
1. 개요
이번 실습에서는 Vertex AI Workbench를 사용하여 노트북 실행을 구성하고 실행하는 방법을 알아봅니다.
학습 내용
다음 작업을 수행하는 방법을 배우게 됩니다.
- 노트북에서 매개변수 사용
- Vertex AI Workbench UI에서 노트북 실행 구성 및 실행
Google Cloud에서 이 실습을 진행하는 데 드는 총 비용은 약 $2 입니다.
2. Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 이전할 수도 있습니다. 의견이 있는 경우 지원 페이지를 참고하세요.
Vertex AI에는 엔드 투 엔드 ML 워크플로를 지원하는 다양한 제품이 포함되어 있습니다. 이 실습은 Vertex AI Workbench에 중점을 둡니다.
Vertex AI Workbench는 데이터 서비스 (예: Dataproc, Dataflow, BigQuery, Dataplex) 및 Vertex AI와의 긴밀한 통합을 통해 사용자가 엔드 투 엔드 노트북 기반 워크플로를 빠르게 빌드할 수 있도록 지원합니다. 데이터 과학자는 이를 통해 GCP 데이터 서비스에 연결하고, 데이터 세트를 분석하고, 다양한 모델링 기법을 실험하고, 학습된 모델을 프로덕션에 배포하고, 모델 수명 주기를 통해 MLOps를 관리할 수 있습니다.
3. 사용 사례 개요
이 실습에서는 전이 학습을 사용하여 DeepWeeds 데이터 세트에서 TensorFlow 데이터 세트의 이미지 분류 모델을 학습시킵니다. TensorFlow Hub를 사용하여 ImageNet 벤치마크 데이터 세트에서 사전 학습된 ResNet50, Inception, MobileNet과 같은 다양한 모델 아키텍처에서 추출된 특징 벡터를 실험합니다. Vertex AI Workbench UI를 통해 노트북 실행자를 활용하여 이러한 사전 학습된 모델을 사용하고 마지막 레이어를 재학습하여 DeepWeeds 데이터 세트의 클래스를 인식하는 Vertex AI Training에서 작업을 실행합니다.
4. 환경 설정하기
이 Codelab을 실행하려면 결제가 사용 설정된 Google Cloud Platform 프로젝트가 필요합니다. 프로젝트를 만들려면 여기의 안내를 따르세요.
1단계: Compute Engine API 사용 설정
아직 사용 설정되지 않은 경우 Compute Engine으로 이동하고 사용 설정을 선택합니다.
2단계: Vertex AI API 사용 설정
Cloud Console의 Vertex AI 섹션으로 이동하고 Vertex AI API 사용 설정을 클릭합니다.

3단계: Vertex AI Workbench 인스턴스 만들기
Cloud 콘솔의 Vertex AI 섹션에서 'Workbench'를 클릭합니다.

Notebooks API를 아직 사용 설정하지 않은 경우 사용 설정합니다.

사용 설정했으면 관리형 노트북을 클릭합니다.

그런 다음 새 노트북을 선택합니다.

노트북 이름을 지정한 후 고급 설정을 클릭합니다.

고급 설정에서 유휴 상태 종료를 사용 설정하고 분을 60으로 설정합니다. 즉, 노트북을 사용하지 않을 때는 자동으로 종료되므로 불필요한 비용이 발생하지 않습니다.

다른 고급 설정은 모두 그대로 두면 됩니다.
그런 다음 만들기 를 클릭합니다.
인스턴스가 생성되면 JupyterLab 열기 를 선택합니다.

새 인스턴스를 처음 사용하는 경우 인증하라는 메시지가 표시됩니다.

Vertex AI Workbench에는 단일 노트북 인스턴스에서 TensorFlow, PySpark, R 등의 커널을 실행할 수 있는 컴퓨팅 호환성 레이어가 있습니다. 인증 후 실행기에서 사용할 노트북 유형을 선택할 수 있습니다.
이 실습에서는 TensorFlow 2 커널을 선택합니다.

5. 학습 코드 작성
DeepWeeds 데이터 세트는 호주에 서식하는 8가지 잡초 종을 포착한 17,509개의 이미지로 구성됩니다. 이 섹션에서는 DeepWeeds 데이터 세트를 사전 처리하고 TensorFlow Hub에서 다운로드한 특징 벡터를 사용하여 이미지 분류 모델을 빌드하고 학습시키는 코드를 작성합니다.
다음 코드 스니펫을 노트북의 셀에 복사해야 합니다. 셀 실행은 선택사항입니다.
1단계: 데이터 세트 다운로드 및 사전 처리
먼저 TensorFlow 데이터 세트의 야간 버전을 설치하여 최신 버전의 DeepWeeds 데이터 세트를 가져오도록 합니다.
!pip install tfds-nightly
그런 다음 필요한 라이브러리를 가져옵니다.
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
TensorFlow 데이터 세트에서 데이터를 다운로드하고 클래스 수와 데이터 세트 크기를 추출합니다.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
이미지 데이터를 255로 조정하는 사전 처리 함수를 정의합니다.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
DeepWeeds 데이터 세트에는 학습/검증 분할이 포함되어 있지 않습니다. 학습 데이터 세트만 포함되어 있습니다. 아래 코드에서는 해당 데이터의 80% 를 학습에 사용하고 나머지 20% 를 검증에 사용합니다.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
2단계: 모델 만들기
이제 학습 및 검증 데이터 세트를 만들었으므로 모델을 빌드할 준비가 되었습니다. TensorFlow Hub는 상위 분류 레이어가 없는 사전 학습된 모델인 특징 벡터를 제공합니다. TensorFlow SavedModel을 Keras 레이어로 래핑하는 hub.KerasLayer로 사전 학습된 모델을 래핑하여 특징 추출기를 만듭니다. 그런 다음 분류 레이어를 추가하고 Keras Sequential API로 모델을 만듭니다.
먼저 모델의 기반으로 사용할 TensorFlow Hub 특징 벡터의 이름인 feature_extractor_model 매개변수를 정의합니다.
feature_extractor_model = "inception_v3"
그런 다음 이 셀을 매개변수 셀로 만들어 런타임에 feature_extractor_model의 값을 전달할 수 있도록 합니다.
먼저 셀을 선택하고 오른쪽 패널에서 속성 검사기를 클릭합니다.

태그는 노트북에 메타데이터를 추가하는 간단한 방법입니다. 태그 추가 상자에 'parameters'를 입력하고 Enter 키를 누릅니다. 나중에 실행을 구성할 때 테스트할 다양한 값(이 경우 TensorFlow Hub 모델)을 전달합니다. 노트북 실행자가 매개변수화할 셀을 인식하는 방법이므로 'parameters'라는 단어를 입력해야 합니다(다른 단어는 안 됨).
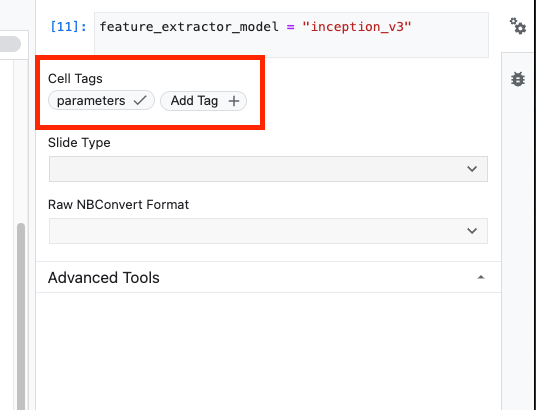
이중 톱니바퀴 아이콘을 다시 클릭하여 속성 검사기를 닫을 수 있습니다.
새 셀을 만들고 tf_hub_uri를 정의합니다. 여기서 문자열 보간을 사용하여 노트북의 특정 실행에 대한 기본 모델로 사용할 사전 학습된 모델의 이름을 대체합니다. 기본적으로 feature_extractor_model은 "inception_v3"으로 설정되어 있지만 다른 유효한 값은 "resnet_v2_50" 또는 "mobilenet_v1_100_224"입니다. TensorFlow Hub 카탈로그에서 추가 옵션을 살펴볼 수 있습니다.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
그런 다음 hub.KerasLayer를 사용하여 특징 추출기를 만들고 위에서 정의한 tf_hub_uri를 전달합니다. trainable=False 인수를 설정하여 변수를 고정하면 학습 시 추가할 새 분류기 레이어만 수정됩니다.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
모델을 완성하려면 특징 추출기 레이어를 tf.keras.Sequential 모델로 래핑하고 분류를 위한 완전 연결 레이어를 추가합니다. 이 분류 헤드의 단위 수는 데이터 세트의 클래스 수와 같아야 합니다.
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
마지막으로 모델을 컴파일하고 맞춥니다.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. 노트북 실행
노트북 상단의 실행자 아이콘을 클릭합니다.

1단계: 학습 작업 구성
실행 이름을 지정하고 프로젝트에 스토리지 버킷을 제공합니다.

머신 유형을 CPU 4개, RAM 15GB 로 설정합니다.
그리고 NVIDIA GPU 1개 를 추가합니다.
환경을 TensorFlow Enterprise 2.6 (GPU)으로 설정합니다.
일회성 실행을 선택합니다.
2단계: 매개변수 구성
고급 옵션 드롭다운을 클릭하여 매개변수를 설정합니다. 상자에 feature_extractor_model=resnet_v2_50을 입력합니다. 이렇게 하면 노트북에서 이 매개변수에 대해 설정한 기본값인 inception_v3이 resnet_v2_50으로 재정의됩니다.

기본 서비스 계정 사용 상자는 선택된 상태로 두면 됩니다.
그런 다음 제출 을 클릭합니다.
3단계: 결과 검토
콘솔 UI의 실행 탭에서 노트북 실행 상태를 확인할 수 있습니다.

실행 이름을 클릭하면 노트북이 실행 중인 Vertex AI Training 작업으로 이동합니다.

작업이 완료되면 결과 보기 를 클릭하여 출력 노트북을 볼 수 있습니다.

출력 노트북에서 feature_extractor_model의 값이 런타임에 전달한 값으로 덮어쓰여진 것을 확인할 수 있습니다.

🎉 수고하셨습니다. 🎉
Vertex AI Workbench를 사용하여 다음을 수행하는 방법을 배웠습니다.
- 노트북에서 매개변수 사용
- Vertex AI Workbench UI에서 노트북 실행 구성 및 실행
Vertex AI의 다른 부분에 대해 자세히 알아보려면 문서를 확인하세요.
7. 삭제
기본적으로 관리형 노트북은 180분 동안 활동이 없으면 자동으로 종료됩니다. 인스턴스를 수동으로 종료하려면 콘솔의 Vertex AI Workbench 섹션에서 '중지' 버튼을 클릭합니다. 노트북을 완전히 삭제하려면 삭제 버튼을 클릭합니다.

스토리지 버킷을 삭제하려면 Cloud Console의 탐색 메뉴를 사용하여 스토리지로 이동하고 버킷을 선택하고 삭제를 클릭합니다.
