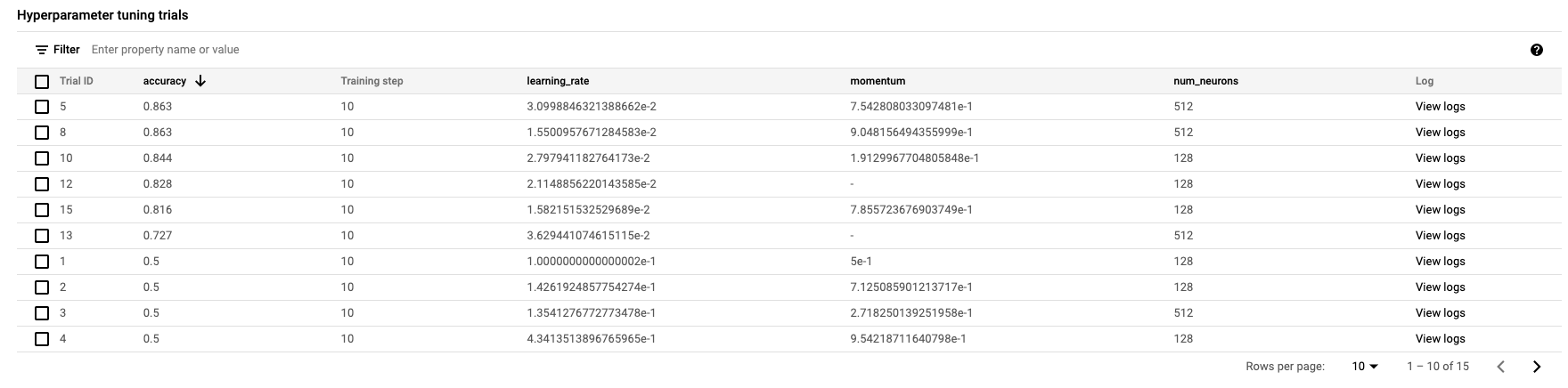
เมื่อดำเนินการเสร็จสิ้น คุณจะสามารถคลิกชื่องานและดูผลลัพธ์ของการทดลองปรับแต่งได้
🎉 ยินดีด้วย 🎉
คุณได้เรียนรู้วิธีใช้ Vertex AI เพื่อทำสิ่งต่อไปนี้แล้ว
- เริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์สําหรับโค้ดการฝึกที่ให้ไว้ในคอนเทนเนอร์ที่กําหนดเอง คุณใช้โมเดล TensorFlow ในตัวอย่างนี้ แต่สามารถฝึกโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้โดยใช้คอนเทนเนอร์ที่กำหนดเอง
ดูข้อมูลเพิ่มเติมเกี่ยวกับส่วนต่างๆ ของ Vertex ได้ในเอกสารประกอบ
6 [ไม่บังคับ] ใช้ Vertex SDK
ส่วนก่อนหน้านี้แสดงวิธีเรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ผ่าน UI ในส่วนนี้ คุณจะเห็นวิธีอื่นในการส่งงานการปรับแต่งไฮเปอร์พารามิเตอร์โดยใช้ Vertex Python API
สร้างโน้ตบุ๊ก TensorFlow 2 จากตัวเปิด

นําเข้า Vertex AI SDK
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
หากต้องการเรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ คุณต้องกำหนดข้อกำหนดต่อไปนี้ก่อน คุณจะต้องแทนที่ {PROJECT_ID} ใน image_uri ด้วยโปรเจ็กต์ของคุณ
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
ถัดไป ให้สร้าง CustomJob คุณจะต้องแทนที่ {YOUR_BUCKET} ด้วยที่เก็บข้อมูลในโปรเจ็กต์สำหรับการทดลองใช้
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
จากนั้นสร้างและเรียกใช้ HyperparameterTuningJob
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7 ล้างข้อมูล
เนื่องจากเรากำหนดค่าให้สมุดบันทึกหมดเวลาหลังจากไม่มีการใช้งาน 60 นาที เราจึงไม่ต้องกังวลเกี่ยวกับการปิดอินสแตนซ์ หากต้องการปิดอินสแตนซ์ด้วยตนเอง ให้คลิกปุ่ม "หยุด" ในส่วน Vertex AI Workbench ของคอนโซล หากคุณต้องการลบสมุดบันทึกทั้งหมด ให้คลิกปุ่ม ลบ

หากต้องการลบที่เก็บข้อมูลของพื้นที่เก็บข้อมูล โดยใช้เมนูการนำทางใน Cloud Console จากนั้นเรียกดูพื้นที่เก็บข้อมูล เลือกที่เก็บข้อมูล แล้วคลิกลบ: