1. Ringkasan
Di lab ini, Anda akan menggunakan Vertex AI untuk menjalankan tugas penyesuaian hyperparameter untuk model TensorFlow. Meskipun lab ini menggunakan TensorFlow sebagai kode model, konsepnya juga berlaku untuk framework ML lainnya.
Yang Anda pelajari
Anda akan mempelajari cara:
- Mengubah kode aplikasi pelatihan untuk penyesuaian hyperparameter otomatis.
- Mengonfigurasi dan meluncurkan tugas penyesuaian hyperparameter dari UI Vertex AI
- Mengonfigurasi dan meluncurkan tugas penyelesaian hyperparameter dengan Vertex AI Python SDK
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $3 USD.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI. Jika Anda memiliki masukan, harap lihat halaman dukungan.
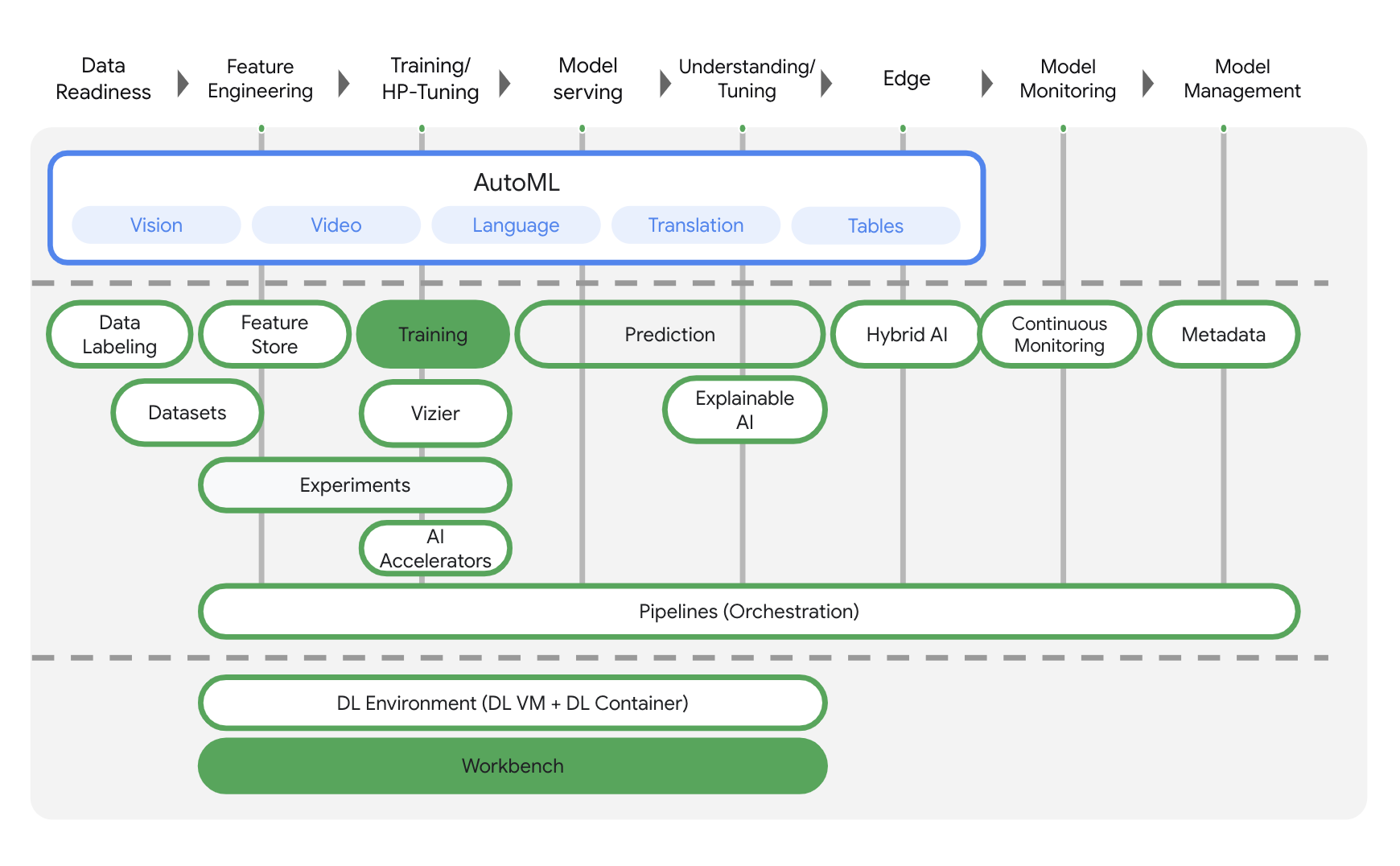
Vertex AI mencakup banyak produk yang berbeda untuk mendukung alur kerja ML secara menyeluruh. Lab ini akan berfokus pada produk yang disorot di bawah: Training dan Workbench.
3. Menyiapkan lingkungan Anda
Anda memerlukan project Google Cloud Platform dengan penagihan yang diaktifkan untuk menjalankan codelab ini. Untuk membuat project, ikuti petunjuk di sini.
Langkah 1: Aktifkan Compute Engine API
Buka Compute Engine dan pilih Aktifkan jika belum diaktifkan. Anda akan memerlukan ini untuk membuat instance notebook.
Langkah 2: Aktifkan Container Registry API
Buka Container Registry dan pilih Aktifkan jika belum melakukannya. Anda akan menggunakannya untuk membuat container tugas pelatihan kustom.
Langkah 3: Aktifkan Vertex AI API
Buka bagian Vertex AI di Cloud Console Anda, lalu klik Aktifkan Vertex AI API.
Langkah 4: Buat instance Vertex AI Workbench
Dari bagian Vertex AI di Cloud Console Anda, klik Workbench:
Aktifkan Notebooks API jika belum diaktifkan.
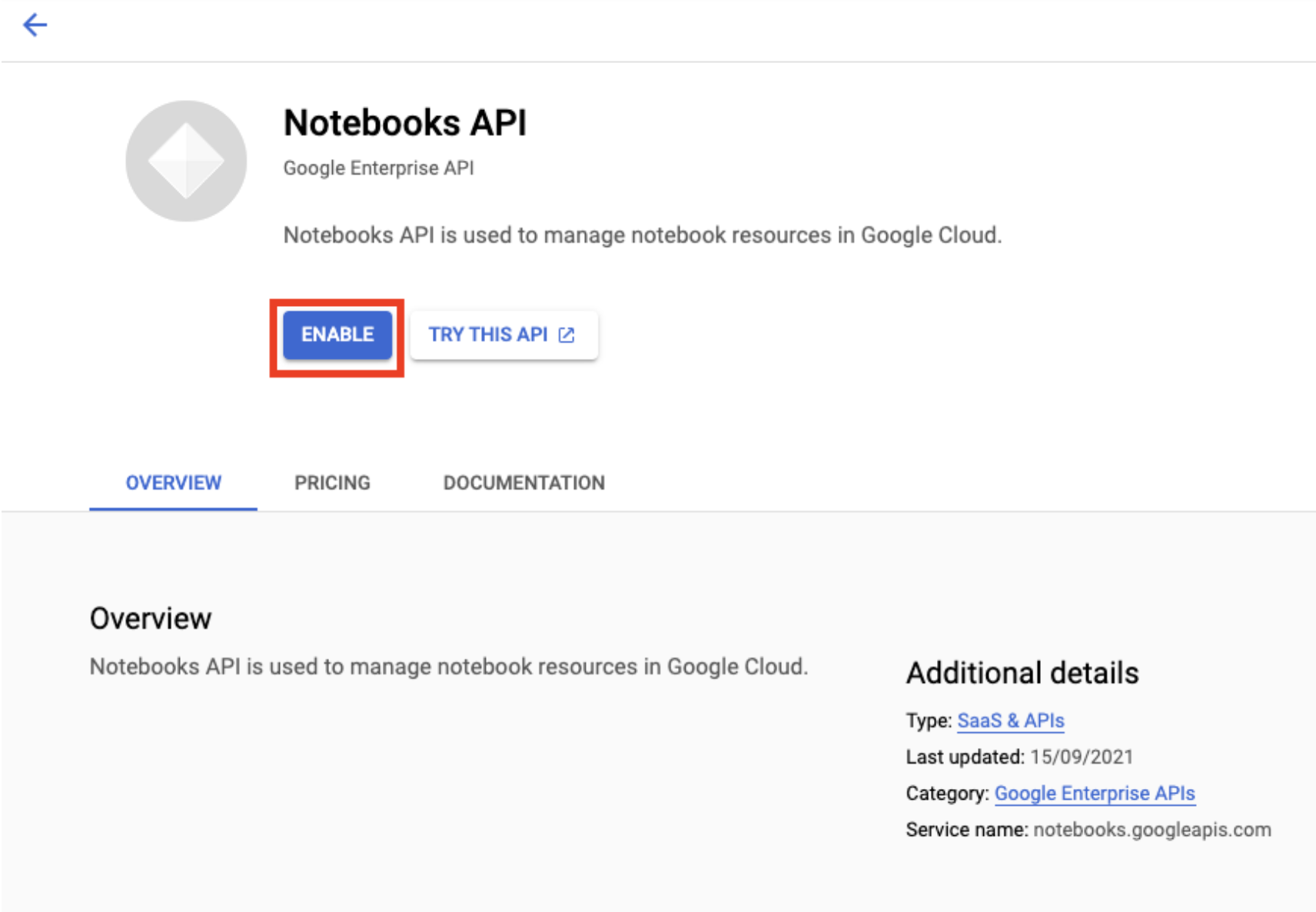
Setelah diaktifkan, klik NOTEBOOK TERKELOLA:

Kemudian, pilih NOTEBOOK BARU.
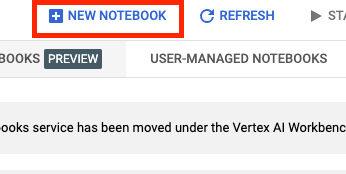
Beri nama notebook Anda, lalu klik Setelan Lanjutan.

Di bagian Setelan Lanjutan, aktifkan penonaktifan tidak ada aktivitas dan setel jumlah menit ke 60. Artinya, notebook Anda akan otomatis dinonaktifkan saat tidak digunakan agar tidak menimbulkan biaya tambahan.

Di bagian Keamanan, pilih "Aktifkan terminal" jika belum diaktifkan.
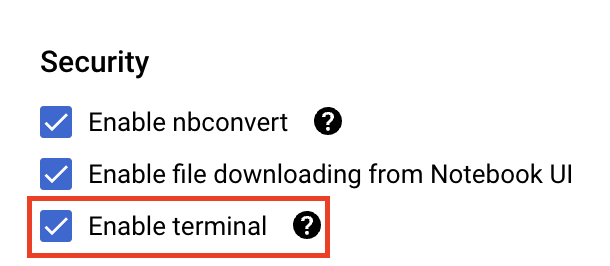
Anda dapat membiarkan semua setelan lanjutan lainnya apa adanya.
Selanjutnya, klik Buat. Instance akan memerlukan waktu beberapa menit untuk disediakan.
Setelah instance dibuat, pilih Buka JupyterLab.

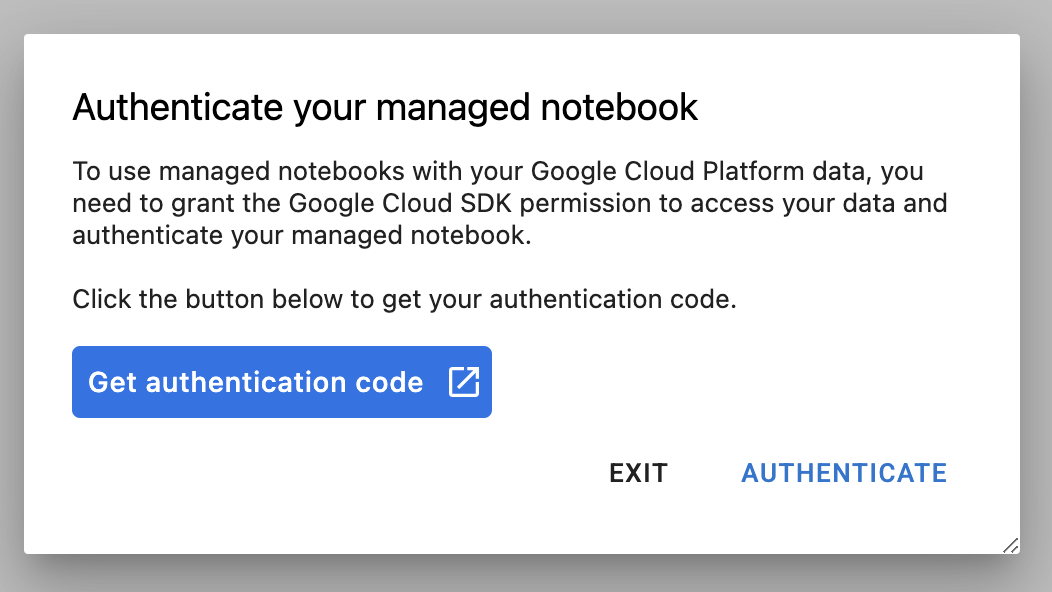
Saat pertama kali menggunakan instance baru, Anda akan diminta untuk mengautentikasi. Ikuti langkah-langkah di UI untuk melakukannya.
4. Menyimpan kode aplikasi pelatihan dalam container
Model yang akan Anda latih dan sesuaikan di lab ini adalah model klasifikasi gambar yang dilatih di set data kuda atau manusia dari Set Data TensorFlow.
Anda akan mengirim tugas penyesuaian hyperparameter ini ke Vertex AI dengan menempatkan kode aplikasi pelatihan dalam container Docker dan mengirim container ini ke Google Container Registry. Dengan pendekatan ini, Anda dapat menyesuaikan hyperparameter untuk model yang dibangun dengan framework apa pun.
Untuk memulai, dari menu Peluncur, buka jendela Terminal di instance notebook Anda:

Buat direktori baru bernama horses_or_humans dan cd ke dalamnya:
mkdir horses_or_humans
cd horses_or_humans
Langkah 1: Buat Dockerfile
Langkah pertama untuk mem-build kode dalam container adalah membuat Dockerfile. Dalam Dockerfile, Anda akan menyertakan semua perintah yang diperlukan untuk menjalankan image. Tindakan ini akan menginstal semua library yang diperlukan, termasuk library CloudML Hypertune, dan menyiapkan titik entri untuk kode pelatihan.
Dari Terminal Anda, buat Dockerfile kosong:
touch Dockerfile
Buka Dockerfile dan salin kode berikut ke dalamnya:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Dockerfile ini menggunakan image Docker GPU Deep Learning Container TensorFlow Enterprise 2.7. Deep Learning Containers di Google Cloud dilengkapi dengan banyak ML umum dan framework data science yang diiinstal sebelumnya. Setelah mendownload image tersebut, Dockerfile ini akan menyiapkan titik entri untuk kode pelatihan. Anda belum membuat file ini – pada langkah berikutnya, Anda akan menambahkan kode untuk melatih dan menyetel model.
Langkah 2: Tambahkan kode pelatihan model
Dari Terminal, jalankan perintah berikut guna membuat direktori untuk kode pelatihan dan file Python tempat Anda akan menambahkan kodenya:
mkdir trainer
touch trainer/task.py
Sekarang Anda akan memiliki kode berikut di direktori horses_or_humans/ Anda:
+ Dockerfile
+ trainer/
+ task.py
Selanjutnya, buka file task.py yang baru saja Anda buat dan salin kode di bawah.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Sebelum Anda mem-build container, mari pelajari lebih lanjut kode tersebut. Ada beberapa komponen yang spesifik untuk penggunaan layanan penyesuaian hyperparameter.
- Skrip ini akan mengimpor library
hypertune. Perhatikan bahwa Dockerfile dari Langkah 1 menyertakan petunjuk untuk menginstal library ini menggunakan pip. - Fungsi
get_args()menentukan argumen command line untuk setiap hyperparameter yang ingin Anda sesuaikan. Dalam contoh ini, hyperparameter yang akan disesuaikan adalah kecepatan pembelajaran, nilai momentum dalam pengoptimal, dan jumlah unit dalam lapisan tersembunyi terakhir dari model, tetapi jangan ragu untuk bereksperimen menggunakan yang lainnya. Nilai yang diteruskan dalam argumen tersebut kemudian akan digunakan untuk menetapkan hyperparameter yang sesuai dalam kode. - Di bagian akhir fungsi
main(), libraryhypertunedigunakan untuk menentukan metrik yang ingin Anda optimalkan. Di TensorFlow, metodemodel.fitKeras akan menampilkan objekHistory. AtributHistory.historyadalah data nilai kerugian pelatihan dan nilai metrik pada iterasi pelatihan berturut-turut. Jika Anda meneruskan data validasi kemodel.fit, atributHistory.historyjuga akan menyertakan nilai metrik dan kerugian validasi. Misalnya, jika Anda melatih model untuk tiga iterasi pelatihan dengan data validasi dan memberikanaccuracysebagai metrik, atributHistory.historyakan terlihat mirip dengan kamus berikut.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Jika Anda ingin layanan penyesuaian hyperparameter menemukan nilai yang memaksimalkan akurasi validasi model, Anda perlu menentukan metrik sebagai entri terakhir (atau NUM_EPOCS - 1) dari daftar val_accuracy. Kemudian, teruskan metrik ini ke instance HyperTune. Anda dapat memilih string apa pun yang diinginkan untuk hyperparameter_metric_tag, tetapi Anda harus menggunakan string tersebut lagi saat memulai tugas penyesuaian hyperparameter.
Langkah 3: Bangun container
Dari Terminal Anda, jalankan perintah berikut guna menentukan variabel env untuk project Anda, pastikan untuk mengganti your-cloud-project dengan ID project Anda:
PROJECT_ID='your-cloud-project'
Tentukan variabel dengan URI image container Anda di Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Konfigurasi Docker
gcloud auth configure-docker
Kemudian, build container dengan menjalankan perintah berikut dari root direktori horses_or_humans Anda:
docker build ./ -t $IMAGE_URI
Terakhir, teruskan ke Google Container Registry:
docker push $IMAGE_URI
Dengan container yang dikirim ke Container Registry, sekarang Anda siap untuk memulai tugas penyesuaian hyperparameter model kustom.
5. Menjalankan tugas penyesuaian hyperparameter di Vertex AI
Lab ini menggunakan pelatihan kustom melalui container kustom di Google Container Registry, tetapi Anda juga dapat menjalankan tugas penyesuaian hyperparameter dengan container bawaan Vertex AI.
Untuk memulai, buka bagian Pelatihan di bagian Vertex pada Konsol Cloud Anda:
Langkah 1: Konfigurasi tugas pelatihan
Klik Buat untuk memasukkan parameter ke tugas penyesuaian hyperparameter Anda.
- Di bagian Set data, pilih Tidak ada set data terkelola
- Lalu, pilih Pelatihan kustom (lanjutan) sebagai metode pelatihan Anda dan klik Lanjutkan.
- Masukkan
horses-humans-hyptertune(atau apa pun nama model yang Anda inginkan) untuk Nama model - Klik Lanjutkan
Dalam langkah setelan Container, pilih Container kustom:

Di kotak pertama (Image container), masukkan nilai variabel IMAGE_URI Anda dari bagian sebelumnya. Nilainya harus: gcr.io/your-cloud-project/horse-human:hypertune, dengan nama project Anda. Biarkan kolom lainnya kosong dan klik Lanjutkan.
Langkah 2: Konfigurasi tugas penyesuaian hyperparameter
Pilih Aktifkan penyesuaian hyperparameter.
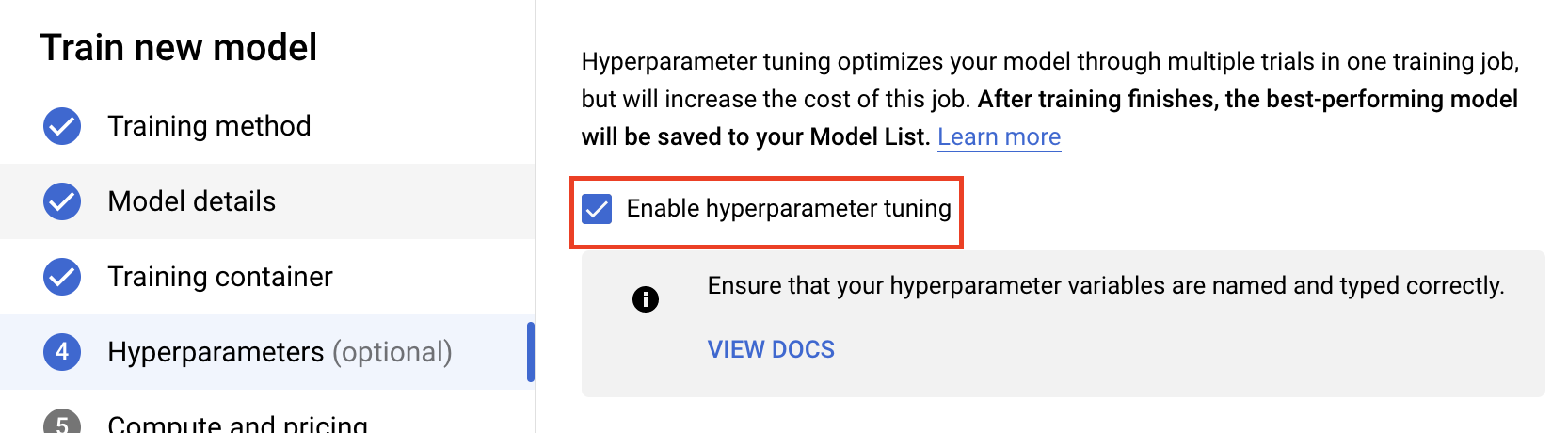
Mengonfigurasi hyperparameter
Selanjutnya, Anda perlu menambahkan hyperparameter yang Anda tetapkan sebagai argumen command line dalam kode aplikasi pelatihan. Saat menambahkan hyperparameter, Anda harus memberikan namanya terlebih dahulu. Nama ini harus cocok dengan nama argumen yang Anda teruskan ke argparse.

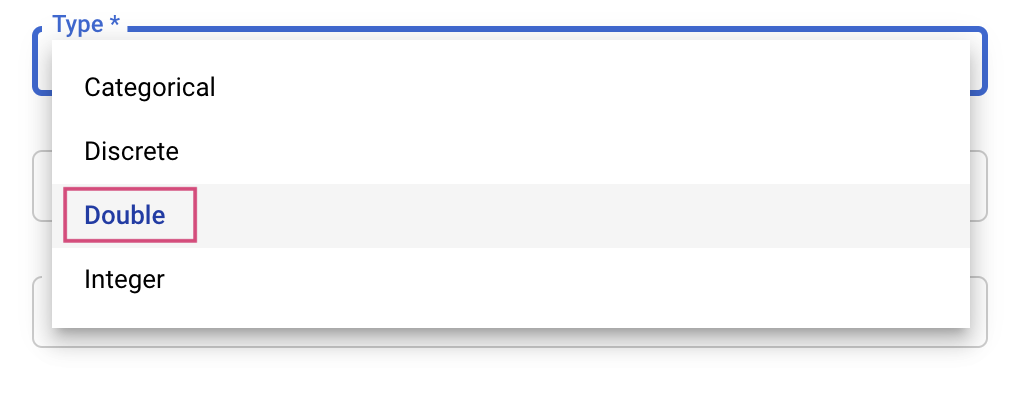
Kemudian, Anda akan memilih Jenis serta batas nilai yang akan dicoba oleh layanan penyesuaian. Jika memilih jenis Ganda atau Bilangan Bulat, Anda harus memberikan nilai minimum dan maksimum. Dan jika memilih Kategoris atau Diskret, Anda harus memberikan nilainya.

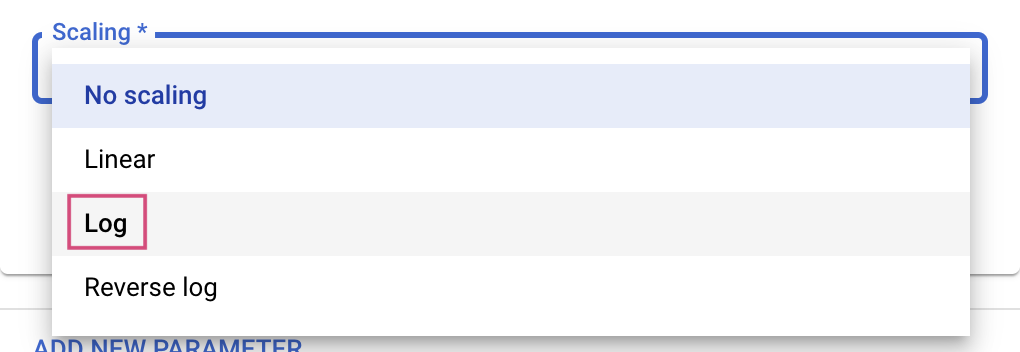
Untuk jenis Ganda dan Bilangan Bulat, Anda juga harus memberikan nilai Penskalaan.
Setelah menambahkan hyperparameter learning_rate, tambahkan parameter untuk momentum dan num_units.


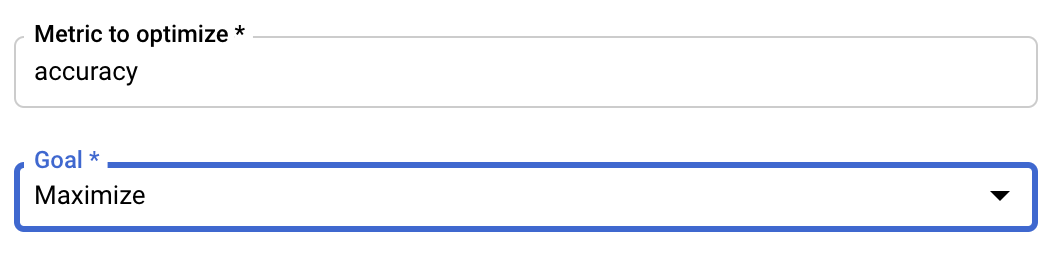
Konfigurasi Metrik
Setelah menambahkan hyperparameter, Anda akan memberikan metrik yang ingin dioptimalkan serta tujuannya. Nilai ini harus sama dengan hyperparameter_metric_tag yang Anda tetapkan di aplikasi pelatihan.
Layanan penyesuaian Hyperparameter Vertex AI akan menjalankan beberapa uji coba aplikasi pelatihan Anda dengan nilai yang dikonfigurasi pada langkah-langkah sebelumnya. Anda harus menetapkan batas maksimal terkait jumlah uji coba yang akan dijalankan oleh layanan tersebut. Lebih banyak uji coba umumnya memberikan hasil yang lebih baik, tetapi akan ada titik penurunan hasil, lalu uji coba tambahan yang dilakukan setelahnya memiliki sedikit hingga tanpa pengaruh pada metrik yang akan Anda optimalkan. Praktik terbaiknya adalah memulai dengan jumlah uji coba yang lebih sedikit dan memahami dampaknya terhadap hyperparameter yang Anda pilih sebelum meningkatkan skalanya ke jumlah uji coba yang besar.
Anda juga harus menetapkan batas atas untuk jumlah uji coba paralel. Peningkatan jumlah uji coba paralel akan mengurangi jumlah waktu yang diperlukan untuk menjalankan tugas penyesuaian hyperparameter; tetapi, cara ini dapat mengurangi efektivitas tugas secara keseluruhan. Hal ini karena strategi penyesuaian default menggunakan hasil uji coba sebelumnya untuk menentukan penetapan nilai dalam uji coba berikutnya. Jika Anda menjalankan terlalu banyak uji coba secara paralel, akan ada uji coba yang dimulai tanpa mendapatkan manfaat dari hasil uji coba yang masih berjalan.
Untuk tujuan demonstrasi, Anda dapat menetapkan jumlah uji coba menjadi 15 dan jumlah maksimum uji coba paralel menjadi 3. Anda dapat bereksperimen dengan angka yang berbeda, tetapi hal ini dapat menyebabkan waktu penyesuaian yang lebih lama dan biaya yang lebih tinggi.

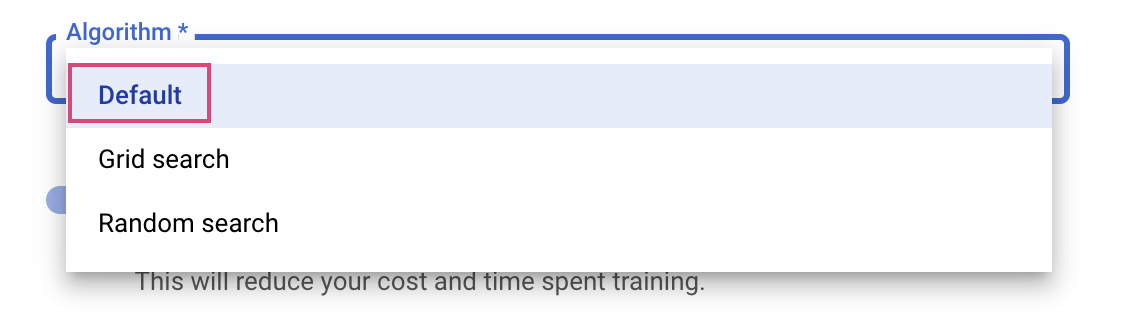
Langkah terakhir adalah memilih Default sebagai algoritma penelusuran, yang akan menggunakan Google Vizier untuk melakukan pengoptimalan Bayesian untuk penyesuaian hyperparameter. Anda dapat mempelajari lebih lanjut algoritma ini di sini.
Klik Lanjutkan.
Langkah 3: Konfigurasi komputasi
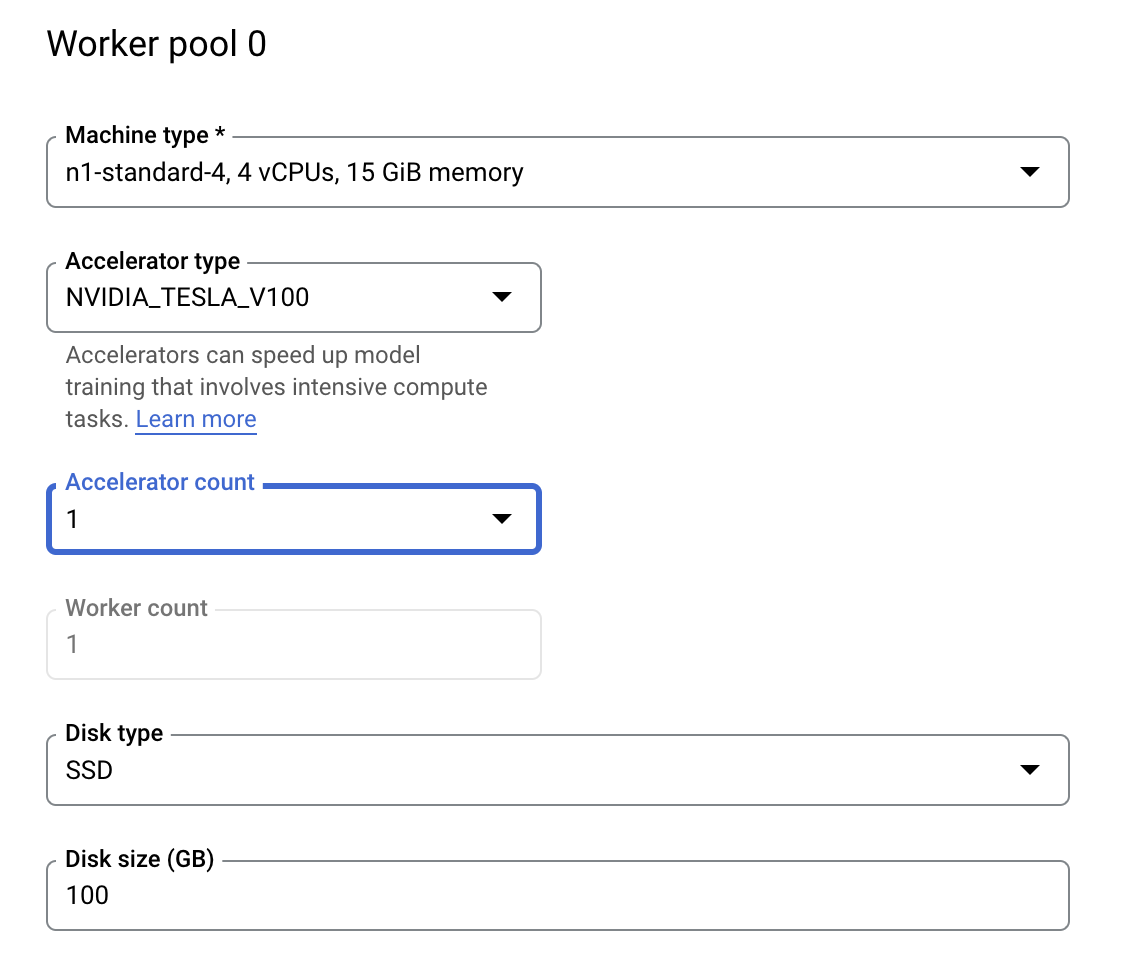
Di Compute and pricing, biarkan region yang dipilih seperti apa adanya dan konfigurasi Worker pool 0 sebagai berikut.
Klik Start training untuk memulai tugas penyesuaian hyperparameter. Di bagian Pelatihan konsol, pada tab TUGAS PENYESUAIAN HYPERPARAMETER, Anda akan melihat sesuatu seperti ini:
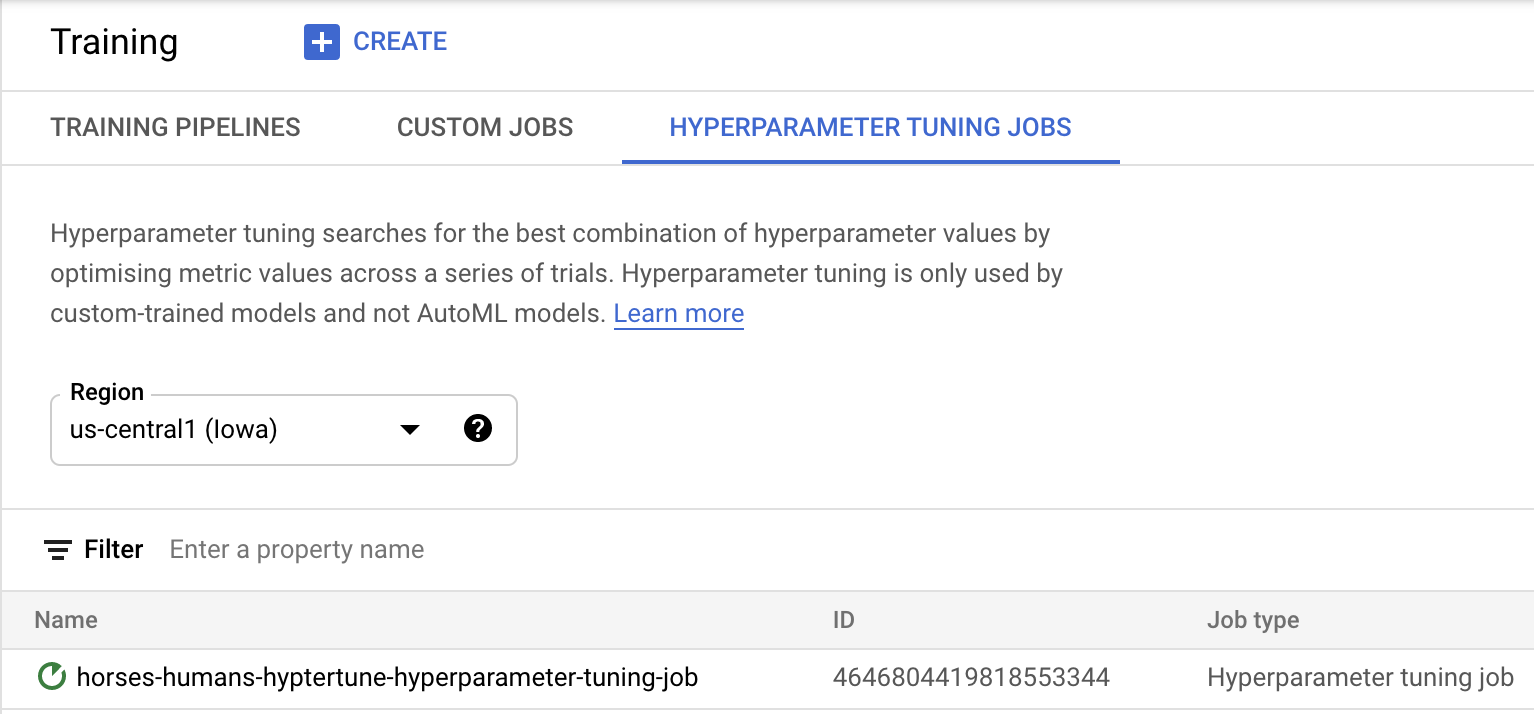
Setelah selesai, Anda dapat mengklik nama tugas dan melihat hasil uji coba penyetelan.
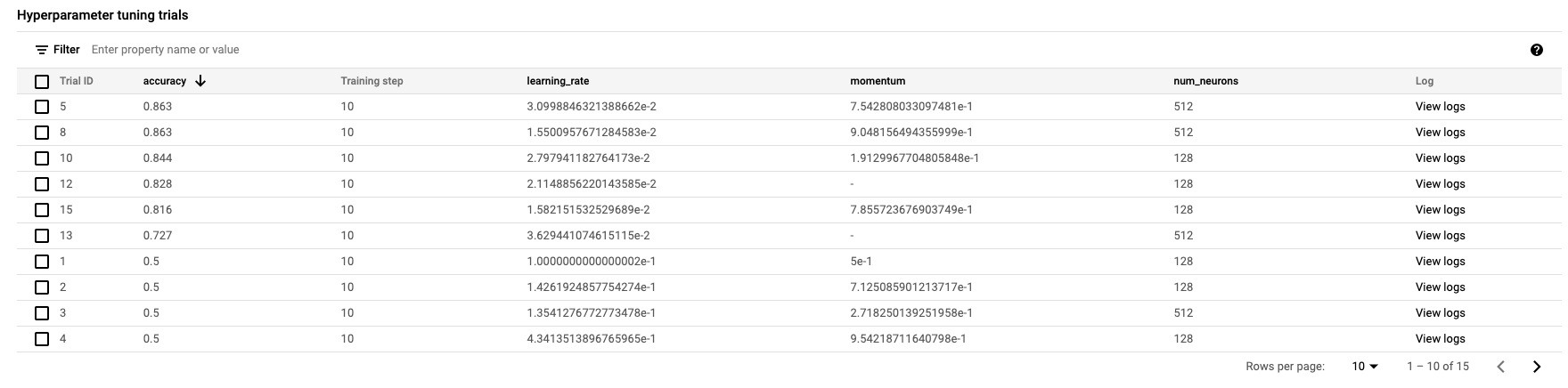
🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI untuk:
- Meluncurkan tugas penyesuaian hyperparameter untuk kode pelatihan yang disediakan dalam container kustom. Anda telah menggunakan model TensorFlow dalam contoh ini, tetapi Anda dapat melatih model yang dibangun dengan framework apa pun menggunakan container kustom.
Untuk mempelajari lebih lanjut berbagai bagian Vertex, lihat dokumentasinya.
6. [Opsional] Menggunakan Vertex SDK
Bagian sebelumnya menunjukkan cara meluncurkan tugas penyesuaian hyperparameter melalui UI. Di bagian ini, Anda akan melihat cara alternatif untuk mengirim tugas penyesuaian hyperparameter menggunakan Vertex Python API.
Dari Peluncur, buat notebook TensorFlow 2.

Impor Vertex AI SDK.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Untuk meluncurkan tugas penyesuaian hyperparameter, Anda harus terlebih dahulu menentukan spesifikasi berikut. Anda harus mengganti {PROJECT_ID} di image_uri dengan project Anda.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Selanjutnya, buat CustomJob. Anda harus mengganti {YOUR_BUCKET} dengan bucket dalam project Anda untuk staging.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Kemudian, buat dan jalankan HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Pembersihan
Karena sebelumnya kita telah mengonfigurasi notebook agar kehabisan waktu setelah 60 menit tidak ada aktivitas, jangan khawatir untuk menonaktifkan instance-nya. Jika Anda ingin menonaktifkan instance secara manual, klik tombol Hentikan di bagian Vertex AI Workbench pada konsol. Jika Anda ingin menghapus notebook secara keseluruhan, klik tombol Hapus.

Untuk menghapus Bucket Penyimpanan, menggunakan menu Navigasi di Konsol Cloud, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus: