۱. مرور کلی
در این آزمایشگاه، نحوه پیکربندی و اجرای نوتبوک با Vertex AI Workbench را خواهید آموخت.
آنچه یاد میگیرید
شما یاد خواهید گرفت که چگونه:
- استفاده از پارامترها در دفترچه یادداشت
- پیکربندی و اجرای نوتبوک از رابط کاربری Vertex AI Workbench
هزینه کل اجرای این آزمایشگاه در گوگل کلود حدود ۲ دلار است.
۲. مقدمهای بر هوش مصنوعی ورتکس
این آزمایشگاه از جدیدترین محصول هوش مصنوعی موجود در Google Cloud استفاده میکند. Vertex AI، محصولات یادگیری ماشین را در Google Cloud ادغام میکند تا یک تجربه توسعه یکپارچه را فراهم کند. پیش از این، مدلهای آموزشدیده با AutoML و مدلهای سفارشی از طریق سرویسهای جداگانه قابل دسترسی بودند. این محصول جدید، هر دو را در یک API واحد، به همراه سایر محصولات جدید، ترکیب میکند. همچنین میتوانید پروژههای موجود را به Vertex AI منتقل کنید. در صورت داشتن هرگونه بازخورد، لطفاً به صفحه پشتیبانی مراجعه کنید.
Vertex AI شامل محصولات مختلفی برای پشتیبانی از گردشهای کاری یادگیری ماشینی سرتاسری است. این آزمایشگاه بر روی Vertex AI Workbench تمرکز خواهد کرد.
ورکبنچ هوش مصنوعی ورتکس (Vertex AI Workbench) به کاربران کمک میکند تا از طریق ادغام عمیق با سرویسهای داده (مانند Dataproc، Dataflow، BigQuery و Dataplex) و ورتکس هوش مصنوعی، به سرعت گردشهای کاری مبتنی بر نوتبوک را به صورت سرتاسری ایجاد کنند. این نرمافزار دانشمندان داده را قادر میسازد تا به سرویسهای داده GCP متصل شوند، مجموعه دادهها را تجزیه و تحلیل کنند، تکنیکهای مختلف مدلسازی را آزمایش کنند، مدلهای آموزشدیده را در تولید مستقر کنند و MLOps را از طریق چرخه عمر مدل مدیریت کنند.
۳. مرور کلی موارد استفاده
در این آزمایش، شما از یادگیری انتقالی برای آموزش یک مدل طبقهبندی تصویر روی مجموعه داده DeepWeeds از TensorFlow Datasets استفاده خواهید کرد. شما از TensorFlow Hub برای آزمایش بردارهای ویژگی استخراج شده از معماریهای مدل مختلف، مانند ResNet50 ، Inception و MobileNet ، که همگی روی مجموعه داده ImageNet benchmark از قبل آموزش دیدهاند، استفاده خواهید کرد. با استفاده از notebook executor از طریق رابط کاربری Vertex AI Workbench، کارهایی را روی Vertex AI Training راهاندازی خواهید کرد که از این مدلهای از پیش آموزش دیده استفاده میکنند و آخرین لایه را برای تشخیص کلاسها از مجموعه داده DeepWeeds دوباره آموزش خواهید داد.
۴. محیط خود را آماده کنید
برای اجرای این codelab به یک پروژه Google Cloud Platform با قابلیت پرداخت صورتحساب نیاز دارید. برای ایجاد یک پروژه، دستورالعملهای اینجا را دنبال کنید.
مرحله ۱: فعال کردن رابط برنامهنویسی کاربردی موتور محاسبات
به Compute Engine بروید و اگر از قبل فعال نیست، آن را فعال کنید .
مرحله 2: فعال کردن API هوش مصنوعی Vertex
به بخش Vertex AI در کنسول ابری خود بروید و روی Enable Vertex AI API کلیک کنید.

مرحله 3: یک نمونه Vertex AI Workbench ایجاد کنید
از بخش Vertex AI در کنسول ابری خود، روی Workbench کلیک کنید:

اگر API نوتبوکها فعال نیست، آن را فعال کنید.

پس از فعال کردن، روی «دفترچههای مدیریتشده» کلیک کنید:
سپس دفترچه یادداشت جدید را انتخاب کنید.

برای نوتبوک خود یک نام انتخاب کنید و سپس روی تنظیمات پیشرفته (Advanced Settings) کلیک کنید.

در قسمت تنظیمات پیشرفته، خاموش شدن در حالت بیکاری را فعال کنید و تعداد دقیقهها را روی ۶۰ تنظیم کنید. این یعنی نوتبوک شما در صورت عدم استفاده به طور خودکار خاموش میشود تا هزینههای غیرضروری متحمل نشوید.

میتوانید تمام تنظیمات پیشرفته دیگر را همانطور که هست، رها کنید.
در مرحله بعد، روی ایجاد کلیک کنید.
پس از ایجاد نمونه، گزینه Open JupyterLab را انتخاب کنید.

اولین باری که از یک نمونه جدید استفاده میکنید، از شما خواسته میشود که احراز هویت کنید.

ورکبنچ هوش مصنوعی ورتکس (Vertex AI Workbench) دارای یک لایه سازگاری محاسباتی است که به شما امکان میدهد هستههای TensorFlow، PySpark، R و غیره را از یک نمونه نوتبوک واحد اجرا کنید. پس از احراز هویت، میتوانید نوع نوتبوکی را که میخواهید از آن استفاده کنید، از لانچر انتخاب کنید.
برای این آزمایش، هسته TensorFlow 2 را انتخاب کنید.

۵. کد آموزشی را بنویسید
مجموعه داده DeepWeeds شامل ۱۷۵۰۹ تصویر است که هشت گونه مختلف علف هرز بومی استرالیا را ثبت میکنند. در این بخش، شما کدی را برای پیشپردازش مجموعه داده DeepWeeds خواهید نوشت و یک مدل طبقهبندی تصویر را با استفاده از بردارهای ویژگی دانلود شده از TensorFlow Hub خواهید ساخت و آموزش خواهید داد.
شما باید قطعه کدهای زیر را در سلولهای دفترچه یادداشت خود کپی کنید. اجرای سلولها اختیاری است.
مرحله ۱: دانلود و پیشپردازش مجموعه دادهها
ابتدا، نسخه شبانه مجموعه دادههای TensorFlow را نصب کنید تا مطمئن شوید که آخرین نسخه مجموعه دادههای DeepWeeds را دریافت میکنید.
!pip install tfds-nightly
سپس، کتابخانههای لازم را وارد کنید:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
دادهها را از TensorFlow Datasets دانلود کنید و تعداد کلاسها و اندازه مجموعه دادهها را استخراج کنید.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
یک تابع پیشپردازش تعریف کنید تا دادههای تصویر را به اندازه ۲۵۵ مقیاسبندی کند.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
مجموعه داده DeepWeeds شامل تقسیمبندیهای آموزش/اعتبارسنجی نیست. فقط شامل یک مجموعه داده آموزشی است. در کد زیر، ۸۰٪ از این دادهها را برای آموزش و ۲۰٪ باقیمانده را برای اعتبارسنجی استفاده خواهید کرد.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
مرحله ۲: ایجاد مدل
اکنون که مجموعه دادههای آموزشی و اعتبارسنجی را ایجاد کردهاید، آماده ساخت مدل خود هستید. TensorFlow Hub بردارهای ویژگی را ارائه میدهد که مدلهای از پیش آموزشدیده بدون لایه طبقهبندی بالایی هستند. شما با قرار دادن مدل از پیش آموزشدیده در hub.KerasLayer ، که یک TensorFlow SavedModel را به عنوان یک لایه Keras در بر میگیرد، یک استخراجکننده ویژگی ایجاد خواهید کرد. سپس یک لایه طبقهبندی اضافه میکنید و با Keras Sequential API یک مدل ایجاد میکنید.
ابتدا پارامتر feature_extractor_model را تعریف کنید، که نام بردار ویژگی TensorFlow Hub است که به عنوان مبنای مدل خود استفاده خواهید کرد.
feature_extractor_model = "inception_v3"
در مرحله بعد، این سلول را به یک سلول پارامتر تبدیل خواهید کرد که به شما امکان میدهد در زمان اجرا مقداری را برای feature_extractor_model ارسال کنید.
ابتدا سلول را انتخاب کنید و روی property inspector در پنل سمت راست کلیک کنید.

برچسبها روشی ساده برای افزودن فراداده به نوتبوک شما هستند. در کادر افزودن برچسب، عبارت "parameters" را تایپ کرده و Enter را بزنید. بعداً هنگام پیکربندی اجرای خود، مقادیر مختلفی را ارسال خواهید کرد، در این مورد مدل TensorFlow Hub که میخواهید آزمایش کنید. توجه داشته باشید که باید کلمه "parameters" (و نه هیچ کلمه دیگری) را تایپ کنید زیرا به این ترتیب اجراکننده نوتبوک میداند کدام سلولها را پارامتردهی کند.

میتوانید با کلیک مجدد روی آیکون چرخدنده دوتایی، پنجرهی Property inspector را ببندید.
یک سلول جدید ایجاد کنید و tf_hub_uri را تعریف کنید، که در آن از درونیابی رشتهای برای جایگزینی نام مدل از پیش آموزشدیدهای که میخواهید به عنوان مدل پایه برای اجرای خاص نوتبوک خود استفاده کنید، استفاده خواهید کرد. به طور پیشفرض، feature_extractor_model روی "inception_v3" تنظیم کردهاید، اما سایر مقادیر معتبر "resnet_v2_50" یا "mobilenet_v1_100_224" هستند. میتوانید گزینههای اضافی را در کاتالوگ TensorFlow Hub بررسی کنید.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
در مرحله بعد، با استفاده از hub.KerasLayer و ارسال tf_hub_uri که در بالا تعریف کردید، استخراجکننده ویژگی را ایجاد کنید. آرگومان trainable=False را طوری تنظیم کنید که متغیرها را ثابت نگه دارد تا آموزش فقط لایه طبقهبندی جدیدی را که به بالا اضافه خواهید کرد، تغییر دهد.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
برای تکمیل مدل، لایه استخراجکننده ویژگی را در یک مدل tf.keras.Sequential قرار دهید و یک لایه کاملاً متصل برای طبقهبندی اضافه کنید. تعداد واحدهای موجود در این سر طبقهبندی باید برابر با تعداد کلاسهای موجود در مجموعه دادهها باشد:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
در نهایت، مدل را کامپایل و برازش دهید.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
۶. اجرای دفترچه یادداشت
روی نماد مجری در بالای دفترچه یادداشت کلیک کنید.

مرحله 1: پیکربندی شغل آموزشی
به اجرای خود یک نام بدهید و یک سطل ذخیرهسازی در پروژه خود فراهم کنید.
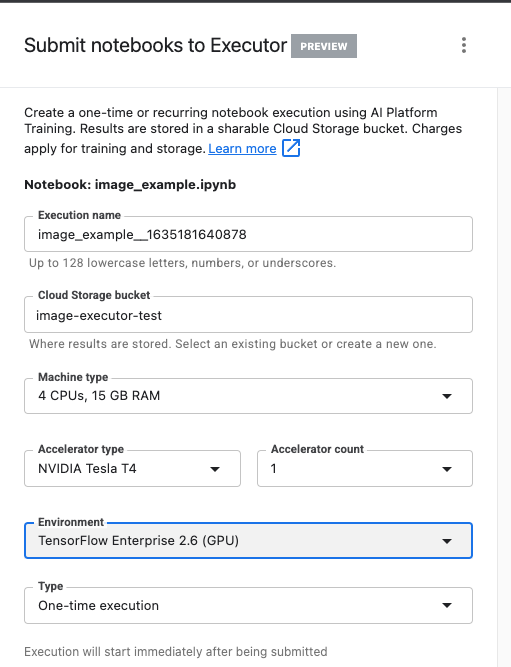
نوع ماشین را روی ۴ پردازنده و ۱۵ گیگابایت رم تنظیم کنید.
و 1 پردازنده گرافیکی NVIDIA اضافه کنید.
محیط را روی TensorFlow Enterprise 2.6 (GPU) تنظیم کنید.
اجرای یکباره را انتخاب کنید.
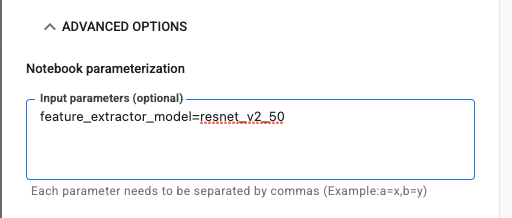
مرحله ۲: پیکربندی پارامترها
برای تنظیم پارامتر خود، روی منوی کشویی ADVANCED OPTIONS کلیک کنید. در کادر، عبارت feature_extractor_model=resnet_v2_50 را تایپ کنید. این کار inception_v3 ، مقدار پیشفرضی که برای این پارامتر در نوتبوک تنظیم کردهاید، را با resnet_v2_50 جایگزین میکند.
میتوانید گزینهی «استفاده از حساب کاربری پیشفرض سرویس» را تیک بزنید.
سپس روی ارسال کلیک کنید
مرحله ۳: بررسی نتایج
در تب Executions در رابط کاربری کنسول، میتوانید وضعیت اجرای نوتبوک خود را مشاهده کنید.

اگر روی نام اجرا کلیک کنید، به کار Vertex AI Training که نوتبوک شما در آن اجرا میشود، هدایت میشوید.

وقتی کارتان تمام شد، میتوانید با کلیک روی «مشاهده نتیجه»، دفترچه خروجی را ببینید.

در دفترچه خروجی، خواهید دید که مقدار feature_extractor_model توسط مقداری که در زمان اجرا ارسال کردهاید، بازنویسی شده است.

🎉 تبریک میگویم! 🎉
شما یاد گرفتید که چگونه از Vertex AI Workbench برای موارد زیر استفاده کنید:
- استفاده از پارامترها در دفترچه یادداشت
- پیکربندی و اجرای نوتبوک از رابط کاربری Vertex AI Workbench
برای کسب اطلاعات بیشتر در مورد بخشهای مختلف Vertex AI، مستندات را بررسی کنید.
۷. پاکسازی
به طور پیشفرض، نوتبوکهای مدیریتشده پس از ۱۸۰ دقیقه عدم فعالیت، به طور خودکار خاموش میشوند. اگر میخواهید نمونه را به صورت دستی خاموش کنید، روی دکمه Stop در بخش Vertex AI Workbench کنسول کلیک کنید. اگر میخواهید نوتبوک را به طور کامل حذف کنید، روی دکمه Delete کلیک کنید.

برای حذف Storage Bucket، با استفاده از منوی ناوبری در Cloud Console خود، به Storage بروید، Bucket خود را انتخاب کنید و روی Delete کلیک کنید: