
1. Ringkasan
Di lab ini, Anda akan mempelajari cara mengonfigurasi dan meluncurkan eksekusi notebook dengan Vertex AI Workbench.
Yang Anda pelajari
Anda akan mempelajari cara:
- Menggunakan parameter dalam notebook
- Mengonfigurasi dan meluncurkan eksekusi notebook dari UI Vertex AI Workbench
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $2.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI. Jika Anda memiliki masukan, harap lihat halaman dukungan.
Vertex AI mencakup banyak produk yang berbeda untuk mendukung alur kerja ML secara menyeluruh. Lab ini akan berfokus pada Vertex AI Workbench.
Vertex AI Workbench membantu pengguna membangun alur kerja berbasis notebook end-to-end dengan cepat melalui integrasi yang mendalam dengan layanan data (seperti Dataproc, Dataflow, BigQuery, dan Dataplex) dan Vertex AI. Vertex AI Workbench memungkinkan data scientist terhubung ke layanan data GCP, menganalisis set data, bereksperimen dengan berbagai teknik pemodelan, men-deploy model terlatih ke produksi, dan mengelola MLOps melalui siklus proses model.
3. Ringkasan kasus penggunaan
Di lab ini, Anda akan menggunakan transfer learning untuk melatih model klasifikasi gambar pada set data DeepWeeds dari Set Data TensorFlow. Anda akan menggunakan TensorFlow Hub untuk bereksperimen dengan vektor fitur yang diekstrak dari berbagai arsitektur model, seperti ResNet50, Inception, dan MobileNet, yang semuanya telah dilatih sebelumnya pada set data tolok ukur ImageNet. Dengan memanfaatkan eksekutor notebook melalui UI Vertex AI Workbench, Anda akan meluncurkan tugas di Vertex AI Training yang menggunakan model terlatih ini dan melatih ulang lapisan terakhir untuk mengenali kelas dari set data DeepWeeds.
4. Menyiapkan lingkungan Anda
Anda memerlukan project Google Cloud Platform dengan penagihan yang diaktifkan untuk menjalankan codelab ini. Untuk membuat project, ikuti petunjuk di sini.
Langkah 1: Aktifkan Compute Engine API
Buka Compute Engine dan pilih Aktifkan jika belum diaktifkan.
Langkah 2: Aktifkan Vertex AI API
Buka bagian Vertex AI di Cloud Console Anda, lalu klik Aktifkan Vertex AI API.

Langkah 3: Membuat instance Vertex AI Workbench
Dari bagian Vertex AI di Cloud Console Anda, klik Workbench:

Aktifkan Notebooks API jika belum diaktifkan.

Setelah diaktifkan, klik NOTEBOOK TERKELOLA:

Kemudian, pilih NOTEBOOK BARU.

Beri nama notebook Anda, lalu klik Setelan Lanjutan.

Di bagian Setelan Lanjutan, aktifkan penonaktifan tidak ada aktivitas dan setel jumlah menit ke 60. Artinya, notebook Anda akan otomatis dinonaktifkan saat tidak digunakan agar tidak menimbulkan biaya tambahan.

Anda dapat membiarkan semua setelan lanjutan lainnya apa adanya.
Selanjutnya, klik Buat.
Setelah instance dibuat, pilih Buka JupyterLab.

Saat pertama kali menggunakan instance baru, Anda akan diminta untuk mengautentikasi.

Vertex AI Workbench memiliki lapisan kompatibilitas komputasi yang memungkinkan Anda meluncurkan kernel untuk TensorFlow, PySpark, R, dll., semuanya dari satu instance notebook. Setelah melakukan autentikasi, Anda dapat memilih jenis notebook yang ingin digunakan dari peluncur.
Untuk lab ini, pilih kernel TensorFlow 2.

5. Menulis kode pelatihan
Set data DeepWeeds terdiri dari 17.509 gambar yang merekam delapan spesies gulma berbeda yang berasal dari Australia. Di bagian ini, Anda akan menulis kode untuk memproses awal set data DeepWeeds, serta membuat dan melatih model klasifikasi gambar menggunakan vektor fitur yang didownload dari TensorFlow Hub.
Anda harus menyalin cuplikan kode berikut ke dalam sel notebook. Eksekusi sel bersifat opsional.
Langkah 1: Download dan lakukan pra-pemrosesan set data
Pertama, instal set data TensorFlow versi malam untuk memastikan kita mengambil set data DeepWeeds versi terbaru.
!pip install tfds-nightly
Kemudian, impor library yang diperlukan:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Download data dari TensorFlow Datasets dan ekstrak jumlah kelas dan ukuran set data.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Tentukan fungsi praproses untuk menskalakan data gambar sebesar 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
Set data DeepWeeds tidak dilengkapi dengan pemisahan pelatihan/validasi. Model ini hanya dilengkapi dengan set data pelatihan. Dalam kode di bawah, Anda akan menggunakan 80% data tersebut untuk pelatihan, dan 20% sisanya untuk validasi.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Langkah 2: Buat model
Setelah membuat set data pelatihan dan validasi, Anda siap membangun model. TensorFlow Hub menyediakan vektor fitur, yang merupakan model terlatih tanpa lapisan klasifikasi teratas. Anda akan membuat pengekstraksi fitur dengan membungkus model terlatih dengan hub.KerasLayer, yang membungkus TensorFlow SavedModel sebagai lapisan Keras. Kemudian, Anda akan menambahkan lapisan klasifikasi dan membuat model dengan Keras Sequential API.
Pertama, tentukan parameter feature_extractor_model, yaitu nama vektor fitur TensorFlow Hub yang akan Anda gunakan sebagai dasar model.
feature_extractor_model = "inception_v3"
Selanjutnya, Anda akan menjadikan sel ini sebagai sel parameter, yang akan memungkinkan Anda meneruskan nilai untuk feature_extractor_model saat runtime.
Pertama, pilih sel dan klik pemeriksa properti di panel kanan.

Tag adalah cara sederhana untuk menambahkan metadata ke notebook Anda. Ketik "parameters" di kotak Tambahkan Tag, lalu tekan Enter. Nanti saat mengonfigurasi eksekusi, Anda akan meneruskan nilai yang berbeda, dalam hal ini model TensorFlow Hub, yang ingin Anda uji. Perhatikan bahwa Anda harus mengetik kata "parameters" (dan bukan kata lain) karena dengan cara ini, eksekutor notebook mengetahui sel mana yang akan diparameterkan.
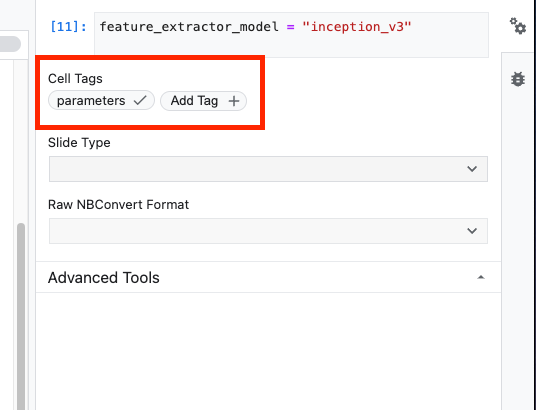
Anda dapat menutup pemeriksa properti dengan mengklik ikon roda gigi ganda lagi.
Buat sel baru dan tentukan tf_hub_uri, tempat Anda akan menggunakan interpolasi string untuk mengganti nama model terlatih yang ingin digunakan sebagai model dasar untuk eksekusi spesifik notebook Anda. Secara default, Anda telah menyetel feature_extractor_model ke "inception_v3", tetapi nilai valid lainnya adalah "resnet_v2_50" atau "mobilenet_v1_100_224". Anda dapat menjelajahi opsi tambahan di katalog TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
Selanjutnya, buat pengekstraksi fitur menggunakan hub.KerasLayer dan teruskan tf_hub_uri yang Anda tentukan di atas. Tetapkan argumen trainable=False untuk membekukan variabel sehingga pelatihan hanya mengubah lapisan klasifikasi baru yang akan Anda tambahkan di atasnya.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Untuk melengkapi model, gabungkan lapisan pengekstraksi fitur dalam model tf.keras.Sequential dan tambahkan lapisan yang terhubung sepenuhnya untuk klasifikasi. Jumlah unit dalam head klasifikasi ini harus sama dengan jumlah kelas dalam set data:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Terakhir, kompilasi dan sesuaikan model.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Menjalankan notebook
Klik ikon Executor di bagian atas notebook.

Langkah 1: Konfigurasi tugas pelatihan
Beri nama eksekusi Anda dan sediakan bucket penyimpanan di project Anda.

Setel Jenis mesin ke 4 CPU, RAM 15 GB.
Lalu tambahkan 1 GPU NVIDIA.
Setel lingkungan ke TensorFlow Enterprise 2.6 (GPU).
Pilih Eksekusi sekali.
Langkah 2: Konfigurasi parameter
Klik drop-down OPSI LANJUTAN untuk menetapkan parameter. Di kotak, ketik feature_extractor_model=resnet_v2_50. Tindakan ini akan mengganti inception_v3, nilai default yang Anda tetapkan untuk parameter ini di notebook, dengan resnet_v2_50.

Anda dapat membiarkan kotak gunakan akun layanan default dicentang.
Kemudian, klik KIRIM
Langkah 3: Periksa hasil
Di tab Executions di UI Konsol, Anda dapat melihat status eksekusi notebook.

Jika mengklik nama eksekusi, Anda akan diarahkan ke tugas Vertex AI Training tempat notebook Anda berjalan.

Setelah tugas selesai, Anda dapat melihat notebook output dengan mengklik LIHAT HASIL.

Di notebook output, Anda akan melihat bahwa nilai untuk feature_extractor_model ditimpa oleh nilai yang Anda teruskan saat runtime.

🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI Workbench untuk:
- Menggunakan parameter dalam notebook
- Mengonfigurasi dan meluncurkan eksekusi notebook dari UI Vertex AI Workbench
Untuk mempelajari lebih lanjut berbagai bagian Vertex AI, lihat dokumentasinya.
7. Pembersihan
Secara default, notebook terkelola akan dinonaktifkan secara otomatis setelah 180 menit tidak ada aktivitas. Jika Anda ingin menonaktifkan instance secara manual, klik tombol Hentikan di bagian Vertex AI Workbench pada konsol. Jika Anda ingin menghapus notebook secara keseluruhan, klik tombol Hapus.

Untuk menghapus Bucket Penyimpanan menggunakan menu Navigasi di Cloud Console, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus:
