
1. Обзор
В этой лабораторной работе вы будете использовать Vertex AI для запуска многопроцессорного обучения модели TensorFlow.
Чему вы научитесь
Вы научитесь:
- Измените код приложения для обучения нескольких сотрудников.
- Настройте и запустите задачу обучения с участием нескольких рабочих процессов из пользовательского интерфейса Vertex AI.
- Настройте и запустите многопроцессорное задание обучения с помощью Vertex SDK.
Общая стоимость запуска этой лабораторной работы в Google Cloud составляет около 5 долларов .
2. Введение в Vertex AI
В этой лабораторной работе используется новейший продукт для искусственного интеллекта, доступный в Google Cloud. Vertex AI интегрирует предложения машинного обучения в Google Cloud в единый процесс разработки. Ранее модели, обученные с помощью AutoML, и пользовательские модели были доступны через отдельные сервисы. Новое предложение объединяет оба варианта в единый API, а также включает другие новые продукты. Вы также можете перенести существующие проекты в Vertex AI. Если у вас есть какие-либо замечания, пожалуйста, посетите страницу поддержки .
Vertex AI предлагает множество различных продуктов для поддержки комплексных рабочих процессов машинного обучения. В этой лабораторной работе мы сосредоточимся на продуктах, перечисленных ниже: Training и Workbench.

3. Обзор вариантов использования
В этой лабораторной работе вы будете использовать трансферное обучение для обучения модели классификации изображений на наборе данных cassava из TensorFlow Datasets . В качестве архитектуры вы будете использовать модель ResNet50 из библиотеки tf.keras.applications , предварительно обученную на наборе данных Imagenet.
Почему именно дистанционное обучение?
Если у вас всего один графический процессор (GPU), TensorFlow будет использовать этот ускоритель для ускорения обучения модели без каких-либо дополнительных усилий с вашей стороны. Однако, если вы хотите получить дополнительный прирост производительности за счет использования нескольких графических процессоров на одной или нескольких машинах (каждая из которых потенциально может иметь несколько графических процессоров), вам потребуется использовать tf.distribute — библиотеку TensorFlow для выполнения вычислений на нескольких устройствах. Устройство — это центральный процессор (CPU) или ускоритель, такой как графический процессор (GPU) или тензорный процессор (TPU), на какой-либо машине, на которой TensorFlow может выполнять операции.
Простейший способ начать работу с распределенным обучением — это использовать одну машину с несколькими графическими процессорами. Стратегия распределения TensorFlow из модуля tf.distribute будет управлять координацией распределения данных и обновления градиентов на всех графических процессорах. Если вы освоили обучение на одном хосте и хотите масштабировать систему еще больше, добавление нескольких машин в кластер поможет вам добиться еще большего повышения производительности. Вы можете использовать кластер машин, работающих только на ЦП, или машин, каждая из которых имеет один или несколько графических процессоров. В этой лабораторной работе рассматривается последний случай и демонстрируется, как использовать MultiWorkerMirroredStrategy для распределения обучения модели TensorFlow между несколькими машинами на Vertex AI.
MultiWorkerMirroredStrategy — это стратегия синхронного параллелизма данных, которую можно использовать всего с несколькими изменениями в коде. Копия модели создается на каждом устройстве в вашем кластере. Последующие обновления градиентов будут происходить синхронно. Это означает, что каждое рабочее устройство вычисляет прямые и обратные проходы через модель на разных срезах входных данных. Вычисленные градиенты из каждого из этих срезов затем агрегируются по всем устройствам на машине и по всем машинам в кластере и уменьшаются (обычно до среднего значения) в процессе, известном как all-reduce. Затем оптимизатор выполняет обновление параметров с использованием этих уменьшенных градиентов, тем самым поддерживая синхронизацию устройств. Чтобы узнать больше о распределенном обучении с TensorFlow, посмотрите видео ниже:
4. Настройте свою среду.
Для выполнения этого практического задания вам потребуется проект Google Cloud Platform с включенной оплатой. Чтобы создать проект, следуйте инструкциям здесь .
Шаг 1: Включите API Compute Engine.
Перейдите в Compute Engine и выберите «Включить», если эта опция еще не включена. Она понадобится для создания экземпляра ноутбука.
Шаг 2: Включите API реестра контейнеров.
Перейдите в Реестр контейнеров и выберите «Включить», если эта опция еще не включена. Это позволит создать контейнер для вашей пользовательской задачи обучения.
Шаг 3: Включите API Vertex AI
Перейдите в раздел Vertex AI в вашей облачной консоли и нажмите «Включить API Vertex AI» .

Шаг 4: Создайте экземпляр Vertex AI Workbench.
В разделе Vertex AI вашей облачной консоли нажмите на Workbench:

Включите API для блокнотов, если он еще не включен.

После включения нажмите «УПРАВЛЯЕМЫЕ ЗАПИСНЫЕ КНИЖКИ» :

Затем выберите «Создать новый блокнот» .

Присвойте своему блокноту имя, а затем нажмите «Дополнительные настройки» .

В разделе «Дополнительные настройки» включите функцию автоматического выключения в режиме ожидания и установите количество минут равным 60. Это означает, что ваш ноутбук будет автоматически выключаться, когда не используется, чтобы избежать лишних расходов.

В разделе «Безопасность» выберите «Включить терминал», если он еще не включен.
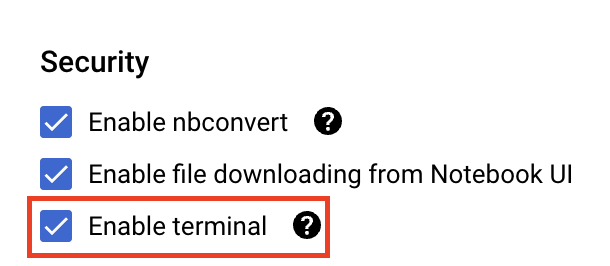
Все остальные расширенные настройки можно оставить без изменений.
Далее нажмите «Создать» . Создание экземпляра займет несколько минут.
После создания экземпляра выберите «Открыть JupyterLab» .

При первом использовании нового экземпляра вам будет предложено пройти аутентификацию. Для этого следуйте инструкциям в пользовательском интерфейсе.

5. Контейнеризация кода обучающего приложения
Для отправки задания на обучение в Vertex вам потребуется поместить код вашего обучающего приложения в контейнер Docker и загрузить этот контейнер в Google Container Registry . Используя этот подход, вы можете обучить модель, созданную с помощью любого фреймворка.
Для начала откройте окно Терминала в вашем ноутбуке из меню «Запуск»:

Создайте новую директорию с именем cassava и перейдите в неё с помощью команды cd:
mkdir cassava
cd cassava
Шаг 1: Создайте Dockerfile.
Первый шаг в контейнеризации вашего кода — создание Dockerfile. В Dockerfile вы укажете все команды, необходимые для запуска образа. Он установит все необходимые библиотеки и настроит точку входа для кода обучения.
Создайте пустой Dockerfile в терминале:
touch Dockerfile
Откройте Dockerfile и скопируйте в него следующее:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
В этом Dockerfile используется образ Docker для контейнеров глубокого обучения TensorFlow Enterprise 2.7 GPU . Контейнеры глубокого обучения в Google Cloud поставляются со множеством распространенных фреймворков для машинного обучения и анализа данных, предварительно установленных в них. После загрузки этого образа данный Dockerfile настраивает точку входа для кода обучения. Вы еще не создали эти файлы — на следующем шаге вы добавите код для обучения и настройки модели.
Шаг 2: Создайте сегмент облачного хранилища.
В этом задании по обучению вам нужно будет экспортировать обученную модель TensorFlow в хранилище Cloud Storage. В терминале выполните следующую команду, чтобы определить переменную окружения для вашего проекта, заменив your-cloud-project на идентификатор вашего проекта:
PROJECT_ID='your-cloud-project'
Далее выполните в терминале следующую команду, чтобы создать новый бакет в вашем проекте.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Шаг 3: Добавьте код для обучения модели.
В терминале выполните следующую команду, чтобы создать директорию для кода обучения и файл Python, куда вы добавите этот код:
mkdir trainer
touch trainer/task.py
Теперь в папке cassava/ у вас должно быть следующее:
+ Dockerfile
+ trainer/
+ task.py
Далее откройте только что созданный файл task.py и скопируйте приведенный ниже код. Вам нужно будет заменить {your-gcs-bucket} на имя созданного вами сегмента Cloud Storage.
import tensorflow as tf
import tensorflow_datasets as tfds
import os
PER_REPLICA_BATCH_SIZE = 64
EPOCHS = 2
# TODO: replace {your-gcs-bucket} with the name of the Storage bucket you created earlier
BUCKET = 'gs://{your-gcs-bucket}/mwms'
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
def create_dataset(batch_size):
'''Loads Cassava dataset and preprocesses data.'''
data, info = tfds.load(name='cassava', as_supervised=True, with_info=True)
number_of_classes = info.features['label'].num_classes
train_data = data['train'].map(preprocess_data,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(batch_size)
train_data = train_data.prefetch(tf.data.experimental.AUTOTUNE)
# Set AutoShardPolicy
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
train_data = train_data.with_options(options)
return train_data, number_of_classes
def create_model(number_of_classes):
'''Creates and compiles pretrained ResNet50 model.'''
base_model = tf.keras.applications.ResNet50(weights='imagenet', include_top=False)
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(1016, activation='relu')(x)
predictions = tf.keras.layers.Dense(number_of_classes, activation='softmax')(x)
model = tf.keras.Model(inputs=base_model.input, outputs=predictions)
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.0001),
metrics=['accuracy'])
return model
def _is_chief(task_type, task_id):
'''Helper function. Determines if machine is chief.'''
return task_type == 'chief'
def _get_temp_dir(dirpath, task_id):
'''Helper function. Gets temporary directory for saving model.'''
base_dirpath = 'workertemp_' + str(task_id)
temp_dir = os.path.join(dirpath, base_dirpath)
tf.io.gfile.makedirs(temp_dir)
return temp_dir
def write_filepath(filepath, task_type, task_id):
'''Helper function. Gets filepath to save model.'''
dirpath = os.path.dirname(filepath)
base = os.path.basename(filepath)
if not _is_chief(task_type, task_id):
dirpath = _get_temp_dir(dirpath, task_id)
return os.path.join(dirpath, base)
def main():
# Create strategy
strategy = tf.distribute.MultiWorkerMirroredStrategy()
# Get data
global_batch_size = PER_REPLICA_BATCH_SIZE * strategy.num_replicas_in_sync
train_data, number_of_classes = create_dataset(global_batch_size)
# Wrap variable creation within strategy scope
with strategy.scope():
model = create_model(number_of_classes)
model.fit(train_data, epochs=EPOCHS)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(BUCKET, task_type, task_id)
model.save(write_model_path)
if __name__ == "__main__":
main()
Прежде чем создавать контейнер, давайте подробнее рассмотрим код, который использует MultiWorkerMirroredStrategy из API tf.distribute.Strategy .
Для корректной работы вашего кода с MultiWorkerMirroredStrategy необходимо наличие нескольких компонентов.
- Данные необходимо сегментировать, то есть каждому рабочему процессу назначается подмножество всего набора данных. Таким образом, на каждом шаге каждый рабочий процесс будет обрабатывать глобальный размер пакета непересекающихся элементов набора данных. Это сегментирование происходит автоматически с помощью
tf.data.experimental.AutoShardPolicy, который может быть установлен в значениеFILEилиDATA. В этом примере функцияcreate_dataset()устанавливаетAutoShardPolicyвDATAпоскольку набор данных о маниоке не загружается в виде нескольких файлов. Однако, если бы вы не установили политику вDATA, сработала бы политикаAUTOпо умолчанию, и конечный результат был бы тем же. Подробнее о сегментировании набора данных с помощьюMultiWorkerMirroredStrategyможно узнать здесь. - В функции
main()создается объектMultiWorkerMirroredStrategy. Затем вы заключаете создание переменных вашей модели в область действия стратегии. Этот важный шаг сообщает TensorFlow, какие переменные должны быть зеркально отображены между репликами. - Размер пакета увеличивается на величину
num_replicas_in_sync. Это гарантирует, что каждая реплика обрабатывает одинаковое количество примеров на каждом шаге. Масштабирование размера пакета является рекомендуемой практикой при использовании стратегий синхронного параллелизма данных в TensorFlow. - Сохранение модели в случае многопроцессорной обработки несколько сложнее, поскольку место назначения должно быть разным для каждого из процессов. Главный процесс сохранит модель в нужную директорию, а остальные процессы сохранят её во временные директории. Важно, чтобы эти временные директории были уникальными, чтобы предотвратить запись несколькими процессами в одно и то же место. Сохранение может включать коллективные операции, то есть сохранение должны выполняться всеми процессами, а не только главным. Функции
_is_chief(),_get_temp_dir(),write_filepath(), а также функцияmain()содержат шаблонный код, помогающий сохранить модель.
Обратите внимание, что если вы использовали MultiWorkerMirroredStrategy в другой среде, вы могли настроить переменную среды TF_CONFIG . Vertex AI автоматически устанавливает TF_CONFIG , поэтому вам не нужно определять эту переменную на каждой машине в вашем кластере.
Шаг 4: Создайте контейнер
В терминале выполните следующую команду, чтобы определить переменную окружения для вашего проекта, заменив your-cloud-project на идентификатор вашего проекта:
PROJECT_ID='your-cloud-project'
Создайте переменную с URI образа вашего контейнера в реестре Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/multiworker:cassava"
Настройка Docker
gcloud auth configure-docker
Затем соберите контейнер, выполнив следующую команду из корневой директории вашего каталога cassava :
docker build ./ -t $IMAGE_URI
Наконец, загрузите его в реестр контейнеров Google:
docker push $IMAGE_URI
После загрузки контейнера в Реестр контейнеров вы готовы приступить к обучению.
6. Запустите задачу обучения с участием нескольких рабочих процессов на Vertex AI.
В этой лабораторной работе используется пользовательское обучение с помощью пользовательского контейнера в Google Container Registry, но вы также можете запустить задачу обучения с использованием предварительно созданных контейнеров.
Для начала перейдите в раздел «Обучение» в разделе Vertex вашей облачной консоли:

Шаг 1: Настройка задания обучения
Нажмите «Создать» , чтобы ввести параметры для вашего задания по обучению.
- В разделе «Набор данных» выберите «Нет управляемого набора данных» .
- Затем выберите в качестве метода обучения «Пользовательское обучение (расширенное)» и нажмите «Продолжить» .
- Введите
multiworker-cassava(или любое другое название вашей модели) в поле «Название модели» . - Нажмите «Продолжить»
На этапе настройки контейнера выберите «Пользовательский контейнер» :

В первом поле ( «Образ контейнера» ) введите значение вашей переменной IMAGE_URI из предыдущего раздела. Оно должно быть следующим: gcr.io/your-cloud-project/multiworker:cassava , указав идентификатор вашего проекта. Оставьте остальные поля пустыми и нажмите «Продолжить» .
Пропустите шаг с гиперпараметрами, снова нажав кнопку «Продолжить» .
Шаг 2: Настройка вычислительного кластера
Vertex AI предоставляет 4 пула рабочих процессов для выполнения различных типов машинных задач.
В пуле рабочих процессов 0 настраивается основной, главный, планировщик или «мастер». В MultiWorkerMirroredStrategy все машины назначаются рабочими, то есть физическими машинами, на которых выполняется реплицируемое вычисление. Помимо того, что каждая машина является рабочим, должен быть еще один рабочий, который выполняет дополнительную работу, например, сохранение контрольных точек и запись сводных файлов в TensorBoard. Эта машина называется главным. Главный рабочий всегда один, поэтому количество рабочих для пула рабочих процессов 0 всегда будет равно 1.
В разделе «Вычисления и ценообразование» оставьте выбранный регион без изменений и настройте пул рабочих процессов 0 следующим образом:

В пуле рабочих процессов 1 вы настраиваете рабочие процессы для вашего кластера.
Настройте пул рабочих процессов 1 следующим образом:
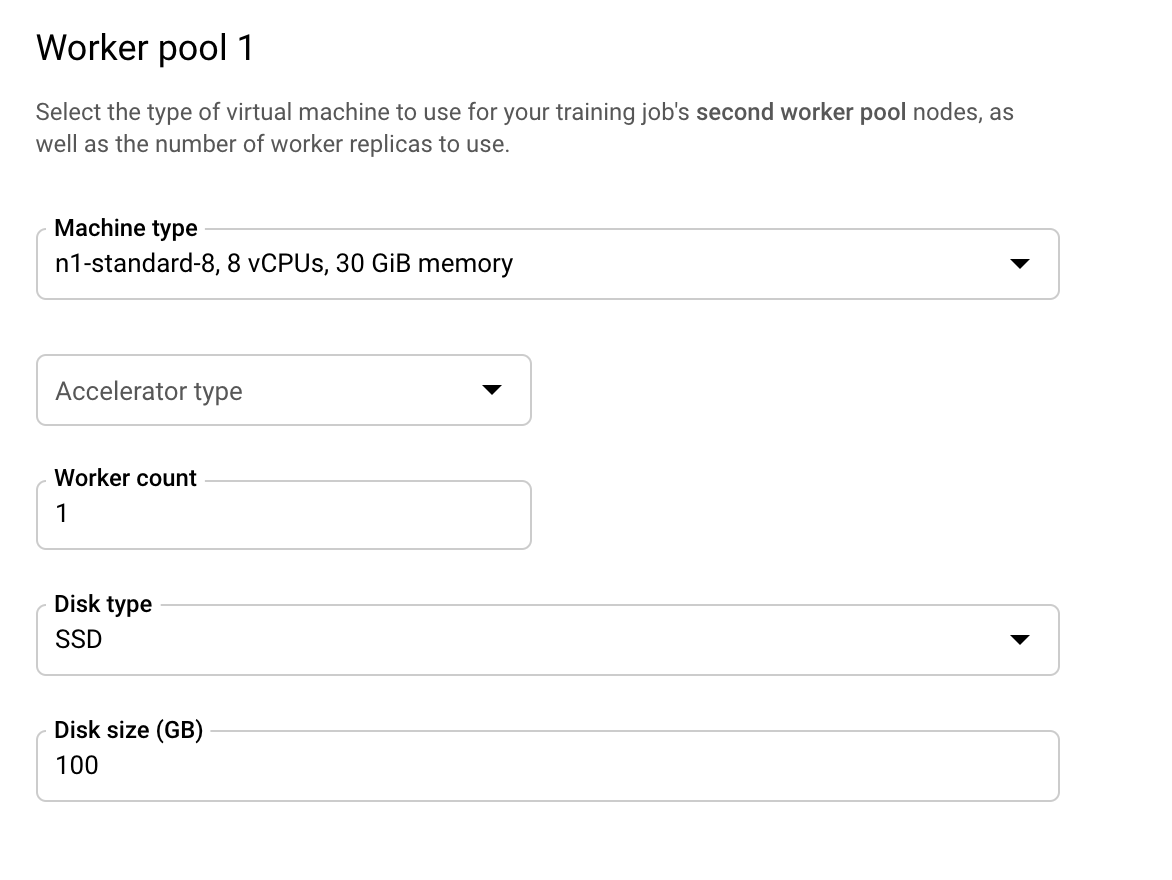
Теперь кластер настроен на использование двух машин только с процессорами. При запуске кода обучающего приложения MultiWorkerMirroredStrategy распределит обучение между обеими машинами.
MultiWorkerMirroredStrategy есть только типы задач chief и worker, поэтому нет необходимости настраивать дополнительные пулы Worker. Однако, если бы вы использовали ParameterServerStrategy от TensorFlow, вам пришлось бы настраивать серверы параметров в пуле Worker 2. А если бы вы хотели добавить в свой кластер оценщик, вам пришлось бы настраивать эту машину в пуле Worker 3 .
Нажмите «Начать обучение» , чтобы запустить задачу настройки гиперпараметров. В разделе «Обучение» вашей консоли на вкладке «КОНВЕЙЕРЫ ОБУЧЕНИЯ» вы увидите только что запущенную задачу:
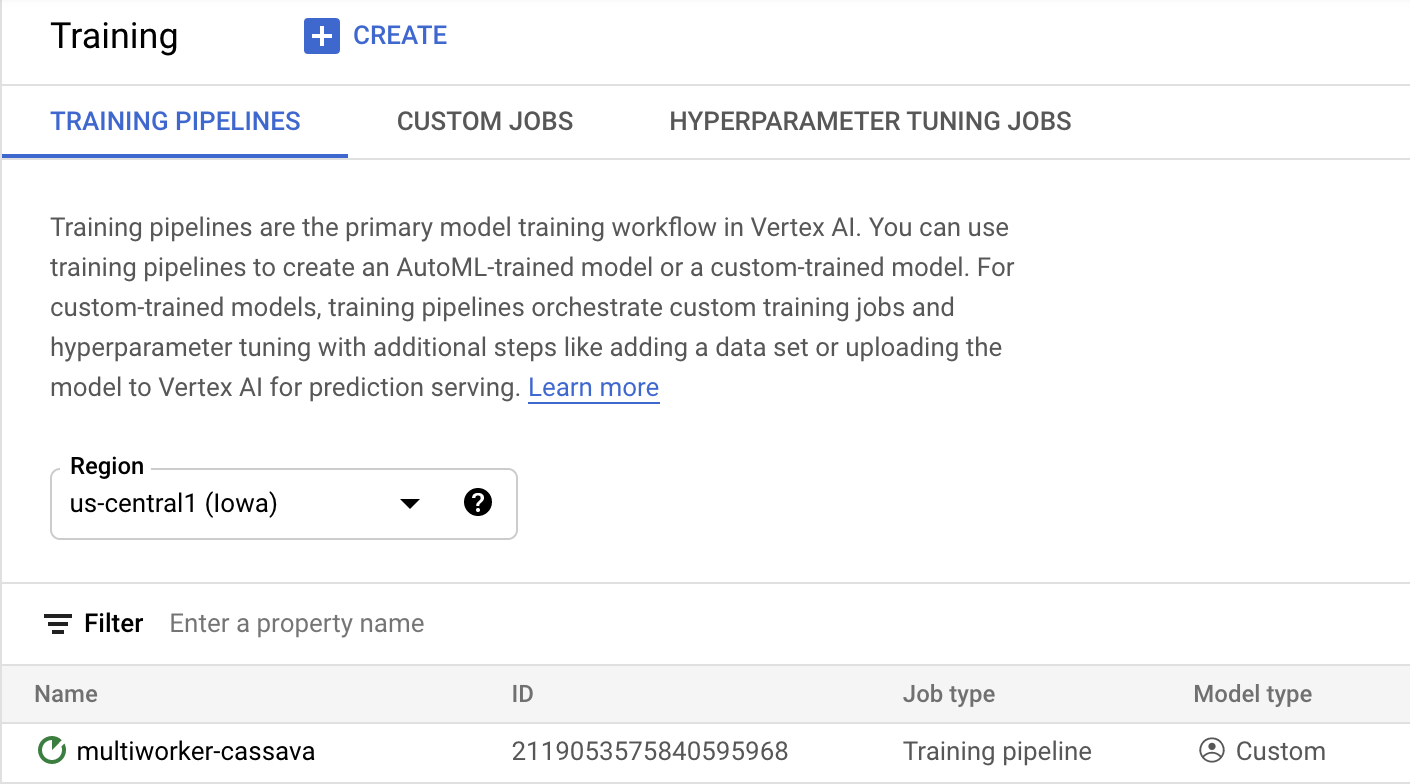
🎉 Поздравляем! 🎉
Вы научились использовать Vertex AI для:
- Запустите многопроцессорное задание обучения для кода обучения, предоставленного в пользовательском контейнере. В этом примере вы использовали модель TensorFlow, но вы можете обучить модель, созданную с помощью любой платформы, используя пользовательские или встроенные контейнеры.
Чтобы узнать больше о различных компонентах Vertex, ознакомьтесь с документацией .
7. [Необязательно] Используйте SDK Vertex.
В предыдущем разделе было показано, как запустить задачу обучения через пользовательский интерфейс. В этом разделе вы увидите альтернативный способ отправки задачи обучения с помощью API Vertex на Python.
Вернитесь к своему экземпляру блокнота и создайте блокнот TensorFlow 2 из панели запуска:

Импортируйте Vertex AI SDK.
from google.cloud import aiplatform
Для запуска многопроцессорного задания обучения необходимо сначала определить спецификацию пула рабочих процессов. Обратите внимание, что использование графических процессоров в спецификации является полностью необязательным, и вы можете удалить accelerator_type и accelerator_count если хотите использовать кластер только на ЦП, как показано в предыдущем разделе.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace {YOUR-PROJECT-ID} with your project ID.
worker_pool_specs=[
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
},
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
}
]
Далее создайте и запустите CustomJob . Вам нужно будет заменить {YOUR_BUCKET} на название корзины в вашем проекте для промежуточного хранения. Вы можете использовать ту же корзину, которую создали ранее.
# Replace YOUR_BUCKET
my_multiworker_job = aiplatform.CustomJob(display_name='multiworker-cassava-sdk',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
my_multiworker_job.run()
В разделе «Обучение» вашей консоли, на вкладке «ПОЛЬЗОВАТЕЛЬСКИЕ ЗАДАНИЯ», вы увидите свое задание на обучение:

8. Уборка
Поскольку мы настроили ноутбук на автоматическое завершение работы через 60 минут простоя, нам не нужно беспокоиться о выключении экземпляра. Если вы хотите выключить экземпляр вручную, нажмите кнопку «Стоп» в разделе Vertex AI Workbench в консоли. Если вы хотите полностью удалить ноутбук, нажмите кнопку «Удалить».

Чтобы удалить сегмент хранилища, воспользуйтесь меню навигации в консоли Cloud Console, перейдите в раздел «Хранилище», выберите свой сегмент и нажмите «Удалить».
