1. खास जानकारी
इस लैब में, Vertex AI का इस्तेमाल करके, TensorFlow मॉडल के लिए हाइपरपैरामीटर ट्यूनिंग जॉब चलाया जाएगा. इस लैब में मॉडल कोड के लिए TensorFlow का इस्तेमाल किया गया है. हालांकि, ये कॉन्सेप्ट अन्य एमएल फ़्रेमवर्क पर भी लागू होते हैं.
आपको ये सब सीखने को मिलेगा
आपको, इनके बारे में जानकारी मिलेगी:
- ऑटोमेटेड हाइपरपैरामीटर ट्यूनिंग के लिए, ट्रेनिंग ऐप्लिकेशन कोड में बदलाव करना
- Vertex AI के यूज़र इंटरफ़ेस (यूआई) से, हाइपरपैरामीटर ट्यूनिंग जॉब को कॉन्फ़िगर करना और लॉन्च करना
- Vertex AI Python SDK की मदद से, हाइपरपैरामीटर ट्यूनिंग जॉब को कॉन्फ़िगर और लॉन्च करना
Google Cloud पर इस लैब को चलाने की कुल लागत करीब 300 रुपये है.
2. Vertex AI के बारे में जानकारी
इस लैब में, Google Cloud पर उपलब्ध एआई प्रॉडक्ट की नई सुविधा का इस्तेमाल किया जाता है. Vertex AI, Google Cloud के सभी एमएल प्रॉडक्ट को एक साथ इंटिग्रेट करता है, ताकि डेवलपर को बेहतर अनुभव मिल सके. पहले, AutoML और कस्टम मॉडल से ट्रेन किए गए मॉडल को अलग-अलग सेवाओं के ज़रिए ऐक्सेस किया जा सकता था. नए ऑफ़र में, इन दोनों को एक ही एपीआई में शामिल किया गया है. साथ ही, इसमें अन्य नए प्रॉडक्ट भी शामिल हैं. मौजूदा प्रोजेक्ट को भी Vertex AI पर माइग्रेट किया जा सकता है. अगर आपको कोई सुझाव देना है या शिकायत करनी है, तो कृपया सहायता पेज पर जाएं.
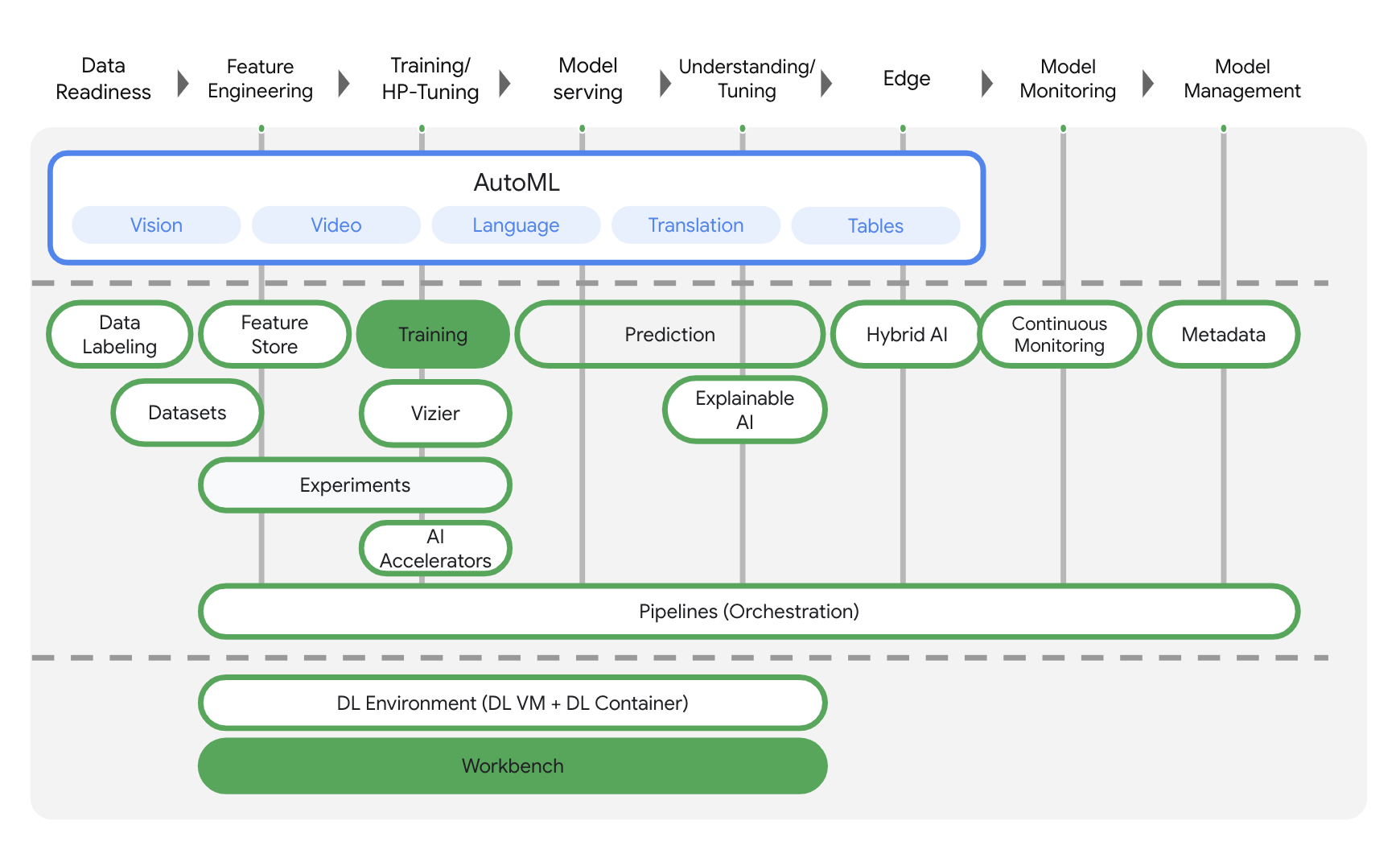
Vertex AI में कई अलग-अलग प्रॉडक्ट शामिल हैं, ताकि मशीन लर्निंग के वर्कफ़्लो को शुरू से लेकर आखिर तक सपोर्ट किया जा सके. इस लैब में, यहां हाइलाइट किए गए प्रॉडक्ट पर फ़ोकस किया जाएगा: ट्रेनिंग और वर्कबेंच.
3. अपना एनवायरमेंट सेट अप करना
इस कोडलैब को चलाने के लिए, आपके पास बिलिंग की सुविधा वाला Google Cloud Platform प्रोजेक्ट होना चाहिए. प्रोजेक्ट बनाने के लिए, यहां दिए गए निर्देशों का पालन करें.
पहला चरण: Compute Engine API चालू करना
Compute Engine पर जाएं. अगर यह पहले से चालू नहीं है, तो चालू करें को चुनें. आपको नोटबुक इंस्टेंस बनाने के लिए इसकी ज़रूरत होगी.
दूसरा चरण: Container Registry API चालू करना
Container Registry पर जाएं. अगर यह पहले से चालू नहीं है, तो चालू करें को चुनें. इसका इस्तेमाल, कस्टम ट्रेनिंग जॉब के लिए कंटेनर बनाने के लिए किया जाएगा.
तीसरा चरण: Vertex AI API चालू करना
Cloud Console के Vertex AI सेक्शन पर जाएं और Vertex AI API चालू करें पर क्लिक करें.
चौथा चरण: Vertex AI Workbench इंस्टेंस बनाना
Cloud Console के Vertex AI सेक्शन में जाकर, Workbench पर क्लिक करें:
अगर Notebooks API पहले से चालू नहीं है, तो इसे चालू करें.
चालू होने के बाद, मैनेज की गई नोटबुक पर क्लिक करें:

इसके बाद, नई नोटबुक चुनें.
अपनी नोटबुक को कोई नाम दें. इसके बाद, बेहतर सेटिंग पर क्लिक करें.

ऐडवांस सेटिंग में जाकर, डिवाइस के बंद होने की सुविधा चालू करें. इसके बाद, डिवाइस के बंद होने का समय 60 मिनट पर सेट करें. इसका मतलब है कि इस्तेमाल न किए जाने पर, आपकी नोटबुक अपने-आप बंद हो जाएगी, ताकि आपको बिना वजह शुल्क न देना पड़े.

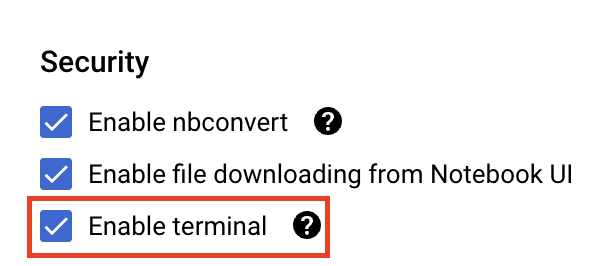
अगर सुरक्षा में जाकर "टर्मिनल चालू करें" विकल्प पहले से चालू नहीं है, तो इसे चालू करें.
अन्य सभी ऐडवांस सेटिंग को डिफ़ॉल्ट रूप से सेट रहने दें.
इसके बाद, बनाएं पर क्लिक करें. इंस्टेंस को चालू होने में कुछ मिनट लगेंगे.
इंस्टेंस बन जाने के बाद, JupyterLab खोलें को चुनें.

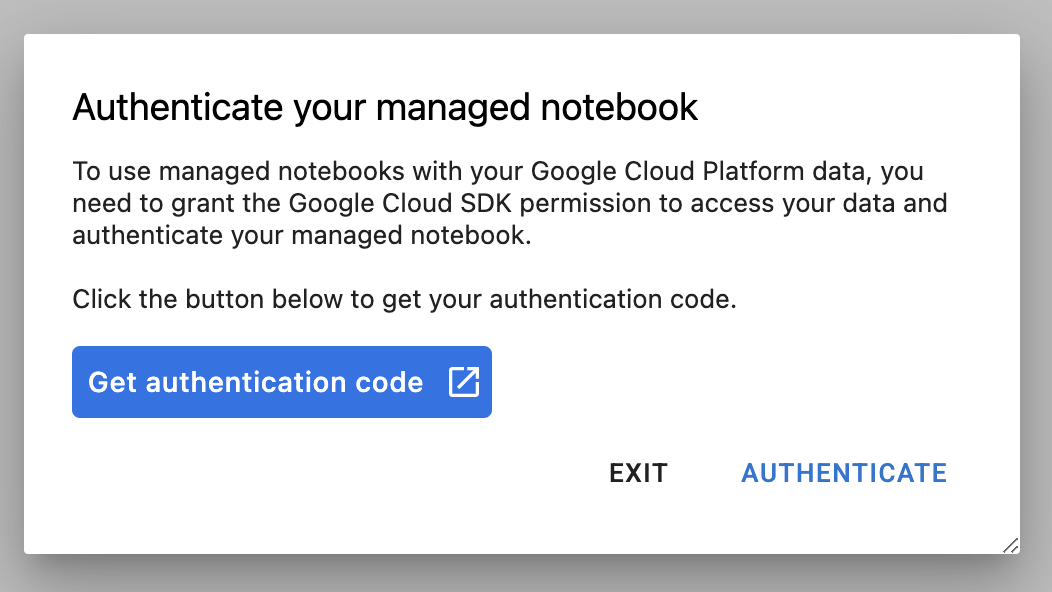
पहली बार किसी नए इंस्टेंस का इस्तेमाल करते समय, आपसे पुष्टि करने के लिए कहा जाएगा. इसके लिए, यूज़र इंटरफ़ेस (यूआई) में दिया गया तरीका अपनाएं.
4. ट्रेनिंग ऐप्लिकेशन कोड को कंटेनर में रखना
इस लैब में, आपको जिस मॉडल को ट्रेन और ट्यून करना है वह इमेज क्लासिफ़िकेशन मॉडल है. इसे TensorFlow Datasets के घोड़ों या इंसानों के डेटासेट पर ट्रेन किया गया है.
आपको इस हाइपरपैरामीटर ट्यूनिंग जॉब को Vertex AI में सबमिट करना होगा. इसके लिए, आपको अपने ट्रेनिंग ऐप्लिकेशन कोड को Docker कंटेनर में डालना होगा. इसके बाद, इस कंटेनर को Google Container Registry में पुश करना होगा. इस तरीके का इस्तेमाल करके, किसी भी फ़्रेमवर्क की मदद से बनाए गए मॉडल के लिए हाइपरपैरामीटर को ट्यून किया जा सकता है.
शुरू करने के लिए, लॉन्चर मेन्यू से अपने नोटबुक इंस्टेंस में टर्मिनल विंडो खोलें:

horses_or_humans नाम की नई डायरेक्ट्री बनाएं और उसमें cd करें:
mkdir horses_or_humans
cd horses_or_humans
पहला चरण: Dockerfile बनाना
अपने कोड को कंटेनर में रखने के लिए, सबसे पहले Dockerfile बनाएं. Dockerfile में, इमेज को चलाने के लिए ज़रूरी सभी कमांड शामिल करें. यह CloudML Hypertune लाइब्रेरी के साथ-साथ सभी ज़रूरी लाइब्रेरी इंस्टॉल करेगा. साथ ही, ट्रेनिंग कोड के लिए एंट्री पॉइंट सेट अप करेगा.
अपने टर्मिनल में, एक खाली Dockerfile बनाएं:
touch Dockerfile
Dockerfile खोलें और इसमें यह कोड कॉपी करें:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
इस Dockerfile में, Deep Learning Container TensorFlow Enterprise 2.7 GPU Docker इमेज का इस्तेमाल किया गया है. Google Cloud पर मौजूद डीप लर्निंग कंटेनर में, एमएल और डेटा साइंस के कई सामान्य फ़्रेमवर्क पहले से इंस्टॉल होते हैं. उस इमेज को डाउनलोड करने के बाद, यह Dockerfile ट्रेनिंग कोड के लिए एंट्रीपॉइंट सेट अप करता है. आपने अब तक ये फ़ाइलें नहीं बनाई हैं. अगले चरण में, आपको मॉडल को ट्रेनिंग देने और उसे बेहतर बनाने के लिए कोड जोड़ना होगा.
दूसरा चरण: मॉडल ट्रेनिंग कोड जोड़ना
टर्मिनल से, ट्रेनिंग कोड के लिए डायरेक्ट्री बनाने और Python फ़ाइल बनाने के लिए, यहाँ दिया गया कोड चलाएँ. इस फ़ाइल में आपको कोड जोड़ना होगा:
mkdir trainer
touch trainer/task.py
अब आपकी horses_or_humans/ डायरेक्ट्री में ये फ़ाइलें होनी चाहिए:
+ Dockerfile
+ trainer/
+ task.py
इसके बाद, अभी बनाई गई task.py फ़ाइल खोलें और नीचे दिया गया कोड कॉपी करें.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
कंटेनर बनाने से पहले, आइए कोड के बारे में ज़्यादा जानकारी देखें. हाइपरपैरामीटर ट्यूनिंग सेवा का इस्तेमाल करने के लिए, कुछ कॉम्पोनेंट ज़रूरी होते हैं.
- यह स्क्रिप्ट,
hypertuneलाइब्रेरी को इंपोर्ट करती है. ध्यान दें कि पहले चरण के Dockerfile में, इस लाइब्रेरी को pip install करने के निर्देश शामिल थे. get_args()फ़ंक्शन, हर उस हाइपरपैरामीटर के लिए कमांड-लाइन आर्ग्युमेंट तय करता है जिसे आपको ट्यून करना है. इस उदाहरण में, जिन हाइपरपैरामीटर को ट्यून किया जाएगा वे हैं लर्निंग रेट, ऑप्टिमाइज़र में मोमेंटम वैल्यू, और मॉडल की आखिरी हिडन लेयर में यूनिट की संख्या. हालांकि, आपके पास अन्य हाइपरपैरामीटर के साथ एक्सपेरिमेंट करने का विकल्प भी है. इसके बाद, उन आर्ग्युमेंट में पास की गई वैल्यू का इस्तेमाल, कोड में उससे जुड़े हाइपरपैरामीटर को सेट करने के लिए किया जाता है.main()फ़ंक्शन के आखिर में,hypertuneलाइब्रेरी का इस्तेमाल करके उस मेट्रिक को तय किया जाता है जिसे आपको ऑप्टिमाइज़ करना है. TensorFlow में, kerasmodel.fitतरीका,Historyऑब्जेक्ट दिखाता है.History.historyएट्रिब्यूट, ट्रेनिंग के दौरान हुए नुकसान की वैल्यू और लगातार होने वाले इपॉक में मेट्रिक की वैल्यू का रिकॉर्ड होता है. अगर आपने पुष्टि करने से जुड़ा डेटाmodel.fitएट्रिब्यूट को भेजा है, तोHistory.historyएट्रिब्यूट में पुष्टि करने से होने वाले नुकसान और मेट्रिक की वैल्यू भी शामिल होंगी. उदाहरण के लिए, अगर आपने पुष्टि करने के लिए इस्तेमाल किए गए डेटा के साथ तीन इपोक के लिए किसी मॉडल को ट्रेन किया है औरaccuracyको मेट्रिक के तौर पर दिया है, तोaccuracyएट्रिब्यूट, इस डिक्शनरी की तरह दिखेगा.History.history
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
अगर आपको हाइपरपैरामीटर ट्यूनिंग सेवा को ऐसी वैल्यू का पता लगाने के लिए कहना है जिनसे मॉडल की पुष्टि करने की सटीकता को ज़्यादा से ज़्यादा किया जा सके, तो मेट्रिक को val_accuracy सूची की आखिरी एंट्री (या NUM_EPOCS - 1) के तौर पर तय करें. इसके बाद, इस मेट्रिक को HyperTune के किसी इंस्टेंस पर पास करें. hyperparameter_metric_tag के लिए, अपनी पसंद की कोई भी स्ट्रिंग चुनी जा सकती है. हालांकि, हाइपरपैरामीटर ट्यूनिंग का काम शुरू करते समय, आपको इस स्ट्रिंग का फिर से इस्तेमाल करना होगा.
तीसरा चरण: कंटेनर बनाना
अपने टर्मिनल से, अपने प्रोजेक्ट के लिए एनवायरमेंट वैरिएबल तय करने के लिए, यहां दिया गया कमांड चलाएं. साथ ही, यह पक्का करें कि आपने your-cloud-project की जगह अपने प्रोजेक्ट का आईडी डाला हो:
PROJECT_ID='your-cloud-project'
Google Container Registry में, अपने कंटेनर इमेज के यूआरआई के साथ एक वैरिएबल तय करें:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Docker को कॉन्फ़िगर करना
gcloud auth configure-docker
इसके बाद, horses_or_humans डायरेक्ट्री के रूट से यह कमांड चलाकर कंटेनर बनाएं:
docker build ./ -t $IMAGE_URI
आखिर में, इसे Google Container Registry पर पुश करें:
docker push $IMAGE_URI
कंटेनर को Container Registry में पुश करने के बाद, अब कस्टम मॉडल के हाइपरपैरामीटर को ट्यून करने का काम शुरू किया जा सकता है.
5. Vertex AI पर हाइपरपैरामीटर ट्यूनिंग का काम पूरा करना
इस लैब में, Google Container Registry पर मौजूद कस्टम कंटेनर की मदद से कस्टम ट्रेनिंग का इस्तेमाल किया गया है. हालांकि, Vertex AI के पहले से बने कंटेनर की मदद से, हाइपरपैरामीटर ट्यूनिंग का काम भी किया जा सकता है.
शुरू करने के लिए, Cloud Console के Vertex सेक्शन में मौजूद ट्रेनिंग सेक्शन पर जाएं:
पहला चरण: ट्रेनिंग जॉब कॉन्फ़िगर करना
हाइपरपैरामीटर ट्यूनिंग जॉब के लिए पैरामीटर डालने के लिए, बनाएं पर क्लिक करें.
- डेटासेट में जाकर, कोई मैनेज किया गया डेटासेट नहीं चुनें
- इसके बाद, ट्रेनिंग के तरीके के तौर पर कस्टम ट्रेनिंग (ऐडवांस) चुनें और जारी रखें पर क्लिक करें.
- मॉडल का नाम के लिए,
horses-humans-hyptertuneडालें. इसके अलावा, अपने मॉडल के लिए कोई भी नाम डाला जा सकता है - जारी रखें पर क्लिक करें
कंटेनर की सेटिंग वाले चरण में, कस्टम कंटेनर चुनें:

पहले बॉक्स (कंटेनर इमेज) में, पिछले सेक्शन से अपने IMAGE_URI वैरिएबल की वैल्यू डालें. यह gcr.io/your-cloud-project/horse-human:hypertune होना चाहिए. इसमें आपके प्रोजेक्ट का नाम होना चाहिए. बाकी फ़ील्ड को खाली छोड़ दें और जारी रखें पर क्लिक करें.
दूसरा चरण: हाइपरपैरामीटर ट्यूनिंग जॉब कॉन्फ़िगर करना
हाइपरपैरामीटर ट्यूनिंग चालू करें को चुनें.
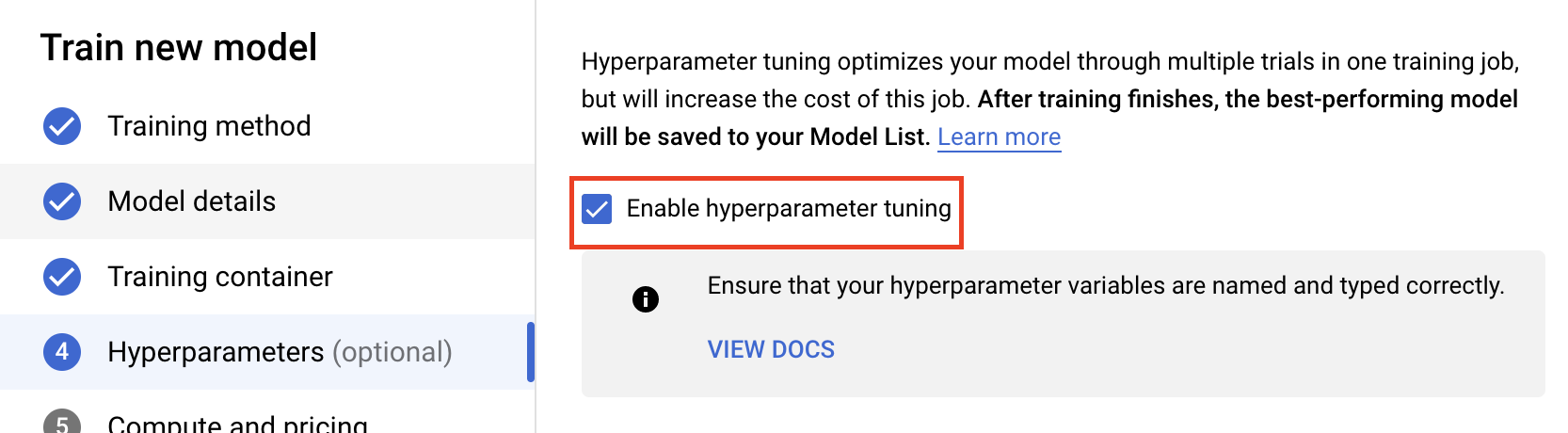
हाइपरपैरामीटर कॉन्फ़िगर करना
इसके बाद, आपको उन हाइपरपैरामीटर को जोड़ना होगा जिन्हें आपने ट्रेनिंग ऐप्लिकेशन कोड में कमांड लाइन आर्ग्युमेंट के तौर पर सेट किया है. हाइपरपैरामीटर जोड़ते समय, आपको सबसे पहले उसका नाम देना होगा. यह उस आर्ग्युमेंट के नाम से मेल खाना चाहिए जिसे आपने argparse में पास किया है.

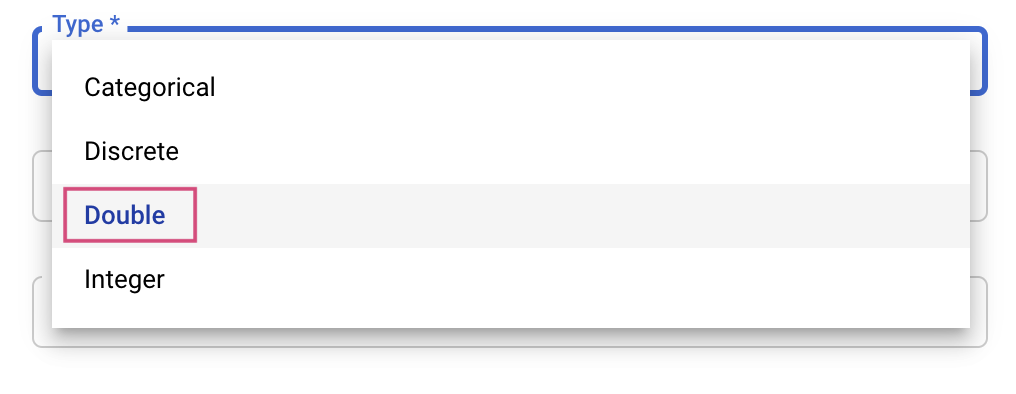
इसके बाद, आपको टाइप के साथ-साथ उन वैल्यू की सीमाएं चुननी होंगी जिनके लिए ट्यूनिंग सेवा कोशिश करेगी. डबल या पूर्णांक टाइप चुनने पर, आपको कम से कम और ज़्यादा से ज़्यादा वैल्यू देनी होगी. अगर आपने कैटगरी के हिसाब से या अलग-अलग वैल्यू चुनी हैं, तो आपको वैल्यू देनी होंगी.

डबल और पूर्णांक टाइप के लिए, आपको स्केलिंग वैल्यू भी देनी होगी.
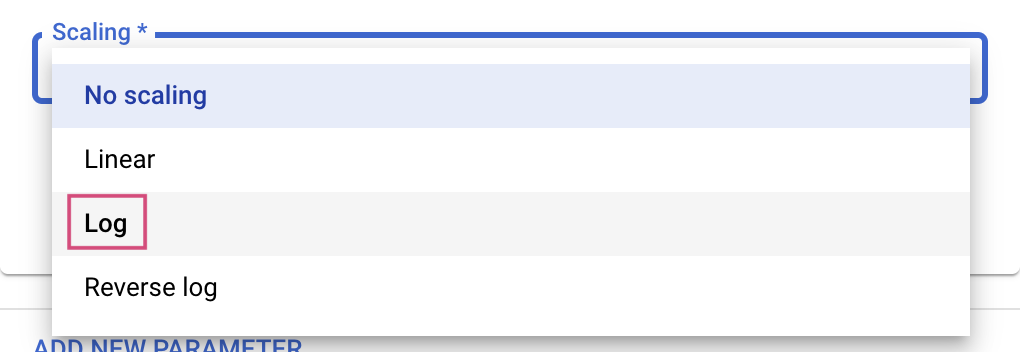
learning_rate हाइपरपैरामीटर जोड़ने के बाद, momentum और num_units के लिए पैरामीटर जोड़ें.


मेट्रिक कॉन्फ़िगर करना
हाइपरपैरामीटर जोड़ने के बाद, आपको वह मेट्रिक और लक्ष्य देना होगा जिसे ऑप्टिमाइज़ करना है. यह वही hyperparameter_metric_tag होना चाहिए जिसे आपने ट्रेनिंग के लिए आवेदन करते समय सेट किया था.
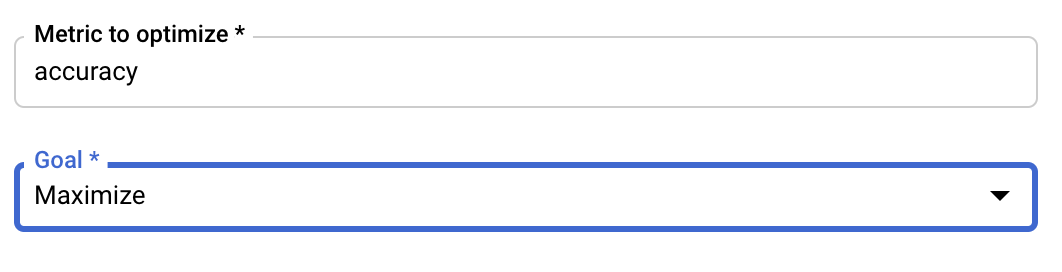
Vertex AI की हाइपरपैरामीटर ट्यूनिंग सेवा, आपके ट्रेनिंग ऐप्लिकेशन के कई ट्रायल चलाएगी. इसके लिए, पिछले चरणों में कॉन्फ़िगर की गई वैल्यू का इस्तेमाल किया जाएगा. आपको यह तय करना होगा कि सेवा कितने ट्रायल चलाएगी. आम तौर पर, ज़्यादा ट्रायल करने से बेहतर नतीजे मिलते हैं. हालांकि, एक समय के बाद ट्रायल करने से कोई फ़ायदा नहीं होता. इसके बाद, ज़्यादा ट्रायल करने से उस मेट्रिक पर कोई असर नहीं पड़ता जिसे ऑप्टिमाइज़ करने की कोशिश की जा रही है. सबसे सही तरीका यह है कि कम संख्या में ट्रायल से शुरुआत की जाए. इससे आपको यह पता चल जाएगा कि चुने गए हाइपरपैरामीटर कितने असरदार हैं. इसके बाद, ज़्यादा संख्या में ट्रायल किए जा सकते हैं.
आपको पैरलल ट्रायल की संख्या की ऊपरी सीमा भी सेट करनी होगी. एक साथ कई ट्रायल चलाने से, हाइपरपैरामीटर ट्यूनिंग जॉब को पूरा होने में कम समय लगेगा. हालांकि, इससे जॉब की परफ़ॉर्मेंस पर असर पड़ सकता है. ऐसा इसलिए होता है, क्योंकि डिफ़ॉल्ट ट्यूनिंग की रणनीति में, पिछले ट्रायल के नतीजों का इस्तेमाल किया जाता है. इससे आने वाले ट्रायल में वैल्यू असाइन करने के बारे में जानकारी मिलती है. अगर एक साथ कई ट्रायल चलाए जाते हैं, तो कुछ ट्रायल ऐसे होंगे जो अब भी चल रहे ट्रायल के नतीजों के फ़ायदे के बिना शुरू हो जाएंगे.
डेमो के लिए, आज़माने की संख्या 15 और एक साथ आज़माए जाने वाले वर्शन की ज़्यादा से ज़्यादा संख्या 3 पर सेट की जा सकती है. अलग-अलग नंबरों के साथ एक्सपेरिमेंट किया जा सकता है. हालांकि, इससे ट्यूनिंग में ज़्यादा समय लग सकता है और लागत भी बढ़ सकती है.

आखिरी चरण में, सर्च एल्गोरिदम के तौर पर डिफ़ॉल्ट को चुनें. इससे हाइपरपैरामीटर ट्यूनिंग के लिए, बेज़ियन ऑप्टिमाइज़ेशन करने के लिए Google Vizier का इस्तेमाल किया जाएगा. इस एल्गोरिदम के बारे में ज़्यादा जानने के लिए, यहां जाएं.
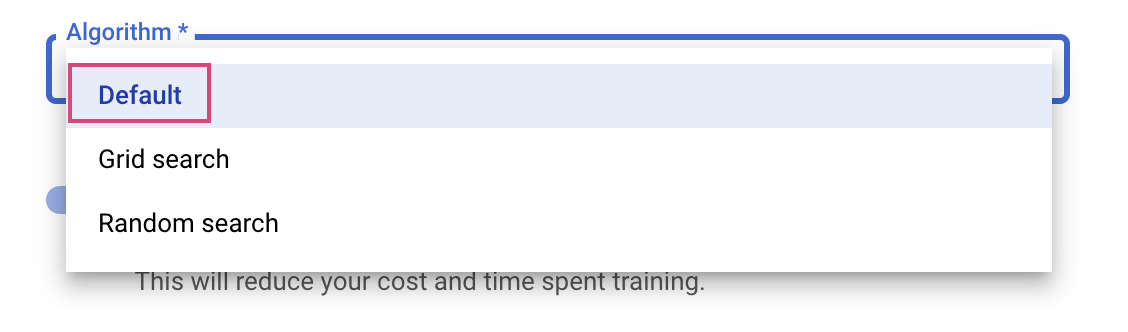
जारी रखें पर क्लिक करें.
तीसरा चरण: कंप्यूट कॉन्फ़िगर करना
कंप्यूट और कीमत में, चुने गए क्षेत्र को वैसे ही रहने दें और वर्कर पूल 0 को इस तरह कॉन्फ़िगर करें.
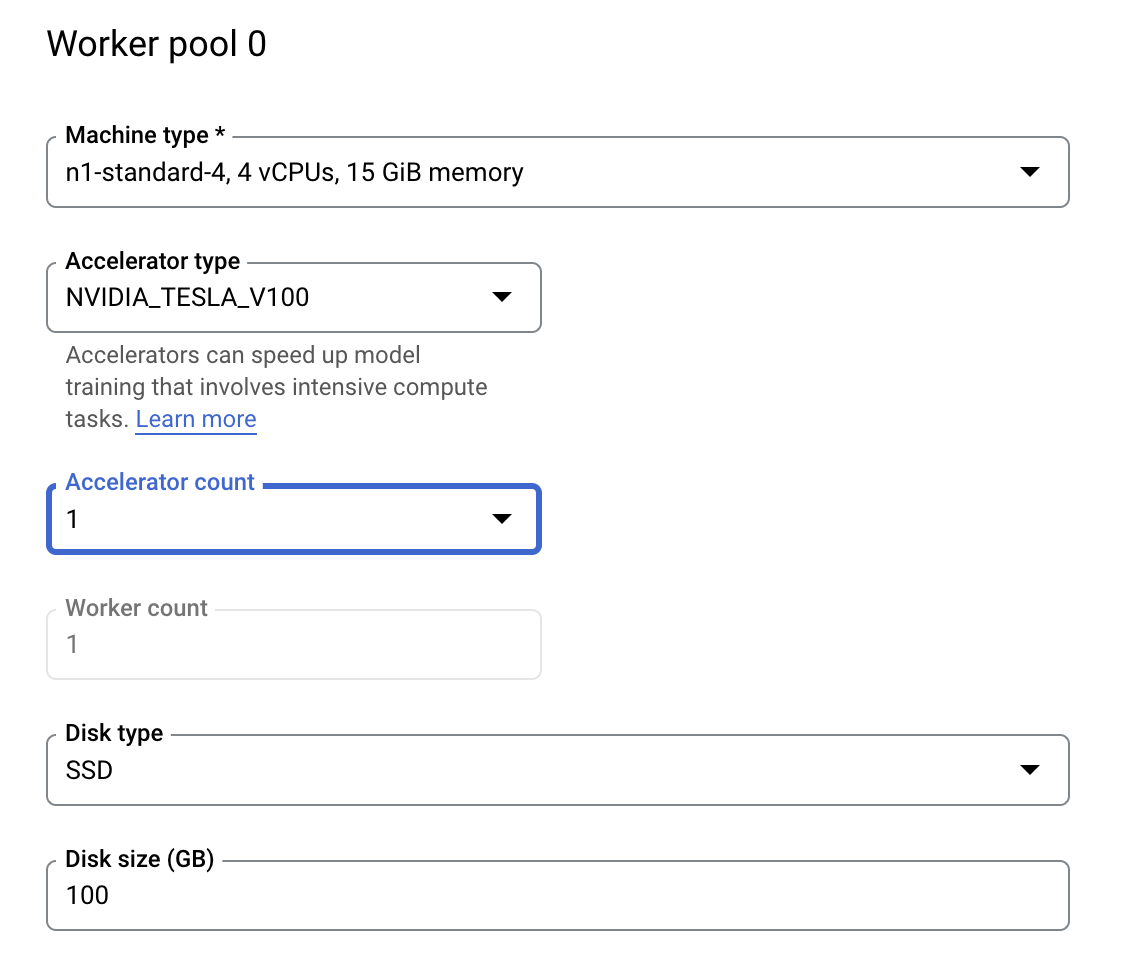
हाइपरपैरामीटर ट्यूनिंग का काम शुरू करने के लिए, ट्रेनिंग शुरू करें पर क्लिक करें. आपको अपनी कंसोल के ट्रेनिंग सेक्शन में, हाइपरपैरामीटर ट्यूनिंग जॉब टैब में कुछ ऐसा दिखेगा:
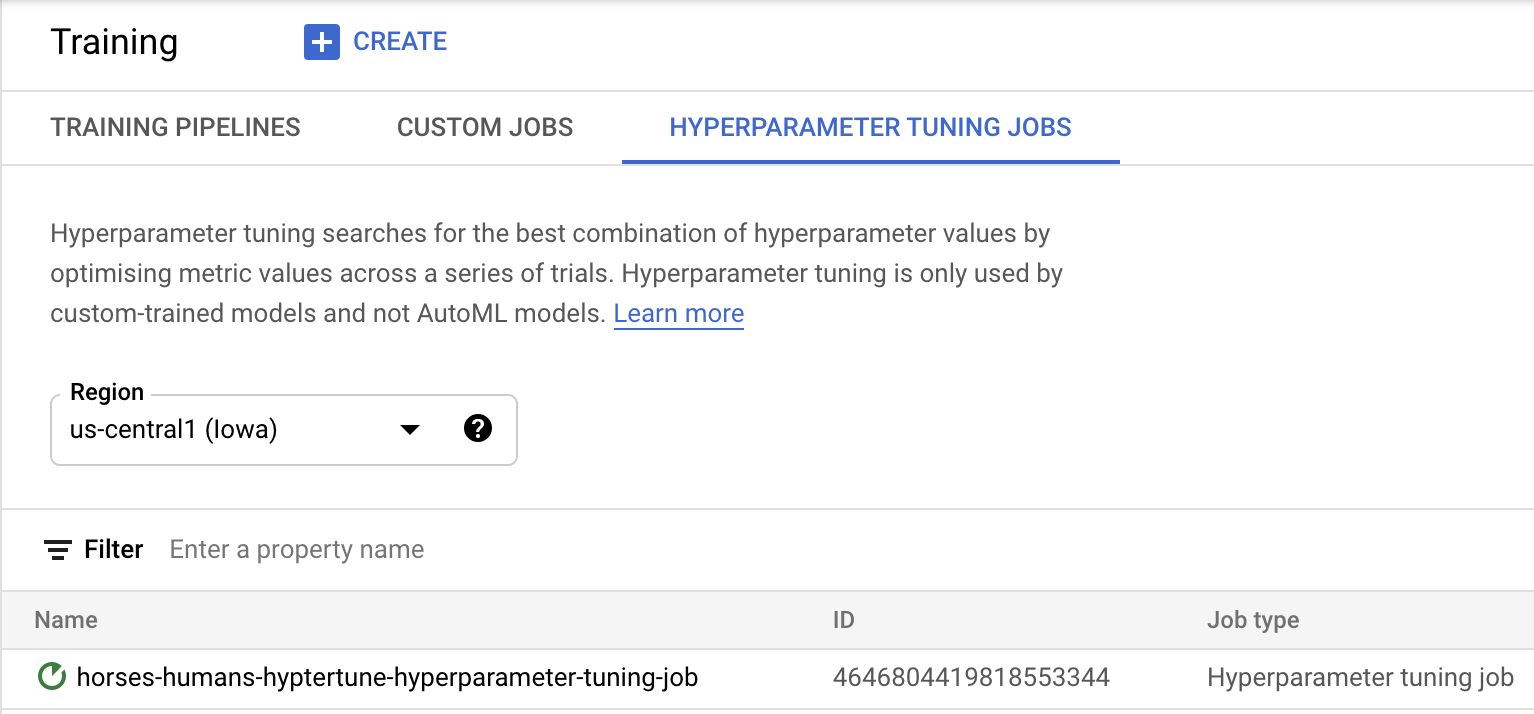
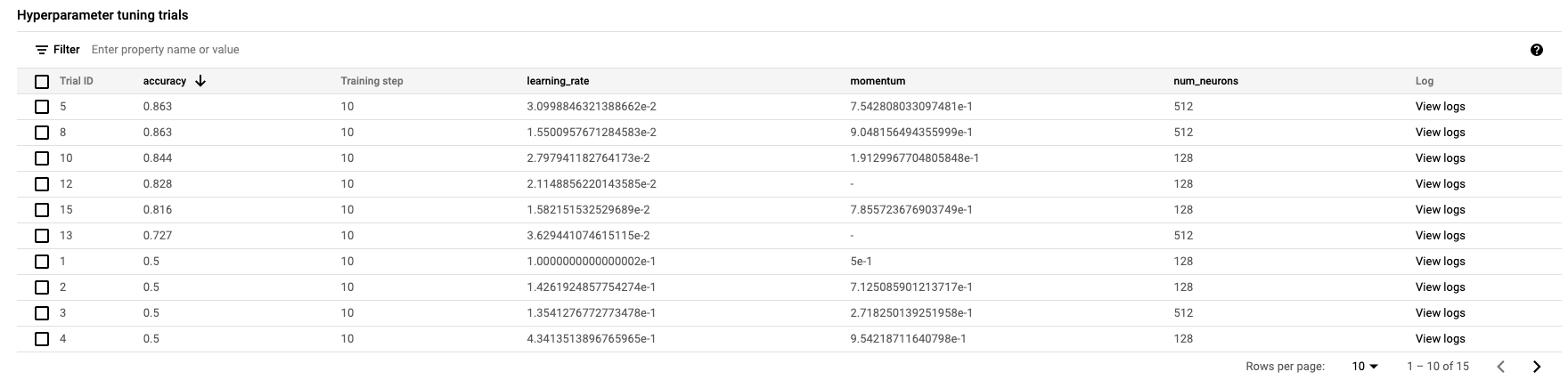
इसके पूरा होने पर, नौकरी के नाम पर क्लिक करके ट्यूनिंग के ट्रायल के नतीजे देखे जा सकेंगे.
🎉 बधाई हो! 🎉
आपने Vertex AI का इस्तेमाल करके ये काम करने का तरीका सीखा है:
- कस्टम कंटेनर में दिए गए ट्रेनिंग कोड के लिए, हाइपरपैरामीटर ट्यूनिंग जॉब लॉन्च करें. इस उदाहरण में, TensorFlow मॉडल का इस्तेमाल किया गया है. हालांकि, कस्टम कंटेनर का इस्तेमाल करके, किसी भी फ़्रेमवर्क से बनाए गए मॉडल को ट्रेन किया जा सकता है.
Vertex के अलग-अलग हिस्सों के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
6. [ज़रूरी नहीं] Vertex SDK का इस्तेमाल करना
पिछले सेक्शन में, यूज़र इंटरफ़ेस (यूआई) के ज़रिए हाइपरपैरामीटर ट्यूनिंग जॉब लॉन्च करने का तरीका बताया गया था. इस सेक्शन में, Vertex Python API का इस्तेमाल करके, हाइपरपैरामीटर ट्यूनिंग जॉब सबमिट करने का दूसरा तरीका बताया गया है.
लॉन्चर से, TensorFlow 2 नोटबुक बनाएं.

Vertex AI SDK इंपोर्ट करें.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
हाइपरपैरामीटर ट्यूनिंग की प्रोसेस शुरू करने के लिए, आपको सबसे पहले यहां दी गई खास बातें तय करनी होंगी. आपको image_uri में मौजूद {PROJECT_ID} को अपने प्रोजेक्ट से बदलना होगा.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
इसके बाद, CustomJob बनाएं. आपको {YOUR_BUCKET} की जगह, अपने प्रोजेक्ट में मौजूद किसी बकेट का इस्तेमाल करना होगा.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
इसके बाद, HyperparameterTuningJob बनाएं और उसे चलाएं.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. साफ़-सफ़ाई सेवा
हमने नोटबुक को 60 मिनट तक इस्तेमाल न किए जाने पर टाइम आउट होने के लिए कॉन्फ़िगर किया है. इसलिए, हमें इंस्टेंस को बंद करने की ज़रूरत नहीं है. अगर आपको इंस्टेंस को मैन्युअल तरीके से बंद करना है, तो कंसोल के Vertex AI Workbench सेक्शन में जाकर, Stop बटन पर क्लिक करें. अगर आपको नोटबुक पूरी तरह से मिटानी है, तो 'मिटाएं' बटन पर क्लिक करें.

स्टोरेज बकेट को मिटाने के लिए, Cloud Console में नेविगेशन मेन्यू का इस्तेमाल करके, स्टोरेज पर जाएं. इसके बाद, अपनी बकेट चुनें और मिटाएं पर क्लिक करें: