1. Resumen
En este lab, usará Vertex AI a fin de ejecutar un trabajo de ajuste de hiperparámetros para un modelo de TensorFlow. Si bien este lab usa TensorFlow para el código del modelo, los conceptos también se aplican a otros frameworks de AA.
Qué aprenderá
Obtendrás información sobre cómo hacer las siguientes acciones:
- Modifique el código de la aplicación de entrenamiento para el ajuste automatizado de hiperparámetros
- Configurar e iniciar un trabajo de ajuste de hiperparámetros desde la IU de Vertex AI
- Configura e inicia un trabajo de ajuste de hiperparámetros con el SDK de Vertex AI Python
El costo total de la ejecución de este lab en Google Cloud es de aproximadamente $3 USD.
2. Introducción a Vertex AI
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puede migrar proyectos existentes a Vertex AI. Para enviarnos comentarios, visite la página de asistencia.
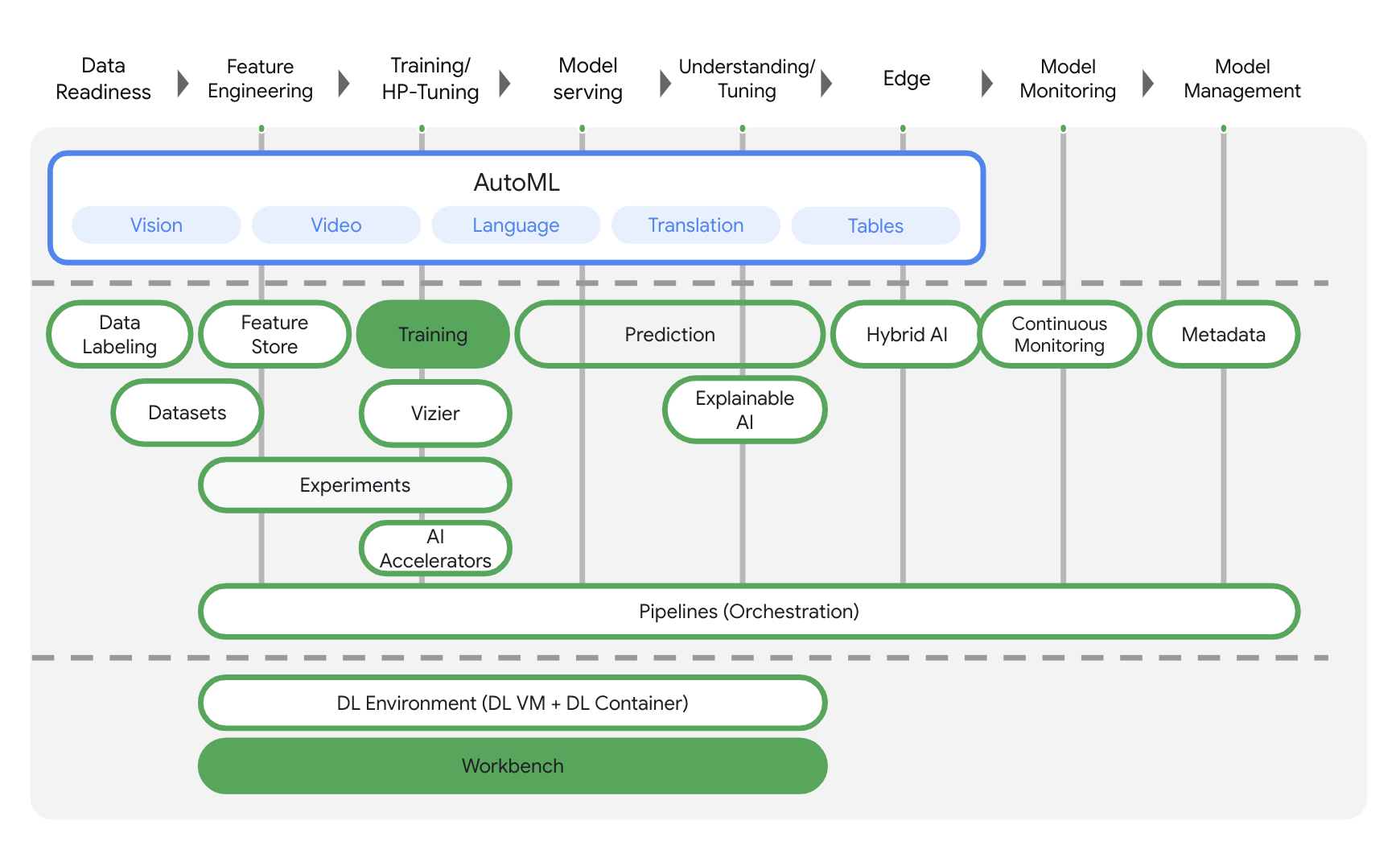
Vertex AI incluye muchos productos distintos para respaldar flujos de trabajo de AA de extremo a extremo. Este lab se centrará en los productos destacados a continuación: Entrenamiento y Workbench.
3. Cómo configurar tu entorno
Para ejecutar este codelab, necesitarás un proyecto de Google Cloud Platform con facturación habilitada. Para crear un proyecto, sigue estas instrucciones.
Paso 1: Habilita la API de Compute Engine
Ve a Compute Engine y selecciona Habilitar (si aún no está habilitado). La necesitarás para crear tu instancia de notebook.
Paso 2: Habilita la API de Container Registry
Navegue a Container Registry y seleccione Habilitar si aún no lo ha hecho. Usarás esto a fin de crear un contenedor para tu trabajo de entrenamiento personalizado.
Paso 3: Habilita la API de Vertex AI
Navegue hasta la sección de Vertex AI en Cloud Console y haga clic en Habilitar API de Vertex AI.
Paso 4: Crea una instancia de Vertex AI Workbench
En la sección de Vertex AI de Cloud Console, haga clic en Workbench:
Habilita la API de Notebooks si aún no lo está.
Una vez habilitada, haga clic en NOTED NOTEBOOK:

Luego, selecciona NUEVO NOTEBOOK.
Asigne un nombre a su notebook y, luego, haga clic en Configuración avanzada.

En Configuración avanzada, habilita el cierre inactivo y establece la cantidad de minutos en 60. Esto significa que el notebook se cerrará automáticamente cuando no esté en uso para que no se generen costos innecesarios.

En Seguridad, selecciona "Habilitar terminal" si aún no está habilitado.
Puede dejar el resto de la configuración avanzada tal como está.
Luego, haga clic en Crear. La instancia tardará algunos minutos en aprovisionarse.
Una vez que se haya creado la instancia, selecciona Abrir JupyterLab.

La primera vez que uses una instancia nueva, se te solicitará que te autentiques. Sigue los pasos en la IU para hacerlo.
4. Crea contenedores para el código de aplicaciones de entrenamiento
El modelo que entrenará y ajustará en este lab es un modelo de clasificación de imágenes entrenado con el conjunto de datos caballos o seres humanos de TensorFlow Datasets.
Enviará este trabajo de ajuste de hiperparámetros a Vertex AI. Para ello, colocará el código de su aplicación de entrenamiento en un contenedor de Docker y lo enviará a Google Container Registry. Con este enfoque, puedes ajustar los hiperparámetros para un modelo compilado con cualquier framework.
Para comenzar, desde el menú Selector, abre una ventana de la terminal en tu instancia de notebook:

Crea un directorio nuevo llamado horses_or_humans y cd en él:
mkdir horses_or_humans
cd horses_or_humans
Paso 1: Cree un Dockerfile
El primer paso para crear un contenedor de código es crear un Dockerfile. En el Dockerfile, incluirá todos los comandos necesarios para ejecutar la imagen. Se instalarán todas las bibliotecas necesarias, incluida la biblioteca de CloudML Hypertune, y configurará el punto de entrada para el código de entrenamiento.
Desde tu terminal, crea un Dockerfile vacío:
touch Dockerfile
Abra el Dockerfile y copie lo siguiente:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Este Dockerfile usa la imagen de Docker de Deep Learning Container TensorFlow Enterprise 2.7. Los contenedores de aprendizaje profundo de Google Cloud tienen muchos frameworks comunes de AA y ciencia de datos preinstalados. Después de descargar esa imagen, este Dockerfile configura el punto de entrada para el código de entrenamiento. Aún no has creado estos archivos. En el siguiente paso, agregarás el código para entrenar y ajustar el modelo.
Paso 2: Agrega el código de entrenamiento de modelos
Desde su terminal, ejecute el siguiente comando a fin de crear un directorio para el código de entrenamiento y un archivo de Python en el que agregará el código:
mkdir trainer
touch trainer/task.py
Ahora, deberías tener lo siguiente en el directorio horses_or_humans/:
+ Dockerfile
+ trainer/
+ task.py
A continuación, abre el archivo task.py que acabas de crear y copia el siguiente código.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Antes de compilar el contenedor, analicemos el código con más detalle. Hay algunos componentes que son específicos del uso del servicio de ajuste de hiperparámetros.
- La secuencia de comandos importa la biblioteca
hypertune. Tenga en cuenta que el Dockerfile del paso 1 incluyó instrucciones para instalar pip con esta biblioteca. - La función
get_args()define un argumento de la línea de comandos para cada hiperparámetro que deseas ajustar. En este ejemplo, los hiperparámetros que se ajustarán son la tasa de aprendizaje, el valor de impulso en el optimizador y la cantidad de unidades en la última capa oculta del modelo, pero puede experimentar con otras. El valor que se pasa en esos argumentos se usa para establecer el hiperparámetro correspondiente en el código. - Al final de la función
main(), se usa la bibliotecahypertunepara definir la métrica que deseas optimizar. En TensorFlow, el métodomodel.fitde Keras muestra un objetoHistory. El atributoHistory.historyes un registro de los valores de pérdida de entrenamiento y valores de métricas en ciclos sucesivos. Si pasas datos de validación amodel.fit, el atributoHistory.historytambién incluirá valores de métricas y pérdida de validación. Por ejemplo, si entrenaste un modelo durante tres ciclos con datos de validación y proporcionasteaccuracycomo métrica, el atributoHistory.historysería similar al siguiente diccionario.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Si deseas que el servicio de ajuste de hiperparámetros descubra los valores que maximizan la exactitud de la validación del modelo, define la métrica como la última entrada (o NUM_EPOCS - 1) de la lista val_accuracy. Luego, pasa esta métrica a una instancia de HyperTune. Puedes elegir la string que desees para el hyperparameter_metric_tag, pero deberás volver a usarla más adelante cuando inicies el trabajo de ajuste de hiperparámetros.
Paso 3: Compila el contenedor
Desde tu terminal, ejecuta lo siguiente a fin de definir una variable de entorno para tu proyecto y asegúrate de reemplazar your-cloud-project por el ID de tu proyecto:
PROJECT_ID='your-cloud-project'
Defina una variable con el URI de su imagen de contenedor en Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Luego, ejecuta el siguiente comando para compilar el contenedor desde la raíz de tu directorio horses_or_humans:
docker build ./ -t $IMAGE_URI
Por último, envíela a Google Container Registry:
docker push $IMAGE_URI
Con el contenedor enviado a Container Registry, ya está listo para iniciar un trabajo de ajuste de hiperparámetros de modelo personalizado.
5. Ejecuta un trabajo de ajuste de hiperparámetros en Vertex AI
En este lab, se usa entrenamiento personalizado a través de un contenedor personalizado de Google Container Registry, pero también puede ejecutar un trabajo de ajuste de hiperparámetros con un contenedor precompilado de Vertex AI.
Para comenzar, navega a la sección Entrenamiento en la sección Vertex de Cloud Console:
Paso 1: Configura el trabajo de entrenamiento
Haz clic en Crear para ingresar los parámetros de tu trabajo de ajuste de hiperparámetros.
- En Conjunto de datos, selecciona Sin conjunto de datos administrado.
- Luego, selecciona Entrenamiento personalizado (avanzado) como método de entrenamiento y haz clic en Continuar.
- Ingresa
horses-humans-hyptertune(o el nombre que quieras llamar al modelo) en Model name. - Haga clic en Continue.
En el paso de Configuración del contenedor, seleccione Contenedor personalizado:

En el primer cuadro (Imagen del contenedor), ingresa el valor de tu variable IMAGE_URI de la sección anterior. Debería ser gcr.io/your-cloud-project/horse-human:hypertune con el nombre de tu proyecto. Deje el resto de los campos en blanco y haga clic en Continuar.
Paso 2: Configura el trabajo de ajuste de hiperparámetros
Selecciona Habilitar ajuste de hiperparámetros.
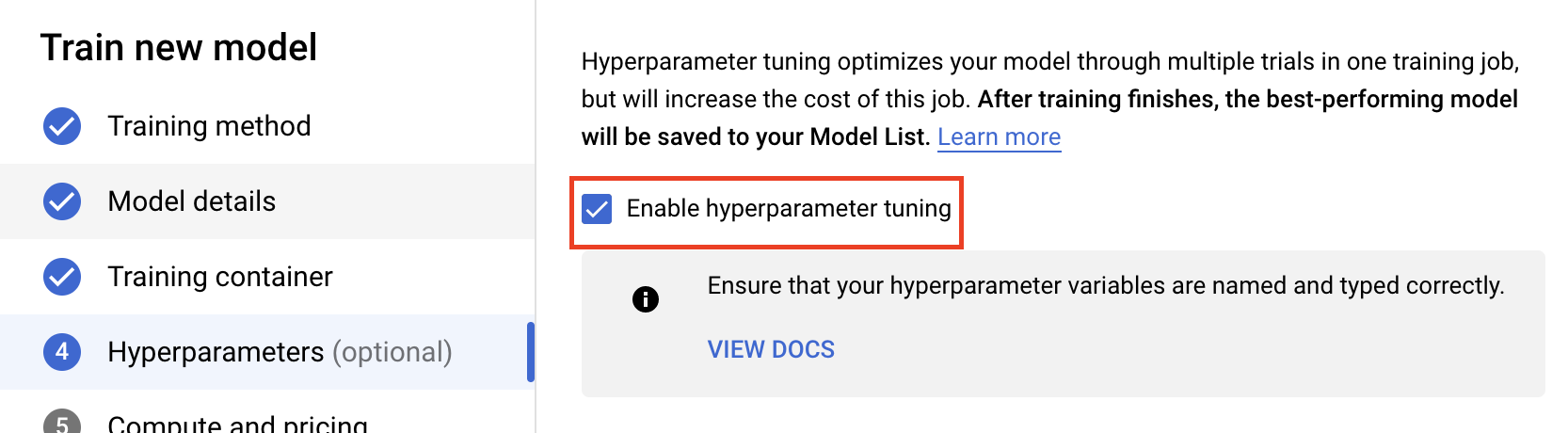
Configurar hiperparámetros
A continuación, deberá agregar los hiperparámetros que configuró como argumentos de línea de comandos en el código de la aplicación de entrenamiento. Cuando agrega un hiperparámetro, primero debe proporcionar el nombre. Debe coincidir con el nombre del argumento que pasaste a argparse.
![learning_rate_name [nombre_tasa_de_aprendizaje]](https://codelabs.developers.google.com/static/vertex_hyperparameter_tuning/img/learning-rate-name.png?hl=es)
Luego, deberás seleccionar el tipo y los límites para los valores que intentará el servicio de ajuste. Si seleccionas el tipo doble o número entero, deberás proporcionar un valor mínimo y uno máximo. Además, si seleccionas categórica o discreta, debes proporcionar los valores.
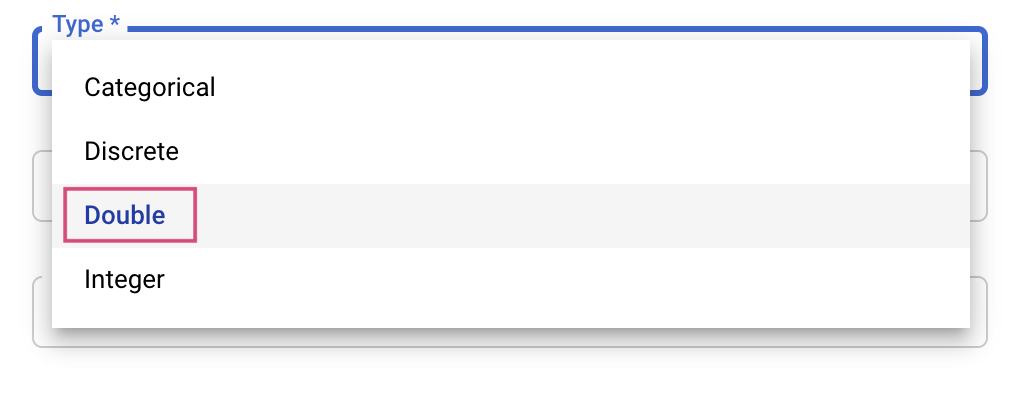
![learning_rate_name [nombre_tasa_de_aprendizaje]](https://codelabs.developers.google.com/static/vertex_hyperparameter_tuning/img/learning-rate-minmax.png?hl=es)
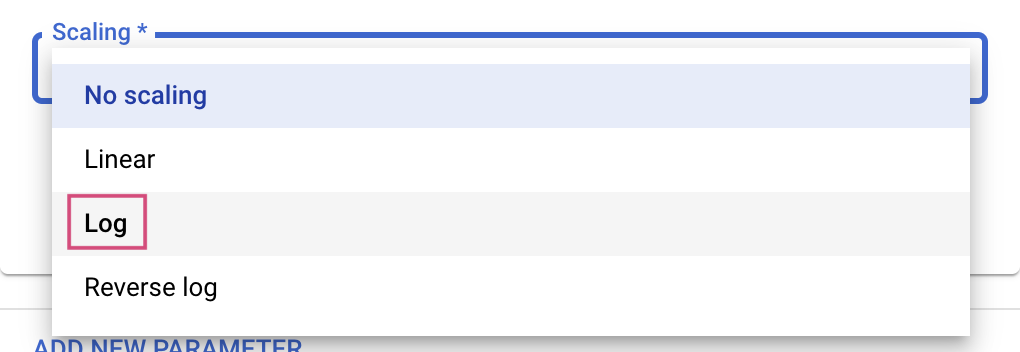
Para los tipos doble y entero, también deberás proporcionar el valor de escalamiento.
Después de agregar el hiperparámetro learning_rate, agrega parámetros para momentum y num_units.


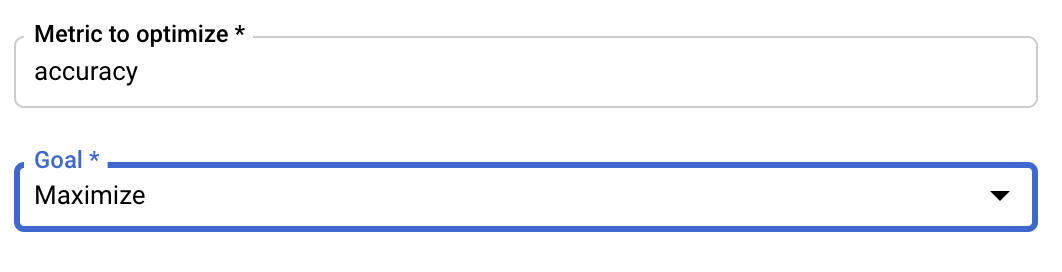
Configurar métrica
Luego de agregar los hiperparámetros, debe proporcionar la métrica que desea optimizar y el objetivo. Debe ser la misma que la hyperparameter_metric_tag que configuraste en la aplicación de entrenamiento.
El servicio de ajuste de hiperparámetros de Vertex AI ejecutará varias pruebas de su aplicación de entrenamiento con los valores configurados en los pasos anteriores. Deberá establecer un límite superior para la cantidad de pruebas que se ejecutarán en el servicio. Por lo general, una mayor cantidad de pruebas genera mejores resultados, pero habrá un momento de disminuir los retornos después de los cuales las pruebas adicionales tendrán poco o ningún efecto en la métrica que intenta optimizar. Se recomienda comenzar con una cantidad menor de pruebas y tener una idea del impacto que tienen los hiperparámetros elegidos antes de escalar verticalmente a una gran cantidad de pruebas.
También deberá establecer un límite superior para la cantidad de pruebas paralelas. Aumentar la cantidad de pruebas paralelas reducirá la cantidad de tiempo que tarda en ejecutarse el trabajo de ajuste de hiperparámetros. pero sí puede reducir la efectividad del trabajo. Esto se debe a que la estrategia de ajuste predeterminada utiliza los resultados de pruebas anteriores para informar la asignación de valores en las pruebas posteriores. Si ejecutas demasiadas pruebas en paralelo, habrá pruebas que comenzarán sin el beneficio del resultado de las que aún se estén ejecutando.
A modo de demostración, puede establecer la cantidad de pruebas en 15 y la cantidad máxima de pruebas paralelas en 3. Puedes experimentar con diferentes números, pero esto puede generar un tiempo de ajuste más largo y un costo más alto.

El último paso consiste en seleccionar Default como el algoritmo de búsqueda, que usará Google Vizier para realizar optimizaciones bayesianas para el ajuste de hiperparámetros. Puedes obtener más información sobre este algoritmo aquí.
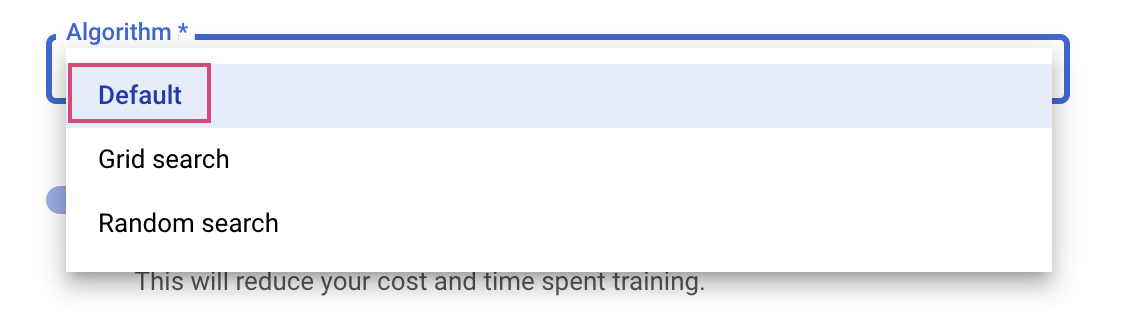
Haga clic en Continuar.
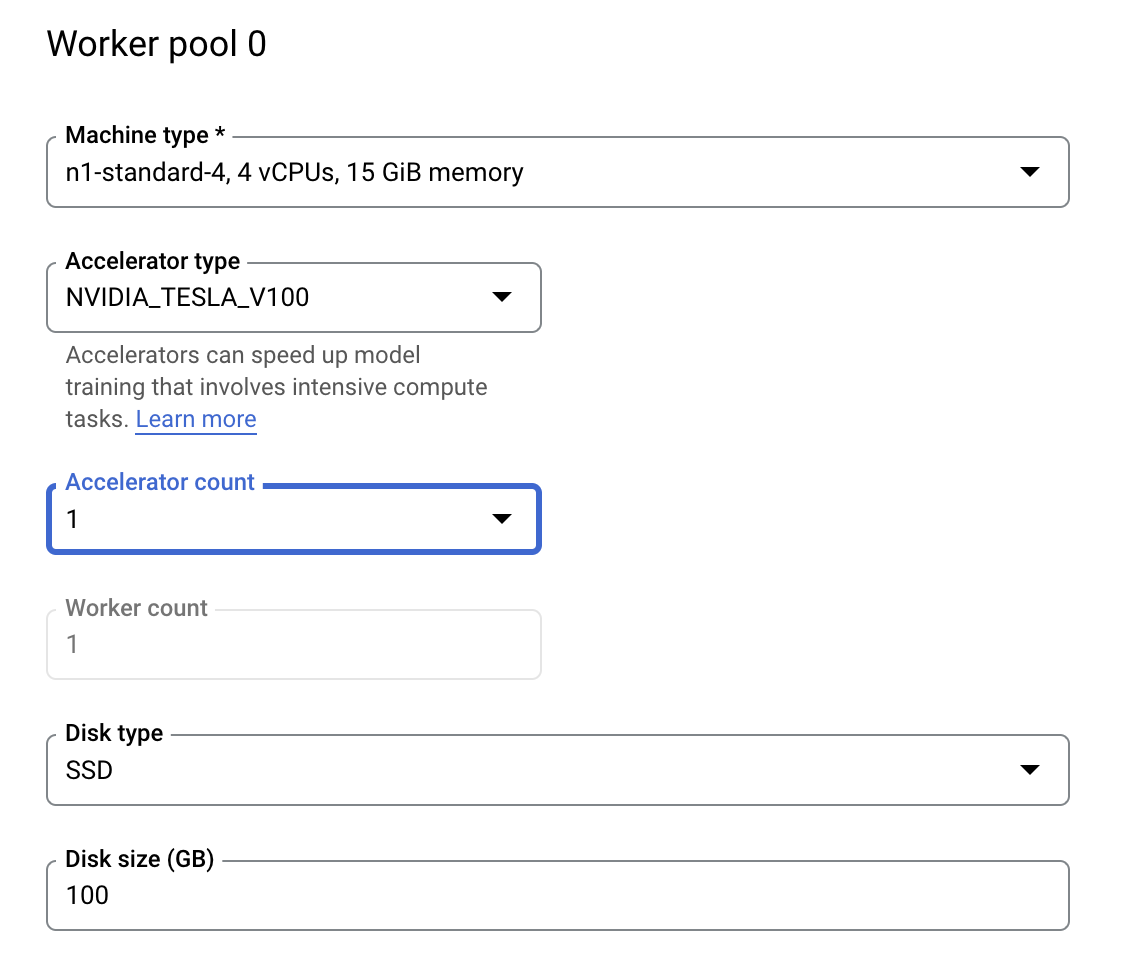
Paso 3: Configura el procesamiento
En Compute and pricing, deje la región seleccionada tal como está y configure el Grupo de trabajadores 0 de la siguiente manera.
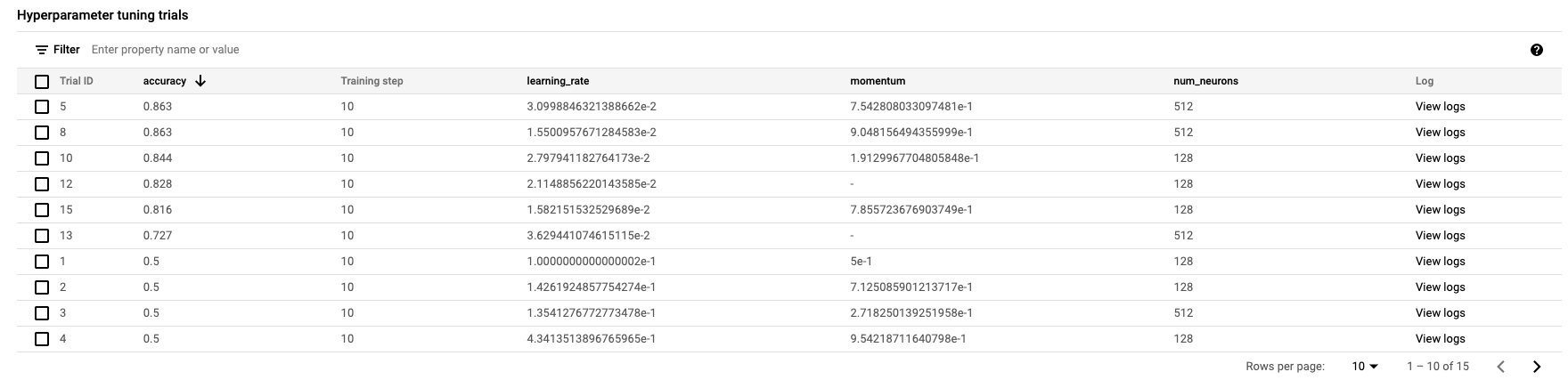
Haz clic en Iniciar entrenamiento para iniciar el trabajo de ajuste de hiperparámetros. En la sección de Entrenamiento de su consola, en la pestaña HYPERPARAMETER TUNING JOBS, verá algo similar a lo siguiente:
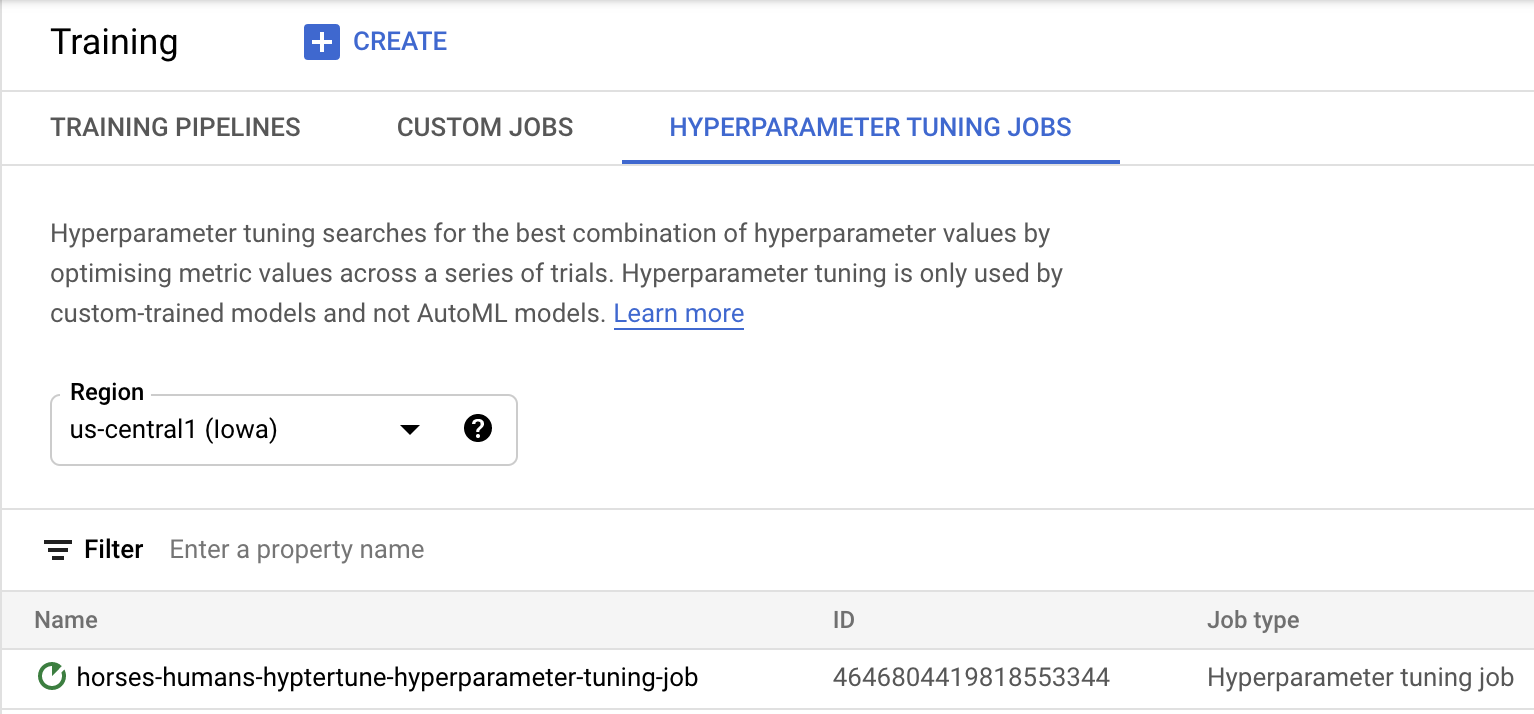
Cuando termine, podrá hacer clic en el nombre del trabajo y ver los resultados de las pruebas de ajuste.
🎉 ¡Felicitaciones! 🎉
Aprendiste a usar Vertex AI para hacer lo siguiente:
- Iniciar un trabajo de ajuste de hiperparámetros para el código de entrenamiento proporcionado en un contenedor personalizado En este ejemplo, usó un modelo de TensorFlow, pero puede entrenar un modelo creado con cualquier framework mediante contenedores personalizados.
Si quieres obtener más información sobre las distintas partes de Vertex, consulta la documentación.
6. Usa el SDK de Vertex (opcional)
En la sección anterior, se mostró cómo iniciar el trabajo de ajuste de hiperparámetros a través de la IU. En esta sección, verá una forma alternativa de enviar el trabajo de ajuste de hiperparámetros mediante la API de Vertex Python.
Desde el Selector, crea un notebook de TensorFlow 2.

Importa el SDK de Vertex AI.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Para iniciar el trabajo de ajuste de hiperparámetros, primero debe definir las siguientes especificaciones. Deberás reemplazar {PROJECT_ID} en el image_uri por tu proyecto.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
A continuación, crea un objeto CustomJob. Deberás reemplazar {YOUR_BUCKET} por un bucket de tu proyecto para la etapa de pruebas.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Luego, crea y ejecuta HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Limpieza
Debido a que configuramos el notebook para que se agote el tiempo de espera después de 60 minutos de inactividad, no tenemos que preocuparnos por cerrar la instancia. Si desea cerrar la instancia de forma manual, haga clic en el botón Detener en la sección Vertex AI Workbench de la consola. Si deseas borrar el notebook por completo, haz clic en el botón Borrar.

Para borrar el bucket de Storage, en el menú de navegación de Cloud Console, navegue a Storage, seleccione su bucket y haga clic en Borrar: