
১. সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি শিখবেন কীভাবে Vertex AI Workbench ব্যবহার করে নোটবুক এক্সিকিউশন কনফিগার এবং চালু করতে হয়।
আপনি যা শিখবেন
আপনি শিখবেন কীভাবে:
- নোটবুকে প্যারামিটার ব্যবহার করুন
- Vertex AI Workbench UI থেকে নোটবুক এক্সিকিউশন কনফিগার এবং চালু করুন।
গুগল ক্লাউডে এই ল্যাবটি চালানোর মোট খরচ প্রায় ২ ডলার ।
২. ভার্টেক্স এআই-এর পরিচিতি
এই ল্যাবটি গুগল ক্লাউডে উপলব্ধ সর্বাধুনিক এআই প্রোডাক্টটি ব্যবহার করে। ভার্টেক্স এআই গুগল ক্লাউডের এমএল অফারিংগুলোকে একটি নির্বিঘ্ন ডেভেলপমেন্ট অভিজ্ঞতায় একীভূত করে। পূর্বে, অটোএমএল (AutoML) দিয়ে প্রশিক্ষিত মডেল এবং কাস্টম মডেলগুলো আলাদা সার্ভিসের মাধ্যমে অ্যাক্সেস করা যেত। নতুন অফারিংটি অন্যান্য নতুন প্রোডাক্টের সাথে উভয়কে একটি একক এপিআই-তে একত্রিত করেছে। আপনি আপনার বিদ্যমান প্রোজেক্টগুলোও ভার্টেক্স এআই-তে মাইগ্রেট করতে পারেন। আপনার কোনো মতামত থাকলে, অনুগ্রহ করে সাপোর্ট পেজটি দেখুন।
ভার্টেক্স এআই-এর এন্ড-টু-এন্ড এমএল ওয়ার্কফ্লো সমর্থন করার জন্য বিভিন্ন পণ্য রয়েছে। এই ল্যাবটি ভার্টেক্স এআই ওয়ার্কবেঞ্চ-এর উপর আলোকপাত করবে।
ভার্টেক্স এআই ওয়ার্কবেঞ্চ, ডেটা সার্ভিস (যেমন ডেটাপ্রক, ডেটাফ্লো, বিগকোয়েরি, এবং ডেটাপ্লেক্স) এবং ভার্টেক্স এআই-এর সাথে গভীর ইন্টিগ্রেশনের মাধ্যমে ব্যবহারকারীদের দ্রুত এন্ড-টু-এন্ড নোটবুক-ভিত্তিক ওয়ার্কফ্লো তৈরি করতে সাহায্য করে। এটি ডেটা সায়েন্টিস্টদের GCP ডেটা সার্ভিসের সাথে সংযোগ স্থাপন করতে, ডেটাসেট বিশ্লেষণ করতে, বিভিন্ন মডেলিং কৌশল নিয়ে পরীক্ষা-নিরীক্ষা করতে, প্রশিক্ষিত মডেলগুলোকে প্রোডাকশনে ডেপ্লয় করতে এবং মডেলের জীবনচক্র জুড়ে MLOps পরিচালনা করতে সক্ষম করে।
৩. ব্যবহারের ক্ষেত্রের সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি TensorFlow Datasets- এর DeepWeeds ডেটাসেটের উপর ট্রান্সফার লার্নিং ব্যবহার করে একটি ইমেজ ক্লাসিফিকেশন মডেলকে প্রশিক্ষণ দেবেন। আপনি TensorFlow Hub ব্যবহার করে বিভিন্ন মডেল আর্কিটেকচার, যেমন ResNet50 , Inception , এবং MobileNet থেকে সংগৃহীত ফিচার ভেক্টর নিয়ে পরীক্ষা-নিরীক্ষা করবেন, যেগুলোর সবগুলোই ImageNet বেঞ্চমার্ক ডেটাসেটের উপর প্রি-ট্রেইন করা। Vertex AI Workbench UI-এর মাধ্যমে নোটবুক এক্সিকিউটর ব্যবহার করে, আপনি Vertex AI Training-এ এমন জব চালু করবেন যা এই প্রি-ট্রেইনড মডেলগুলো ব্যবহার করে DeepWeeds ডেটাসেটের ক্লাসগুলো শনাক্ত করার জন্য শেষ লেয়ারটিকে পুনরায় প্রশিক্ষণ দেবে।
৪. আপনার পরিবেশ প্রস্তুত করুন
এই কোডল্যাবটি চালানোর জন্য আপনার বিলিং চালু করা একটি গুগল ক্লাউড প্ল্যাটফর্ম প্রজেক্ট প্রয়োজন হবে। প্রজেক্ট তৈরি করতে, এখানের নির্দেশাবলী অনুসরণ করুন।
ধাপ ১: কম্পিউট ইঞ্জিন এপিআই সক্রিয় করুন
Compute Engine- এ যান এবং যদি এটি আগে থেকে চালু না থাকে, তাহলে Enable নির্বাচন করুন।
ধাপ ২: Vertex AI API সক্রিয় করুন
আপনার ক্লাউড কনসোলের Vertex AI বিভাগে যান এবং Enable Vertex AI API-তে ক্লিক করুন।

ধাপ ৩: একটি Vertex AI Workbench ইনস্ট্যান্স তৈরি করুন
আপনার ক্লাউড কনসোলের Vertex AI সেকশন থেকে Workbench-এ ক্লিক করুন:

নোটবুকস এপিআই (Notebooks API) সক্রিয় করুন, যদি আগে থেকে সক্রিয় করা না থাকে।

একবার চালু হয়ে গেলে, ম্যানেজড নোটবুকস-এ ক্লিক করুন:

তারপর নতুন নোটবুক নির্বাচন করুন।

আপনার নোটবুকটির একটি নাম দিন, এবং তারপর অ্যাডভান্সড সেটিংস-এ ক্লিক করুন।

অ্যাডভান্সড সেটিংস-এর অধীনে, আইডল শাটডাউন চালু করুন এবং মিনিটের সংখ্যা ৬০-এ সেট করুন। এর মানে হলো, আপনার নোটবুকটি ব্যবহার না করা হলে স্বয়ংক্রিয়ভাবে বন্ধ হয়ে যাবে, ফলে আপনার অপ্রয়োজনীয় খরচ হবে না।

আপনি অন্যান্য সমস্ত উন্নত সেটিংস অপরিবর্তিত রাখতে পারেন।
এরপর, Create-এ ক্লিক করুন।
ইনস্ট্যান্সটি তৈরি হয়ে গেলে, Open JupyterLab নির্বাচন করুন।

আপনি প্রথমবার কোনো নতুন ইনস্ট্যান্স ব্যবহার করার সময়, আপনাকে প্রমাণীকরণের জন্য বলা হবে।

ভার্টেক্স এআই ওয়ার্কবেঞ্চ-এ একটি কম্পিউট কম্প্যাটিবিলিটি লেয়ার রয়েছে, যা আপনাকে একটিমাত্র নোটবুক ইনস্ট্যান্স থেকেই টেনসরফ্লো, পাইস্পার্ক, আর (R) ইত্যাদির কার্নেল চালু করার সুযোগ দেয়। অথেন্টিকেট করার পর, আপনি লঞ্চার থেকে কোন ধরনের নোটবুক ব্যবহার করতে চান তা বেছে নিতে পারবেন।
এই ল্যাবের জন্য টেনসরফ্লো ২ কার্নেলটি নির্বাচন করুন।

৫. প্রশিক্ষণ কোড লিখুন
DeepWeeds ডেটাসেটটিতে অস্ট্রেলিয়ার স্থানীয় আটটি ভিন্ন আগাছা প্রজাতির ১৭,৫০৯টি ছবি রয়েছে। এই অংশে, আপনি DeepWeeds ডেটাসেটটি প্রিপ্রসেস করার জন্য এবং TensorFlow Hub থেকে ডাউনলোড করা ফিচার ভেক্টর ব্যবহার করে একটি ইমেজ ক্লাসিফিকেশন মডেল তৈরি ও প্রশিক্ষণ দেওয়ার জন্য কোড লিখবেন।
আপনাকে নিচের কোড স্নিপেটগুলো আপনার নোটবুকের সেলগুলোতে কপি করতে হবে। সেলগুলো এক্সিকিউট করা ঐচ্ছিক।
ধাপ ১: ডেটাসেট ডাউনলোড এবং প্রিপ্রসেস করুন
প্রথমে, TensorFlow ডেটাসেটের নাইটলি সংস্করণটি ইনস্টল করুন, যাতে আমরা DeepWeeds ডেটাসেটের সর্বশেষ সংস্করণটি পাই।
!pip install tfds-nightly
তারপর, প্রয়োজনীয় লাইব্রেরিগুলো ইম্পোর্ট করুন:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
TensorFlow ডেটাসেট থেকে ডেটা ডাউনলোড করুন এবং ক্লাসের সংখ্যা ও ডেটাসেটের আকার বের করুন।
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
ইমেজ ডেটাকে ২৫৫ দ্বারা স্কেল করার জন্য একটি প্রিপ্রসেসিং ফাংশন সংজ্ঞায়িত করুন।
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
DeepWeeds ডেটাসেটে ট্রেন/ভ্যালিডেশন বিভাজন নেই। এতে শুধু একটি ট্রেনিং ডেটাসেট রয়েছে। নিচের কোডে আপনি সেই ডেটার ৮০% ট্রেনিংয়ের জন্য এবং বাকি ২০% ভ্যালিডেশনের জন্য ব্যবহার করবেন।
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
ধাপ ২: মডেল তৈরি করুন
এখন যেহেতু আপনি ট্রেনিং এবং ভ্যালিডেশন ডেটাসেট তৈরি করে ফেলেছেন, আপনি আপনার মডেল তৈরি করার জন্য প্রস্তুত। TensorFlow Hub ফিচার ভেক্টর প্রদান করে, যা হলো টপ ক্লাসিফিকেশন লেয়ার ছাড়া প্রি-ট্রেইনড মডেল। আপনি প্রি-ট্রেইনড মডেলটিকে hub.KerasLayer দিয়ে র্যাপ করে একটি ফিচার এক্সট্র্যাক্টর তৈরি করবেন, যা একটি TensorFlow SavedModel-কে Keras লেয়ার হিসেবে র্যাপ করে। এরপর আপনি একটি ক্লাসিফিকেশন লেয়ার যোগ করবেন এবং Keras Sequential API ব্যবহার করে একটি মডেল তৈরি করবেন।
প্রথমে, feature_extractor_model প্যারামিটারটি নির্ধারণ করুন, যেটি হলো TensorFlow Hub ফিচার ভেক্টরের নাম, যা আপনি আপনার মডেলের ভিত্তি হিসেবে ব্যবহার করবেন।
feature_extractor_model = "inception_v3"
এরপরে, আপনি এই সেলটিকে একটি প্যারামিটার সেল বানাবেন, যার ফলে আপনি রানটাইমে feature_extractor_model এর জন্য একটি ভ্যালু পাস করতে পারবেন।
প্রথমে, সেলটি নির্বাচন করুন এবং ডান প্যানেলে থাকা প্রপার্টি ইন্সপেক্টরে ক্লিক করুন।

আপনার নোটবুকে মেটাডেটা যোগ করার একটি সহজ উপায় হলো ট্যাগ। 'Add Tag' বক্সে 'parameters' টাইপ করে এন্টার চাপুন। পরবর্তীতে আপনার এক্সিকিউশন কনফিগার করার সময়, আপনি যে বিভিন্ন ভ্যালুগুলো পরীক্ষা করতে চান, যেমন এই ক্ষেত্রে TensorFlow Hub মডেল, সেগুলো পাস করবেন। মনে রাখবেন, আপনাকে অবশ্যই 'parameters' শব্দটি টাইপ করতে হবে (অন্য কোনো শব্দ নয়), কারণ এভাবেই নোটবুক এক্সিকিউটর জানতে পারে কোন সেলগুলোকে প্যারামিটারাইজ করতে হবে।
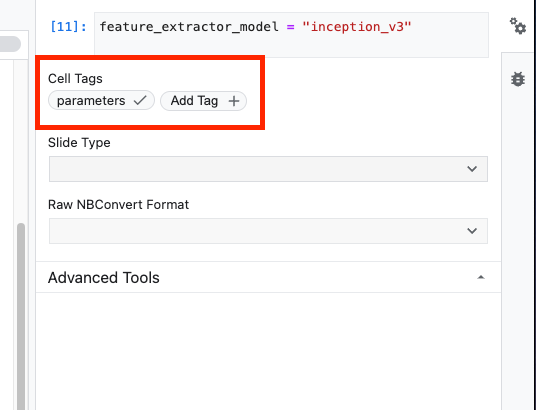
ডাবল গিয়ার আইকনটিতে আবার ক্লিক করে আপনি প্রপার্টি ইন্সপেক্টরটি বন্ধ করতে পারেন।
একটি নতুন সেল তৈরি করুন এবং tf_hub_uri নির্ধারণ করুন, যেখানে আপনি আপনার নোটবুকের একটি নির্দিষ্ট এক্সিকিউশনের জন্য বেস মডেল হিসেবে ব্যবহার করতে চান এমন প্রি-ট্রেইনড মডেলের নামটি প্রতিস্থাপন করতে স্ট্রিং ইন্টারপোলেশন ব্যবহার করবেন। ডিফল্টরূপে, আপনি feature_extractor_model "inception_v3" হিসেবে সেট করেছেন, কিন্তু অন্যান্য বৈধ মান হলো "resnet_v2_50" বা "mobilenet_v1_100_224" । আপনি TensorFlow Hub ক্যাটালগে অতিরিক্ত বিকল্পগুলো অন্বেষণ করতে পারেন।
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
এরপরে, hub.KerasLayer ব্যবহার করে এবং উপরে সংজ্ঞায়িত tf_hub_uri পাস করে ফিচার এক্সট্র্যাক্টরটি তৈরি করুন। ভেরিয়েবলগুলো ফ্রিজ করার জন্য trainable=False আর্গুমেন্টটি সেট করুন, যাতে ট্রেনিং শুধুমাত্র উপরে যোগ করা নতুন ক্লাসিফায়ার লেয়ারটিকেই পরিবর্তন করে।
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
মডেলটি সম্পূর্ণ করতে, ফিচার এক্সট্র্যাক্টর লেয়ারটিকে একটি tf.keras.Sequential মডেলে র্যাপ করুন এবং ক্লাসিফিকেশনের জন্য একটি ফুললি-কানেক্টেড লেয়ার যোগ করুন। এই ক্লাসিফিকেশন হেডের ইউনিটের সংখ্যা ডেটাসেটের ক্লাসের সংখ্যার সমান হওয়া উচিত।
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
সবশেষে, মডেলটি কম্পাইল ও ফিট করুন।
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
৬. নোটবুকটি চালান।
নোটবুকের শীর্ষে থাকা এক্সিকিউটর আইকনটিতে ক্লিক করুন।

ধাপ ১: প্রশিক্ষণ কাজটি কনফিগার করুন
আপনার এক্সিকিউশনকে একটি নাম দিন এবং আপনার প্রোজেক্টে একটি স্টোরেজ বাকেট প্রদান করুন।

মেশিনের ধরন ৪টি সিপিইউ, ১৫ জিবি র্যাম- এ সেট করুন।
এবং ১টি এনভিডিয়া জিপিইউ যোগ করুন।
পরিবেশটি TensorFlow Enterprise 2.6 (GPU)-তে সেট করুন।
এককালীন সম্পাদন নির্বাচন করুন।
ধাপ ২: প্যারামিটার কনফিগার করুন
আপনার প্যারামিটার সেট করতে অ্যাডভান্সড অপশনস ড্রপ-ডাউনে ক্লিক করুন। বক্সে, feature_extractor_model=resnet_v2_50 টাইপ করুন। এটি নোটবুকে এই প্যারামিটারের জন্য আপনার সেট করা ডিফল্ট মান inception_v3 resnet_v2_50 দিয়ে ওভাররাইড করবে।

আপনি ‘use default service account’ বক্সটি চেক করা অবস্থায় রাখতে পারেন।
তারপর SUBMIT-এ ক্লিক করুন।
ধাপ ৩: ফলাফল পরীক্ষা করুন
কনসোল UI-এর এক্সিকিউশনস ট্যাবে আপনি আপনার নোটবুক এক্সিকিউশনের স্ট্যাটাস দেখতে পারবেন।

এক্সিকিউশন নামে ক্লিক করলে আপনাকে ভার্টেক্স এআই ট্রেনিং জবে নিয়ে যাওয়া হবে, যেখানে আপনার নোটবুকটি চলছে।

আপনার কাজটি সম্পন্ন হলে, 'VIEW RESULT'-এ ক্লিক করে আপনি আউটপুট নোটবুকটি দেখতে পারবেন।

আউটপুট নোটবুকে আপনি দেখতে পাবেন যে, feature_extractor_model এর মানটি রানটাইমে আপনার দেওয়া মান দ্বারা ওভাররাইট হয়ে গেছে।

🎉 অভিনন্দন! 🎉
আপনি শিখেছেন কীভাবে Vertex AI Workbench ব্যবহার করে নিম্নলিখিত কাজগুলো করা যায়:
- নোটবুকে প্যারামিটার ব্যবহার করুন
- Vertex AI Workbench UI থেকে নোটবুক এক্সিকিউশন কনফিগার এবং চালু করুন।
Vertex AI-এর বিভিন্ন অংশ সম্পর্কে আরও জানতে ডকুমেন্টেশন দেখুন।
৭. পরিচ্ছন্নতা
ডিফল্টরূপে, পরিচালিত নোটবুকগুলো ১৮০ মিনিট নিষ্ক্রিয় থাকার পর স্বয়ংক্রিয়ভাবে বন্ধ হয়ে যায়। আপনি যদি ইনস্ট্যান্সটি ম্যানুয়ালি বন্ধ করতে চান, তাহলে কনসোলের Vertex AI Workbench বিভাগে থাকা Stop বোতামে ক্লিক করুন। আর যদি নোটবুকটি সম্পূর্ণরূপে মুছে ফেলতে চান, তাহলে Delete বোতামে ক্লিক করুন।

স্টোরেজ বাকেটটি ডিলিট করতে, আপনার ক্লাউড কনসোলের নেভিগেশন মেনু ব্যবহার করে স্টোরেজ-এ যান, আপনার বাকেটটি সিলেক্ট করুন এবং ডিলিট-এ ক্লিক করুন:
