۱. مرور کلی
در این آزمایش، شما از Vertex AI برای اجرای یک کار تنظیم هایپرپارامتر برای یک مدل TensorFlow استفاده خواهید کرد. اگرچه این آزمایش از TensorFlow برای کد مدل استفاده میکند، اما مفاهیم آن برای سایر چارچوبهای یادگیری ماشین نیز قابل استفاده است.
آنچه یاد میگیرید
شما یاد خواهید گرفت که چگونه:
- اصلاح کد برنامه آموزشی برای تنظیم خودکار هایپرپارامتر
- پیکربندی و اجرای یک کار تنظیم هایپرپارامتر از رابط کاربری Vertex AI
- پیکربندی و اجرای یک کار تنظیم هایپرپارامتر با Vertex AI Python SDK
هزینه کل اجرای این آزمایشگاه در گوگل کلود حدود ۳ دلار آمریکا است.
۲. مقدمهای بر هوش مصنوعی ورتکس
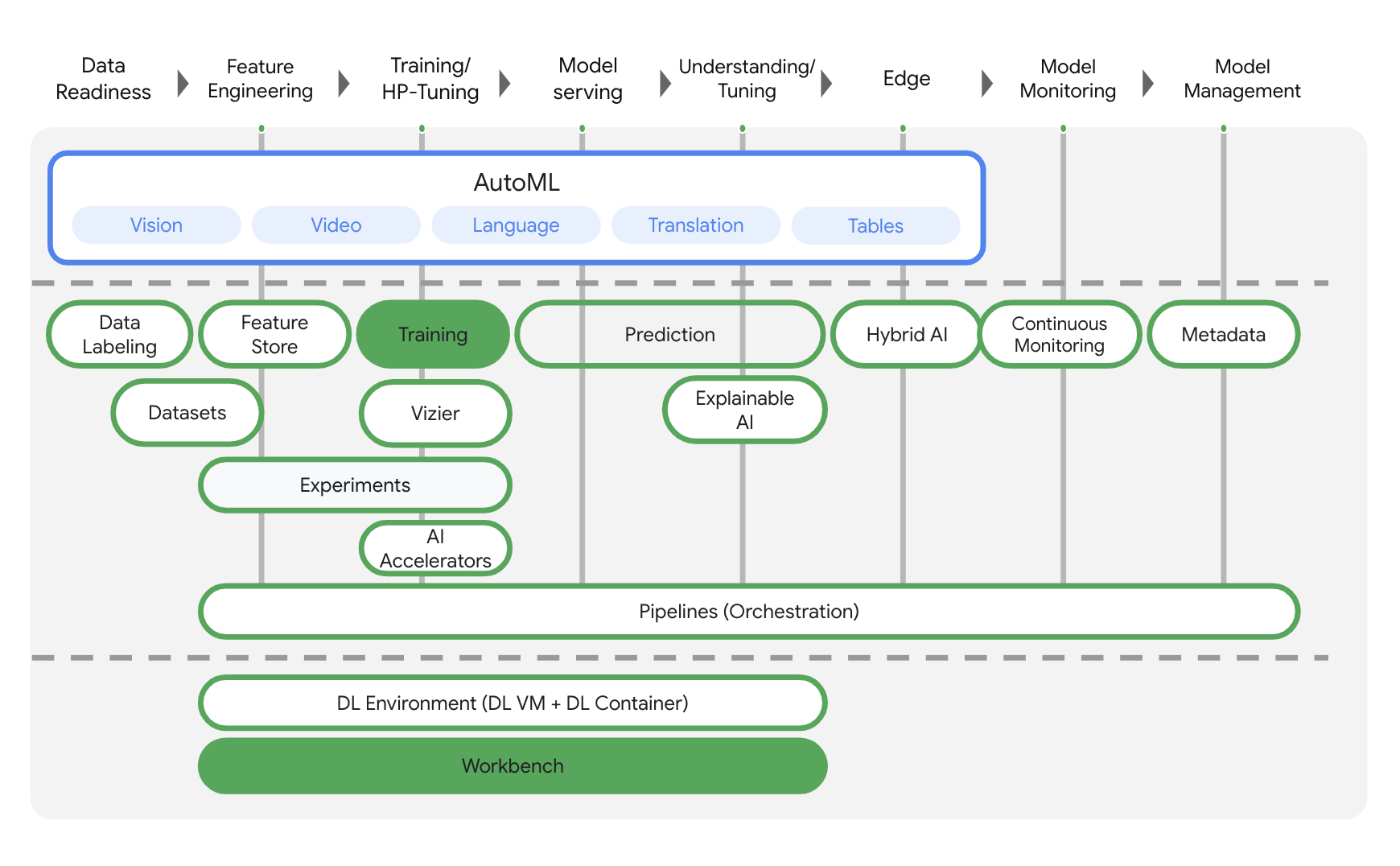
این آزمایشگاه از جدیدترین محصول هوش مصنوعی موجود در Google Cloud استفاده میکند. Vertex AI، محصولات یادگیری ماشین را در Google Cloud ادغام میکند تا یک تجربه توسعه یکپارچه را فراهم کند. پیش از این، مدلهای آموزشدیده با AutoML و مدلهای سفارشی از طریق سرویسهای جداگانه قابل دسترسی بودند. این محصول جدید، هر دو را در یک API واحد، به همراه سایر محصولات جدید، ترکیب میکند. همچنین میتوانید پروژههای موجود را به Vertex AI منتقل کنید. در صورت داشتن هرگونه بازخورد، لطفاً به صفحه پشتیبانی مراجعه کنید.
Vertex AI شامل محصولات مختلفی برای پشتیبانی از گردشهای کاری یادگیری ماشینی سرتاسری است. این آزمایشگاه بر روی محصولات برجسته زیر تمرکز خواهد کرد: آموزش و میز کار .
۳. محیط خود را راهاندازی کنید
برای اجرای این codelab به یک پروژه Google Cloud Platform با قابلیت پرداخت صورتحساب نیاز دارید. برای ایجاد یک پروژه، دستورالعملهای اینجا را دنبال کنید.
مرحله ۱: فعال کردن رابط برنامهنویسی کاربردی موتور محاسبات
به Compute Engine بروید و اگر از قبل فعال نشده است، آن را فعال کنید . برای ایجاد نمونه نوتبوک خود به این مورد نیاز خواهید داشت.
مرحله 2: فعال کردن API رجیستری کانتینر
به رجیستری کانتینر بروید و اگر فعال نیست، آن را فعال کنید. از این برای ایجاد یک کانتینر برای کار آموزشی سفارشی خود استفاده خواهید کرد.
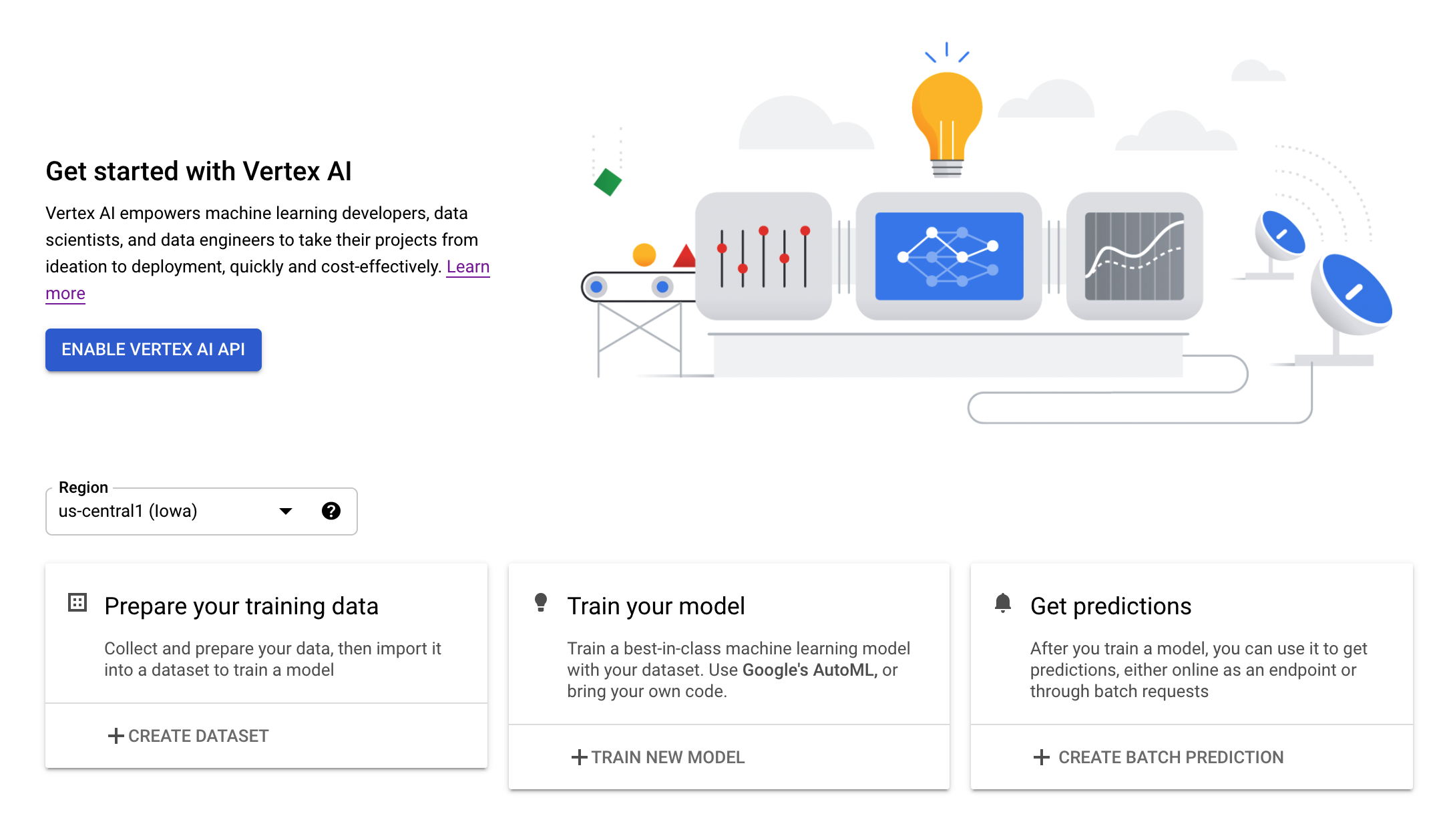
مرحله 3: فعال کردن API هوش مصنوعی Vertex
به بخش Vertex AI در کنسول ابری خود بروید و روی Enable Vertex AI API کلیک کنید.
مرحله ۴: ایجاد یک نمونه از Vertex AI Workbench
از بخش Vertex AI در کنسول ابری خود، روی Workbench کلیک کنید:
اگر API نوتبوکها فعال نیست، آن را فعال کنید.
پس از فعال کردن، روی «دفترچههای مدیریتشده» کلیک کنید:

سپس دفترچه یادداشت جدید را انتخاب کنید.
برای نوتبوک خود یک نام انتخاب کنید و سپس روی تنظیمات پیشرفته (Advanced Settings) کلیک کنید.

در قسمت تنظیمات پیشرفته، خاموش شدن در حالت بیکاری را فعال کنید و تعداد دقیقهها را روی ۶۰ تنظیم کنید. این یعنی نوتبوک شما در صورت عدم استفاده به طور خودکار خاموش میشود تا هزینههای غیرضروری متحمل نشوید.

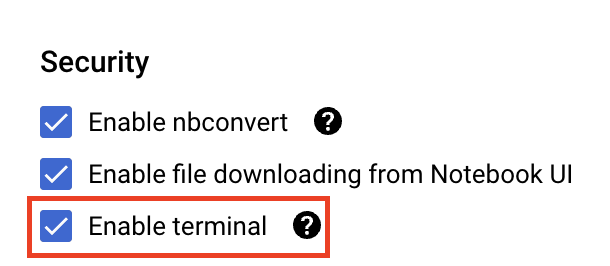
در قسمت امنیت، اگر از قبل فعال نشده است، گزینه «فعال کردن ترمینال» را انتخاب کنید.
میتوانید تمام تنظیمات پیشرفته دیگر را همانطور که هست، رها کنید.
سپس، روی ایجاد (Create) کلیک کنید. آمادهسازی نمونه (instance) چند دقیقه طول خواهد کشید.
پس از ایجاد نمونه، گزینه Open JupyterLab را انتخاب کنید.

اولین باری که از یک نمونه جدید استفاده میکنید، از شما خواسته میشود که احراز هویت کنید. برای انجام این کار، مراحل موجود در رابط کاربری را دنبال کنید.
۴. کد برنامه آموزشی را کانتینریزه کنید
مدلی که در این آزمایشگاه آموزش داده و تنظیم خواهید کرد، یک مدل طبقهبندی تصویر است که بر روی مجموعه دادههای اسبها یا انسانها از مجموعه دادههای TensorFlow آموزش داده شده است.
شما این کار تنظیم هایپرپارامترها را با قرار دادن کد برنامه آموزشی خود در یک کانتینر Docker و ارسال این کانتینر به Google Container Registry به Vertex AI ارسال خواهید کرد. با استفاده از این رویکرد، میتوانید هایپرپارامترها را برای مدلی که با هر چارچوبی ساخته شده است، تنظیم کنید.
برای شروع، از منوی Launcher، یک پنجره ترمینال در نوتبوک خود باز کنید:

یک دایرکتوری جدید به نام horses_or_humans ایجاد کنید و با دستور cd به آن وارد شوید:
mkdir horses_or_humans
cd horses_or_humans
مرحله ۱: ایجاد یک داکرفایل
اولین قدم برای کانتینرایز کردن کد شما، ایجاد یک Dockerfile است. در Dockerfile تمام دستورات مورد نیاز برای اجرای تصویر را قرار خواهید داد. این فایل تمام کتابخانههای لازم، از جمله کتابخانه CloudML Hypertune را نصب کرده و نقطه ورود کد آموزشی را تنظیم میکند.
از ترمینال خود، یک Dockerfile خالی ایجاد کنید:
touch Dockerfile
فایل Docker را باز کنید و موارد زیر را در آن کپی کنید:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
این داکرفایل از ایمیج داکر پردازنده گرافیکی کانتینر یادگیری عمیق TensorFlow Enterprise 2.7 استفاده میکند. کانتینرهای یادگیری عمیق در Google Cloud با بسیاری از چارچوبهای رایج یادگیری ماشین و علم داده از پیش نصب شده ارائه میشوند. پس از دانلود آن ایمیج، این داکرفایل نقطه ورود کد آموزشی را تنظیم میکند. شما هنوز این فایلها را ایجاد نکردهاید - در مرحله بعدی، کد آموزش و تنظیم مدل را اضافه خواهید کرد.
مرحله ۲: کد آموزشی مدل را اضافه کنید
از ترمینال خود، دستور زیر را اجرا کنید تا یک دایرکتوری برای کد آموزشی و یک فایل پایتون که کد را در آن اضافه خواهید کرد، ایجاد شود:
mkdir trainer
touch trainer/task.py
اکنون باید موارد زیر را در دایرکتوری horses_or_humans/ خود داشته باشید:
+ Dockerfile
+ trainer/
+ task.py
سپس، فایل task.py که ایجاد کردید را باز کنید و کد زیر را در آن کپی کنید.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
قبل از ساخت کانتینر، بیایید نگاه عمیقتری به کد بیندازیم. چند مؤلفه وجود دارد که مختص استفاده از سرویس تنظیم هایپرپارامتر هستند.
- این اسکریپت کتابخانه
hypertuneرا وارد میکند. توجه داشته باشید که Dockerfile مرحله 1 شامل دستورالعملهایی برای نصب این کتابخانه با استفاده از pip است. - تابع
get_args()یک آرگومان خط فرمان برای هر ابرپارامتری که میخواهید تنظیم کنید، تعریف میکند. در این مثال، ابرپارامترهایی که تنظیم میشوند عبارتند از نرخ یادگیری، مقدار تکانه در بهینهساز و تعداد واحدها در آخرین لایه پنهان مدل، اما میتوانید با موارد دیگر نیز آزمایش کنید. مقداری که در این آرگومانها ارسال میشود، سپس برای تنظیم ابرپارامتر مربوطه در کد استفاده میشود. - در انتهای تابع
main()، از کتابخانهhypertuneبرای تعریف معیاری که میخواهید بهینهسازی کنید استفاده میشود. در TensorFlow، متدmodel.fitدر keras یک شیءHistoryرا برمیگرداند. ویژگیHistory.historyرکوردی از مقادیر تلفات آموزش و مقادیر معیارها در دورههای متوالی است. اگر دادههای اعتبارسنجی را بهmodel.fitارسال کنید، ویژگیHistory.historyشامل مقادیر تلفات اعتبارسنجی و معیارها نیز خواهد بود. به عنوان مثال، اگر مدلی را برای سه دوره با دادههای اعتبارسنجی آموزش دادهاید وaccuracyبه عنوان معیار ارائه دادهاید، ویژگیHistory.historyمشابه دیکشنری زیر خواهد بود.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
اگر میخواهید سرویس تنظیم هایپرپارامتر مقادیری را که دقت اعتبارسنجی مدل را به حداکثر میرسانند، کشف کند، باید معیار را به عنوان آخرین ورودی (یا NUM_EPOCS - 1 ) از لیست val_accuracy تعریف کنید. سپس، این معیار را به یک نمونه از HyperTune منتقل کنید. میتوانید هر رشتهای را که دوست دارید برای hyperparameter_metric_tag انتخاب کنید، اما بعداً هنگام شروع کار تنظیم هایپرپارامتر، باید دوباره از این رشته استفاده کنید.
مرحله 3: ساخت کانتینر
از ترمینال خود، دستور زیر را برای تعریف یک متغیر env برای پروژه خود اجرا کنید، و مطمئن شوید که your-cloud-project را با شناسه پروژه خود جایگزین میکنید:
PROJECT_ID='your-cloud-project'
یک متغیر با آدرس URL تصویر کانتینر خود در رجیستری کانتینر گوگل تعریف کنید:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
پیکربندی داکر
gcloud auth configure-docker
سپس، با اجرای دستور زیر از ریشه دایرکتوری horses_or_humans کانتینر را بسازید:
docker build ./ -t $IMAGE_URI
در آخر، آن را به Google Container Registry ارسال کنید:
docker push $IMAGE_URI
با قرار دادن کانتینر در رجیستری کانتینر، اکنون آمادهاید تا یک کار تنظیم هایپرپارامتر مدل سفارشی را شروع کنید.
۵. اجرای یک کار تنظیم فراپارامتر روی Vertex AI
این آزمایشگاه از آموزش سفارشی از طریق یک کانتینر سفارشی در Google Container Registry استفاده میکند، اما میتوانید یک کار تنظیم هایپرپارامتر را با یک کانتینر از پیش ساخته شده Vertex AI نیز اجرا کنید.
برای شروع، به بخش آموزش در بخش Vertex کنسول Cloud خود بروید:
مرحله 1: پیکربندی شغل آموزشی
برای وارد کردن پارامترهای مربوط به کار تنظیم ابرپارامتر خود، روی «ایجاد» کلیک کنید.
- در قسمت مجموعه داده ، گزینه «بدون مجموعه داده مدیریتشده» را انتخاب کنید.
- سپس آموزش سفارشی (پیشرفته) را به عنوان روش آموزش خود انتخاب کرده و روی ادامه کلیک کنید.
- برای نام مدل،
horses-humans-hyptertune(یا هر نامی که دوست دارید برای مدل خود انتخاب کنید) را وارد کنید. - روی ادامه کلیک کنید
در مرحله تنظیمات کانتینر، کانتینر سفارشی را انتخاب کنید:

در کادر اول ( Container image )، مقدار متغیر IMAGE_URI خود را از بخش قبل وارد کنید. باید به صورت gcr.io/your-cloud-project/horse-human:hypertune و با نام پروژه خودتان باشد. بقیه فیلدها را خالی بگذارید و روی ادامه کلیک کنید.
مرحله 2: پیکربندی کار تنظیم هایپرپارامتر
فعال کردن تنظیم ابرپارامتر را انتخاب کنید.
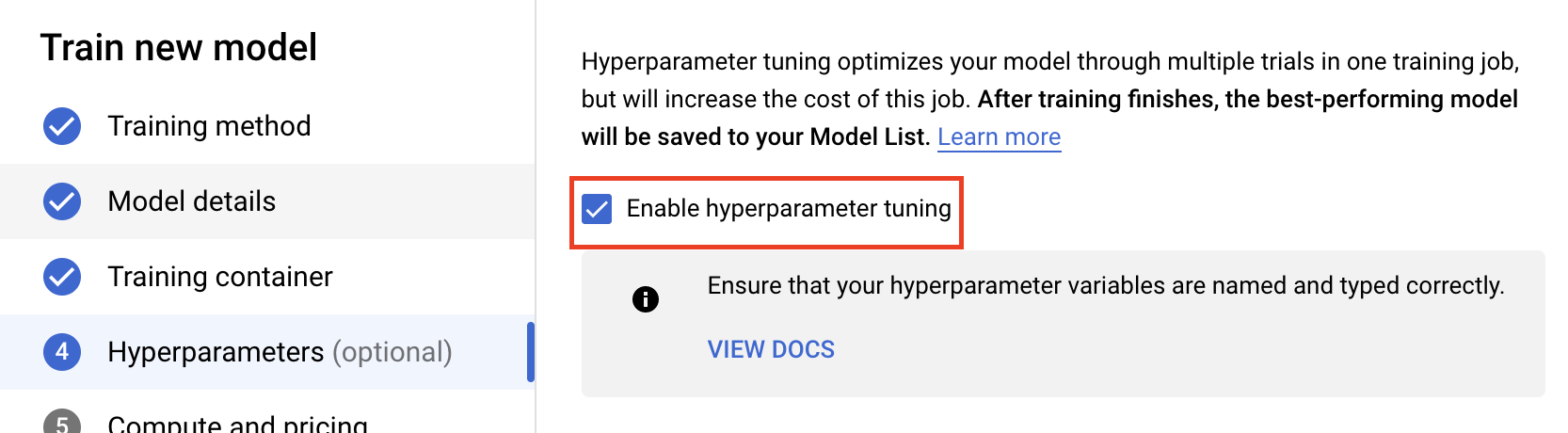
پیکربندی هایپرپارامترها
در مرحله بعد، باید ابرپارامترهایی را که به عنوان آرگومانهای خط فرمان در کد برنامه آموزشی تنظیم کردهاید، اضافه کنید. هنگام اضافه کردن یک ابرپارامتر، ابتدا باید نام آن را ارائه دهید. این باید با نام آرگومانی که به argparse ارسال کردهاید، مطابقت داشته باشد.

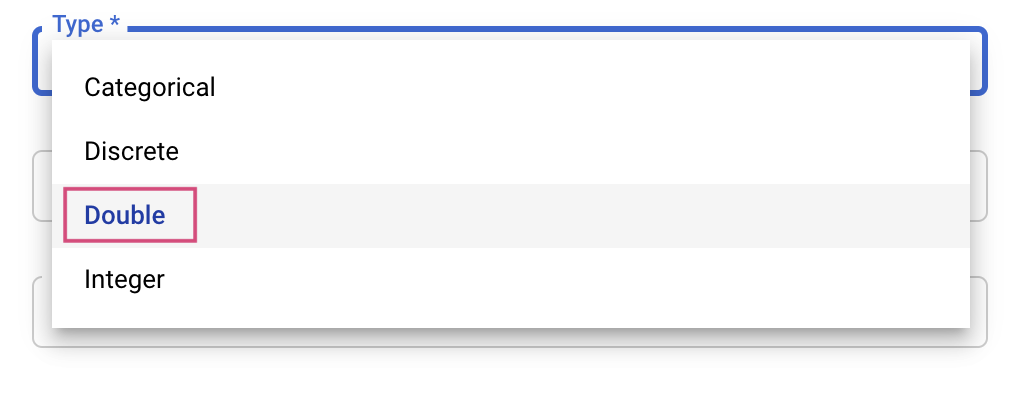
سپس، نوع (Type) و همچنین محدوده مقادیری که سرویس تنظیم امتحان خواهد کرد را انتخاب خواهید کرد. اگر نوع Double یا Integer را انتخاب کنید، باید حداقل و حداکثر مقدار را ارائه دهید. و اگر Categorical یا Discrete را انتخاب کنید، باید مقادیر را ارائه دهید.

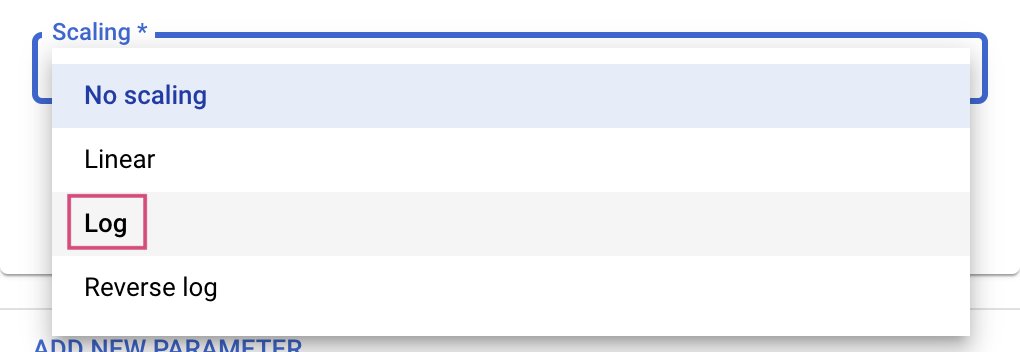
برای انواع Double و Integer، باید مقدار Scaling را نیز ارائه دهید.
پس از افزودن هایپرپارامتر learning_rate ، پارامترهایی برای momentum و num_units اضافه کنید.


پیکربندی متریک
پس از اضافه کردن هایپرپارامترها، باید معیاری که میخواهید بهینهسازی کنید و همچنین هدف را ارائه دهید. این باید همان hyperparameter_metric_tag باشد که در برنامه آموزشی خود تنظیم کردهاید.
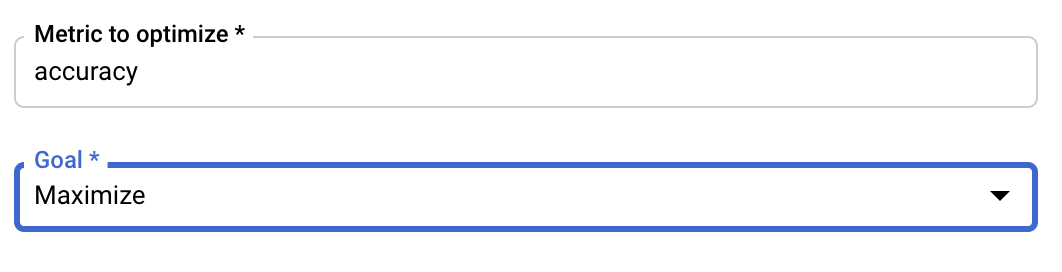
سرویس تنظیم Vertex AI Hyperparameter چندین آزمایش از برنامه آموزشی شما را با مقادیر پیکربندی شده در مراحل قبلی اجرا خواهد کرد. شما باید یک حد بالا برای تعداد آزمایشهایی که سرویس اجرا خواهد کرد، تعیین کنید. آزمایشهای بیشتر عموماً منجر به نتایج بهتری میشوند، اما نقطهای از بازده نزولی وجود خواهد داشت که پس از آن آزمایشهای اضافی تأثیر کمی بر معیاری که سعی در بهینهسازی آن دارید، دارند یا اصلاً تأثیری ندارند. بهترین روش این است که با تعداد کمتری آزمایش شروع کنید و قبل از افزایش تعداد آزمایشها، میزان تأثیرگذاری ابرپارامترهای انتخابی خود را ارزیابی کنید.
همچنین باید یک حد بالا برای تعداد آزمایشهای موازی تعیین کنید. افزایش تعداد آزمایشهای موازی، مدت زمان اجرای کار تنظیم هایپرپارامتر را کاهش میدهد؛ با این حال، میتواند اثربخشی کار را به طور کلی کاهش دهد. دلیل این امر این است که استراتژی تنظیم پیشفرض از نتایج آزمایشهای قبلی برای تعیین مقادیر در آزمایشهای بعدی استفاده میکند. اگر آزمایشهای زیادی را به صورت موازی اجرا کنید، آزمایشهایی وجود خواهند داشت که بدون بهرهگیری از نتیجه آزمایشهای در حال اجرا، شروع میشوند.
برای اهداف نمایشی، میتوانید تعداد آزمایشها را روی ۱۵ و حداکثر تعداد آزمایشهای موازی را روی ۳ تنظیم کنید. میتوانید با اعداد مختلف آزمایش کنید، اما این میتواند منجر به زمان تنظیم طولانیتر و هزینه بالاتر شود.

آخرین مرحله انتخاب Default به عنوان الگوریتم جستجو است که از Google Vizier برای انجام بهینهسازی بیزی برای تنظیم ابرپارامتر استفاده میکند. میتوانید اطلاعات بیشتری در مورد این الگوریتم را اینجا کسب کنید.
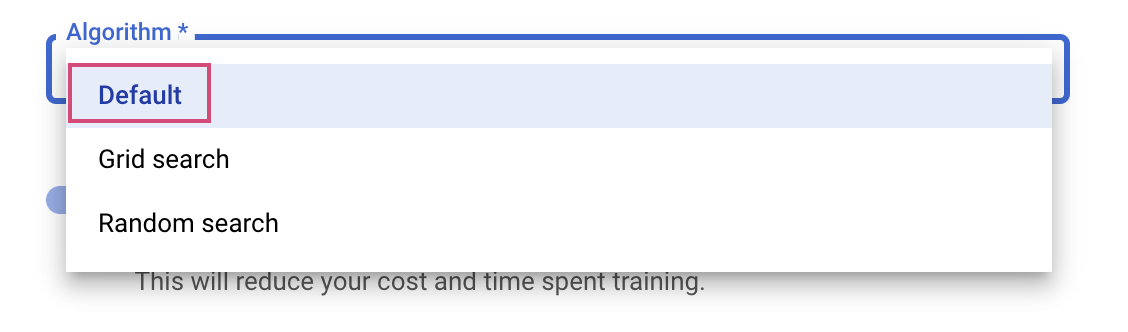
روی ادامه کلیک کنید.
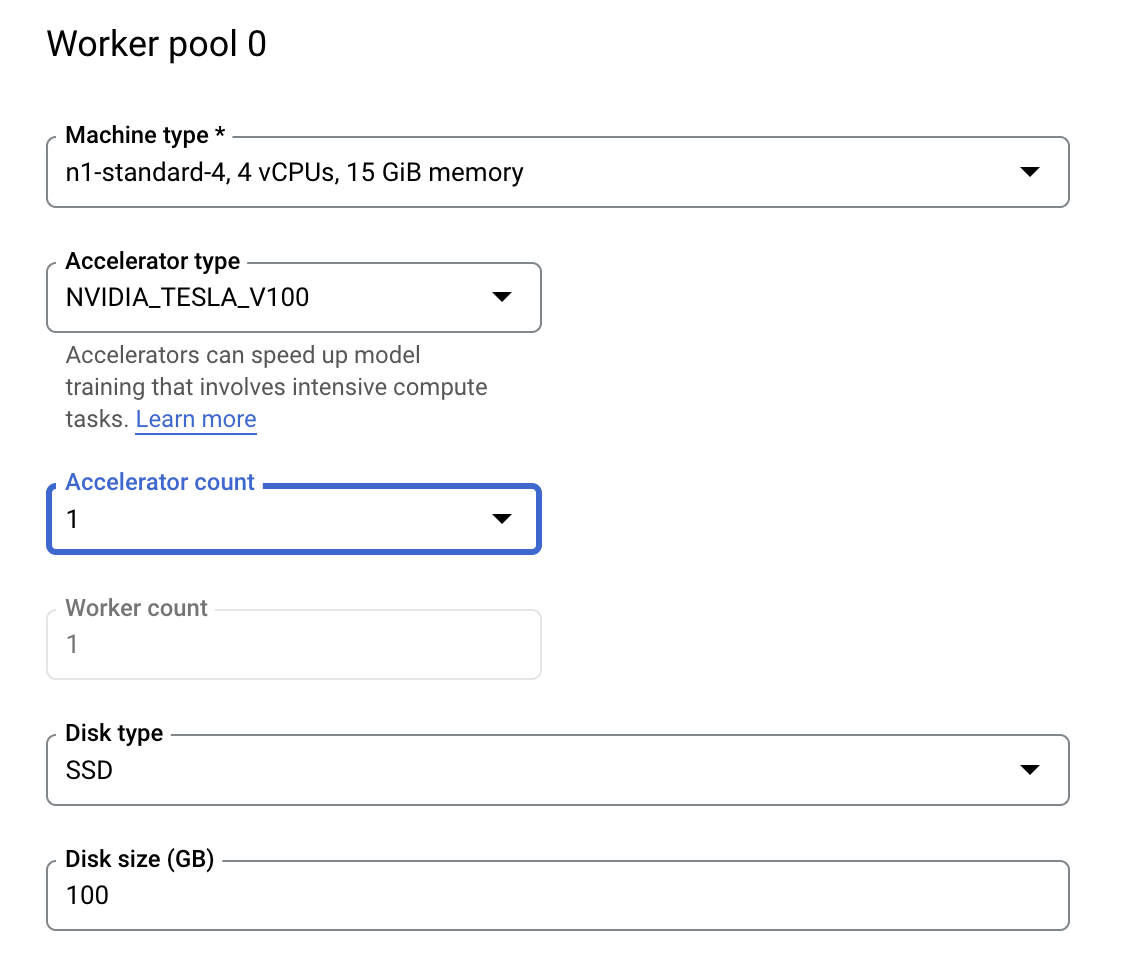
مرحله ۳: پیکربندی محاسبات
در بخش محاسبه و قیمتگذاری ، منطقه انتخاب شده را به همان صورت باقی بگذارید و Worker pool 0 را به صورت زیر پیکربندی کنید.
برای شروع کار تنظیم هایپرپارامتر، روی شروع آموزش کلیک کنید. در بخش آموزش کنسول خود، زیر تب HYPERPARAMETER TUNING JOBS، چیزی شبیه به این خواهید دید:
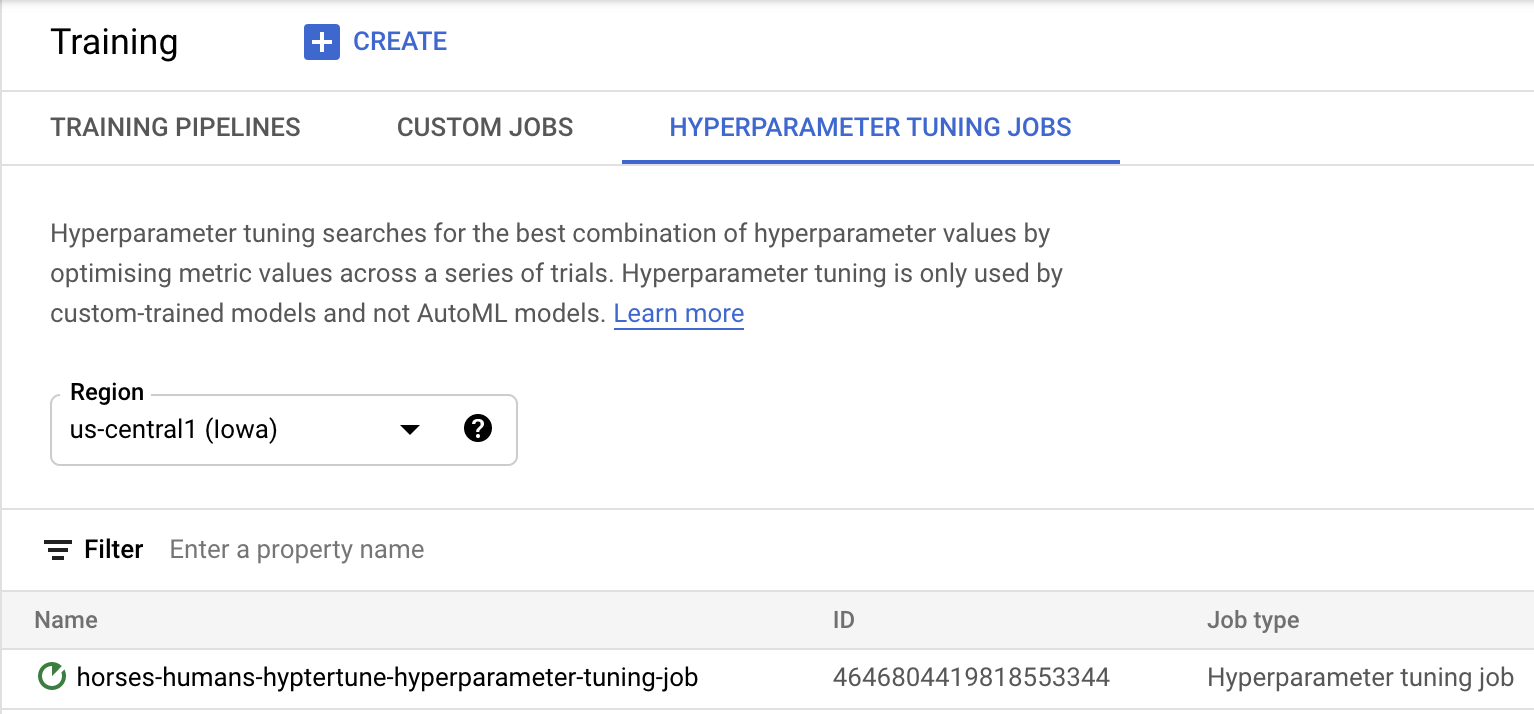
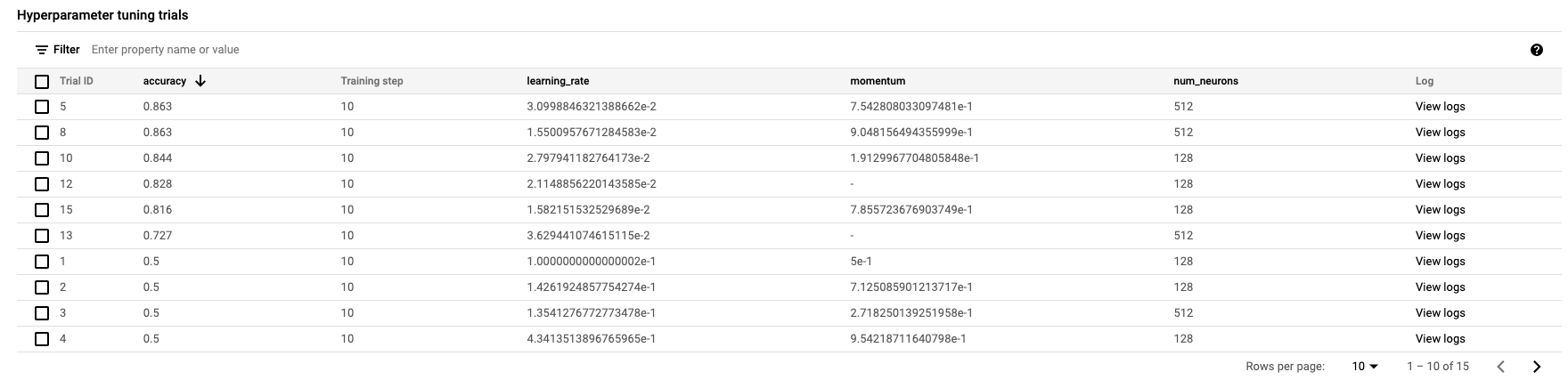
وقتی کار تمام شد، میتوانید روی نام کار کلیک کنید و نتایج آزمایشهای تنظیم را ببینید.
🎉 تبریک میگویم! 🎉
شما یاد گرفتید که چگونه از Vertex AI برای موارد زیر استفاده کنید:
- یک کار تنظیم هایپرپارامتر را برای کد آموزشی ارائه شده در یک کانتینر سفارشی اجرا کنید. شما در این مثال از یک مدل TensorFlow استفاده کردید، اما میتوانید مدلی را که با هر چارچوبی با استفاده از کانتینرهای سفارشی ساخته شده است، آموزش دهید.
برای کسب اطلاعات بیشتر در مورد بخشهای مختلف Vertex، مستندات آن را بررسی کنید.
۶. [اختیاری] استفاده از Vertex SDK
بخش قبلی نحوهی راهاندازی کار تنظیم هایپرپارامتر را از طریق رابط کاربری نشان داد. در این بخش، روش جایگزینی برای ارسال کار تنظیم هایپرپارامتر با استفاده از API پایتون Vertex مشاهده خواهید کرد.
از طریق Launcher، یک دفترچه یادداشت TensorFlow 2 ایجاد کنید.

Vertex AI SDK را وارد کنید.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
برای شروع کار تنظیم هایپرپارامتر، ابتدا باید مشخصات زیر را تعریف کنید. باید {PROJECT_ID} را در image_uri با پروژه خود جایگزین کنید.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
در مرحله بعد، یک CustomJob ایجاد کنید. برای مرحلهبندی، باید {YOUR_BUCKET} را با یک bucket در پروژه خود جایگزین کنید.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
سپس، HyperparameterTuningJob را ایجاد و اجرا کنید.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
۷. پاکسازی
از آنجا که نوتبوک را طوری پیکربندی کردهایم که پس از ۶۰ دقیقه بیکاری، زمان انقضا داشته باشد، نیازی نیست نگران خاموش کردن نمونه باشیم. اگر میخواهید نمونه را به صورت دستی خاموش کنید، روی دکمه Stop در بخش Vertex AI Workbench کنسول کلیک کنید. اگر میخواهید نوتبوک را به طور کامل حذف کنید، روی دکمه Delete کلیک کنید.

برای حذف Storage Bucket، با استفاده از منوی ناوبری در Cloud Console خود، به Storage بروید، Bucket خود را انتخاب کنید و روی Delete کلیک کنید: