
1. Overview
In today's data-rich world, extracting meaningful insights from unstructured content, especially video, is a significant necessity. Imagine needing to analyze hundreds or thousands of video URLs, summarizing their content, extracting key technologies, and even generating Q&A pairs for educational materials. Doing this one by one is not only time-consuming but also inefficient. This is where modern cloud architectures shine.
In this lab, we'll walk through the scalable, serverless solution to process video content using Google Cloud's powerful suite of services: Cloud Run, BigQuery, and Google's Generative AI (Gemini). We'll detail our journey from processing a single URL to orchestrating parallel execution across a large dataset, all without the overhead of managing complex messaging queues and integrations.
The Challenge
We were tasked with processing a large catalog of video content, specifically focusing on hands-on lab sessions. The goal was to analyze each video and generate a structured summary, including chapter titles, introduction context, step-by-step instructions, technologies used, and relevant Q&A pairs. This output needed to be stored efficiently for later use in building educational materials.
Initially, we had a simple HTTP-based Cloud Run service that could process one URL at a time. This worked well for testing and ad-hoc analysis. However, when faced with a list of thousands of URLs sourced from BigQuery, the limitations of this single-request, single-response model became apparent. Sequential processing would take days, if not weeks.
The opportunity was to transform a manual or slow sequential process into an automated, parallelized workflow. By leveraging the cloud, we aimed to:
- Process data in parallel: Significantly reduce processing time for large datasets.
- Leverage existing AI capabilities: Utilize Gemini's power for sophisticated content analysis.
- Maintain serverless architecture: Avoid managing servers or complex infrastructure.
- Centralize data: Use BigQuery as the single source of truth for input URLs and a reliable destination for processed results.
- Build a robust pipeline: Create a system that is resilient to failures and can be easily managed and monitored.
Objective
Orchestrating Parallel AI Processing with Cloud Run Jobs:
Our solution centers around a Cloud Run Job that acts as an orchestrator. It intelligently reads batches of URLs from BigQuery, dispatches these URLs to our existing, deployed Cloud Run Service (which handles the AI processing for a single URL), and then aggregates the results to write them back into BigQuery. This approach allows us to:
- Decouple orchestration from processing: The job manages the workflow, while the separate Service focuses on the AI task.
- Leverage Cloud Run Job's parallelism: The job can scale out multiple container instances to call the AI service concurrently.
- Reduce complexity: We achieve parallelism by having the job manage concurrent HTTP calls directly, simplifying the architecture.
Use Case
AI-Powered Insights from Code Vipassana Session Videos
Our specific use case was analyzing videos of Google Cloud sessions of Code Vipassana hands-on labs. The goal was to automatically generate structured documentation (book chapter outlines), including:
- Chapter Titles: Concise titles for each video segment
- Introduction Context: Explaining the video's relevance in a broader learning path
- What Will Be Built: The core task or goal of the session
- Technologies Used: A list of cloud services and other technologies mentioned
- Step-by-Step Instructions: How the task was performed, including code snippets
- Source Code/Demo URLs: Links provided in the video
- Q&A Segment: Generating relevant questions and answers for knowledge checks.
Flow

Flow of the architecture
What is Cloud Run? What are Cloud Run Jobs?
Cloud Run
A fully managed serverless platform that allows you to run stateless containers. It's ideal for web services, APIs, and microservices that can scale automatically based on incoming requests. You provide a container image, and Cloud Run handles the rest — from deploying and scaling to managing infrastructure. It excels at handling synchronous, request-response workloads.
Cloud Run Jobs
An offering that complements Cloud Run services. Cloud Run Jobs are designed for batch processing tasks that need to complete and then stop. They are perfect for data processing, ETL, machine learning batch inference, and any task that involves processing a dataset rather than serving live requests. A key feature is their ability to scale out the number of container instances (tasks) running concurrently to process a batch of work, and they can be triggered by various event sources or manually.
Key Difference
Cloud Run Services are for long-running, request-driven applications. Cloud Run Jobs are for finite, task-oriented batch processing that runs to completion.
What you'll build
A Retail Search Application
As part of this, you will:
- Create a BigQuery Dataset, table and ingest data (Code Vipassana Metadata)
- Create a Python Cloud Run Functions for implementing the Generative AI functionality (converting video to book chapter json)
- Create a Python application for the data to AI pipeline - Read from BigQuery and invoke the Cloud Run Functions Endpoint for insights and write the context back to BigQuery
- Build and Containerize the application
- Configure a Cloud Run Jobs with this container
- Execute & monitor the job
- Report result
Requirements
2. Before you begin
Create a project
- In the Google Cloud Console, on the project selector page, select or create a Google Cloud project.
- Make sure that billing is enabled for your Cloud project. Learn how to check if billing is enabled on a project .
- You'll use Cloud Shell, a command-line environment running in Google Cloud. Click Activate Cloud Shell at the top of the Google Cloud console.

- Once connected to Cloud Shell, you check that you're already authenticated and that the project is set to your project ID using the following command:
gcloud auth list
- Run the following command in Cloud Shell to confirm that the gcloud command knows about your project.
gcloud config list project
- If your project is not set, use the following command to set it:
gcloud config set project <YOUR_PROJECT_ID>
- Enable the required APIs: Follow the link and enable the APIs.
Alternatively you can use the gcloud command for this. Refer documentation for gcloud commands and usage.
3. Database/Warehouse setup
BigQuery served as the backbone of our data pipeline. Its serverless, highly scalable nature makes it perfect for both storing our input data and housing the processed results.
- Data Storage: BigQuery acted as our data warehouse. It stores the list of video URLs, their status (e.g., PENDING, PROCESSING, COMPLETED), and the final generated context. It's the single source of truth for which videos need processing.
- Destination: It's where the AI-generated insights are persisted, making them easily queryable for downstream applications or manual review. Our dataset consisted of video session details, particularly from "Code Vipassana Seasons" content, which often involves detailed technical demonstrations.
- Source Table: A BigQuery table (e.g., post_session_labs) containing records like:
- id: A unique identifier for each session/row.
- url: The URL of the video (e.g., a YouTube link or an accessible drive link).
- status: A string indicating the processing state (e.g., PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: A string field to store the AI-generated summary.
- Data Ingestion: In this scenario, the data was ingested into BigQuery with INSERT scripts. For our pipeline, BigQuery was the starting point.
Go to BigQuery console, open a new tab and execute the following SQL statements:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Data ingestion
Now it's time to add a table with the data about the store. Navigate to a tab in BigQuery Studio and execute the following SQL statements to insert the sample records:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Video Insights Function Creation
We have to create and deploy a Cloud Run Function to implement the core of the functionality that is to create a structured book chapter from the video URL. Inorder to be able to access this as an independent endpoint toolbox tools we just created and deployed a Cloud Run Function. Alternatively you can choose to include this as a separate function in the actual Python application for the Cloud Run Job:
- In the Google Cloud console, go to the Cloud Run page
- Click Write a function.
- In the Service name field, enter a name to describe your function. Service names must only begin with a letter, and contain up to 49 characters or less, including letters, numbers, or hyphens. Service names can't end with hyphens, and must be unique per region and project. A service name cannot be changed later and is publicly visible. ( generate-video-insights**)**
- In the Region list, use the default value, or select the region where you want to deploy your function. (Choose us-central1)
- In the Runtime list, use the default value, or select a runtime version. (Choose Python 3.11)
- In Authentication section, choose "Allow public access"
- Click "Create" button
- The function is created and loads with a template main.py and requirements.txt
- Replace that with the files: main.py and requirements.txt from this project's repo
IMPORTANT NOTE: In the main.py, remember to replace <<YOUR_PROJECT_ID>> with your project id.
- Deploy and save the endpoint so you can use it in your source for the Cloud Run Job.
Your endpoint should look like this (or something similar): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
What is in this Cloud Run Function?
Gemini 2.5 Flash for Video Processing
For the core task of understanding and summarizing video content, we leveraged Google's Gemini 2.5 Flash model. Gemini models are powerful, multimodal AI models capable of understanding and processing various types of input, including text and, with specific integrations, video.
In our setup, we didn't directly feed the video file to Gemini. Instead, we sent a textual prompt that included the video URL and instructed Gemini on how to analyze the (hypothetical) content of a video at that URL. While Gemini 2.5 Flash is capable of multimodal input, this specific pipeline used a text-based prompt that described the video's nature (a hands-on lab session) and requested a structured JSON output. This leverages Gemini's advanced reasoning and natural language understanding to infer and synthesize information based on the prompt's context.
The Gemini Prompt: Guiding the AI
A well-crafted prompt is crucial for AI models. Our prompt was designed to extract very specific information and structure it into a JSON format, making it easily parseable by our application.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
This prompt is highly specific, guiding Gemini to act as an educator of sorts. The request for a JSON string ensures structured, machine-readable output.
Here is the code for analyzing video input and returning its context:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
This snippet above demonstrates the core function of the use case. It receives a video URL and utilizes the Gemini model via the Vertex AI client to analyze the video content and extract relevant insights per the prompt. The extracted context is then returned for further processing. This represents a synchronous operation where the Cloud Run Job waits for the service to complete.
6. Pipeline Application Development (Python)
Our central pipeline logic resides in the application's source code that will be containerized into a Cloud Run Job, which orchestrates the entire parallel execution. Here's a look at the key parts:
The orchestrator's role in managing the workflow and ensuring data integrity:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
This snippet above begins by fetching a batch of video URLs with a ‘PENDING' status from the BigQuery source table. It then updates the status of these URLs to ‘PROCESSING' in BigQuery, preventing duplicate processing.
Parallel Processing with ThreadPoolExecutor and Calling the Processor Service:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
This part of the code leverages ThreadPoolExecutor to achieve parallel processing of the fetched video URLs. For each URL, it submits a task to call the Cloud Run Service (URL Processor) asynchronously. This allows the Cloud Run Job to efficiently process multiple videos concurrently, enhancing overall pipeline performance. The snippet also handles potential timeouts and errors from the processor service.
Reading & Writing from & to BigQuery
The core interaction with BigQuery involves fetching pending URLs and then updating them with processed results.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Writing the results back to BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
The snippets above focus on the data interaction between the Cloud Run Job and BigQuery. It retrieves a batch of ‘PENDING' video URLs and their IDs from the source table. After the URLs are processed, this snippet demonstrates writing the extracted context and status (‘COMPLETED' or ‘FAILED_PROCESSING') back to the target BigQuery table using an UPDATE query. This snippet completes the data processing loop. It also includes the update_bq_row helper function which shows how to define parameters of the update statement.
Application Setup
The application is structured as a single Python script that will be containerized. It leverages Google Cloud client libraries and the functions-framework to define its entry point.
- Dependencies: google-cloud-bigquery, requests
- Configuration: All critical settings (BigQuery project/dataset/table, URL processor service URL) are loaded from environment variables, making the application portable and secure
- Core Logic: The process_batch_from_bq function orchestrates the entire workflow
- External Service Integration: The call_url_processor_service function handles communication with the separate Cloud Run Service
- BigQuery Interaction: bq_client is used for fetching URLs and updating results, with proper parameter handling
- Parallelism: concurrent.futures.ThreadPoolExecutor manages concurrent calls to the external servic
- Entry Point: The Python code named main.py acts as the entrypoint that kickoff the batch processing.
Let's setup the application now:
- You can start by navigating to your Cloud Shell Terminal and cloning the repository:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Navigate to the Cloud Shell Editor, where you can see the newly created folder video-context-crj
- Delete the following as those steps are already completed in the previous sections:
- Delete the folder Cloud_Run_Function
- Navigate into the project folder video-context-crj and you should see the project structure:
7. Dockerfile Setup and Containerization
To deploy this logic as a Cloud Run Job, we need to containerize it. Containerization is the process of packaging our application code, its dependencies, and runtime into a portable image.
MAke sure to replace the placeholders (text in bold) with your values in the Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
The Dockerfile snippet above defines the base image, installs dependencies, copies our code, and sets the command to run our application using the functions-framework with the correct target function (process_batch_from_bq). This image is then pushed to the Artifact Registry.
Containerize
To containerize it, go to the Cloud Shell Terminal and execute the following commands (Remember to replace the <<YOUR_PROJECT_ID>> placeholder):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Once the container image is created, you should see the output:
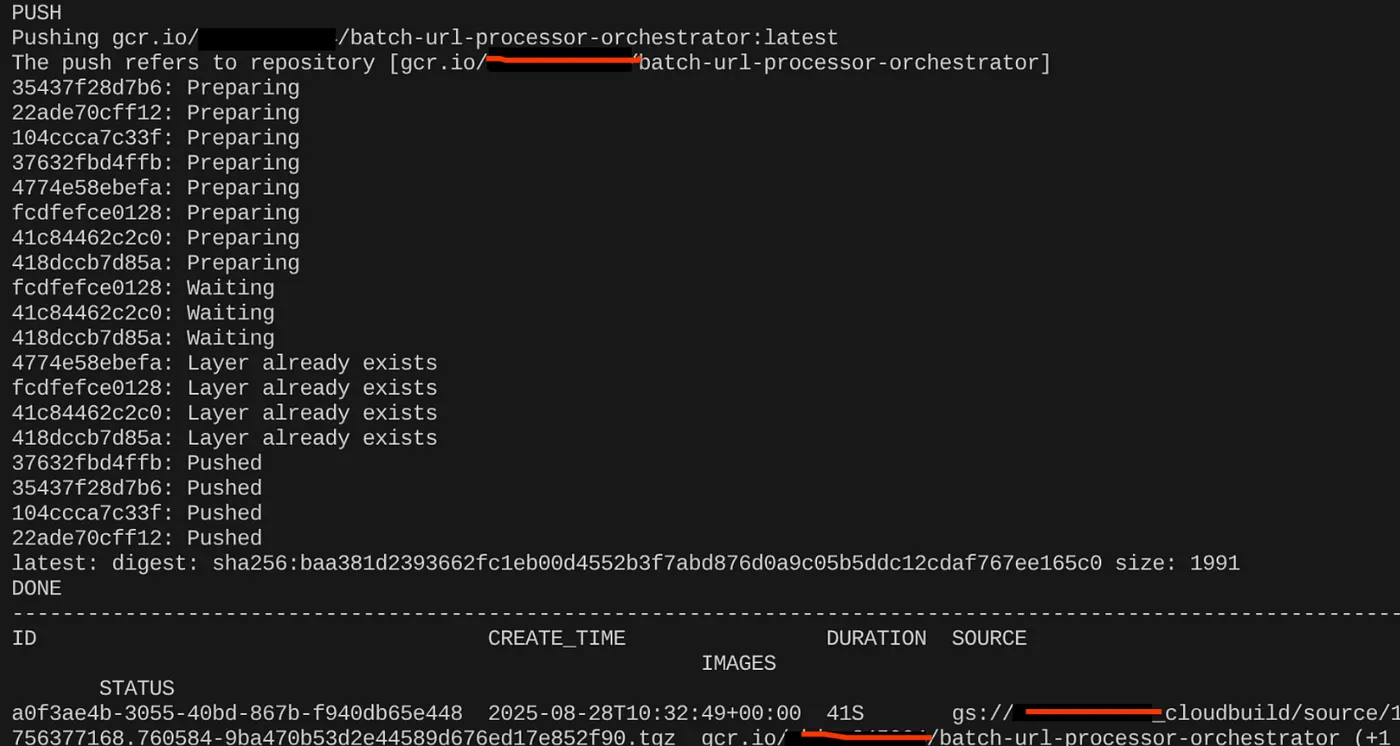
Our container is now created and saved in the Artifact Registry. We are good to go to the next step.
8. Cloud Run Jobs Creation
Deploying the job involves building the container image and then creating a Cloud Run Job resource.
We have already created the container image and stored it in the Artifact Registry. Now let's create the job.
- Go to the Cloud Run Jobs console and click Deploy Container:

- Select the container image that we just created:
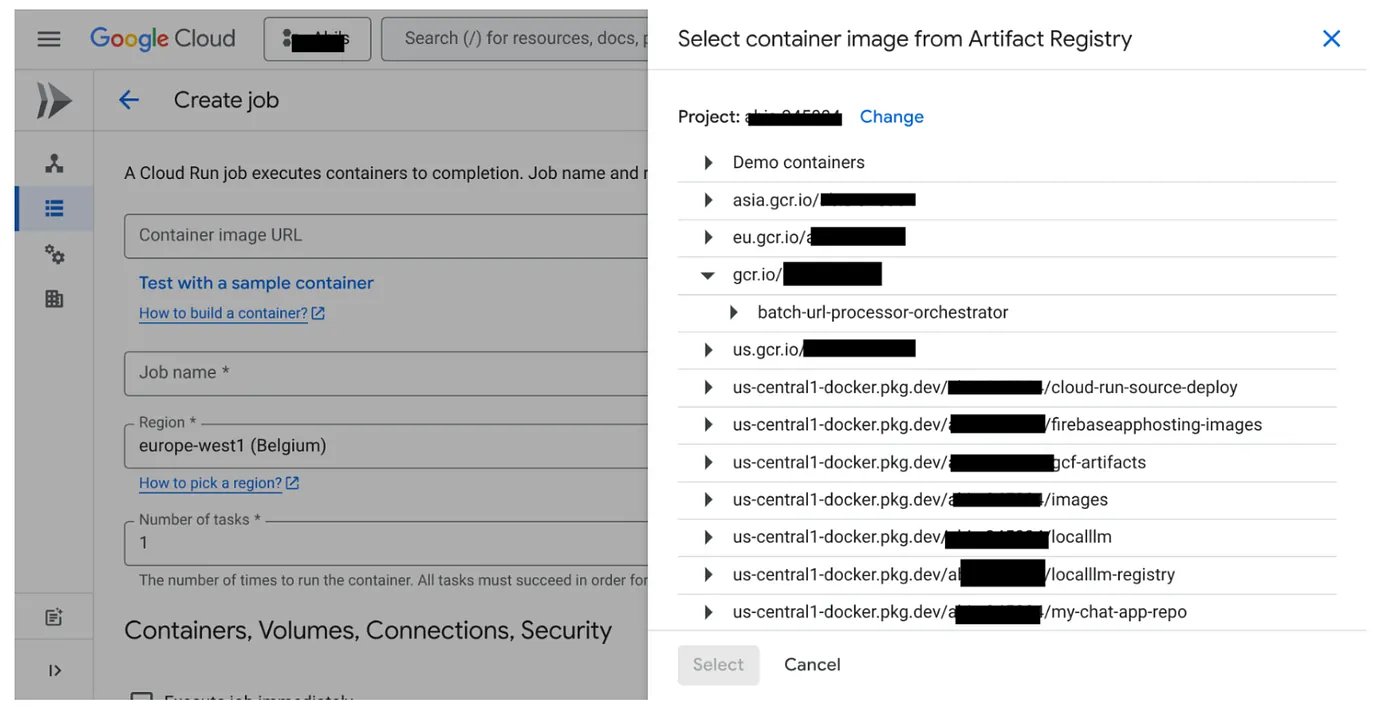
- Enter other configuration details as follows:

- Set Task Capacity as follows:
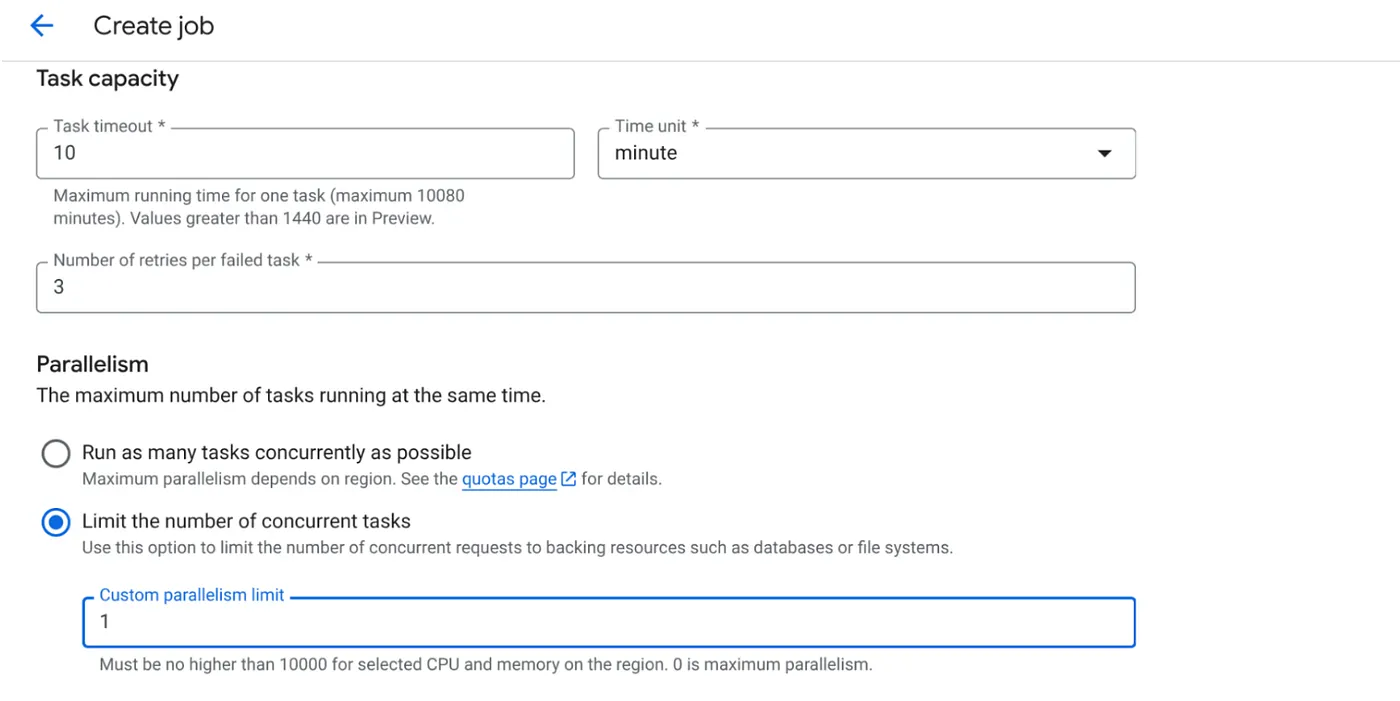
Since we have database writes and the fact that parallelization (max_instances and task concurrency) is already handled in the code, we'll set the number of concurrent tasks to 1. But feel free to increase it per your requirement. The objective here is that the tasks will run to completion as per configuration with the concurrency level set in parallelism.
- Click Create
Your Cloud Run Job will be created successfully.
How it works
A container instance of our job starts. It queries BigQuery to get a small batch (BATCH_SIZE) of URLs marked as PENDING. It immediately updates the status of these fetched URLs to PROCESSING in BigQuery to prevent other job instances from picking them up. It creates a ThreadPoolExecutor and submits a task for each URL in the batch. Each task calls the call_url_processor_service function. As the call_url_processor_service requests complete (or time out/fail), their results (either the AI-generated context or an error message) are collected, mapped back to the original row_id. Once all tasks for the batch are finished, the job iterates through the collected results and updates the context and status fields for each corresponding row in BigQuery. If successful, the job instance exits cleanly. If it encounters unhandled errors, it raises an exception, potentially triggering a retry by Cloud Run Jobs (depending on job configuration).
How Cloud Run Jobs Fit In: Orchestration
This is where Cloud Run Jobs truly shine.
Serverless Batch Processing: We get managed infrastructure that can spin up as many container instances as needed (up to MAX_INSTANCES) to process our data concurrently.
Parallelism Control: We define MAX_INSTANCES (how many jobs can run in parallel overall) and TASK_CONCURRENCY (how many operations each job instance performs in parallel). This provides fine-grained control over throughput and resource utilization.
Fault Tolerance: If a job instance fails midway, Cloud Run Jobs can be configured to retry the entire job or specific tasks, ensuring that data processing isn't lost.
Simplified Architecture: By orchestrating HTTP calls directly within the Job and using BigQuery for state management, we avoid the complexity of setting up and managing Pub/Sub, its topics, subscriptions, and acknowledgment logic.
MAX_INSTANCES vs. TASK_CONCURRENCY:
MAX_INSTANCES: The total number of job instances that can run concurrently across your entire job execution. This is your main parallelism lever for processing many URLs at once.
TASK_CONCURRENCY: The number of parallel operations (calls to your processor service) that a single instance of your job will perform. This helps saturate the CPU/network of one instance.
9. Executing & Monitoring the Cloud Run Job
Video Metadata
Before we click execute, let's view the status of the data.
Go to BigQuery Studio and run the following query:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
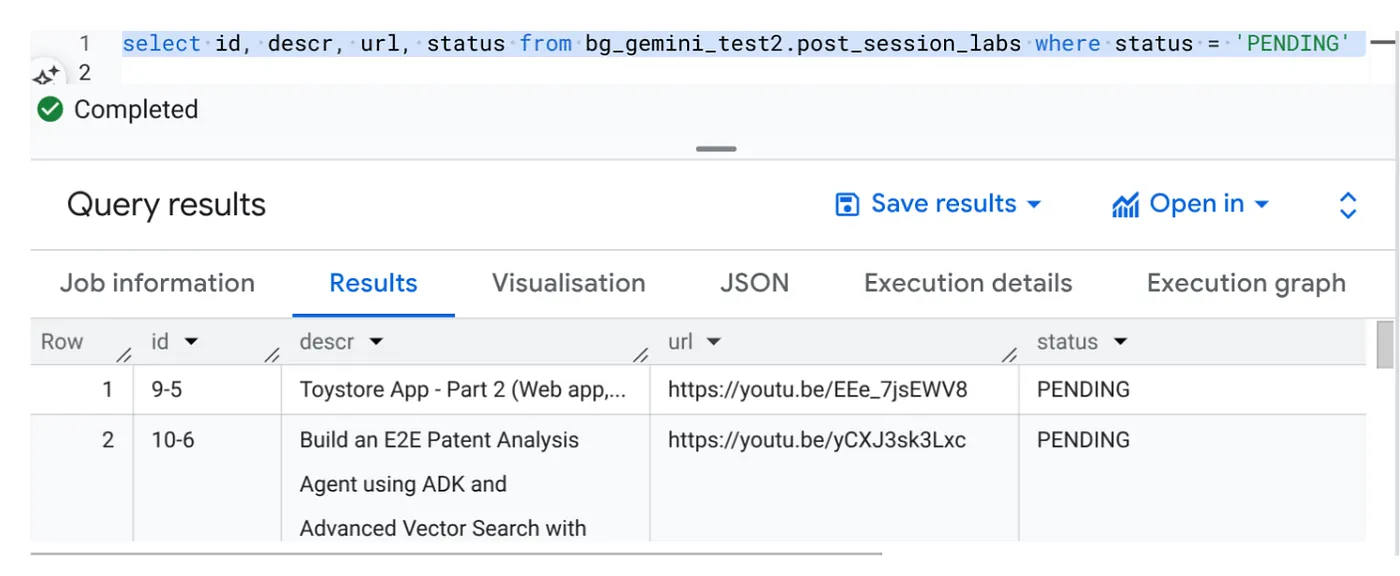
We have a few sample records with video URLs and in PENDING status. Our goal is to populate the "context" field with insights from the video in the format explained in the prompt.
Job Trigger
Let's go ahead and execute the job by clicking the EXECUTE button on the job in the Cloud Run Jobs console and you should be able to see the progress and status of the jobs in the console:
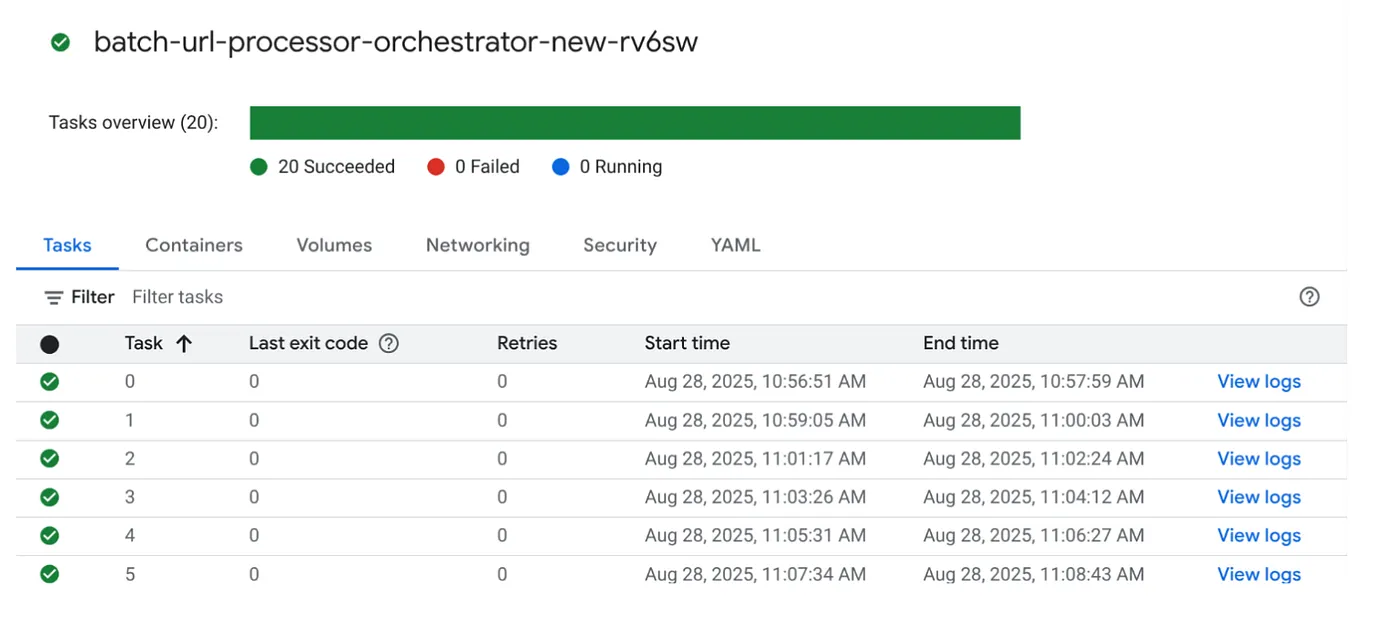
You can check the LOGS tag in OBSERVABILITY for monitoring steps and other details about the job and the tasks.
10. Result Analysis
Once the job is complete, you should be able to see the context for each video URL updated in the table:
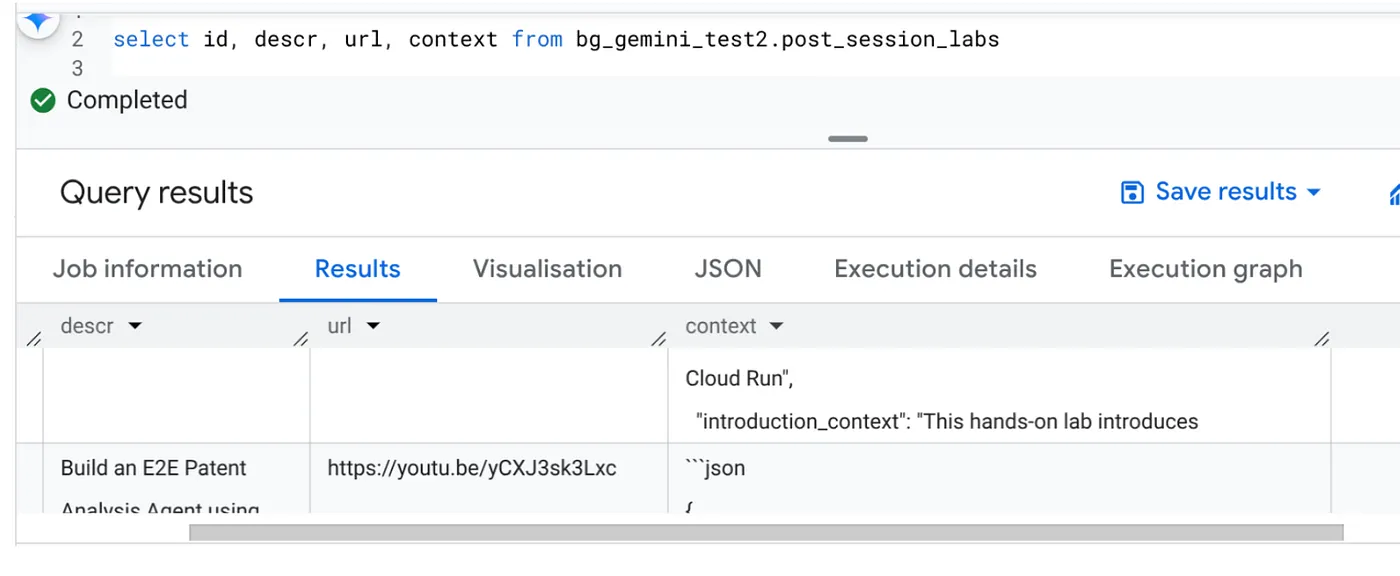
Output Context (for one of the records)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
You should be able to validate this JSON structure now for more advanced agentic use cases.
Why this approach?
This architecture provides significant strategic advantages:
- Cost-Effectiveness: Serverless services mean you only pay for what you use. Cloud Run Jobs scale down to zero when not in use.
- Scalability: Effortlessly handles tens of thousands of URLs by adjusting Cloud Run Job instance and concurrency settings.
- Agility: Rapid development and deployment cycles for new processing logic or AI models by simply updating the contained application and its service.
- Reduced Operational Overhead: No servers to patch or manage; Google handles the infrastructure.
- Democratizing AI: Makes advanced AI processing accessible for batch tasks without deep ML Ops expertise.
11. Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this post, follow these steps:
- In the Google Cloud console, go to the resource manager page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
12. Congratulations
Congratulations! By architecting our solution around Cloud Run Jobs and leveraging the power of BigQuery for data management and an external Cloud Run Service for AI processing, you've built a highly scalable, cost-effective, and maintainable system. This pattern decouples processing logic, allows for parallel execution without complex infrastructure, and significantly accelerates time-to-insight.
We encourage you to explore Cloud Run Jobs for your own batch processing needs. Whether it's scaling AI analysis, running ETL pipelines, or performing periodic data tasks, this serverless approach offers a powerful and efficient solution. To get started on your own, check this out.
If you are curious to build and deploy all your apps serverlessly and agentic, register for Code Vipassana which is focused on accelerating data-driven generative agentic applications!