
1. खास जानकारी
आज के डेटा से भरपूर इस दुनिया में, बिना किसी स्ट्रक्चर वाले कॉन्टेंट, खासकर वीडियो से काम की इनसाइट निकालना बहुत ज़रूरी है. मान लें कि आपको सैकड़ों या हज़ारों वीडियो यूआरएल का विश्लेषण करना है. साथ ही, उनके कॉन्टेंट की खास जानकारी देनी है, मुख्य टेक्नोलॉजी निकालनी हैं, और शिक्षा से जुड़े कॉन्टेंट के लिए सवाल-जवाब के जोड़े जनरेट करने हैं. एक-एक करके ऐसा करने में न सिर्फ़ ज़्यादा समय लगता है, बल्कि यह तरीका असरदार भी नहीं है. मॉडर्न क्लाउड आर्किटेक्चर यहीं काम आते हैं.
इस लैब में, हम Google Cloud की सेवाओं के शक्तिशाली सुइट का इस्तेमाल करके, वीडियो कॉन्टेंट को प्रोसेस करने के लिए, ज़्यादा डेटा हैंडल करने वाले, बिना सर्वर के काम करने वाले सलूशन के बारे में जानेंगे. इन सेवाओं में Cloud Run, BigQuery, और Google का जनरेटिव एआई (Gemini) शामिल हैं. हम आपको बताएंगे कि हमने एक यूआरएल को प्रोसेस करने से लेकर, बड़े डेटासेट पर एक साथ कई कार्रवाइयां करने तक का सफ़र कैसे तय किया. साथ ही, हम आपको यह भी बताएंगे कि हमने जटिल मैसेजिंग कतारों और इंटिग्रेशन को मैनेज करने की ज़रूरत के बिना यह सब कैसे किया.
चुनौती
हमें वीडियो कॉन्टेंट के बड़े कैटलॉग को प्रोसेस करने का काम सौंपा गया था. इसमें खास तौर पर, हैंड्स-ऑन लैब सेशन पर फ़ोकस किया गया था. इस सुविधा का मकसद, हर वीडियो का विश्लेषण करना और एक स्ट्रक्चर्ड खास जानकारी जनरेट करना था. इसमें चैप्टर के टाइटल, वीडियो के बारे में जानकारी, चरण-दर-चरण निर्देश, इस्तेमाल की गई टेक्नोलॉजी, और काम के सवाल-जवाब के जोड़े शामिल हैं. इस आउटपुट को सेव करना ज़रूरी था, ताकि बाद में इसका इस्तेमाल शिक्षा से जुड़े कॉन्टेंट को बनाने के लिए किया जा सके.
शुरुआत में, हमारे पास एचटीटीपी पर आधारित एक सामान्य Cloud Run सेवा थी. यह एक बार में सिर्फ़ एक यूआरएल को प्रोसेस कर सकती थी. यह टेस्टिंग और ऐड-हॉक विश्लेषण के लिए काफ़ी कारगर रहा. हालांकि, जब BigQuery से लिए गए हज़ारों यूआरएल की सूची का सामना करना पड़ा, तो एक अनुरोध और एक जवाब वाले इस मॉडल की सीमाएं साफ़ तौर पर दिखने लगीं. एक के बाद एक करके प्रोसेस करने में, कई दिन या हफ़्ते लग सकते हैं.
मौका, मैन्युअल या धीमी क्रमवार प्रोसेस को ऑटोमेटेड, पैरलल वर्कफ़्लो में बदलने का था. क्लाउड का इस्तेमाल करके, हमारा मकसद ये था:
- डेटा को पैरलल में प्रोसेस करना: इससे बड़े डेटासेट को प्रोसेस करने में लगने वाला समय काफ़ी कम हो जाता है.
- एआई की मौजूदा सुविधाओं का फ़ायदा पाएं: कॉन्टेंट का बेहतर तरीके से विश्लेषण करने के लिए, Gemini की सुविधाओं का इस्तेमाल करें.
- बिना सर्वर वाले आर्किटेक्चर को बनाए रखें: सर्वर या जटिल इन्फ़्रास्ट्रक्चर को मैनेज करने से बचें.
- डेटा को एक जगह पर इकट्ठा करें: इनपुट यूआरएल के लिए BigQuery का इस्तेमाल करें. साथ ही, प्रोसेस किए गए नतीजों के लिए भरोसेमंद डेस्टिनेशन के तौर पर भी इसका इस्तेमाल करें.
- एक मज़बूत पाइपलाइन बनाएं: ऐसा सिस्टम बनाएं जो गड़बड़ियों को आसानी से ठीक कर सके. साथ ही, जिसे आसानी से मैनेज और मॉनिटर किया जा सके.
मकसद
Cloud Run जॉब की मदद से, एआई प्रोसेसिंग को एक साथ व्यवस्थित करना:
हमारा समाधान, Cloud Run जॉब पर आधारित है. यह ऑर्केस्ट्रेटर के तौर पर काम करता है. यह BigQuery से यूआरएल के बैच को समझदारी से पढ़ता है. इसके बाद, इन यूआरएल को हमारी मौजूदा, डिप्लॉय की गई Cloud Run सेवा को भेजता है. यह सेवा, एक यूआरएल के लिए एआई प्रोसेसिंग को मैनेज करती है. इसके बाद, यह नतीजों को इकट्ठा करके, उन्हें वापस BigQuery में लिखता है. इस तरीके से, हम ये काम कर पाते हैं:
- प्रोसेसिंग से ऑर्केस्ट्रेशन को अलग करना: जॉब, वर्कफ़्लो को मैनेज करता है. वहीं, अलग सर्विस, एआई टास्क पर फ़ोकस करती है.
- Cloud Run Job की पैरललिज़्म सुविधा का इस्तेमाल करें: यह सुविधा, एआई सेवा को एक साथ कॉल करने के लिए, कई कंटेनर इंस्टेंस को स्केल आउट कर सकती है.
- जटिलता कम करना: हम एक साथ कई काम करने की सुविधा देते हैं. इसके लिए, जॉब सीधे तौर पर एक साथ कई एचटीटीपी कॉल मैनेज करती है. इससे आर्किटेक्चर आसान हो जाता है.
इस्तेमाल का उदाहरण
कोड विपासना सेशन के वीडियो से एआई की मदद से मिली अहम जानकारी
हमें खास तौर पर, Code Vipassana की हैंड्स-ऑन लैब के Google Cloud सेशन के वीडियो का विश्लेषण करना था. इसका मकसद, स्ट्रक्चर्ड दस्तावेज़ (किताब के चैप्टर की आउटलाइन) अपने-आप जनरेट करना था. इसमें ये शामिल हैं:
- चैप्टर के टाइटल: हर वीडियो सेगमेंट के लिए छोटे टाइटल
- इंट्रोडक्टरी कॉन्टेक्स्ट: वीडियो के कॉन्टेंट के बारे में बताना कि यह किसी बड़े लर्निंग पाथ के लिए कितना ज़रूरी है
- क्या बनाया जाएगा: सेशन का मुख्य टास्क या लक्ष्य
- इस्तेमाल की गई टेक्नोलॉजी: क्लाउड सेवाओं और अन्य टेक्नोलॉजी की सूची
- सिलसिलेवार निर्देश: टास्क को कैसे पूरा किया गया, इसमें कोड स्निपेट भी शामिल हैं
- सोर्स कोड/डेमो यूआरएल: वीडियो में दिए गए लिंक
- सवाल-जवाब वाला सेगमेंट: जानकारी की जांच करने के लिए, काम के सवाल और जवाब जनरेट करना.
Flow

आर्किटेक्चर का फ़्लो
Cloud Run क्या है? Cloud Run जॉब क्या हैं?
Cloud Run
यह पूरी तरह से मैनेज किया गया सर्वरलेस प्लैटफ़ॉर्म है. इसकी मदद से, स्टेटलेस कंटेनर चलाए जा सकते हैं. यह वेब सेवाओं, एपीआई, और माइक्रोसर्विस के लिए सबसे सही है. ये सभी, आने वाले अनुरोधों के आधार पर अपने-आप स्केल हो सकती हैं. आपको सिर्फ़ कंटेनर इमेज देनी होती है. इसके बाद, Cloud Run बाकी काम करता है. जैसे, डिप्लॉय करना, स्केल करना, और इन्फ़्रास्ट्रक्चर को मैनेज करना. यह सिंक्रोनस, अनुरोध-जवाब वाले वर्कलोड को मैनेज करने में माहिर है.
Cloud Run Jobs
यह Cloud Run की सेवाओं के साथ काम करने वाली सेवा है. Cloud Run जॉब को बैच प्रोसेसिंग वाले ऐसे टास्क के लिए डिज़ाइन किया गया है जिन्हें पूरा होने के बाद बंद कर दिया जाता है. ये डेटा प्रोसेसिंग, ईटीएल, मशीन लर्निंग बैच इन्फ़रेंस, और ऐसे किसी भी टास्क के लिए सबसे सही हैं जिनमें लाइव अनुरोधों को पूरा करने के बजाय, डेटासेट को प्रोसेस करना शामिल होता है. इनकी मुख्य सुविधा यह है कि ये एक साथ कई कंटेनर इंस्टेंस (टास्क) चला सकते हैं, ताकि काम के बैच को प्रोसेस किया जा सके. इन्हें अलग-अलग इवेंट सोर्स से ट्रिगर किया जा सकता है या मैन्युअल तरीके से भी ट्रिगर किया जा सकता है.
मुख्य अंतर
Cloud Run की सेवाएं, लंबे समय तक चलने वाले और अनुरोध पर आधारित ऐप्लिकेशन के लिए होती हैं. Cloud Run Jobs का इस्तेमाल, टास्क के हिसाब से बैच प्रोसेसिंग के लिए किया जाता है. यह प्रोसेसिंग तब तक चलती है, जब तक टास्क पूरा नहीं हो जाता.
आपको क्या बनाना है
रीटेल सर्च ऐप्लिकेशन
इसके तहत, आपको ये काम करने होंगे:
- BigQuery डेटासेट और टेबल बनाना और डेटा को शामिल करना (कोड विपासना मेटाडेटा)
- जनरेटिव एआई की सुविधा लागू करने के लिए, Python Cloud Run फ़ंक्शन बनाएं. इससे वीडियो को किताब के चैप्टर के JSON फ़ाइल में बदला जा सकेगा
- डेटा को एआई पाइपलाइन में भेजने के लिए Python ऐप्लिकेशन बनाएं - BigQuery से डेटा पढ़ें और अहम जानकारी पाने के लिए Cloud Run Functions Endpoint को कॉल करें. इसके बाद, कॉन्टेक्स्ट को वापस BigQuery में लिखें
- ऐप्लिकेशन बनाना और उसे कंटेनर में रखना
- इस कंटेनर की मदद से Cloud Run जॉब कॉन्फ़िगर करना
- जॉब को लागू करना और उसकी निगरानी करना
- नतीजे की शिकायत करें
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें .
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें: लिंक पर जाएं और एपीआई चालू करें.
इसके अलावा, इसके लिए gcloud कमांड का इस्तेमाल किया जा सकता है. gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
3. डेटाबेस/वेयरहाउस सेटअप करना
BigQuery, हमारी डेटा पाइपलाइन का मुख्य हिस्सा था. इसे बिना सर्वर के इस्तेमाल किया जा सकता है और इसकी क्षमता को ज़रूरत के हिसाब से बढ़ाया जा सकता है. इसलिए, यह हमारे इनपुट डेटा को सेव करने और प्रोसेस किए गए नतीजों को सेव करने के लिए सबसे सही है.
- डेटा स्टोरेज: BigQuery ने हमारे डेटा वेयरहाउस के तौर पर काम किया. यह कुकी, वीडियो यूआरएल की सूची, उनकी स्थिति (जैसे, PENDING, PROCESSING, COMPLETED) और जनरेट किए गए फ़ाइनल कॉन्टेक्स्ट को सेव करती है. यह एकमात्र भरोसेमंद सोर्स है, जिससे पता चलता है कि किन वीडियो को प्रोसेस करने की ज़रूरत है.
- डेस्टिनेशन: यह वह जगह है जहां एआई से जनरेट की गई अहम जानकारी सेव की जाती है. इससे डाउनस्ट्रीम ऐप्लिकेशन के लिए, इस जानकारी को आसानी से क्वेरी किया जा सकता है या मैन्युअल तरीके से इसकी समीक्षा की जा सकती है. हमारे डेटासेट में वीडियो सेशन की जानकारी शामिल थी. खास तौर पर, "कोड विपश्यना सीज़न" कॉन्टेंट से जुड़ी जानकारी. इसमें अक्सर तकनीकी प्रदर्शनों के बारे में पूरी जानकारी शामिल होती है.
- सोर्स टेबल: यह BigQuery टेबल होती है.उदाहरण के लिए, post_session_labs. इसमें इस तरह के रिकॉर्ड होते हैं:
- id: यह हर सेशन/लाइन के लिए एक यूनीक आइडेंटिफ़ायर होता है.
- url: वीडियो का यूआरएल. जैसे, YouTube का लिंक या ऐक्सेस किया जा सकने वाला Drive का लिंक.
- status: यह एक स्ट्रिंग है.इससे प्रोसेसिंग की स्थिति के बारे में पता चलता है. जैसे, PENDING, PROCESSING, COMPLETED, FAILED_PROCESSING.
- context: यह एक स्ट्रिंग फ़ील्ड है. इसमें एआई से जनरेट की गई खास जानकारी सेव की जाती है.
- डेटा इंपोर्ट करना: इस उदाहरण में, INSERT स्क्रिप्ट की मदद से डेटा को BigQuery में इंपोर्ट किया गया था. हमारी पाइपलाइन के लिए, BigQuery शुरुआती पॉइंट था.
BigQuery कंसोल पर जाएं, नया टैब खोलें, और यहां दिए गए एसक्यूएल स्टेटमेंट लागू करें:
--1. Create your dataset for the project
CREATE SCHEMA `<<YOUR_PROJECT_ID>>.cv_metadata`
OPTIONS(
location = 'us-central1', -- Specify the location (e.g., 'US', 'EU', 'asia-east1')
description = 'Code Vipassana Sessions Metadata' -- Optional: Add a description
);
--2. Create table
create table cv_metadata.post_session_labs(id STRING, descr STRING, url STRING, context STRING, status STRING);
4. डेटा डालना
अब स्टोर के बारे में जानकारी देने वाली टेबल जोड़ें. BigQuery Studio में किसी टैब पर जाएं और सैंपल रिकॉर्ड डालने के लिए, यहां दिए गए SQL स्टेटमेंट लागू करें:
--Insert sample data
insert into cv_metadata.post_session_labs(id,descr,url) values('10-1','Gen AI to Agents, where do I begin? Get started with building a single agent application on ADK Python SDK','https://youtu.be/tyqnQQXpxtI');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-2','Build an E2E multi-agent kitchen renovation app on ADK in Python with AlloyDB data and multiple tools','https://youtu.be/RdrMo2lNh0o');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-3','Augment your multiagent app with tools from MCP Toolbox for AlloyDB','https://youtu.be/9VVNh77Q3ZU?si=oQ4fhAX59Y3D5iWa');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-4','Build an agentic MCP client application using MCP Toolbox for BigQuery','https://youtu.be/HmluMag5s20');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-5','Build a travel agent using ADK & MCP Toolbox for Cloud SQL','https://youtu.be/IWg5CH6ZNs0');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-6','Build an E2E Patent Analysis Agent using ADK and Advanced Vector Search with AlloyDB','https://youtu.be/yCXJ3sk3Lxc');
insert into cv_metadata.post_session_labs(id,descr,url) values('10-7','Getting Started with MCP, ADK and A2A','https://youtu.be/JcQ_DyWc0X0');
update cv_metadata.post_session_labs set status = ‘PENDING' where id is not null;
5. वीडियो की अहम जानकारी देने वाले फ़ंक्शन को बनाना
हमें Cloud Run फ़ंक्शन बनाना और डिप्लॉय करना होगा, ताकि वीडियो के यूआरएल से किताब के चैप्टर का स्ट्रक्चर्ड वर्शन बनाया जा सके. इसे इंडिपेंडेंट एंडपॉइंट टूलबॉक्स टूल के तौर पर ऐक्सेस करने के लिए, हमने अभी-अभी एक Cloud Run फ़ंक्शन बनाया और डिप्लॉय किया है. इसके अलावा, Cloud Run Job के लिए, इस फ़ंक्शन को Python ऐप्लिकेशन में अलग से शामिल किया जा सकता है:
- Google Cloud Console में, Cloud Run पेज पर जाएं
- 'फ़ंक्शन लिखें' पर क्लिक करें.
- 'सेवा का नाम' फ़ील्ड में, अपने फ़ंक्शन के बारे में बताने के लिए कोई नाम डालें. सेवा के नाम की शुरुआत सिर्फ़ किसी अक्षर से होनी चाहिए. साथ ही, इसमें 49 या इससे कम वर्ण होने चाहिए. इनमें अक्षर, संख्याएं या हाइफ़न शामिल हैं. सेवा के नाम, हाइफ़न से खत्म नहीं होने चाहिए. साथ ही, हर क्षेत्र और प्रोजेक्ट के लिए ये नाम अलग-अलग होने चाहिए. सेवा का नाम बाद में नहीं बदला जा सकता. यह सार्वजनिक तौर पर दिखता है. ( generate-video-insights**)**
- रीजन की सूची में, डिफ़ॉल्ट वैल्यू का इस्तेमाल करें या वह रीजन चुनें जहां आपको फ़ंक्शन डिप्लॉय करना है. (us-central1 चुनें)
- रनटाइम की सूची में, डिफ़ॉल्ट वैल्यू का इस्तेमाल करें या रनटाइम का कोई वर्शन चुनें. (Python 3.11 चुनें)
- Authentication सेक्शन में जाकर, "Allow public access" चुनें
- "बनाएं" बटन पर क्लिक करें
- फ़ंक्शन बनाया जाता है और यह main.py और requirements.txt टेंप्लेट के साथ लोड होता है
- इस प्रोजेक्ट के रेपो से, इन फ़ाइलों को बदलें: main.py और requirements.txt
अहम जानकारी: main.py में, <<YOUR_PROJECT_ID>> की जगह अपना प्रोजेक्ट आईडी डालना न भूलें.
- एंडपॉइंट को डिप्लॉय करें और सेव करें, ताकि Cloud Run जॉब के लिए इसका इस्तेमाल किया जा सके.
आपका एंडपॉइंट कुछ ऐसा दिखना चाहिए (या इससे मिलता-जुलता): https://generate-video-insights-<<YOUR_POJECT_NUMBER>>.us-central1.run.app
इस Cloud Run फ़ंक्शन में क्या है?
वीडियो प्रोसेसिंग के लिए Gemini 2.5 Flash
वीडियो कॉन्टेंट को समझने और उसकी खास जानकारी देने के मुख्य काम के लिए, हमने Google के Gemini 2.5 Flash मॉडल का इस्तेमाल किया. Gemini मॉडल, कई तरह के काम करने वाले एआई मॉडल हैं. ये टेक्स्ट और वीडियो जैसे अलग-अलग तरह के इनपुट को समझ सकते हैं और उन्हें प्रोसेस कर सकते हैं.
हमने अपने सेटअप में, वीडियो फ़ाइल को सीधे तौर पर Gemini को नहीं दिया. इसके बजाय, हमने टेक्स्ट वाला एक प्रॉम्प्ट भेजा. इसमें वीडियो का यूआरएल शामिल था. साथ ही, Gemini को यह निर्देश दिया गया था कि उस यूआरएल पर मौजूद (काल्पनिक) वीडियो के कॉन्टेंट का विश्लेषण कैसे किया जाए. Gemini 2.5 Flash में टेक्स्ट, इमेज, वीडियो वगैरह का इस्तेमाल करके इनपुट दिया जा सकता है. हालांकि, इस खास पाइपलाइन में टेक्स्ट पर आधारित प्रॉम्प्ट का इस्तेमाल किया गया था. इसमें वीडियो के बारे में बताया गया था कि यह एक हैंड्स-ऑन लैब सेशन है. साथ ही, स्ट्रक्चर्ड JSON आउटपुट का अनुरोध किया गया था. यह Gemini की, तर्क करने और स्वाभाविक भाषा को समझने की बेहतर क्षमता का इस्तेमाल करता है. इससे, प्रॉम्प्ट के कॉन्टेक्स्ट के आधार पर जानकारी का अनुमान लगाया जा सकता है और उसे इकट्ठा किया जा सकता है.
Gemini के लिए प्रॉम्प्ट: एआई को निर्देश देना
एआई मॉडल के लिए, अच्छी तरह से तैयार किया गया प्रॉम्प्ट बहुत ज़रूरी होता है. हमारे प्रॉम्प्ट को इस तरह से डिज़ाइन किया गया था कि वह खास जानकारी निकाल सके और उसे JSON फ़ॉर्मैट में स्ट्रक्चर कर सके. इससे हमारा ऐप्लिकेशन उसे आसानी से पार्स कर पाता है.
PROMPT_TEMPLATE = """
In the video at the following URL: {youtube_url}, which is a hands-on lab session:
Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Take only the first 30-40 minutes of the video without throwing any error.
Analyze the rest of the content of the video.
Extract and synthesize information to create a book chapter section with the following structure, formatted as a JSON string:
1. **chapter_title:** A concise and engaging title for the chapter.
2. **introduction_context:** Briefly explain the relevance of this video segment within a broader learning context.
3. **what_will_build:** Clearly state the specific task or goal accomplished in this video segment.
4. **technologies_and_services:** List all mentioned Google Cloud services and any other relevant technologies (e.g., programming languages, tools, frameworks).
5. **how_we_did_it:** Provide a clear, numbered step-by-step guide of the actions performed. Include any exact commands or code snippets as they appear in the video. Format code/commands using markdown backticks (e.g., `my-command`).
6. **source_code_url:** Provide a URL to the source code repository if mentioned or implied. If not available, use "N/A".
7. **demo_url:** Provide a URL to a demo if mentioned or implied. If not available, use "N/A".
8. **qa_segment:** Generate 10–15 relevant questions based on the content of this segment, along with concise answers. Ensure the questions are thought-provoking and test understanding of the material.
REMEMBER: Ignore the credits set-up part particularly the coupon code and credits link aspect should not be included in your analysis or the extaction of context. Also exclude any credentials that are explicit in the video.
Format the entire output as a JSON string. Ensure all keys and string values are enclosed in double quotes.
Example structure:
...
"""
यह प्रॉम्प्ट बहुत खास है. इससे Gemini को एक शिक्षक की तरह काम करने का निर्देश मिलता है. JSON स्ट्रिंग के लिए किए गए अनुरोध से, स्ट्रक्चर्ड और मशीन से पढ़े जा सकने वाले आउटपुट मिलते हैं.
वीडियो इनपुट का विश्लेषण करने और उसका कॉन्टेक्स्ट वापस पाने के लिए कोड यहां दिया गया है:
def process_videos_batch(video_url: str, PROMPT_TEMPLATE: str) -> str:
"""
Processes a video URL, generates chapter content using Gemini
"""
formatted_prompt = PROMPT_TEMPLATE.format(youtube_url=video_url)
try:
client = genai.Client(vertexai=True,project='<<YOUR_PROJECT_ID>>',location='us-central1',http_options=HttpOptions(api_version="v1"))
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=formatted_prompt,
)
print(response.text)
except Exception as e:
print(f"An error occurred during content generation: {e}")
return f"Error processing video: {e}"
print(response.text)
return response.text
ऊपर दिए गए स्निपेट में, इस्तेमाल के उदाहरण का मुख्य फ़ंक्शन दिखाया गया है. इसे वीडियो का यूआरएल मिलता है. यह वीडियो के कॉन्टेंट का विश्लेषण करने और प्रॉम्प्ट के हिसाब से काम की अहम जानकारी निकालने के लिए, Vertex AI क्लाइंट के ज़रिए Gemini मॉडल का इस्तेमाल करता है. इसके बाद, निकाले गए कॉन्टेक्स्ट को आगे की प्रोसेस के लिए वापस भेज दिया जाता है. यह एक सिंक्रोनस ऑपरेशन है, जिसमें Cloud Run Job, सेवा के पूरा होने का इंतज़ार करता है.
6. पाइपलाइन ऐप्लिकेशन डेवलपमेंट (Python)
हमारी सेंट्रल पाइपलाइन का लॉजिक, ऐप्लिकेशन के सोर्स कोड में मौजूद होता है. इसे Cloud Run जॉब में कंटेनर के तौर पर रखा जाएगा. यह पूरे पैरलल एक्ज़ीक्यूशन को व्यवस्थित करता है. यहां मुख्य हिस्सों के बारे में बताया गया है:
वर्कफ़्लो को मैनेज करने और डेटा की सुरक्षा को पक्का करने में ऑर्केस्ट्रेटर की भूमिका:
# ... (imports and configuration) ...
def process_batch_from_bq(request_or_trigger_data=None):
# ... (initial checks for config) ...
BATCH_SIZE = 5 # Fetch 5 URLs at a time per job instance
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
try:
logging.info(f"Fetching up to {BATCH_SIZE} pending URLs from BigQuery...")
rows = bq_client.query(query).result() # job_should_wait=True is default for result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
if not pending_urls_data:
logging.info("No pending URLs found. Job finished.")
return "No pending URLs found. Job finished.", 200
row_ids_to_process = [item["id"] for item in pending_urls_data]
# --- Mark as PROCESSING to prevent duplicate work ---
update_status_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
SET status = 'PROCESSING'
WHERE id IN UNNEST(@row_ids_to_process)
"""
status_update_job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ArrayQueryParameter("row_ids_to_process", "STRING", values=row_ids_to_process)
]
)
update_status_job = bq_client.query(update_status_query, job_config=status_update_job_config)
update_status_job.result()
logging.info(f"Marked {len(row_ids_to_process)} URLs as 'PROCESSING'.")
# ... (rest of the code for parallel processing and writing) ...
except Exception as e:
# ... (error handling) ...
ऊपर दिए गए इस स्निपेट में, BigQuery सोर्स टेबल से ‘PENDING' स्टेटस वाले वीडियो यूआरएल का बैच फ़ेच किया जाता है. इसके बाद, यह BigQuery में इन यूआरएल की स्थिति को ‘PROCESSING' के तौर पर अपडेट करता है, ताकि डुप्लीकेट प्रोसेसिंग को रोका जा सके.
ThreadPoolExecutor की मदद से, एक साथ प्रोसेस करने की सुविधा और प्रोसेसर सेवा को कॉल करना:
# ... (inside process_batch_from_bq function) ...
# --- Step 3: Call the external URL Processor Service in parallel ---
processed_results = {}
futures = []
# ThreadPoolExecutor for I/O-bound tasks (HTTP requests to the processor service)
# MAX_CONCURRENT_TASKS_PER_INSTANCE controls parallelism within one job instance.
with ThreadPoolExecutor(max_workers=MAX_CONCURRENT_TASKS_PER_INSTANCE) as executor:
for item in pending_urls_data:
url = item["url"]
row_id = item["id"]
# Submit the task: call the processor service for this URL
future = executor.submit(call_url_processor_service, url)
futures.append((row_id, future))
# Collect results as they complete
for row_id, future in futures:
try:
content = future.result(timeout=URL_PROCESSOR_TIMEOUT_SECONDS)
# Check if the processor service returned an error message
if content.startswith("ERROR:"):
processed_results[row_id] = {"context": content, "status": "FAILED_PROCESSING"}
else:
processed_results[row_id] = {"context": content, "status": "COMPLETED"}
except TimeoutError:
logging.warning(f"URL processing timed out (service call for row ID {row_id}). Marking as FAILED.")
processed_results[row_id] = {"context": f"ERROR: Processing timed out for '{row_id}'.", "status": "FAILED_PROCESSING"}
except Exception as e:
logging.error(f"Exception during future result retrieval for row ID {row_id}: {e}")
processed_results[row_id] = {"context": f"ERROR: Unexpected error during result retrieval for '{row_id}'. Details: {e}", "status": "FAILED_PROCESSING"}
कोड का यह हिस्सा, फ़ेच किए गए वीडियो के यूआरएल को एक साथ प्रोसेस करने के लिए, ThreadPoolExecutor का इस्तेमाल करता है. यह हर यूआरएल के लिए, Cloud Run Service (यूआरएल प्रोसेसर) को एसिंक्रोनस तरीके से कॉल करने का टास्क सबमिट करता है. इससे Cloud Run Job, एक साथ कई वीडियो को बेहतर तरीके से प्रोसेस कर पाता है. इससे पूरी पाइपलाइन की परफ़ॉर्मेंस बेहतर होती है. यह स्निपेट, प्रोसेसर सेवा से होने वाले संभावित टाइमआउट और गड़बड़ियों को भी मैनेज करता है.
BigQuery से डेटा पढ़ना और उसमें डेटा लिखना
BigQuery के साथ मुख्य इंटरैक्शन में, प्रोसेस किए जाने वाले यूआरएल फ़ेच करना और फिर उन्हें प्रोसेस किए गए नतीजों के साथ अपडेट करना शामिल है.
# ... (inside process_batch_from_bq) ...
BATCH_SIZE = 5
query = f"""
SELECT url, id
FROM `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_SOURCE}`
WHERE status = 'PENDING'
LIMIT {BATCH_SIZE}
"""
rows = bq_client.query(query).result()
pending_urls_data = []
for row in rows:
pending_urls_data.append({"url": row.url, "id": row.id})
# ... (rest of fetching and marking as PROCESSING) ...
नतीजों को वापस BigQuery में लिखा जा रहा है:
# --- Step 4: Write results back to BigQuery ---
logging.info(f"Writing {len(processed_results)} results back to BigQuery...")
successful_updates = 0
for row_id, data in processed_results.items():
if update_bq_row(row_id, data["context"], data["status"]):
successful_updates += 1
logging.info(f"Finished processing. {successful_updates} out of {len(processed_results)} rows updated successfully.")
# ... (return statement) ...
# --- Helper to update a single row in BigQuery ---
def update_bq_row(row_id, context, status="COMPLETED"):
"""Updates a specific row in the target BigQuery table."""
# ... (checks for config) ...
update_query = f"""
UPDATE `{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{BIGQUERY_TABLE_TARGET}`
SET
context = @context,
status = @status
WHERE id = @row_id
"""
# Correctly defining query parameters for the UPDATE statement
job_config = bigquery.QueryJobConfig(
query_parameters=[
bigquery.ScalarQueryParameter("context", "STRING", value=context),
bigquery.ScalarQueryParameter("status", "STRING", value=status),
# Assuming 'id' column is STRING. Adjust if it's INT64.
bigquery.ScalarQueryParameter("row_id", "STRING", value=row_id)
]
)
try:
update_job = bq_client.query(update_query, job_config=job_config)
update_job.result() # Wait for the job to complete
logging.info(f"Successfully updated BigQuery row ID {row_id} with status {status}.")
return True
except Exception as e:
logging.error(f"Failed to update BigQuery row ID {row_id}: {e}")
return False
ऊपर दिए गए स्निपेट, Cloud Run Job और BigQuery के बीच डेटा इंटरैक्शन पर फ़ोकस करते हैं. यह सोर्स टेबल से, ‘PENDING' स्थिति वाले वीडियो के यूआरएल और उनके आईडी का बैच वापस लाता है. यूआरएल प्रोसेस होने के बाद, यह स्निपेट दिखाता है कि UPDATE क्वेरी का इस्तेमाल करके, निकाले गए कॉन्टेक्स्ट और स्टेटस (‘COMPLETED' या ‘FAILED_PROCESSING') को वापस टारगेट BigQuery टेबल में कैसे लिखा जाता है. यह स्निपेट, डेटा प्रोसेसिंग लूप को पूरा करता है. इसमें update_bq_row हेल्पर फ़ंक्शन भी शामिल है. यह दिखाता है कि अपडेट स्टेटमेंट के पैरामीटर कैसे तय किए जाते हैं.
ऐप्लिकेशन सेटअप
ऐप्लिकेशन को एक ही Python स्क्रिप्ट के तौर पर स्ट्रक्चर किया गया है. इसे कंटेनर में रखा जाएगा. यह अपने एंट्री पॉइंट को तय करने के लिए, Google Cloud की क्लाइंट लाइब्रेरी और फ़ंक्शन-फ़्रेमवर्क का इस्तेमाल करता है.
- डिपेंडेंसी: google-cloud-bigquery, requests
- कॉन्फ़िगरेशन: सभी ज़रूरी सेटिंग (BigQuery प्रोजेक्ट/डेटासेट/टेबल, यूआरएल प्रोसेसर सेवा का यूआरएल) एनवायरमेंट वैरिएबल से लोड की जाती हैं. इससे ऐप्लिकेशन को पोर्टेबल और सुरक्षित बनाया जा सकता है
- मुख्य लॉजिक: process_batch_from_bq फ़ंक्शन, पूरे वर्कफ़्लो को व्यवस्थित करता है
- बाहरी सेवा का इंटिग्रेशन: call_url_processor_service फ़ंक्शन, अलग Cloud Run सेवा के साथ कम्यूनिकेशन को मैनेज करता है
- BigQuery इंटरैक्शन: bq_client का इस्तेमाल यूआरएल फ़ेच करने और नतीजों को अपडेट करने के लिए किया जाता है. साथ ही, पैरामीटर को सही तरीके से हैंडल किया जाता है
- पैरललिज़्म: concurrent.futures.ThreadPoolExecutor, बाहरी सेवा के लिए एक साथ किए जाने वाले कॉल मैनेज करता है
- एंट्री पॉइंट: main.py नाम का Python कोड, एंट्रीपॉइंट के तौर पर काम करता है. यह बैच प्रोसेसिंग शुरू करता है.
अब ऐप्लिकेशन सेट अप करते हैं:
- इसके लिए, Cloud Shell टर्मिनल पर जाएं और रिपॉज़िटरी को क्लोन करें:
git clone https://github.com/AbiramiSukumaran/video-context-crj
- Cloud Shell Editor पर जाएं. यहां आपको नया बनाया गया फ़ोल्डर video-context-crj दिखेगा
- नीचे दिए गए चरणों को मिटाएं, क्योंकि ये चरण पिछले सेक्शन में पहले ही पूरे किए जा चुके हैं:
- Cloud_Run_Function फ़ोल्डर मिटाएँ
- प्रोजेक्ट फ़ोल्डर video-context-crj पर जाएं. आपको प्रोजेक्ट का यह स्ट्रक्चर दिखेगा:
7. Dockerfile सेटअप और कंटेनराइज़ेशन
इस लॉजिक को Cloud Run जॉब के तौर पर डिप्लॉय करने के लिए, हमें इसे कंटेनर में रखना होगा. कंटेनर बनाने की प्रोसेस में, हमारे ऐप्लिकेशन कोड, उसकी डिपेंडेंसी, और रनटाइम को पोर्टेबल इमेज में पैकेज किया जाता है.
पक्का करें कि आपने Dockerfile में, प्लेसहोल्डर (बोल्ड टेक्स्ट) को अपनी वैल्यू से बदल दिया हो:
# Use an official Python runtime as a parent image
FROM python:3.12-alpine
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Copy the rest of the application code
COPY . .
# Define environment variables for configuration (these will be overridden during deployment)
ENV BIGQUERY_PROJECT="YOUR-project"
ENV BIGQUERY_DATASET="YOUR-dataset"
ENV BIGQUERY_TABLE_SOURCE="YOUR-source-table"
ENV URL_PROCESSOR_SERVICE_URL="ENDPOINT FOR VIDEO PROCESSING"
ENV BIGQUERY_TABLE_TARGET = "YOUR-destination-table"
ENTRYPOINT ["python", "main.py"]
ऊपर दिए गए Dockerfile स्निपेट में, बेस इमेज को तय किया गया है. साथ ही, इसमें डिपेंडेंसी इंस्टॉल करने, हमारे कोड को कॉपी करने, और सही टारगेट फ़ंक्शन (process_batch_from_bq) के साथ functions-framework का इस्तेमाल करके, हमारे ऐप्लिकेशन को चलाने के लिए कमांड सेट करने की जानकारी दी गई है. इसके बाद, इस इमेज को Artifact Registry में पुश किया जाता है.
कंटेनर बनाना
इसे कंटेनर में बदलने के लिए, Cloud Shell टर्मिनल पर जाएं और यहां दिए गए निर्देश लागू करें. <<YOUR_PROJECT_ID>> प्लेसहोल्डर को बदलना न भूलें:
export CONTAINER_IMAGE="gcr.io/<<YOUR_PROJECT_ID>>/batch-url-processor-orchestrator:latest"
gcloud builds submit --tag $CONTAINER_IMAGE .
कंटेनर इमेज बन जाने के बाद, आपको यह आउटपुट दिखेगा:
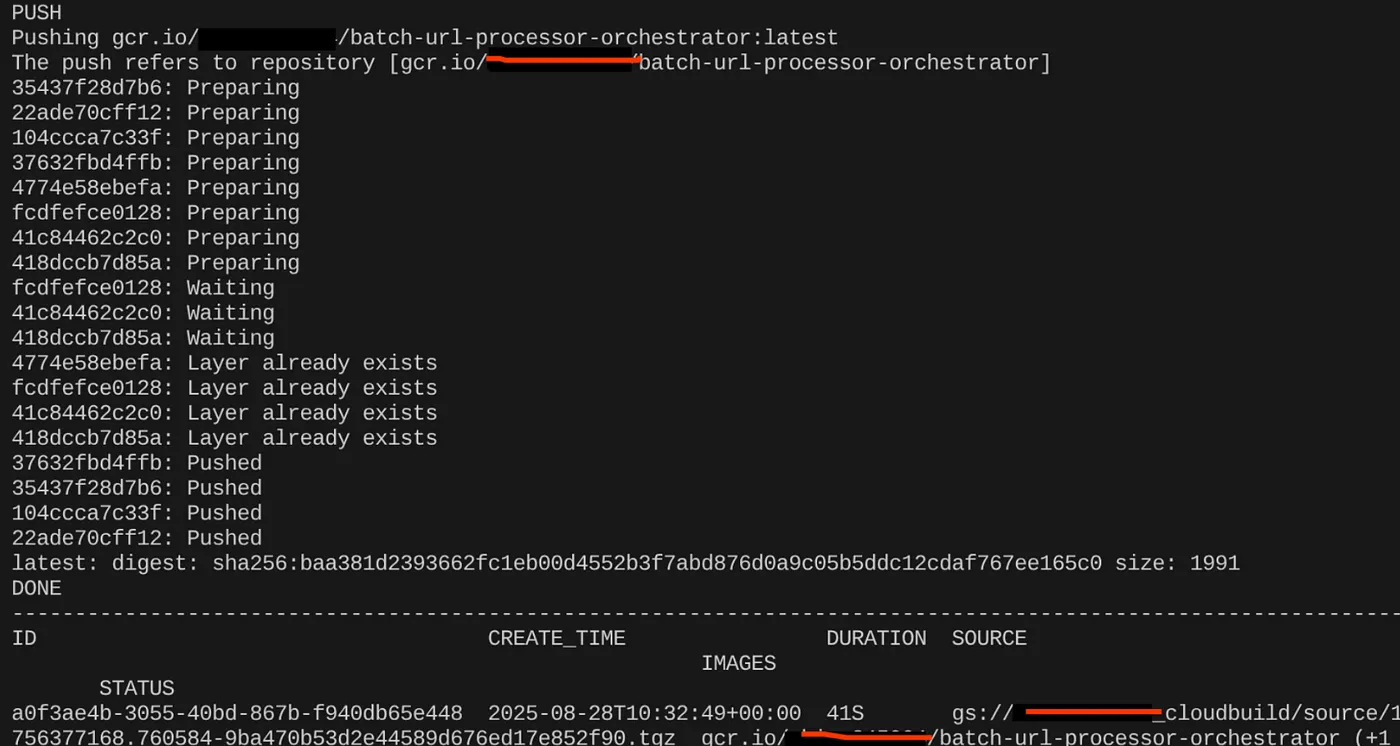
अब हमारा कंटेनर बन गया है और Artifact Registry में सेव हो गया है. अब हम अगले चरण पर जा सकते हैं.
8. Cloud Run जॉब बनाना
जॉब को डिप्लॉय करने के लिए, कंटेनर इमेज बनाई जाती है. इसके बाद, Cloud Run Job का संसाधन बनाया जाता है.
हमने कंटेनर इमेज पहले ही बना ली है और उसे Artifact Registry में सेव कर दिया है. अब हम जॉब बनाते हैं.
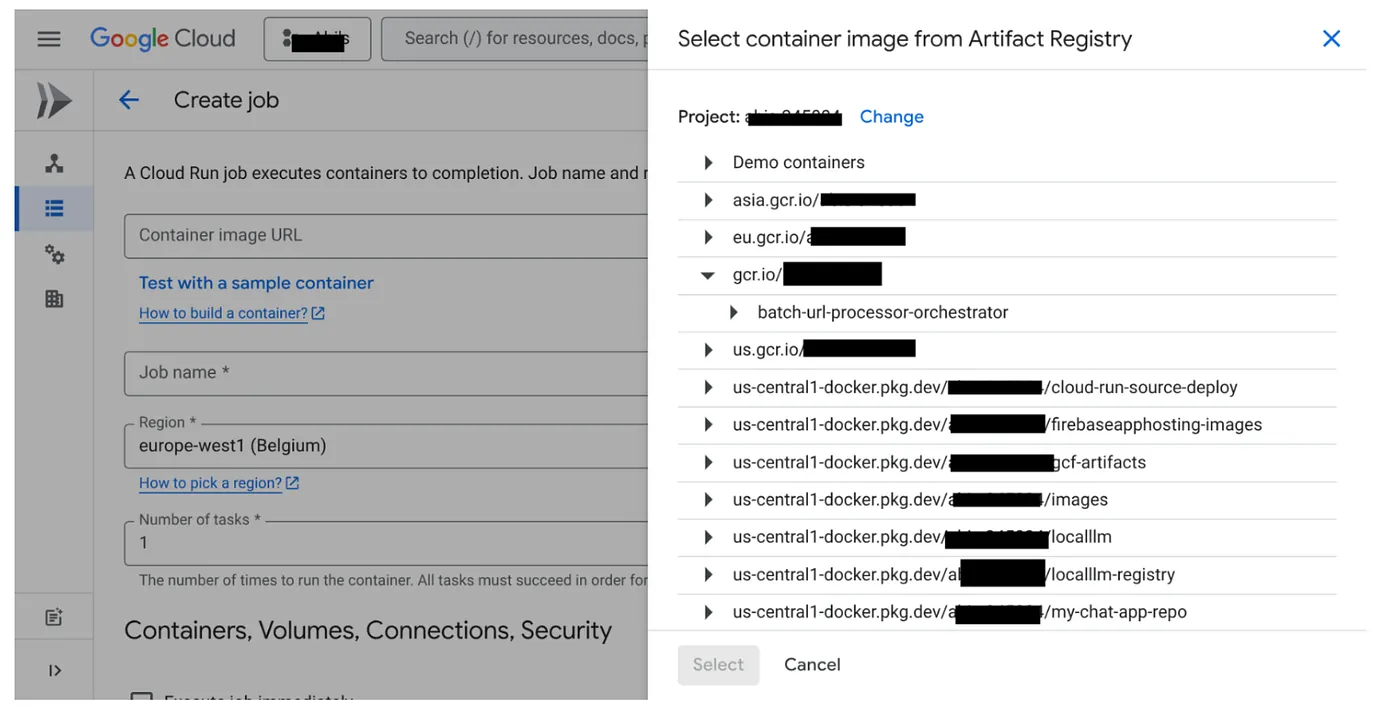
- Cloud Run Jobs कंसोल पर जाएं और कंटेनर डिप्लॉय करें पर क्लिक करें:

- हमने अभी जो कंटेनर इमेज बनाई है उसे चुनें:
- कॉन्फ़िगरेशन की अन्य जानकारी इस तरह डालें:

- टास्क की क्षमता को इस तरह सेट करें:
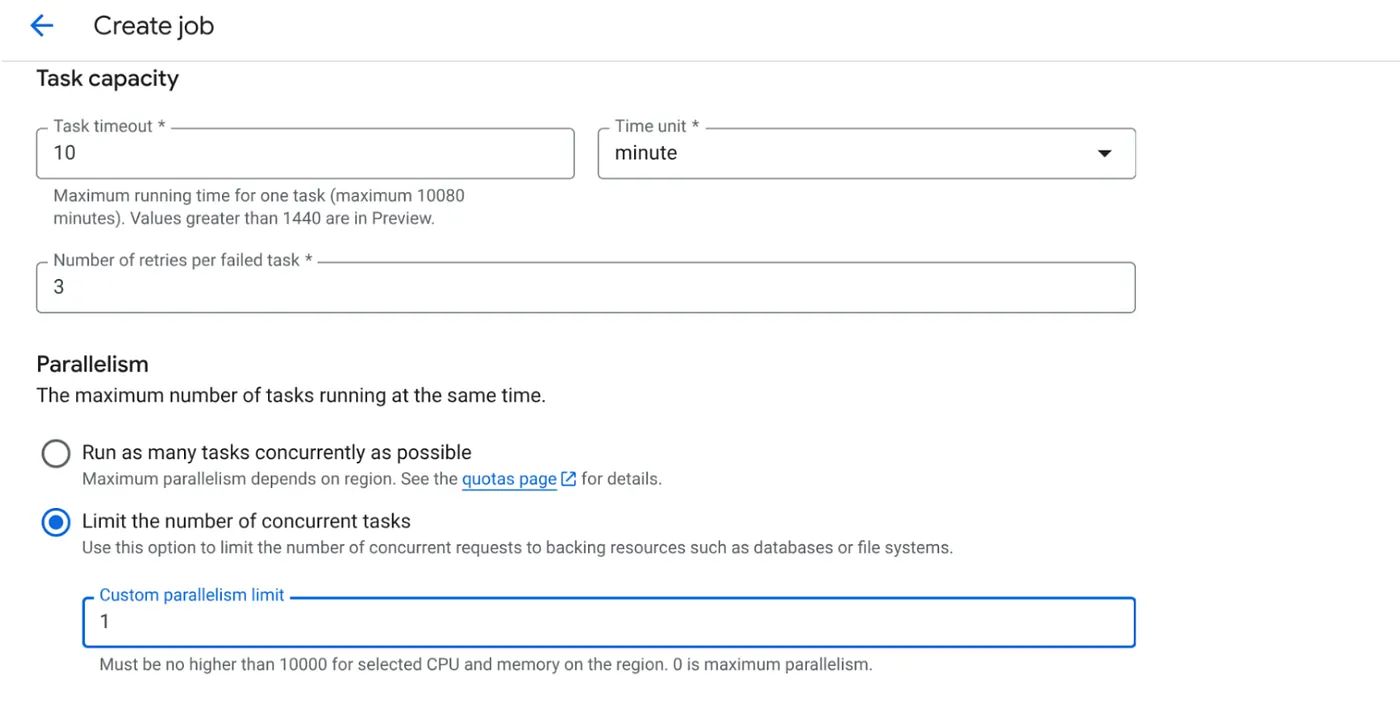
हमारे पास डेटाबेस राइट हैं. साथ ही, कोड में पैरललाइज़ेशन (max_instances और task concurrency) को पहले ही हैंडल किया जा चुका है. इसलिए, हम एक साथ चलने वाले टास्क की संख्या को 1 पर सेट करेंगे. हालांकि, अपनी ज़रूरत के हिसाब से इसे बढ़ाया जा सकता है. यहां मकसद यह है कि टास्क, कॉन्फ़िगरेशन के मुताबिक पूरे किए जाएं. साथ ही, पैरललिज़्म में सेट किए गए कॉन्करेंसी लेवल के मुताबिक पूरे किए जाएं.
- बनाएं पर क्लिक करें
आपका Cloud Run Job बन जाएगा.
यह कैसे काम करता है
हमारे काम का कंटेनर इंस्टेंस शुरू होता है. यह BigQuery से, PENDING के तौर पर मार्क किए गए यूआरएल का छोटा बैच (BATCH_SIZE) पाने के लिए क्वेरी करता है. यह फ़ेच किए गए यूआरएल की स्थिति को BigQuery में तुरंत PROCESSING के तौर पर अपडेट करता है, ताकि अन्य जॉब इंस्टेंस उन्हें न चुन सकें. यह ThreadPoolExecutor बनाता है और बैच में मौजूद हर यूआरएल के लिए एक टास्क सबमिट करता है. हर टास्क, call_url_processor_service फ़ंक्शन को कॉल करता है. call_url_processor_service के अनुरोध पूरे होने (या टाइम आउट/काम न करने) पर, उनके नतीजे (एआई से जनरेट किया गया कॉन्टेक्स्ट या गड़बड़ी का मैसेज) इकट्ठा किए जाते हैं. इसके बाद, उन्हें ओरिजनल row_id पर वापस मैप किया जाता है. बैच के सभी टास्क पूरे होने के बाद, जॉब इकट्ठा किए गए नतीजों को दोहराती है. साथ ही, BigQuery में हर लाइन के लिए कॉन्टेक्स्ट और स्टेटस फ़ील्ड को अपडेट करती है. अगर यह प्रोसेस पूरी हो जाती है, तो जॉब इंस्टेंस बंद हो जाता है. अगर इसे ऐसी गड़बड़ियां मिलती हैं जिन्हें हैंडल नहीं किया गया है, तो यह एक अपवाद दिखाता है. इससे Cloud Run Jobs, फिर से कोशिश करने की प्रोसेस को ट्रिगर कर सकता है. हालांकि, यह जॉब के कॉन्फ़िगरेशन पर निर्भर करता है.
Cloud Run Jobs का इस्तेमाल कहां किया जा सकता है: ऑर्केस्ट्रेशन
Cloud Run Jobs की सबसे बड़ी खासियत यही है.
बिना सर्वर वाली बैच प्रोसेसिंग: हमें मैनेज किया गया इंफ़्रास्ट्रक्चर मिलता है. यह हमारे डेटा को एक साथ प्रोसेस करने के लिए, ज़रूरत के हिसाब से ज़्यादा से ज़्यादा कंटेनर इंस्टेंस (MAX_INSTANCES तक) स्पिन अप कर सकता है.
पैरललिज़्म कंट्रोल: हम MAX_INSTANCES (कुल मिलाकर, एक साथ कितने जॉब चल सकते हैं) और TASK_CONCURRENCY (हर जॉब इंस्टेंस, एक साथ कितने ऑपरेशन करता है) तय करते हैं. इससे थ्रूपुट और संसाधन के इस्तेमाल पर बेहतर कंट्रोल मिलता है.
गड़बड़ी होने पर भी काम जारी रखना: अगर कोई जॉब इंस्टेंस बीच में ही बंद हो जाता है, तो Cloud Run Jobs को इस तरह से कॉन्फ़िगर किया जा सकता है कि वह पूरी जॉब या कुछ खास टास्क को फिर से शुरू कर सके. इससे यह पक्का किया जा सकता है कि डेटा प्रोसेसिंग बंद न हो.
आसान आर्किटेक्चर: जॉब में सीधे तौर पर एचटीटीपी कॉल को व्यवस्थित करके और स्टेट मैनेजमेंट के लिए BigQuery का इस्तेमाल करके, हम Pub/Sub, इसके विषयों, सदस्यता, और सूचना पाने की सुविधा को सेट अप करने और मैनेज करने की जटिलता से बचते हैं.
MAX_INSTANCES बनाम TASK_CONCURRENCY:
MAX_INSTANCES: यह आपके पूरे जॉब एक्ज़ीक्यूशन में एक साथ चल सकने वाले जॉब इंस्टेंस की कुल संख्या होती है. एक साथ कई यूआरएल प्रोसेस करने के लिए, यह मुख्य पैरललिज़्म लीवर है.
TASK_CONCURRENCY: यह आपके जॉब के एक इंस्टेंस के ज़रिए एक साथ किए जाने वाले ऑपरेशन (प्रोसेसर सेवा को कॉल) की संख्या होती है. इससे एक इंस्टेंस के सीपीयू/नेटवर्क पर ज़्यादा लोड पड़ता है.
9. Cloud Run जॉब को एक्ज़ीक्यूट करना और उसकी निगरानी करना
वीडियो मेटाडेटा
'लागू करें' पर क्लिक करने से पहले, डेटा का स्टेटस देखते हैं.
BigQuery Studio पर जाएं और यह क्वेरी चलाएं:
Select id, descr, url, status from cv_metadata.post_session_labs where status = ‘PENDING'
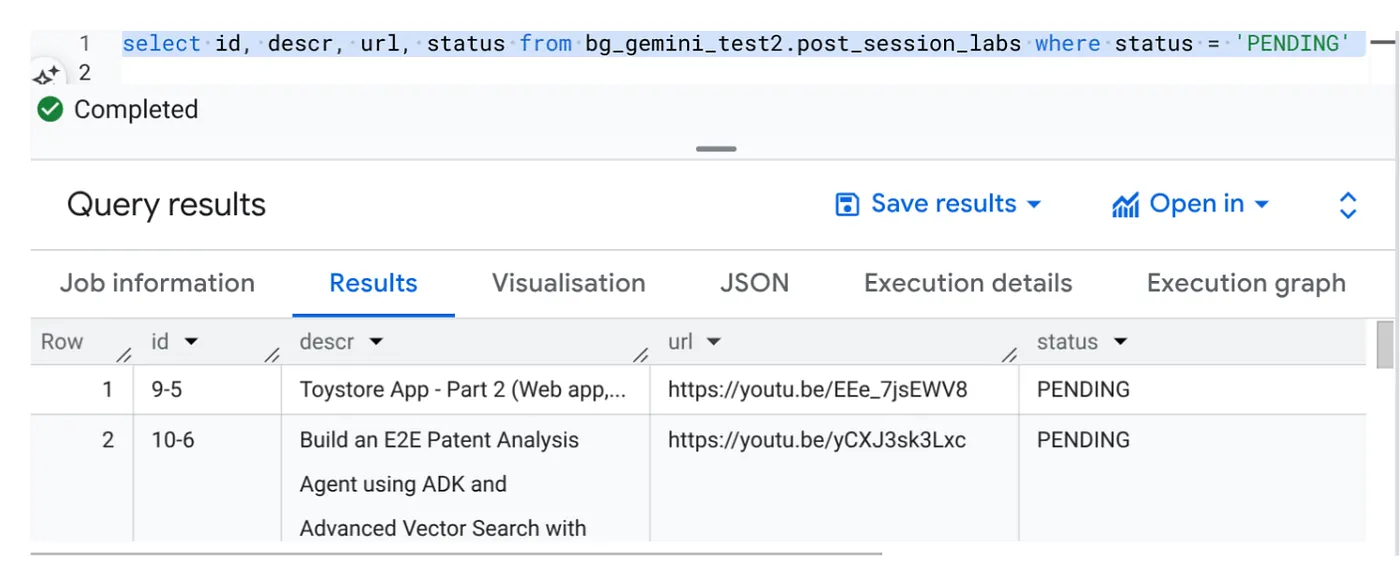
हमारे पास वीडियो के यूआरएल वाले कुछ सैंपल रिकॉर्ड हैं. इनकी स्थिति 'लंबित है' के तौर पर सेट है. हमारा लक्ष्य, "संदर्भ" फ़ील्ड में वीडियो से मिली अहम जानकारी को प्रॉम्प्ट में बताए गए फ़ॉर्मैट में भरना है.
जॉब ट्रिगर
आइए, Cloud Run Jobs कंसोल में मौजूद जॉब पर EXECUTE बटन पर क्लिक करके जॉब को लागू करें. आपको कंसोल में जॉब की प्रोग्रेस और स्थिति दिखनी चाहिए:
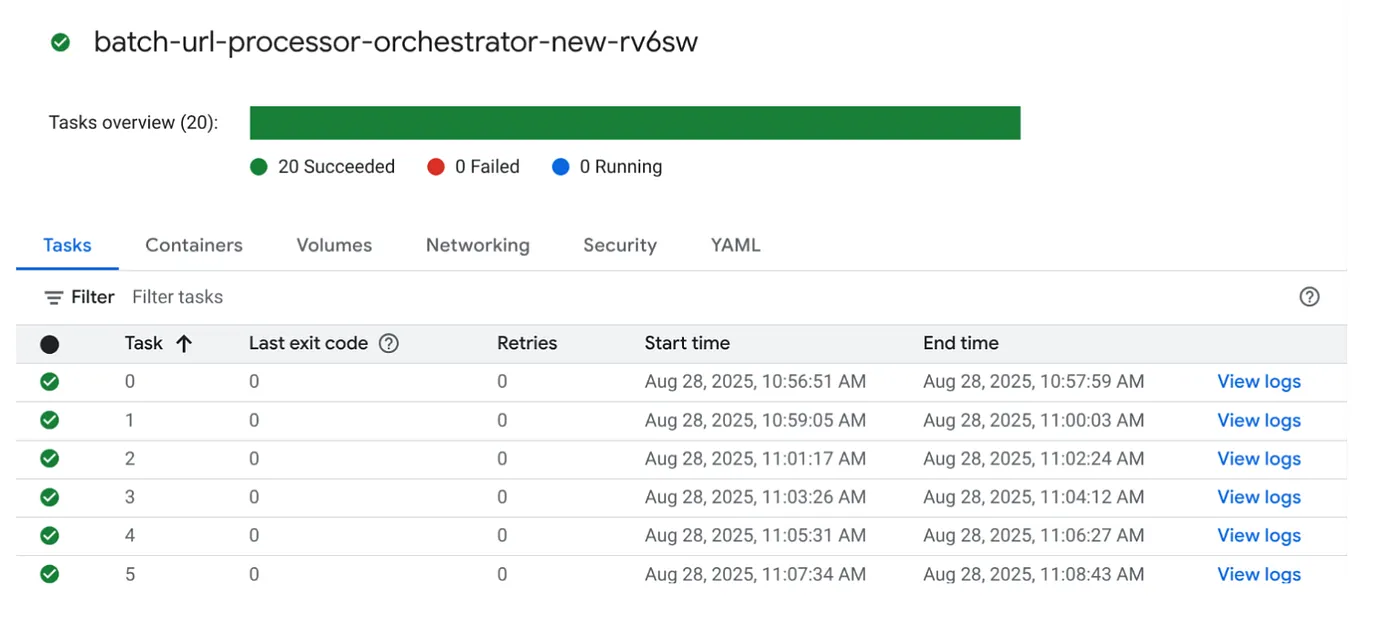
जॉब और टास्क के बारे में निगरानी के चरणों और अन्य जानकारी के लिए, OBSERVABILITY में LOGS टैग देखा जा सकता है.
10. नतीजों का विश्लेषण
टास्क पूरा होने के बाद, आपको टेबल में अपडेट किए गए हर वीडियो यूआरएल के लिए कॉन्टेक्स्ट दिखेगा:
आउटपुट कॉन्टेक्स्ट (किसी एक रिकॉर्ड के लिए)
{
"chapter_title": "Building a Travel Agent with ADK and MCP Toolbox",
"introduction_context": "This chapter section is derived from a hands-on lab session focused on building a travel agent. It details the process of integrating various Google Cloud services and tools to create an intelligent agent capable of querying a database and interacting with users.",
"what_will_build": "The goal is to build and deploy a travel agent that can answer user queries about hotels using the Agent Development Kit (ADK) and the MCP Toolbox for Databases, connecting to a PostgreSQL database.",
"technologies_and_services": [
"Google Cloud Platform",
"Cloud SQL for PostgreSQL",
"Agent Development Kit (ADK)",
"MCP Toolbox for Databases",
"Cloud Shell",
"Cloud Run",
"Python",
"Docker"
],
"how_we_did_it": [
"Provision a Cloud SQL instance for PostgreSQL with the 'hoteldb-instance'.",
"Prepare the 'hotels' database by creating a table with relevant schema and populating it with sample data.",
"Set up the MCP Toolbox for Databases by downloading and configuring the necessary components.",
"Install the Agent Development Kit (ADK) and its dependencies.",
"Create a new agent using the ADK, specifying the model (Gemini 2.0-flash) and backend (Vertex AI).",
"Modify the agent's code to connect to the PostgreSQL database via the MCP Toolbox.",
"Run the agent locally to test its functionality and ability to interact with the database.",
"Deploy the agent to Cloud Run for cloud-based access and further testing.",
"Interact with the deployed agent through a web console or command line to query hotel information."
],
"source_code_url": "N/A",
"demo_url": "N/A",
"qa_segment": [
{
"question": "What is the primary purpose of the MCP Toolbox for Databases?",
"answer": "The MCP Toolbox for Databases is an open-source MCP server designed to help users develop tools faster, more securely, and by handling complexities like connection pooling, authentication, and more."
},
{
"question": "Which Google Cloud service is used to create the database for the travel agent?",
"answer": "Cloud SQL for PostgreSQL is used to create the database."
},
{
"question": "What is the role of the Agent Development Kit (ADK)?",
"answer": "The ADK helps build Generative AI tools that allow agents to access data in a database. It enables agents to perform actions, interact with users, utilize external tools, and coordinate with other agents."
},
{
"question": "What command is used to create the initial agent application using ADK?",
"answer": "The command `adk create hotel-agent-app` is used to create the agent application."
},
....
अब आपके पास, एजेंट के इस्तेमाल के ज़्यादा बेहतर उदाहरणों के लिए, इस JSON स्ट्रक्चर की पुष्टि करने का विकल्प है.
यह तरीका क्यों इस्तेमाल किया गया है?
इस आर्किटेक्चर से, रणनीति के हिसाब से कई फ़ायदे मिलते हैं:
- किफ़ायती: सर्वरलेस सेवाओं का मतलब है कि आपको सिर्फ़ इस्तेमाल की गई सेवाओं के लिए पेमेंट करना होगा. Cloud Run के जॉब का इस्तेमाल न होने पर, उन्हें शून्य तक कम किया जा सकता है.
- स्केलेबिलिटी: Cloud Run Job इंस्टेंस और एक साथ कई अनुरोध प्रोसेस करने की सेटिंग में बदलाव करके, हज़ारों यूआरएल को आसानी से मैनेज किया जा सकता है.
- तेज़ी से काम करने की क्षमता: इसमें, ऐप्लिकेशन और उसकी सेवा को अपडेट करके, प्रोसेसिंग के नए लॉजिक या एआई मॉडल को तेज़ी से डेवलप और डिप्लॉय किया जा सकता है.
- ऑपरेशनल ओवरहेड कम होना: पैच करने या मैनेज करने के लिए कोई सर्वर नहीं होता. Google, इंफ़्रास्ट्रक्चर को मैनेज करता है.
- एआई को सभी के लिए उपलब्ध कराना: यह बैच टास्क के लिए, एआई की मदद से बेहतर प्रोसेसिंग की सुविधा देता है. इसके लिए, एमएल ऑप्स की विशेषज्ञता की ज़रूरत नहीं होती.
11. व्यवस्थित करें
इस पोस्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेजर पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
12. बधाई हो
बधाई हो! आपने Cloud Run Jobs के आधार पर हमारा सलूशन तैयार किया है. साथ ही, डेटा मैनेजमेंट के लिए BigQuery और एआई प्रोसेसिंग के लिए बाहरी Cloud Run सेवा का इस्तेमाल किया है. इससे आपको एक ऐसा सिस्टम बनाने में मदद मिली है जिसे आसानी से बढ़ाया जा सकता है, जो किफ़ायती है, और जिसे आसानी से मैनेज किया जा सकता है. इस पैटर्न से प्रोसेसिंग लॉजिक अलग हो जाता है. साथ ही, मुश्किल इन्फ़्रास्ट्रक्चर के बिना पैरलल एक्ज़ीक्यूशन की अनुमति मिलती है. इससे, अहम जानकारी पाने में लगने वाला समय काफ़ी कम हो जाता है.
हमारा सुझाव है कि आप बैच प्रोसेसिंग की अपनी ज़रूरतों के लिए, Cloud Run Jobs का इस्तेमाल करें. चाहे एआई विश्लेषण को बढ़ाना हो, ईटीएल पाइपलाइन चलाना हो या समय-समय पर डेटा से जुड़े टास्क पूरे करने हों, सर्वरलेस अप्रोच एक असरदार और बेहतर समाधान उपलब्ध कराता है. खुद से शुरू करने के लिए, इसे देखें.
अगर आपको सर्वरलेस और एजेंटिक तरीके से अपने सभी ऐप्लिकेशन बनाने और उन्हें डिप्लॉय करने के बारे में जानना है, तो Code Vipassana के लिए रजिस्टर करें. यह इवेंट, डेटा पर आधारित जनरेटिव एजेंटिक ऐप्लिकेशन को तेज़ी से बनाने पर फ़ोकस करता है!