
1. Descripción general
En el mundo actual, que está repleto de datos, es muy necesario extraer estadísticas significativas del contenido no estructurado, en especial de los videos. Imagina que necesitas analizar cientos o miles de URLs de videos, resumir su contenido, extraer tecnologías clave y hasta generar pares de preguntas y respuestas para materiales educativos. Hacerlo uno por uno no solo lleva mucho tiempo, sino que también es ineficiente. Aquí es donde se destacan las arquitecturas de nube modernas.
En este lab, analizaremos la solución escalable y sin servidores para procesar contenido de video con el potente paquete de servicios de Google Cloud: Cloud Run, BigQuery y la IA generativa de Google (Gemini). Detallaremos nuestro recorrido desde el procesamiento de una sola URL hasta la organización de la ejecución paralela en un gran conjunto de datos, todo sin la sobrecarga de administrar complejas colas de mensajes e integraciones.
El desafío
Se nos encomendó la tarea de procesar un gran catálogo de contenido de video, en particular, las sesiones de lab práctico. El objetivo era analizar cada video y generar un resumen estructurado, incluidos los títulos de los capítulos, el contexto de la introducción, las instrucciones paso a paso, las tecnologías utilizadas y los pares de preguntas y respuestas pertinentes. Esta salida debía almacenarse de manera eficiente para su uso posterior en la creación de materiales educativos.
Inicialmente, teníamos un servicio de Cloud Run simple basado en HTTP que podía procesar una URL a la vez. Esto funcionó bien para las pruebas y el análisis ad hoc. Sin embargo, cuando nos enfrentamos a una lista de miles de URLs provenientes de BigQuery, las limitaciones de este modelo de una sola solicitud y una sola respuesta se hicieron evidentes. El procesamiento secuencial tardaría días, si no semanas.
La oportunidad consistía en transformar un proceso manual o secuencial lento en un flujo de trabajo automatizado y paralelizado. Aprovechando la nube, nuestro objetivo era lograr lo siguiente:
- Procesa datos en paralelo: Reduce significativamente el tiempo de procesamiento de grandes conjuntos de datos.
- Aprovecha las capacidades existentes de la IA: Utiliza el poder de Gemini para realizar análisis de contenido sofisticados.
- Mantener la arquitectura sin servidores: Evita administrar servidores o infraestructura compleja.
- Centraliza los datos: Usa BigQuery como la única fuente de información para las URLs de entrada y como un destino confiable para los resultados procesados.
- Crea una canalización sólida: Crea un sistema que sea resistente a las fallas y que se pueda administrar y supervisar con facilidad.
Objetivo
Organización del procesamiento paralelo de IA con trabajos de Cloud Run:
Nuestra solución se centra en un trabajo de Cloud Run que actúa como organizador. Lee de forma inteligente lotes de URLs de BigQuery, los envía a nuestro servicio de Cloud Run existente y ya implementado (que controla el procesamiento de IA para una sola URL) y, luego, agrega los resultados para volver a escribirlos en BigQuery. Este enfoque nos permite hacer lo siguiente:
- Desvincula la organización del procesamiento: El trabajo administra el flujo de trabajo, mientras que el servicio independiente se enfoca en la tarea de IA.
- Aprovecha el paralelismo de Cloud Run Job: El trabajo puede escalar horizontalmente varias instancias de contenedor para llamar al servicio de IA de forma simultánea.
- Reducción de la complejidad: Logramos el paralelismo haciendo que el trabajo administre las llamadas HTTP simultáneas directamente, lo que simplifica la arquitectura.
Caso de uso
Estadísticas potenciadas por IA de los videos de las sesiones de Code Vipassana
Nuestro caso de uso específico fue analizar videos de las sesiones de Google Cloud de los labs prácticos de Code Vipassana. El objetivo era generar automáticamente documentación estructurada (esquemas de capítulos de libros), lo que incluye lo siguiente:
- Títulos de capítulos: Títulos concisos para cada segmento de video
- Contexto de la introducción: Explicar la relevancia del video en una ruta de aprendizaje más amplia
- Qué se creará: La tarea o el objetivo principal de la sesión
- Tecnologías utilizadas: Una lista de los servicios de nube y otras tecnologías mencionadas
- Instrucciones paso a paso: Cómo se realizó la tarea, incluidos fragmentos de código
- URLs de código fuente o demostración: Vínculos proporcionados en el video
- Segmento de preguntas y respuestas: Genera preguntas y respuestas pertinentes para las verificaciones de conocimientos.
Flujo

Flujo de la arquitectura
¿Qué es Cloud Run? ¿Qué son los trabajos de Cloud Run?
Cloud Run
Es una plataforma sin servidores completamente administrada que te permite ejecutar contenedores sin estado. Es ideal para servicios web, APIs y microservicios que pueden escalar automáticamente en función de las solicitudes entrantes. Tú proporcionas una imagen de contenedor y Cloud Run se encarga del resto, desde la implementación y el ajuste de escala hasta la administración de la infraestructura. Se destaca por controlar las cargas de trabajo síncronas de solicitud y respuesta.
Trabajos de Cloud Run
Es una oferta que complementa los servicios de Cloud Run. Los trabajos de Cloud Run están diseñados para tareas de procesamiento por lotes que deben completarse y, luego, detenerse. Son perfectas para el procesamiento de datos, la ETL, la inferencia por lotes del aprendizaje automático y cualquier tarea que implique el procesamiento de un conjunto de datos en lugar de atender solicitudes en vivo. Una característica clave es su capacidad para escalar horizontalmente la cantidad de instancias de contenedor (tareas) que se ejecutan de forma simultánea para procesar un lote de trabajo, y se pueden activar de forma manual o a través de varias fuentes de eventos.
Diferencia clave
Los servicios de Cloud Run son para aplicaciones de larga duración basadas en solicitudes. Los trabajos de Cloud Run son para el procesamiento por lotes finito y orientado a tareas que se ejecuta hasta su finalización.
Qué compilarás
Una aplicación de Retail Search
Como parte de esto, harás lo siguiente:
- Crea un conjunto de datos y una tabla de BigQuery, y luego ingiere datos (metadatos de Vipassana de código)
- Crea una función de Cloud Run Functions en Python para implementar la funcionalidad de IA generativa (convertir un video en un archivo JSON de capítulos de un libro)
- Crea una aplicación en Python para la canalización de datos a IA: lee desde BigQuery, invoca el extremo de Cloud Run Functions para obtener estadísticas y escribe el contexto en BigQuery
- Compila la aplicación y organízala en contenedores
- Configura un trabajo de Cloud Run con este contenedor
- Ejecuta y supervisa el trabajo
- Resultado del informe
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto .
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando de gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
3. Configuración de la base de datos o el almacén
BigQuery sirvió como la columna vertebral de nuestra canalización de datos. Su naturaleza sin servidores y altamente escalable lo hace perfecto para almacenar nuestros datos de entrada y alojar los resultados procesados.
- Almacenamiento de datos: BigQuery actuó como nuestro almacén de datos. Almacena la lista de URLs de videos, su estado (p.ej., PENDING, PROCESSING, COMPLETED) y el contexto final generado. Es la única fuente de información sobre qué videos se deben procesar.
- Destino: Es el lugar donde se almacenan las estadísticas generadas por IA, lo que facilita la consulta para las aplicaciones posteriores o la revisión manual. Nuestro conjunto de datos consistía en detalles de sesiones de video, en particular del contenido de "Code Vipassana Seasons", que a menudo incluye demostraciones técnicas detalladas.
- Tabla de origen: Una tabla de BigQuery (p.ej., post_session_labs) que contiene registros como los siguientes:
- ID: Es un identificador único para cada sesión o fila.
- url: Es la URL del video (p.ej., un vínculo de YouTube o un vínculo accesible de Drive).
- status: Es una cadena que indica el estado de procesamiento (p.ej., PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: Es un campo de cadena para almacenar el resumen generado por IA.
- Transferencia de datos: En este caso, los datos se transfirieron a BigQuery con secuencias de comandos INSERT. Para nuestra canalización, BigQuery fue el punto de partida.
Ve a la consola de BigQuery, abre una pestaña nueva y ejecuta las siguientes instrucciones de SQL:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Transferencia de datos
Ahora es el momento de agregar una tabla con los datos de la tienda. Navega a una pestaña en BigQuery Studio y ejecuta las siguientes instrucciones de SQL para insertar los registros de muestra:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Creación de la función de estadísticas de video
Tenemos que crear e implementar una Cloud Run Function para implementar el núcleo de la funcionalidad, que consiste en crear un capítulo estructurado de un libro a partir de la URL de un video. Para poder acceder a esto como herramientas independientes de la caja de herramientas de extremos, acabamos de crear e implementar una función de Cloud Run. También puedes incluirla como una función separada en la aplicación de Python real para el trabajo de Cloud Run:
- En la consola de Google Cloud, ve a la página de Cloud Run.
- Haz clic en Escribir una función.
- En el campo Nombre del servicio, ingresa un nombre para describir tu función. Los nombres de servicios solo deben comenzar con una letra y contener hasta 49 caracteres o menos, incluidas letras, números o guiones. Los nombres de los servicios no pueden terminar con guiones y deben ser únicos por región y proyecto. Un nombre de servicio no se puede cambiar más adelante y es visible de forma pública. ( generate-video-insights**)**
- En la lista Región, usa el valor predeterminado o selecciona la región en la que quieres implementar la función. (Elige us-central1)
- En la lista Runtime, usa el valor predeterminado o selecciona una versión de entorno de ejecución. (Elige Python 3.11)
- En la sección Autenticación, elige "Permitir acceso público".
- Haz clic en el botón "Crear".
- Se crea la función y se carga con una plantilla de main.py y requirements.txt
- Reemplaza ese contenido por los archivos main.py y requirements.txt del repo de este proyecto.
NOTA IMPORTANTE: En main.py, recuerda reemplazar <<YOUR_PROJECT_ID>> por el ID de tu proyecto.
- Implementa y guarda el extremo para que puedas usarlo en la fuente de tu trabajo de Cloud Run.
Tu extremo debería verse así (o de forma similar): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
¿Qué contiene esta función de Cloud Run?
Gemini 2.5 Flash para el procesamiento de video
Para la tarea principal de comprender y resumir el contenido de video, aprovechamos el modelo Gemini 2.5 Flash de Google. Los modelos de Gemini son modelos de IA multimodales y potentes capaces de comprender y procesar varios tipos de entrada, incluido texto y, con integraciones específicas, video.
En nuestra configuración, no alimentamos directamente el archivo de video a Gemini. En su lugar, enviamos una instrucción textual que incluía la URL del video y le indicaba a Gemini cómo analizar el contenido (hipotético) de un video en esa URL. Si bien Gemini 2.5 Flash es capaz de recibir entradas multimodales, esta canalización específica usó una instrucción basada en texto que describía la naturaleza del video (una sesión de laboratorio práctica) y solicitaba un resultado JSON estructurado. Esto aprovecha el razonamiento avanzado y la comprensión del lenguaje natural de Gemini para inferir y sintetizar información según el contexto de la instrucción.
La instrucción de Gemini: Cómo guiar a la IA
Una instrucción bien elaborada es fundamental para los modelos de IA. Nuestra instrucción se diseñó para extraer información muy específica y estructurarla en formato JSON, lo que facilita su análisis por parte de nuestra aplicación.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Esta instrucción es muy específica y guía a Gemini para que actúe como una especie de educador. La solicitud de una cadena JSON garantiza un resultado estructurado y legible por máquina.
Este es el código para analizar la entrada de video y devolver su contexto:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
El fragmento anterior demuestra la función principal del caso de uso. Recibe una URL de video y utiliza el modelo de Gemini a través del cliente de Vertex AI para analizar el contenido del video y extraer estadísticas relevantes según la instrucción. Luego, se devuelve el contexto extraído para su procesamiento posterior. Esto representa una operación síncrona en la que el trabajo de Cloud Run espera a que se complete el servicio.
6. Desarrollo de aplicaciones de canalización (Python)
La lógica central de nuestra canalización reside en el código fuente de la aplicación que se incluirá en un contenedor de un trabajo de Cloud Run, que coordina toda la ejecución paralela. Estas son las partes clave:
El rol del organizador en la administración del flujo de trabajo y la garantía de la integridad de los datos:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
El fragmento de código anterior comienza recuperando un lote de URLs de videos con el estado “PENDING” de la tabla de origen de BigQuery. Luego, actualiza el estado de estas URLs a "PROCESSING" en BigQuery, lo que evita el procesamiento duplicado.
Procesamiento paralelo con ThreadPoolExecutor y llamada al servicio de procesador:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Esta parte del código aprovecha ThreadPoolExecutor para lograr el procesamiento paralelo de las URLs de video recuperadas. Para cada URL, envía una tarea para llamar al servicio de Cloud Run (procesador de URLs) de forma asíncrona. Esto permite que el trabajo de Cloud Run procese de manera eficiente varios videos de forma simultánea, lo que mejora el rendimiento general de la canalización. El fragmento también controla los posibles tiempos de espera y errores del servicio del procesador.
Lectura y escritura desde y hacia BigQuery
La interacción principal con BigQuery implica recuperar URLs pendientes y, luego, actualizarlas con los resultados procesados.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Escribe los resultados en BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Los fragmentos de código anteriores se enfocan en la interacción de datos entre el trabajo de Cloud Run y BigQuery. Recupera un lote de URLs de video con el estado "PENDING" y sus IDs de la tabla de origen. Después de procesar las URLs, este fragmento demuestra cómo escribir el contexto y el estado extraídos (“COMPLETED” o “FAILED_PROCESSING”) en la tabla de BigQuery de destino con una consulta UPDATE. Este fragmento completa el bucle de procesamiento de datos. También incluye la función auxiliar update_bq_row, que muestra cómo definir los parámetros de la instrucción de actualización.
Configuración de la aplicación
La aplicación se estructura como una sola secuencia de comandos de Python que se alojará en un contenedor. Aprovecha las bibliotecas cliente de Google Cloud y el framework de funciones para definir su punto de entrada.
- Dependencias: google-cloud-bigquery, requests
- Configuración: Todos los parámetros de configuración críticos (proyecto, conjunto de datos y tabla de BigQuery, URL del servicio de procesador de URLs) se cargan desde variables de entorno, lo que hace que la aplicación sea portátil y segura.
- Lógica principal: La función process_batch_from_bq coordina todo el flujo de trabajo
- Integración de servicios externos: La función call_url_processor_service controla la comunicación con el servicio de Cloud Run independiente.
- Interacción con BigQuery: bq_client se usa para recuperar URLs y actualizar resultados, con un manejo adecuado de los parámetros
- Paralelismo: concurrent.futures.ThreadPoolExecutor administra las llamadas simultáneas al servicio externo.
- Punto de entrada: El código de Python llamado main.py actúa como el punto de entrada que inicia el procesamiento por lotes.
Ahora, configuremos la aplicación:
- Para comenzar, navega a la terminal de Cloud Shell y clona el repositorio:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Navega al editor de Cloud Shell, donde puedes ver la carpeta recién creada video-context-crj.
- Borra lo siguiente, ya que esos pasos ya se completaron en las secciones anteriores:
- Borra la carpeta Cloud_Run_Function
- Navega a la carpeta del proyecto video-context-crj y deberías ver la estructura del proyecto:
7. Configuración de Dockerfile y contenedorización
Para implementar esta lógica como un trabajo de Cloud Run, debemos contenerizarla. La contenedorización es el proceso de empaquetar el código de nuestra aplicación, sus dependencias y el tiempo de ejecución en una imagen portátil.
Asegúrate de reemplazar los marcadores de posición (texto en negrita) por tus valores en el Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
El fragmento de Dockerfile anterior define la imagen base, instala dependencias, copia nuestro código y establece el comando para ejecutar nuestra aplicación con functions-framework y la función de destino correcta (process_batch_from_bq). Luego, esta imagen se envía a Artifact Registry.
Creación de contenedores
Para contenerizarlo, ve a la terminal de Cloud Shell y ejecuta los siguientes comandos (recuerda reemplazar el marcador de posición <<YOUR_PROJECT_ID>>):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Una vez que se cree la imagen del contenedor, deberías ver el siguiente resultado:
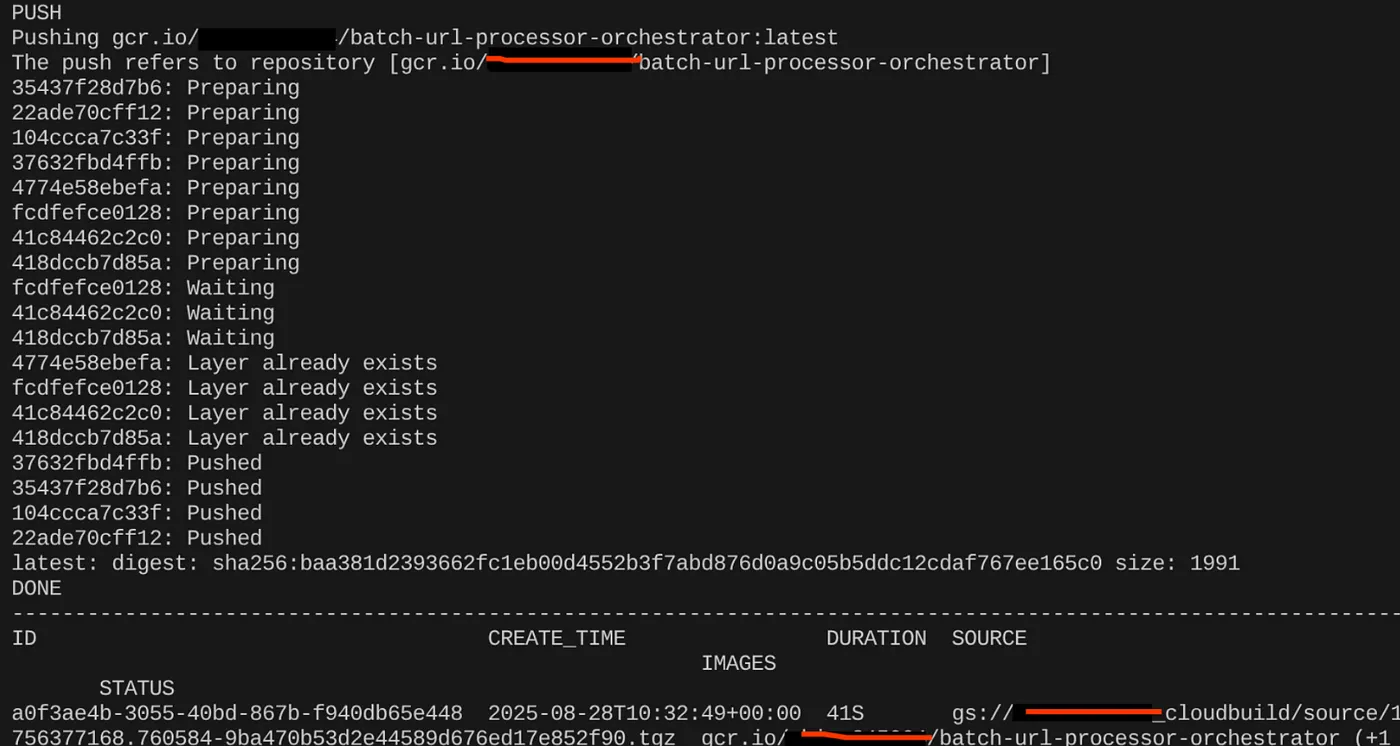
Ahora, nuestro contenedor se creó y guardó en Artifact Registry. Ya podemos continuar con el siguiente paso.
8. Creación de trabajos de Cloud Run
La implementación del trabajo implica compilar la imagen del contenedor y, luego, crear un recurso de Cloud Run Job.
Ya creamos la imagen de contenedor y la almacenamos en Artifact Registry. Ahora, creemos el trabajo.
- Ve a la consola de Cloud Run Jobs y haz clic en Deploy Container:

- Selecciona la imagen de contenedor que acabamos de crear:
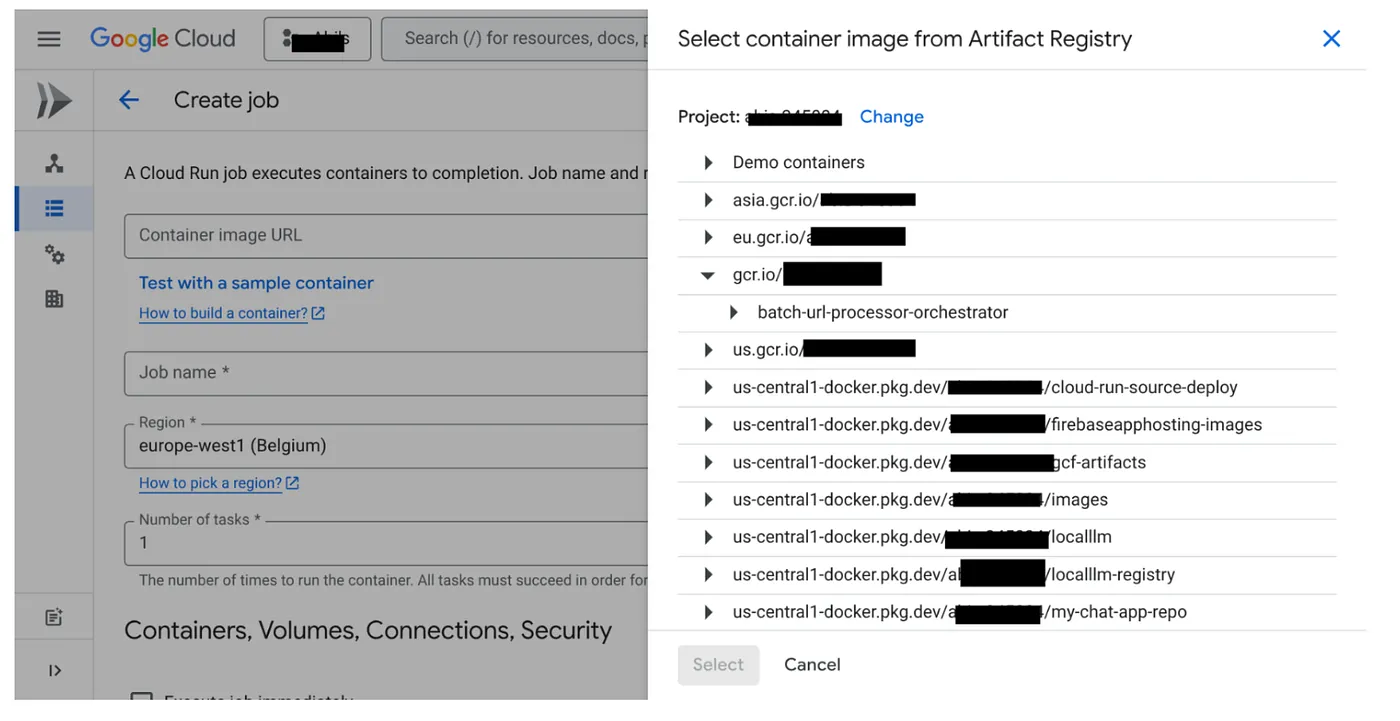
- Ingresa otros detalles de configuración de la siguiente manera:

- Establece la capacidad de la tarea de la siguiente manera:
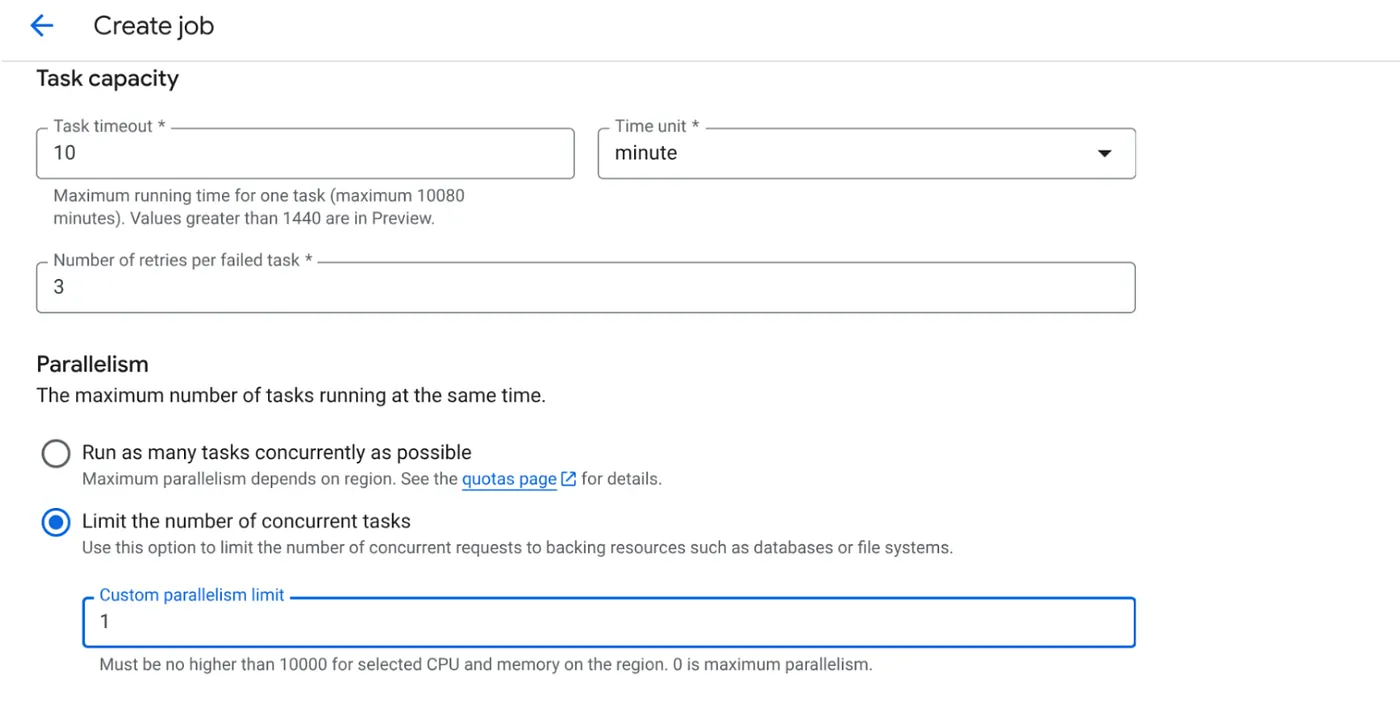
Como tenemos escrituras en la base de datos y la paralelización (max_instances y concurrencia de tareas) ya se controla en el código, estableceremos la cantidad de tareas simultáneas en 1. Sin embargo, puedes aumentarlo según tus requisitos. El objetivo aquí es que las tareas se ejecuten hasta completarse según la configuración con el nivel de simultaneidad establecido en el paralelismo.
- Haz clic en Crear
Tu trabajo de Cloud Run se creará correctamente.
Cómo funciona
Se inicia una instancia de contenedor de nuestro trabajo. Consulta BigQuery para obtener un lote pequeño (BATCH_SIZE) de URLs marcadas como PENDING. Actualiza de inmediato el estado de estas URLs recuperadas a PROCESSING en BigQuery para evitar que otras instancias de trabajo las seleccionen. Crea un ThreadPoolExecutor y envía una tarea para cada URL del lote. Cada tarea llama a la función call_url_processor_service. A medida que se completan las solicitudes de call_url_processor_service (o se agotan los tiempos de espera o fallan), se recopilan sus resultados (ya sea el contexto generado por IA o un mensaje de error) y se vuelven a asignar al row_id original. Una vez que se completan todas las tareas del lote, el trabajo itera los resultados recopilados y actualiza los campos de contexto y estado de cada fila correspondiente en BigQuery. Si la operación se realiza correctamente, la instancia del trabajo se cierra correctamente. Si encuentra errores no controlados, genera una excepción, lo que podría activar un reintento por parte de Cloud Run Jobs (según la configuración del trabajo).
Cómo se ajustan los trabajos de Cloud Run: organización
Aquí es donde los trabajos de Cloud Run realmente brillan.
Procesamiento por lotes sin servidores: Obtenemos una infraestructura administrada que puede iniciar tantas instancias de contenedor como sean necesarias (hasta MAX_INSTANCES) para procesar nuestros datos de forma simultánea.
Control de paralelismo: Definimos MAX_INSTANCES (cuántos trabajos pueden ejecutarse en paralelo en general) y TASK_CONCURRENCY (cuántas operaciones realiza cada instancia de trabajo en paralelo). Esto proporciona un control detallado sobre el rendimiento y el uso de recursos.
Tolerancia a errores: Si una instancia de trabajo falla a mitad de camino, los trabajos de Cloud Run se pueden configurar para que reintenten todo el trabajo o tareas específicas, lo que garantiza que no se pierda el procesamiento de datos.
Arquitectura simplificada: Al coordinar las llamadas HTTP directamente dentro del trabajo y usar BigQuery para la administración del estado, evitamos la complejidad de configurar y administrar Pub/Sub, sus temas, suscripciones y lógica de confirmación.
MAX_INSTANCES vs. TASK_CONCURRENCY:
MAX_INSTANCES: Es la cantidad total de instancias de trabajo que se pueden ejecutar de forma simultánea en toda la ejecución del trabajo. Esta es tu principal palanca de paralelismo para procesar muchas URLs a la vez.
TASK_CONCURRENCY: Es la cantidad de operaciones paralelas (llamadas a tu servicio de procesador) que realizará una sola instancia de tu trabajo. Esto ayuda a saturar la CPU o la red de una instancia.
9. Ejecuta y supervisa el trabajo de Cloud Run
Metadatos de video
Antes de hacer clic en Ejecutar, veamos el estado de los datos.
Ve a BigQuery Studio y ejecuta la siguiente consulta:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
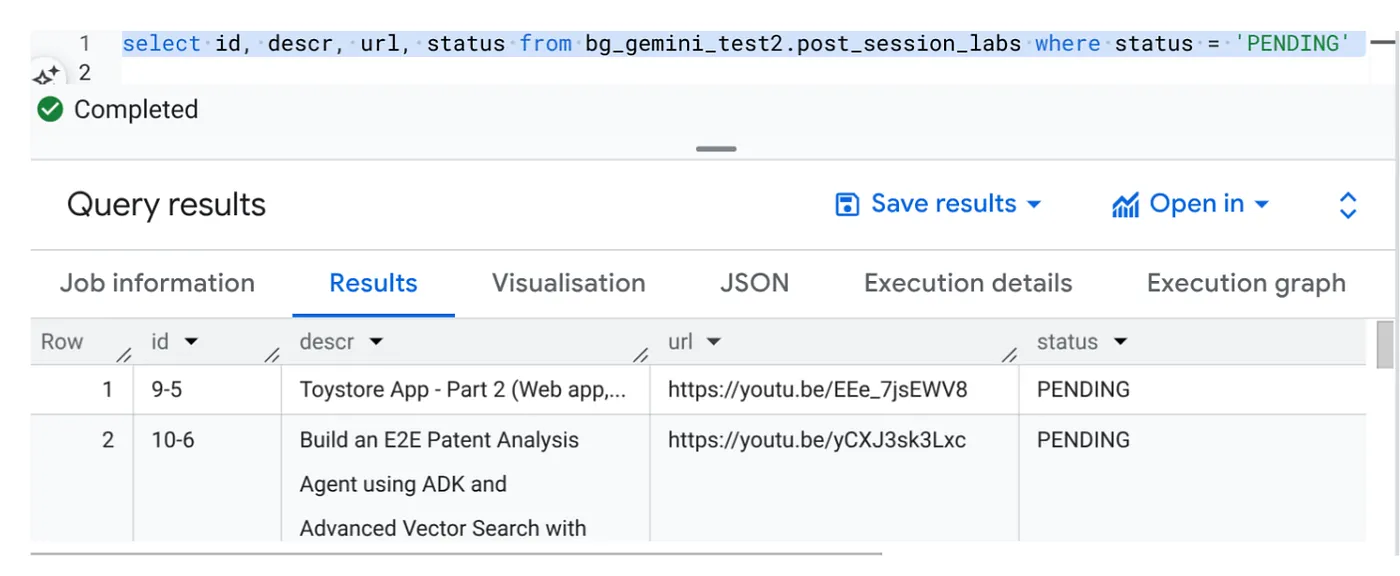
Tenemos algunos registros de muestra con URLs de videos y el estado PENDING. Nuestro objetivo es completar el campo "contexto" con estadísticas del video en el formato que se explica en la instrucción.
Activador de trabajo
Haz clic en el botón EJECUTAR del trabajo en la consola de Cloud Run Jobs para ejecutar el trabajo. Deberías poder ver el progreso y el estado de los trabajos en la consola:
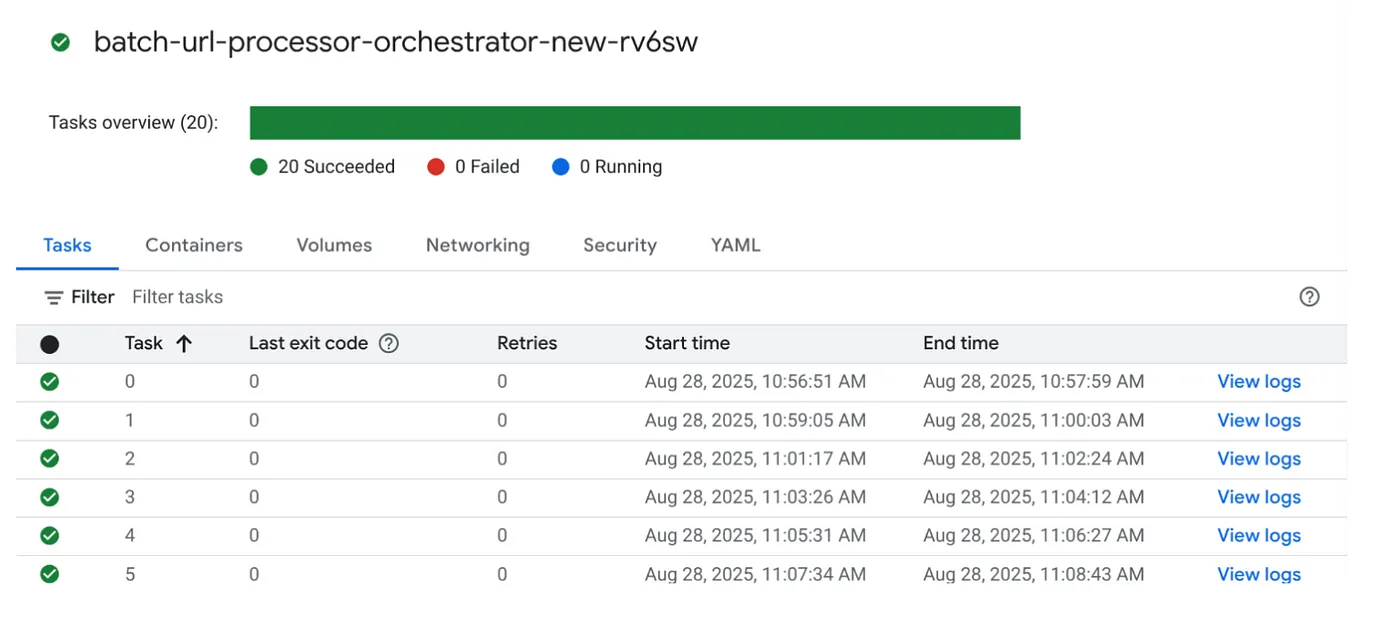
Puedes consultar la etiqueta LOGS en OBSERVABILITY para ver los pasos de supervisión y otros detalles sobre el trabajo y las tareas.
10. Análisis de resultados
Una vez que se complete el trabajo, deberías poder ver el contexto de cada URL de video actualizado en la tabla:
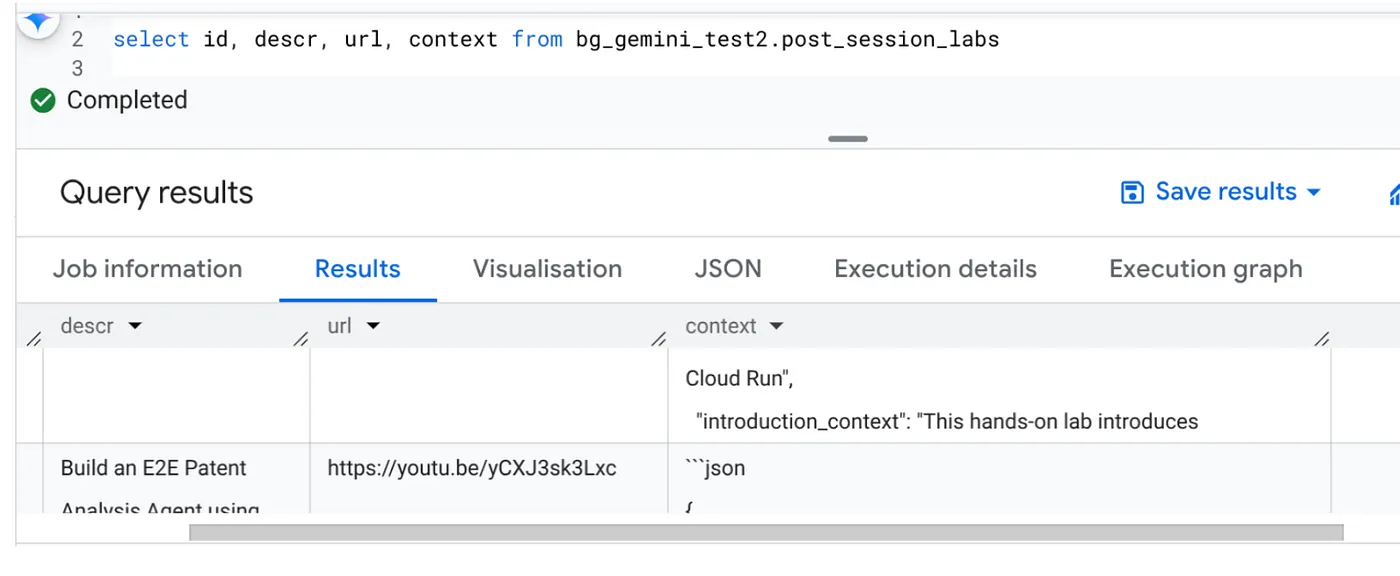
Contexto de salida (para uno de los registros)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Ahora deberías poder validar esta estructura JSON para casos de uso más avanzados de agentes.
¿Por qué se usa este enfoque?
Esta arquitectura proporciona importantes ventajas estratégicas:
- Rentabilidad: Los servicios sin servidores significan que solo pagas por lo que usas. Los trabajos de Cloud Run reducen su escala a cero cuando no se usan.
- Escalabilidad: Controla sin esfuerzo decenas de miles de URLs ajustando la configuración de simultaneidad y de instancias de trabajos de Cloud Run.
- Agilidad: Ciclos rápidos de desarrollo e implementación para la nueva lógica de procesamiento o los modelos de IA con solo actualizar la aplicación contenida y su servicio
- Reducción de la sobrecarga operativa: No hay servidores para aplicar parches ni administrar; Google se encarga de la infraestructura.
- Democratización de la IA: Permite que el procesamiento avanzado de IA sea accesible para las tareas por lotes sin necesidad de tener experiencia en ML Ops.
11. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a la página del administrador de recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
12. ¡Felicitaciones!
¡Felicitaciones! Al diseñar nuestra solución en torno a los trabajos de Cloud Run y aprovechar la potencia de BigQuery para la administración de datos y un servicio externo de Cloud Run para el procesamiento de IA, creaste un sistema altamente escalable, rentable y fácil de mantener. Este patrón desacopla la lógica de procesamiento, permite la ejecución paralela sin infraestructura compleja y acelera significativamente el tiempo de obtención de estadísticas.
Te recomendamos que explores los trabajos de Cloud Run para tus propias necesidades de procesamiento por lotes. Ya sea que se trate de escalar el análisis de IA, ejecutar canalizaciones de ETL o realizar tareas de datos periódicas, este enfoque sin servidores ofrece una solución potente y eficiente. Para comenzar por tu cuenta, consulta este artículo.
Si te interesa crear e implementar todas tus apps de forma agentiva y sin servidores, regístrate en Code Vipassana, que se enfoca en acelerar las aplicaciones agentivas generativas basadas en datos.