1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ sử dụng Vertex AI để chạy một công việc điều chỉnh siêu tham số cho mô hình TensorFlow. Mặc dù phòng thí nghiệm này sử dụng TensorFlow cho mã mô hình, nhưng các khái niệm này cũng áp dụng được cho các khung học máy khác.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Sửa đổi mã xử lý ứng dụng huấn luyện để tự động điều chỉnh siêu tham số
- Định cấu hình và chạy một công việc điều chỉnh siêu tham số từ giao diện người dùng Vertex AI
- Định cấu hình và chạy một công việc điều chỉnh siêu tham số bằng Vertex AI Python SDK
Tổng chi phí để chạy phòng thí nghiệm này trên Google Cloud là khoảng 3 USD.
2. Giới thiệu về Vertex AI
Phòng thí nghiệm này sử dụng sản phẩm AI mới nhất hiện có trên Google Cloud. Vertex AI tích hợp các sản phẩm học máy trên Google Cloud thành một trải nghiệm phát triển liền mạch. Trước đây, các mô hình được huấn luyện bằng AutoML và các mô hình tuỳ chỉnh có thể truy cập thông qua các dịch vụ riêng biệt. Sản phẩm mới này kết hợp cả hai thành một API duy nhất, cùng với các sản phẩm mới khác. Bạn cũng có thể di chuyển các dự án hiện có sang Vertex AI. Nếu bạn có bất kỳ ý kiến phản hồi nào, vui lòng xem trang hỗ trợ.
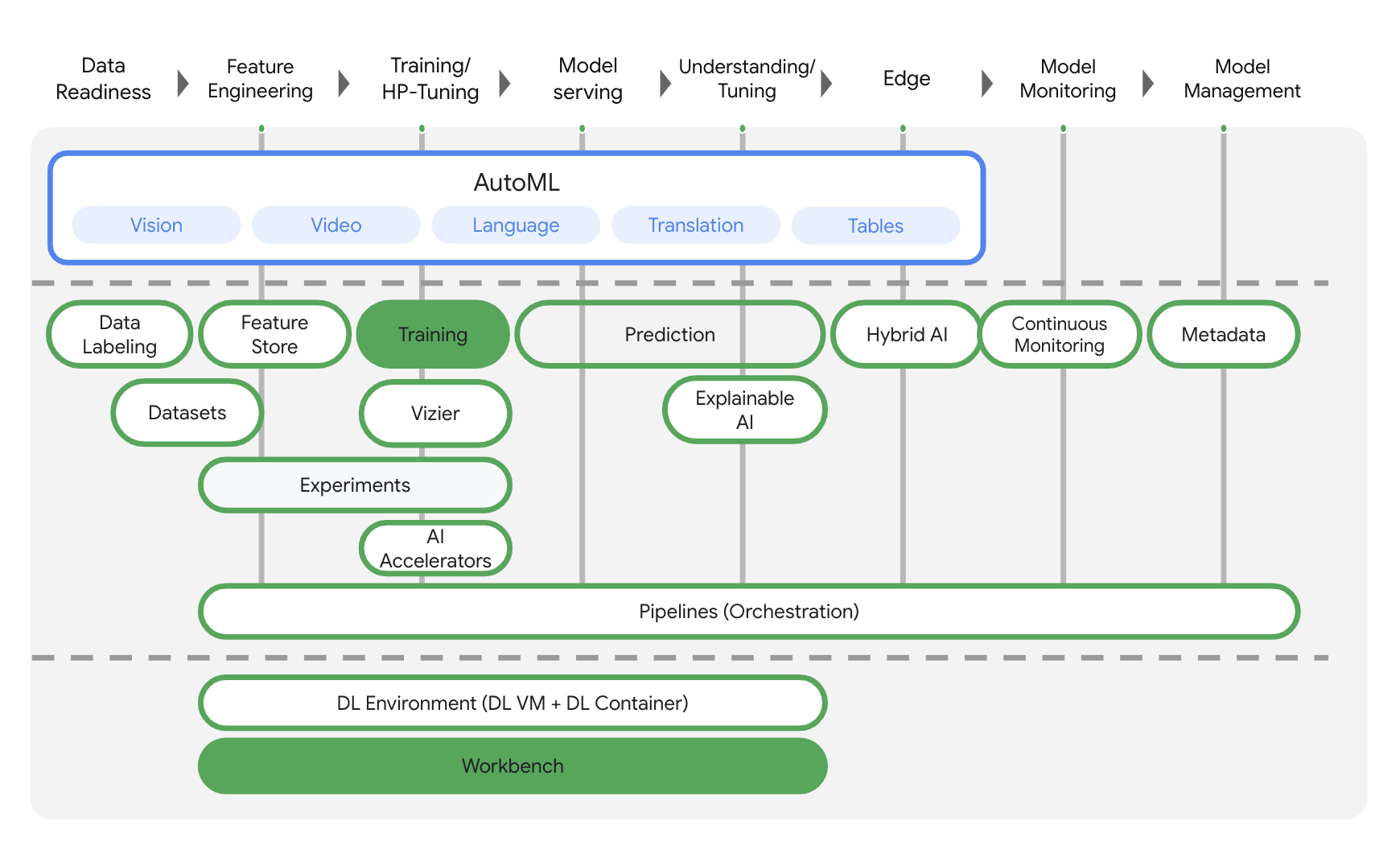
Vertex AI bao gồm nhiều sản phẩm khác nhau để hỗ trợ quy trình làm việc học máy từ đầu đến cuối. Phòng thí nghiệm này sẽ tập trung vào các sản phẩm được nêu bật bên dưới: Huấn luyện và Workbench.
3. Thiết lập môi trường
Bạn cần có một dự án trên Google Cloud Platform đã bật tính năng thanh toán để chạy lớp học lập trình này. Để tạo một dự án, hãy làm theo hướng dẫn tại đây.
Bước 1: Bật Compute Engine API
Chuyển đến Compute Engine rồi chọn Bật nếu bạn chưa bật. Bạn cần bật API này để tạo thực thể sổ tay.
Bước 2: Bật Container Registry API
Chuyển đến Container Registry rồi chọn Bật nếu bạn chưa bật. Bạn sẽ sử dụng API này để tạo một vùng chứa cho công việc huấn luyện tuỳ chỉnh.
Bước 3: Bật Vertex AI API
Chuyển đến phần Vertex AI của Cloud Console rồi nhấp vào Bật Vertex AI API.
Bước 4: Tạo thực thể Vertex AI Workbench
Trong phần Vertex AI của Cloud Console, hãy nhấp vào Workbench:
Bật Notebooks API nếu bạn chưa bật.
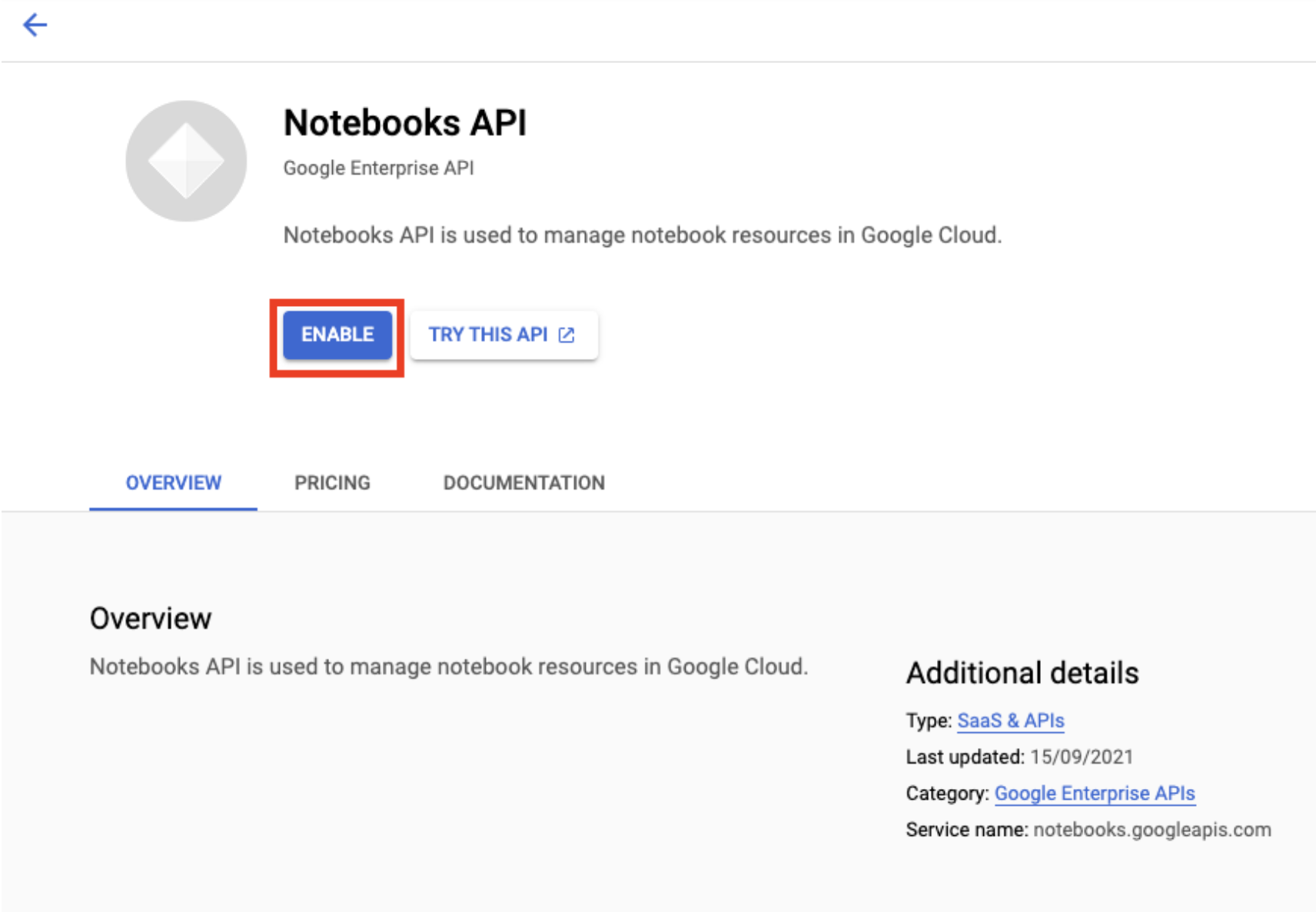
Sau khi bật, hãy nhấp vào NOTEBOOKS ĐƯỢC QUẢN LÝ:

Sau đó, chọn NOTEBOOK MỚI.
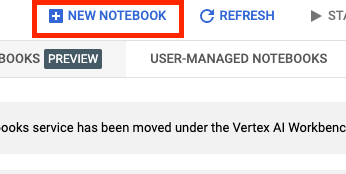
Đặt tên cho sổ tay rồi nhấp vào Cài đặt nâng cao.

Trong phần Cài đặt nâng cao, hãy bật tính năng tắt khi không hoạt động và đặt số phút thành 60. Điều này có nghĩa là sổ tay của bạn sẽ tự động tắt khi không sử dụng để bạn không phải chịu chi phí không cần thiết.

Trong phần Bảo mật, hãy chọn "Bật thiết bị đầu cuối" nếu bạn chưa bật.
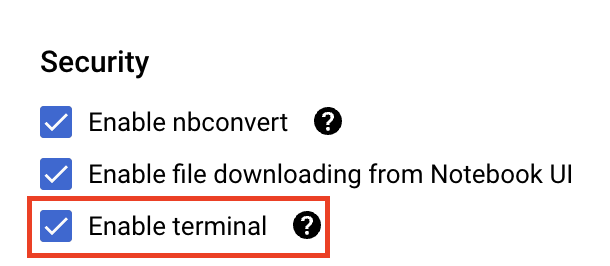
Bạn có thể để nguyên tất cả các chế độ cài đặt nâng cao khác.
Tiếp theo, hãy nhấp vào Tạo. Thực thể sẽ mất vài phút để được cung cấp.
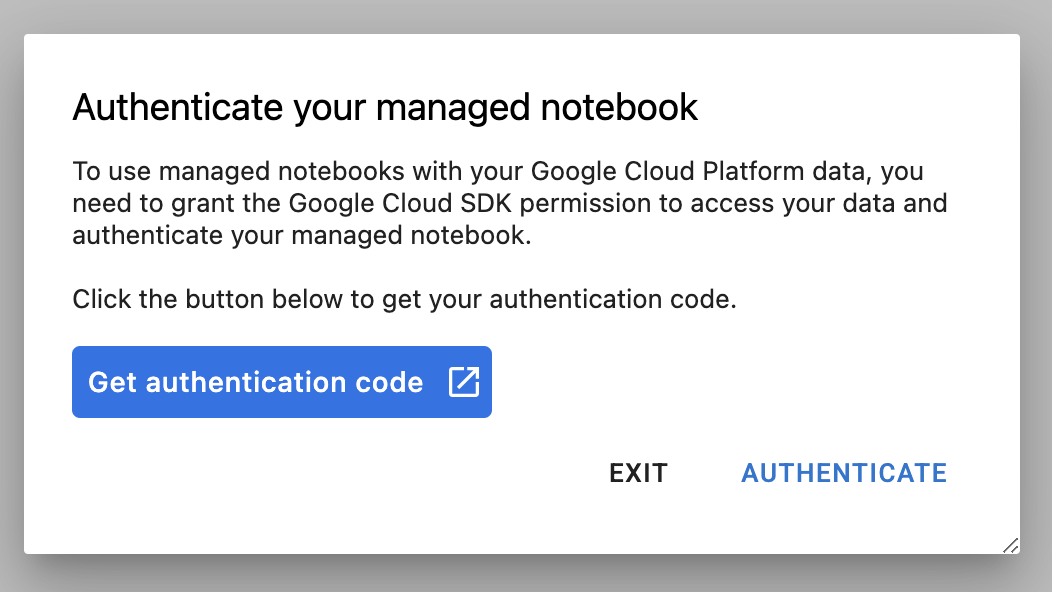
Sau khi tạo thực thể, hãy chọn Mở JupyterLab.

Vào lần đầu tiên sử dụng một thực thể mới, bạn sẽ được yêu cầu xác thực. Hãy làm theo các bước trong giao diện người dùng để thực hiện.
4. Vùng chứa hoá mã xử lý ứng dụng huấn luyện
Mô hình mà bạn sẽ huấn luyện và điều chỉnh trong phòng thí nghiệm này là một mô hình phân loại hình ảnh được huấn luyện trên tập dữ liệu ngựa hoặc người từ TensorFlow Datasets.
Bạn sẽ gửi công việc điều chỉnh siêu tham số này đến Vertex AI bằng cách đặt mã xử lý ứng dụng huấn luyện vào một vùng chứa Docker và đẩy vùng chứa này đến Google Container Registry. Bằng cách sử dụng phương pháp này, bạn có thể điều chỉnh siêu tham số cho một mô hình được xây dựng bằng bất kỳ khung nào.
Để bắt đầu, trong trình đơn Trình chạy, hãy mở một cửa sổ Thiết bị đầu cuối trong thực thể sổ tay:

Tạo một thư mục mới có tên là horses_or_humans và cd vào thư mục đó:
mkdir horses_or_humans
cd horses_or_humans
Bước 1: Tạo Dockerfile
Bước đầu tiên trong việc vùng chứa hoá mã của bạn là tạo một Dockerfile. Trong Dockerfile, bạn sẽ đưa vào tất cả các lệnh cần thiết để chạy hình ảnh. Lệnh này sẽ cài đặt tất cả các thư viện cần thiết, bao gồm cả thư viện CloudML Hypertune và thiết lập điểm vào cho mã huấn luyện.
Trong Thiết bị đầu cuối, hãy tạo một Dockerfile trống:
touch Dockerfile
Mở Dockerfile rồi sao chép nội dung sau vào đó:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Dockerfile này sử dụng hình ảnh Docker GPU TensorFlow Enterprise 2.7 Deep Learning Container. Deep Learning Containers trên Google Cloud được cài đặt sẵn nhiều khung khoa học dữ liệu và học máy phổ biến. Sau khi tải hình ảnh đó xuống, Dockerfile này sẽ thiết lập điểm nhập cho mã huấn luyện. Bạn chưa tạo các tệp này – trong bước tiếp theo, bạn sẽ thêm mã để huấn luyện và điều chỉnh mô hình.
Bước 2: Thêm mã huấn luyện mô hình
Trong Thiết bị đầu cuối, hãy chạy lệnh sau để tạo một thư mục cho mã huấn luyện và một tệp Python nơi bạn sẽ thêm mã:
mkdir trainer
touch trainer/task.py
Giờ đây, bạn sẽ có những nội dung sau trong thư mục horses_or_humans/:
+ Dockerfile
+ trainer/
+ task.py
Tiếp theo, hãy mở tệp task.py mà bạn vừa tạo rồi sao chép mã bên dưới.
import tensorflow as tf
import tensorflow_datasets as tfds
import argparse
import hypertune
NUM_EPOCHS = 10
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (150,150))
return tf.cast(image, tf.float32) / 255., label
def create_dataset():
'''Loads Horses Or Humans dataset and preprocesses data.'''
data, info = tfds.load(name='horses_or_humans', as_supervised=True, with_info=True)
# Create train dataset
train_data = data['train'].map(preprocess_data)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(64)
# Create validation dataset
validation_data = data['test'].map(preprocess_data)
validation_data = validation_data.batch(64)
return train_data, validation_data
def create_model(num_units, learning_rate, momentum):
'''Defines and compiles model.'''
inputs = tf.keras.Input(shape=(150, 150, 3))
x = tf.keras.layers.Conv2D(16, (3, 3), activation='relu')(inputs)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(32, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Conv2D(64, (3, 3), activation='relu')(x)
x = tf.keras.layers.MaxPooling2D((2, 2))(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(num_units, activation='relu')(x)
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_data, validation_data = create_dataset()
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_data, epochs=NUM_EPOCHS, validation_data=validation_data)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=NUM_EPOCHS)
if __name__ == "__main__":
main()
Trước khi bạn xây dựng vùng chứa, hãy xem xét kỹ hơn về mã. Có một vài thành phần dành riêng cho việc sử dụng dịch vụ điều chỉnh siêu tham số.
- Tập lệnh nhập thư viện
hypertune. Lưu ý rằng tệp Docker từ Bước 1 bao gồm hướng dẫn để cài đặt thư viện này bằng pip. - Hàm
get_args()xác định một đối số dòng lệnh cho từng siêu tham số mà bạn muốn điều chỉnh. Trong ví dụ này, các siêu tham số sẽ được điều chỉnh là tốc độ học, giá trị động lượng trong trình tối ưu hoá và số lượng đơn vị trong lớp ẩn cuối cùng của mô hình, nhưng bạn có thể thoải mái thử nghiệm với các siêu tham số khác. Sau đó, giá trị được truyền trong các đối số đó sẽ được dùng để đặt siêu tham số tương ứng trong mã. - Ở cuối hàm
main(), thư việnhypertuneđược dùng để xác định chỉ số mà bạn muốn tối ưu hoá. Trong TensorFlow, phương thức kerasmodel.fittrả về một đối tượngHistory. Thuộc tínhHistory.historylà một bản ghi các giá trị tổn thất huấn luyện và giá trị chỉ số ở các kỷ nguyên liên tiếp. Nếu bạn truyền dữ liệu xác thực đếnmodel.fit, thì thuộc tínhHistory.historycũng sẽ bao gồm giá trị tổn thất và chỉ số xác thực. Ví dụ: nếu bạn huấn luyện một mô hình trong 3 kỷ nguyên bằng dữ liệu xác thực và cung cấpaccuracylàm chỉ số, thì thuộc tínhHistory.historysẽ có dạng tương tự như từ điển sau.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Nếu bạn muốn dịch vụ điều chỉnh siêu tham số khám phá các giá trị giúp tối đa hoá độ chính xác xác thực của mô hình, thì bạn sẽ xác định chỉ số là mục nhập cuối cùng (hoặc NUM_EPOCS - 1) của danh sách val_accuracy. Sau đó, hãy truyền chỉ số này đến một thực thể của HyperTune. Bạn có thể chọn bất kỳ chuỗi nào bạn thích cho hyperparameter_metric_tag, nhưng bạn sẽ cần sử dụng lại chuỗi đó sau này khi bắt đầu công việc điều chỉnh siêu tham số.
Bước 3: Xây dựng vùng chứa
Trong Thiết bị đầu cuối, hãy chạy lệnh sau để xác định một biến môi trường cho dự án của bạn, nhớ thay thế your-cloud-project bằng mã dự án:
PROJECT_ID='your-cloud-project'
Xác định một biến bằng URI của hình ảnh vùng chứa trong Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/horse-human:hypertune"
Định cấu hình Docker
gcloud auth configure-docker
Sau đó, hãy xây dựng vùng chứa bằng cách chạy lệnh sau từ thư mục gốc của horses_or_humans:
docker build ./ -t $IMAGE_URI
Cuối cùng, hãy đẩy vùng chứa đó đến Google Container Registry:
docker push $IMAGE_URI
Sau khi đẩy vùng chứa đến Container Registry, giờ đây, bạn đã sẵn sàng bắt đầu công việc điều chỉnh siêu tham số mô hình tuỳ chỉnh.
5. Chạy một công việc điều chỉnh siêu tham số trên Vertex AI
Phòng thí nghiệm này sử dụng tính năng huấn luyện tuỳ chỉnh thông qua một vùng chứa tuỳ chỉnh trên Google Container Registry, nhưng bạn cũng có thể chạy một công việc điều chỉnh siêu tham số bằng một vùng chứa xây dựng sẵn của Vertex AI.
Để bắt đầu, hãy chuyển đến phần Huấn luyện trong phần Vertex của bảng điều khiển Cloud:
Bước 1: Định cấu hình công việc huấn luyện
Nhấp vào Tạo để nhập các tham số cho công việc điều chỉnh siêu tham số.
- Trong phần Tập dữ liệu, hãy chọn Không có tập dữ liệu được quản lý
- Sau đó, chọn Huấn luyện tuỳ chỉnh (nâng cao) làm phương thức huấn luyện rồi nhấp vào Tiếp tục.
- Nhập
horses-humans-hyptertune(hoặc bất kỳ tên nào bạn muốn đặt cho mô hình) cho Tên mô hình - Nhấp vào Tiếp tục
Trong bước Cài đặt vùng chứa, hãy chọn Vùng chứa tuỳ chỉnh:

Trong hộp đầu tiên (Hình ảnh vùng chứa), hãy nhập giá trị của biến IMAGE_URI từ phần trước. Giá trị này phải là: gcr.io/your-cloud-project/horse-human:hypertune, với tên dự án của riêng bạn. Để trống các trường còn lại rồi nhấp vào Tiếp tục.
Bước 2: Định cấu hình công việc điều chỉnh siêu tham số
Chọn Bật tính năng điều chỉnh siêu tham số.
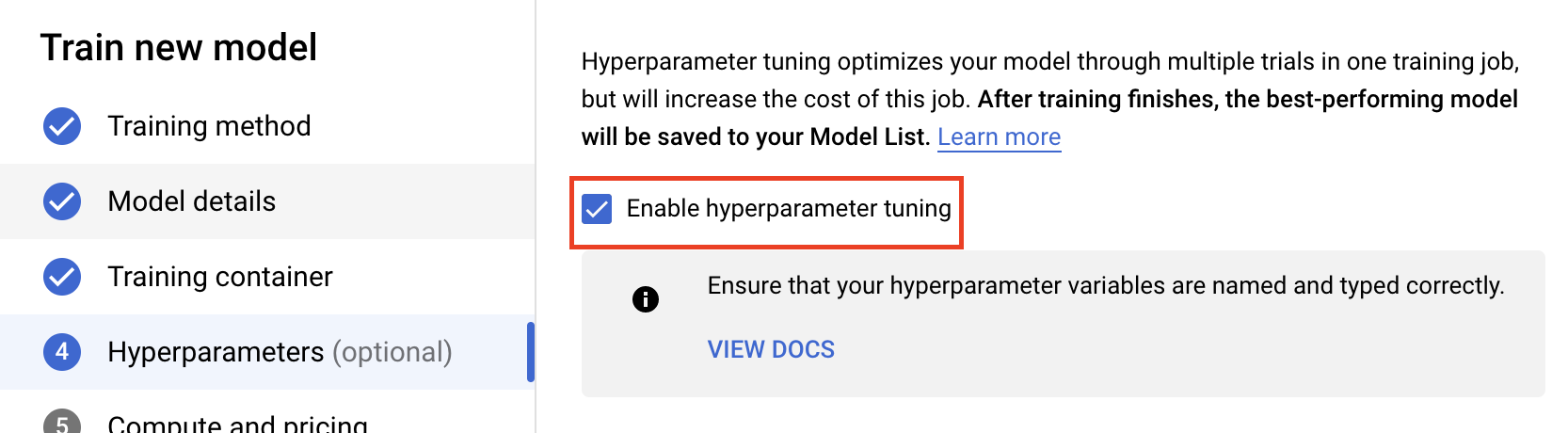
Định cấu hình siêu tham số
Tiếp theo, bạn cần thêm các siêu tham số mà bạn đặt làm đối số dòng lệnh trong mã xử lý ứng dụng huấn luyện. Khi thêm một siêu tham số, trước tiên, bạn cần cung cấp tên. Tên này phải khớp với tên đối số mà bạn đã truyền đến argparse.

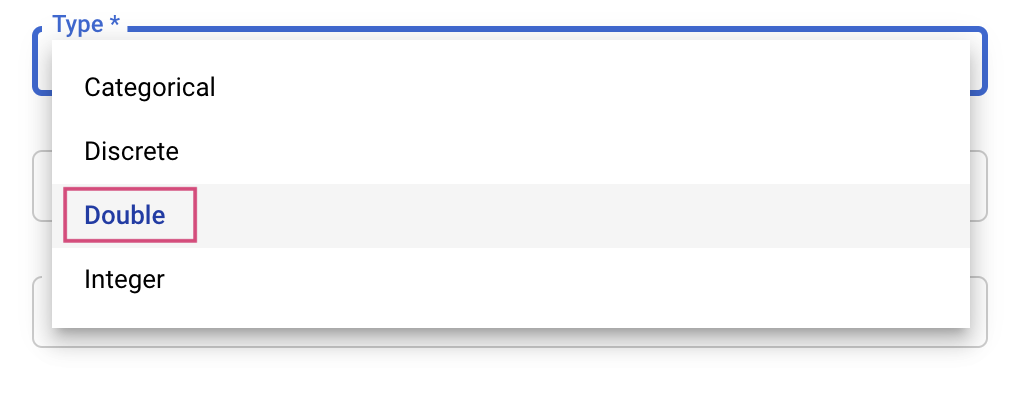
Sau đó, bạn sẽ chọn Loại cũng như ranh giới cho các giá trị mà dịch vụ điều chỉnh sẽ thử. Nếu chọn loại Double hoặc Integer, bạn cần cung cấp giá trị tối thiểu và tối đa. Và nếu chọn Categorical hoặc Discrete, bạn cần cung cấp các giá trị.

Đối với các loại Double và Integer, bạn cũng cần cung cấp giá trị Tỷ lệ.
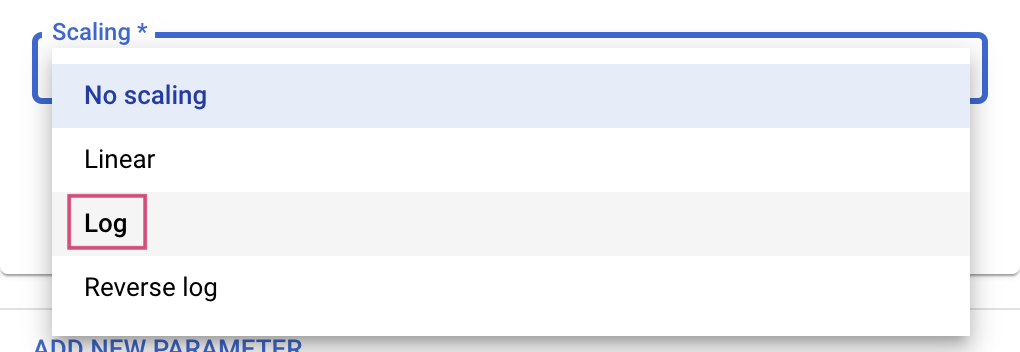
Sau khi thêm siêu tham số learning_rate, hãy thêm các tham số cho momentum và num_units.


Định cấu hình chỉ số
Sau khi thêm các siêu tham số, tiếp theo, bạn sẽ cung cấp chỉ số mà bạn muốn tối ưu hoá cũng như mục tiêu. Chỉ số này phải giống với hyperparameter_metric_tag mà bạn đã đặt trong ứng dụng huấn luyện.
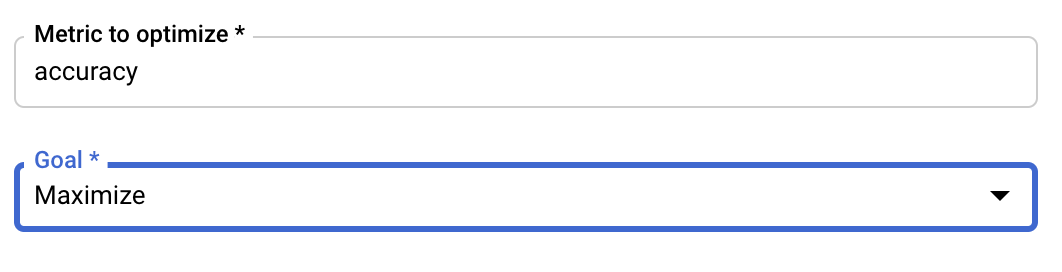
Dịch vụ điều chỉnh siêu tham số Vertex AI sẽ chạy nhiều lần thử ứng dụng huấn luyện của bạn với các giá trị được định cấu hình trong các bước trước. Bạn cần đặt một giới hạn trên cho số lần thử mà dịch vụ sẽ chạy. Thông thường, càng nhiều lần thử thì kết quả càng tốt, nhưng sẽ có một điểm lợi nhuận giảm dần sau đó các lần thử bổ sung sẽ ít hoặc không ảnh hưởng đến chỉ số mà bạn đang cố gắng tối ưu hoá. Bạn nên bắt đầu với một số lần thử nhỏ hơn và cảm nhận được mức độ ảnh hưởng của các siêu tham số đã chọn trước khi tăng lên một số lần thử lớn.
Bạn cũng cần đặt một giới hạn trên cho số lần thử song song. Việc tăng số lần thử song song sẽ giảm thời gian chạy công việc điều chỉnh siêu tham số; tuy nhiên, điều này có thể làm giảm hiệu quả của công việc nói chung. Lý do là vì chiến lược điều chỉnh mặc định sử dụng kết quả của các lần thử trước để thông báo việc gán giá trị trong các lần thử tiếp theo. Nếu bạn chạy quá nhiều lần thử song song, sẽ có những lần thử bắt đầu mà không có lợi ích từ kết quả của các lần thử vẫn đang chạy.
Để minh hoạ, bạn có thể đặt số lần thử là 15 và số lần thử song song tối đa là 3. Bạn có thể thử nghiệm với các số khác nhau, nhưng điều này có thể dẫn đến thời gian điều chỉnh lâu hơn và chi phí cao hơn.

Bước cuối cùng là chọn Mặc định làm thuật toán tìm kiếm, thuật toán này sẽ sử dụng Google Vizier để thực hiện tối ưu hoá Bayesian cho việc điều chỉnh siêu tham số. Bạn có thể tìm hiểu thêm về thuật toán này tại đây.
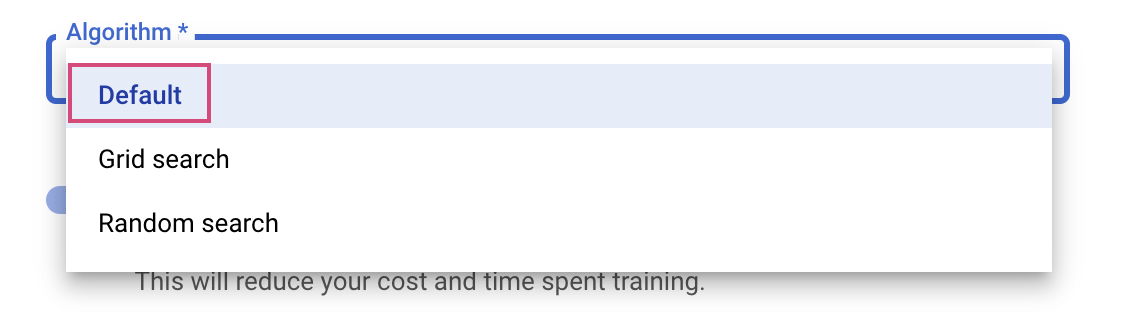
Nhấp vào Tiếp tục.
Bước 3: Định cấu hình tính toán
Trong phần Tính toán và giá, hãy để nguyên vùng đã chọn và định cấu hình Nhóm nhân viên 0 như sau.
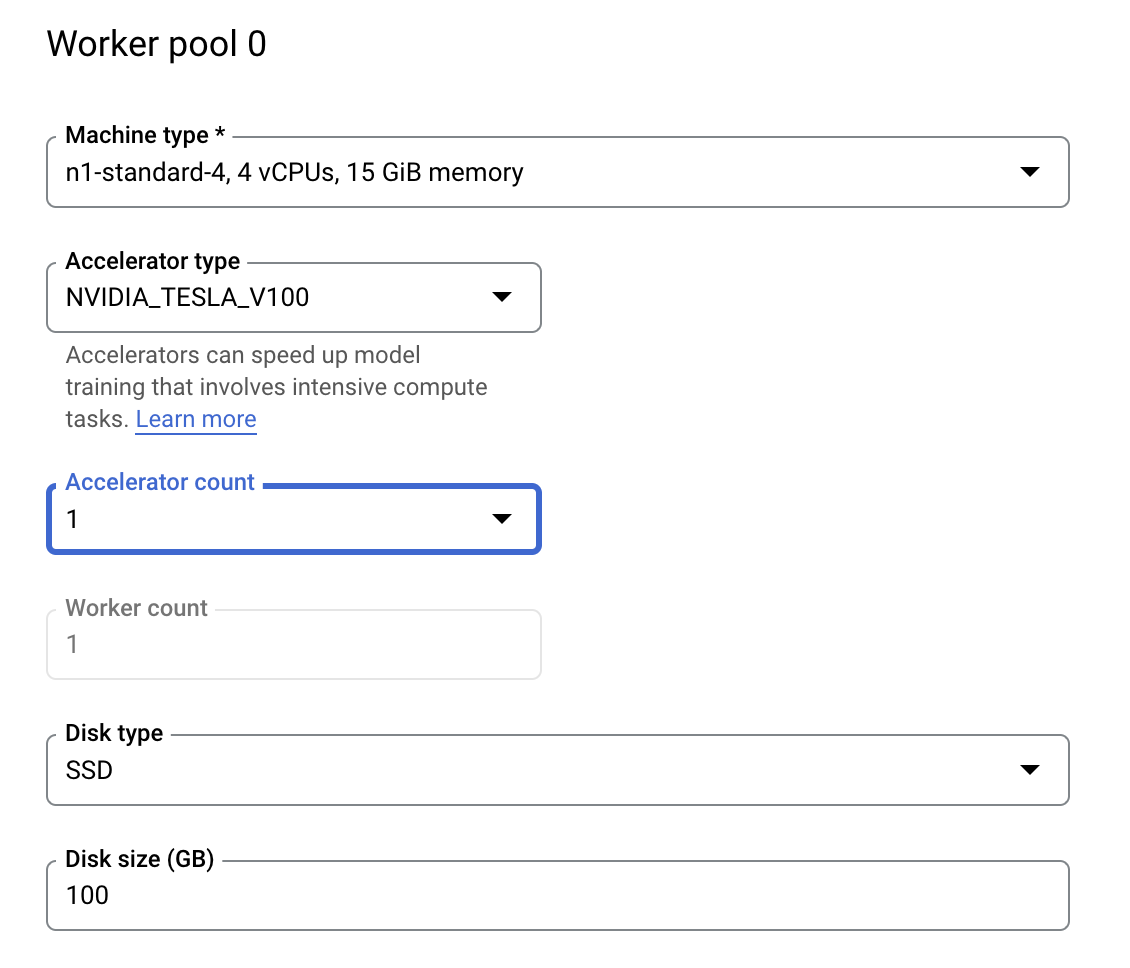
Nhấp vào Bắt đầu huấn luyện để bắt đầu công việc điều chỉnh siêu tham số. Trong phần Huấn luyện của bảng điều khiển, trên thẻ CÔNG VIỆC ĐIỀU CHỈNH SIÊU THAM SỐ, bạn sẽ thấy nội dung như sau:
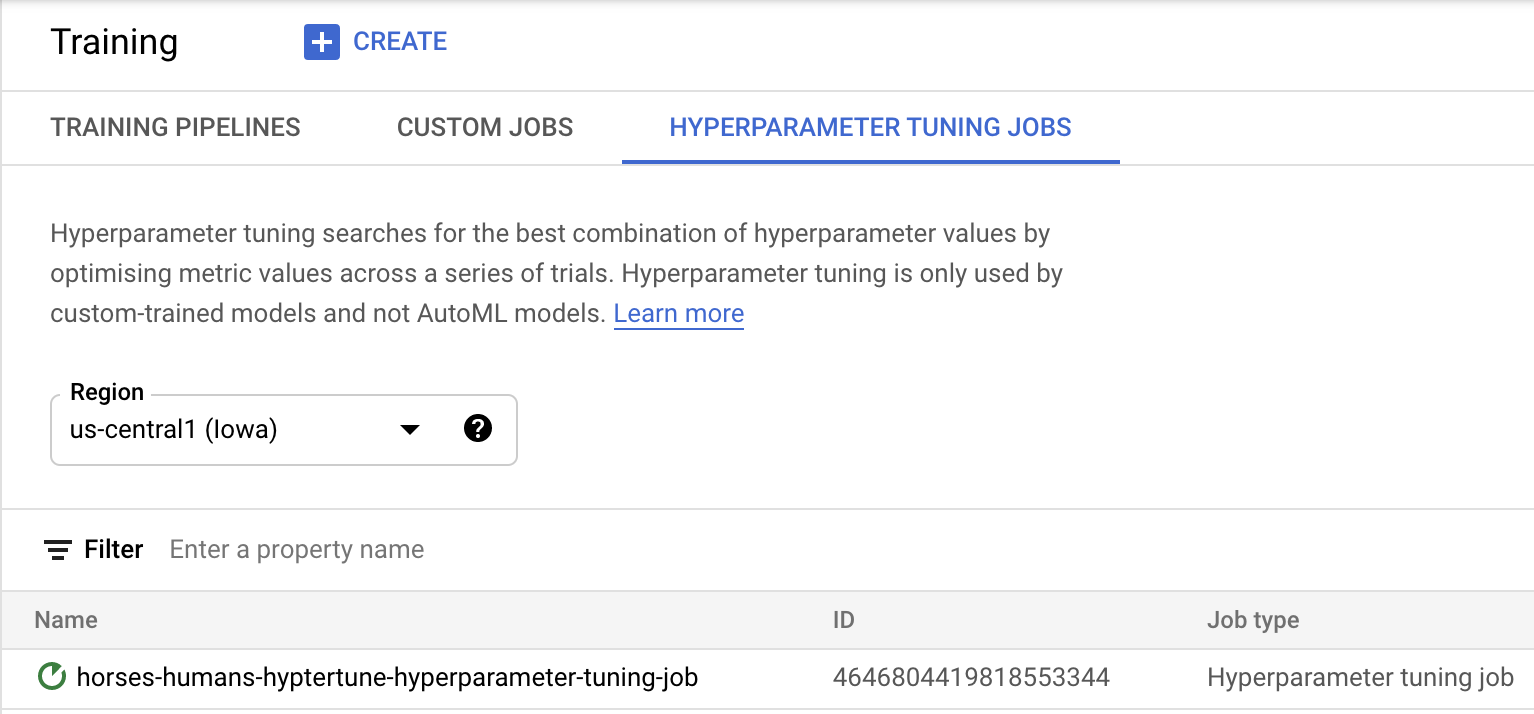
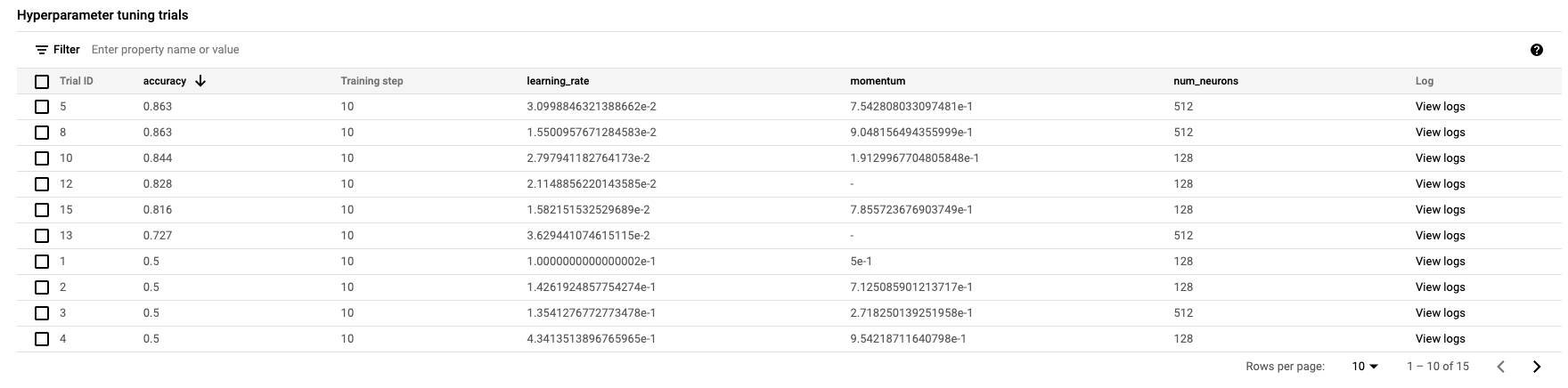
Khi hoàn tất, bạn có thể nhấp vào tên công việc và xem kết quả của các lần thử điều chỉnh.
🎉 Xin chúc mừng! 🎉
Bạn đã tìm hiểu cách sử dụng Vertex AI để:
- Chạy một công việc điều chỉnh siêu tham số cho mã huấn luyện được cung cấp trong một vùng chứa tuỳ chỉnh. Bạn đã sử dụng mô hình TensorFlow trong ví dụ này, nhưng bạn có thể huấn luyện một mô hình được xây dựng bằng bất kỳ khung nào bằng cách sử dụng các vùng chứa tuỳ chỉnh.
Để tìm hiểu thêm về các phần khác nhau của Vertex, hãy xem tài liệu.
6. [Không bắt buộc] Sử dụng Vertex SDK
Phần trước đã hướng dẫn cách chạy công việc điều chỉnh siêu tham số thông qua giao diện người dùng. Trong phần này, bạn sẽ thấy một cách khác để gửi công việc điều chỉnh siêu tham số bằng cách sử dụng Vertex Python API.
Trong Trình chạy, hãy tạo một sổ tay TensorFlow 2.

Nhập Vertex AI SDK.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Để chạy công việc điều chỉnh siêu tham số, trước tiên, bạn cần xác định các thông số kỹ thuật sau. Bạn cần thay thế {PROJECT_ID} trong image_uri bằng dự án của mình.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "gcr.io/{PROJECT_ID}/horse-human:hypertune"
}
}]
# Dictionary representing metrics to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Tiếp theo, hãy tạo một CustomJob. Bạn cần thay thế {YOUR_BUCKET} bằng một vùng chứa trong dự án của mình để dàn dựng.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='horses-humans-sdk-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Sau đó, hãy tạo và chạy HyperparameterTuningJob.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='horses-humans-sdk-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
7. Dọn dẹp
Vì chúng tôi đã định cấu hình sổ tay để hết thời gian chờ sau 60 phút không hoạt động, nên bạn không cần lo lắng về việc tắt thực thể. Nếu muốn tắt thực thể theo cách thủ công, hãy nhấp vào nút Dừng trên phần Vertex AI Workbench của bảng điều khiển. Nếu muốn xoá hoàn toàn sổ tay, hãy nhấp vào nút Xoá.

Để xoá Vùng chứa lưu trữ, hãy sử dụng trình đơn Điều hướng trong Cloud Console, duyệt đến phần Lưu trữ, chọn vùng chứa rồi nhấp vào Xoá: