
1. نظرة عامة
في عالمنا اليوم الذي يزخر بالبيانات، يُعدّ استخراج معلومات مفيدة من المحتوى غير المنظَّم، وخاصةً الفيديو، ضرورة كبيرة. تخيّل أنّك بحاجة إلى تحليل مئات أو آلاف عناوين URL للفيديوهات، وتلخيص محتواها، واستخراج التكنولوجيات الرئيسية، وحتى إنشاء أزواج من الأسئلة والأجوبة للمواد التعليمية. إنّ تنفيذ ذلك بشكل فردي لا يستغرق وقتًا طويلاً فحسب، بل يكون أيضًا غير فعّال. وهنا تبرز أهمية بنى السحابة الحديثة.
في هذا المختبر، سنشرح الحلّ القابل للتوسّع والذي لا يتطلّب خادمًا لمعالجة محتوى الفيديو باستخدام مجموعة خدمات Google Cloud الفعّالة: Cloud Run وBigQuery و"الذكاء الاصطناعي التوليدي" من Google (Gemini). سنشرح بالتفصيل رحلتنا من معالجة عنوان URL واحد إلى تنسيق التنفيذ المتوازي على مجموعة بيانات كبيرة، وكل ذلك بدون عبء إدارة قوائم انتظار الرسائل وعمليات الدمج المعقّدة.
التحدّي
كانت مهمتنا معالجة كتالوج كبير من محتوى الفيديو، مع التركيز بشكل خاص على الجلسات العملية في المختبر. كان الهدف هو تحليل كل فيديو وإنشاء ملخّص منظَّم، بما في ذلك عناوين الفصول وسياق المقدمة والتعليمات المفصّلة والتقنيات المستخدَمة وأزواج الأسئلة والأجوبة ذات الصلة. كان من الضروري تخزين هذا الناتج بكفاءة لاستخدامه لاحقًا في إنشاء مواد تعليمية.
في البداية، كان لدينا خدمة بسيطة مستندة إلى HTTP في Cloud Run يمكنها معالجة عنوان URL واحد في كل مرة. وقد كان هذا الإعداد مناسبًا للاختبار والتحليل المخصّص. ومع ذلك، عند مواجهة قائمة تضمّ آلاف عناوين URL من BigQuery، أصبحت القيود المفروضة على نموذج الطلب الواحد والاستجابة الواحدة واضحة. ستستغرق المعالجة التسلسلية أيامًا، إن لم يكن أسابيع.
الفرصة كانت تحويل عملية يدوية أو تسلسلية بطيئة إلى سير عمل آلي ومتوازٍ. من خلال الاستفادة من السحابة الإلكترونية، أردنا تحقيق ما يلي:
- معالجة البيانات بالتوازي: تقليل وقت المعالجة بشكل كبير لمجموعات البيانات الكبيرة
- الاستفادة من إمكانات الذكاء الاصطناعي الحالية: يمكنك الاستفادة من إمكانات Gemini في تحليل المحتوى المعقّد.
- الحفاظ على بنية الحوسبة بدون خادم: تجنَّب إدارة الخوادم أو البنية الأساسية المعقّدة.
- تجميع البيانات في مكان واحد: استخدِم BigQuery كمصدر واحد للحقائق بشأن عناوين URL المُدخَلة ووجهة موثوقة للنتائج المعالَجة.
- إنشاء مسار معالجة قوي: أنشئ نظامًا مرنًا في مواجهة الأعطال ويمكن إدارته ومراقبته بسهولة.
الهدف
تنظيم المعالجة المتوازية للذكاء الاصطناعي باستخدام "مهام Cloud Run":
يرتكز حلّنا على مهمة Cloud Run تعمل كمنسّق. يقرأ هذا الحلّ بذكاء مجموعات من عناوين URL من BigQuery، ويرسلها إلى خدمة Cloud Run الحالية التي تم نشرها (والتي تعالج المعالجة بالذكاء الاصطناعي لعنوان URL واحد)، ثم يجمع النتائج لإعادة كتابتها في BigQuery. يتيح لنا هذا النهج ما يلي:
- فصل عملية التنظيم عن المعالجة: تدير المهمة سير العمل، بينما تركّز الخدمة المنفصلة على مهمة الذكاء الاصطناعي.
- الاستفادة من التوازي في Cloud Run Job: يمكن أن تتوسّع المهمة لتشمل عدة مثيلات حاوية من أجل استدعاء خدمة الذكاء الاصطناعي بشكل متزامن.
- تقليل التعقيد: نحقّق التوازي من خلال جعل المهمة تدير طلبات HTTP المتزامنة مباشرةً، ما يؤدي إلى تبسيط البنية.
حالة الاستخدام
إحصاءات مستندة إلى الذكاء الاصطناعي من فيديوهات جلسات Code Vipassana
كانت حالة الاستخدام المحدّدة لدينا هي تحليل فيديوهات جلسات Google Cloud في مختبرات Code Vipassana العملية. كان الهدف هو إنشاء مستندات منظَّمة تلقائيًا (مخطّطات فصول الكتب)، بما في ذلك:
- عناوين الفصول: عناوين موجزة لكل قسم من الفيديو
- مقدمة حول السياق: شرح مدى صلة الفيديو بمسار تعليمي أوسع
- ما سيتم إنشاؤه: المهمة الأساسية أو الهدف من الجلسة
- التقنيات المستخدَمة: قائمة بالخدمات السحابية والتقنيات الأخرى المذكورة
- تعليمات مفصّلة: كيفية تنفيذ المهمة، بما في ذلك مقتطفات الرموز
- عناوين URL الخاصة برمز المصدر/العرض التوضيحي: الروابط المقدَّمة في الفيديو
- مقطع "أسئلة وأجوبة": إنشاء أسئلة وأجوبة مناسبة للتحقّق من المعلومات
Flow

مسار الهندسة المعمارية
ما هي خدمة Cloud Run؟ ما هي "مهام Cloud Run"؟
Cloud Run
منصة مُدارة بالكامل بدون خادم تتيح لك تشغيل الحاويات التي لا يتم تسجيل بياناتها. وهي مثالية لخدمات الويب وواجهات برمجة التطبيقات والخدمات المصغّرة التي يمكن توسيع نطاقها تلقائيًا استنادًا إلى الطلبات الواردة. ما عليك سوى تقديم صورة حاوية، وسيتولّى Cloud Run بقية المهام، بدءًا من النشر والتوسيع إلى إدارة البنية الأساسية. وهو متميّز في التعامل مع أحمال العمل المتزامنة التي تتطلب إرسال طلب وتلقّي رد.
مهام Cloud Run
عرض تكميلي لخدمات Cloud Run تم تصميم "مهام Cloud Run" لمعالجة المهام على دفعات التي يجب إكمالها ثم إيقافها. وهي مثالية لمعالجة البيانات واستخراجها وتحويلها وتحميلها (ETL) والاستدلال المجمّع في تعلُّم الآلة وأي مهمة تتضمّن معالجة مجموعة بيانات بدلاً من الاستجابة للطلبات المباشرة. من الميزات الرئيسية قدرتها على توسيع نطاق عدد مثيلات الحاويات (المهام) التي يتم تشغيلها بشكل متزامن لمعالجة مجموعة من المهام، ويمكن تشغيلها من خلال مصادر أحداث مختلفة أو يدويًا.
الاختلاف الرئيسي
خدمات Cloud Run مخصّصة للتطبيقات التي تعمل لفترة طويلة والمستندة إلى الطلبات. تُستخدَم "مهام Cloud Run" للمعالجة على دفعات المحدودة والموجّهة نحو المهام والتي يتم تنفيذها حتى اكتمالها.
ما ستنشئه
تطبيق بحث للبيع بالتجزئة
في إطار ذلك، ستتمكّن من:
- إنشاء مجموعة بيانات وجدول في BigQuery واستيعاب البيانات (البيانات الوصفية لـ Code Vipassana)
- إنشاء دالة Python Cloud Run لتنفيذ وظيفة الذكاء الاصطناعي التوليدي (تحويل الفيديو إلى ملف json خاص بفصول الكتاب)
- إنشاء تطبيق Python لخط أنابيب البيانات إلى الذكاء الاصطناعي - القراءة من BigQuery واستدعاء نقطة نهاية "وظائف Cloud Run" للحصول على إحصاءات وكتابة السياق مرة أخرى إلى BigQuery
- إنشاء التطبيق وحفظه في حاوية
- ضبط مهمة Cloud Run باستخدام هذه الحاوية
- تنفيذ المهمة ومراقبتها
- الإبلاغ عن نتيجة
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع .
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من إكمال عملية المصادقة وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة: اتّبِع الرابط وفعِّل واجهات برمجة التطبيقات.
يمكنك بدلاً من ذلك استخدام أمر gcloud لهذا الغرض. راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
3- إعداد قاعدة البيانات أو مستودع البيانات
BigQuery العمود الفقري لعملية نقل البيانات. وبفضل طبيعتها التي لا تعتمد على خادم والقابلة للتوسع بدرجة كبيرة، فهي مثالية لتخزين بيانات الإدخال واحتواء النتائج المعالَجة.
- تخزين البيانات: عملت خدمة BigQuery كمستودع بيانات. يخزّن هذا الجدول قائمة بعناوين URL للفيديوهات وحالتها (مثل "في انتظار المراجعة" أو "قيد المعالجة" أو "مكتملة") والسياق النهائي الذي تم إنشاؤه. وهو المصدر الوحيد للحقيقة الذي يحدّد الفيديوهات التي تحتاج إلى معالجة.
- الوجهة: هي المكان الذي يتم فيه تخزين الإحصاءات التي تم إنشاؤها بواسطة الذكاء الاصطناعي، ما يسهّل طلبها من التطبيقات اللاحقة أو مراجعتها يدويًا. تألّفت مجموعة البيانات لدينا من تفاصيل جلسات الفيديو، لا سيما من محتوى "مواسم Code Vipassana" الذي يتضمّن غالبًا عروضًا توضيحية فنية مفصّلة.
- جدول المصدر: هو جدول BigQuery (مثل post_session_labs) يحتوي على سجلّات مثل:
- المعرّف: معرّف فريد لكل جلسة أو صف.
- url: عنوان URL للفيديو (مثل رابط YouTube أو رابط Drive يمكن الوصول إليه)
- الحالة: سلسلة تشير إلى حالة المعالجة (مثل PENDING أو PROCESSING أو COMPLETED أو FAILED_PROCESSING).
- السياق: حقل سلسلة لتخزين الملخّص من إنشاء الذكاء الاصطناعي
- نقل البيانات: في هذا السيناريو، تم نقل البيانات إلى BigQuery باستخدام نصوص INSERT البرمجية. كانت BigQuery نقطة البداية في مسارنا.
انتقِل إلى وحدة تحكّم BigQuery، وافتح علامة تبويب جديدة ونفِّذ عبارات SQL التالية:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. نقل البيانات
حان الوقت الآن لإضافة جدول يتضمّن بيانات حول المتجر. انتقِل إلى علامة تبويب في BigQuery Studio ونفِّذ عبارات SQL التالية لإدراج السجلات النموذجية:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5- إنشاء وظيفة "إحصاءات الفيديو"
علينا إنشاء وظيفة Cloud Run وتفعيلها لتنفيذ الوظيفة الأساسية، وهي إنشاء فصل كتاب منظَّم من عنوان URL الخاص بالفيديو. للوصول إلى هذه الأدوات كمجموعة أدوات مستقلة لنقطة النهاية، أنشأنا ونشرنا دالة Cloud Run. يمكنك بدلاً من ذلك اختيار تضمين هذا كدالة منفصلة في تطبيق Python الفعلي لـ Cloud Run Job:
- في Google Cloud Console، انتقِل إلى صفحة Cloud Run.
- انقر على "كتابة دالة".
- في حقل "اسم الخدمة"، أدخِل اسمًا لوصف الدالة. يجب أن تبدأ أسماء الخدمات بحرف فقط، وأن تحتوي على 49 حرفًا أو أقل، بما في ذلك الأحرف أو الأرقام أو الواصلات. لا يمكن أن تنتهي أسماء الخدمات بشرطات، ويجب أن تكون فريدة لكل منطقة ومشروع. لا يمكن تغيير اسم الخدمة لاحقًا، وهو يظهر للجميع. ( generate-video-insights**)**
- في قائمة "المنطقة"، استخدِم القيمة التلقائية أو اختَر المنطقة التي تريد نشر الدالة فيها. (اختَر us-central1)
- في قائمة "وقت التشغيل" (Runtime)، استخدِم القيمة التلقائية أو اختَر إصدارًا لوقت التشغيل. (اختَر Python 3.11)
- في قسم "المصادقة"، اختَر "السماح بالوصول العام".
- انقر على الزر "إنشاء"
- يتم إنشاء الدالة وتحميلها باستخدام نموذج main.py وrequirements.txt
- استبدِل ذلك بالملفات: main.py و requirements.txt من مستودع هذا المشروع
ملاحظة مهمة: في ملف main.py، تذكَّر استبدال <<YOUR_PROJECT_ID>> بمعرّف مشروعك.
- انشر نقطة النهاية واحفظها لتتمكّن من استخدامها في المصدر الخاص بـ Cloud Run Job.
يجب أن تبدو نقطة النهاية على النحو التالي (أو ما شابه): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
ماذا تتضمّن دالة Cloud Run هذه؟
Gemini 2.5 Flash لمعالجة الفيديوهات
بالنسبة إلى المهمة الأساسية المتمثلة في فهم محتوى الفيديو وتلخيصه، استخدمنا نموذج Gemini 2.5 Flash من Google. نماذج Gemini هي نماذج ذكاء اصطناعي قوية ومتعددة الوسائط قادرة على فهم ومعالجة أنواع مختلفة من المدخلات، بما في ذلك النصوص والفيديوهات من خلال عمليات دمج محدّدة.
في عملية الإعداد، لم نزوّد Gemini بملف الفيديو مباشرةً. بدلاً من ذلك، أرسلنا طلبًا نصيًا يتضمّن عنوان URL للفيديو وطلبنا من Gemini تحليل المحتوى (الافتراضي) للفيديو على عنوان URL هذا. على الرغم من أنّ Gemini 2.5 Flash يتيح إدخال بيانات متعددة الوسائط، استخدمت هذه السلسلة المحدّدة طلبًا نصيًا يصف طبيعة الفيديو (جلسة عملية في المختبر) ويطلب إخراج JSON منظَّم. تستفيد هذه الميزة من قدرات Gemini المتقدّمة على الاستدلال المتقدّم وفهم اللغات الطبيعية لاستنتاج المعلومات وتلخيصها استنادًا إلى سياق الطلب.
الطلب المُوجَّه إلى Gemini: توجيه الذكاء الاصطناعي
تُعدّ الطلبات المصمَّمة جيدًا ضرورية لنماذج الذكاء الاصطناعي. تم تصميم الطلب لاستخراج معلومات محدّدة جدًا وتنظيمها بتنسيق JSON، ما يسهّل على تطبيقنا تحليلها.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
هذا الطلب محدّد للغاية، إذ يوجّه Gemini إلى التصرّف كمعلّم. يضمن طلب سلسلة JSON الحصول على ناتج منظَّم وقابل للقراءة آليًا.
في ما يلي الرمز البرمجي لتحليل إدخال الفيديو وعرض سياقه:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
يوضّح المقتطف أعلاه الوظيفة الأساسية لحالة الاستخدام. يتلقّى عنوان URL لفيديو ويستخدم نموذج Gemini من خلال برنامج Vertex AI للعميل من أجل تحليل محتوى الفيديو واستخراج المعلومات ذات الصلة وفقًا للطلب. بعد ذلك، يتم عرض السياق المستخرَج لمزيد من المعالجة. يمثّل ذلك عملية متزامنة تنتظر فيها مهمة Cloud Run اكتمال الخدمة.
6. تطوير تطبيقات مسار التعلّم (Python)
تتوفّر منطق خطوط الإنتاج المركزية في الرمز المصدر للتطبيق الذي سيتم وضعه في حاوية ضمن Cloud Run Job، ما ينسّق عملية التنفيذ المتوازي بأكملها. في ما يلي نظرة على الأجزاء الرئيسية:
دور أداة التنسيق في إدارة سير العمل وضمان صحّة البيانات:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
تبدأ المقتطفة أعلاه باسترداد مجموعة من عناوين URL للفيديوهات التي تحمل الحالة "في انتظار المراجعة" من جدول المصدر في BigQuery. بعد ذلك، يعدّل حالة عناوين URL هذه إلى "قيد المعالجة" في BigQuery، ما يمنع معالجتها بشكل مكرّر.
المعالجة المتوازية باستخدام ThreadPoolExecutor واستدعاء خدمة المعالجة:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
يستفيد هذا الجزء من الرمز من ThreadPoolExecutor لتحقيق المعالجة المتوازية لعناوين URL الخاصة بالفيديوهات التي تم جلبها. وبالنسبة إلى كل عنوان URL، يتم إرسال مهمة لاستدعاء خدمة Cloud Run (معالج عناوين URL) بشكل غير متزامن. يسمح ذلك لخدمة Cloud Run Job بمعالجة فيديوهات متعددة في الوقت نفسه بكفاءة، ما يحسّن أداء خط المعالجة بشكل عام. يتعامل المقتطف أيضًا مع المهلات والأخطاء المحتملة من خدمة المعالجة.
القراءة والكتابة من BigQuery وإليه
يتضمّن التفاعل الأساسي مع BigQuery جلب عناوين URL في انتظار المعالجة ثم تعديلها بالنتائج المعالَجة.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
كتابة النتائج مرة أخرى في BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
تركز المقتطفات أعلاه على التفاعل بين البيانات في Cloud Run Job وBigQuery. يستردّ هذا الإجراء مجموعة من عناوين URL للفيديوهات التي تحمل الحالة "في انتظار المراجعة" ومعرّفاتها من جدول المصدر. بعد معالجة عناوين URL، توضّح هذه المقتطفة كيفية إعادة كتابة السياق والحالة المستخرَجَين ("مكتملة" أو "تعذّر المعالجة") إلى جدول BigQuery المستهدَف باستخدام طلب بحث UPDATE. تُكمل هذه المقتطفة حلقة معالجة البيانات. يتضمّن أيضًا الدالة المساعدة update_bq_row التي توضّح كيفية تحديد مَعلمات عبارة التعديل.
إعداد التطبيق
يتم تنظيم التطبيق كنص برمجي واحد بلغة Python سيتم وضعه في حاوية. تستفيد هذه الأداة من مكتبات برامج Google Cloud ووظائف إطار العمل لتحديد نقطة الدخول.
- الاعتماديات: google-cloud-bigquery وrequests
- الإعداد: يتم تحميل جميع الإعدادات المهمة (مشروع/مجموعة بيانات/جدول BigQuery، وعنوان URL لخدمة معالجة عناوين URL) من متغيرات البيئة، ما يجعل التطبيق قابلاً للنقل وآمنًا
- المنطق الأساسي: تنظّم الدالة process_batch_from_bq سير العمل بأكمله
- دمج الخدمات الخارجية: تعالج الدالة call_url_processor_service عملية التواصل مع خدمة Cloud Run المنفصلة
- التفاعل مع BigQuery: يتم استخدام bq_client لجلب عناوين URL وتعديل النتائج، مع التعامل مع المعلمات بشكلٍ سليم
- التوازي: تدير concurrent.futures.ThreadPoolExecutor المكالمات المتزامنة إلى الخدمة الخارجية
- نقطة الدخول: تعمل رموز Python البرمجية المسماة main.py كنقطة دخول تبدأ عملية المعالجة على دفعات.
لنبدأ إعداد التطبيق الآن:
- يمكنك البدء بالانتقال إلى "وحدة طرفية Cloud Shell" واستنساخ المستودع على النحو التالي:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- انتقِل إلى Cloud Shell Editor، حيث يمكنك الاطّلاع على المجلد الذي تم إنشاؤه حديثًا video-context-crj.
- احذف ما يلي لأنّ هذه الخطوات مكتملة في الأقسام السابقة:
- احذف المجلد Cloud_Run_Function.
- انتقِل إلى مجلد المشروع video-context-crj، وستظهر لك بنية المشروع على النحو التالي:
7. إعداد Dockerfile وإنشاء الحاويات
لنشر هذه المنطق كـ "مهمة Cloud Run"، علينا وضعها في حاوية. الحاويات هي عملية تجميع الرمز البرمجي للتطبيق والعناصر التابعة له ووقت التشغيل في صورة قابلة للنقل.
تأكَّد من استبدال العناصر النائبة (النص بالخط الغامق) بقيمك في Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
يحدّد مقتطف Dockerfile أعلاه الصورة الأساسية، ويثبّت التبعيات، وينسخ الرمز، ويضبط الأمر لتشغيل تطبيقنا باستخدام functions-framework مع الدالة المستهدَفة الصحيحة (process_batch_from_bq). بعد ذلك، يتم إرسال هذه الصورة إلى Artifact Registry.
إنشاء حاوية
لإنشاء حاوية له، انتقِل إلى "وحدة Cloud Shell الطرفية" ونفِّذ الأوامر التالية (تذكَّر استبدال العنصر النائب <<YOUR_PROJECT_ID>>):
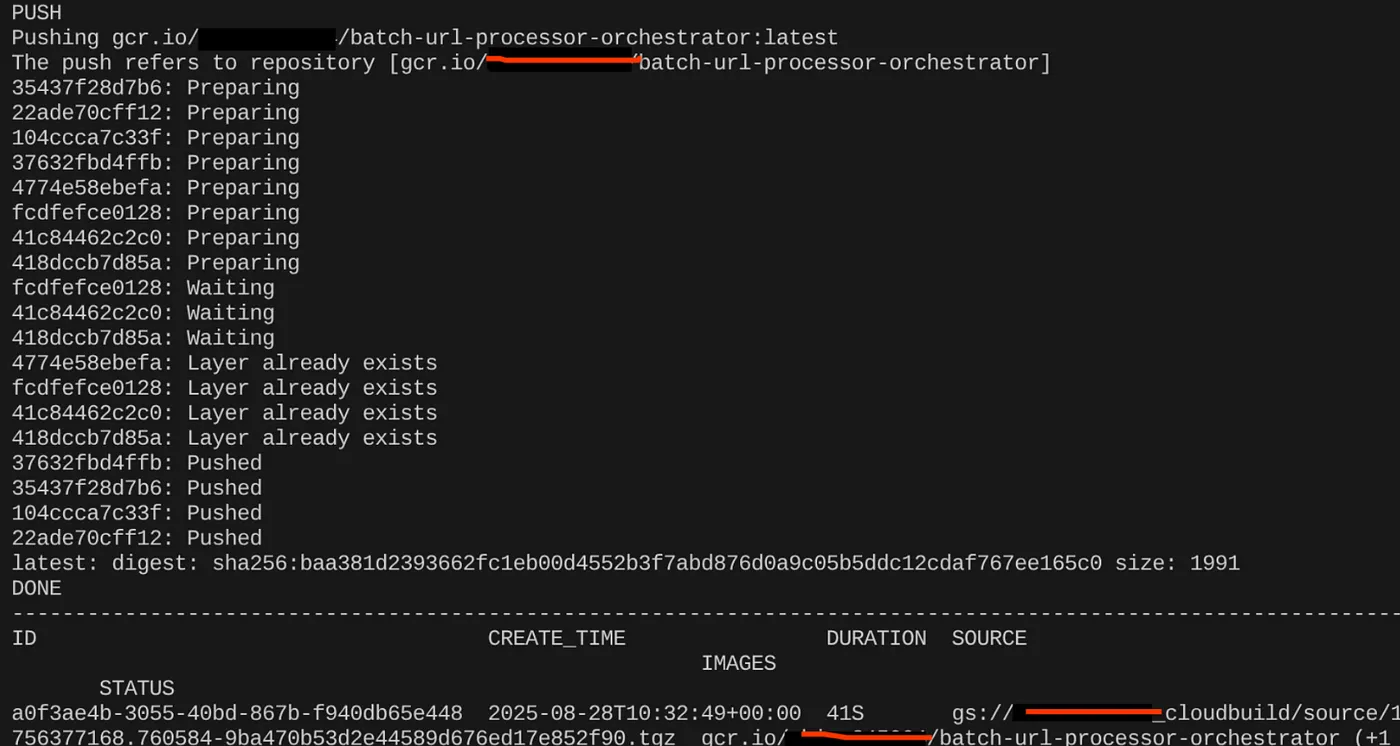
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
بعد إنشاء صورة الحاوية، من المفترض أن يظهر لك الناتج التالي:
تم الآن إنشاء الحاوية وحفظها في Artifact Registry. يمكننا الانتقال إلى الخطوة التالية.
8. إنشاء مهام Cloud Run
يتضمّن نشر المهمة إنشاء صورة الحاوية ثم إنشاء مورد Cloud Run Job.
لقد أنشأنا صورة الحاوية وخزّناها في Artifact Registry. لننشئ الآن مهمة.
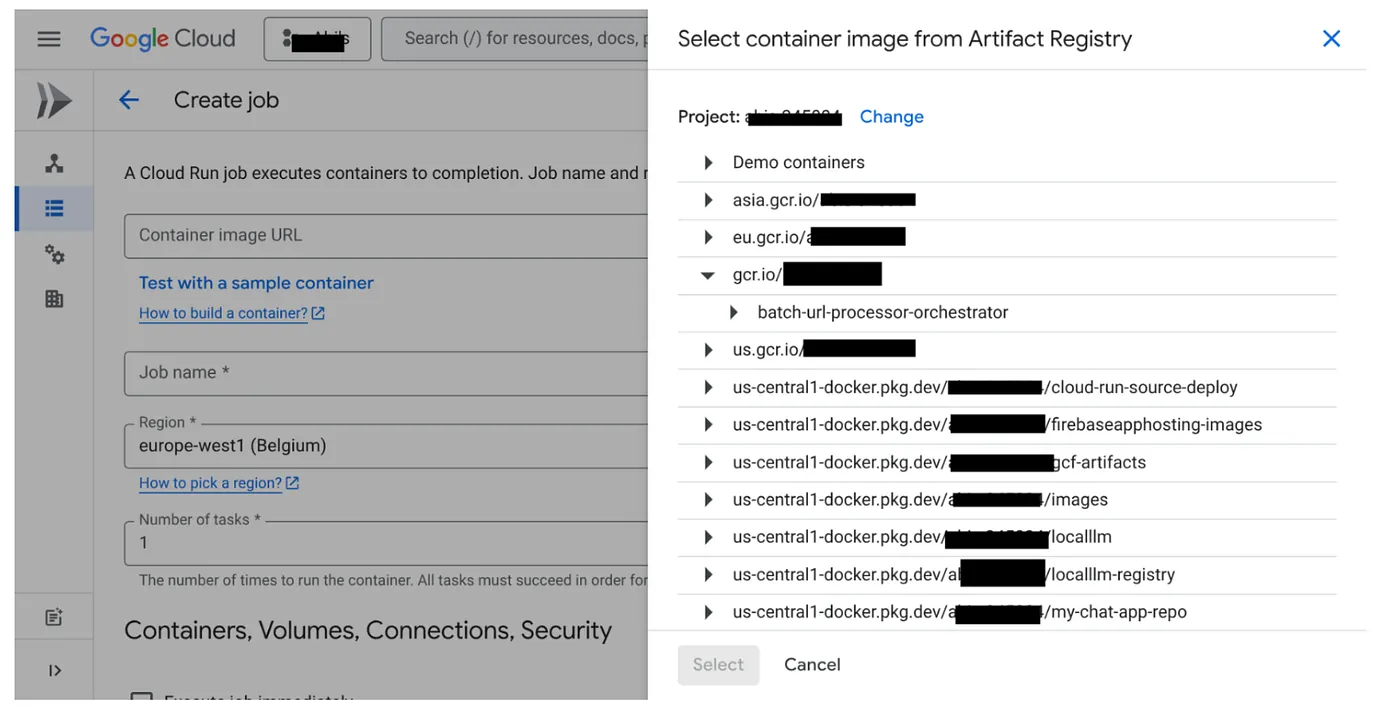
- انتقِل إلى وحدة تحكّم مهام Cloud Run وانقر على "نشر الحاوية":

- اختَر صورة الحاوية التي أنشأناها للتو:
- أدخِل تفاصيل الإعدادات الأخرى على النحو التالي:

- اضبط "سعة المهمة" على النحو التالي:
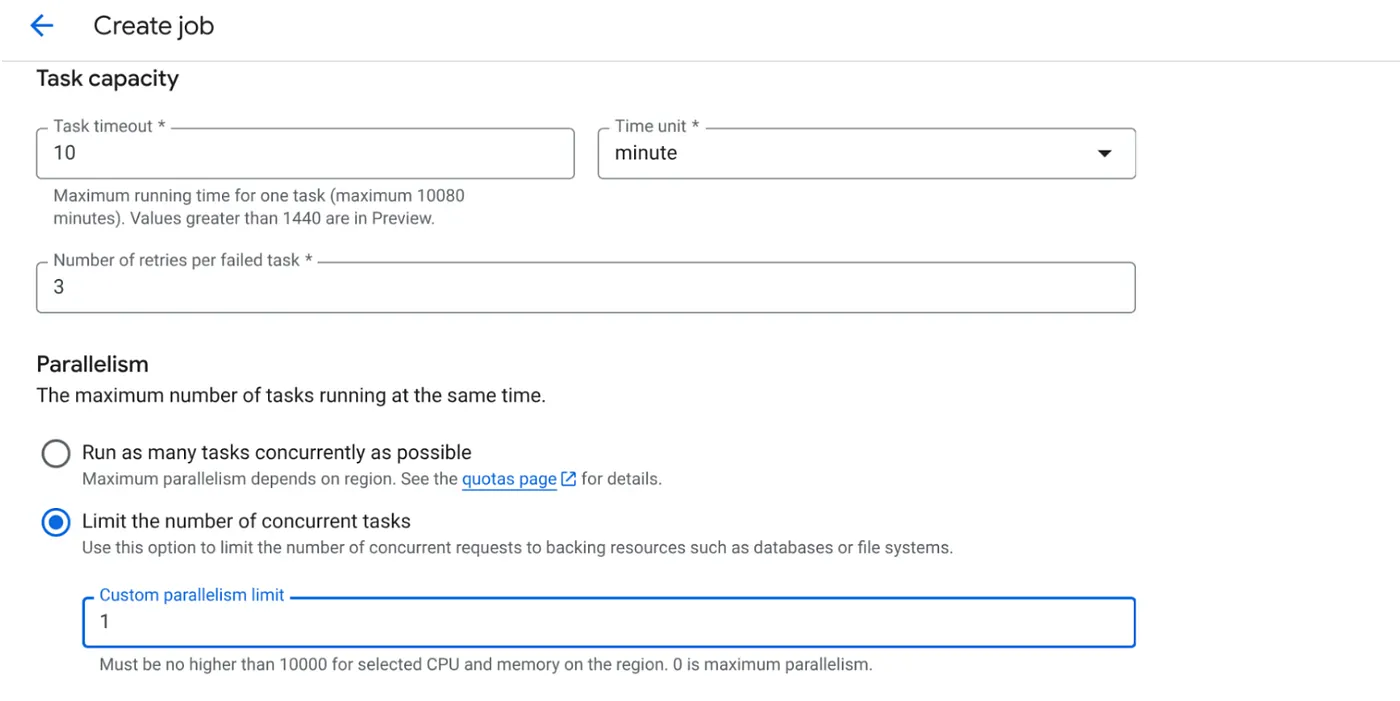
بما أنّ لدينا عمليات كتابة في قاعدة البيانات، وبما أنّ التوازي (max_instances وتزامن المهام) يتم التعامل معه في الرمز، سنضبط عدد المهام المتزامنة على 1. ولكن يمكنك زيادتها حسب متطلباتك. والهدف هنا هو أن يتم تنفيذ المهام حتى اكتمالها وفقًا للإعدادات مع ضبط مستوى التزامن في التوازي.
- انقر على "إنشاء".
سيتم إنشاء مهمة Cloud Run بنجاح.
آلية العمل
يبدأ مثيل حاوية لمهمتنا. يطلب هذا البرنامج بيانات من BigQuery للحصول على مجموعة صغيرة (BATCH_SIZE) من عناوين URL التي تم وضع علامة PENDING عليها. ويعدّل على الفور حالة عناوين URL التي تم جلبها إلى PROCESSING في BigQuery لمنع مثيلات الوظائف الأخرى من اختيارها. تنشئ هذه الطريقة ThreadPoolExecutor وترسل مهمة لكل عنوان URL في الدفعة. تستدعي كل مهمة الدالة call_url_processor_service. عند اكتمال طلبات call_url_processor_service (أو انتهاء المهلة أو حدوث خطأ)، يتم جمع النتائج (إما السياق من إنشاء الذكاء الاصطناعي أو رسالة خطأ) وإعادة ربطها بـ row_id الأصلي. بعد الانتهاء من جميع مهام الدُفعة، تتكرّر الوظيفة من خلال النتائج التي تم جمعها وتعدّل حقلَي السياق والحالة لكل صف مطابق في BigQuery. في حال نجاح العملية، سيتم إنهاء مثيل المهمة بشكل سليم. إذا واجهت أخطاء لم تتم معالجتها، فإنّها ستُصدر استثناءً، ما قد يؤدي إلى إعادة المحاولة من خلال "مهام Cloud Run" (حسب إعدادات المهمة).
كيف تتناسب مهام Cloud Run مع التنسيق؟
وهنا تتألق مهام Cloud Run حقًا.
المعالجة المجمّعة بدون خادم: نحصل على بنية أساسية مُدارة يمكنها تشغيل أكبر عدد ممكن من مثيلات الحاويات حسب الحاجة (حتى MAX_INSTANCES) لمعالجة بياناتنا في الوقت نفسه.
التحكّم في التوازي: نحدّد MAX_INSTANCES (عدد المهام التي يمكن تشغيلها بالتوازي بشكل عام) وTASK_CONCURRENCY (عدد العمليات التي تنفّذها كل مهمة بالتوازي). ويوفّر ذلك تحكّمًا دقيقًا في معدل النقل واستخدام الموارد.
التسامح مع الأخطاء: إذا تعذّر تنفيذ مثيل مهمة في منتصف العملية، يمكن ضبط Cloud Run Jobs لإعادة محاولة تنفيذ المهمة بأكملها أو مهام معيّنة، ما يضمن عدم فقدان معالجة البيانات.
بنية مبسطة: من خلال تنسيق طلبات HTTP مباشرةً داخل المهمة واستخدام BigQuery لإدارة الحالة، نتجنب تعقيد عملية إعداد Pub/Sub وإدارتها، بما في ذلك المواضيع والاشتراكات ومنطق الإقرار.
MAX_INSTANCES مقابل TASK_CONCURRENCY:
MAX_INSTANCES: هو إجمالي عدد مثيلات المهام التي يمكن تشغيلها بشكل متزامن في جميع عمليات تنفيذ المهام. هذا هو عامل التوازي الرئيسي لمعالجة العديد من عناوين URL في الوقت نفسه.
TASK_CONCURRENCY: عدد العمليات المتوازية (طلبات إلى خدمة المعالجة) التي سينفّذها مثيل واحد من مهمتك. يساعد ذلك في إشباع وحدة المعالجة المركزية/الشبكة في إحدى الآلات الافتراضية.
9- تنفيذ مهمة Cloud Run ومراقبتها
البيانات الوصفية للفيديو
قبل النقر على "تنفيذ"، لنطّلع على حالة البيانات.
انتقِل إلى BigQuery Studio ونفِّذ طلب البحث التالي:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
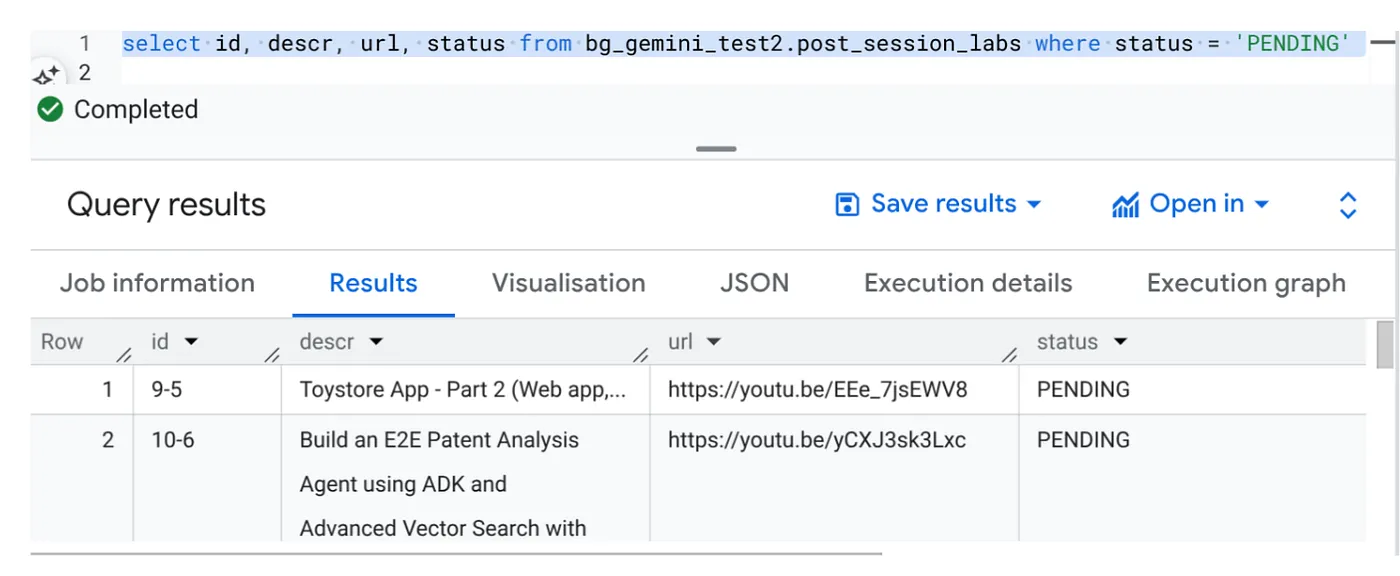
لدينا بعض نماذج السجلات التي تتضمّن عناوين URL لفيديوهات وحالتها PENDING. هدفنا هو ملء حقل "السياق" بمعلومات مفيدة من الفيديو بالتنسيق الموضّح في الطلب.
مشغّل الوظيفة
لننفّذ المهمة الآن من خلال النقر على الزر EXECUTE (تنفيذ) في المهمة في وحدة تحكّم Cloud Run Jobs، وسيصبح بإمكانك الاطّلاع على مستوى تقدّم المهام وحالتها في وحدة التحكّم:
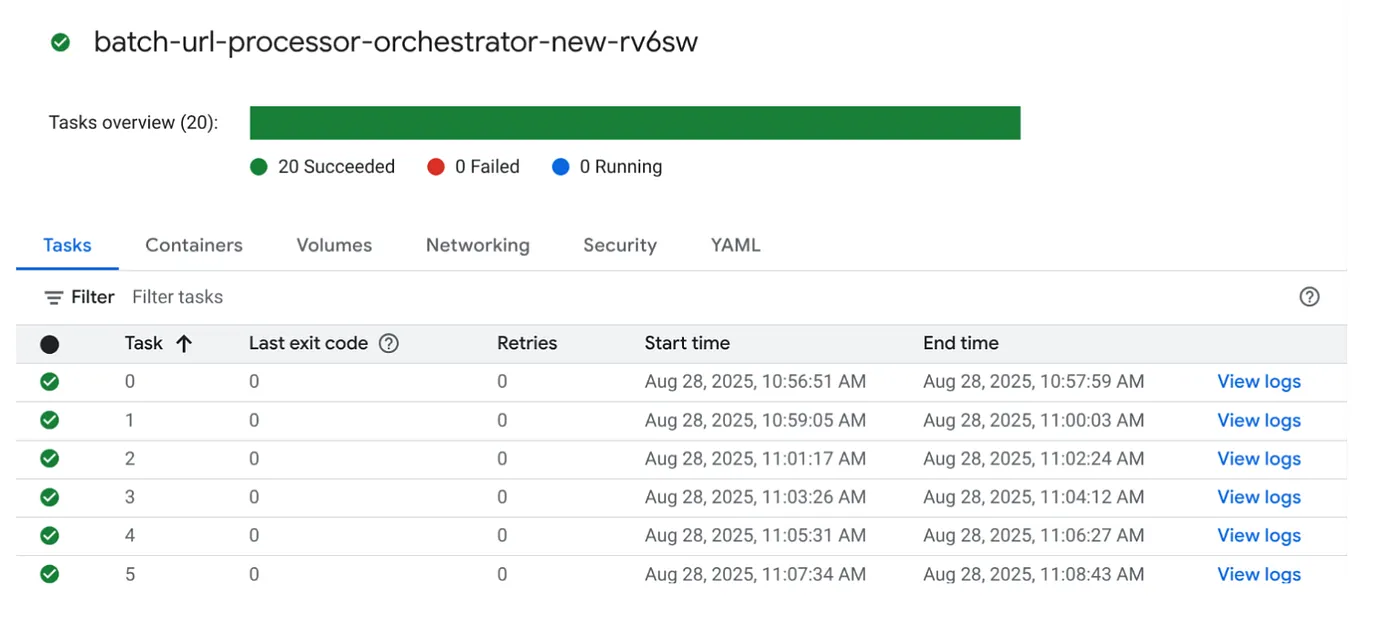
يمكنك الاطّلاع على علامة LOGS في إمكانية تتبّع البيانات لمراقبة الخطوات والتفاصيل الأخرى حول المهمة والمهام.
10. تحليل النتائج
بعد اكتمال المهمة، من المفترض أن تتمكّن من الاطّلاع على سياق كل عنوان URL للفيديو تم تعديله في الجدول:
سياق الإخراج (لأحد السجلات)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
يجب أن تتمكّن الآن من التحقّق من صحة بنية JSON هذه لحالات استخدام أكثر تقدّمًا.
لماذا هذا النهج؟
توفّر هذه البنية مزايا استراتيجية كبيرة:
- فعالية التكلفة: تعني الخدمات بلا خادم أنّك تدفع فقط مقابل ما تستخدمه. يتم تقليل حجم مهام Cloud Run إلى صفر عندما لا تكون قيد الاستخدام.
- قابلية التوسّع: يمكن التعامل بسهولة مع عشرات الآلاف من عناوين URL من خلال تعديل إعدادات مثيل Cloud Run Job والتزامن.
- المرونة: دورات تطوير وتفعيل سريعة لمنطق معالجة جديد أو نماذج ذكاء اصطناعي من خلال تعديل التطبيق المضمّن وخدمته ببساطة
- تقليل النفقات التشغيلية: لا حاجة إلى تصحيح الخوادم أو إدارتها، إذ تتولّى Google إدارة البنية الأساسية.
- إتاحة الذكاء الاصطناعي للجميع: تتيح المعالجة بالذكاء الاصطناعي المتقدّمة للمهام المجمّعة بدون الحاجة إلى خبرة كبيرة في عمليات تعلُّم الآلة.
11. تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة Resource Manager.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
12. تهانينا
تهانينا! من خلال تصميم حلّنا استنادًا إلى Cloud Run Jobs والاستفادة من إمكانات BigQuery في إدارة البيانات وخدمة Cloud Run خارجية لمعالجة الذكاء الاصطناعي، تمكّنت من إنشاء نظام قابل للتوسّع بدرجة كبيرة وفعّال من حيث التكلفة وسهل الصيانة. يفصل هذا النمط منطق المعالجة، ويسمح بالتنفيذ المتوازي بدون بنية أساسية معقّدة، ويسرّع بشكل كبير الوقت اللازم للحصول على الإحصاءات.
ننصحك باستكشاف "مهام Cloud Run" لتلبية احتياجاتك الخاصة بمعالجة البيانات المجمّعة. سواء كان الأمر يتعلق بتوسيع نطاق تحليل الذكاء الاصطناعي أو تشغيل مسارات استخراج البيانات وتحويلها وتحميلها (ETL) أو تنفيذ مهام البيانات الدورية، يقدّم هذا النهج الذي لا يتطلّب خادمًا حلاً قويًا وفعّالاً. للبدء بنفسك، اطّلِع على هذا.
إذا كنت مهتمًا بإنشاء جميع تطبيقاتك ونشرها بدون خادم وبطريقة آلية، يمكنك التسجيل في Code Vipassana الذي يركّز على تسريع التطبيقات الآلية المستندة إلى البيانات.