
۱. مرور کلی
در دنیای غنی از دادههای امروزی، استخراج بینشهای معنادار از محتوای بدون ساختار، به ویژه ویدیو، یک ضرورت مهم است. تصور کنید که نیاز به تجزیه و تحلیل صدها یا هزاران URL ویدیو، خلاصه کردن محتوای آنها، استخراج فناوریهای کلیدی و حتی ایجاد جفتهای پرسش و پاسخ برای مطالب آموزشی دارید. انجام این کارها به صورت تک تک نه تنها زمانبر است، بلکه ناکارآمد نیز میباشد. اینجاست که معماریهای ابری مدرن میدرخشند.
در این آزمایش، ما با استفاده از مجموعه قدرتمند سرویسهای گوگل کلود، یعنی Cloud Run، BigQuery و Generative AI گوگل (Gemini)، به بررسی راهکار مقیاسپذیر و بدون سرور برای پردازش محتوای ویدیویی خواهیم پرداخت. ما سفر خود را از پردازش یک URL واحد تا هماهنگسازی اجرای موازی در یک مجموعه داده بزرگ، بدون سربار مدیریت صفهای پیچیده پیامرسانی و ادغامها، به تفصیل شرح خواهیم داد.
چالش
وظیفه ما پردازش مجموعهای بزرگ از محتوای ویدیویی، به ویژه با تمرکز بر جلسات آزمایشگاهی عملی بود. هدف، تجزیه و تحلیل هر ویدیو و تولید خلاصهای ساختارمند، شامل عناوین فصلها، مقدمه، دستورالعملهای گام به گام، فناوریهای مورد استفاده و پرسش و پاسخهای مرتبط بود. این خروجی باید به طور کارآمد برای استفادههای بعدی در ساخت مواد آموزشی ذخیره میشد.
در ابتدا، ما یک سرویس Cloud Run ساده مبتنی بر HTTP داشتیم که میتوانست یک URL را در یک زمان پردازش کند. این سرویس برای آزمایش و تحلیلهای موردی به خوبی کار میکرد. با این حال، وقتی با لیستی از هزاران URL که از BigQuery تهیه شده بودند مواجه شدیم، محدودیتهای این مدل تک درخواست-تک پاسخ آشکار شد. پردازش متوالی روزها، اگر نگوییم هفتهها، طول میکشید.
این فرصت ، تبدیل یک فرآیند دستی یا متوالی کند به یک گردش کار خودکار و موازی بود. با بهرهگیری از فضای ابری، هدف ما این بود که:
- پردازش دادهها به صورت موازی: کاهش قابل توجه زمان پردازش برای مجموعه دادههای بزرگ.
- از قابلیتهای موجود هوش مصنوعی بهره ببرید: از قدرت Gemini برای تحلیل محتوای پیچیده استفاده کنید.
- معماری بدون سرور را حفظ کنید: از مدیریت سرورها یا زیرساختهای پیچیده خودداری کنید.
- متمرکزسازی دادهها: از BigQuery به عنوان تنها منبع معتبر برای URLهای ورودی و یک مقصد قابل اعتماد برای نتایج پردازششده استفاده کنید.
- ساخت یک خط لوله قوی: سیستمی ایجاد کنید که در برابر خرابیها مقاوم باشد و به راحتی قابل مدیریت و نظارت باشد.
هدف
هماهنگسازی پردازش موازی هوش مصنوعی با مشاغل ابری:
راهکار ما حول یک Cloud Run Job میچرخد که به عنوان یک هماهنگکننده عمل میکند. این سرویس به طور هوشمندانه دستههایی از URLها را از BigQuery میخواند، این URLها را به سرویس Cloud Run موجود و مستقر ما (که پردازش هوش مصنوعی را برای یک URL واحد انجام میدهد) ارسال میکند و سپس نتایج را برای نوشتن مجدد در BigQuery جمعآوری میکند. این رویکرد به ما امکان میدهد:
- جداسازی هماهنگی از پردازش: وظیفه، گردش کار را مدیریت میکند، در حالی که سرویس جداگانه بر وظیفه هوش مصنوعی تمرکز دارد.
- از موازی بودن کار Cloud Run استفاده کنید: این کار میتواند چندین نمونه کانتینر را برای فراخوانی همزمان سرویس هوش مصنوعی، مقیاسپذیر کند.
- کاهش پیچیدگی: ما با مدیریت مستقیم فراخوانیهای همزمان HTTP توسط وظیفه، به موازیسازی دست مییابیم و معماری را ساده میکنیم.
مورد استفاده
بینشهای مبتنی بر هوش مصنوعی از ویدیوهای جلسه Code Vipassana
مورد استفاده خاص ما، تجزیه و تحلیل ویدیوهای جلسات Google Cloud از آزمایشگاههای عملی Code Vipassana بود. هدف، تولید خودکار مستندات ساختاریافته (طرح کلی فصلهای کتاب) بود، از جمله:
- عناوین فصلها: عناوین مختصر برای هر بخش ویدیویی
- مقدمه، زمینه: توضیح ارتباط ویدیو با یک مسیر یادگیری گستردهتر
- چه چیزی ساخته خواهد شد: وظیفه یا هدف اصلی جلسه
- فناوریهای مورد استفاده: فهرستی از سرویسهای ابری و سایر فناوریهای ذکر شده
- دستورالعملهای گام به گام: نحوه انجام کار، شامل قطعه کدها
- آدرسهای کد منبع/نسخه آزمایشی: لینکها در ویدیو ارائه شدهاند
- بخش پرسش و پاسخ: ایجاد پرسشها و پاسخهای مرتبط برای سنجش دانش.
جریان

جریان معماری
کلود ران چیست؟ مشاغل کلود ران کدامند؟
اجرای ابری
یک پلتفرم کاملاً مدیریتشده بدون سرور که به شما امکان اجرای کانتینرهای بدون وضعیت را میدهد. این پلتفرم برای سرویسهای وب، APIها و میکروسرویسهایی که میتوانند بهطور خودکار بر اساس درخواستهای ورودی مقیاسپذیر شوند، ایدهآل است. شما یک تصویر کانتینر ارائه میدهید و Cloud Run بقیه کارها را انجام میدهد - از استقرار و مقیاسپذیری گرفته تا مدیریت زیرساخت. این پلتفرم در مدیریت بارهای کاری همزمان و درخواست-پاسخ عالی است.
مشاغل ابری
پیشنهادی که مکمل سرویسهای Cloud Run است. Cloud Run Jobs برای وظایف پردازش دستهای طراحی شدهاند که باید تکمیل و سپس متوقف شوند. آنها برای پردازش دادهها، ETL، استنتاج دستهای یادگیری ماشین و هر وظیفهای که شامل پردازش یک مجموعه داده به جای ارائه درخواستهای زنده است، عالی هستند. یکی از ویژگیهای کلیدی آنها توانایی آنها در مقیاسبندی تعداد نمونههای کانتینر (وظایف) در حال اجرا به طور همزمان برای پردازش یک دسته از کارها است و میتوانند توسط منابع رویداد مختلف یا به صورت دستی فعال شوند.
تفاوت کلیدی
سرویسهای Cloud Run برای برنامههای کاربردی طولانیمدت و مبتنی بر درخواست هستند. کارهای Cloud Run برای پردازش دستهای محدود و وظیفهمحور هستند که تا زمان تکمیل اجرا میشوند.
آنچه خواهید ساخت
یک برنامه جستجوی خرده فروشی
به عنوان بخشی از این، شما:
- ایجاد یک مجموعه داده BigQuery، جدول و دریافت دادهها (کد فراداده Vipassana)
- ایجاد یک تابع پایتون کلود ران برای پیادهسازی قابلیت هوش مصنوعی مولد (تبدیل ویدیو به فصل کتاب با فرمت json)
- یک برنامه پایتون برای انتقال دادهها به هوش مصنوعی ایجاد کنید - از BigQuery بخوانید و Cloud Run Functions Endpoint را برای دریافت اطلاعات فراخوانی کنید و متن را در BigQuery بنویسید.
- ساخت و کانتینرایز کردن برنامه
- پیکربندی یک کار Cloud Run با این کانتینر
- اجرا و نظارت بر کار
- گزارش نتیجه
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: روی لینک کلیک کنید و API ها را فعال کنید.
به عنوان یک روش جایگزین، میتوانید از دستور gcloud برای این کار استفاده کنید. برای مشاهده دستورات و نحوه استفاده از gcloud به مستندات آن مراجعه کنید.
۳. راهاندازی پایگاه داده/انبار داده
بیگکوئری (BigQuery) به عنوان ستون فقرات خط لوله داده ما عمل میکرد. ماهیت بدون سرور و بسیار مقیاسپذیر آن، آن را برای ذخیره دادههای ورودی و همچنین نگهداری نتایج پردازششده ایدهآل میکند.
- ذخیرهسازی دادهها: BigQuery نقش انبار داده ما را ایفا میکرد. این انبار، فهرست URLهای ویدیو، وضعیت آنها (مثلاً در انتظار، در حال پردازش، تکمیلشده) و متن نهایی تولید شده را ذخیره میکند. این تنها منبع حقیقتی است که ویدیوها برای آن نیاز به پردازش دارند.
- مقصد: جایی است که بینشهای تولید شده توسط هوش مصنوعی در آن ذخیره میشوند و به راحتی برای برنامههای پاییندستی یا بررسی دستی قابل پرسوجو هستند. مجموعه دادههای ما شامل جزئیات جلسات ویدیویی، به ویژه از محتوای «فصلهای کدنویسی ویپاسانا» بود که اغلب شامل نمایشهای فنی دقیق است.
- جدول منبع: یک جدول BigQuery (مثلاً post_session_labs) حاوی رکوردهایی مانند:
- شناسه (id): یک شناسه منحصر به فرد برای هر جلسه/ردیف.
- url: آدرس اینترنتی ویدیو (مثلاً لینک یوتیوب یا لینک درایو قابل دسترسی).
- وضعیت: رشتهای که وضعیت پردازش را نشان میدهد (مثلاً، در حال انتظار، در حال پردازش، تکمیل شده، ناموفق در پردازش).
- context: یک فیلد رشتهای برای ذخیره خلاصه تولید شده توسط هوش مصنوعی.
- دریافت دادهها: در این سناریو، دادهها با استفاده از اسکریپتهای INSERT به BigQuery وارد میشدند. برای خط لوله ما، BigQuery نقطه شروع بود.
به کنسول BigQuery بروید، یک تب جدید باز کنید و دستورات SQL زیر را اجرا کنید:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
۴. دریافت دادهها
حالا وقت آن رسیده که یک جدول با دادههای مربوط به فروشگاه اضافه کنیم. به یک تب در BigQuery Studio بروید و دستورات SQL زیر را برای درج رکوردهای نمونه اجرا کنید:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
۵. ایجاد عملکرد بینش ویدیویی
ما باید یک تابع Cloud Run ایجاد و مستقر کنیم تا هسته اصلی عملکرد، یعنی ایجاد یک فصل کتاب ساختاریافته از URL ویدیو، را پیادهسازی کنیم. برای اینکه بتوانیم به عنوان یک ابزار مستقل در جعبه ابزار endpoint به این تابع دسترسی داشته باشیم، ما یک تابع Cloud Run ایجاد و مستقر کردهایم. همچنین میتوانید این تابع را به عنوان یک تابع جداگانه در برنامه پایتون واقعی برای کار Cloud Run بگنجانید:
- در کنسول گوگل کلود، به صفحه Cloud Run بروید
- روی نوشتن یک تابع کلیک کنید.
- در فیلد نام سرویس، نامی را برای توصیف عملکرد خود وارد کنید. نام سرویسها فقط باید با یک حرف شروع شوند و حداکثر شامل ۴۹ کاراکتر یا کمتر، شامل حروف، اعداد یا خط فاصله باشند. نام سرویسها نمیتوانند با خط فاصله تمام شوند و باید برای هر منطقه و پروژه منحصر به فرد باشند. نام سرویس بعداً قابل تغییر نیست و به صورت عمومی قابل مشاهده است. ( generate-video-insights **)**
- در لیست منطقه، از مقدار پیشفرض استفاده کنید، یا منطقهای را که میخواهید عملکرد خود را در آن مستقر کنید، انتخاب کنید. (us-central1 را انتخاب کنید)
- در لیست Runtime، از مقدار پیشفرض استفاده کنید یا یک نسخه runtime انتخاب کنید. (پایتون ۳.۱۱ را انتخاب کنید)
- در بخش احراز هویت، گزینه «اجازه دسترسی عمومی» را انتخاب کنید.
- روی دکمه "ایجاد" کلیک کنید
- تابع ایجاد شده و با قالب main.py و requirements.txt بارگذاری میشود.
- آن را با فایلهای main.py و requirements.txt از مخزن این پروژه جایگزین کنید.
نکته مهم: در فایل main.py، به یاد داشته باشید که <<YOUR_PROJECT_ID>> را با شناسه پروژه خود جایگزین کنید.
- نقطه پایانی را مستقر و ذخیره کنید تا بتوانید از آن در منبع خود برای کار Cloud Run استفاده کنید.
نقطه پایانی شما باید چیزی شبیه به این (یا چیزی شبیه به آن) باشد: https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
این قابلیت Cloud Run چیست؟
فلش Gemini 2.5 برای پردازش ویدیو
برای وظیفه اصلی درک و خلاصهسازی محتوای ویدیویی، ما از مدل Gemini 2.5 Flash گوگل استفاده کردیم. مدلهای Gemini، مدلهای هوش مصنوعی قدرتمند و چندوجهی هستند که قادر به درک و پردازش انواع مختلف ورودی، از جمله متن و با ادغامهای خاص، ویدیو، میباشند.
در تنظیمات ما، ما مستقیماً فایل ویدیویی را به Gemini ندادیم. در عوض، یک پیام متنی ارسال کردیم که شامل URL ویدیو بود و به Gemini دستور دادیم که چگونه محتوای (فرضی) یک ویدیو را در آن URL تجزیه و تحلیل کند. در حالی که Gemini 2.5 Flash قادر به ورودی چندوجهی است، این خط لوله خاص از یک پیام متنی استفاده کرد که ماهیت ویدیو را توصیف میکرد (یک جلسه آزمایشگاهی عملی) و یک خروجی JSON ساختاریافته درخواست کرد. این امر از استدلال پیشرفته و درک زبان طبیعی Gemini برای استنباط و ترکیب اطلاعات بر اساس متن پیام استفاده میکند.
راهنمای Gemini: هدایت هوش مصنوعی
یک اعلان خوشساخت برای مدلهای هوش مصنوعی بسیار مهم است. اعلان ما طوری طراحی شده بود که اطلاعات بسیار خاصی را استخراج کرده و آن را در قالب JSON ساختاردهی کند، که باعث میشود برنامه ما به راحتی آن را تجزیه و تحلیل کند.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
این درخواست بسیار خاص است و Gemini را راهنمایی میکند تا به نوعی به عنوان یک مربی عمل کند. درخواست یک رشته JSON، خروجی ساختار یافته و قابل خواندن توسط ماشین را تضمین میکند.
در اینجا کد مربوط به تجزیه و تحلیل ورودی ویدیو و بازگرداندن متن آن آمده است:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
این قطعه کد بالا عملکرد اصلی این مورد استفاده را نشان میدهد. این قطعه کد یک URL ویدیویی را دریافت میکند و از مدل Gemini از طریق کلاینت هوش مصنوعی Vertex برای تجزیه و تحلیل محتوای ویدیو و استخراج بینشهای مرتبط با هر اعلان استفاده میکند. سپس زمینه استخراج شده برای پردازش بیشتر بازگردانده میشود. این نشان دهنده یک عملیات همزمان است که در آن Cloud Run Job منتظر تکمیل سرویس میماند.
۶. توسعه اپلیکیشن پایپلاین (پایتون)
منطق خط لوله مرکزی ما در کد منبع برنامه قرار دارد که در یک کار اجرای ابری (Cloud Run Job) کانتینر میشود و کل اجرای موازی را هماهنگ میکند. در اینجا نگاهی به بخشهای کلیدی میاندازیم:
نقش هماهنگکننده در مدیریت گردش کار و تضمین یکپارچگی دادهها:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
این قطعه کد بالا با دریافت دستهای از URLهای ویدیو با وضعیت «در انتظار» از جدول منبع BigQuery آغاز میشود. سپس وضعیت این URLها را در BigQuery به «در حال پردازش» بهروزرسانی میکند و از پردازش تکراری جلوگیری میکند.
پردازش موازی با ThreadPoolExecutor و فراخوانی سرویس پردازنده:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
این بخش از کد، از ThreadPoolExecutor برای دستیابی به پردازش موازی URLهای ویدیوی واکشی شده استفاده میکند. برای هر URL، وظیفهای را برای فراخوانی سرویس Cloud Run (پردازنده URL) به صورت غیرهمزمان ارسال میکند. این امر به Cloud Run Job اجازه میدهد تا چندین ویدیو را به طور همزمان پردازش کند و عملکرد کلی خط لوله را افزایش دهد. این قطعه کد همچنین وقفهها و خطاهای احتمالی از سرویس پردازنده را مدیریت میکند.
خواندن و نوشتن از & به BigQuery
تعامل اصلی با BigQuery شامل دریافت URL های در انتظار و سپس بهروزرسانی آنها با نتایج پردازش شده است.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
نوشتن نتایج به BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
قطعه کدهای بالا بر تعامل دادهها بین Cloud Run Job و BigQuery تمرکز دارند. این قطعه کد، مجموعهای از URLهای ویدیویی «در انتظار» و شناسههای آنها را از جدول منبع بازیابی میکند. پس از پردازش URLها، این قطعه کد، نوشتن متن و وضعیت استخراجشده («COMPLETED» یا «FAILED_PROCESSING») را با استفاده از یک کوئری UPDATE به جدول BigQuery هدف نشان میدهد. این قطعه کد، حلقه پردازش دادهها را تکمیل میکند. همچنین شامل تابع کمکی update_bq_row است که نحوه تعریف پارامترهای دستور بهروزرسانی را نشان میدهد.
تنظیمات برنامه
این برنامه به صورت یک اسکریپت پایتون واحد ساختار یافته است که کانتینریزه خواهد شد. این برنامه از کتابخانههای کلاینت Google Cloud و functions-framework برای تعریف نقطه ورود خود استفاده میکند.
- وابستگیها: google-cloud-bigquery، درخواستها
- پیکربندی: تمام تنظیمات حیاتی (پروژه/مجموعه داده/جدول BigQuery، URL سرویس پردازشگر URL) از متغیرهای محیطی بارگذاری میشوند و برنامه را قابل حمل و ایمن میکنند.
- منطق اصلی: تابع process_batch_from_bq کل گردش کار را هماهنگ میکند.
- یکپارچهسازی سرویسهای خارجی: تابع call_url_processor_service ارتباط با سرویس جداگانه Cloud Run را مدیریت میکند.
- تعامل BigQuery: bq_client برای دریافت URLها و بهروزرسانی نتایج، با مدیریت صحیح پارامترها، استفاده میشود.
- موازیسازی: concurrent.futures.ThreadPoolExecutor فراخوانیهای همزمان به سرویس خارجی را مدیریت میکند.
- نقطه ورود: کد پایتون با نام main.py به عنوان نقطه ورود عمل میکند که پردازش دستهای را آغاز میکند.
حالا بیایید برنامه را راهاندازی کنیم:
- میتوانید با رفتن به ترمینال Cloud Shell خود و کلون کردن مخزن شروع کنید:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- به ویرایشگر Cloud Shell بروید ، جایی که میتوانید پوشه تازه ایجاد شده video-context-crj را مشاهده کنید.
- موارد زیر را حذف کنید زیرا این مراحل قبلاً در بخشهای قبلی انجام شدهاند:
- پوشه Cloud_Run_Function را حذف کنید
- به پوشه پروژه video-context-crj بروید و باید ساختار پروژه را ببینید:
۷. راهاندازی و کانتینرسازی داکرفایل
برای استقرار این منطق به عنوان یک کار ابری، باید آن را کانتینرایز کنیم. کانتینرایز کردن فرآیند بستهبندی کد برنامه، وابستگیهای آن و زمان اجرا در یک تصویر قابل حمل است.
مطمئن شوید که متغیرهای متغیر (متن پررنگ) را با مقادیر خود در Dockerfile جایگزین میکنید:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
قطعه کد Dockerfile بالا، ایمیج پایه را تعریف میکند، وابستگیها را نصب میکند، کد ما را کپی میکند و دستور اجرای برنامه ما را با استفاده از functions-framework با تابع هدف صحیح (process_batch_from_bq) تنظیم میکند. سپس این ایمیج به رجیستری Artifact منتقل میشود.
کانتینر کردن
برای کانتینرایز کردن آن، به ترمینال Cloud Shell بروید و دستورات زیر را اجرا کنید (به یاد داشته باشید که عبارت <<YOUR_PROJECT_ID>> را جایگزین کنید):
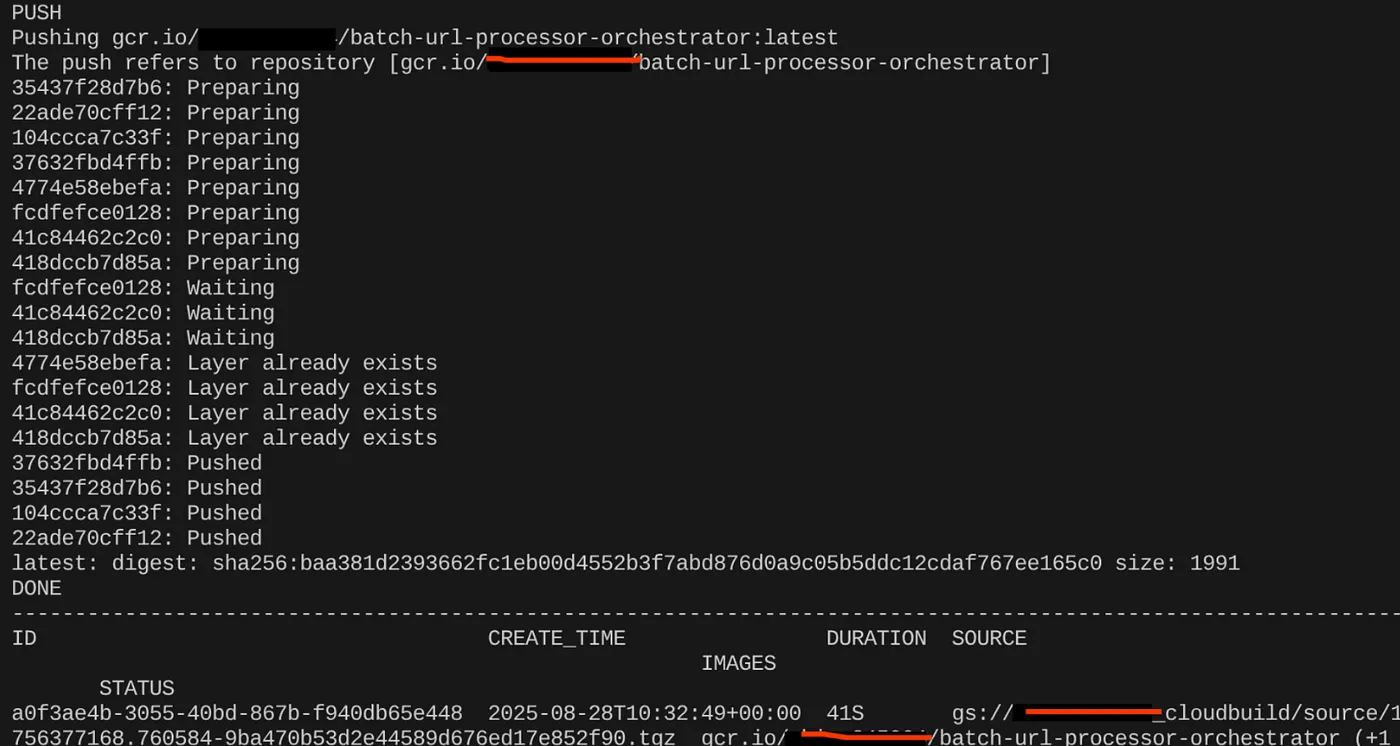
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
پس از ایجاد تصویر کانتینر، باید خروجی را مشاهده کنید:
اکنون کانتینر ما ایجاد و در رجیستری مصنوعات ذخیره شده است. میتوانیم به مرحله بعدی برویم.
۸. ایجاد مشاغل ابری
استقرار این کار شامل ساخت تصویر کانتینر و سپس ایجاد یک منبع Cloud Run Job است.
ما قبلاً تصویر کانتینر را ایجاد و در رجیستری مصنوعات ذخیره کردهایم. حالا بیایید کار را ایجاد کنیم.
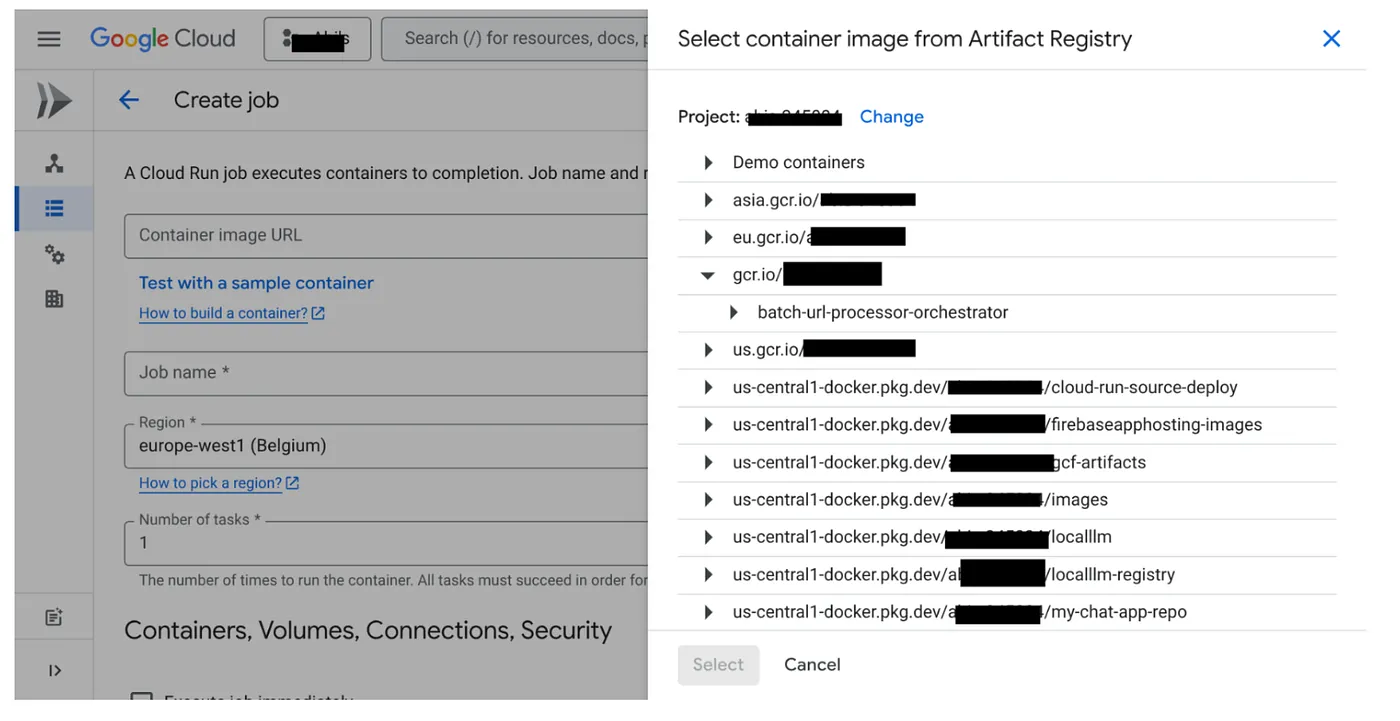
- به کنسول Cloud Run Jobs بروید و روی Deploy Container کلیک کنید:

- تصویر کانتینری که تازه ایجاد کردیم را انتخاب کنید:
- سایر جزئیات پیکربندی را به شرح زیر وارد کنید:

- ظرفیت وظیفه را به صورت زیر تنظیم کنید:
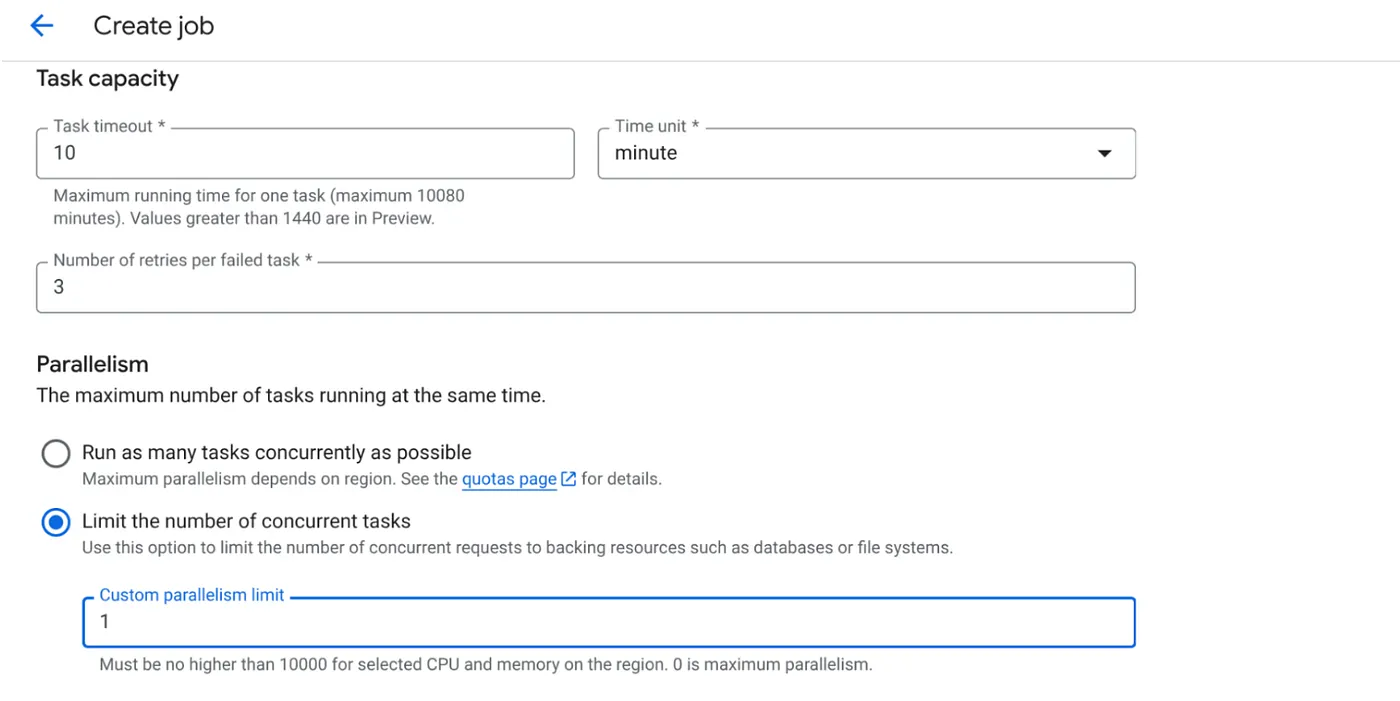
از آنجایی که ما نوشتن در پایگاه داده را داریم و این واقعیت که موازیسازی (max_instances و همزمانی وظایف) از قبل در کد مدیریت شده است، تعداد وظایف همزمان را روی ۱ تنظیم میکنیم. اما میتوانید آن را طبق نیاز خود افزایش دهید. هدف در اینجا این است که وظایف طبق پیکربندی با سطح همزمانی تنظیم شده در موازیسازی، تا زمان تکمیل اجرا شوند.
- روی ایجاد کلیک کنید
کار Cloud Run شما با موفقیت ایجاد خواهد شد.
چگونه کار میکند؟
یک نمونه کانتینر از کار ما شروع میشود. این کار از BigQuery درخواست میکند تا یک دسته کوچک (BATCH_SIZE) از URLهایی که به عنوان PENDING علامتگذاری شدهاند را دریافت کند. بلافاصله وضعیت این URLهای واکشی شده را در BigQuery به PROCESSING بهروزرسانی میکند تا از انتخاب آنها توسط سایر نمونههای کار جلوگیری کند. این کار یک ThreadPoolExecutor ایجاد میکند و برای هر URL در دسته، یک وظیفه ارسال میکند. هر وظیفه تابع call_url_processor_service را فراخوانی میکند. همانطور که call_url_processor_service درخواست تکمیل (یا اتمام زمان/شکست) را میدهد، نتایج آنها (یا زمینه تولید شده توسط هوش مصنوعی یا یک پیام خطا) جمعآوری شده و به row_id اصلی نگاشت میشوند. پس از اتمام تمام وظایف برای دسته، کار از طریق نتایج جمعآوری شده تکرار میشود و زمینه و فیلدهای وضعیت را برای هر ردیف مربوطه در BigQuery بهروزرسانی میکند. در صورت موفقیت، نمونه کار به طور کامل خارج میشود. اگر با خطاهای مدیریت نشده مواجه شود، یک استثنا ایجاد میکند که به طور بالقوه باعث تلاش مجدد توسط Cloud Run Jobs (بسته به پیکربندی کار) میشود.
چگونه مشاغل ابری در این حوزه قرار میگیرند: ارکستراسیون
اینجاست که Cloud Run Jobs واقعاً میدرخشد.
پردازش دستهای بدون سرور: ما زیرساخت مدیریتشدهای داریم که میتواند به تعداد مورد نیاز (تا MAX_INSTANCES) نمونه کانتینر ایجاد کند تا دادههای ما را به صورت همزمان پردازش کند.
کنترل موازیسازی: ما MAX_INSTANCES (تعداد کارهایی که میتوانند به صورت موازی اجرا شوند) و TASK_CONCURRENCY (تعداد عملیاتی که هر نمونه کار به صورت موازی انجام میدهد) را تعریف میکنیم. این امر کنترل دقیقی بر توان عملیاتی و میزان استفاده از منابع فراهم میکند.
تحمل خطا: اگر یک نمونه کار در میانه راه با شکست مواجه شود، میتوان Cloud Run Jobs را طوری پیکربندی کرد که کل کار یا وظایف خاص را دوباره امتحان کند و اطمینان حاصل شود که پردازش دادهها از دست نمیرود.
معماری سادهشده: با هماهنگسازی مستقیم فراخوانیهای HTTP درون Job و استفاده از BigQuery برای مدیریت وضعیت، از پیچیدگی راهاندازی و مدیریت Pub/Sub، موضوعات آن، اشتراکها و منطق تأیید جلوگیری میکنیم.
MAX_INSTANCES در مقابل TASK_CONCURRENCY:
MAX_INSTANCES: تعداد کل نمونههای کاری که میتوانند به طور همزمان در کل اجرای کار شما اجرا شوند. این اهرم موازیسازی اصلی شما برای پردازش همزمان بسیاری از URLها است.
TASK_CONCURRENCY: تعداد عملیات موازی (فراخوانیهای سرویس پردازنده شما) که یک نمونه از کار شما انجام خواهد داد. این به اشباع CPU/شبکه از یک نمونه کمک میکند.
۹. اجرا و نظارت بر کار Cloud Run
فراداده ویدئو
قبل از اینکه روی اجرا کلیک کنیم، بیایید وضعیت دادهها را مشاهده کنیم.
به BigQuery Studio بروید و کوئری زیر را اجرا کنید:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
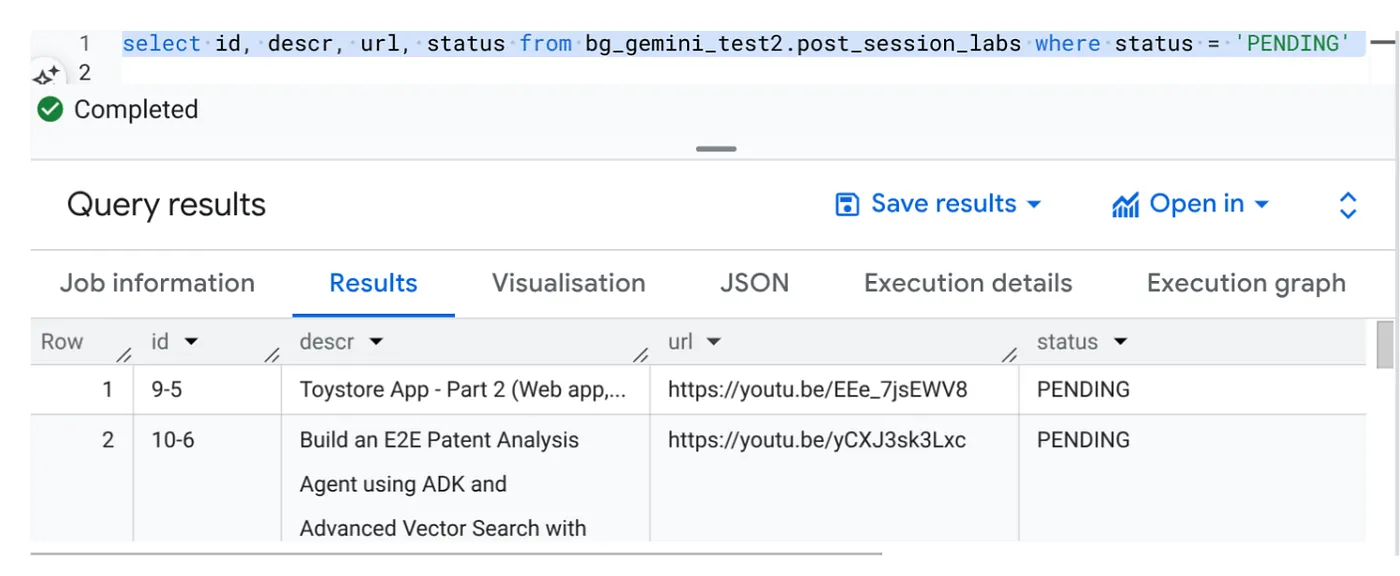
ما چند رکورد نمونه با URL های ویدیویی و در وضعیت PENDING داریم. هدف ما این است که فیلد "context" را با اطلاعاتی از ویدیو در قالبی که در اعلان توضیح داده شده است، پر کنیم.
محرک شغلی
بیایید با کلیک بر روی دکمه EXECUTE روی کار در کنسول Cloud Run Jobs، کار را اجرا کنیم و باید بتوانید پیشرفت و وضعیت کارها را در کنسول مشاهده کنید:
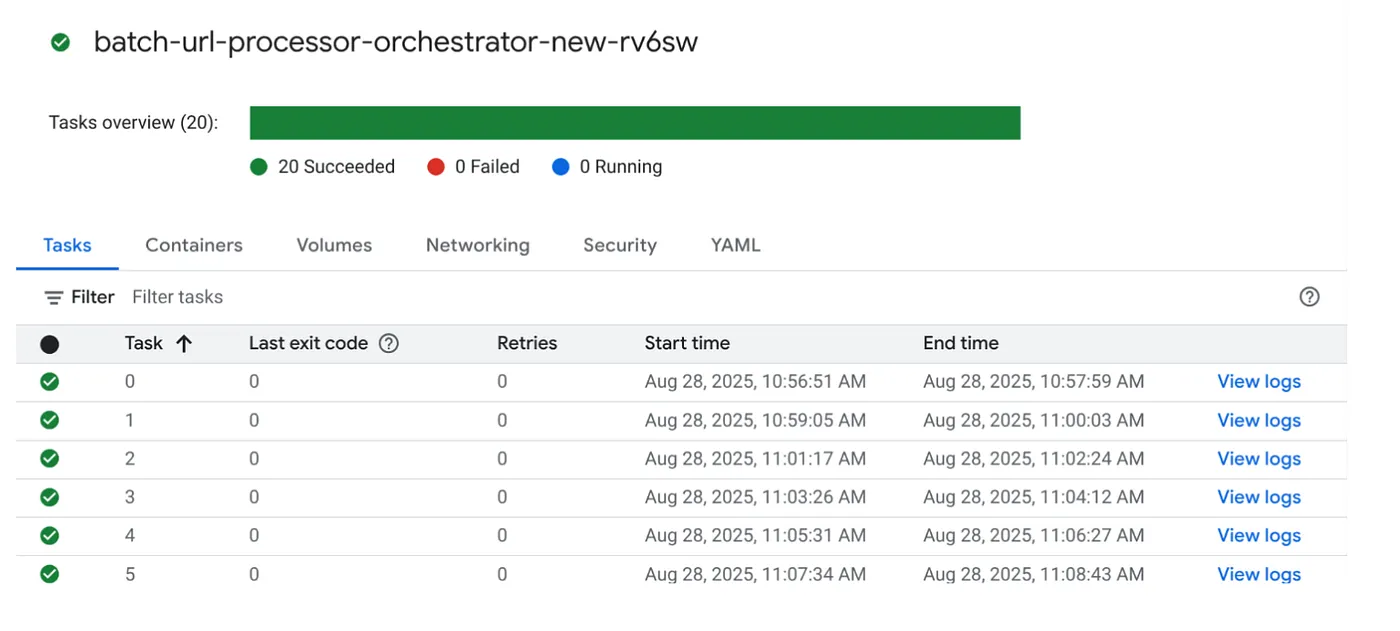
برای مشاهده مراحل نظارت و سایر جزئیات مربوط به کار و وظایف، میتوانید تگ LOGS را در OBSERVAILITY بررسی کنید.
۱۰. تحلیل نتایج
پس از اتمام کار، باید بتوانید متن مربوط به هر URL ویدیویی که بهروزرسانی شده است را در جدول مشاهده کنید:
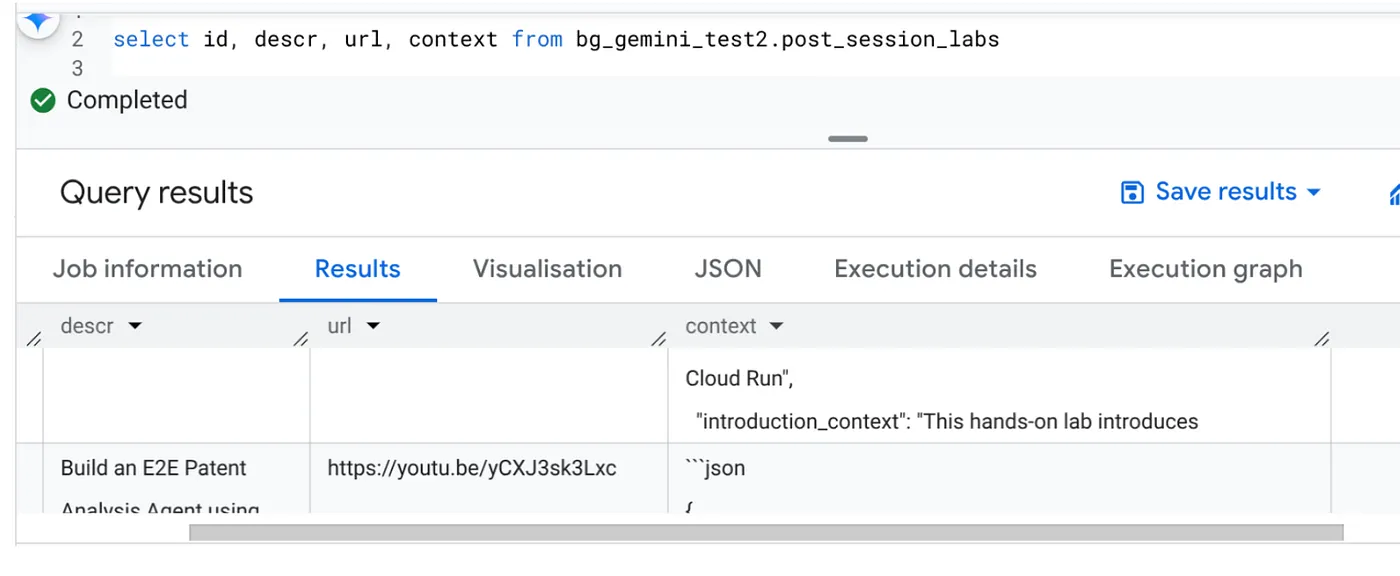
زمینه خروجی (برای یکی از رکوردها)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
اکنون باید بتوانید این ساختار JSON را برای موارد استفاده پیشرفتهتر عاملمحور اعتبارسنجی کنید.
چرا این رویکرد؟
این معماری مزایای استراتژیک قابل توجهی را ارائه میدهد:
- مقرون به صرفه بودن: سرویسهای بدون سرور به این معنی است که شما فقط برای آنچه استفاده میکنید هزینه پرداخت میکنید. پروژههای ابری در صورت عدم استفاده، مقیاسپذیری خود را به صفر میرسانند.
- مقیاسپذیری: با تنظیم نمونه Cloud Run Job و تنظیمات همزمانی، دهها هزار URL را به راحتی مدیریت میکند.
- چابکی: چرخههای توسعه و استقرار سریع برای منطق پردازش جدید یا مدلهای هوش مصنوعی، تنها با بهروزرسانی سادهی برنامهی کاربردی و سرویس آن.
- کاهش سربار عملیاتی: نیازی به وصله کردن یا مدیریت سرور نیست؛ گوگل زیرساخت را مدیریت میکند.
- دموکراتیزه کردن هوش مصنوعی: پردازش پیشرفته هوش مصنوعی را برای وظایف دستهای بدون تخصص عمیق در عملیات یادگیری ماشین در دسترس قرار میدهد.
۱۱. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
۱۲. تبریک
تبریک! با معماری راهکار ما پیرامون Cloud Run Jobs و بهرهگیری از قدرت BigQuery برای مدیریت دادهها و یک Cloud Run Service خارجی برای پردازش هوش مصنوعی، شما یک سیستم بسیار مقیاسپذیر، مقرونبهصرفه و قابل نگهداری ساختهاید. این الگو منطق پردازش را از هم جدا میکند، امکان اجرای موازی را بدون زیرساخت پیچیده فراهم میکند و زمان رسیدن به بینش را به طور قابل توجهی تسریع میکند.
ما شما را تشویق میکنیم که برای نیازهای پردازش دستهای خود، Cloud Run Jobs را بررسی کنید. چه تجزیه و تحلیل هوش مصنوعی در مقیاس بزرگ باشد، چه اجرای خطوط لوله ETL یا انجام وظایف دادهای دورهای، این رویکرد بدون سرور، یک راهحل قدرتمند و کارآمد ارائه میدهد. برای شروع کار خودتان، این را بررسی کنید .
اگر کنجکاو هستید که تمام برنامههای خود را به صورت بدون سرور و عاملدار بسازید و مستقر کنید، در Code Vipassana ثبت نام کنید که بر تسریع برنامههای عاملدار مولد مبتنی بر داده متمرکز است!