1. Übersicht
In diesem Lab erfahren Sie, wie Sie mit Vertex AI Workbench Notebook-Ausführungen konfigurieren und starten.
Lerninhalte
Die folgenden Themen werden behandelt:
- Parameter in einem Notebook verwenden
- Notebook-Ausführungen über die Vertex AI Workbench-UI konfigurieren und starten
Die Gesamtkosten für die Ausführung dieses Labs in Google Cloud betragen etwa 2$.
2. Einführung in Vertex AI
In diesem Lab wird das neueste KI-Produkt von Google Cloud verwendet. Vertex AI vereint die ML-Angebote von Google Cloud in einer nahtlosen Entwicklungsumgebung. Bisher musste auf mit AutoML trainierte und benutzerdefinierte Modelle über verschiedene Dienste zugegriffen werden. Das neue Angebot kombiniert diese und weitere, neue Produkte zu einer einzigen API. Sie können auch vorhandene Projekte zu Vertex AI migrieren. Wenn Sie Feedback haben, lesen Sie die Supportseite.
Vertex AI umfasst viele verschiedene Produkte zur Unterstützung von End-to-End-ML-Workflows. In diesem Lab konzentrieren wir uns auf Vertex AI Workbench.
Mit Vertex AI Workbench können Nutzer schnell End-to-End-Notebook-basierte Workflows erstellen. Dazu ist eine enge Integration mit Datendiensten wie Dataproc, Dataflow, BigQuery und Dataplex sowie mit Vertex AI erforderlich. Data Scientists können sich mit GCP-Datendiensten verbinden, Datasets analysieren, mit verschiedenen Modellierungstechniken experimentieren, trainierte Modelle in der Produktion bereitstellen und MLOps über den gesamten Modelllebenszyklus hinweg verwalten.
3. Anwendungsfallübersicht
In diesem Lab verwenden Sie Transfer Learning, um ein Bildklassifizierungsmodell für das DeepWeeds-Dataset aus TensorFlow Datasets zu trainieren. Mit TensorFlow Hub experimentieren Sie mit Featurevektoren, die aus verschiedenen Modellarchitekturen wie ResNet50, Inception und MobileNet extrahiert wurden. Alle wurden mit dem ImageNet-Benchmark-Dataset vortrainiert. Über den Notebook-Executor in der Vertex AI Workbench-UI starten Sie Jobs in Vertex AI Training, die diese vortrainierten Modelle verwenden und die letzte Ebene neu trainieren, um die Klassen aus dem DeepWeeds-Dataset zu erkennen.
4. Umgebung einrichten
Für dieses Codelab benötigen Sie ein Google Cloud-Projekt mit aktivierter Abrechnung. Eine Anleitung zum Erstellen eines Projekts finden Sie hier.
Schritt 1: Compute Engine API aktivieren
Rufen Sie Compute Engine auf und wählen Sie Aktivieren aus, falls die API noch nicht aktiviert ist.
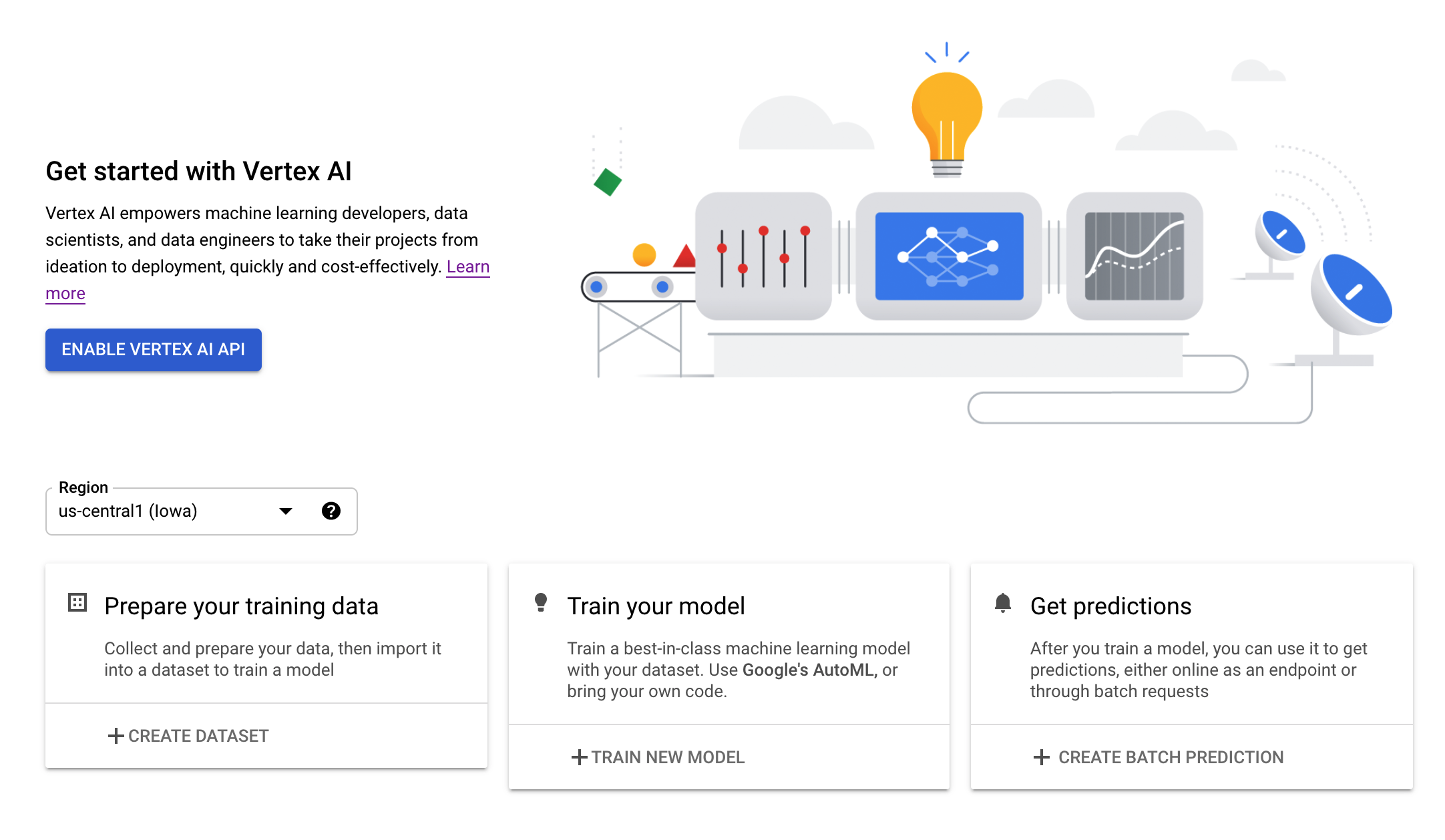
Schritt 2: Vertex AI API aktivieren
Rufen Sie den Bereich „Vertex AI“ in der Cloud Console auf und klicken Sie auf **Vertex AI API aktivieren**.
Schritt 3: Vertex AI Workbench-Instanz erstellen
Klicken Sie im Bereich „Vertex AI“ der Cloud Console auf „Workbench“:
Aktivieren Sie die Notebooks API, falls sie noch nicht aktiviert ist.
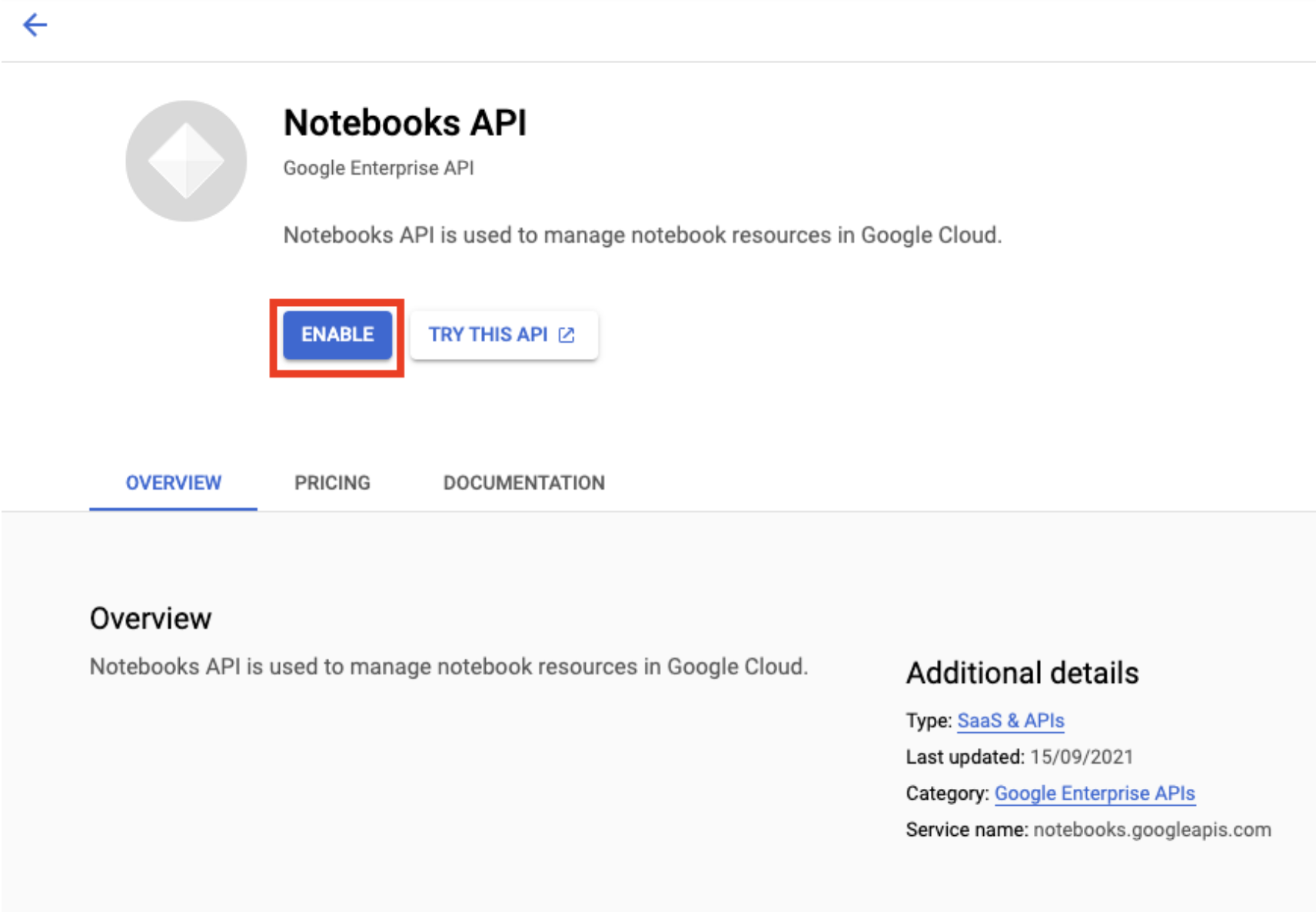
Klicken Sie nach der Aktivierung auf VERWALTETE NOTEBOOKS:
Wählen Sie dann NEUES NOTEBOOK aus.
Geben Sie Ihrem Notebook einen Namen und klicken Sie dann auf Erweiterte Einstellungen.
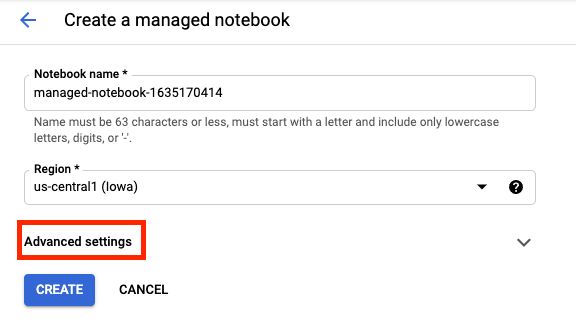
Aktivieren Sie unter „Erweiterte Einstellungen“ das Herunterfahren bei Inaktivität und legen Sie die Anzahl der Minuten auf 60 fest. Das bedeutet, dass Ihr Notebook automatisch heruntergefahren wird, wenn es nicht verwendet wird, damit keine unnötigen Kosten entstehen.

Sie können alle anderen erweiterten Einstellungen unverändert lassen.
Klicken Sie anschließend auf Erstellen.
Nachdem die Instanz erstellt wurde, klicken Sie auf JupyterLab öffnen.

Wenn Sie eine neue Instanz zum ersten Mal verwenden, werden Sie aufgefordert, sich zu authentifizieren.
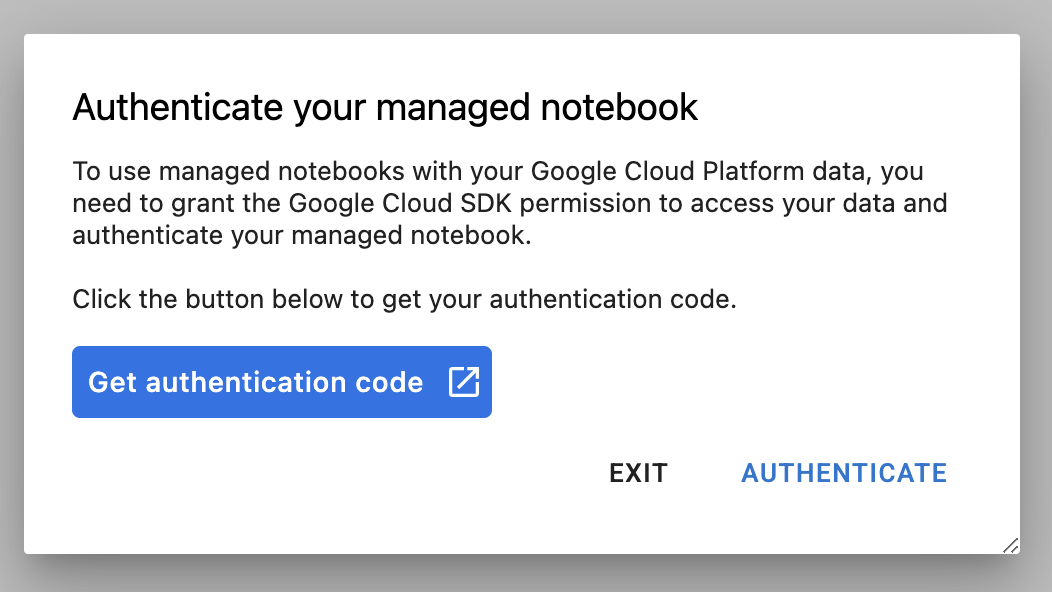
Vertex AI Workbench verfügt über eine Kompatibilitätsebene für die Berechnung, mit der Sie Kernel für TensorFlow, PySpark, R usw. über eine einzige Notebook-Instanz starten können. Nach der Authentifizierung können Sie im Launcher den Typ des Notebooks auswählen, das Sie verwenden möchten.
Wählen Sie für dieses Lab den TensorFlow 2-Kernel aus.

5. Trainingscode schreiben
Das DeepWeeds-Dataset besteht aus 17.509 Bildern von acht verschiedenen Unkrautarten,die in Australien heimisch sind. In diesem Abschnitt schreiben Sie den Code, um das DeepWeeds-Dataset vorzuverarbeiten und ein Bildklassifizierungsmodell mit Featurevektoren zu erstellen und zu trainieren, die von TensorFlow Hub heruntergeladen wurden.
Sie müssen die folgenden Code-Snippets in die Zellen Ihres Notebooks kopieren. Das Ausführen der Zellen ist optional.
Schritt 1: Dataset herunterladen und vorverarbeiten
Installieren Sie zuerst die Nightly-Version von TensorFlow Datasets, um sicherzustellen, dass Sie die neueste Version des DeepWeeds-Datasets verwenden.
!pip install tfds-nightly
Importieren Sie dann die erforderlichen Bibliotheken:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Laden Sie die Daten aus TensorFlow Datasets herunter und extrahieren Sie die Anzahl der Klassen und die Dataset-Größe.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Definieren Sie eine Vorverarbeitungsfunktion, um die Bilddaten um 255 zu skalieren.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
Das DeepWeeds-Dataset enthält keine Aufteilung in Trainings- und Validierungsdaten. Es enthält nur ein Trainings-Dataset. Im folgenden Code werden 80% dieser Daten für das Training und die restlichen 20% für die Validierung verwendet.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Schritt 2: Modell erstellen
Nachdem Sie Trainings- und Validierungs-Datasets erstellt haben, können Sie Ihr Modell erstellen. TensorFlow Hub bietet Featurevektoren, die vortrainierte Modelle ohne die oberste Klassifizierungsebene sind. Sie erstellen einen Feature-Extraktor, indem Sie das vortrainierte Modell mit hub.KerasLayer umschließen. Dadurch wird ein TensorFlow SavedModel als Keras-Ebene umschlossen. Anschließend fügen Sie eine Klassifizierungsebene hinzu und erstellen ein Modell mit der Keras Sequential API.
Definieren Sie zuerst den Parameter feature_extractor_model. Das ist der Name des TensorFlow Hub-Featurevektors, den Sie als Grundlage für Ihr Modell verwenden.
feature_extractor_model = "inception_v3"
Als Nächstes machen Sie diese Zelle zu einer Parameterzelle, mit der Sie zur Laufzeit einen Wert für feature_extractor_model übergeben können.
Wählen Sie zuerst die Zelle aus und klicken Sie im rechten Bereich auf den Attributprüfer.
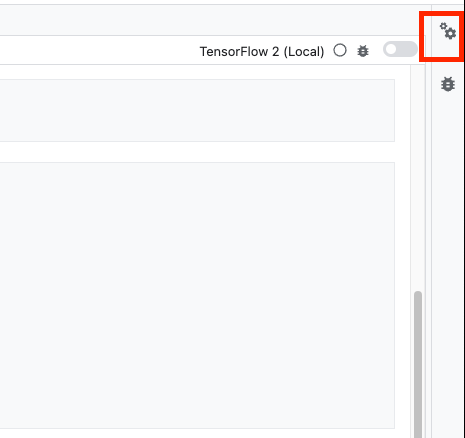
Mit Tags können Sie Ihrem Notebook auf einfache Weise Metadaten hinzufügen. Geben Sie „parameters“ in das Feld „Tag hinzufügen“ ein und drücken Sie die Eingabetaste. Wenn Sie später die Ausführung konfigurieren, übergeben Sie die verschiedenen Werte, in diesem Fall das TensorFlow Hub-Modell, das Sie testen möchten. Sie müssen das Wort „parameters“ (und kein anderes Wort) eingeben, da der Notebook-Executor so weiß, welche Zellen parametrisiert werden müssen.

Sie können den Attributprüfer schließen, indem Sie noch einmal auf das Symbol mit den beiden Zahnrädern klicken.
Erstellen Sie eine neue Zelle und definieren Sie die tf_hub_uri. Hier verwenden Sie Stringinterpolation, um den Namen des vortrainierten Modells zu ersetzen, das Sie als Basismodell für eine bestimmte Ausführung Ihres Notebooks verwenden möchten. Standardmäßig ist feature_extractor_model auf "inception_v3" festgelegt. Andere gültige Werte sind "resnet_v2_50" oder "mobilenet_v1_100_224". Weitere Optionen finden Sie im TensorFlow Hub-Katalog.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
Erstellen Sie als Nächstes den Feature-Extraktor mit hub.KerasLayer und übergeben Sie die tf_hub_uri, die Sie oben definiert haben. Legen Sie das Argument trainable=False fest, um die Variablen einzufrieren, sodass beim Training nur die neue Klassifizierungsebene geändert wird, die Sie oben hinzufügen.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Um das Modell zu vervollständigen, umschließen Sie die Feature-Extraktor-Ebene mit einem tf.keras.Sequential-Modell und fügen Sie eine vollständig verbundene Ebene für die Klassifizierung hinzu. Die Anzahl der Einheiten in diesem Klassifizierungskopf sollte der Anzahl der Klassen im Dataset entsprechen:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Kompilieren und trainieren Sie das Modell.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Notebook ausführen
Klicken Sie oben im Notebook auf das Symbol Executor.
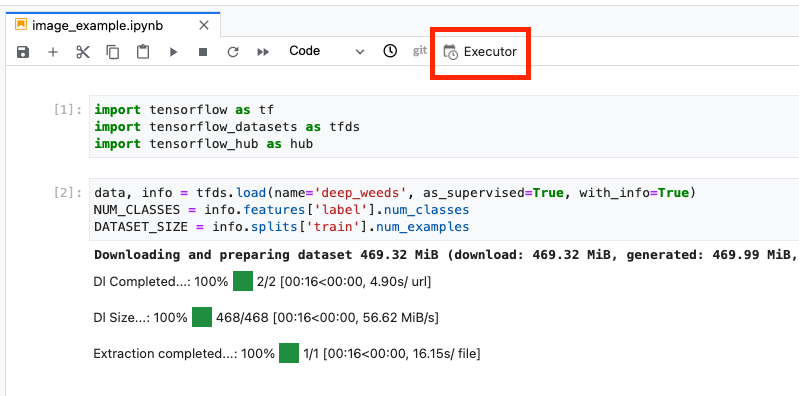
Schritt 1: Trainingsjob konfigurieren
Geben Sie Ihrer Ausführung einen Namen und geben Sie einen Storage-Bucket in Ihrem Projekt an.
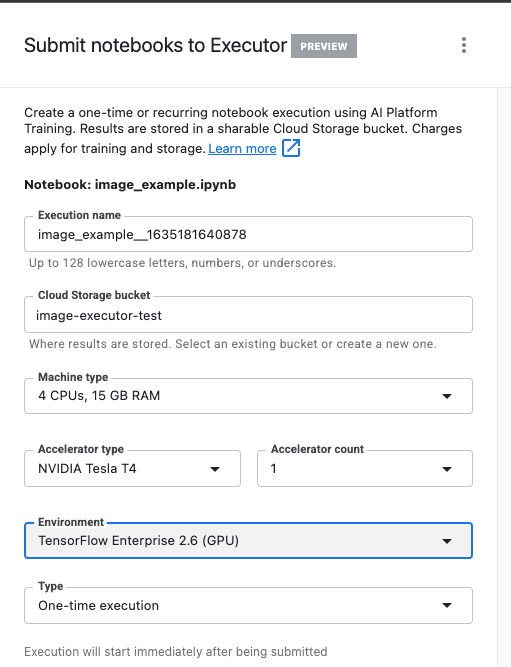
Legen Sie den Maschinentyp auf 4 CPUs, 15 GB RAM fest.
Fügen Sie 1 NVIDIA-GPU hinzu.
Legen Sie die Umgebung auf TensorFlow Enterprise 2.6 (GPU) fest.
Wählen Sie „Einmalige Ausführung“ aus.
Schritt 2: Parameter konfigurieren
Klicken Sie auf das Drop-down-Menü ERWEITERTE OPTIONEN , um den Parameter festzulegen. Geben Sie im Feld feature_extractor_model=resnet_v2_50 ein. Dadurch wird inception_v3, der Standardwert, den Sie für diesen Parameter im Notebook festgelegt haben, mit resnet_v2_50 überschrieben.
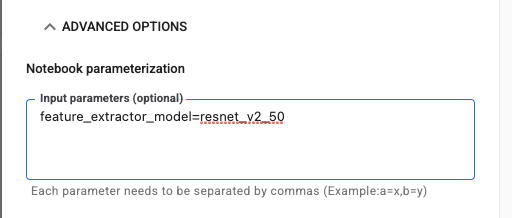
Das Kästchen Standarddienstkonto verwenden kann aktiviert bleiben.
Klicken Sie dann auf SENDEN.
Schritt 3: Ergebnisse prüfen
Auf dem Tab „Ausführungen“ in der Console-UI sehen Sie den Status der Notebook-Ausführung.
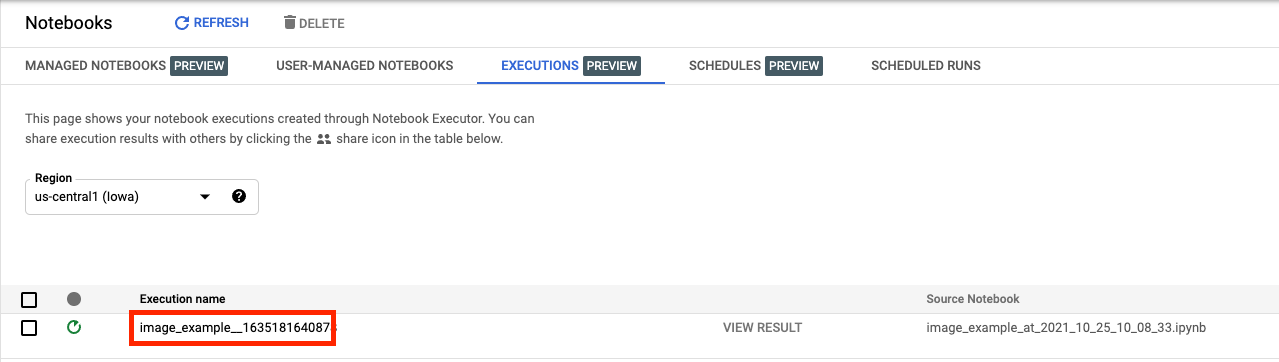
Wenn Sie auf den Namen der Ausführung klicken, gelangen Sie zum Vertex AI Training-Job, in dem Ihr Notebook ausgeführt wird.
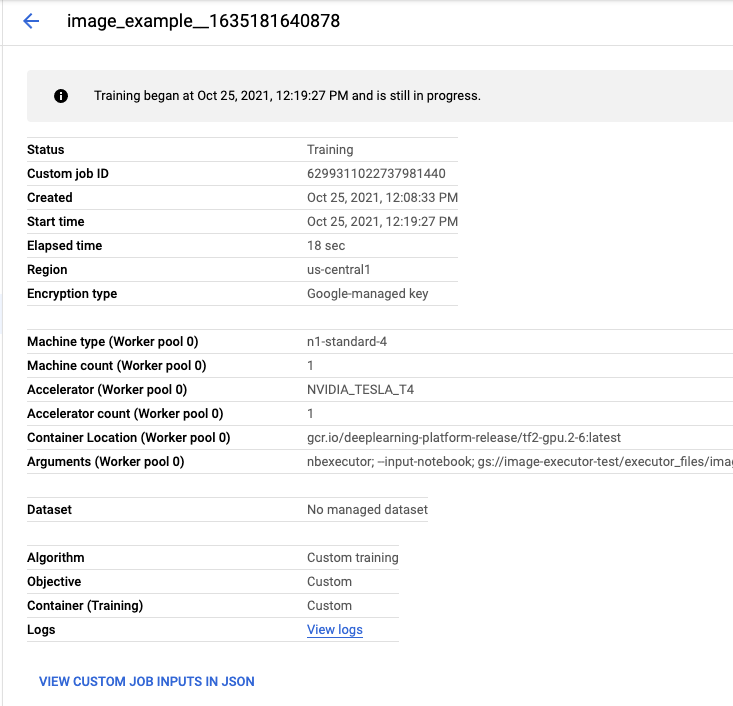
Wenn der Job abgeschlossen ist, können Sie das Ausgabenotebook aufrufen, indem Sie auf ERGEBNIS ANZEIGEN klicken.

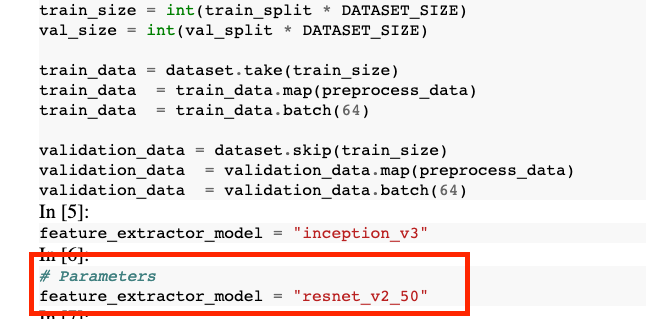
Im Ausgabenotebook sehen Sie, dass der Wert für feature_extractor_model mit dem Wert überschrieben wurde, den Sie zur Laufzeit übergeben haben.
🎉 Das wars! 🎉
Sie haben gelernt, wie Sie Vertex AI Workbench für folgende Aufgaben verwenden:
- Parameter in einem Notebook verwenden
- Notebook-Ausführungen über die Vertex AI Workbench-UI konfigurieren und starten
Weitere Informationen zu den verschiedenen Bereichen von Vertex AI finden Sie in der Dokumentation.
7. Bereinigen
Standardmäßig werden verwaltete Notebooks nach 180 Minuten Inaktivität automatisch heruntergefahren. Wenn Sie die Instanz manuell herunterfahren möchten, klicken Sie im Bereich „Vertex AI Workbench“ der Console auf die Schaltfläche „Beenden“. Wenn Sie das Notebook vollständig löschen möchten, klicken Sie auf die Schaltfläche „Löschen“.

Wenn Sie den Storage-Bucket löschen möchten, rufen Sie in der Cloud Console über das Navigationsmenü „Storage“ auf, wählen Sie den Bucket aus und klicken Sie auf „Löschen“: