1. Przegląd
W tym module użyjesz Vertex AI do uruchomienia zadania dostrajania hiperparametrów dla modelu TensorFlow. W tym laboratorium używamy TensorFlow do kodu modelu, ale te koncepcje mają zastosowanie również do innych platform ML.
Czego się dowiesz
Poznasz takie zagadnienia jak:
- Modyfikowanie kodu aplikacji trenującej na potrzeby automatycznego dostrajania hiperparametrów
- Konfigurowanie i uruchamianie zadania dostrajania hiperparametrów w interfejsie Vertex AI
- Skonfiguruj i uruchom zadanie dostrajania hiperparametrów za pomocą pakietu Vertex AI SDK dla Pythona.
Całkowity koszt przeprowadzenia tego modułu w Google Cloud wynosi około 3 USD.
2. Wprowadzenie do Vertex AI
W tym module wykorzystujemy najnowszą ofertę produktów AI dostępną w Google Cloud. Vertex AI integruje oferty ML w Google Cloud, zapewniając płynne środowisko programistyczne. Wcześniej modele wytrenowane za pomocą AutoML i modele niestandardowe były dostępne w ramach osobnych usług. Nowa oferta łączy je w jeden interfejs API wraz z innymi nowymi usługami. Możesz też przeprowadzić migrację istniejących projektów do Vertex AI. Jeśli masz jakieś uwagi, odwiedź stronę pomocy.
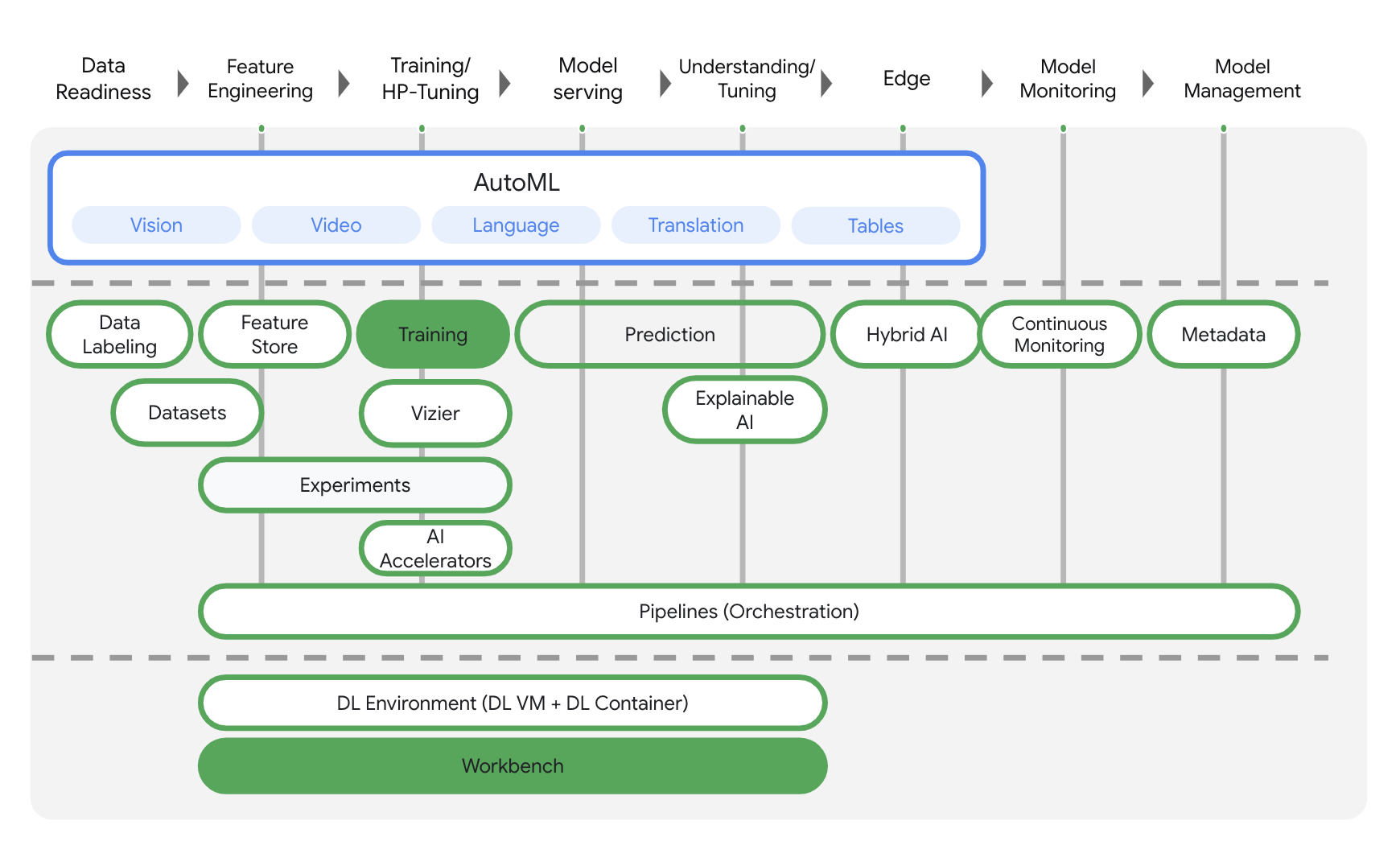
Vertex AI obejmuje wiele różnych usług, które obsługują kompleksowe przepływy pracy związane z uczeniem maszynowym. To laboratorium skupi się na produktach wyróżnionych poniżej: Training i Workbench.
3. Konfigurowanie środowiska
Aby wykonać to ćwiczenie, musisz mieć projekt w Google Cloud Platform z włączonymi płatnościami. Aby utworzyć projekt, postępuj zgodnie z instrukcjami.
Krok 1. Włącz interfejs Compute Engine API
Przejdź do Compute Engine i kliknij Włącz, jeśli nie jest jeszcze włączona. Będzie Ci potrzebny do utworzenia instancji notatnika.
Krok 2. Włącz interfejs Container Registry API
Otwórz Container Registry i kliknij Włącz, jeśli nie jest jeszcze włączona. Użyjesz go do utworzenia kontenera na potrzeby niestandardowego zadania trenowania.
Krok 3. Włącz interfejs Vertex AI API
Otwórz sekcję Vertex AI w konsoli Cloud i kliknij Włącz interfejs Vertex AI API.
Krok 4. Tworzenie instancji Vertex AI Workbench
W sekcji Vertex AI w konsoli Cloud kliknij Workbench:
Włącz interfejs Notebooks API, jeśli nie jest jeszcze włączony.
Po włączeniu kliknij ZARZĄDZANE NOTATNIKI:

Następnie wybierz NOWY NOTEBOOK.
Nadaj notatnikowi nazwę, a potem kliknij Ustawienia zaawansowane.

W sekcji Ustawienia zaawansowane włącz wyłączanie w przypadku bezczynności i ustaw liczbę minut na 60. Oznacza to, że Twój notebook będzie się automatycznie wyłączać, gdy nie jest używany, dzięki czemu nie poniesiesz niepotrzebnych kosztów.

W sekcji Zabezpieczenia wybierz „Włącz terminal”, jeśli nie jest jeszcze włączony.
Wszystkie pozostałe ustawienia zaawansowane możesz pozostawić bez zmian.
Następnie kliknij Utwórz. Udostępnienie instancji zajmie kilka minut.
Po utworzeniu instancji wybierz Otwórz JupyterLab.

Przy pierwszym użyciu nowej instancji pojawi się prośba o uwierzytelnienie. Aby to zrobić, postępuj zgodnie z instrukcjami wyświetlanymi w interfejsie.
4. Konteneryzowanie kodu aplikacji trenującej
Model, który wytrenujesz i dostroisz w tym laboratorium, to model klasyfikacji obrazów wytrenowany na zbiorze danych konie lub ludzie z TensorFlow Datasets.
To zadanie dostrajania hiperparametrów prześlesz do Vertex AI, umieszczając kod aplikacji do trenowania w kontenerze Dockera i przenosząc ten kontener do Google Container Registry. Dzięki temu możesz dostrajać hiperparametry modelu utworzonego w dowolnej platformie.
Aby rozpocząć, w menu Launchera otwórz okno terminala w instancji notatnika:

Utwórz nowy katalog o nazwie horses_or_humans i przejdź do niego:
mkdir horses_or_humans
cd horses_or_humans
Krok 1. Utwórz plik Dockerfile
Pierwszym krokiem w procesie kontenerowania kodu jest utworzenie pliku Dockerfile. W pliku Dockerfile umieścisz wszystkie polecenia potrzebne do uruchomienia obrazu. Zainstaluje wszystkie niezbędne biblioteki, w tym bibliotekę CloudML Hypertune, i skonfiguruje punkt wejścia dla kodu trenowania.
W terminalu utwórz pusty plik Dockerfile:
touch Dockerfile
Otwórz plik Dockerfile i skopiuj do niego ten kod:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Ten plik Dockerfile używa obrazu Dockera kontenera Deep Learning Container TensorFlow Enterprise 2.7 z GPU. Kontenery do deep learningu w Google Cloud mają fabrycznie zainstalowanych wiele popularnych platform ML i narzędzi do nauki o danych. Po pobraniu tego obrazu ten plik Dockerfile konfiguruje punkt wejścia dla kodu trenującego. Nie masz jeszcze tych plików. W następnym kroku dodasz kod do trenowania i dostrajania modelu.
Krok 2. Dodaj kod trenowania modelu
W terminalu uruchom to polecenie, aby utworzyć katalog z kodem szkoleniowym i plik Pythona, do którego dodasz kod:
mkdir trainer
touch trainer/task.py
W katalogu horses_or_humans/ powinny się teraz znajdować te pliki:
+ Dockerfile
+ trainer/
+ task.py
Następnie otwórz utworzony plik task.py i skopiuj poniższy kod.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Zanim utworzysz kontener, przyjrzyjmy się bliżej kodowi. Korzystanie z usługi dostrajania hiperparametrów wymaga kilku komponentów.
- Skrypt importuje bibliotekę
hypertune. Pamiętaj, że plik Dockerfile z kroku 1 zawierał instrukcje instalacji tej biblioteki za pomocą narzędzia pip. - Funkcja
get_args()definiuje argument wiersza poleceń dla każdego hiperparametru, który chcesz dostroić. W tym przykładzie dostrajane hiperparametry to tempo uczenia się, wartość momentum w optymalizatorze i liczba jednostek w ostatniej warstwie ukrytej modelu, ale możesz eksperymentować z innymi. Wartość przekazana w tych argumentach jest następnie używana do ustawienia odpowiedniego hiperparametru w kodzie. - Na końcu funkcji
main()bibliotekahypertunesłuży do zdefiniowania danych, które chcesz zoptymalizować. W TensorFlow metoda kerasmodel.fitzwraca obiektHistory. AtrybutHistory.historyto zapis wartości funkcji straty i wartości danych w kolejnych epokach. Jeśli przekażesz dane weryfikacyjne domodel.fit, atrybutHistory.historybędzie zawierać również wartości utraty i wartości wskaźników weryfikacji. Jeśli na przykład wytrenujesz model w 3 epokach z danymi do weryfikacji i podaszaccuracyjako wskaźnik, atrybutHistory.historybędzie wyglądać podobnie do tego słownika.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Jeśli chcesz, aby usługa dostrajania hiperparametrów odkryła wartości, które maksymalizują dokładność weryfikacji modelu, zdefiniuj dane jako ostatni wpis (lub NUM_EPOCS - 1) na liście val_accuracy. Następnie przekaż te dane do instancji elementu HyperTune. W przypadku parametru hyperparameter_metric_tag możesz wybrać dowolny ciąg znaków, ale musisz go użyć ponownie później, gdy uruchomisz zadanie dostrajania hiperparametrów.
Krok 3. Utwórz kontener
W terminalu uruchom to polecenie, aby zdefiniować zmienną środowiskową dla projektu. Pamiętaj, aby zastąpić your-cloud-project identyfikatorem projektu:
PROJECT_ID='your-cloud-project'
Zdefiniuj zmienną z identyfikatorem URI obrazu kontenera w Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Konfigurowanie Dockera
gcloud auth configure-docker
Następnie utwórz kontener, uruchamiając to polecenie w katalogu głównym horses_or_humans:
docker build ./ -t $IMAGE_URI
Na koniec przenieś go do Google Container Registry:
docker push $IMAGE_URI
Po przeniesieniu kontenera do Container Registry możesz uruchomić zadanie dostrajania hiperparametrów modelu niestandardowego.
5. Uruchamianie zadania dostrajania hiperparametrów w Vertex AI
W tym laboratorium używamy niestandardowego trenowania za pomocą niestandardowego kontenera w Google Container Registry, ale możesz też uruchomić zadanie dostrajania hiperparametrów za pomocą gotowego kontenera Vertex AI.
Na początek otwórz sekcję Trenowanie w sekcji Vertex w konsoli Cloud:
Krok 1. Skonfiguruj zadanie trenowania
Kliknij Utwórz, aby wprowadzić parametry zadania dostrajania hiperparametrów.
- W sekcji Zbiór danych wybierz Brak zarządzanego zbioru danych.
- Następnie jako metodę trenowania wybierz Trenowanie niestandardowe (zaawansowane) i kliknij Dalej.
- W polu Nazwa modelu wpisz
horses-humans-hyptertune(lub dowolną inną nazwę). - Kliknij Dalej.
W kroku Ustawienia kontenera wybierz Kontener niestandardowy:

W pierwszym polu (Obraz kontenera) wpisz wartość zmiennej IMAGE_URI z poprzedniej sekcji. Powinna mieć postać: gcr.io/your-cloud-project/horse-human:hypertune, gdzie gcr.io/your-cloud-project/horse-human:hypertune to nazwa Twojego projektu. Pozostałe pola pozostaw puste i kliknij Dalej.
Krok 2. Skonfiguruj zadanie dostrajania hiperparametrów
Wybierz Włącz dostrajanie hiperparametrów.
Konfigurowanie hiperparametrów
Następnie musisz dodać hiperparametry, które zostały ustawione jako argumenty wiersza poleceń w kodzie aplikacji do trenowania. Podczas dodawania hiperparametru musisz najpierw podać jego nazwę. Powinna ona odpowiadać nazwie argumentu przekazanego do funkcji argparse.

Następnie wybierz typ oraz zakres wartości, które będzie testować usługa dostrajania. Jeśli wybierzesz typ Double lub Integer, musisz podać wartość minimalną i maksymalną. Jeśli wybierzesz opcję Kategorialne lub Dyskretne, musisz podać wartości.

W przypadku typów Double i Integer musisz też podać wartość skalowania.
Po dodaniu hiperparametru learning_rate dodaj parametry dla momentum i num_units.


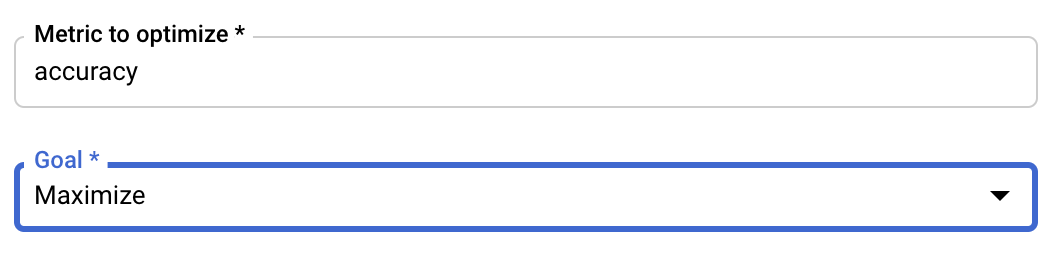
Konfigurowanie wskaźnika
Po dodaniu hiperparametrów podaj dane, które chcesz zoptymalizować, oraz cel. Powinien on być taki sam jak hyperparameter_metric_tag ustawiony w aplikacji do trenowania.
Usługa dostrajania hiperparametrów Vertex AI przeprowadzi wiele prób aplikacji do trenowania z wartościami skonfigurowanymi w poprzednich krokach. Musisz określić górną granicę liczby prób, które usługa będzie przeprowadzać. Większa liczba prób zwykle pozwala uzyskać lepsze wyniki, ale po pewnym czasie dodatkowe próby mają niewielki lub żaden wpływ na wskaźnik, który próbujesz zoptymalizować. Najlepiej zacząć od mniejszej liczby prób i sprawdzić, jak duże znaczenie mają wybrane hiperparametry, zanim zwiększysz liczbę prób.
Musisz też ustawić górny limit liczby równoległych prób. Zwiększenie liczby równoległych prób skróci czas działania zadania dostrajania hiperparametrów, ale może zmniejszyć ogólną skuteczność zadania. Dzieje się tak, ponieważ domyślna strategia dostrajania wykorzystuje wyniki poprzednich prób do określania wartości w kolejnych próbach. Jeśli przeprowadzisz zbyt wiele prób równolegle, niektóre z nich rozpoczną się bez uwzględnienia wyników prób, które są jeszcze w toku.
Na potrzeby demonstracji możesz ustawić liczbę prób na 15, a maksymalną liczbę równoległych prób na 3. Możesz eksperymentować z różnymi liczbami, ale może to wydłużyć czas dostrajania i zwiększyć koszty.

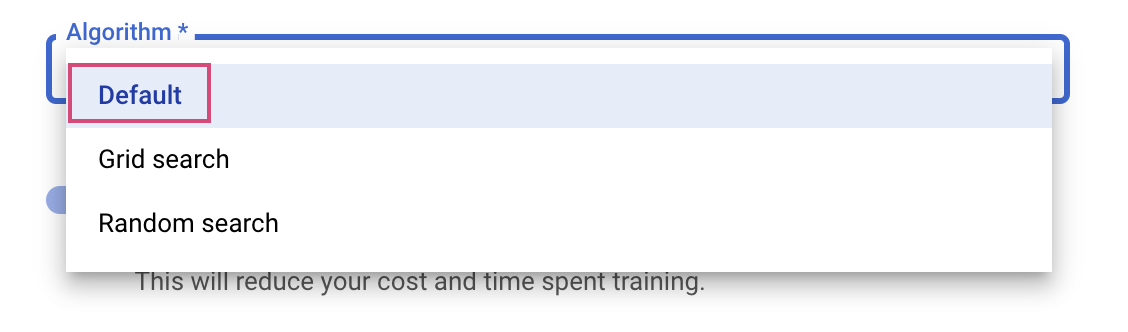
Ostatnim krokiem jest wybranie algorytmu wyszukiwania Domyślny, który będzie używać Google Vizier do przeprowadzania optymalizacji bayesowskiej w celu dostrajania hiperparametrów. Więcej informacji o tym algorytmie znajdziesz tutaj.
Kliknij Dalej.
Krok 3. Skonfiguruj zasoby obliczeniowe
W sekcji Obliczenia i ceny pozostaw wybrany region bez zmian i skonfiguruj Pulę instancji roboczych 0 w ten sposób:
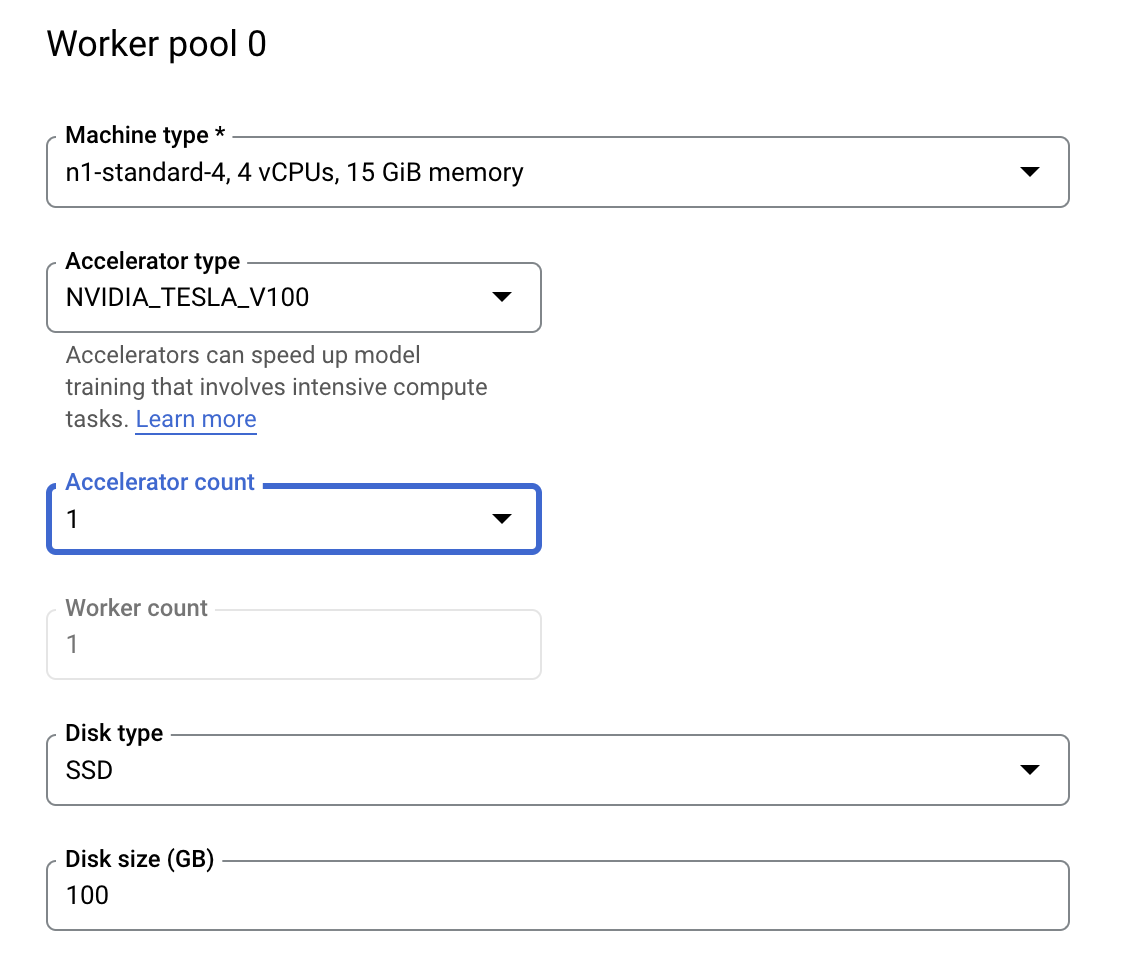
Kliknij Rozpocznij trenowanie, aby uruchomić zadanie dostrajania hiperparametrów. W sekcji Trenowanie w konsoli na karcie ZADANIA DOSTOSOWYWANIA HIPERPARAMETRÓW zobaczysz coś takiego:
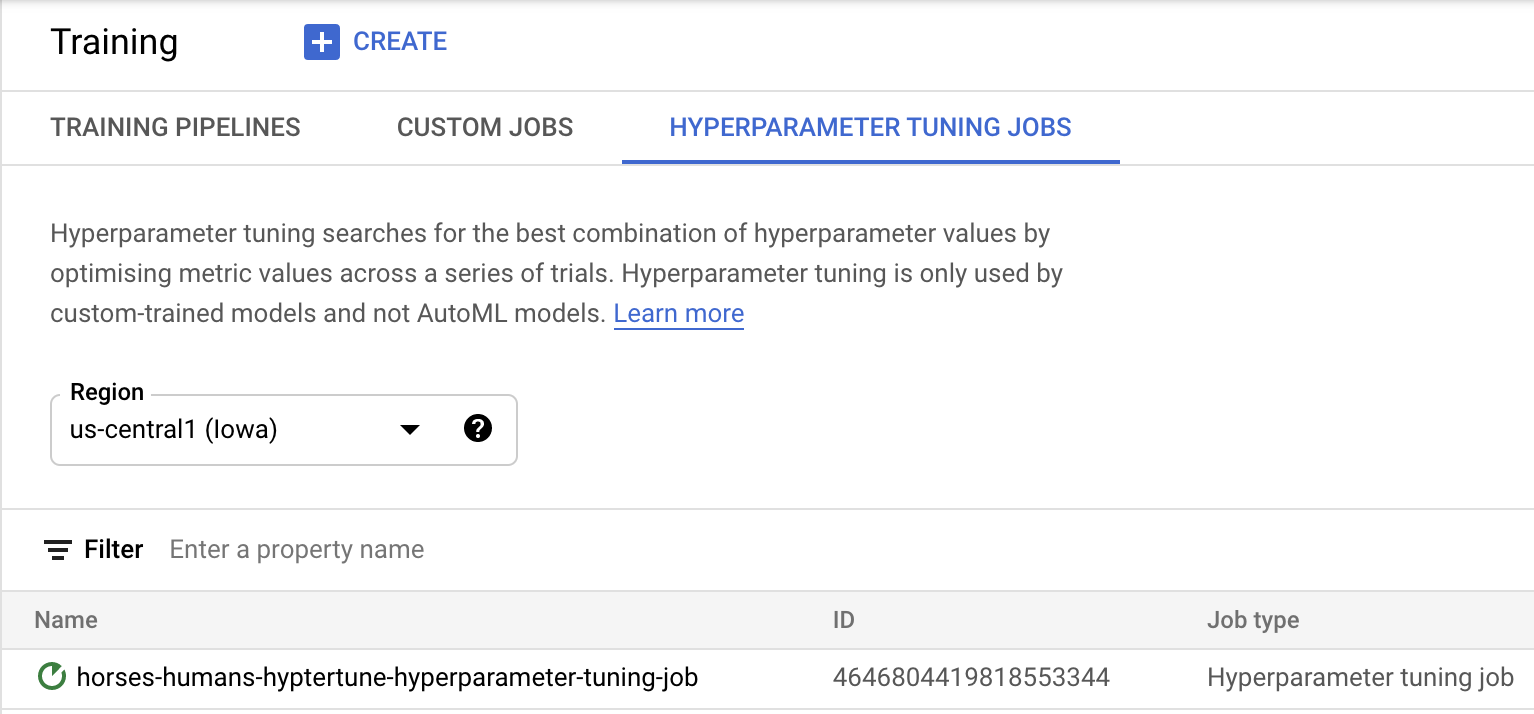
Po zakończeniu możesz kliknąć nazwę zadania i wyświetlić wyniki prób dostrajania.
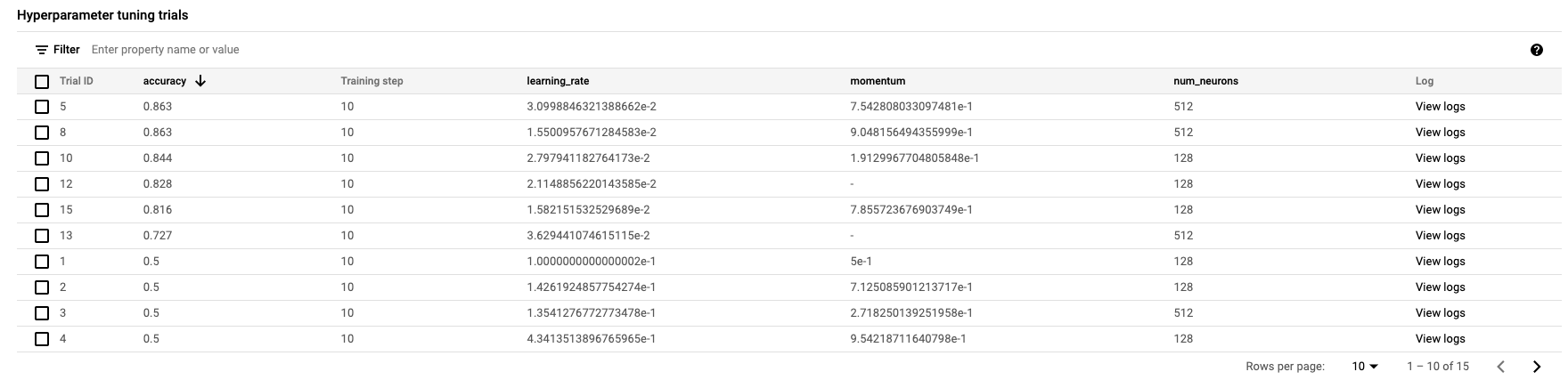
🎉 Gratulacje! 🎉
Dowiedziałeś się, jak używać Vertex AI do:
- Uruchom zadanie dostrajania hiperparametrów dla kodu trenowania podanego w kontenerze niestandardowym. W tym przykładzie użyto modelu TensorFlow, ale za pomocą kontenerów niestandardowych możesz wytrenować model utworzony w dowolnej platformie.
Więcej informacji o różnych częściach Vertex znajdziesz w dokumentacji.
6. [Opcjonalnie] Użyj pakietu Vertex SDK
W poprzedniej sekcji pokazaliśmy, jak uruchomić zadanie dostrajania hiperparametrów za pomocą interfejsu. W tej sekcji znajdziesz alternatywny sposób przesyłania zadania dostrajania hiperparametrów za pomocą interfejsu Vertex Python API.
W menu uruchamiania utwórz notatnik TensorFlow 2.

Zaimportuj pakiet Vertex AI SDK.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Aby uruchomić zadanie dostrajania hiperparametrów, musisz najpierw zdefiniować te specyfikacje: W image_uri musisz zastąpić {PROJECT_ID} nazwą swojego projektu.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Następnie utwórz CustomJob. Zamiast {YOUR_BUCKET} wpisz zasobnik w projekcie, który będzie służyć jako miejsce tymczasowe.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Następnie utwórz i uruchom HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Czyszczenie
Skonfigurowaliśmy notatnik tak, aby po 60 minutach bezczynności przekraczał limit czasu, więc nie musimy się martwić o zamykanie instancji. Jeśli chcesz ręcznie wyłączyć instancję, kliknij przycisk Zatrzymaj w sekcji Vertex AI Workbench w konsoli. Jeśli chcesz całkowicie usunąć notatnik, kliknij przycisk Usuń.

Aby usunąć zasobnik Storage, w menu nawigacyjnym w konsoli Cloud otwórz Storage, wybierz zasobnik i kliknij Usuń: