1. Panoramica
In questo lab imparerai a configurare e lanciare le esecuzioni di blocchi note con Vertex AI Workbench.
Cosa imparerai
Al termine del corso sarai in grado di:
- Utilizzare i parametri in un blocco note
- Configurare e avviare le esecuzioni di notebook dall'interfaccia utente di Vertex AI Workbench
Il costo totale per eseguire questo lab su Google Cloud è di circa 2$.
2. Introduzione a Vertex AI
Questo lab utilizza la più recente offerta di prodotti AI disponibile su Google Cloud. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. La nuova offerta combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Puoi anche migrare progetti esistenti su Vertex AI. In caso di feedback, consulta la pagina di supporto.
Vertex AI include molti prodotti diversi per supportare i flussi di lavoro ML end-to-end. Questo lab si concentrerà su Vertex AI Workbench.
Vertex AI Workbench aiuta gli utenti a creare rapidamente workflow end-to-end basati su notebook grazie all'integrazione profonda con i servizi di dati (come Dataproc, Dataflow, BigQuery e Dataplex) e Vertex AI. Consente ai data scientist di connettersi ai servizi di dati GCP, analizzare i set di dati, sperimentare diverse tecniche di modellazione, eseguire il deployment dei modelli addestrati in produzione e gestire MLOps durante il ciclo di vita del modello.
3. Panoramica del caso d'uso
In questo lab utilizzerai il transfer learning per addestrare un modello di classificazione delle immagini sul set di dati DeepWeeds di TensorFlow Datasets. Utilizzerai TensorFlow Hub per sperimentare con i vettori delle caratteristiche estratti da diverse architetture di modelli, come ResNet50, Inception e MobileNet, tutti preaddestrati sul set di dati di riferimento ImageNet. Sfruttando l'executor di notebook tramite la UI di Vertex AI Workbench, avvierai job su Vertex AI Training che utilizzano questi modelli preaddestrati e riaddestrerai l'ultimo livello per riconoscere le classi del set di dati DeepWeeds.
4. Configura l'ambiente
Per eseguire questo codelab, devi avere un progetto Google Cloud Platform con la fatturazione abilitata. Per creare un progetto, segui le istruzioni riportate qui.
Passaggio 1: abilita l'API Compute Engine
Vai a Compute Engine e seleziona Abilita se non è già abilitato.
Passaggio 2: attiva l'API Vertex AI
Accedi alla sezione Vertex AI della tua console Cloud e fai clic su Abilita API Vertex AI.
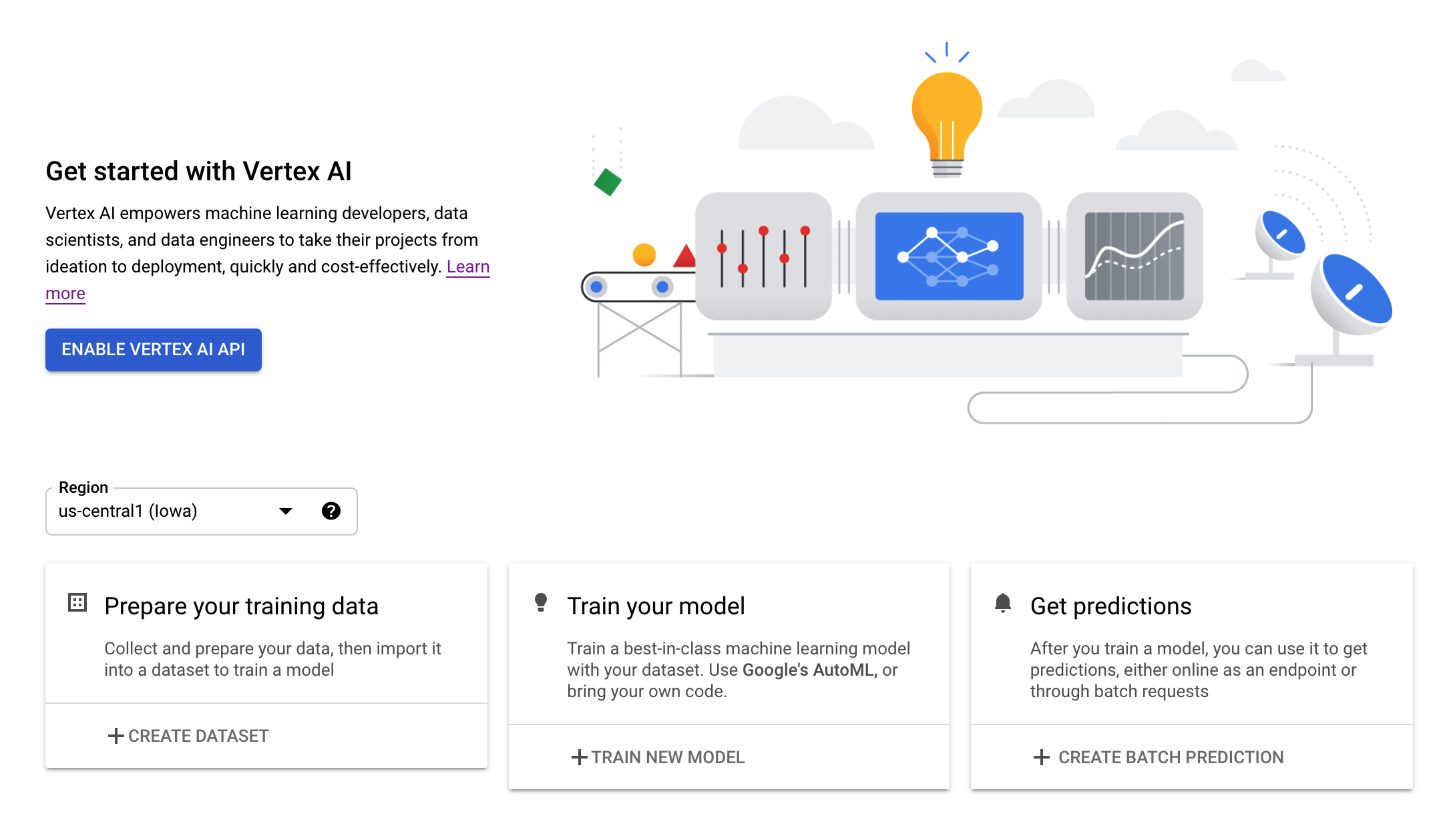
Passaggio 3: crea un'istanza di Vertex AI Workbench
Nella sezione Vertex AI della console Cloud, fai clic su Workbench:
Abilita l'API Notebooks, se non l'hai ancora fatto.
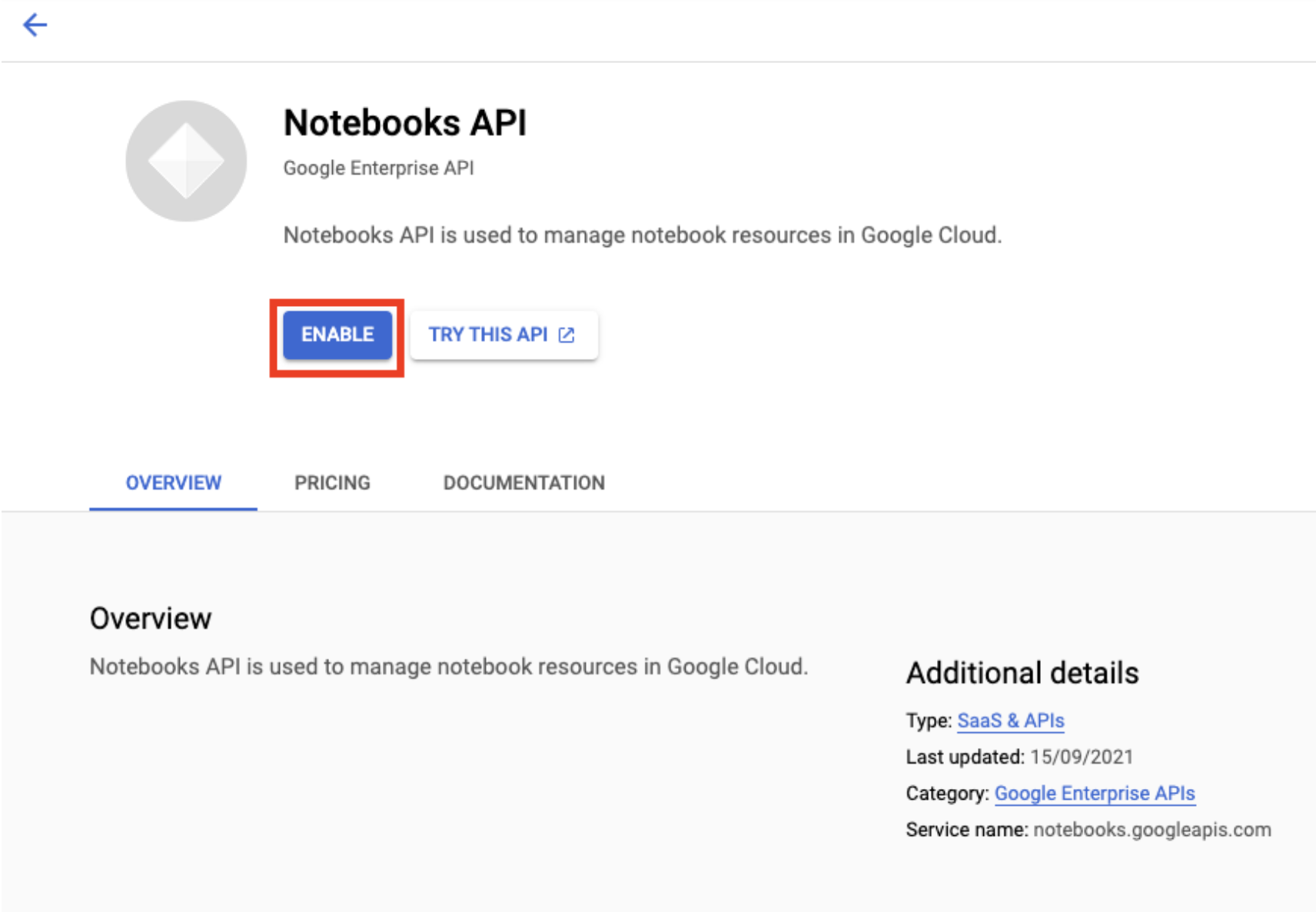
Una volta attivata, fai clic su BLOCCHI NOTE GESTITI:
Poi seleziona NUOVO QUADERNO.
Assegna un nome al notebook, quindi fai clic su Impostazioni avanzate.
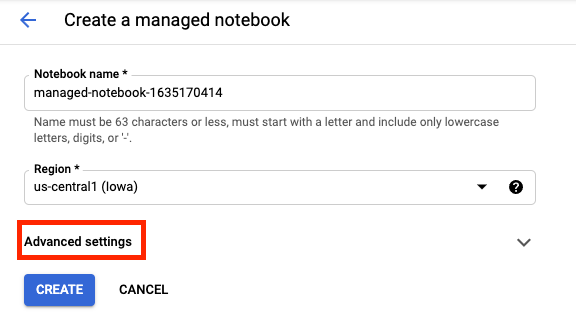
In Impostazioni avanzate, attiva l'arresto per inattività e imposta il numero di minuti su 60. Ciò significa che il notebook si spegnerà automaticamente quando non viene utilizzato, in modo da non sostenere costi non necessari.

Puoi lasciare invariate tutte le altre impostazioni avanzate.
Quindi, fai clic su Crea.
Una volta creata l'istanza, seleziona Apri JupyterLab.

La prima volta che utilizzi una nuova istanza, ti verrà chiesto di autenticarti.
Vertex AI Workbench dispone di un livello di compatibilità di calcolo che consente di avviare kernel per TensorFlow, PySpark, R e così via, tutto da una singola istanza notebook. Dopo l'autenticazione, potrai selezionare il tipo di notebook che vuoi utilizzare dal launcher.
Per questo lab, seleziona il kernel TensorFlow 2.

5. Scrivere il codice di allenamento
Il set di dati DeepWeeds è composto da 17.509 immagini che catturano otto diverse specie di erbe infestanti autoctone dell'Australia. In questa sezione scriverai il codice per preelaborare il set di dati DeepWeeds e creare e addestrare un modello di classificazione delle immagini utilizzando i vettori delle caratteristiche scaricati da TensorFlow Hub.
Dovrai copiare i seguenti snippet di codice nelle celle del notebook. L'esecuzione delle celle è facoltativa.
Passaggio 1: scarica ed elabora il set di dati
Innanzitutto, installa la versione notturna di TensorFlow Datasets per assicurarti di acquisire l'ultima versione del set di dati DeepWeeds.
!pip install tfds-nightly
Poi, importa le librerie necessarie:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Scarica i dati da TensorFlow Datasets ed estrai il numero di classi e le dimensioni del set di dati.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Definisci una funzione di pre-elaborazione per scalare i dati delle immagini di 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
Il set di dati DeepWeeds non include suddivisioni di addestramento/convalida. Viene fornito solo con un set di dati di addestramento. Nel codice riportato di seguito, utilizzerai l'80% di questi dati per l'addestramento e il restante 20% per la convalida.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Passaggio 2: crea il modello
Ora che hai creato i set di dati di addestramento e convalida, puoi creare il modello. TensorFlow Hub fornisce vettori delle caratteristiche, ovvero modelli preaddestrati senza il livello di classificazione superiore. Creerai un estrattore di caratteristiche eseguendo il wrapping del modello preaddestrato con hub.KerasLayer, che esegue il wrapping di un SavedModel di TensorFlow come livello Keras. Aggiungerai quindi un livello di classificazione e creerai un modello con l'API Keras Sequential.
Innanzitutto, definisci il parametro feature_extractor_model, ovvero il nome del vettore delle funzionalità di TensorFlow Hub che utilizzerai come base per il modello.
feature_extractor_model = "inception_v3"
Successivamente, trasformerai questa cella in una cella di parametri, che ti consentirà di inserire un valore per feature_extractor_model in fase di runtime.
Innanzitutto, seleziona la cella e fai clic sull'inspector delle proprietà nel riquadro a destra.
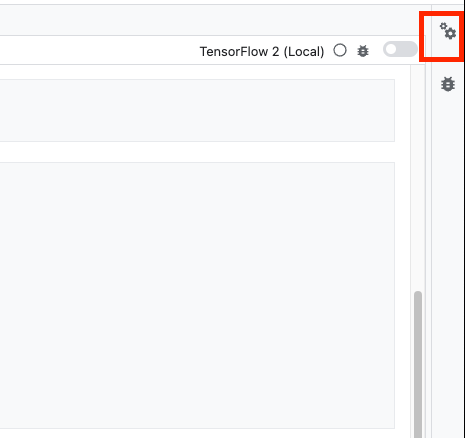
I tag sono un modo semplice per aggiungere metadati al tuo notebook. Digita "parametri" nella casella Aggiungi tag e premi Invio. In un secondo momento, durante la configurazione dell'esecuzione, passerai i diversi valori, in questo caso il modello TensorFlow Hub, che vuoi testare. Tieni presente che devi digitare la parola "parameters" (e non un'altra parola), perché è così che l'executor del notebook sa quali celle parametrizzare.

Puoi chiudere l'ispettore delle proprietà facendo di nuovo clic sull'icona dell'ingranaggio doppio.
Crea una nuova cella e definisci tf_hub_uri, dove utilizzerai l'interpolazione di stringhe per sostituire il nome del modello preaddestrato che vuoi utilizzare come modello di base per un'esecuzione specifica del notebook. Per impostazione predefinita, hai impostato feature_extractor_model su "inception_v3", ma altri valori validi sono "resnet_v2_50" o "mobilenet_v1_100_224". Puoi esplorare altre opzioni nel catalogo di TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
A questo punto, crea l'estrattore di funzionalità utilizzando hub.KerasLayer e passando tf_hub_uri che hai definito in precedenza. Imposta l'argomento trainable=False per bloccare le variabili in modo che l'addestramento modifichi solo il nuovo strato del classificatore che aggiungerai in alto.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Per completare il modello, racchiudi lo strato di estrazione delle caratteristiche in un modello tf.keras.Sequential e aggiungi un livello completamente connesso per la classificazione. Il numero di unità in questa intestazione di classificazione deve essere uguale al numero di classi nel set di dati:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Infine, compila e adatta il modello.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Esegui notebook
Fai clic sull'icona Executor nella parte superiore del blocco note.
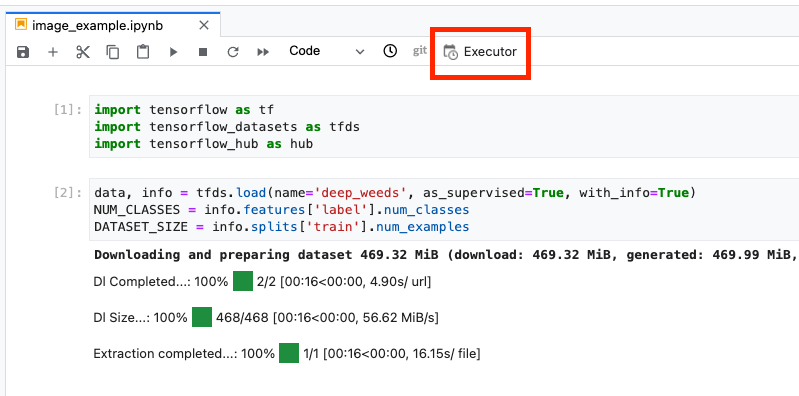
Passaggio 1: configura il job di addestramento
Assegna un nome all'esecuzione e fornisci un bucket di archiviazione nel tuo progetto.
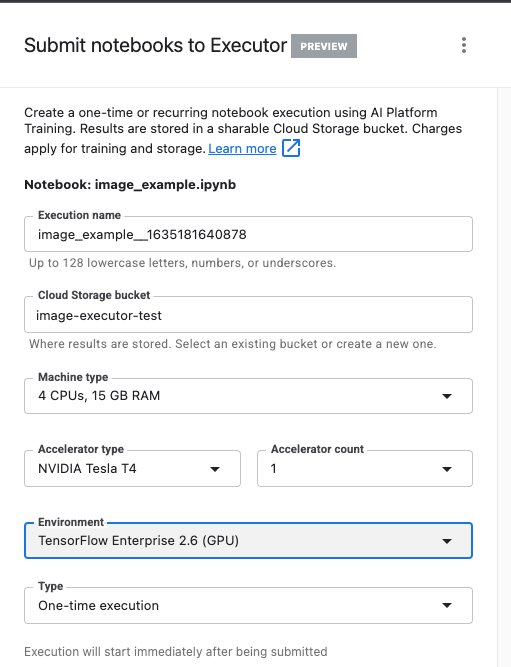
Imposta il tipo di macchina su 4 CPU, 15 GB di RAM.
e aggiungi 1 GPU NVIDIA.
Imposta l'ambiente su TensorFlow Enterprise 2.6 (GPU).
Scegli Esecuzione singola.
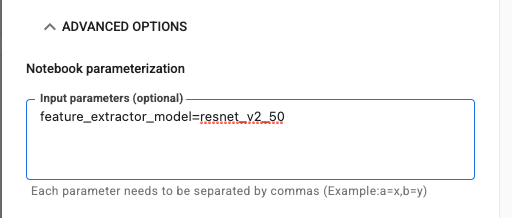
Passaggio 2: configura i parametri
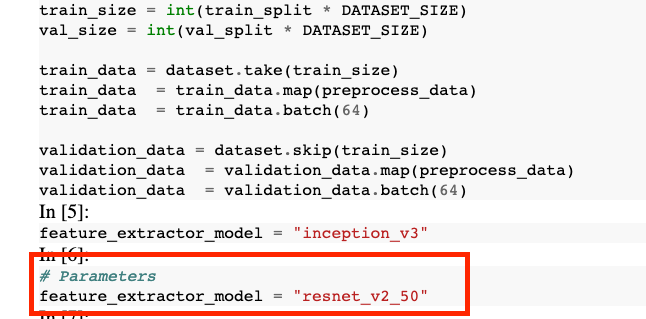
Fai clic sul menu a discesa OPZIONI AVANZATE per impostare il parametro. Nella casella, digita feature_extractor_model=resnet_v2_50. Questo sostituirà inception_v3, il valore predefinito impostato per questo parametro nel blocco note, con resnet_v2_50.
Puoi lasciare selezionata la casella Utilizza il service account predefinito.
Quindi, fai clic su INVIA.
Passaggio 3: esamina i risultati
Nella scheda Esecuzioni dell'interfaccia utente della console, potrai visualizzare lo stato dell'esecuzione del notebook.
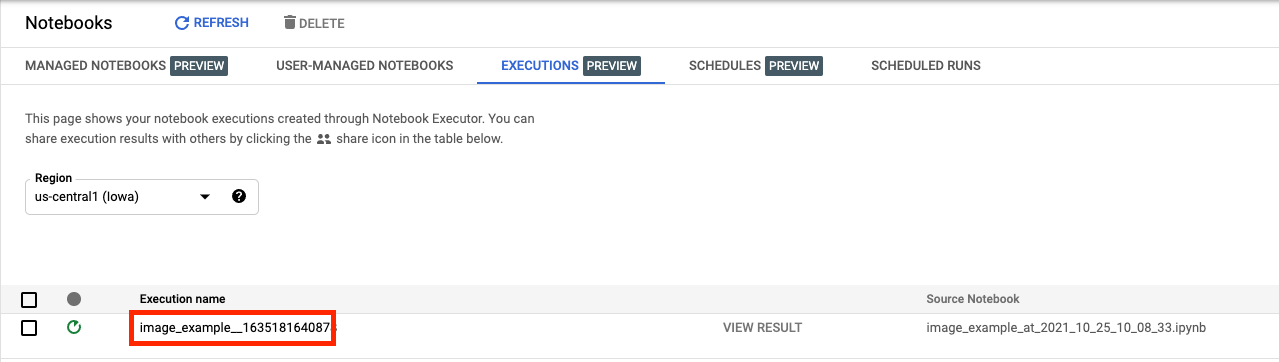
Se fai clic sul nome dell'esecuzione, si aprirà il job Vertex AI Training in cui è in esecuzione il notebook.
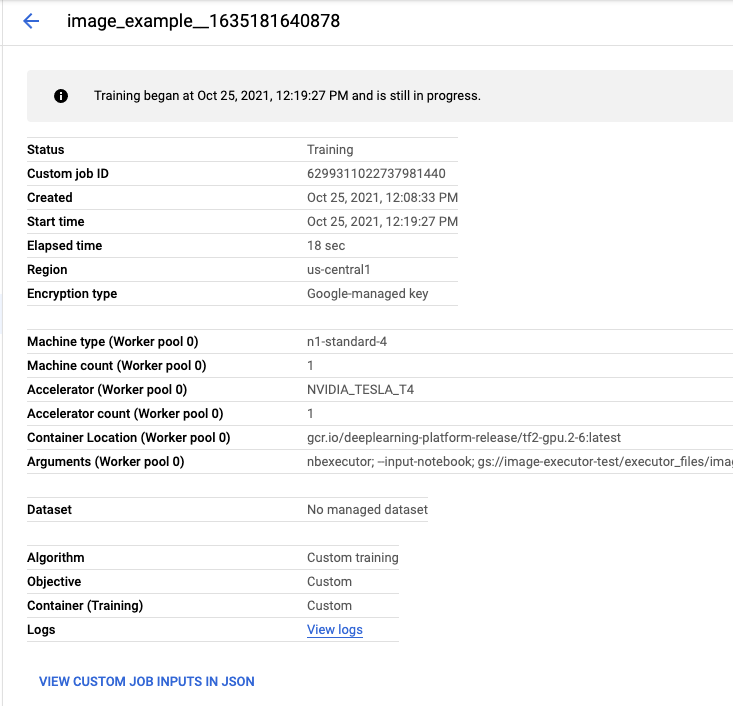
Al termine del job, potrai visualizzare il notebook di output facendo clic su VISUALIZZA RISULTATO.

Nel notebook di output, vedrai che il valore di feature_extractor_model è stato sovrascritto dal valore che hai passato in fase di runtime.
🎉 Congratulazioni! 🎉
Hai imparato a utilizzare Vertex AI Workbench per:
- Utilizzare i parametri in un blocco note
- Configurare e avviare le esecuzioni di notebook dall'interfaccia utente di Vertex AI Workbench
Per saperne di più sulle diverse parti di Vertex AI, consulta la documentazione.
7. Esegui la pulizia
Per impostazione predefinita, i blocchi note gestiti si spengono automaticamente dopo 180 minuti di inattività. Se vuoi arrestare manualmente l'istanza, fai clic sul pulsante Arresta nella sezione Vertex AI Workbench della console. Se vuoi eliminare completamente il blocco note, fai clic sul pulsante Elimina.

Per eliminare il bucket di archiviazione, utilizza il menu di navigazione nella console Google Cloud, vai a Storage, seleziona il bucket e fai clic su Elimina: