
১. সংক্ষিপ্ত বিবরণ
আজকের ডেটা-সমৃদ্ধ বিশ্বে, অসংগঠিত কন্টেন্ট, বিশেষ করে ভিডিও থেকে অর্থপূর্ণ তথ্য বের করা একটি অত্যন্ত জরুরি বিষয়। কল্পনা করুন, আপনাকে শত শত বা হাজার হাজার ভিডিও ইউআরএল বিশ্লেষণ করতে হচ্ছে, সেগুলোর বিষয়বস্তু সংক্ষিপ্ত করতে হচ্ছে, মূল প্রযুক্তিগুলো বের করতে হচ্ছে, এবং এমনকি শিক্ষামূলক উপকরণের জন্য প্রশ্নোত্তরের জোড়া তৈরি করতে হচ্ছে। এই কাজগুলো এক এক করে করা কেবল সময়সাপেক্ষই নয়, বরং অদক্ষও বটে। এখানেই আধুনিক ক্লাউড আর্কিটেকচারগুলো তাদের শ্রেষ্ঠত্ব প্রমাণ করে।
এই ল্যাবে, আমরা গুগল ক্লাউডের শক্তিশালী পরিষেবাগুচ্ছ—ক্লাউড রান, বিগকোয়েরি এবং গুগলের জেনারেটিভ এআই (জেমিনি)—ব্যবহার করে ভিডিও কন্টেন্ট প্রসেস করার একটি স্কেলেবল ও সার্ভারবিহীন সমাধান নিয়ে আলোচনা করব। আমরা একটিমাত্র ইউআরএল প্রসেস করা থেকে শুরু করে একটি বৃহৎ ডেটাসেট জুড়ে সমান্তরাল এক্সিকিউশন পরিচালনা পর্যন্ত আমাদের পুরো যাত্রাপথটি বিস্তারিতভাবে তুলে ধরব, এবং এই পুরো প্রক্রিয়াটি জটিল মেসেজিং কিউ ও ইন্টিগ্রেশন ব্যবস্থাপনার বাড়তি ঝামেলা ছাড়াই সম্পন্ন করা হয়েছে।
চ্যালেঞ্জ
আমাদেরকে হাতে-কলমে ল্যাব সেশনগুলোর উপর বিশেষভাবে আলোকপাত করে বিপুল পরিমাণ ভিডিও কন্টেন্ট প্রক্রিয়াকরণের দায়িত্ব দেওয়া হয়েছিল। এর লক্ষ্য ছিল প্রতিটি ভিডিও বিশ্লেষণ করে একটি সুসংগঠিত সারাংশ তৈরি করা, যার মধ্যে থাকবে অধ্যায়ের শিরোনাম, ভূমিকার প্রেক্ষাপট, ধাপে ধাপে নির্দেশাবলী, ব্যবহৃত প্রযুক্তি এবং প্রাসঙ্গিক প্রশ্নোত্তর। শিক্ষামূলক উপকরণ তৈরির কাজে পরবর্তীতে ব্যবহারের জন্য এই আউটপুটটি দক্ষতার সাথে সংরক্ষণ করা প্রয়োজন ছিল।
শুরুতে, আমাদের একটি সাধারণ HTTP-ভিত্তিক ক্লাউড রান সার্ভিস ছিল যা একবারে একটি ইউআরএল প্রসেস করতে পারত। টেস্টিং এবং তাৎক্ষণিক বিশ্লেষণের জন্য এটি বেশ ভালো কাজ করত। কিন্তু, BigQuery থেকে পাওয়া হাজার হাজার ইউআরএলের একটি তালিকার সম্মুখীন হয়ে এই একক-অনুরোধ, একক-প্রতিক্রিয়া মডেলের সীমাবদ্ধতাগুলো স্পষ্ট হয়ে ওঠে। পর্যায়ক্রমিক প্রসেসিংয়ে দিন, এমনকি সপ্তাহও লেগে যেত।
একটি ম্যানুয়াল বা ধীরগতির ধারাবাহিক প্রক্রিয়াকে একটি স্বয়ংক্রিয়, সমান্তরাল কর্মপ্রবাহে রূপান্তরিত করার সুযোগ ছিল। ক্লাউডকে কাজে লাগিয়ে আমাদের লক্ষ্য ছিল:
- সমান্তরালভাবে ডেটা প্রক্রিয়াকরণ: বৃহৎ ডেটাসেটের জন্য প্রক্রিয়াকরণের সময় উল্লেখযোগ্যভাবে হ্রাস করুন।
- বিদ্যমান এআই সক্ষমতার সদ্ব্যবহার করুন: অত্যাধুনিক বিষয়বস্তু বিশ্লেষণের জন্য জেমিনির শক্তি ব্যবহার করুন।
- সার্ভারবিহীন আর্কিটেকচার বজায় রাখুন: সার্ভার বা জটিল পরিকাঠামো পরিচালনা করা এড়িয়ে চলুন।
- ডেটা কেন্দ্রীভূত করুন: ইনপুট URL-এর জন্য তথ্যের একমাত্র উৎস এবং প্রক্রিয়াকৃত ফলাফলের জন্য একটি নির্ভরযোগ্য গন্তব্য হিসেবে BigQuery ব্যবহার করুন।
- একটি শক্তিশালী পাইপলাইন তৈরি করুন: এমন একটি সিস্টেম গড়ে তুলুন যা ব্যর্থতা মোকাবিলায় সক্ষম এবং যা সহজে পরিচালনা ও পর্যবেক্ষণ করা যায়।
উদ্দেশ্য
ক্লাউড রান জবস-এর মাধ্যমে সমান্তরাল এআই প্রসেসিং সমন্বয় করা:
আমাদের সমাধানটি একটি ক্লাউড রান জবকে কেন্দ্র করে গড়ে উঠেছে, যা অর্কেস্ট্রেটর হিসেবে কাজ করে। এটি বুদ্ধিমত্তার সাথে BigQuery থেকে URL-এর ব্যাচ পড়ে, এই URL-গুলোকে আমাদের আগে থেকে ডেপ্লয় করা ক্লাউড রান সার্ভিসে পাঠায় (যা একটিমাত্র URL-এর জন্য AI প্রসেসিং পরিচালনা করে), এবং তারপর ফলাফলগুলোকে একত্রিত করে আবার BigQuery-তে লিখে দেয়। এই পদ্ধতিটি আমাদেরকে নিম্নলিখিত কাজগুলো করতে সক্ষম করে:
- প্রসেসিং থেকে অর্কেস্ট্রেশনকে পৃথক করুন: জবটি ওয়ার্কফ্লো পরিচালনা করে, আর পৃথক সার্ভিসটি এআই টাস্কের ওপর মনোযোগ দেয়।
- ক্লাউড রান জব-এর প্যারালালিজম বা সমান্তরাল কার্যক্রমের সুবিধা নিন: জবটি একই সাথে এআই সার্ভিসকে কল করার জন্য একাধিক কন্টেইনার ইনস্ট্যান্সকে স্কেল আউট করতে পারে।
- জটিলতা হ্রাস করুন: আমরা জবটিকে সরাসরি যুগপৎ HTTP কলগুলো পরিচালনা করার সুযোগ দিয়ে প্যারালালিজম অর্জন করি, যা আর্কিটেকচারকে সরল করে তোলে।
ব্যবহারের ক্ষেত্র
কোড বিপাসনা সেশন ভিডিও থেকে প্রাপ্ত এআই-চালিত অন্তর্দৃষ্টি
আমাদের নির্দিষ্ট কাজের ক্ষেত্রটি ছিল কোড বিপাসনা হ্যান্ডস-অন ল্যাবের গুগল ক্লাউড সেশনের ভিডিও বিশ্লেষণ করা। এর লক্ষ্য ছিল স্বয়ংক্রিয়ভাবে কাঠামোগত ডকুমেন্টেশন (বইয়ের অধ্যায়ের রূপরেখা) তৈরি করা, যার মধ্যে অন্তর্ভুক্ত ছিল:
- অধ্যায়ের শিরোনাম: প্রতিটি ভিডিও অংশের জন্য সংক্ষিপ্ত শিরোনাম
- ভূমিকার প্রেক্ষাপট: একটি বৃহত্তর শিক্ষাপথে ভিডিওটির প্রাসঙ্গিকতা ব্যাখ্যা করা।
- কী নির্মাণ করা হবে: অধিবেশনের মূল কাজ বা লক্ষ্য
- ব্যবহৃত প্রযুক্তি: ক্লাউড পরিষেবা এবং উল্লিখিত অন্যান্য প্রযুক্তির একটি তালিকা
- ধাপে ধাপে নির্দেশাবলী: কাজটি কীভাবে করা হয়েছিল, কোড স্নিপেট সহ
- সোর্স কোড/ডেমো ইউআরএল: ভিডিওতে লিঙ্ক দেওয়া আছে।
- প্রশ্নোত্তর পর্ব: জ্ঞান যাচাইয়ের জন্য প্রাসঙ্গিক প্রশ্ন ও উত্তর তৈরি করা।
প্রবাহ

স্থাপত্যের প্রবাহ
ক্লাউড রান কী? ক্লাউড রান জবস কী?
ক্লাউড রান
একটি সম্পূর্ণ পরিচালিত সার্ভারলেস প্ল্যাটফর্ম যা আপনাকে স্টেটলেস কন্টেইনার চালাতে দেয়। এটি ওয়েব সার্ভিস, এপিআই এবং মাইক্রোসার্ভিসের জন্য আদর্শ, যা আগত অনুরোধের উপর ভিত্তি করে স্বয়ংক্রিয়ভাবে স্কেল করতে পারে। আপনি একটি কন্টেইনার ইমেজ সরবরাহ করেন এবং ক্লাউড রান বাকিটা সামলে নেয় — ডেপ্লয়িং ও স্কেলিং থেকে শুরু করে ইনফ্রাস্ট্রাকচার পরিচালনা পর্যন্ত। এটি সিনক্রোনাস, রিকোয়েস্ট-রেসপন্স ওয়ার্কলোড পরিচালনায় বিশেষভাবে পারদর্শী।
ক্লাউড রান জবস
এটি ক্লাউড রান পরিষেবাগুলোর একটি পরিপূরক পরিষেবা। ক্লাউড রান জবস এমন সব ব্যাচ প্রসেসিং টাস্কের জন্য ডিজাইন করা হয়েছে, যেগুলো সম্পন্ন হওয়ার পর থেমে যাওয়ার প্রয়োজন হয়। ডেটা প্রসেসিং, ETL, মেশিন লার্নিং ব্যাচ ইনফারেন্স এবং লাইভ রিকোয়েস্ট সার্ভ করার পরিবর্তে ডেটাসেট প্রসেস করার মতো যেকোনো কাজের জন্য এগুলো আদর্শ। এর একটি প্রধান বৈশিষ্ট্য হলো, একবারে অনেকগুলো কাজ প্রসেস করার জন্য একই সাথে চলমান কন্টেইনার ইনস্ট্যান্সের (টাস্ক) সংখ্যা বাড়িয়ে তোলার ক্ষমতা, এবং এগুলো বিভিন্ন ইভেন্ট সোর্স থেকে বা ম্যানুয়ালি ট্রিগার করা যায়।
মূল পার্থক্য
ক্লাউড রান সার্ভিসেস দীর্ঘস্থায়ী, অনুরোধ-চালিত অ্যাপ্লিকেশনগুলির জন্য ব্যবহৃত হয়। ক্লাউড রান জবস সীমিত, কার্য-ভিত্তিক ব্যাচ প্রক্রিয়াকরণের জন্য ব্যবহৃত হয় যা সম্পূর্ণ না হওয়া পর্যন্ত চলে।
আপনি যা তৈরি করবেন
একটি খুচরা অনুসন্ধান অ্যাপ্লিকেশন
এর অংশ হিসেবে, আপনাকে যা করতে হবে তা হলো:
- একটি BigQuery ডেটাসেট, টেবিল তৈরি করুন এবং ডেটা ইনজেস্ট করুন (বিপাসনা মেটাডেটা কোড)
- জেনারেটিভ এআই কার্যকারিতা (ভিডিওকে বইয়ের অধ্যায়ের json-এ রূপান্তর) বাস্তবায়নের জন্য একটি পাইথন ক্লাউড রান ফাংশন তৈরি করুন।
- ডেটা টু এআই পাইপলাইনের জন্য একটি পাইথন অ্যাপ্লিকেশন তৈরি করুন - BigQuery থেকে ডেটা পড়ুন, ইনসাইটসের জন্য Cloud Run Functions Endpoint-কে কল করুন এবং কনটেক্সটটি আবার BigQuery-তে লিখে দিন।
- অ্যাপ্লিকেশনটি তৈরি এবং কন্টেইনারাইজ করুন
- এই কন্টেইনারটি দিয়ে একটি ক্লাউড রান জবস কনফিগার করুন।
- কাজটি সম্পাদন ও পর্যবেক্ষণ করুন
- রিপোর্টের ফলাফল
প্রয়োজনীয়তা
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন: লিঙ্কটি অনুসরণ করুন এবং এপিআইগুলো সক্রিয় করুন।
বিকল্পভাবে আপনি এর জন্য gcloud কমান্ড ব্যবহার করতে পারেন। gcloud কমান্ড এবং এর ব্যবহার সম্পর্কে জানতে ডকুমেন্টেশন দেখুন।
৩. ডাটাবেস/ওয়্যারহাউস সেটআপ
BigQuery আমাদের ডেটা পাইপলাইনের মেরুদণ্ড হিসেবে কাজ করেছে। এর সার্ভারবিহীন ও অত্যন্ত স্কেলেবল বৈশিষ্ট্য এটিকে আমাদের ইনপুট ডেটা সংরক্ষণ এবং প্রক্রিয়াজাত ফলাফল রাখার জন্য নিখুঁত করে তুলেছে।
- ডেটা স্টোরেজ: BigQuery আমাদের ডেটা ওয়্যারহাউস হিসেবে কাজ করেছে। এটি ভিডিও ইউআরএল-এর তালিকা, সেগুলোর স্ট্যাটাস (যেমন, পেন্ডিং, প্রসেসিং, কমপ্লিটেড) এবং চূড়ান্তভাবে তৈরি হওয়া কনটেক্সট সংরক্ষণ করে। কোন ভিডিওগুলো প্রসেস করা প্রয়োজন, তার জন্য এটিই তথ্যের একমাত্র নির্ভরযোগ্য উৎস।
- গন্তব্য: এখানেই এআই-দ্বারা তৈরি অন্তর্দৃষ্টিগুলো সংরক্ষণ করা হয়, যার ফলে পরবর্তী অ্যাপ্লিকেশন বা ম্যানুয়াল পর্যালোচনার জন্য সেগুলোকে সহজেই অনুসন্ধান করা যায়। আমাদের ডেটাসেটটি ভিডিও সেশনের বিবরণ নিয়ে গঠিত ছিল, বিশেষ করে 'কোড বিপাসনা সিজনস' কন্টেন্ট থেকে, যেখানে প্রায়শই বিশদ প্রযুক্তিগত প্রদর্শনী অন্তর্ভুক্ত থাকে।
- উৎস টেবিল: একটি BigQuery টেবিল (যেমন, post_session_labs) যাতে নিম্নলিখিত ধরনের রেকর্ড থাকে:
- id: প্রতিটি সেশন/সারি-র জন্য একটি অনন্য শনাক্তকারী।
- url: ভিডিওটির ইউআরএল (যেমন, একটি ইউটিউব লিঙ্ক বা একটি অ্যাক্সেসযোগ্য ড্রাইভ লিঙ্ক)।
- অবস্থা: প্রক্রিয়াকরণের অবস্থা নির্দেশকারী একটি স্ট্রিং (যেমন, অপেক্ষাধীন, প্রক্রিয়াকরণ চলছে, সম্পন্ন, প্রক্রিয়াকরণ ব্যর্থ)।
- context: এআই-দ্বারা তৈরি সারাংশ সংরক্ষণের জন্য একটি স্ট্রিং ফিল্ড।
- ডেটা ইনজেশন: এই ক্ষেত্রে, INSERT স্ক্রিপ্ট ব্যবহার করে BigQuery-তে ডেটা ইনজেস্ট করা হয়েছিল। আমাদের পাইপলাইনের জন্য BigQuery ছিল সূচনা বিন্দু।
BigQuery কনসোলে যান, একটি নতুন ট্যাব খুলুন এবং নিম্নলিখিত SQL স্টেটমেন্টগুলো চালান:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
৪. ডেটা গ্রহণ
এখন স্টোর সম্পর্কিত ডেটা সহ একটি টেবিল যুক্ত করার সময় এসেছে। BigQuery Studio-এর একটি ট্যাবে যান এবং নমুনা রেকর্ডগুলি সন্নিবেশ করতে নিম্নলিখিত SQL স্টেটমেন্টগুলি চালান:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
৫. ভিডিও ইনসাইটস ফাংশন তৈরি
ভিডিও ইউআরএল থেকে একটি কাঠামোবদ্ধ বইয়ের অধ্যায় তৈরির মূল কার্যকারিতাটি বাস্তবায়নের জন্য আমাদের একটি ক্লাউড রান ফাংশন তৈরি ও ডেপ্লয় করতে হবে। এটিকে একটি স্বাধীন এন্ডপয়েন্ট টুলবক্স টুলস হিসেবে অ্যাক্সেস করার জন্য আমরা এইমাত্র একটি ক্লাউড রান ফাংশন তৈরি ও ডেপ্লয় করেছি। বিকল্পভাবে, আপনি ক্লাউড রান জবের জন্য প্রকৃত পাইথন অ্যাপ্লিকেশনে এটিকে একটি পৃথক ফাংশন হিসেবে অন্তর্ভুক্ত করতে পারেন:
- Google Cloud কনসোলে, Cloud Run পৃষ্ঠায় যান
- একটি ফাংশন লিখুন-এ ক্লিক করুন।
- 'সার্ভিস নেম' ফিল্ডে, আপনার কাজের ধরন বর্ণনা করার জন্য একটি নাম লিখুন। সার্ভিসের নাম অবশ্যই একটি অক্ষর দিয়ে শুরু হতে হবে এবং এতে অক্ষর, সংখ্যা বা হাইফেন সহ সর্বোচ্চ ৪৯টি অক্ষর বা তার কম থাকতে হবে। সার্ভিসের নাম হাইফেন দিয়ে শেষ হতে পারবে না এবং প্রতিটি অঞ্চল ও প্রকল্পের জন্য এটি অবশ্যই স্বতন্ত্র হতে হবে। সার্ভিসের নাম পরবর্তীতে পরিবর্তন করা যাবে না এবং এটি সর্বজনীনভাবে দৃশ্যমান থাকবে। ( generate-video-insights **)**
- অঞ্চল তালিকায়, ডিফল্ট মান ব্যবহার করুন, অথবা যে অঞ্চলে আপনি আপনার ফাংশনটি স্থাপন করতে চান তা নির্বাচন করুন। (us-central1 বেছে নিন)
- রানটাইম তালিকায় ডিফল্ট মান ব্যবহার করুন, অথবা একটি রানটাইম সংস্করণ নির্বাচন করুন। (পাইথন ৩.১১ বেছে নিন)
- প্রমাণীকরণ বিভাগে, "সর্বজনীন প্রবেশাধিকার অনুমতি দিন" নির্বাচন করুন।
- "তৈরি করুন" বোতামে ক্লিক করুন
- ফাংশনটি main.py এবং requirements.txt টেমপ্লেট দিয়ে তৈরি ও লোড করা হয়।
- ওটাকে এই প্রোজেক্টের রিপো থেকে main.py এবং requirements.txt ফাইল দুটি দিয়ে প্রতিস্থাপন করুন।
গুরুত্বপূর্ণ দ্রষ্টব্য: main.py ফাইলে, <<YOUR_PROJECT_ID>> এর জায়গায় আপনার প্রজেক্ট আইডি বসাতে ভুলবেন না।
- এন্ডপয়েন্টটি ডেপ্লয় ও সেভ করুন, যাতে আপনি ক্লাউড রান জবের সোর্সে এটি ব্যবহার করতে পারেন।
আপনার এন্ডপয়েন্টটি দেখতে এইরকম (বা এর কাছাকাছি) হওয়া উচিত: https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
এই ক্লাউড রান ফাংশনটিতে কী আছে?
ভিডিও প্রসেসিংয়ের জন্য জেমিনি ২.৫ ফ্ল্যাশ
ভিডিও কন্টেন্ট বোঝা এবং সারসংক্ষেপ করার মূল কাজের জন্য, আমরা গুগলের জেমিনি ২.৫ ফ্ল্যাশ মডেল ব্যবহার করেছি। জেমিনি মডেলগুলো হলো শক্তিশালী, মাল্টিমোডাল এআই মডেল, যা টেক্সট এবং নির্দিষ্ট ইন্টিগ্রেশনের মাধ্যমে ভিডিওসহ বিভিন্ন ধরনের ইনপুট বুঝতে ও প্রসেস করতে সক্ষম।
আমাদের সেটআপে, আমরা সরাসরি ভিডিও ফাইলটি জেমিনিতে ফিড করিনি। পরিবর্তে, আমরা একটি টেক্সচুয়াল প্রম্পট পাঠিয়েছিলাম, যাতে ভিডিওটির ইউআরএল অন্তর্ভুক্ত ছিল এবং সেই ইউআরএল-এ থাকা একটি ভিডিওর (কাল্পনিক) বিষয়বস্তু কীভাবে বিশ্লেষণ করতে হবে, সে বিষয়ে জেমিনিকে নির্দেশ দেওয়া হয়েছিল। যদিও জেমিনি ২.৫ ফ্ল্যাশ মাল্টিমোডাল ইনপুট গ্রহণে সক্ষম, এই নির্দিষ্ট পাইপলাইনটিতে একটি টেক্সট-ভিত্তিক প্রম্পট ব্যবহার করা হয়েছিল, যা ভিডিওটির প্রকৃতি (একটি হ্যান্ডস-অন ল্যাব সেশন) বর্ণনা করে এবং একটি স্ট্রাকচার্ড JSON আউটপুটের অনুরোধ জানায়। এটি প্রম্পটের প্রেক্ষাপটের উপর ভিত্তি করে তথ্য অনুমান ও সংশ্লেষণ করার জন্য জেমিনির উন্নত রিজনিং এবং ন্যাচারাল ল্যাঙ্গুয়েজ আন্ডারস্ট্যান্ডিং-কে কাজে লাগায়।
জেমিনি প্রম্পট: এআই-কে পথ দেখানো
এআই মডেলের জন্য একটি সুচিন্তিত প্রম্পট অত্যন্ত গুরুত্বপূর্ণ। আমাদের প্রম্পটটি খুব নির্দিষ্ট তথ্য আহরণ করে সেটিকে JSON ফরম্যাটে সাজানোর জন্য ডিজাইন করা হয়েছিল, যার ফলে আমাদের অ্যাপ্লিকেশনটি সহজেই তা পার্স করতে পারে।
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
এই নির্দেশটি অত্যন্ত সুনির্দিষ্ট, যা জেমিনিকে এক প্রকার শিক্ষকের ভূমিকা পালনে পরিচালিত করে। JSON স্ট্রিং-এর অনুরোধটি একটি সুগঠিত ও যন্ত্রপাঠযোগ্য আউটপুট নিশ্চিত করে।
ভিডিও ইনপুট বিশ্লেষণ করে তার কনটেক্সট ফেরত দেওয়ার কোডটি নিচে দেওয়া হলো:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
উপরের এই কোড স্নিপেটটি ইউজ কেসটির মূল কার্যকারিতা প্রদর্শন করে। এটি একটি ভিডিও ইউআরএল গ্রহণ করে এবং ভার্টেক্স এআই ক্লায়েন্টের মাধ্যমে জেমিনি মডেল ব্যবহার করে নির্দেশ অনুযায়ী ভিডিওর বিষয়বস্তু বিশ্লেষণ করে ও প্রাসঙ্গিক তথ্য বের করে আনে। এরপর বের করা তথ্যগুলো পরবর্তী প্রক্রিয়াকরণের জন্য ফেরত পাঠানো হয়। এটি একটি সিনক্রোনাস অপারেশন, যেখানে ক্লাউড রান জবটি সার্ভিসটি সম্পূর্ণ হওয়ার জন্য অপেক্ষা করে।
৬. পাইপলাইন অ্যাপ্লিকেশন উন্নয়ন (পাইথন)
আমাদের কেন্দ্রীয় পাইপলাইন লজিক অ্যাপ্লিকেশনটির সোর্স কোডে থাকে, যা একটি ক্লাউড রান জব-এ কন্টেইনারাইজ করা হবে এবং এটি সম্পূর্ণ প্যারালাল এক্সিকিউশন পরিচালনা করে। এর মূল অংশগুলো নিচে দেওয়া হলো:
ওয়ার্কফ্লো পরিচালনা এবং ডেটার অখণ্ডতা নিশ্চিতকরণে অর্কেস্ট্রেটরের ভূমিকা:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
উপরের এই কোড স্নিপেটটি BigQuery সোর্স টেবিল থেকে 'PENDING' স্ট্যাটাসযুক্ত একগুচ্ছ ভিডিও URL ফেচ করার মাধ্যমে শুরু হয়। এরপর এটি BigQuery-তে এই URL-গুলোর স্ট্যাটাস 'PROCESSING'-এ আপডেট করে, যা ডুপ্লিকেট প্রসেসিং প্রতিরোধ করে।
ThreadPoolExecutor ব্যবহার করে সমান্তরাল প্রক্রিয়াকরণ এবং প্রসেসর সার্ভিসকে কল করা:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
কোডের এই অংশটি ফেচ করা ভিডিও ইউআরএলগুলোর প্যারালাল প্রসেসিং সম্পন্ন করতে থ্রেডপুলএক্সিকিউটর (ThreadPoolExecutor) ব্যবহার করে। প্রতিটি ইউআরএলের জন্য, এটি অ্যাসিঙ্ক্রোনাসভাবে ক্লাউড রান সার্ভিস (ইউআরএল প্রসেসর) কল করার জন্য একটি টাস্ক সাবমিট করে। এর ফলে ক্লাউড রান জবটি একই সাথে একাধিক ভিডিও দক্ষতার সাথে প্রসেস করতে পারে, যা সার্বিক পাইপলাইন পারফরম্যান্স উন্নত করে। এই কোড স্নিপেটটি প্রসেসর সার্ভিস থেকে আসা সম্ভাব্য টাইমআউট এবং এররগুলোও সামাল দেয়।
BigQuery থেকে এবং BigQuery-তে পড়া ও লেখা
BigQuery-এর সাথে মূল কাজটি হলো অপেক্ষাধীন URL-গুলো সংগ্রহ করা এবং তারপর প্রক্রিয়াকৃত ফলাফল দিয়ে সেগুলোকে আপডেট করা।
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
BigQuery-তে ফলাফলগুলো পুনরায় লেখা:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
উপরের কোড স্নিপেটগুলো ক্লাউড রান জব এবং বিগকোয়েরি-এর মধ্যে ডেটা আদান-প্রদানের উপর আলোকপাত করে। এটি সোর্স টেবিল থেকে একগুচ্ছ 'পেন্ডিং' ভিডিও ইউআরএল এবং তাদের আইডি সংগ্রহ করে। ইউআরএলগুলো প্রসেস করার পর, এই স্নিপেটটি একটি আপডেট কোয়েরি ব্যবহার করে নিষ্কাশিত কনটেক্সট এবং স্ট্যাটাস ('কমপ্লিটেড' বা 'ফেইলড_প্রসেসিং') টার্গেট বিগকোয়েরি টেবিলে পুনরায় লেখার পদ্ধতি প্রদর্শন করে। এই স্নিপেটটি ডেটা প্রসেসিং চক্রটি সম্পূর্ণ করে। এতে update_bq_row হেল্পার ফাংশনটিও অন্তর্ভুক্ত রয়েছে, যা দেখায় কীভাবে আপডেট স্টেটমেন্টের প্যারামিটারগুলো নির্ধারণ করতে হয়।
অ্যাপ্লিকেশন সেটআপ
অ্যাপ্লিকেশনটি একটি একক পাইথন স্ক্রিপ্ট হিসেবে গঠিত, যা কন্টেইনারাইজড করা হবে। এর এন্ট্রি পয়েন্ট নির্ধারণের জন্য এটি গুগল ক্লাউড ক্লায়েন্ট লাইব্রেরি এবং ফাংশনস-ফ্রেমওয়ার্ক ব্যবহার করে।
- নির্ভরতা: google-cloud-bigquery, requests
- কনফিগারেশন: সমস্ত গুরুত্বপূর্ণ সেটিংস (BigQuery প্রজেক্ট/ডেটাসেট/টেবিল, URL প্রসেসর সার্ভিস URL) এনভায়রনমেন্ট ভেরিয়েবল থেকে লোড করা হয়, যা অ্যাপ্লিকেশনটিকে পোর্টেবল এবং সুরক্ষিত করে তোলে।
- মূল যুক্তি: process_batch_from_bq ফাংশনটি সম্পূর্ণ কর্মপ্রবাহকে পরিচালনা করে।
- বাহ্যিক পরিষেবা ইন্টিগ্রেশন: `call_url_processor_service` ফাংশনটি পৃথক ক্লাউড রান সার্ভিসের সাথে যোগাযোগ পরিচালনা করে।
- BigQuery ইন্টারঅ্যাকশন: যথাযথ প্যারামিটার হ্যান্ডলিং সহ URL ফেচ করতে এবং ফলাফল আপডেট করতে bq_client ব্যবহৃত হয়।
- সমান্তরালতা: concurrent.futures.ThreadPoolExecutor বাহ্যিক পরিষেবাতে যুগপৎ কল পরিচালনা করে।
- এন্ট্রি পয়েন্ট: main.py নামের পাইথন কোডটি এন্ট্রি পয়েন্ট হিসেবে কাজ করে, যা ব্যাচ প্রসেসিং শুরু করে।
চলুন এখন অ্যাপ্লিকেশনটি সেটআপ করা যাক:
- আপনি আপনার ক্লাউড শেল টার্মিনালে গিয়ে রিপোজিটরিটি ক্লোন করার মাধ্যমে শুরু করতে পারেন:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- ক্লাউড শেল এডিটর-এ যান , যেখানে আপনি নতুন তৈরি করা video-context-crj ফোল্ডারটি দেখতে পাবেন।
- নিম্নলিখিতগুলি মুছে ফেলুন, কারণ সেই ধাপগুলি পূর্ববর্তী বিভাগগুলিতে ইতিমধ্যেই সম্পন্ন করা হয়েছে:
- Cloud_Run_Function ফোল্ডারটি মুছে ফেলুন
- video-context-crj প্রজেক্ট ফোল্ডারে প্রবেশ করুন এবং আপনি প্রজেক্টের কাঠামোটি দেখতে পাবেন:
৭. ডকারফাইল সেটআপ এবং কন্টেইনারাইজেশন
এই লজিকটিকে একটি ক্লাউড রান জব হিসেবে ডেপ্লয় করতে হলে, আমাদের এটিকে কন্টেইনারাইজ করতে হবে। কন্টেইনারাইজেশন হলো আমাদের অ্যাপ্লিকেশন কোড, এর ডিপেন্ডেন্সি এবং রানটাইমকে একটি পোর্টেবল ইমেজে প্যাকেজ করার প্রক্রিয়া।
Dockerfile-এ প্লেসহোল্ডারগুলো (গাঢ় অক্ষরে লেখা) আপনার মান দিয়ে প্রতিস্থাপন করতে ভুলবেন না:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
উপরের Dockerfile কোডটি বেস ইমেজ তৈরি করে, ডিপেন্ডেন্সিগুলো ইনস্টল করে, আমাদের কোড কপি করে এবং functions-framework ব্যবহার করে সঠিক টার্গেট ফাংশন (process_batch_from_bq) দিয়ে আমাদের অ্যাপ্লিকেশনটি চালানোর জন্য কমান্ড সেট করে। এরপর এই ইমেজটি আর্টিফ্যাক্ট রেজিস্ট্রি-তে পুশ করা হয়।
কন্টেইনারাইজ
এটিকে কন্টেইনারাইজ করতে, ক্লাউড শেল টার্মিনালে যান এবং নিম্নলিখিত কমান্ডগুলি চালান (<<YOUR_PROJECT_ID>> প্লেসহোল্ডারটি প্রতিস্থাপন করতে মনে রাখবেন):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
কন্টেইনার ইমেজটি তৈরি হয়ে গেলে, আপনি আউটপুটটি দেখতে পাবেন:
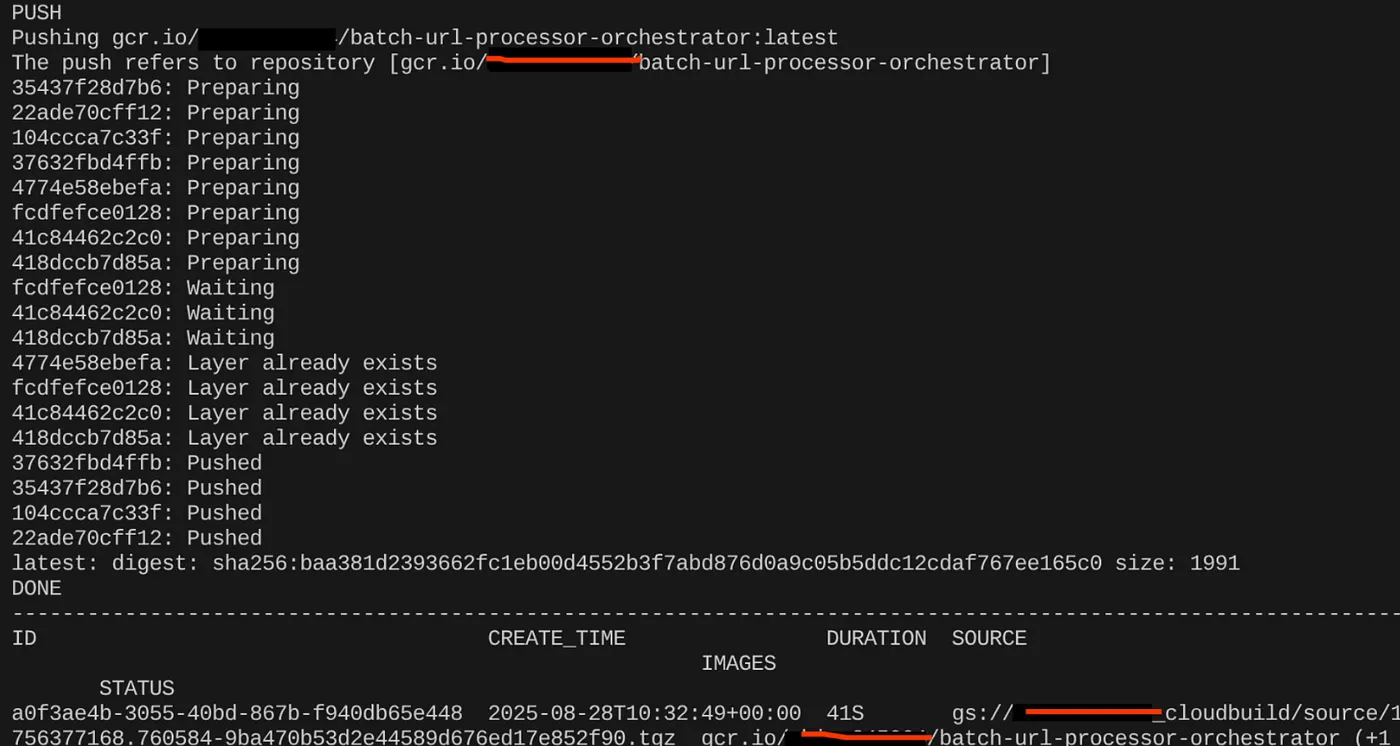
আমাদের কন্টেইনারটি এখন তৈরি হয়ে আর্টিফ্যাক্ট রেজিস্ট্রি-তে সংরক্ষিত হয়েছে। আমরা এখন পরবর্তী ধাপে যাওয়ার জন্য প্রস্তুত।
৮. ক্লাউড রান জব তৈরি
জবটি ডেপ্লয় করার জন্য প্রথমে কন্টেইনার ইমেজ তৈরি করতে হয় এবং তারপর একটি ক্লাউড রান জব রিসোর্স তৈরি করতে হয়।
আমরা ইতিমধ্যে কন্টেইনার ইমেজটি তৈরি করে আর্টিফ্যাক্ট রেজিস্ট্রি-তে সংরক্ষণ করেছি। এখন চলুন জবটি তৈরি করি।
- Cloud Run Jobs কনসোলে যান এবং Deploy Container-এ ক্লিক করুন:

- আমরা এইমাত্র যে কন্টেইনার ইমেজটি তৈরি করেছি তা নির্বাচন করুন:
- অন্যান্য কনফিগারেশন বিবরণ নিম্নরূপভাবে প্রবেশ করান:

- টাস্ক ক্যাপাসিটি নিম্নরূপভাবে সেট করুন:
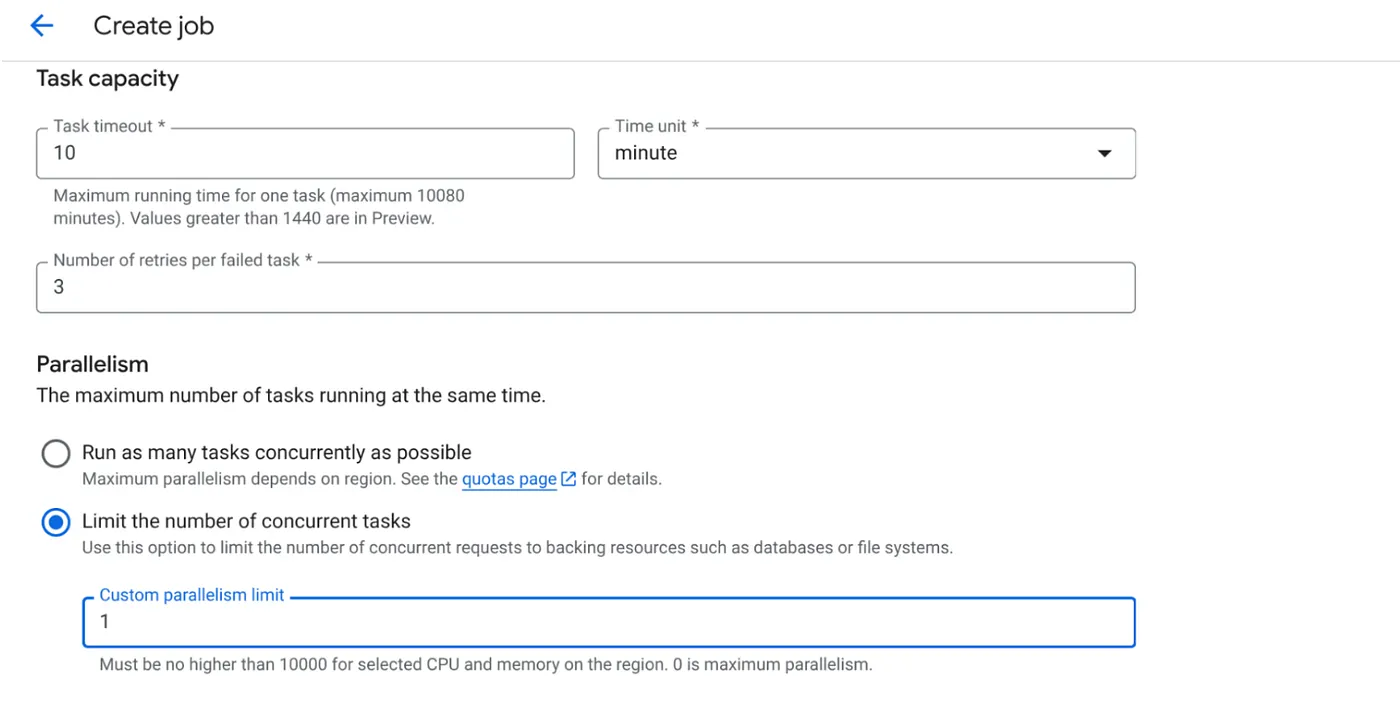
যেহেতু আমাদের ডাটাবেস রাইট রয়েছে এবং কোডে প্যারালেলাইজেশন (max_instances ও টাস্ক কনকারেন্সি) আগে থেকেই সেট করা আছে, তাই আমরা কনকারেন্ট টাস্কের সংখ্যা ১-এ সেট করব। তবে আপনার প্রয়োজন অনুযায়ী এটি বাড়াতে পারেন। এখানকার উদ্দেশ্য হলো, প্যারালেলিজমে সেট করা কনকারেন্সি লেভেল অনুযায়ী টাস্কগুলো কনফিগারেশন অনুসারে সম্পূর্ণভাবে রান করবে।
- তৈরি করতে ক্লিক করুন
আপনার ক্লাউড রান জবটি সফলভাবে তৈরি হয়ে যাবে।
এটি কীভাবে কাজ করে
আমাদের জবের একটি কন্টেইনার ইনস্ট্যান্স চালু হয়। এটি BigQuery-কে কোয়েরি করে PENDING হিসেবে চিহ্নিত URL-এর একটি ছোট ব্যাচ (BATCH_SIZE) সংগ্রহ করে। এটি BigQuery-তে সংগৃহীত URL-গুলোর স্ট্যাটাস অবিলম্বে PROCESSING-এ আপডেট করে দেয়, যাতে অন্য জব ইনস্ট্যান্সগুলো সেগুলোকে গ্রহণ করতে না পারে। এটি একটি ThreadPoolExecutor তৈরি করে এবং ব্যাচের প্রতিটি URL-এর জন্য একটি করে টাস্ক সাবমিট করে। প্রতিটি টাস্ক call_url_processor_service ফাংশনটিকে কল করে। যখন call_url_processor_service-এর অনুরোধগুলো সম্পন্ন হয় (অথবা টাইম আউট/ব্যর্থ হয়), তখন সেগুলোর ফলাফল (AI-দ্বারা তৈরি করা কনটেক্সট অথবা একটি এরর মেসেজ) সংগ্রহ করা হয় এবং মূল row_id-এর সাথে ম্যাপ করা হয়। ব্যাচের সমস্ত টাস্ক শেষ হয়ে গেলে, জবটি সংগৃহীত ফলাফলগুলোর মধ্য দিয়ে পুনরাবৃত্তি করে এবং BigQuery-তে প্রতিটি সংশ্লিষ্ট সারির জন্য কনটেক্সট ও স্ট্যাটাস ফিল্ড আপডেট করে। সফল হলে, জব ইনস্ট্যান্সটি কোনো ত্রুটি ছাড়াই বন্ধ হয়ে যায়। যদি এটি কোনো অনিয়ন্ত্রিত ত্রুটির সম্মুখীন হয়, তবে এটি একটি এক্সেপশন তৈরি করে, যা সম্ভবত Cloud Run Jobs-কে পুনরায় চেষ্টা করতে প্ররোচিত করে (জবের কনফিগারেশনের উপর নির্ভর করে)।
অর্কেস্ট্রেশনে ক্লাউড রান জবস কীভাবে খাপ খায়
এইখানেই ক্লাউড রান জবস তার শ্রেষ্ঠত্ব প্রমাণ করে।
সার্ভারবিহীন ব্যাচ প্রসেসিং: আমরা এমন একটি পরিচালিত পরিকাঠামো পাই যা আমাদের ডেটা একযোগে প্রসেস করার জন্য প্রয়োজন অনুযায়ী (MAX_INSTANCES পর্যন্ত) যত খুশি কন্টেইনার ইনস্ট্যান্স চালু করতে পারে।
সমান্তরালতা নিয়ন্ত্রণ: আমরা MAX_INSTANCES (সামগ্রিকভাবে কতগুলো জব সমান্তরালভাবে চলতে পারে) এবং TASK_CONCURRENCY (প্রতিটি জব ইনস্ট্যান্স সমান্তরালভাবে কতগুলো অপারেশন সম্পাদন করে) নির্ধারণ করি। এটি থ্রুপুট এবং রিসোর্স ব্যবহারের উপর সূক্ষ্ম নিয়ন্ত্রণ প্রদান করে।
ফল্ট টলারেন্স: যদি কোনো জব ইনস্ট্যান্স মাঝপথে ব্যর্থ হয়, তাহলে ক্লাউড রান জবসকে সম্পূর্ণ জব বা নির্দিষ্ট টাস্কগুলো পুনরায় চেষ্টা করার জন্য কনফিগার করা যেতে পারে, যা ডেটা প্রসেসিংয়ের ক্ষতি হওয়া থেকে রক্ষা করে।
সরলীকৃত আর্কিটেকচার: সরাসরি জবের মধ্যেই HTTP কলগুলো পরিচালনা করে এবং স্টেট ম্যানেজমেন্টের জন্য BigQuery ব্যবহার করার মাধ্যমে, আমরা Pub/Sub, এর টপিক, সাবস্ক্রিপশন এবং অ্যাকনলেজমেন্ট লজিক সেট আপ ও পরিচালনার জটিলতা এড়িয়ে চলি।
MAX_INSTANCES বনাম TASK_CONCURRENCY:
MAX_INSTANCES: আপনার সম্পূর্ণ জব এক্সিকিউশন জুড়ে মোট যতগুলো জব ইনস্ট্যান্স একযোগে চলতে পারে। একসাথে অনেকগুলো URL প্রসেস করার জন্য এটিই আপনার প্রধান প্যারালালিজম লিভার।
TASK_CONCURRENCY: আপনার জবের একটিমাত্র ইনস্ট্যান্স যতগুলো সমান্তরাল অপারেশন (আপনার প্রসেসর সার্ভিসে কল) সম্পাদন করবে, তার সংখ্যা। এটি একটি ইনস্ট্যান্সের সিপিইউ/নেটওয়ার্ককে পুরোপুরি ব্যবহার করতে সাহায্য করে।
৯. ক্লাউড রান জব সম্পাদন ও পর্যবেক্ষণ করা
ভিডিও মেটাডেটা
এক্সিকিউট করার আগে, চলুন ডেটার স্ট্যাটাস দেখে নিই।
BigQuery Studio-তে যান এবং নিম্নলিখিত কোয়েরিটি চালান:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
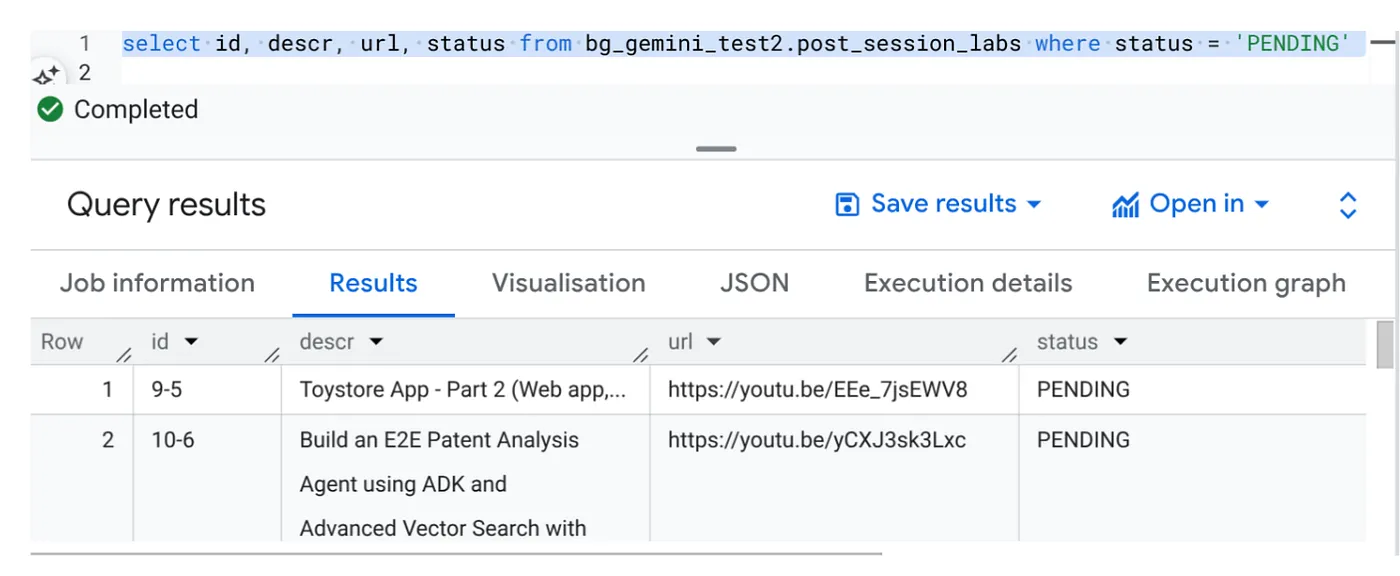
আমাদের কাছে ভিডিও ইউআরএল সহ এবং পেন্ডিং (PENDING) স্ট্যাটাসে থাকা কয়েকটি নমুনা রেকর্ড আছে। আমাদের লক্ষ্য হলো, প্রম্পটে ব্যাখ্যা করা ফরম্যাট অনুযায়ী ভিডিও থেকে প্রাপ্ত তথ্য দিয়ে 'context' ফিল্ডটি পূরণ করা।
কাজের ট্রিগার
চলুন, ক্লাউড রান জবস কনসোলে থাকা জবটির EXECUTE বাটনে ক্লিক করে কাজটি সম্পাদন করা যাক এবং আপনি কনসোলে জবটির অগ্রগতি ও অবস্থা দেখতে পাবেন:
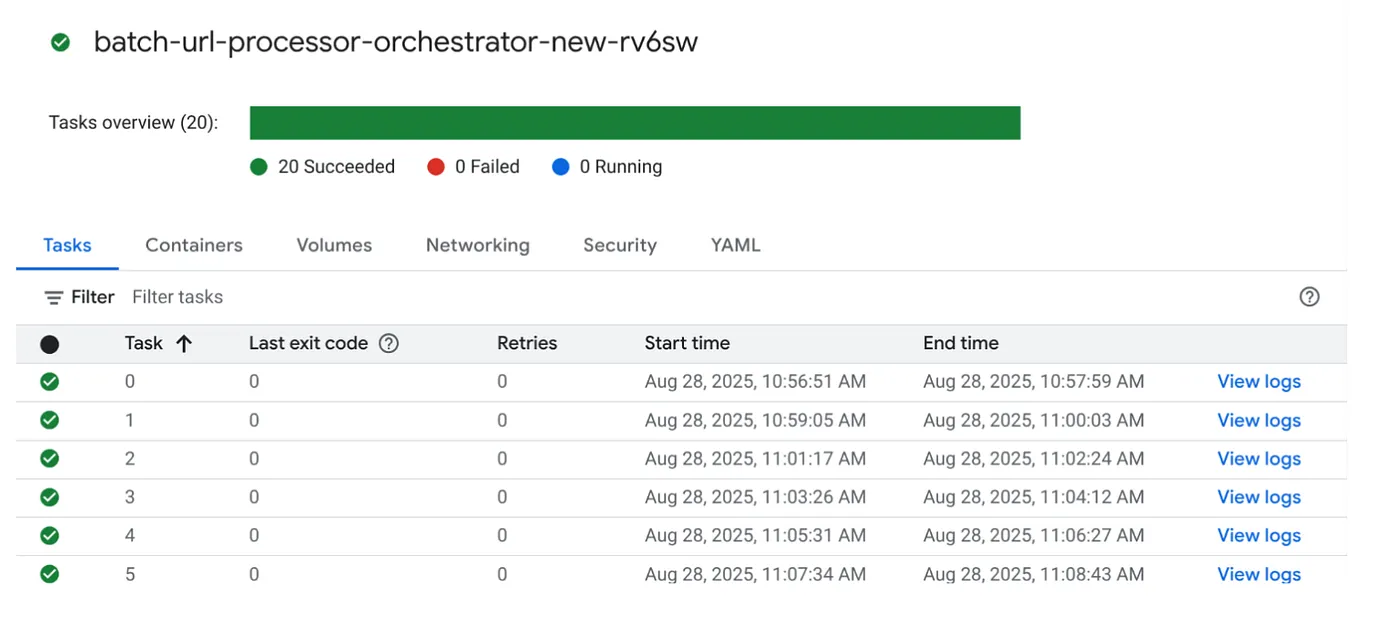
জব এবং টাস্কগুলোর মনিটরিং ধাপ ও অন্যান্য বিবরণ জানতে আপনি OBSERVABILITY-তে থাকা LOGS ট্যাগটি দেখতে পারেন।
১০. ফলাফল বিশ্লেষণ
কাজটি সম্পন্ন হয়ে গেলে, আপনি টেবিলে প্রতিটি ভিডিও ইউআরএল-এর কনটেক্সট আপডেট হতে দেখতে পাবেন:
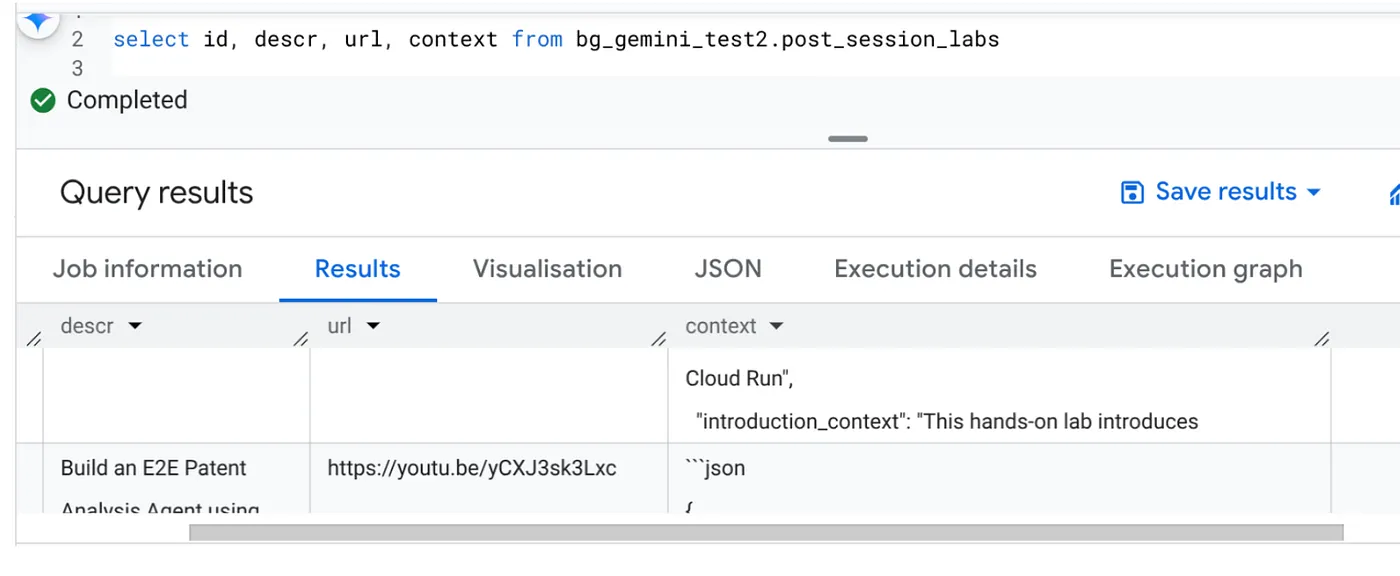
আউটপুট প্রসঙ্গ (রেকর্ডগুলোর একটির জন্য)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
আরও উন্নত এজেন্টিক ব্যবহারের জন্য আপনি এখন এই JSON কাঠামোটি যাচাই করতে পারবেন।
এই পদ্ধতির কারণ কী?
এই স্থাপত্য উল্লেখযোগ্য কৌশলগত সুবিধা প্রদান করে:
- ব্যয়-সাশ্রয়ী: সার্ভারবিহীন পরিষেবার অর্থ হলো আপনি কেবল আপনার ব্যবহৃত অংশের জন্যই অর্থ প্রদান করেন। ব্যবহার না হলে ক্লাউড রান জবস-এর কার্যক্ষমতা শূন্যে নেমে আসে।
- স্কেলেবিলিটি: ক্লাউড রান জব ইনস্ট্যান্স এবং কনকারেন্সি সেটিংস সমন্বয় করে অনায়াসে হাজার হাজার ইউআরএল পরিচালনা করে।
- ক্ষিপ্রতা: শুধুমাত্র অন্তর্ভুক্ত অ্যাপ্লিকেশন এবং এর পরিষেবা আপডেট করার মাধ্যমে নতুন প্রসেসিং লজিক বা এআই মডেলের দ্রুত উন্নয়ন এবং স্থাপন চক্র।
- পরিচালন ব্যয় হ্রাস: কোনো সার্ভার প্যাচ বা পরিচালনা করার প্রয়োজন নেই; গুগলই পরিকাঠামোটি সামলায়।
- এআই-এর গণতান্ত্রিকরণ: গভীর এমএল অপস দক্ষতা ছাড়াই ব্যাচ টাস্কের জন্য উন্নত এআই প্রসেসিংকে সহজলভ্য করে তোলে।
১১. পরিষ্কার করুন
এই পোস্টে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, এই ধাপগুলো অনুসরণ করুন:
- গুগল ক্লাউড কনসোলে, রিসোর্স ম্যানেজার পৃষ্ঠায় যান।
- প্রজেক্ট তালিকা থেকে, আপনি যে প্রজেক্টটি মুছতে চান সেটি নির্বাচন করুন এবং তারপর ডিলিট বোতামে ক্লিক করুন।
- ডায়ালগ বক্সে প্রজেক্ট আইডি টাইপ করুন এবং তারপর প্রজেক্টটি মুছে ফেলার জন্য 'শাট ডাউন'-এ ক্লিক করুন।
১২. অভিনন্দন
অভিনন্দন! ক্লাউড রান জবস-কে কেন্দ্র করে আমাদের সলিউশনটি ডিজাইন করে, ডেটা ম্যানেজমেন্টের জন্য বিগকোয়েরি (BigQuery)-র শক্তি এবং এআই প্রসেসিংয়ের জন্য একটি এক্সটার্নাল ক্লাউড রান সার্ভিস (Cloud Run Service)-কে কাজে লাগিয়ে, আপনি একটি অত্যন্ত স্কেলেবল, সাশ্রয়ী এবং রক্ষণাবেক্ষণযোগ্য সিস্টেম তৈরি করেছেন। এই প্যাটার্নটি প্রসেসিং লজিককে পৃথক করে, জটিল পরিকাঠামো ছাড়াই প্যারালাল এক্সিকিউশনের সুযোগ দেয় এবং ফলাফল প্রাপ্তির সময়কে উল্লেখযোগ্যভাবে ত্বরান্বিত করে।
আপনার নিজস্ব ব্যাচ প্রসেসিংয়ের প্রয়োজনে ক্লাউড রান জবস অন্বেষণ করতে আমরা আপনাকে উৎসাহিত করি। এআই অ্যানালাইসিস স্কেল করা, ইটিএল পাইপলাইন চালানো, বা পর্যায়ক্রমিক ডেটা টাস্ক সম্পাদন করা—যা-ই হোক না কেন, এই সার্ভারলেস পদ্ধতিটি একটি শক্তিশালী ও কার্যকর সমাধান প্রদান করে। নিজে শুরু করতে, এটি দেখুন ।
আপনি যদি আপনার সমস্ত অ্যাপ সার্ভারবিহীন এবং এজেন্টিক পদ্ধতিতে তৈরি ও স্থাপন করতে আগ্রহী হন, তাহলে কোড বিপাসনা -তে নিবন্ধন করুন, যা ডেটা-চালিত জেনারেটিভ এজেন্টিক অ্যাপ্লিকেশনগুলির গতি বাড়ানোর উপর বিশেষভাবে আলোকপাত করে!