1. Übersicht
In diesem Lab verwenden Sie Vertex AI, um einen Trainingsjob mit mehreren Workern für ein TensorFlow-Modell auszuführen.
Lerninhalte
Die folgenden Themen werden behandelt:
- Trainingsanwendungscode für das Training mit mehreren Workern ändern
- Multi-Worker-Trainingsjob über die Vertex AI-Benutzeroberfläche konfigurieren und starten
- Training mit mehreren Worker-Instanzen mit dem Vertex SDK konfigurieren und starten
Die Gesamtkosten für die Ausführung dieses Labs in Google Cloud betragen etwa 5$.
2. Einführung in Vertex AI
In diesem Lab wird das neueste KI-Produkt von Google Cloud verwendet. Vertex AI vereint die ML-Angebote von Google Cloud in einer nahtlosen Entwicklungsumgebung. Bisher musste auf mit AutoML trainierte und benutzerdefinierte Modelle über verschiedene Dienste zugegriffen werden. Das neue Angebot kombiniert diese und weitere, neue Produkte zu einer einzigen API. Sie können auch vorhandene Projekte zu Vertex AI migrieren. Wenn Sie Feedback haben, lesen Sie bitte die Supportseite.
Vertex AI umfasst viele verschiedene Produkte zur Unterstützung von End-to-End-ML-Workflows. In diesem Lab geht es um die unten hervorgehobenen Produkte: Training und Workbench.

3. Übersicht über Anwendungsfälle
In diesem Lab verwenden Sie Transfer Learning, um ein Bildklassifizierungsmodell mit dem Maniok-Dataset aus TensorFlow Datasets zu trainieren. Die verwendete Architektur ist ein ResNet50-Modell aus der tf.keras.applications-Bibliothek, das mit dem Imagenet-Dataset vortrainiert wurde.
Warum verteiltes Training?
Wenn Sie eine einzelne GPU haben, verwendet TensorFlow diesen Beschleuniger, um das Modelltraining zu beschleunigen. Sie müssen dafür nichts weiter tun. Wenn Sie jedoch zusätzliche Leistung durch die Verwendung mehrerer GPUs auf einem einzelnen Computer oder mehreren Computern (jeweils mit potenziell mehreren GPUs) erzielen möchten, müssen Sie tf.distribute verwenden. Das ist die TensorFlow-Bibliothek zum Ausführen einer Berechnung auf mehreren Geräten. Ein Gerät bezieht sich auf eine CPU oder einen Beschleuniger wie GPUs oder TPUs auf einem Computer, auf dem TensorFlow Operationen ausführen kann.
Der einfachste Weg, mit dem verteilten Training zu beginnen, ist eine einzelne Maschine mit mehreren GPU-Geräten. Eine TensorFlow-Verteilungsstrategie aus dem Modul tf.distribute übernimmt die Koordination der Datenverteilung und der Gradientenaktualisierungen auf allen GPUs. Wenn Sie das Training auf einem einzelnen Host beherrschen und die Leistung noch weiter steigern möchten, können Sie Ihrem Cluster mehrere Computer hinzufügen. Sie können einen Cluster von Maschinen verwenden, die nur CPUs haben oder die jeweils eine oder mehrere GPUs haben. In diesem Lab wird der zweite Fall behandelt. Es wird gezeigt, wie Sie MultiWorkerMirroredStrategy verwenden, um das Training eines TensorFlow-Modells auf mehrere Maschinen in Vertex AI zu verteilen.
MultiWorkerMirroredStrategy ist eine synchrone Datenparallelitätsstrategie, die Sie mit nur wenigen Codeänderungen verwenden können. Auf jedem Gerät in Ihrem Cluster wird eine Kopie des Modells erstellt. Die nachfolgenden Gradientenaktualisierungen erfolgen synchron. Das bedeutet, dass jedes Worker-Gerät die Vorwärts- und Rückwärtsdurchläufe durch das Modell für einen anderen Teil der Eingabedaten berechnet. Die berechneten Gradienten aus jedem dieser Segmente werden dann über alle Geräte auf einer Maschine und alle Maschinen im Cluster hinweg aggregiert und in einem Prozess, der als „All-Reduce“ bezeichnet wird, reduziert (in der Regel ein Durchschnitt). Der Optimierer führt dann die Parameteraktualisierungen mit diesen reduzierten Gradienten durch, wodurch die Geräte synchronisiert bleiben. Weitere Informationen zum verteilten Training mit TensorFlow finden Sie im folgenden Video:
4. Umgebung einrichten
Für dieses Codelab benötigen Sie ein Google Cloud Platform-Projekt mit aktivierter Abrechnung. Folgen Sie dieser Anleitung, um ein Projekt zu erstellen.
Schritt 1: Compute Engine API aktivieren
Rufen Sie Compute Engine auf und wählen Sie Aktivieren aus, falls die API noch nicht aktiviert ist. Sie benötigen diese, um Ihre Notebook-Instanz zu erstellen.
Schritt 2: Container Registry API aktivieren
Rufen Sie die Container Registry auf und wählen Sie Aktivieren aus, falls noch nicht geschehen. Damit erstellen Sie einen Container für Ihren benutzerdefinierten Trainingsjob.
Schritt 3: Vertex AI API aktivieren
Rufen Sie den Vertex AI-Bereich Ihrer Cloud Console auf und klicken Sie auf Vertex AI API aktivieren.

Schritt 4: Vertex AI Workbench-Instanz erstellen
Klicken Sie in der Cloud Console im Bereich „Vertex AI“ auf „Workbench“:
Aktivieren Sie die Notebooks API, falls sie noch nicht aktiviert ist.

Klicken Sie nach der Aktivierung auf VERWALTETE NOTEBOOKS:

Wählen Sie dann NEUES NOTEBOOK aus.

Geben Sie einen Namen für das Notebook ein und klicken Sie auf Erweiterte Einstellungen.

Aktivieren Sie unter „Erweiterte Einstellungen“ das Herunterfahren bei Inaktivität und legen Sie die Anzahl der Minuten auf 60 fest. Das bedeutet, dass Ihr Notebook automatisch heruntergefahren wird, wenn es nicht verwendet wird, damit keine unnötigen Kosten anfallen.

Wählen Sie unter Sicherheit die Option „Terminal aktivieren“ aus, falls sie noch nicht aktiviert ist.

Alle anderen erweiterten Einstellungen können Sie unverändert lassen.
Klicken Sie auf Erstellen. Die Bereitstellung der Instanz kann einige Minuten dauern.
Nachdem die Instanz erstellt wurde, klicken Sie auf JupyterLab öffnen.

Wenn Sie eine neue Instanz zum ersten Mal verwenden, werden Sie aufgefordert, sich zu authentifizieren. Folgen Sie dazu der Anleitung auf der Benutzeroberfläche.

5. Trainingsanwendungscode containerisieren
Sie senden diesen Trainingsjob an Vertex, indem Sie den Code Ihrer Trainingsanwendung in einen Docker-Container einfügen und diesen Container in die Google Container Registry übertragen. Mit diesem Ansatz können Sie ein Modell trainieren, das mit einem beliebigen Framework erstellt wurde.
Öffnen Sie zuerst über das Launcher-Menü ein Terminalfenster in Ihrer Notebook-Instanz:

Erstellen Sie ein neues Verzeichnis mit dem Namen cassava und wechseln Sie dorthin:
mkdir cassava
cd cassava
Schritt 1: Dockerfile erstellen
Der erste Schritt beim Containerisieren Ihres Codes ist das Erstellen eines Dockerfile. Das Dockerfile enthält alle Befehle, die zum Ausführen des Images erforderlich sind. Dadurch werden alle erforderlichen Bibliotheken installiert und der Einstiegspunkt für den Trainingscode eingerichtet.
Erstellen Sie über Ihr Terminal ein leeres Dockerfile:
touch Dockerfile
Öffnen Sie das Dockerfile und kopieren Sie Folgendes hinein:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
In diesem Dockerfile wird das Deep Learning Container TensorFlow Enterprise 2.7-GPU-Docker-Image verwendet. In den Deep Learning-Containern in Google Cloud sind viele gängige ML- und Data-Science-Frameworks vorinstalliert. Nachdem Sie dieses Image heruntergeladen haben, wird mit diesem Dockerfile der Einstiegspunkt für den Trainingscode eingerichtet. Sie haben diese Dateien noch nicht erstellt. Im nächsten Schritt fügen Sie den Code zum Trainieren und Optimieren des Modells hinzu.
Schritt 2: Cloud Storage-Bucket erstellen
In diesem Trainingsjob exportieren Sie das trainierte TensorFlow-Modell in einen Cloud Storage-Bucket. Führen Sie im Terminal den folgenden Befehl aus, um eine Umgebungsvariable für Ihr Projekt zu definieren. Ersetzen Sie dabei your-cloud-project durch die ID Ihres Projekts:
PROJECT_ID='your-cloud-project'
Führen Sie als Nächstes den folgenden Befehl im Terminal aus, um einen neuen Bucket in Ihrem Projekt zu erstellen.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Schritt 3: Code für das Modelltraining hinzufügen
Führen Sie im Terminal den folgenden Befehl aus, um ein Verzeichnis für den Trainingscode und eine Python-Datei zu erstellen, in die Sie den Code einfügen:
mkdir trainer
touch trainer/task.py
Ihr cassava/-Verzeichnis sollte jetzt Folgendes enthalten:
+ Dockerfile
+ trainer/
+ task.py
Öffnen Sie dann die gerade erstellte Datei task.py und kopieren Sie den folgenden Code. Ersetzen Sie {your-gcs-bucket} durch den Namen des Cloud Storage-Buckets, den Sie gerade erstellt haben.
import tensorflow as tf
import tensorflow_datasets as tfds
import os
PER_REPLICA_BATCH_SIZE = 64
EPOCHS = 2
# TODO: replace {your-gcs-bucket} with the name of the Storage bucket you created earlier
BUCKET = 'gs://{your-gcs-bucket}/mwms'
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
def create_dataset(batch_size):
'''Loads Cassava dataset and preprocesses data.'''
data, info = tfds.load(name='cassava', as_supervised=True, with_info=True)
number_of_classes = info.features['label'].num_classes
train_data = data['train'].map(preprocess_data,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(batch_size)
train_data = train_data.prefetch(tf.data.experimental.AUTOTUNE)
# Set AutoShardPolicy
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
train_data = train_data.with_options(options)
return train_data, number_of_classes
def create_model(number_of_classes):
'''Creates and compiles pretrained ResNet50 model.'''
base_model = tf.keras.applications.ResNet50(weights='imagenet', include_top=False)
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(1016, activation='relu')(x)
predictions = tf.keras.layers.Dense(number_of_classes, activation='softmax')(x)
model = tf.keras.Model(inputs=base_model.input, outputs=predictions)
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.0001),
metrics=['accuracy'])
return model
def _is_chief(task_type, task_id):
'''Helper function. Determines if machine is chief.'''
return task_type == 'chief'
def _get_temp_dir(dirpath, task_id):
'''Helper function. Gets temporary directory for saving model.'''
base_dirpath = 'workertemp_' + str(task_id)
temp_dir = os.path.join(dirpath, base_dirpath)
tf.io.gfile.makedirs(temp_dir)
return temp_dir
def write_filepath(filepath, task_type, task_id):
'''Helper function. Gets filepath to save model.'''
dirpath = os.path.dirname(filepath)
base = os.path.basename(filepath)
if not _is_chief(task_type, task_id):
dirpath = _get_temp_dir(dirpath, task_id)
return os.path.join(dirpath, base)
def main():
# Create strategy
strategy = tf.distribute.MultiWorkerMirroredStrategy()
# Get data
global_batch_size = PER_REPLICA_BATCH_SIZE * strategy.num_replicas_in_sync
train_data, number_of_classes = create_dataset(global_batch_size)
# Wrap variable creation within strategy scope
with strategy.scope():
model = create_model(number_of_classes)
model.fit(train_data, epochs=EPOCHS)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(BUCKET, task_type, task_id)
model.save(write_model_path)
if __name__ == "__main__":
main()
Bevor wir den Container erstellen, sehen wir uns den Code genauer an. Er verwendet MultiWorkerMirroredStrategy aus der tf.distribute.Strategy API.
Es gibt einige Komponenten im Code, die erforderlich sind, damit Ihr Code mit MultiWorkerMirroredStrategy funktioniert.
- Die Daten müssen partitioniert werden. Das bedeutet, dass jedem Worker eine Teilmenge des gesamten Datasets zugewiesen wird. Daher wird in jedem Schritt eine globale Batchgröße von nicht überlappenden Datensatzelementen von jedem Worker verarbeitet. Die Aufteilung erfolgt automatisch mit
tf.data.experimental.AutoShardPolicy, das aufFILEoderDATAfestgelegt werden kann. In diesem Beispiel wird mit der Funktioncreate_dataset()der WertAutoShardPolicyaufDATAfestgelegt, da das Maniok-Dataset nicht als mehrere Dateien heruntergeladen wird. Wenn Sie die Richtlinie jedoch nicht aufDATAfestgelegt haben, würde die StandardrichtlinieAUTOgreifen und das Endergebnis wäre dasselbe. Weitere Informationen zum Aufteilen von Datasets mitMultiWorkerMirroredStrategy - In der Funktion
main()wird das ObjektMultiWorkerMirroredStrategyerstellt. Als Nächstes umschließen Sie die Erstellung Ihrer Modellvariablen mit dem Bereich der Strategie. Mit diesem wichtigen Schritt wird TensorFlow mitgeteilt, welche Variablen über die Replikate hinweg gespiegelt werden sollen. - Die Batchgröße wird durch
num_replicas_in_syncskaliert. So wird sichergestellt, dass jedes Replikat in jedem Schritt dieselbe Anzahl von Beispielen verarbeitet. Das Skalieren der Batchgröße ist eine Best Practice, wenn Sie synchrone Strategien für Datenparallelität in TensorFlow verwenden. - Das Speichern des Modells ist im Fall mit mehreren Workern etwas komplizierter, da das Ziel für jeden Worker unterschiedlich sein muss. Der Haupt-Worker speichert das Modell im gewünschten Modellverzeichnis, während die anderen Worker das Modell in temporären Verzeichnissen speichern. Es ist wichtig, dass diese temporären Verzeichnisse eindeutig sind, damit nicht mehrere Worker an denselben Speicherort schreiben. Das Speichern kann kollektive Vorgänge enthalten. Das bedeutet, dass alle Worker speichern müssen und nicht nur der Chef. Die Funktionen
_is_chief(),_get_temp_dir(),write_filepath()sowie die Funktionmain()enthalten Boilerplate-Code, mit dem das Modell gespeichert werden kann.
Wenn Sie MultiWorkerMirroredStrategy in einer anderen Umgebung verwendet haben, haben Sie möglicherweise die Umgebungsvariable TF_CONFIG eingerichtet. Vertex AI legt TF_CONFIG automatisch für Sie fest. Sie müssen diese Variable also nicht auf jeder Maschine in Ihrem Cluster definieren.
Schritt 4: Container erstellen
Führen Sie im Terminal den folgenden Befehl aus, um eine Umgebungsvariable für Ihr Projekt zu definieren. Ersetzen Sie dabei your-cloud-project durch die ID Ihres Projekts:
PROJECT_ID='your-cloud-project'
Definieren Sie eine Variable mit dem URI Ihres Container-Images in der Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/multiworker:cassava"
Docker konfigurieren
gcloud auth configure-docker
Erstellen Sie dann den Container, indem Sie den folgenden Befehl im Stammverzeichnis Ihres cassava-Verzeichnisses ausführen:
docker build ./ -t $IMAGE_URI
Übertragen Sie es schließlich per Push in die Google Container Registry:
docker push $IMAGE_URI
Nachdem Sie den Container in Container Registry hochgeladen haben, können Sie den Trainingsjob starten.
6. Training mit mehreren Worker-Instanzen in Vertex AI ausführen
In diesem Lab wird benutzerdefiniertes Training über einen benutzerdefinierten Container in Google Container Registry verwendet. Sie können einen Trainingsjob aber auch mit den vordefinierten Containern ausführen.
Rufen Sie zuerst in der Cloud Console im Bereich „Vertex“ den Abschnitt Training auf:

Schritt 1: Trainingsjob konfigurieren
Klicken Sie auf Erstellen, um die Parameter für Ihren Trainingsjob einzugeben.
- Wählen Sie unter Dataset die Option Kein verwaltetes Dataset aus.
- Wählen Sie dann Benutzerdefiniertes Training (erweitert) als Trainingsmethode aus und klicken Sie auf Weiter.
- Geben Sie
multiworker-cassava(oder einen beliebigen anderen Namen für Ihr Modell) für Modellname ein. - Klicken Sie auf Weiter.
Wählen Sie im Schritt „Containereinstellungen“ die Option Benutzerdefinierter Container aus:

Geben Sie im ersten Feld (Container-Image) den Wert Ihrer IMAGE_URI-Variablen aus dem vorherigen Abschnitt ein. Sie sollte so aussehen: gcr.io/your-cloud-project/multiworker:cassava, wobei Sie Ihre eigene Projekt-ID verwenden. Lassen Sie die anderen Felder leer und klicken Sie auf Weiter.
Überspringen Sie den Schritt „Hyperparameter“ noch einmal, indem Sie auf Weiter klicken.
Schritt 2: Compute-Cluster konfigurieren
Vertex AI bietet vier Worker-Pools für die verschiedenen Arten von Maschinenaufgaben.
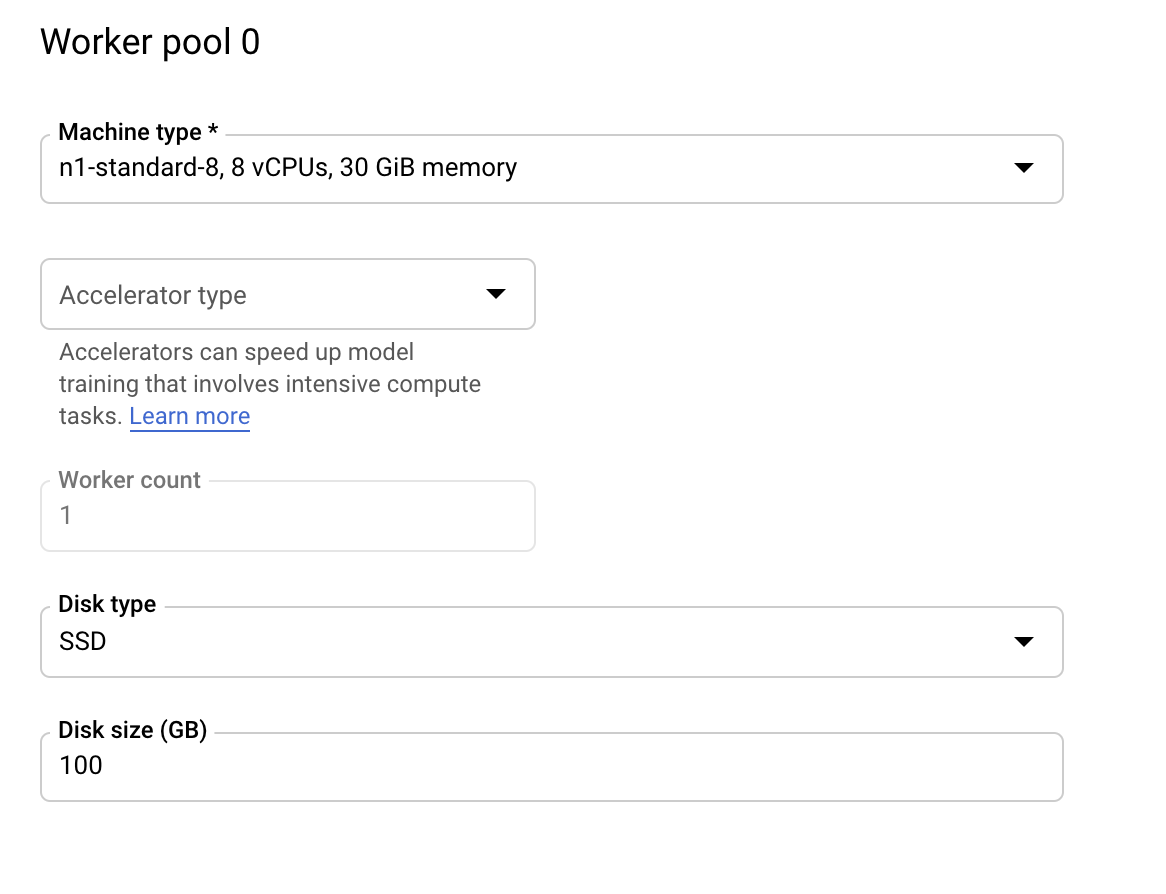
Mit Worker-Pool 0 wird der primäre, Chief-, Scheduler- oder „Master“-Worker konfiguriert. In MultiWorkerMirroredStrategy werden alle Maschinen als Worker bezeichnet. Das sind die physischen Maschinen, auf denen die replizierte Berechnung ausgeführt wird. Neben den einzelnen Maschinen, die als Worker fungieren, muss es einen Worker geben, der zusätzliche Aufgaben übernimmt, z. B. das Speichern von Checkpoints und das Schreiben von Zusammenfassungsdateien für TensorBoard. Diese Maschine wird als „Chief“ bezeichnet. Es gibt immer nur einen Chef-Worker. Die Anzahl der Worker für Worker-Pool 0 ist also immer 1.
Lassen Sie unter Computing und Preise die ausgewählte Region unverändert und konfigurieren Sie Worker-Pool 0 so:
In Worker-Pool 1 konfigurieren Sie die Worker für Ihren Cluster.
Konfigurieren Sie Worker-Pool 1 so:

Der Cluster ist jetzt für zwei reine CPU-Maschinen konfiguriert. Wenn der Trainingsanwendungscode ausgeführt wird, verteilt MultiWorkerMirroredStrategy das Training auf beide Maschinen.
MultiWorkerMirroredStrategy hat nur die Tasktypen „Chef“ und „Worker“, sodass keine zusätzlichen Worker-Pools konfiguriert werden müssen. Wenn Sie jedoch ParameterServerStrategy von TensorFlow verwenden, würden Sie Ihre Parameterserver in Worker-Pool 2 konfigurieren. Wenn Sie Ihrem Cluster einen Evaluator hinzufügen möchten, konfigurieren Sie diese Maschine in Worker-Pool 3.
Klicken Sie auf Training starten, um den Hyperparameter-Abstimmungsjob zu starten. Im Bereich „Training“ der Konsole wird auf dem Tab TRAINING PIPELINES (TRAININGSPIPELINES) der neu gestartete Job angezeigt:

🎉 Das wars! 🎉
Sie haben gelernt, wie Sie Vertex AI für folgende Aufgaben verwenden:
- Starten Sie einen Trainingsjob mit mehreren Workern für Trainingscode, der in einem benutzerdefinierten Container bereitgestellt wird. In diesem Beispiel haben Sie ein TensorFlow-Modell verwendet. Sie können jedoch ein Modell, das mit einem beliebigen Framework erstellt wurde, mit benutzerdefinierten oder integrierten Containern trainieren.
Weitere Informationen zu den verschiedenen Bereichen von Vertex finden Sie in der Dokumentation.
7. [Optional] Vertex SDK verwenden
Im vorherigen Abschnitt wurde gezeigt, wie Sie den Trainingsjob über die Benutzeroberfläche starten. In diesem Abschnitt sehen Sie eine alternative Möglichkeit, den Trainingsjob mit der Vertex Python API zu senden.
Kehren Sie zu Ihrer Notebook-Instanz zurück und erstellen Sie über den Launcher ein TensorFlow 2-Notebook:

Importieren Sie das Vertex AI SDK.
from google.cloud import aiplatform
Um den Multi-Worker-Trainingsjob zu starten, müssen Sie zuerst die Worker-Pool-Spezifikation definieren. Die Verwendung von GPUs in der Spezifikation ist optional. Sie können accelerator_type und accelerator_count entfernen, wenn Sie einen reinen CPU-Cluster möchten, wie im vorherigen Abschnitt gezeigt.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace {YOUR-PROJECT-ID} with your project ID.
worker_pool_specs=[
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
},
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
}
]
Erstellen und führen Sie als Nächstes ein CustomJob aus. Sie müssen {YOUR_BUCKET} durch einen Bucket in Ihrem Projekt für das Staging ersetzen. Sie können denselben Bucket verwenden, den Sie zuvor erstellt haben.
# Replace YOUR_BUCKET
my_multiworker_job = aiplatform.CustomJob(display_name='multiworker-cassava-sdk',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
my_multiworker_job.run()
Im Bereich „Training“ Ihrer Konsole wird auf dem Tab BENUTZERDEFINIERTE JOBS Ihr Trainingsjob angezeigt:

8. Bereinigen
Da wir das Notebook so konfiguriert haben, dass es nach 60 Minuten Inaktivität ein Zeitlimit erreicht, müssen wir uns keine Gedanken über das Herunterfahren der Instanz machen. Wenn Sie die Instanz manuell herunterfahren möchten, klicken Sie im Bereich „Vertex AI Workbench“ der Console auf die Schaltfläche „Beenden“. Wenn Sie das Notebook vollständig löschen möchten, klicken Sie auf die Schaltfläche „Löschen“.

Wenn Sie den Storage-Bucket löschen möchten, rufen Sie in der Cloud Console über das Navigationsmenü „Storage“ auf, wählen Sie den Bucket aus und klicken Sie auf „Löschen“: