
1. Présentation
Dans le monde actuel, où les données sont omniprésentes, il est essentiel d'extraire des insights utiles à partir de contenus non structurés, en particulier des vidéos. Imaginez que vous deviez analyser des centaines ou des milliers d'URL de vidéos, résumer leur contenu, extraire les technologies clés et même générer des paires de questions/réponses pour des supports pédagogiques. Effectuer cette opération une par une est non seulement chronophage, mais aussi inefficace. C'est là que les architectures cloud modernes excellent.
Dans cet atelier, nous allons vous présenter une solution évolutive et sans serveur pour traiter du contenu vidéo à l'aide de la puissante suite de services Google Cloud : Cloud Run, BigQuery et l'IA générative de Google (Gemini). Nous vous expliquerons comment nous sommes passés du traitement d'une seule URL à l'orchestration de l'exécution parallèle sur un grand ensemble de données, le tout sans la surcharge liée à la gestion de files d'attente et d'intégrations de messages complexes.
Le défi
Nous avons été chargés de traiter un vaste catalogue de contenus vidéo, en nous concentrant plus particulièrement sur les ateliers pratiques. L'objectif était d'analyser chaque vidéo et de générer un résumé structuré, y compris les titres des chapitres, le contexte de l'introduction, les instructions détaillées, les technologies utilisées et les paires de questions/réponses pertinentes. Cette sortie devait être stockée efficacement pour être utilisée ultérieurement dans la création de supports pédagogiques.
Au départ, nous avions un simple service Cloud Run basé sur HTTP, capable de traiter une URL à la fois. Cette méthode fonctionnait bien pour les tests et les analyses ponctuelles. Toutefois, face à une liste de milliers d'URL provenant de BigQuery, les limites de ce modèle à requête unique et réponse unique sont devenues évidentes. Le traitement séquentiel prendrait des jours, voire des semaines.
L'opportunité consistait à transformer un processus séquentiel manuel ou lent en un workflow automatisé et parallélisé. En exploitant le cloud, nous avons cherché à :
- Traitez les données en parallèle : réduisez considérablement le temps de traitement des grands ensembles de données.
- Exploitez les fonctionnalités d'IA existantes : utilisez la puissance de Gemini pour analyser le contenu de manière sophistiquée.
- Maintenir une architecture sans serveur : évitez de gérer des serveurs ou une infrastructure complexe.
- Centralisez les données : utilisez BigQuery comme source unique de référence pour les URL d'entrée et comme destination fiable pour les résultats traités.
- Créez un pipeline robuste : mettez en place un système résistant aux échecs, facile à gérer et à surveiller.
Objectif
Orchestrer le traitement parallèle de l'IA avec les jobs Cloud Run :
Notre solution repose sur un job Cloud Run qui sert d'orchestrateur. Il lit intelligemment des lots d'URL depuis BigQuery, les envoie à notre service Cloud Run déployé existant (qui gère le traitement de l'IA pour une seule URL), puis agrège les résultats pour les réécrire dans BigQuery. Cette approche nous permet :
- Dissociez l'orchestration du traitement : le job gère le workflow, tandis que le service distinct se concentre sur la tâche d'IA.
- Exploitez le parallélisme de Cloud Run Jobs : le job peut faire évoluer plusieurs instances de conteneur pour appeler le service d'IA simultanément.
- Réduction de la complexité : nous obtenons le parallélisme en faisant en sorte que le job gère directement les appels HTTP simultanés, ce qui simplifie l'architecture.
Cas d'utilisation
Insights optimisés par l'IA à partir des vidéos des sessions Code Vipassana
Notre cas d'utilisation spécifique consistait à analyser des vidéos de sessions Google Cloud d'ateliers pratiques Code Vipassana. L'objectif était de générer automatiquement une documentation structurée (plans de chapitres de livres), y compris :
- Titres des chapitres : titres concis pour chaque segment vidéo
- Contexte de l'introduction : expliquer la pertinence de la vidéo dans un parcours de formation plus large
- Ce qui sera créé : la tâche ou l'objectif principal de la session
- Technologies utilisées : liste des services cloud et autres technologies mentionnés
- Instructions détaillées : comment la tâche a été effectuée, y compris les extraits de code
- URL du code source/de la démo : liens fournis dans la vidéo
- Section Questions/Réponses : générer des questions et des réponses pertinentes pour les contrôles des connaissances.
Flow

Flux de l'architecture
Qu'est-ce que Cloud Run ? Que sont les tâches Cloud Run ?
Cloud Run
Une plate-forme sans serveur entièrement gérée qui vous permet d'exécuter des conteneurs sans état. Il est idéal pour les services Web, les API et les microservices qui peuvent évoluer automatiquement en fonction des requêtes entrantes. Vous fournissez une image de conteneur, et Cloud Run s'occupe du reste : déploiement, mise à l'échelle et gestion de l'infrastructure. Il excelle dans la gestion des charges de travail synchrones de type requête-réponse.
Tâches Cloud Run
Offre complémentaire aux services Cloud Run. Les jobs Cloud Run sont conçus pour les tâches de traitement par lot qui doivent être terminées, puis arrêtées. Ils sont parfaits pour le traitement des données, l'ETL, l'inférence par lot de machine learning et toute tâche impliquant le traitement d'un ensemble de données plutôt que le traitement de requêtes en direct. Une fonctionnalité clé est leur capacité à faire évoluer le nombre d'instances de conteneur (tâches) exécutées simultanément pour traiter un lot de tâches. Elles peuvent être déclenchées par différentes sources d'événements ou manuellement.
Différence principale
Les services Cloud Run sont destinés aux applications de longue durée basées sur des requêtes. Les jobs Cloud Run sont destinés au traitement par lot fini et axé sur les tâches, qui s'exécute jusqu'à la fin.
Ce que vous allez faire
Application Retail Search
Dans ce cadre, vous allez :
- Créer un ensemble de données et une table BigQuery, et ingérer des données (métadonnées Code Vipassana)
- Créez une fonction Python Cloud Run pour implémenter la fonctionnalité d'IA générative (conversion de la vidéo en fichier JSON de chapitre de livre).
- Créer une application Python pour le pipeline de données vers l'IA : lire les données depuis BigQuery, appeler le point de terminaison des fonctions Cloud Run pour obtenir des insights et réécrire le contexte dans BigQuery
- Compiler et conteneuriser l'application
- Configurer un job Cloud Run avec ce conteneur
- Exécuter et surveiller le job
- Résultat du rapport
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : suivez ce lien et activez les API.
Vous pouvez également utiliser la commande gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
3. Configuration de la base de données/de l'entrepôt
BigQuery a servi de base à notre pipeline de données. Son caractère sans serveur et hautement évolutif le rend idéal pour stocker nos données d'entrée et héberger les résultats traités.
- Stockage des données : BigQuery servait d'entrepôt de données. Elle stocke la liste des URL des vidéos, leur état (par exemple, "EN ATTENTE", "EN COURS DE TRAITEMENT", "TERMINÉ") et le contexte final généré. Il s'agit de la seule source d'informations indiquant les vidéos qui doivent être traitées.
- Destination : il s'agit de l'endroit où les insights générés par l'IA sont conservés, ce qui permet de les interroger facilement pour les applications en aval ou pour un examen manuel. Notre ensemble de données était constitué de détails sur les sessions vidéo, en particulier sur le contenu "Code Vipassana Seasons", qui implique souvent des démonstrations techniques détaillées.
- Table source : table BigQuery (par exemple, post_session_labs) contenant des enregistrements tels que :
- id : identifiant unique pour chaque session/ligne.
- url : URL de la vidéo (par exemple, un lien YouTube ou un lien Drive accessible).
- status : chaîne indiquant l'état du traitement (par exemple, "PENDING", "PROCESSING", "COMPLETED" ou "FAILED_PROCESSING").
- context : champ de chaîne permettant de stocker le résumé généré par l'IA.
- Ingestion de données : dans ce scénario, les données ont été ingérées dans BigQuery à l'aide de scripts INSERT. Pour notre pipeline, BigQuery était le point de départ.
Accédez à la console BigQuery, ouvrez un nouvel onglet et exécutez les instructions SQL suivantes :
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. Ingestion de données
Il est maintenant temps d'ajouter un tableau contenant les données sur le magasin. Accédez à un onglet dans BigQuery Studio et exécutez les instructions SQL suivantes pour insérer les exemples d'enregistrements :
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. Création de la fonction Video Insights
Nous devons créer et déployer une fonction Cloud Run pour implémenter le cœur de la fonctionnalité, qui consiste à créer un chapitre de livre structuré à partir de l'URL d'une vidéo. Pour pouvoir y accéder en tant qu'outil de boîte à outils de point de terminaison indépendant, nous venons de créer et de déployer une fonction Cloud Run. Vous pouvez également choisir d'inclure cette fonction séparément dans l'application Python réelle pour le job Cloud Run :
- Dans la console Google Cloud, accédez à la page Cloud Run.
- Cliquez sur "Écrire une fonction".
- Dans le champ "Nom du service", saisissez un nom pour décrire votre fonction. Les noms de service doivent commencer par une lettre et comporter 49 caractères au maximum (lettres, chiffres ou traits d'union). Les noms de service ne peuvent pas se terminer par un tiret et doivent être uniques par région et par projet. Un nom de service ne peut pas être modifié ultérieurement et il est visible publiquement. ( generate-video-insights**)**
- Dans la liste "Région", utilisez la valeur par défaut ou sélectionnez la région dans laquelle vous souhaitez déployer votre fonction. (Choisissez us-central1)
- Dans la liste "Runtime", utilisez la valeur par défaut ou sélectionnez une version du runtime. (Choisissez Python 3.11)
- Dans la section "Authentification", sélectionnez "Autoriser l'accès public".
- Cliquez sur le bouton "Créer".
- La fonction est créée et chargée avec un fichier main.py et requirements.txt de modèle.
- Remplacez-le par les fichiers main.py et requirements.txt du dépôt de ce projet.
IMPORTANT : Dans main.py, n'oubliez pas de remplacer <<YOUR_PROJECT_ID>> par l'ID de votre projet.
- Déployez et enregistrez le point de terminaison pour pouvoir l'utiliser dans votre source pour le job Cloud Run.
Votre point de terminaison doit ressembler à ceci (ou à quelque chose de similaire) : https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
Que contient cette fonction Cloud Run ?
Gemini 2.5 Flash pour le traitement vidéo
Pour la tâche principale de compréhension et de synthèse du contenu vidéo, nous avons utilisé le modèle Gemini 2.5 Flash de Google. Les modèles Gemini sont des modèles d'IA multimodaux et puissants, capables de comprendre et de traiter différents types d'entrées, y compris du texte et, avec des intégrations spécifiques, des vidéos.
Dans notre configuration, nous n'avons pas directement fourni le fichier vidéo à Gemini. Nous avons plutôt envoyé une requête textuelle incluant l'URL de la vidéo et demandé à Gemini d'analyser le contenu (hypothétique) de la vidéo à cette URL. Bien que Gemini 2.5 Flash soit capable de traiter des entrées multimodales, ce pipeline spécifique utilisait une invite textuelle décrivant la nature de la vidéo (une session d'atelier pratique) et demandant une sortie JSON structurée. Cette fonctionnalité s'appuie sur les capacités avancées de raisonnement et de compréhension du langage naturel de Gemini pour déduire et synthétiser des informations en fonction du contexte de la requête.
Le prompt Gemini : guider l'IA
Une requête bien formulée est essentielle pour les modèles d'IA. Notre requête a été conçue pour extraire des informations très spécifiques et les structurer au format JSON, ce qui permet à notre application de les analyser facilement.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
Ce prompt est très spécifique et demande à Gemini d'agir comme un enseignant. La demande d'une chaîne JSON garantit une sortie structurée et lisible par une machine.
Voici le code permettant d'analyser l'entrée vidéo et de renvoyer son contexte :
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
L'extrait ci-dessus illustre la fonction principale du cas d'utilisation. Il reçoit une URL vidéo et utilise le modèle Gemini via le client Vertex AI pour analyser le contenu vidéo et extraire les insights pertinents selon la requête. Le contexte extrait est ensuite renvoyé pour un traitement ultérieur. Il s'agit d'une opération synchrone dans laquelle le job Cloud Run attend la fin du service.
6. Développement d'applications de pipeline (Python)
La logique de pipeline central réside dans le code source de l'application, qui sera conteneurisé dans un job Cloud Run, lequel orchestre l'ensemble de l'exécution parallèle. Voici les principaux éléments :
Rôle de l'orchestrateur dans la gestion du workflow et la garantie de l'intégrité des données :
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
L'extrait ci-dessus commence par récupérer un lot d'URL de vidéos dont l'état est "EN ATTENTE" à partir de la table source BigQuery. Il met ensuite à jour l'état de ces URL sur "PROCESSING" (EN COURS DE TRAITEMENT) dans BigQuery, ce qui évite le traitement en double.
Traitement parallèle avec ThreadPoolExecutor et appel du service de traitement :
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
Cette partie du code utilise ThreadPoolExecutor pour traiter en parallèle les URL de vidéos récupérées. Pour chaque URL, elle envoie une tâche pour appeler le service Cloud Run (processeur d'URL) de manière asynchrone. Cela permet au job Cloud Run de traiter efficacement plusieurs vidéos simultanément, ce qui améliore les performances globales du pipeline. L'extrait gère également les éventuels délais d'attente et erreurs du service de traitement.
Lire et écrire des données depuis et vers BigQuery
L'interaction principale avec BigQuery consiste à récupérer les URL en attente, puis à les mettre à jour avec les résultats traités.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
Réécrire les résultats dans BigQuery :
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
Les extraits ci-dessus se concentrent sur l'interaction des données entre le job Cloud Run et BigQuery. Elle récupère un lot d'URL vidéo "EN ATTENTE" et leurs ID à partir de la table source. Une fois les URL traitées, cet extrait montre comment réécrire le contexte et l'état extraits ("COMPLETED" ou "FAILED_PROCESSING") dans la table BigQuery cible à l'aide d'une requête UPDATE. Cet extrait complète la boucle de traitement des données. Il inclut également la fonction d'assistance update_bq_row qui montre comment définir les paramètres de l'instruction de mise à jour.
Configuration de l'application
L'application est structurée sous la forme d'un script Python unique qui sera conteneurisé. Il utilise les bibliothèques clientes Google Cloud et le framework de fonctions pour définir son point d'entrée.
- Dépendances : google-cloud-bigquery, requests
- Configuration : tous les paramètres critiques (projet, ensemble de données et table BigQuery, URL du service de traitement des URL) sont chargés à partir des variables d'environnement, ce qui rend l'application portable et sécurisée.
- Logique principale : la fonction process_batch_from_bq orchestre l'ensemble du workflow.
- Intégration de services externes : la fonction call_url_processor_service gère la communication avec le service Cloud Run distinct.
- Interaction BigQuery : bq_client est utilisé pour extraire les URL et mettre à jour les résultats, avec une gestion appropriée des paramètres
- Parallélisme : concurrent.futures.ThreadPoolExecutor gère les appels simultanés au service externe.
- Point d'entrée : le code Python nommé main.py sert de point d'entrée pour lancer le traitement par lot.
Configurons maintenant l'application :
- Vous pouvez commencer par accéder à votre terminal Cloud Shell et cloner le dépôt :
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Accédez à l'éditeur Cloud Shell, où vous pouvez voir le dossier video-context-crj que vous venez de créer.
- Supprimez les éléments suivants, car ces étapes ont déjà été effectuées dans les sections précédentes :
- Supprimez le dossier Cloud_Run_Function.
- Accédez au dossier du projet video-context-crj. La structure du projet devrait s'afficher :
7. Configuration de Dockerfile et conteneurisation
Pour déployer cette logique en tant que job Cloud Run, nous devons la conteneuriser. La conteneurisation consiste à empaqueter le code de notre application, ses dépendances et son environnement d'exécution dans une image portable.
Veillez à remplacer les espaces réservés (texte en gras) par vos valeurs dans le fichier Dockerfile :
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
L'extrait de fichier Dockerfile ci-dessus définit l'image de base, installe les dépendances, copie notre code et définit la commande permettant d'exécuter notre application à l'aide du framework functions avec la fonction cible appropriée (process_batch_from_bq). Cette image est ensuite transférée vers Artifact Registry.
Conteneuriser
Pour le conteneuriser, accédez au terminal Cloud Shell et exécutez les commandes suivantes (n'oubliez pas de remplacer l'espace réservé <<YOUR_PROJECT_ID>>) :
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
Une fois l'image de conteneur créée, le résultat suivant doit s'afficher :
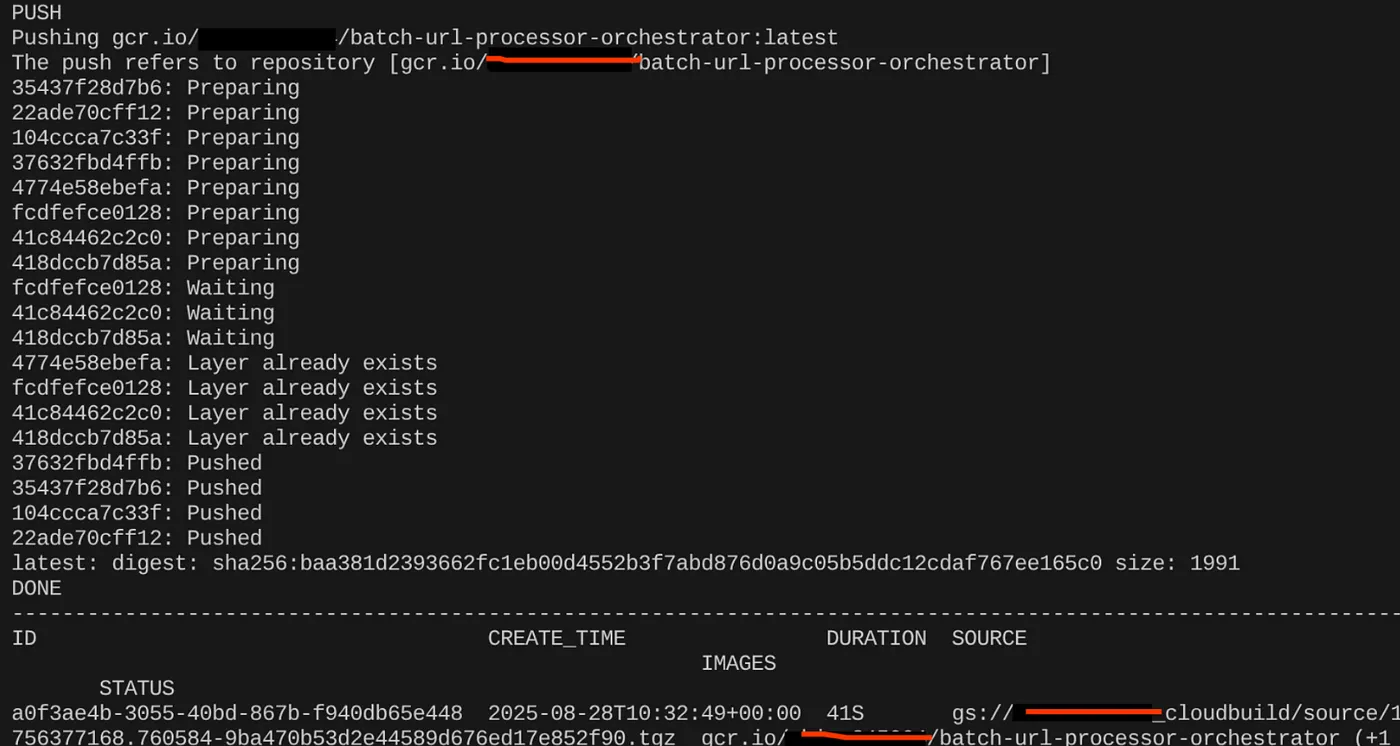
Notre conteneur est maintenant créé et enregistré dans Artifact Registry. Nous pouvons passer à l'étape suivante.
8. Création de jobs Cloud Run
Le déploiement du job implique la création de l'image de conteneur, puis la création d'une ressource Cloud Run Job.
Nous avons déjà créé l'image de conteneur et l'avons stockée dans Artifact Registry. Créons maintenant le job.
- Accédez à la console Cloud Run Jobs et cliquez sur "Déployer un conteneur" :

- Sélectionnez l'image de conteneur que nous venons de créer :
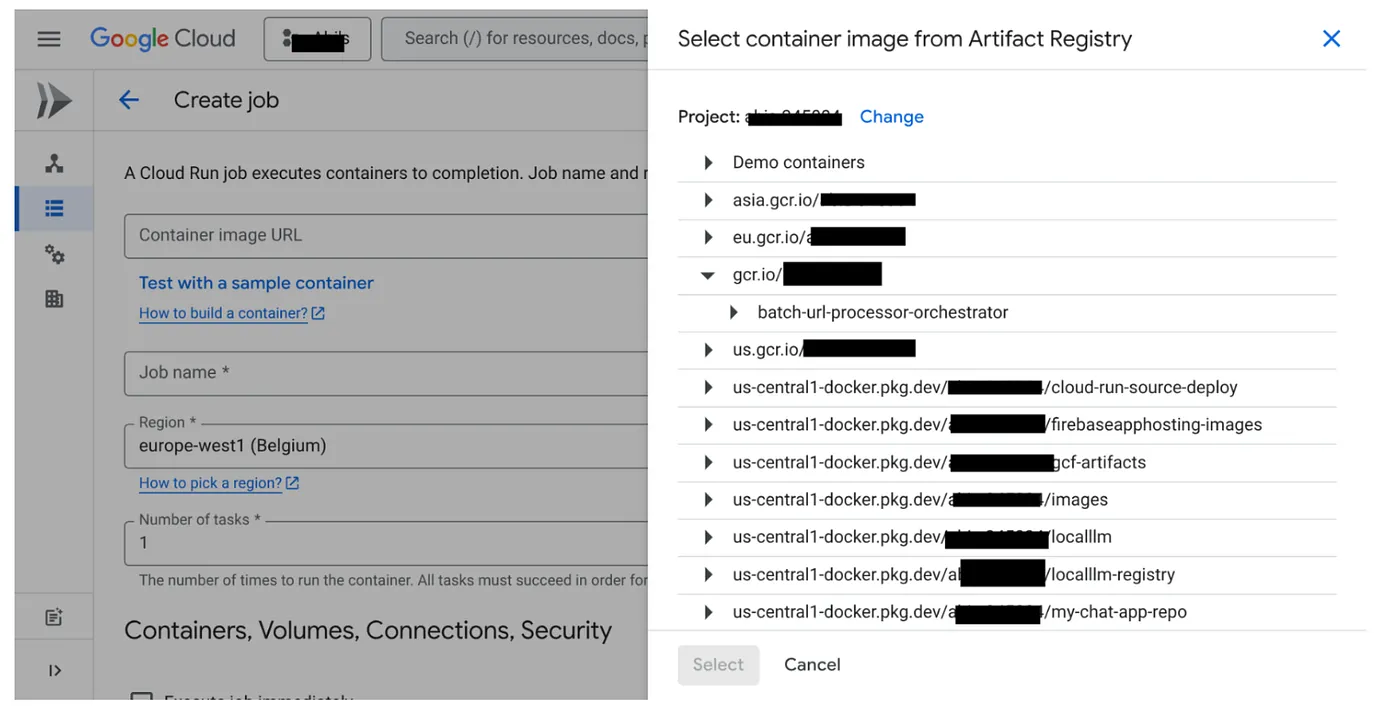
- Saisissez les autres informations de configuration comme suit :

- Définissez la capacité de l'opération comme suit :
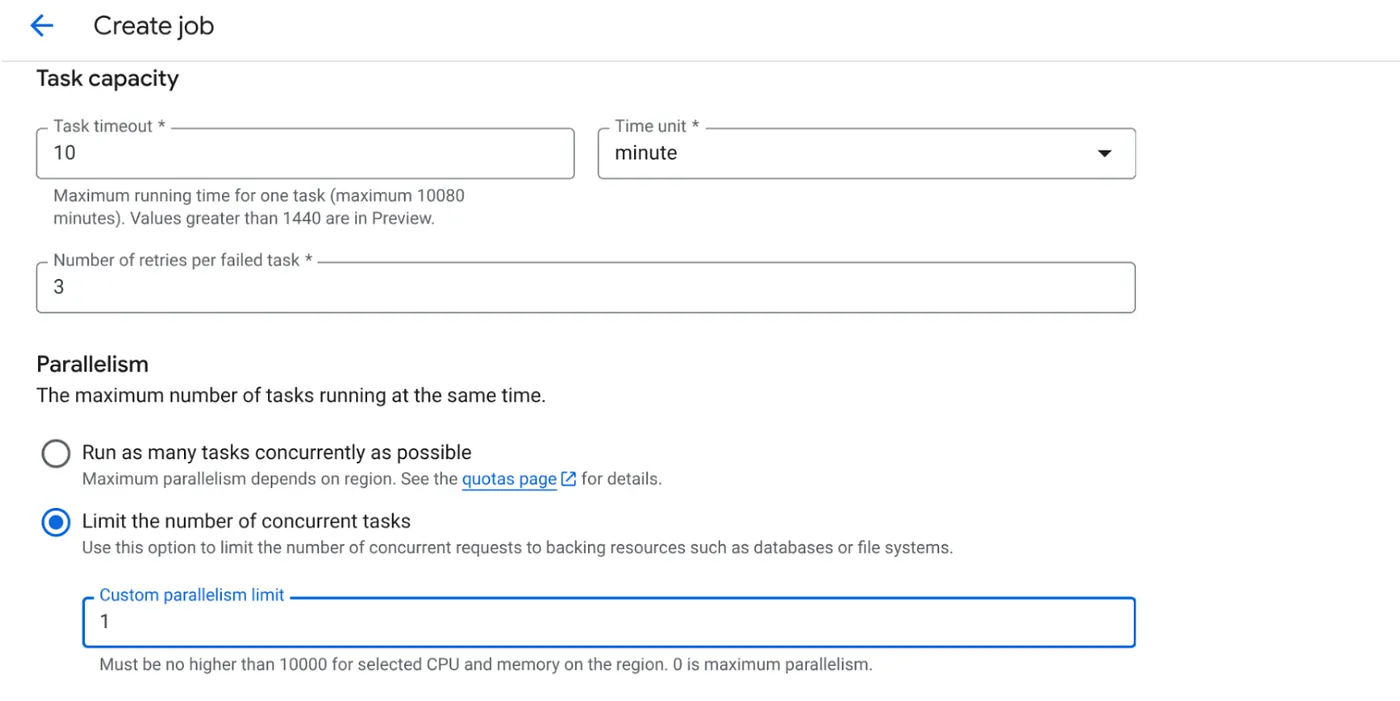
Étant donné que nous avons des écritures de base de données et que la parallélisation (max_instances et concurrence des tâches) est déjà gérée dans le code, nous allons définir le nombre de tâches simultanées sur 1. N'hésitez pas à l'augmenter selon vos besoins. L'objectif ici est que les tâches s'exécutent jusqu'à la fin selon la configuration avec le niveau de concurrence défini dans le parallélisme.
- Cliquez sur "Créer".
Votre job Cloud Run sera créé.
Fonctionnement
Une instance de conteneur de notre job démarre. Il interroge BigQuery pour obtenir un petit lot (BATCH_SIZE) d'URL marquées comme PENDING. Il met immédiatement à jour l'état de ces URL récupérées sur "PROCESSING" (EN COURS DE TRAITEMENT) dans BigQuery pour empêcher d'autres instances de job de les récupérer. Il crée un ThreadPoolExecutor et envoie une tâche pour chaque URL du lot. Chaque tâche appelle la fonction call_url_processor_service. À mesure que les requêtes call_url_processor_service se terminent (ou expirent/échouent), leurs résultats (le contexte généré par l'IA ou un message d'erreur) sont collectés et remappés à l'ID de ligne d'origine. Une fois toutes les tâches du lot terminées, le job parcourt les résultats collectés et met à jour les champs de contexte et d'état pour chaque ligne correspondante dans BigQuery. Si l'opération réussit, l'instance de job se ferme correctement. S'il rencontre des erreurs non traitées, il génère une exception, ce qui peut déclencher une nouvelle tentative par Cloud Run Jobs (en fonction de la configuration du job).
Place des jobs Cloud Run : orchestration
C'est là que les jobs Cloud Run révèlent tout leur potentiel.
Traitement par lot sans serveur : nous obtenons une infrastructure gérée qui peut lancer autant d'instances de conteneur que nécessaire (jusqu'à MAX_INSTANCES) pour traiter nos données simultanément.
Contrôle du parallélisme : nous définissons MAX_INSTANCES (le nombre de jobs pouvant s'exécuter en parallèle au total) et TASK_CONCURRENCY (le nombre d'opérations que chaque instance de job effectue en parallèle). Cela permet de contrôler précisément le débit et l'utilisation des ressources.
Tolérance aux pannes : si une instance de job échoue en cours de route, vous pouvez configurer Cloud Run Jobs pour qu'il relance l'intégralité du job ou des tâches spécifiques, ce qui permet de ne pas perdre le traitement des données.
Architecture simplifiée : en orchestrant les appels HTTP directement dans le job et en utilisant BigQuery pour la gestion de l'état, nous évitons la complexité de la configuration et de la gestion de Pub/Sub, de ses thèmes, de ses abonnements et de sa logique d'accusé de réception.
MAX_INSTANCES vs TASK_CONCURRENCY :
MAX_INSTANCES: : nombre total d'instances de job pouvant s'exécuter simultanément pour l'ensemble de l'exécution du job. Il s'agit de votre principal levier de parallélisme pour traiter plusieurs URL à la fois.
TASK_CONCURRENCY: : nombre d'opérations parallèles (appels à votre service de traitement) qu'une seule instance de votre job effectuera. Cela permet de saturer le processeur/réseau d'une instance.
9. Exécuter et surveiller le job Cloud Run
Métadonnées de vidéo
Avant de cliquer sur "Exécuter", examinons l'état des données.
Accédez à BigQuery Studio et exécutez la requête suivante :
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
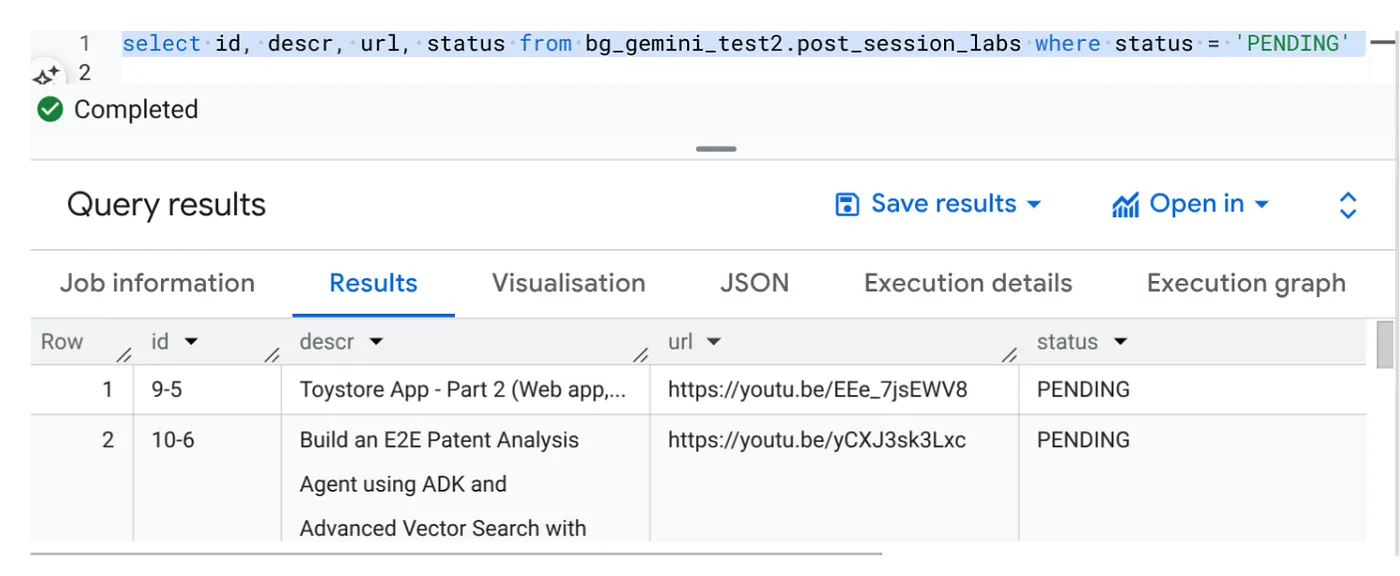
Nous avons quelques exemples d'enregistrements avec des URL de vidéos et l'état "EN ATTENTE". Notre objectif est de remplir le champ "contexte" avec des insights issus de la vidéo, dans le format expliqué dans la requête.
Déclencheur de job
Exécutons la tâche en cliquant sur le bouton "EXÉCUTER" de la tâche dans la console Cloud Run Jobs. Vous devriez pouvoir voir la progression et l'état des tâches dans la console :
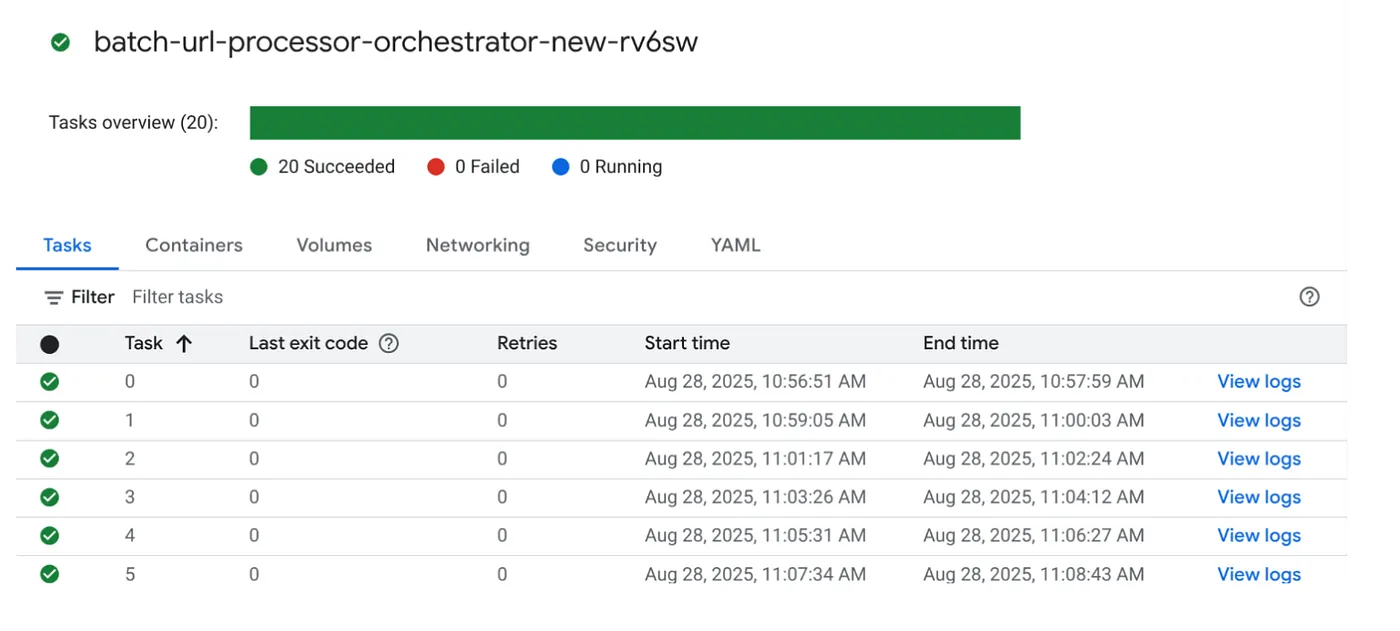
Vous pouvez consulter le tag "JOURNAUX" dans "OBSERVABILITÉ" pour connaître les étapes de surveillance et d'autres détails sur le job et les tâches.
10. Analyse des résultats
Une fois le job terminé, vous devriez pouvoir voir le contexte de chaque URL de vidéo mis à jour dans le tableau :
Contexte de sortie (pour l'un des enregistrements)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
Vous devriez maintenant pouvoir valider cette structure JSON pour des cas d'utilisation agentiques plus avancés.
Pourquoi cette approche ?
Cette architecture offre des avantages stratégiques importants :
- Rentabilité : avec les services sans serveur, vous ne payez que ce que vous utilisez. Les jobs Cloud Run sont mis à l'échelle zéro lorsqu'ils ne sont pas utilisés.
- Scalabilité : gère sans effort des dizaines de milliers d'URL en ajustant les paramètres d'instance et de simultanéité des jobs Cloud Run.
- Agilité : cycles de développement et de déploiement rapides pour les nouvelles logiques de traitement ou les modèles d'IA en mettant simplement à jour l'application et son service.
- Réduction des coûts opérationnels : vous n'avez pas de serveurs à corriger ni à gérer. Google s'occupe de l'infrastructure.
- Démocratisation de l'IA : le traitement avancé de l'IA est accessible pour les tâches par lot sans nécessiter une expertise approfondie en ML Ops.
11. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gestionnaire de ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
12. Félicitations
Félicitations ! En concevant notre solution autour de Cloud Run Jobs et en exploitant la puissance de BigQuery pour la gestion des données et d'un service Cloud Run externe pour le traitement de l'IA, vous avez créé un système hautement évolutif, économique et facile à entretenir. Ce modèle découple la logique de traitement, permet l'exécution parallèle sans infrastructure complexe et accélère considérablement le délai d'obtention d'insights.
Nous vous encourageons à explorer les jobs Cloud Run pour vos propres besoins de traitement par lot. Que ce soit pour mettre à l'échelle l'analyse de l'IA, exécuter des pipelines ETL ou effectuer des tâches de données périodiques, cette approche sans serveur offre une solution puissante et efficace. Pour commencer par vous-même, consultez cette page.
Si vous souhaitez créer et déployer toutes vos applications sans serveur et agentiques, inscrivez-vous à Code Vipassana, qui vise à accélérer les applications agentiques génératives axées sur les données.