
1. סקירה כללית
בעולם עשיר הנתונים של היום, חילוץ תובנות משמעותיות מתוכן לא מובנה, במיוחד מסרטונים, הוא צורך חשוב. תארו לעצמכם שאתם צריכים לנתח מאות או אלפי כתובות URL של סרטונים, לסכם את התוכן שלהם, לחלץ טכנולוגיות מרכזיות ואפילו ליצור צמדים של שאלות ותשובות לחומרי לימוד. הוספה של כל אחד מהם בנפרד היא לא רק בזבוז זמן, אלא גם לא יעילה. כאן נכנסות לתמונה ארכיטקטורות ענן מודרניות.
בשיעור ה-Lab הזה, נסביר על פתרון מדרגי במודל ללא שרת (serverless) לעיבוד תוכן וידאו באמצעות חבילת השירותים העוצמתית של Google Cloud: Cloud Run, BigQuery ו-AI גנרטיבי מבית Google (Gemini). נפרט את המסע שלנו מעיבוד של כתובת URL אחת ועד לתיאום של ביצוע מקביל במערך נתונים גדול, בלי העומס שנובע מניהול של תורים מורכבים של הודעות ושילובים.
האתגר
הוטל עלינו לעבד קטלוג גדול של תוכן וידאו, תוך התמקדות בסשנים מעשיים במעבדה. המטרה הייתה לנתח כל סרטון וליצור סיכום מובנה, כולל שמות הפרקים, הקשר להקדמה, הוראות מפורטות, הטכנולוגיות שבהן נעשה שימוש וזוגות רלוונטיים של שאלות ותשובות. היה צורך לאחסן את הפלט הזה בצורה יעילה כדי להשתמש בו בהמשך ליצירת חומרי לימוד.
בתחילה, היה לנו שירות פשוט מבוסס-HTTP ב-Cloud Run שיכול לעבד כתובת URL אחת בכל פעם. השיטה הזו הייתה יעילה לבדיקות ולניתוח אד-הוק. עם זאת, כשמדובר ברשימה של אלפי כתובות URL שמגיעות מ-BigQuery, המגבלות של מודל הבקשה היחידה והתגובה היחידה הופכות ברורות. אם העיבוד היה מתבצע באופן רציף, הוא היה נמשך ימים, ואולי אפילו שבועות.
ההזדמנות הייתה להפוך תהליך ידני או תהליך איטי שמתבצע ברצף לזרימת עבודה אוטומטית שמבצעת פעולות במקביל. בעזרת הענן, רצינו:
- עיבוד נתונים במקביל: קיצור משמעותי של זמן העיבוד של מערכי נתונים גדולים.
- שימוש ביכולות AI קיימות: אפשר להשתמש ביכולות של Gemini לניתוח תוכן מתוחכם.
- תחזוקה של ארכיטקטורה ללא שרת: לא צריך לנהל שרתים או תשתית מורכבת.
- ריכוז הנתונים: שימוש ב-BigQuery כמקור האמת היחיד לכתובות URL של קלט וכיעד מהימן לתוצאות מעובדות.
- בניית צינור עיבוד נתונים חזק: יצירת מערכת עמידה בפני כשלים שאפשר לנהל ולנטר בקלות.
מטרה
תזמור של עיבוד מקבילי של AI באמצעות משימות Cloud Run:
הפתרון שלנו מתבסס על משימה ב-Cloud Run שפועלת ככלי לניהול תהליכים. הוא קורא בצורה חכמה קבוצות של כתובות URL מ-BigQuery, שולח את כתובות ה-URL האלה לשירות Cloud Run הקיים והפרוס (שמטפל בעיבוד באמצעות AI של כתובת URL אחת), ואז מצטבר את התוצאות כדי לכתוב אותן בחזרה ל-BigQuery. הגישה הזו מאפשרת לנו:
- הפרדה בין תזמור לעיבוד: העבודה מנהלת את תהליך העבודה, בעוד שהשירות הנפרד מתמקד במשימת ה-AI.
- ניצול המקביליות של Cloud Run Job: המשימה יכולה להרחיב כמה מופעי קונטיינר כדי לקרוא לשירות ה-AI במקביל.
- הפחתת המורכבות: אנחנו משיגים מקביליות בכך שהמשימה מנהלת ישירות קריאות HTTP בו-זמניות, וכך מפשטת את הארכיטקטורה.
תרחיש לדוגמה
תובנות מבוססות-AI מסרטונים של מפגשי Code Vipassana
תרחיש השימוש הספציפי שלנו היה ניתוח סרטונים של סשנים ב-Google Cloud של שיעורי Lab מעשיים של Code Vipassana. המטרה הייתה ליצור באופן אוטומטי תיעוד מובנה (מתאר של פרקים בספר), כולל:
- שמות הפרקים: שמות תמציתיים לכל קטע בסרטון
- הקשר להקדמה: הסבר על הרלוונטיות של הסרטון לתוכנית לימודים רחבה יותר
- מה ייבנה: המשימה או המטרה העיקרית של הסשן
- טכנולוגיות בשימוש: רשימה של שירותי ענן וטכנולוגיות אחרות שמוזכרות
- הוראות מפורטות: איך המשימה בוצעה, כולל קטעי קוד
- כתובות URL של קוד מקור או הדגמה: קישורים שמופיעים בסרטון
- קטע שאלות ותשובות: יצירת שאלות ותשובות רלוונטיות לבדיקת הידע.
Flow

התהליך של הארכיטקטורה
מה זה Cloud Run? מהן משימות Cloud Run?
Cloud Run
פלטפורמה מנוהלת ללא שרת (serverless) שמאפשרת להריץ קונטיינרים ללא שמירת מצב. הוא מתאים במיוחד לשירותי אינטרנט, לממשקי API ולמיקרו-שירותים שאפשר להגדיל את הקיבולת שלהם באופן אוטומטי על סמך בקשות נכנסות. אתם מספקים קובץ אימג' של קונטיינר, ו-Cloud Run מטפל בכל השאר – מפריסה והתאמה לעומס ועד לניהול התשתית. היא מצטיינת בטיפול בעומסי עבודה סינכרוניים של בקשות ותגובות.
משימות ב-Cloud Run
מוצר שמשלים את שירותי Cloud Run. משימות Cloud Run מיועדות למשימות עיבוד באצווה שצריכות להסתיים ואז להיפסק. הם מתאימים במיוחד לעיבוד נתונים, ל-ETL, להסקת מסקנות באצווה של למידת מכונה ולכל משימה שכוללת עיבוד של מערך נתונים במקום מענה לבקשות בזמן אמת. תכונה מרכזית שלהם היא היכולת להגדיל את מספר המקרים של קונטיינרים (משימות) שפועלים בו-זמנית כדי לעבד קבוצת עבודה, והם יכולים להיות מופעלים על ידי מקורות שונים של אירועים או באופן ידני.
ההבדל העיקרי
שירותי Cloud Run מיועדים לאפליקציות ארוכות טווח שמבוססות על בקשות. משימות ב-Cloud Run מיועדות לעיבוד ברצף (batch processing) סופי וממוקד משימות שפועל עד להשלמה.
מה תפַתחו
אפליקציית חיפוש קמעונאית
כחלק מהתהליך הזה, תצטרכו:
- יצירת מערך נתונים, טבלה והוספת נתונים ב-BigQuery (מטא-נתונים של Code Vipassana)
- יצירת פונקציות Python Cloud Run להטמעה של פונקציונליות AI גנרטיבי (המרת סרטון ל-JSON של פרק בספר)
- יצירת אפליקציית Python לפייפליין נתונים מנתונים ל-AI – קריאה מ-BigQuery והפעלת נקודת הקצה של פונקציות Cloud Run לקבלת תובנות, וכתיבת ההקשר בחזרה ל-BigQuery
- פיתוח האפליקציה והעברתה לקונטיינר
- הגדרת משימות של Cloud Run באמצעות הקונטיינר הזה
- הפעלת העבודה ומעקב אחריה
- דיווח על תוצאה
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, אפשר לבדוק שכבר בוצע אימות ושהפרויקט מוגדר לפי מזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: לוחצים על הקישור ומפעילים את ממשקי ה-API.
אפשר גם להשתמש בפקודת gcloud. אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
3. הגדרת מסד נתונים או מחסן נתונים
BigQuery שימש כבסיס לצנרת הנתונים שלנו. הוא מתאים באופן מושלם לאחסון נתוני הקלט ולשמירת התוצאות המעובדות, כי הוא ללא שרת וניתן להתאמה רחבה.
- אחסון נתונים: BigQuery שימש כמחסן הנתונים שלנו. הוא שומר את רשימת כתובות ה-URL של הסרטונים, את הסטטוס שלהם (למשל, בהמתנה, בעיבוד, הושלם) ואת ההקשר הסופי שנוצר. זה המקור הקובע לגבי הסרטונים שצריך לעבד.
- יעד: המקום שבו התובנות שנוצרו על ידי AI נשמרות, כך שאפשר להריץ עליהן שאילתות בקלות באפליקציות במורד הזרם או לבדוק אותן ידנית. מערך הנתונים שלנו כלל פרטים על סשנים של צפייה בסרטונים, במיוחד בתוכן של 'Code Vipassana Seasons', שכולל לעיתים קרובות הדגמות טכניות מפורטות.
- טבלת מקור: טבלה ב-BigQuery (לדוגמה, post_session_labs) שמכילה רשומות כמו:
- id: מזהה ייחודי לכל סשן או שורה.
- כתובת URL: כתובת ה-URL של הסרטון (למשל, קישור ל-YouTube או קישור נגיש ל-Drive).
- סטטוס: מחרוזת שמציינת את מצב העיבוד (למשל, PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING).
- context: שדה מחרוזת לאחסון הסיכום שנוצר על ידי AI.
- הטמעת נתונים: בתרחיש הזה, הנתונים הוטמעו ב-BigQuery באמצעות סקריפטים של INSERT. במקרה של צינור הנתונים שלנו, BigQuery היה נקודת ההתחלה.
עוברים אל BigQuery Console, פותחים כרטיסייה חדשה ומריצים את הצהרות ה-SQL הבאות:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. הטמעת נתונים
עכשיו צריך להוסיף טבלה עם הנתונים על החנות. עוברים לכרטיסייה ב-BigQuery Studio ומריצים את הצהרות ה-SQL הבאות כדי להוסיף את הרשומות לדוגמה:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. יצירת פונקציות של תובנות לגבי סרטונים
אנחנו צריכים ליצור ולפרוס פונקציית Cloud Run כדי להטמיע את ליבת הפונקציונליות, כלומר ליצור פרק ספר מובנה מכתובת ה-URL של הסרטון. כדי לגשת לזה כאל ארגז כלים עצמאי של נקודות קצה, יצרנו ופרסנו פונקציית Cloud Run. לחלופין, אפשר לכלול את הפונקציה הזו כפונקציה נפרדת באפליקציית Python בפועל עבור Cloud Run Job:
- במסוף Google Cloud, נכנסים אל הדף Cloud Run.
- לוחצים על 'כתיבת פונקציה'.
- בשדה 'שם השירות', מזינים שם לתיאור הפונקציה. שמות של שירותים חייבים להתחיל באות, ויכולים להכיל עד 49 תווים, כולל אותיות, מספרים או מקפים. שמות השירותים לא יכולים להסתיים במקפים, והם צריכים להיות ייחודיים לכל אזור ולכל פרויקט. אי אפשר לשנות את שם השירות בהמשך, והוא גלוי לכולם. ( generate-video-insights**)**
- ברשימת האזורים, משתמשים בערך שמוגדר כברירת מחדל או בוחרים את האזור שבו רוצים לפרוס את הפונקציה. (בוחרים us-central1)
- ברשימה Runtime, משתמשים בערך ברירת המחדל או בוחרים גרסת זמן ריצה. (בוחרים באפשרות Python 3.11)
- בקטע 'אימות', בוחרים באפשרות 'מתן גישה ציבורית'.
- לוחצים על הלחצן 'יצירה'.
- הפונקציה נוצרת ונטענת עם תבנית main.py ו-requirements.txt
- מחליפים את הקובץ הזה בקבצים: main.py ו- requirements.txt ממאגר הפרויקט הזה
הערה חשובה: בקובץ main.py, צריך להחליף את <<YOUR_PROJECT_ID>> במזהה הפרויקט שלכם.
- פורסים ושומרים את נקודת הקצה כדי שאפשר יהיה להשתמש בה במקור של Cloud Run Job.
נקודת הקצה שלכם אמורה להיראות כך (או משהו דומה): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
מה יש בפונקציית Cloud Run הזו?
Gemini 2.5 Flash לעיבוד וידאו
כדי להבין ולסכם את תוכן הסרטון, השתמשנו במודל Gemini 2.5 Flash של Google. מודלים של Gemini הם מודלים חזקים של AI מולטי-מודאלי שיכולים להבין ולעבד סוגים שונים של קלט, כולל טקסט, ועם שילובים ספציפיים, גם וידאו.
בהגדרה שלנו, לא הזנו את קובץ הווידאו ישירות ל-Gemini. במקום זאת, שלחנו הנחיה טקסטואלית שכללה את כתובת ה-URL של הסרטון והוראות ל-Gemini לגבי ניתוח התוכן (ההיפותטי) של סרטון בכתובת ה-URL הזו. למרות ש-Gemini 2.5 Flash יכול לקבל קלט מולטי-מודאלי, בצינור הספציפי הזה נעשה שימוש בהנחיה מבוססת-טקסט שמתארת את אופי הסרטון (סדנה מעשית) ומבקשת פלט מובנה בפורמט JSON. התכונה הזו מסתמכת על יכולות Gemini של חשיבה רציונלית משופרת והבנת שפה טבעית, כדי להסיק ולסכם מידע על סמך ההקשר של ההנחיה.
הנחיה ל-Gemini: הנחיית ה-AI
פרומפט מנוסח היטב הוא חיוני למודלים של AI. ההנחיה שלנו נועדה לחלץ מידע ספציפי מאוד ולבנות אותו בפורמט JSON, כך שהאפליקציה שלנו תוכל לנתח אותו בקלות.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
ההנחיה הזו ספציפית מאוד, ומנחה את Gemini לפעול כמעין איש חינוך. הבקשה למחרוזת JSON מבטיחה פלט מובנה שמתאים לקריאה למחשבים.
הנה הקוד לניתוח קלט של סרטון ולהחזרת ההקשר שלו:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
קטע הקוד שלמעלה מדגים את הפונקציה העיקרית של תרחיש השימוש. הכלי מקבל כתובת URL של סרטון ומשתמש במודל Gemini דרך לקוח Vertex AI כדי לנתח את תוכן הסרטון ולחלץ תובנות רלוונטיות בהתאם להנחיה. ההקשר שחולץ מוחזר לעיבוד נוסף. הפעולה הזו היא סינכרונית, כלומר, ה-Job ב-Cloud Run ממתין לסיום השירות.
6. פיתוח אפליקציות של צינורות עיבוד נתונים (Python)
הלוגיקה המרכזית של הפייפליין שלנו נמצאת בקוד המקור של האפליקציה, שייארז כקונטיינר ב-Cloud Run Job, שמנהל את כל ההרצה המקבילה. הנה הסבר על החלקים העיקריים:
תפקיד כלי התזמור בניהול תהליך העבודה והבטחת תקינות נתונים:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
קטע הקוד שלמעלה מתחיל באחזור של קבוצת כתובות URL של סרטונים עם סטטוס 'בהמתנה' מטבלת המקור ב-BigQuery. לאחר מכן, המערכת מעדכנת את הסטטוס של כתובות ה-URL האלה ל'בתהליך' ב-BigQuery, כדי למנוע עיבוד כפול.
עיבוד מקבילי באמצעות ThreadPoolExecutor וקריאה לשירות העיבוד:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
החלק הזה של הקוד משתמש ב-ThreadPoolExecutor כדי לבצע עיבוד מקביל של כתובות ה-URL של הסרטונים שאוחזרו. לכל כתובת URL, הוא שולח משימה לקריאה אסינכרונית לשירות Cloud Run (מעבד כתובות ה-URL). כך אפשר לעבד כמה סרטונים בו-זמנית ביעילות באמצעות Cloud Run Job, ולשפר את הביצועים הכוללים של פייפליין הנתונים. קטע הקוד מטפל גם בפסק זמן פוטנציאלי ובשגיאות משירות המעבד.
קריאה וכתיבה מ-BigQuery ואליו
האינטראקציה העיקרית עם BigQuery כוללת אחזור של כתובות URL בהמתנה ואז עדכון שלהן עם תוצאות מעובדות.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
כתיבת התוצאות בחזרה ל-BigQuery:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
קטעי הקוד שלמעלה מתמקדים באינטראקציה של הנתונים בין Cloud Run Job לבין BigQuery. המערכת מאחזרת קבוצה של כתובות URL של סרטונים במצב 'בהמתנה' ואת המזהים שלהם מטבלת המקור. אחרי עיבוד כתובות ה-URL, הקטע הבא מדגים איך לכתוב את ההקשר והסטטוס שחולצו ('COMPLETED' או 'FAILED_PROCESSING') בחזרה לטבלה ב-BigQuery באמצעות שאילתת UPDATE. קטע הקוד הזה משלים את לולאת עיבוד הנתונים. היא כוללת גם את פונקציית העזר update_bq_row שמראה איך להגדיר פרמטרים של הצהרת העדכון.
הגדרת האפליקציה
האפליקציה מובנית כסקריפט Python יחיד שיוכנס לקונטיינר. היא מסתמכת על ספריות לקוח של Google Cloud ועל functions-framework כדי להגדיר את נקודת הכניסה שלה.
- יחסי תלות: google-cloud-bigquery, requests
- הגדרה: כל ההגדרות הקריטיות (פרויקט, מערך נתונים או טבלה ב-BigQuery, כתובת URL של שירות מעבד כתובות URL) נטענות ממשתני סביבה, מה שהופך את האפליקציה לניידת ומאובטחת
- הלוגיקה המרכזית: הפונקציה process_batch_from_bq מתזמרת את כל תהליך העבודה
- שילוב שירותים חיצוניים: הפונקציה call_url_processor_service מטפלת בתקשורת עם שירות Cloud Run נפרד
- אינטראקציה עם BigQuery: נעשה שימוש ב-bq_client כדי לאחזר כתובות URL ולעדכן תוצאות, עם טיפול בפרמטרים
- מקביליות: concurrent.futures.ThreadPoolExecutor מנהל קריאות מקבילות לשירות החיצוני
- נקודת כניסה: קוד Python בשם main.py משמש כנקודת הכניסה שמתחילה את עיבוד הקבוצה.
עכשיו נגדיר את האפליקציה:
- כדי להתחיל, מנווטים אל Cloud Shell Terminal ומשכפלים את המאגר:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- עוברים אל Cloud Shell Editor, שם אפשר לראות את התיקייה החדשה שנוצרה video-context-crj
- מוחקים את השלבים הבאים כי הם כבר הושלמו בקטעים הקודמים:
- מחיקת התיקייה Cloud_Run_Function
- עוברים לתיקיית הפרויקט video-context-crj ורואים את מבנה הפרויקט:
7. הגדרה של קובץ Dockerfile ויצירת קונטיינרים
כדי לפרוס את הלוגיקה הזו כ-Cloud Run Job, צריך להכניס אותה לקונטיינר. קונטיינריזציה היא תהליך של אריזת קוד האפליקציה, התלות שלה וזמן הריצה שלה בקובץ אימג' נייד.
חשוב להחליף את הערכים הזמניים לשמירת מקום (הטקסט המודגש) בערכים שלכם בקובץ Dockerfile:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
קטע ה-Dockerfile שלמעלה מגדיר את תמונת הבסיס, מתקין תלות, מעתיק את הקוד שלנו ומגדיר את הפקודה להפעלת האפליקציה באמצעות functions-framework עם פונקציית היעד הנכונה (process_batch_from_bq). התמונה מועברת ל-Artifact Registry.
העברה למכולה
כדי להוסיף אותו לקונטיינר, עוברים למסוף Cloud Shell ומריצים את הפקודות הבאות (חשוב להחליף את placeholder <<YOUR_PROJECT_ID>>):
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
אחרי שיוצרים את קובץ האימג' של הקונטיינר, אמור להופיע הפלט:
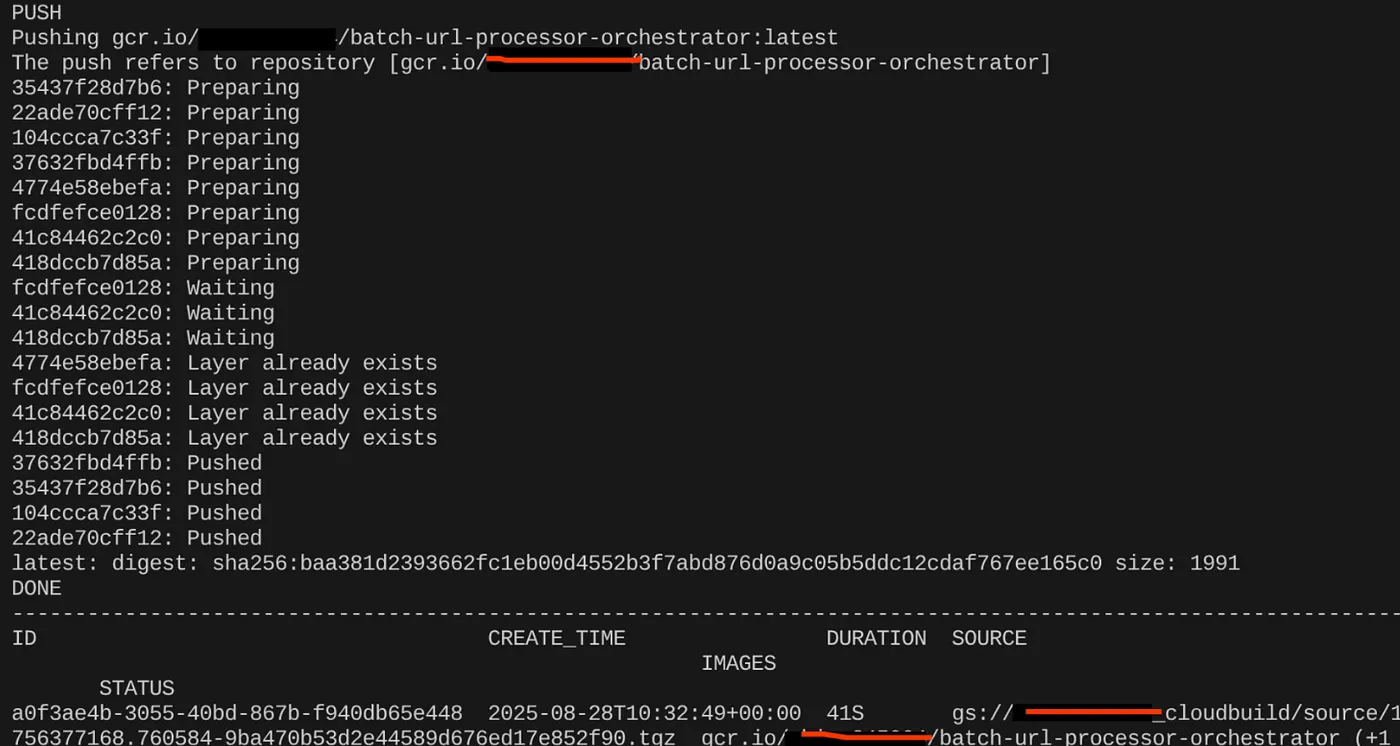
הקונטיינר שלנו נוצר ונשמר ב-Artifact Registry. אפשר לעבור לשלב הבא.
8. יצירת משימות ב-Cloud Run
פריסת העבודה כוללת יצירה של קובץ אימג' של קונטיינר ואז יצירה של משאב Cloud Run Job.
כבר יצרנו את קובץ האימג' של הקונטיינר ואחסנו אותו ב-Artifact Registry. עכשיו ניצור את המשרה.
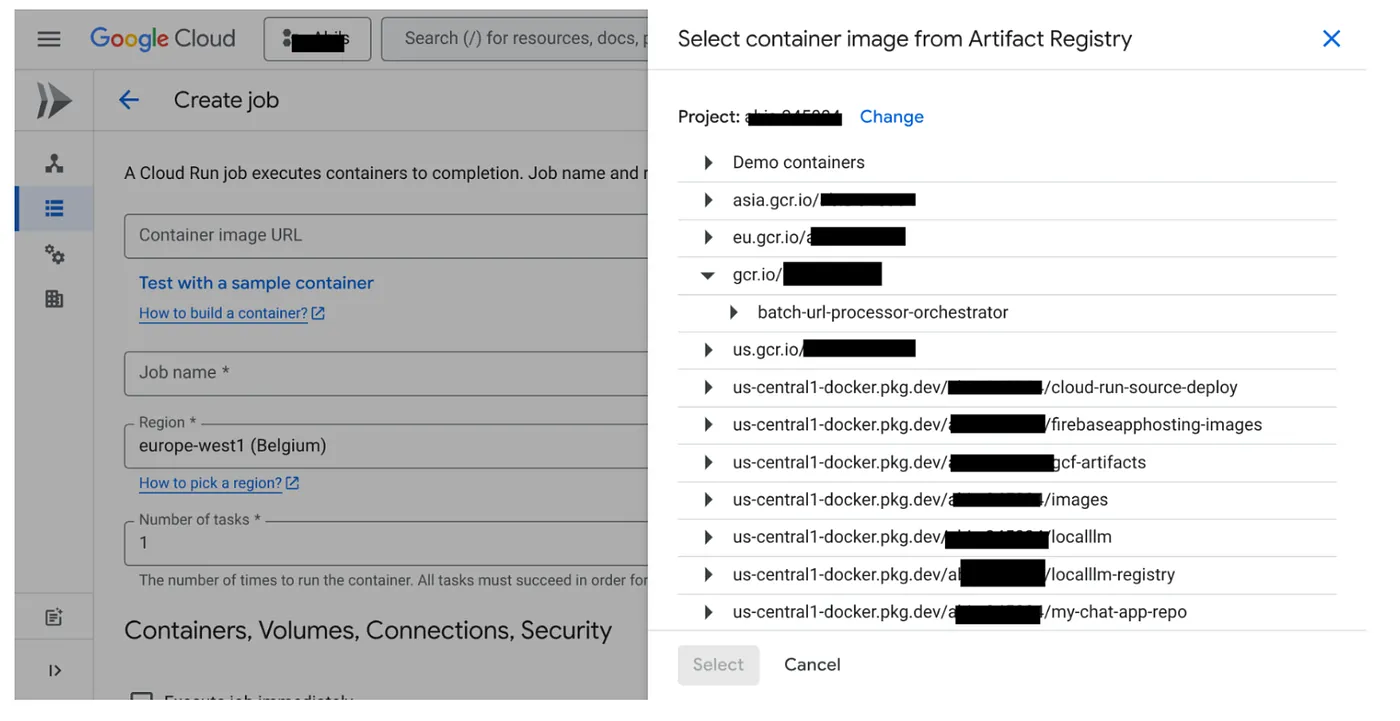
- נכנסים למסוף Cloud Run Jobs ולוחצים על Deploy Container (פריסת קונטיינר):

- בוחרים את קובץ אימג' של קונטיינר שיצרנו:
- מזינים את פרטי ההגדרה האחרים באופן הבא:

- מגדירים את קיבולת המשימות באופן הבא:
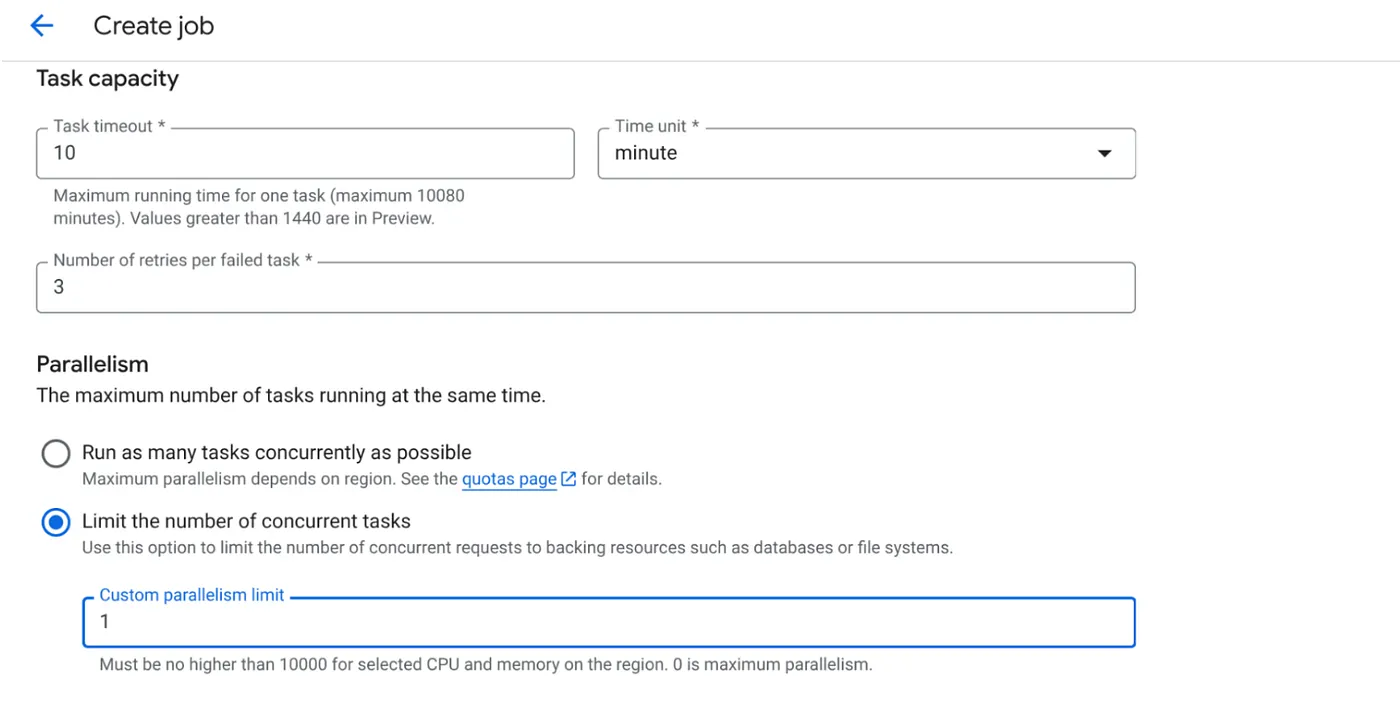
מכיוון שיש לנו כתיבה למסד נתונים והמקביליות (max_instances ו-task concurrency) כבר מטופלת בקוד, נגדיר את מספר המשימות המקבילות ל-1. אבל אפשר להגדיל אותו לפי הצורך. המטרה כאן היא שהמשימות יפעלו עד להשלמה בהתאם להגדרה, עם רמת בו-זמניות שמוגדרת במקביל.
- לוחצים על 'יצירה'.
משימת Cloud Run תיצור בהצלחה.
איך זה עובד
מופעלת מכונת קונטיינר של העבודה שלנו. הוא שולח שאילתה ל-BigQuery כדי לקבל קבוצה קטנה (BATCH_SIZE) של כתובות URL שמסומנות כ-PENDING. הסטטוס של כתובות ה-URL האלה מתעדכן מיד ל-PROCESSING ב-BigQuery כדי למנוע ממופעים אחרים של המשימה לאסוף אותן. הוא יוצר ThreadPoolExecutor ושולח משימה לכל כתובת URL בקבוצה. כל משימה קוראת לפונקציה call_url_processor_service. כשהבקשות של call_url_processor_service מסתיימות (או כשחלף הזמן הקצוב לתגובה או שהן נכשלות), התוצאות שלהן (ההקשר שנוצר על ידי AI או הודעת שגיאה) נאספות וממופות בחזרה ל-row_id המקורי. אחרי שכל המשימות בקבוצה מסתיימות, העבודה חוזרת על התוצאות שנאספו ומעדכנת את שדות ההקשר והסטטוס לכל שורה תואמת ב-BigQuery. אם הפעולה בוצעה ללא שגיאות, מופע העבודה יוצא בצורה נקייה. אם הוא נתקל בשגיאות שלא טופלו, הוא מעלה חריגה, שעשויה להפעיל ניסיון חוזר על ידי Cloud Run Jobs (בהתאם להגדרת העבודה).
איך משימות ב-Cloud Run משתלבות: תזמור
כאן באמת רואים את היתרונות של Cloud Run Jobs.
עיבוד נתונים באצווה ללא שרת: אנחנו מקבלים תשתית מנוהלת שיכולה להתחיל הרצה של כמה מופעי קונטיינר שנדרשים (עד MAX_INSTANCES) כדי לעבד את הנתונים שלנו במקביל.
שליטה בהרצה מקבילית: אנחנו מגדירים את MAX_INSTANCES (כמה משימות יכולות לפעול במקביל באופן כללי) ואת TASK_CONCURRENCY (כמה פעולות כל מופע של משימה מבצע במקביל). כך אפשר לשלוט במדויק בנפח התעבורה ובניצול המשאבים.
עמידות בפני תקלות: אם מופע של משימה נכשל באמצע, אפשר להגדיר את Cloud Run Jobs כך שהמערכת תנסה שוב את כל המשימה או משימות ספציפיות, כדי להבטיח שעיבוד הנתונים לא יאבד.
ארכיטקטורה פשוטה: על ידי תזמון קריאות HTTP ישירות בתוך העבודה ושימוש ב-BigQuery לניהול מצב, אנחנו נמנעים מהמורכבות של הגדרה וניהול של Pub/Sub, הנושאים, המינויים והלוגיקה של האישור שלו.
MAX_INSTANCES לעומת TASK_CONCURRENCY:
MAX_INSTANCES: המספר הכולל של מופעי עבודה שיכולים לפעול בו-זמנית בכל ההרצה של העבודה. זהו המנגנון העיקרי להפעלת מקביליות לעיבוד של הרבה כתובות URL בו-זמנית.
TASK_CONCURRENCY: מספר הפעולות המקבילות (קריאות לשירות העיבוד) שמכונה אחת של העבודה תבצע. כך אפשר להעמיס על המעבד או על הרשת של מכונה אחת.
9. הפעלה ומעקב של משימה ב-Cloud Run
מטא-נתונים של הסרטון
לפני שלוחצים על 'הפעלה', כדאי לראות את סטטוס הנתונים.
עוברים אל BigQuery Studio ומריצים את השאילתה הבאה:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
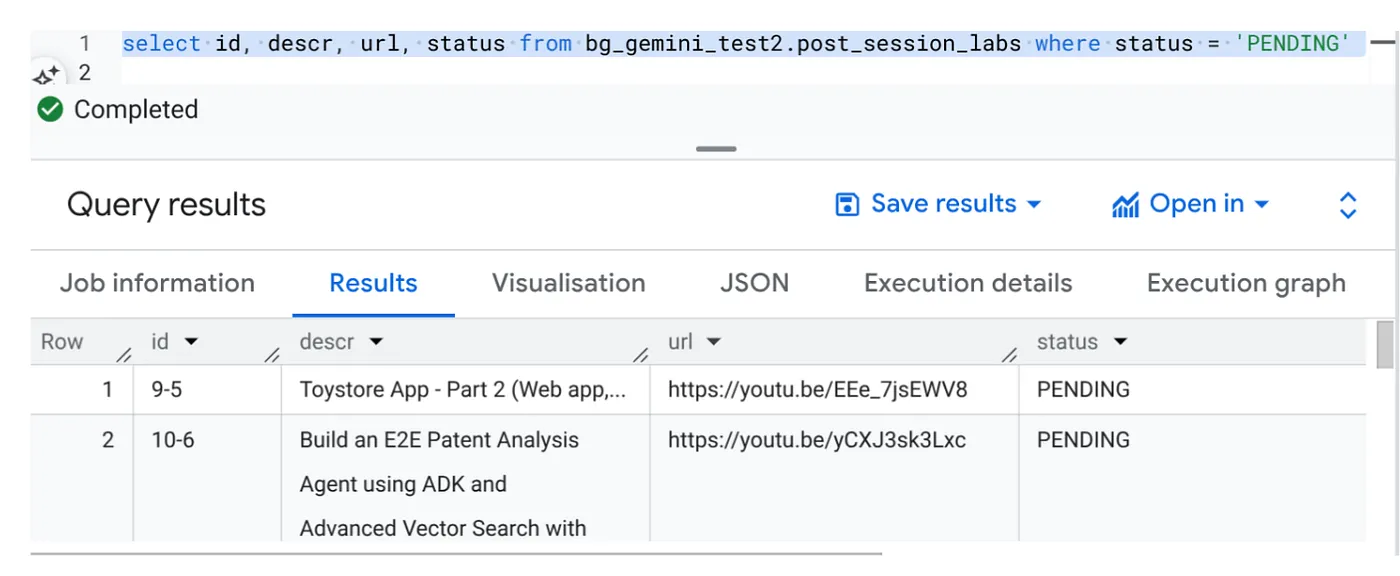
יש לנו כמה רשומות לדוגמה עם כתובות URL של סרטונים וסטטוס 'בהמתנה'. המטרה שלנו היא לאכלס את השדה 'הקשר' בתובנות מהסרטון בפורמט שמוסבר בהנחיה.
טריגר של משימה
כדי להריץ את המשימה, לוחצים על הלחצן EXECUTE במשימה במסוף Cloud Run Jobs. במסוף אפשר לראות את ההתקדמות והסטטוס של המשימות:
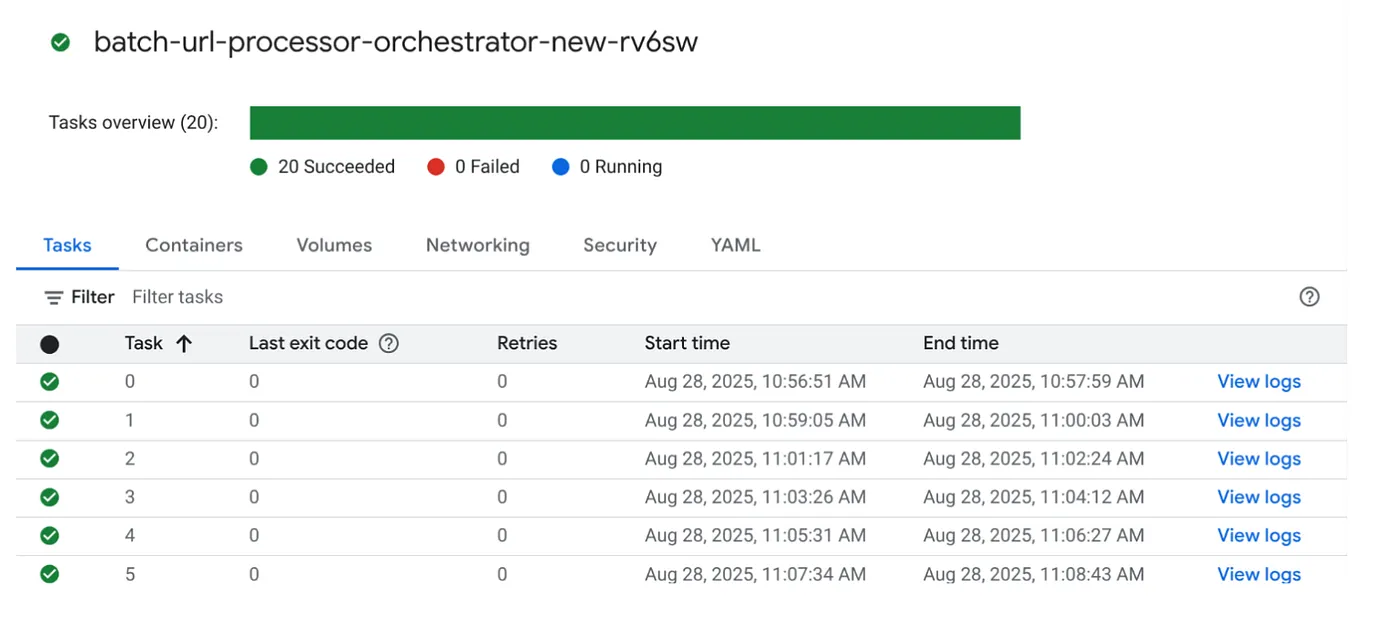
אפשר לבדוק את התג LOGS ב-OBSERVABILITY כדי לראות את שלבי המעקב ופרטים נוספים על העבודה והמשימות.
10. ניתוח התוצאות
אחרי שהעבודה תושלם, תוכלו לראות בטבלה את ההקשר של כל כתובת URL של סרטון:
הקשר של הפלט (לאחד מהרשומות)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
עכשיו תוכלו לאמת את מבנה ה-JSON הזה לתרחישי שימוש מתקדמים יותר של סוכנים.
למה בחרנו בגישה הזו?
לארכיטקטורה הזו יש יתרונות אסטרטגיים משמעותיים:
- חסכוניות: שירותים בלי שרת (serverless) מאפשרים לשלם רק על מה שמשתמשים בו. משימות ב-Cloud Run מצטמצמות לאפס כשהן לא בשימוש.
- מדרגיות: המערכת מטפלת בקלות בעשרות אלפי כתובות URL על ידי התאמת הגדרות המקבילות והמופע של משימת Cloud Run.
- גמישות: מחזורי פיתוח ופריסה מהירים של לוגיקת עיבוד חדשה או מודלים של AI, על ידי עדכון פשוט של האפליקציה הכלולה והשירות שלה.
- הפחתת עלויות תפעול: אין צורך לתקן או לנהל שרתים, כי Google מטפלת בתשתית.
- הנגשת AI: מאפשרת לבצע עיבוד באמצעות AI מתקדם למשימות אצווה בלי צורך במומחיות עמוקה ב-ML Ops.
11. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם במאמר הזה:
- במסוף Google Cloud, עוברים לדף resource manager.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
12. מזל טוב
מעולה! הפתרון שלכם מבוסס על Cloud Run Jobs, ומשתמש ביכולות של BigQuery לניהול נתונים ובשירות חיצוני של Cloud Run לעיבוד באמצעות AI. כך יצרתם מערכת בעלת מדרגיות גבוהה, משתלמת וקלה לתחזוקה. התבנית הזו מפרידה את לוגיקת העיבוד, מאפשרת ביצוע מקביל בלי תשתית מורכבת ומקצרת משמעותית את הזמן עד לקבלת תובנות.
מומלץ לבדוק את Cloud Run Jobs כדי לענות על צורכי העיבוד באצווה שלכם. בין אם מדובר בהרחבת ניתוח AI, בהפעלת צינורות ETL או בביצוע משימות נתונים תקופתיות, הגישה הזו ללא שרת מציעה פתרון יעיל ועוצמתי. כדי להתחיל לבד, כדאי לעיין במאמר הזה.
אם אתם רוצים לפתח ולפרוס את כל האפליקציות שלכם ללא שרתים ובאמצעות סוכנים, אתם יכולים להירשם ל-Code Vipassana, שמתמקד בהאצת פיתוח אפליקציות גנרטיביות מבוססות-סוכנים שמבוססות על נתונים.