
1. Visão geral
Neste laboratório, você vai aprender a configurar e iniciar execuções de notebook com o Vertex AI Workbench.
Conteúdo do laboratório
Você vai aprender a:
- Usar parâmetros em um notebook
- Configurar e iniciar execuções de notebook na interface do Vertex AI Workbench
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$ 2.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos existentes para a Vertex AI. Se você tiver algum feedback, consulte a página de suporte.
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho integrais de ML. Este laboratório se concentra no Vertex AI Workbench.
Com o Vertex AI Workbench, os usuários criam de modo rápido fluxos de trabalho completos com notebooks, por meio da integração entre serviços de dados (como Dataproc, Dataflow, BigQuery e Dataplex) e a Vertex AI. Ele permite que cientistas de dados se conectem aos serviços de dados do GCP, analisem conjuntos de dados, testem diferentes técnicas de modelagem, implantem modelos treinados na produção e gerenciem MLOps durante o ciclo de vida do modelo.
3. Visão geral do caso de uso
Neste laboratório, você vai usar aprendizado por transferência para treinar um modelo de classificação de imagens no conjunto de dados DeepWeeds dos conjuntos de dados do TensorFlow. Você vai usar o TensorFlow Hub para testar vetores de recursos extraídos de diferentes arquiteturas de modelo, como ResNet50, Inception e MobileNet, todos pré-treinados no conjunto de dados de comparativo de mercado ImageNet. Ao aproveitar o executor de notebooks pela interface do Vertex AI Workbench, você vai iniciar jobs no Vertex AI Training que usam esses modelos pré-treinados e treinar novamente a última camada para reconhecer as classes do conjunto de dados DeepWeeds.
4. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 1: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada.
Etapa 2: ativar a API Vertex AI
Navegue até a seção "Vertex AI" do Console do Cloud e clique em Ativar API Vertex AI.

Etapa 3: criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":

Ative a API Notebooks, se ela ainda não tiver sido ativada.

Após a ativação, clique em NOTEBOOK GERENCIADO:

Em seguida, selecione NOVO NOTEBOOK.

Dê um nome ao notebook e clique em Configurações avançadas.

Em "Configurações avançadas", ative o encerramento inativo e defina o número de minutos como 60. Isso significa que o notebook será desligado automaticamente quando não estiver sendo usado.

Você pode manter as outras configurações avançadas como estão.
Em seguida, clique em Criar.
Quando a instância tiver sido criada, selecione Abrir o JupyterLab.

Na primeira vez que usar uma nova instância, você vai receber uma solicitação de autenticação.

O Vertex AI Workbench tem uma camada de compatibilidade de computação que permite iniciar kernels para TensorFlow, PySpark, R etc., tudo em uma única instância de notebook. Depois da autenticação, você poderá selecionar o tipo de notebook que quer usar no iniciador.
Neste laboratório, selecione o kernel do TensorFlow 2.

5. Escrever o código de treinamento
O conjunto de dados DeepWeeds consiste em 17.509 imagens que capturam oito espécies diferentes de ervas daninhas nativas da Austrália. Nesta seção, você vai escrever o código para pré-processar o conjunto de dados DeepWeeds e criar e treinar um modelo de classificação de imagens usando vetores de atributos baixados do TensorFlow Hub.
Você precisará copiar os snippets de código a seguir nas células do notebook. A execução das células é opcional.
Etapa 1: fazer o download e pré-processar o conjunto de dados
Primeiro, instale a versão noturna dos conjuntos de dados do TensorFlow para garantir que estamos usando a versão mais recente do conjunto de dados DeepWeeds.
!pip install tfds-nightly
Em seguida, importe as bibliotecas necessárias:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Faça o download dos dados do TensorFlow Datasets e extraia o número de classes e o tamanho do conjunto de dados.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Defina uma função de pré-processamento para escalonar os dados de imagem em 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
O conjunto de dados DeepWeeds não vem com divisões de treino/validação. Ele vem apenas com um conjunto de dados de treinamento. No código abaixo, você vai usar 80% desses dados para treinamento e os 20% restantes para validação.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Etapa 2: criar modelo
Agora que você criou conjuntos de dados de treinamento e validação, está tudo pronto para criar seu modelo. O TensorFlow Hub oferece vetores de recursos, que são modelos pré-treinados sem a camada de classificação superior. Você vai criar um extrator de recursos envolvendo o modelo pré-treinado com hub.KerasLayer, que envolve um SavedModel do TensorFlow como uma camada do Keras. Em seguida, você vai adicionar uma camada de classificação e criar um modelo com a API Keras Sequential.
Primeiro, defina o parâmetro feature_extractor_model, que é o nome do vetor de recursos do TensorFlow Hub que você vai usar como base para seu modelo.
feature_extractor_model = "inception_v3"
Em seguida, você vai transformar essa célula em uma célula de parâmetro, o que permite transmitir um valor para feature_extractor_model durante a execução.
Primeiro, selecione a célula e clique no inspetor de propriedades no painel à direita.

As tags são uma maneira simples de adicionar metadados ao notebook. Digite "parameters" na caixa "Adicionar tag" e pressione Enter. Mais tarde, ao configurar a execução, você vai transmitir os diferentes valores, nesse caso, o modelo do TensorFlow Hub que você quer testar. Observe que você deve digitar a palavra "parameters" (e não outra palavra), pois é assim que o executor de notebook sabe quais células parametrizar.
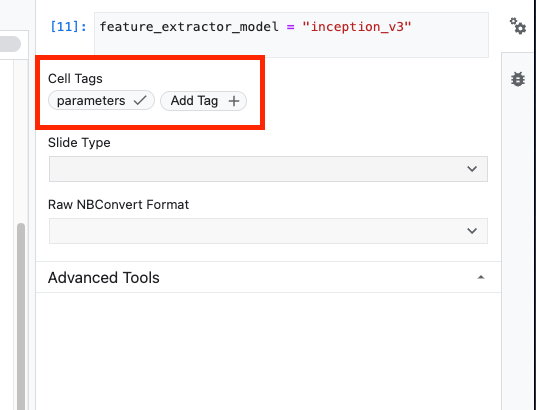
Clique novamente no ícone de engrenagem dupla para fechar o inspetor de propriedades.
Crie uma célula e defina o tf_hub_uri, em que você vai usar a interpolação de strings para substituir o nome do modelo pré-treinado que quer usar como modelo de base para uma execução específica do notebook. Por padrão, você definiu feature_extractor_model como "inception_v3", mas outros valores válidos são "resnet_v2_50" ou "mobilenet_v1_100_224". Confira outras opções no catálogo do TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
Em seguida, crie o extrator de recursos usando hub.KerasLayer e transmitindo o tf_hub_uri definido acima. Defina o argumento trainable=False para congelar as variáveis. Assim, o treinamento só vai modificar a nova camada de classificador que você vai adicionar por cima.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Para concluir o modelo, encapsule a camada de extração de recursos em um modelo tf.keras.Sequential e adicione uma camada totalmente conectada para classificação. O número de unidades neste cabeçalho de classificação precisa ser igual ao número de classes no conjunto de dados:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Por fim, compile e ajuste o modelo.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Executar notebook
Clique no ícone Executor na parte de cima do notebook.

Etapa 1: configurar job de treinamento
Dê um nome à execução e forneça um bucket de armazenamento no projeto.

Defina o tipo de máquina como 4 CPUs, 15 GB de RAM.
e adicione uma GPU NVIDIA.
Defina o ambiente como TensorFlow Enterprise 2.6 (GPU).
Escolha "Execução única".
Etapa 2: configurar parâmetros
Clique no menu suspenso OPÇÕES AVANÇADAS para definir seu parâmetro. Na caixa, digite feature_extractor_model=resnet_v2_50. Isso vai substituir inception_v3, o valor padrão definido para esse parâmetro no notebook, por resnet_v2_50.

Você pode deixar a caixa Usar conta de serviço padrão marcada.
Em seguida, clique em ENVIAR.
Etapa 3: analisar os resultados
Na guia "Execuções" da interface do console, é possível conferir o status da execução do notebook.

Se você clicar no nome da execução, vai acessar o job de treinamento da Vertex AI em que o notebook está sendo executado.

Quando o job for concluído, clique em VER RESULTADO para conferir o notebook de saída.

No notebook de saída, você vai notar que o valor de feature_extractor_model foi substituído pelo valor transmitido durante a execução.

Parabéns! 🎉
Você aprendeu a usar o Vertex AI Workbench para:
- Usar parâmetros em um notebook
- Configurar e iniciar execuções de notebook na interface do Vertex AI Workbench
Para saber mais sobre partes diferentes da Vertex AI, acesse a documentação.
7. Limpeza
Por padrão, os notebooks gerenciados são desligados automaticamente após 180 minutos de inatividade. Para encerrar a instância manualmente, clique no botão "Parar" na seção "Vertex AI Workbench" do console. Se quiser excluir o notebook completamente, clique no botão "Excluir".

Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em "Excluir":
