1. Descripción general
En este lab, aprenderás a configurar y a ejecutar ejecuciones de notebook con Vertex AI Workbench.
Qué aprenderá
Aprenderás a hacer lo siguiente:
- Usa parámetros en un notebook
- Configura y, luego, inicia ejecuciones de notebooks desde la IU de Vertex AI Workbench
El costo total de la ejecución de este lab en Google Cloud es de aproximadamente $2.
2. Introducción a Vertex AI
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puedes migrar proyectos existentes a Vertex AI. Para enviarnos comentarios, visita la página de asistencia.
Vertex AI incluye muchos productos distintos para respaldar flujos de trabajo de AA de extremo a extremo. Este lab se enfocará en Vertex AI Workbench.
Vertex AI Workbench ayuda a los usuarios a compilar con rapidez flujos de trabajo basados en notebooks de extremo a extremo a través de la integración profunda a servicios de datos (como Dataproc, Dataflow, BigQuery y Dataplex) y Vertex AI. Además, permite a los científicos de datos conectarse a los servicios de datos de GCP, analizar conjuntos de datos, experimentar con diferentes técnicas de modelado, implementar los modelos entrenados en producción y administrar MLOps a lo largo del ciclo de vida del modelo.
3. Descripción general del caso de uso
En este lab, usarás el aprendizaje por transferencia para entrenar un modelo de clasificación de imágenes en el conjunto de datos de DeepWeeds de TensorFlow Datasets. Usarás TensorFlow Hub para experimentar con vectores de características extraídos de diferentes arquitecturas de modelos, como ResNet50, Inception y MobileNet, todos previamente entrenados en el conjunto de datos de referencia de ImageNet. Aprovechando el ejecutor de notebooks a través de la IU de Vertex AI Workbench, iniciarás trabajos en Vertex AI Training que usen estos modelos entrenados previamente y volverás a entrenar la última capa para reconocer las clases del conjunto de datos de DeepWeeds.
4. Configura el entorno
Para ejecutar este codelab, necesitarás un proyecto de Google Cloud Platform que tenga habilitada la facturación. Para crear un proyecto, sigue estas instrucciones.
Paso 1: Habilita la API de Compute Engine
Ve a Compute Engine y selecciona Habilitar (si aún no está habilitada).
Paso 2: Habilita la API de Vertex AI
Navegue hasta la sección de Vertex AI en la consola de Cloud y haga clic en Habilitar API de Vertex AI.
Paso 3: Crea una instancia de Vertex AI Workbench
En la sección Vertex AI de Cloud Console, haz clic en Workbench:
Habilita la API de Notebooks si aún no está habilitada.
Una vez habilitada, haz clic en NOTEBOOKS ADMINISTRADOS (MANAGED NOTEBOOKS):
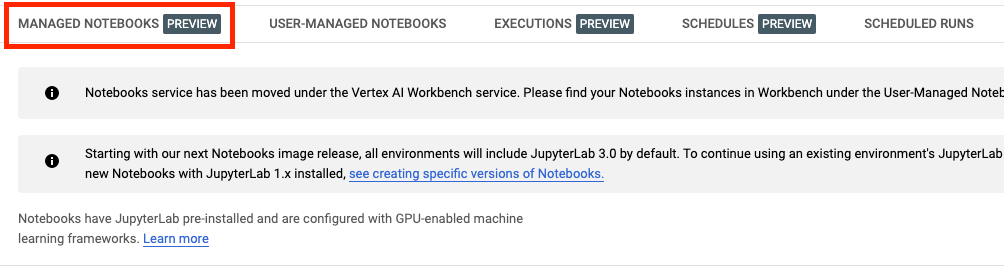
Luego, selecciona NUEVO NOTEBOOK (NEW NOTEBOOK).
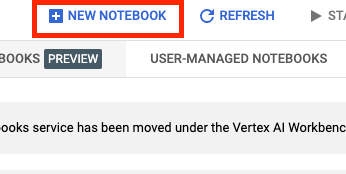
Asígnale un nombre al notebook y, luego, haz clic en Configuración avanzada (Advanced settings).
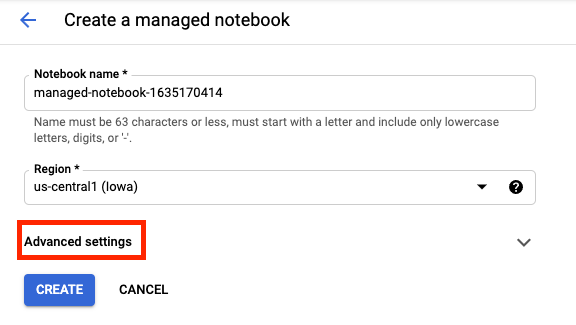
En Configuración avanzada (Advanced settings), activa la opción Habilitar el cierre inactivo (Enable Idle Shutdown) y establece la cantidad de minutos en 60. Esto provocará que el notebook se cierre automáticamente cuando no esté en uso para que no se generen costos innecesarios.

Puedes dejar el resto de la configuración avanzada tal como está.
Luego, haz clic en Crear.
Una vez que se crea la instancia, selecciona Abrir JupyterLab (Open JupyterLab).

La primera vez que uses una instancia nueva, se te solicitará que te autentiques.
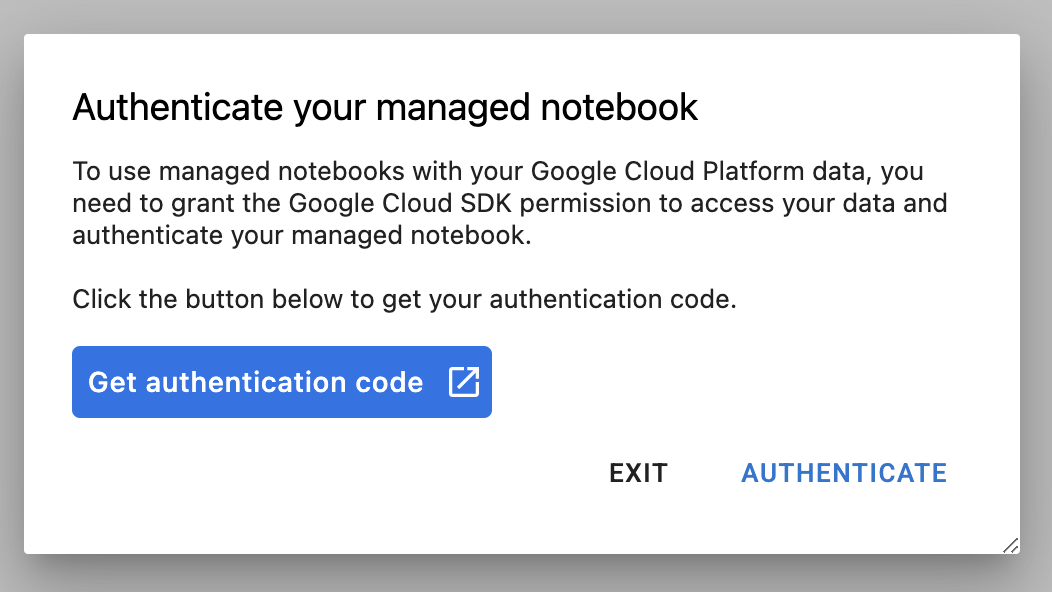
Vertex AI Workbench tiene una capa de compatibilidad de procesamiento que te permite iniciar kernels para TensorFlow, PySpark, R, etc., todo desde una sola instancia de notebook. Después de la autenticación, podrás seleccionar el tipo de notebook que quieras usar desde el selector.
Para este lab, selecciona el kernel de TensorFlow 2.

5. Escribe el código de entrenamiento
El conjunto de datos de DeepWeeds consta de 17,509 imágenes que capturan ocho especies diferentes de malezas autóctonas de Australia. En esta sección, escribirás el código para preprocesar el conjunto de datos de DeepWeeds y compilar y entrenar un modelo de clasificación de imágenes con vectores de atributos descargados de TensorFlow Hub.
Deberás copiar los siguientes fragmentos de código en las celdas de tu notebook. Ejecutar las celdas es opcional.
Paso 1: Descarga y preprocesa el conjunto de datos
Primero, instala la versión nocturna de TensorFlow Datasets para asegurarte de que estamos obteniendo la versión más reciente del conjunto de datos de DeepWeeds.
!pip install tfds-nightly
Luego, importa las bibliotecas necesarias:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Descarga los datos de TensorFlow Datasets y extrae la cantidad de clases y el tamaño del conjunto de datos.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Define una función de procesamiento previo para escalar los datos de la imagen en 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
El conjunto de datos de DeepWeeds no incluye divisiones de entrenamiento/validación. Solo incluye un conjunto de datos de entrenamiento. En el siguiente código, usarás el 80% de esos datos para el entrenamiento y el 20% restante para la validación.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Paso 2: Crea el modelo
Ahora que creaste conjuntos de datos de entrenamiento y validación, puedes compilar tu modelo. TensorFlow Hub proporciona vectores de características, que son modelos previamente entrenados sin la capa de clasificación superior. Crearás un extractor de características envolviendo el modelo previamente entrenado con hub.KerasLayer, que envuelve un modelo guardado de TensorFlow como una capa de Keras. Luego, agregarás una capa de clasificación y crearás un modelo con la API secuencial de Keras.
Primero, define el parámetro feature_extractor_model, que es el nombre del vector de características de TensorFlow Hub que usarás como base para tu modelo.
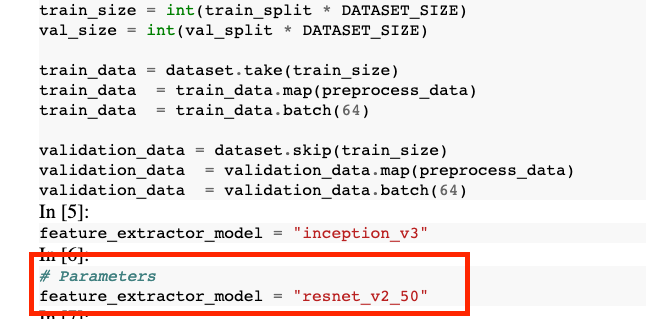
feature_extractor_model = "inception_v3"
A continuación, convertirás esta celda en una celda de parámetros, lo que te permitirá pasar un valor para feature_extractor_model en el tiempo de ejecución.
Primero, selecciona la celda y haz clic en el inspector de propiedades del panel derecho.
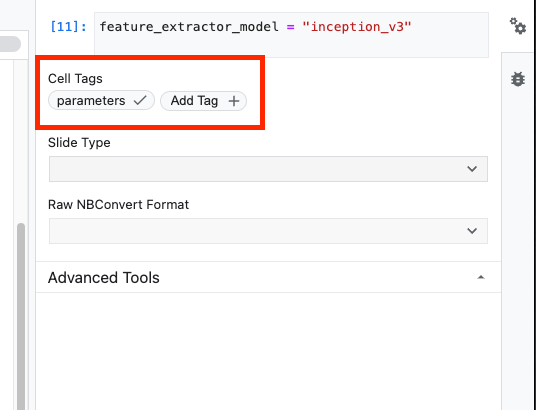
Las etiquetas son una forma sencilla de agregar metadatos a tu notebook. Escribe "parámetros" en el cuadro Agregar etiqueta y presiona Intro. Más adelante, cuando configures tu ejecución, pasarás los diferentes valores, en este caso, el modelo de TensorFlow Hub que deseas probar. Ten en cuenta que debes escribir la palabra "parámetros" (y no cualquier otra palabra), ya que así es como el ejecutor de notebooks sabe qué celdas parametrizar.
Para cerrar el inspector de propiedades, vuelve a hacer clic en el ícono de doble engranaje.
Crea una celda nueva y define tf_hub_uri, en la que usarás la interpolación de cadenas para sustituir el nombre del modelo previamente entrenado que deseas usar como modelo base para una ejecución específica de tu notebook. De forma predeterminada, estableciste feature_extractor_model en "inception_v3", pero otros valores válidos son "resnet_v2_50" o "mobilenet_v1_100_224". Puedes explorar opciones adicionales en el catálogo de TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
A continuación, crea el extractor de características con hub.KerasLayer y pasa el tf_hub_uri que definiste anteriormente. Establece el argumento trainable=False para congelar las variables, de modo que el entrenamiento solo modifique la nueva capa del clasificador que agregarás en la parte superior.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Para completar el modelo, incluye la capa de extracción de características en un modelo tf.keras.Sequential y agrega una capa completamente conectada para la clasificación. La cantidad de unidades en este encabezado de clasificación debe ser igual a la cantidad de clases en el conjunto de datos:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Por último, compila y ajusta el modelo.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Ejecutar notebook
Haz clic en el ícono Ejecutor en la parte superior del notebook.
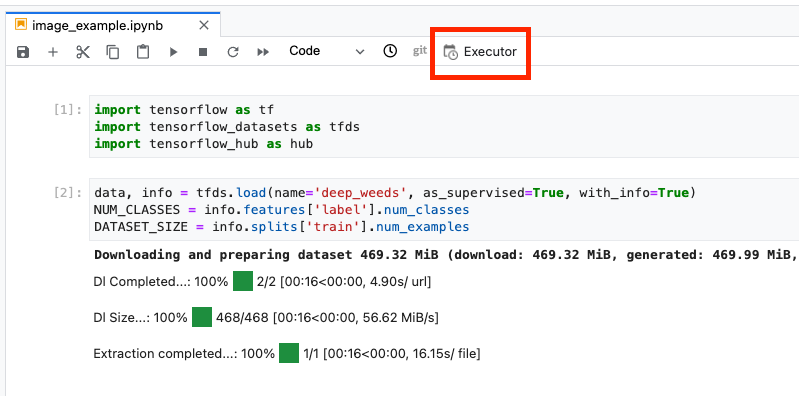
Paso 1: Configura el trabajo de entrenamiento
Asigna un nombre a la ejecución y proporciona un bucket de almacenamiento en tu proyecto.
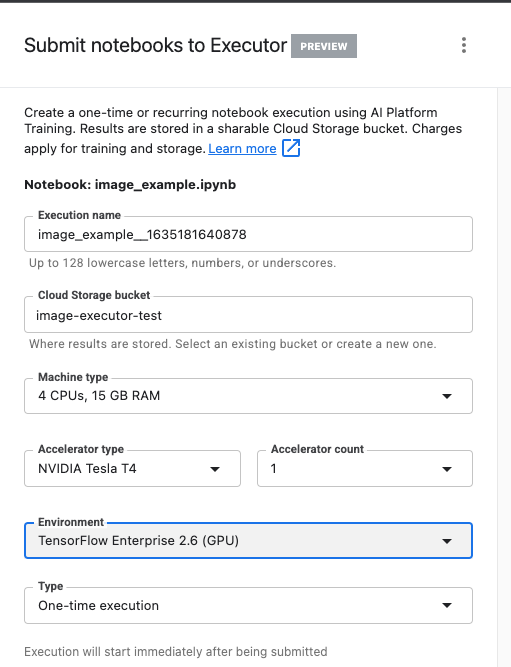
Establece el tipo de máquina en 4 CPU, 15 GB de RAM.
Agrega 1 GPU de NVIDIA.
Establece el entorno en TensorFlow Enterprise 2.6 (GPU).
Elige Ejecución única.
Paso 2: Configura los parámetros
Haz clic en el menú desplegable OPCIONES AVANZADAS para establecer tu parámetro. En el cuadro, escribe feature_extractor_model=resnet_v2_50. Esto anulará inception_v3, el valor predeterminado que estableciste para este parámetro en el notebook, con resnet_v2_50.
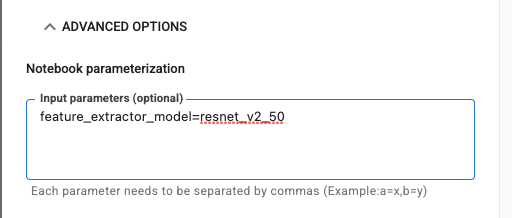
Puedes dejar marcada la casilla Usar la cuenta de servicio predeterminada.
Luego, haz clic en ENVIAR.
Paso 3: Examina los resultados
En la pestaña Ejecuciones de la IU de la consola, podrás ver el estado de la ejecución del notebook.
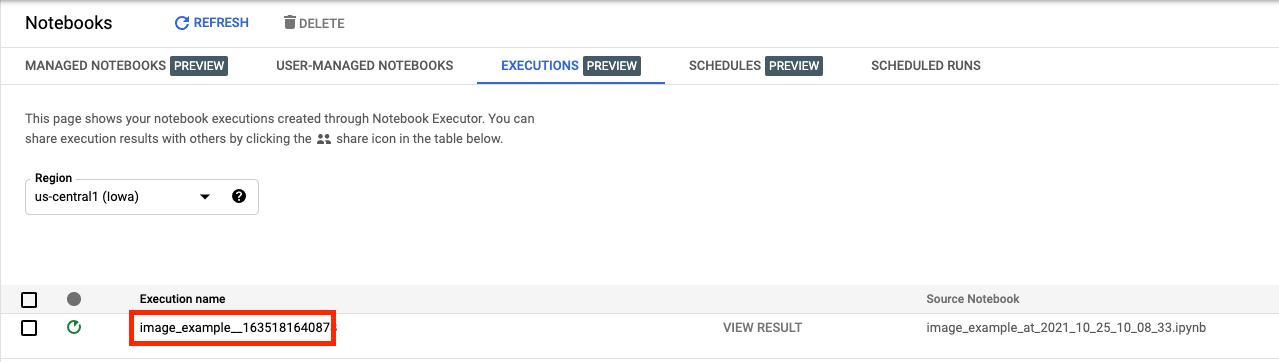
Si haces clic en el nombre de la ejecución, se te dirigirá al trabajo de Vertex AI Training en el que se ejecuta tu notebook.
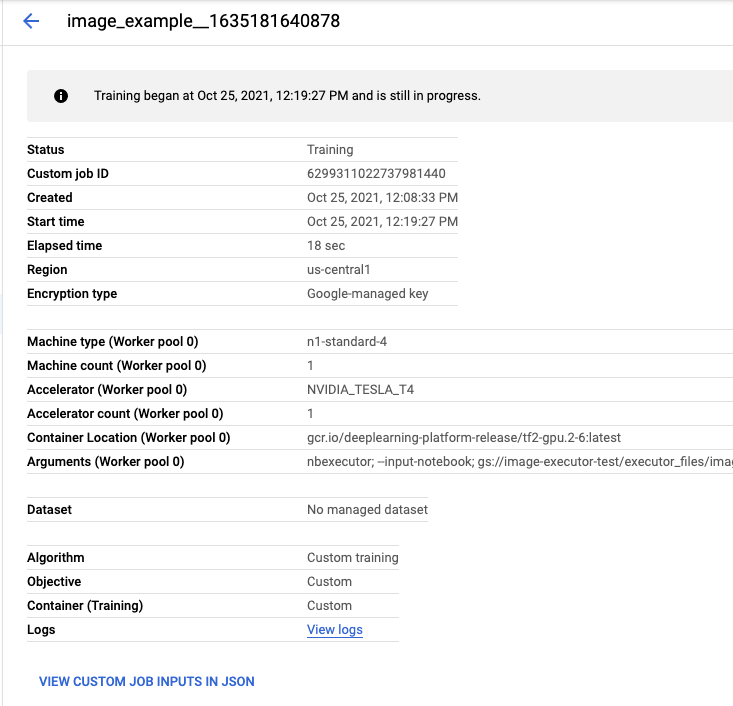
Cuando se complete el trabajo, podrás ver el notebook de salida haciendo clic en VER RESULTADO.

En el notebook de salida, verás que el valor de feature_extractor_model se reemplazó por el valor que pasaste durante el tiempo de ejecución.
🎉 ¡Felicitaciones! 🎉
Aprendiste a usar Vertex AI Workbench para realizar las siguientes tareas:
- Usa parámetros en un notebook
- Configura y, luego, inicia ejecuciones de notebooks desde la IU de Vertex AI Workbench
Si quieres obtener más información sobre los diferentes componentes de Vertex AI, consulta la documentación.
7. Limpieza
De forma predeterminada, los notebooks administrados se cierran automáticamente después de 180 minutos de inactividad. Si quieres cerrar la instancia de forma manual, haz clic en el botón Detener (Stop) en la sección Vertex AI Workbench de la consola. Si quieres borrar el notebook por completo, haz clic en el botón Borrar (Delete).

Para borrar el bucket de almacenamiento, en el menú de navegación de Cloud Console, navega a Almacenamiento, selecciona tu bucket y haz clic en Borrar (Delete):